







 该博客探讨了Transformer在点云处理中的应用,重点介绍了PCT(Point Cloud Transformer)和Point Transformer两个模型。PCT通过naive PCT、Offset-Attention和Neighbor Embedding增强局部特征表示。Point Transformer则提出了新的Attention Module,改进了点云的特征提取。实验结果显示这些方法在点云分类和分割任务上表现出色。
该博客探讨了Transformer在点云处理中的应用,重点介绍了PCT(Point Cloud Transformer)和Point Transformer两个模型。PCT通过naive PCT、Offset-Attention和Neighbor Embedding增强局部特征表示。Point Transformer则提出了新的Attention Module,改进了点云的特征提取。实验结果显示这些方法在点云分类和分割任务上表现出色。
文章目录
Transformer在点云上的应用的研究处于起步阶段。
Transformer的入门可以看我另外一篇博客:从零入门Transformer。
PCT: Point Cloud Transformer
论文链接:https://arxiv.org/abs/2012.09688
代码链接:https://github.com/MenghaoGuo/PCT
naive PCT
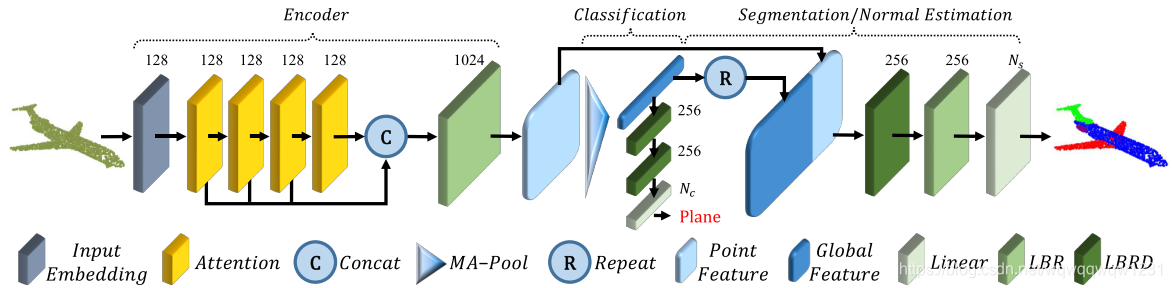
1、输入为点云,用MLP做input embedding。
2、送入transformer中,做成DenseNet的连接形式。
3、然后用LBR进一步提取特征到1024维
4、做MA-Pool,就是max-pooling和average-pooling结合,得到一个global feature
做classification:用这个global feature直接算
做Segmentation和法向量预测:需要恢复到原始点的数量,则把global feature和做MA-pool之前的特征拼接起来。然后用LBR做预测。
Offset-Attention
这块是本文声称的一个创新点:
SA代表self attention这个模块, F s a F_{sa} Fsa代表经过self-attention操作之后的特征

原本的self-attention如上,本文改成了:

然后我认为作者强行与Laplacian matrix关联了一下。那你说有改进,那你就做ablation study看一下效果提升多少啊。
作者也改了normalization的方法。
Neighbor Embedding for Augmented Local Feature Representation
作者认为attention可以很好的提取全局特征,但对于局部特征来说则弱一些。所以作者提出,先用PointNet++来提取一些局部特征,作为transformer的输入。
对于classification,PointNet++中的采样保留就好。但对于分割。就不要FPS这个,对所有点做局部特征提取。
Experiment
实验做出来效果很好,就是没有ablation study说明提出改进的比较性。
Point Transformer
Attention Module
作者首先给出原本transformer的表达式,其中 δ \delta δ是position encoding, ρ \rho ρ是normalizaion函数,例如softmax:

然后作者给出了vector attention的表达式,这里作者也没给出引文,我也没听过没查到说vector attention是啥。但也先不管,其中 γ \gamma γ是MLP, β \beta β是relation function,例如减法:

紧接着,作者给出了本文attention的表达式:

其中, γ \gamma γ, φ \varphi φ, ψ \psi ψ, α \alpha α均是MLP, δ \delta δ如下给出,其中 θ \theta θ也是MLP:

那我们重新整理一下这个公式:
y i = ∑ ρ ( M L P ( x i ) − M L P ( x j ) + M L P ( x i − x j ) ) ⊙ ( M L P
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 763
763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









