







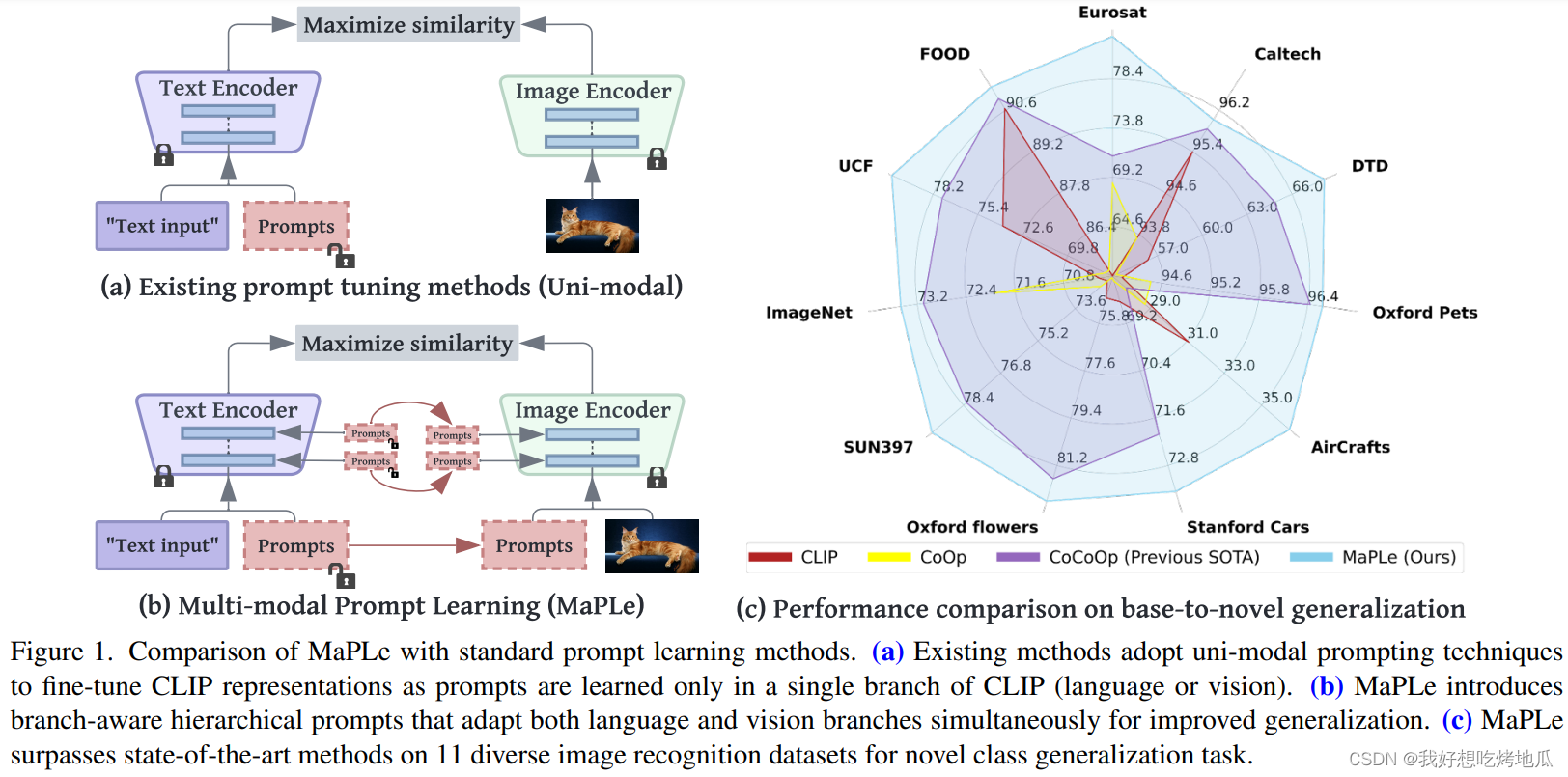
Motivation
预训练的视觉语言 (V-L) 模型,如CLIP,在下游任务中显示出出色的泛化能力。但是,它们对输入文本提示的选择很敏感,需要仔细选择 Prompt 模板来表现良好。使用 Prompt 来适应CLIP (语言或视觉) 的单个分支中的表示是次优的,因为它不允许在下游任务上动态调整两个表示空间的灵活性。
动机源于 CLIP 的多模态特性,其中文本和图像编码器共存,并且都有助于正确对齐 V-L 模态。
作者认为任何提示技术都应该完全适应模型,因此,仅为 CLIP 中的文本编码器学习 Prompt 不足以模拟图像编码器所需的适应。为此,着手在 Prompt 方法中实现完整性,并提出了多模态 Prompt 学习 (MaPLe) 来充分微调文本和图像编码器表示,以便在下游任务中实现最佳对齐。
Method
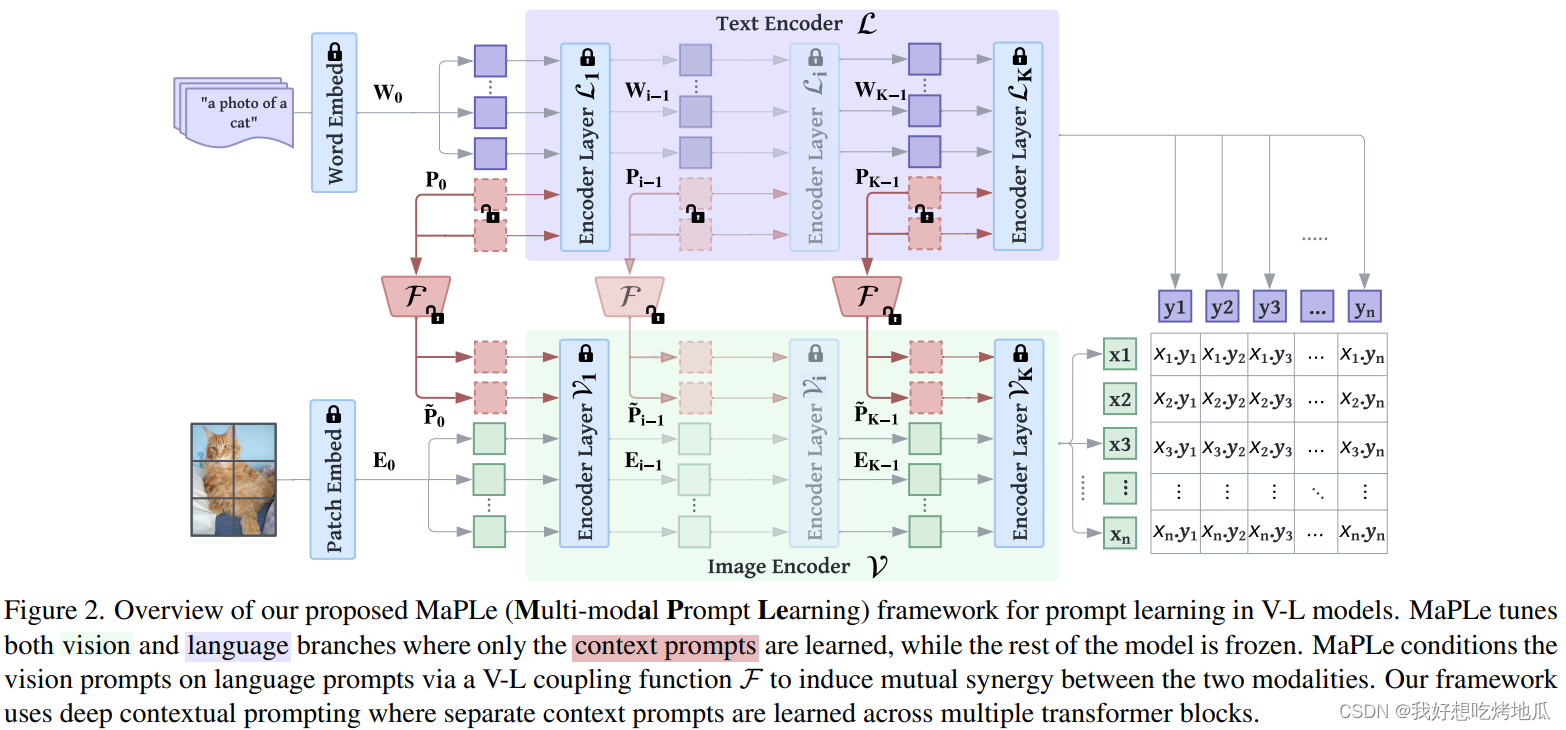
与之前的方法不同,MaPLe 提出了一种联合提示方法,其中上下文 Prompt 在视觉和语言分支中都被学习。具体而言,我们在语言分支中附加可学习的上下文标记,并通过耦合函数显式地将视觉 Prompt 置于语言 Prompt 上,以建立它们之间的交互。为了学习分层上下文表示,在两个分支中通过跨不同转换块的单独可学习上下文提示引入深度 Prompt。在微调期间,只学习上下文提示及其耦合函数,而模型的其余部分被冻结。
MaPLe: Multi-modal Prompt Learning
先前主要探索单模态方法不提供动态适应语言和视觉表示空间的灵活性。将 MaPLe 的图像嵌入与最近最先进的工作 Co-CoOp 进行了可视化和比较。注意 CLIP, CoOp 和 Co-CoOp 的图像嵌入是相同的,因为它们不学习视觉分支中的提示。MaPLe 的图像嵌入具有更强的可分离性,这表明除了学习语言提示外,学习视觉提示可以更好地适应 CLIP。除了多模态提示外,发现在更深的 Transformer 层中学习提示以逐步建模阶段特征表示是必不可少的。为此,在视觉和语言分支的前 J J J 层 ( J < K J < K J<K) 引入可学习 Token。这些多模态分层 Prompt 利用 CLIP 模型中嵌入的知识来有效地学习任务相关的上下文表示。
Deep Language Prompting
为学习语言上下文提示,在 CLIP 的语言分支中引入了
b
b
b 个可学习的标记
{
P
i
∈
R
d
l
}
i
=
1
b
\{{P_i∈\mathbb{R}^{d_l}}\}^b_{i=1}
{Pi∈Rdl}i=1b。输入嵌入遵循
[
P
1
,
P
2
,
⋅
⋅
⋅
,
P
b
,
W
0
]
[P^1, P^2, ···, P^b, W_0]
[P1,P2,⋅⋅⋅,Pb,W0] 的形式,其中
W
0
=
[
w
1
,
w
2
,
⋅
⋅
⋅
,
w
N
]
W_0 = [w^1, w^2, ···, w^N]
W0=[w1,w2,⋅⋅⋅,wN] 对应固定的输入 Token。新的可学习的 Token 在文本编码器 (
L
i
\mathcal{L}_i
Li) 的每个 Transformer 块中引入,直至特定深度
J
J
J。
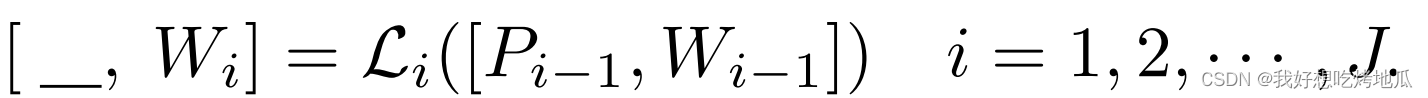
Deep Vision Prompting
与深度语言提示类似,在 CLIP 的视觉分支中引入
b
b
b 个可学习 Token
{
P
i
∈
R
d
v
}
i
=
1
b
\{{P_i∈\mathbb{R}^{d_v}}\}^b_{i=1}
{Pi∈Rdv}i=1b。在图像编码器(V)的更深的变压器层中进一步引入新的可学习标记,直至深度
J
J
J。
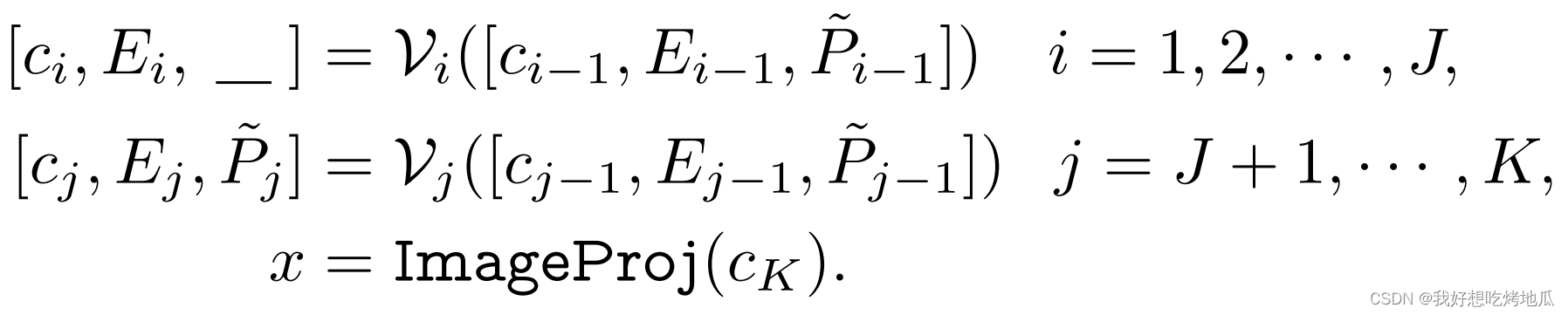
深度提示提供了在 ViT 结构中跨不同特性层次学习提示的灵活性。与独立提示相比,跨阶段共享提示更好,由于连续的 Transformer 块处理,特征更加相关。因此,与 early stage 相比,later stage 不提供独立学习的补充提示。
Vision Language Prompt Coupling
在 Prompt Tuning 中,必须采取多模态方法获得同时适应 CLIP 的视觉和语言分支,以实现上下文优化的完整性。一种简单的方法是将深度视觉和语言提示结合起来,其中语言提示 P P P 和视觉提示 P ~ \tilde{P} P~ 同时学习。这种设计命名为Independent V-L Prompting。虽然这种方法满足 Prompt 的完整性要求,但视觉和语言分支在学习任务时是独立的,缺乏协同作用。
由此,提出了一种分支感知的多模态 Prompt,通过在两种模态之间共享提示来协调 CLIP 的视觉和语言分支。语言 Prompt Token 被引入到语言分支,为了确保 V-L Prompt 之间的协同作用,视觉提示符
P
~
\tilde{P}
P~ 通过视觉到语言的投影来获得,称其为 V-L 耦合函数
F
(
⋅
)
\mathcal{F}(·)
F(⋅),使得
P
~
k
=
F
k
(
P
k
)
\tilde{P}_k=\mathcal{F}_k(P_k)
P~k=Fk(Pk) 。耦合函数通过一个线性层实现,它将
d
l
d_l
dl 维输入映射到
d
v
d_v
dv。这作为两种模式之间的桥梁,从而鼓励梯度的相互传播。
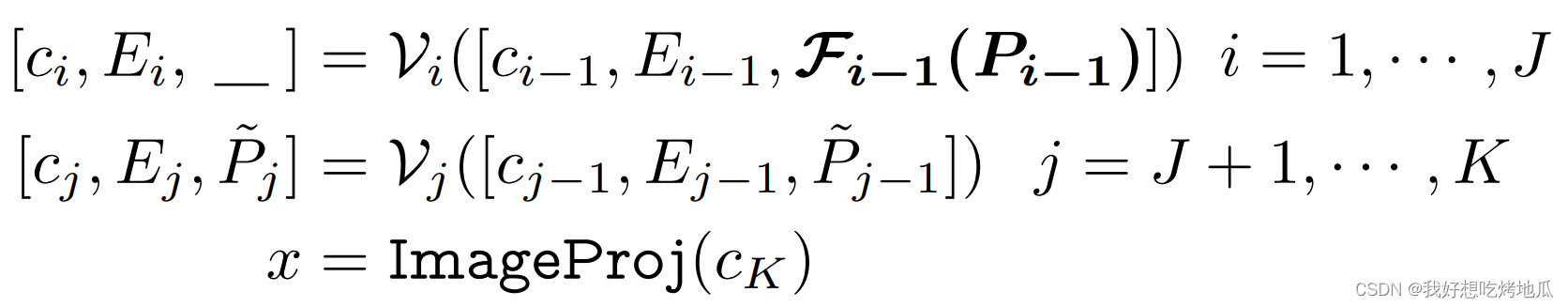
与独立的 V-L Prompt 不同,
P
~
\tilde{P}
P~ 对
P
P
P 的显式条件约束有助于两个分支间共享嵌入空间的学习,提高协同作用














 739
739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









