







文章目录
基本信息:
论文标题:Denoising Vision Transformers
作者:Jiawei Yang, Katie Z Luo, Jiefeng Li, Kilian Q Weinberger, Yonglong Tian, Yue Wang
机构:University of Southern California, Cornell University, Shanghai Jiao Tong University, Google Research
项目页面和代码:https://jiawei-yang.github.io/DenoisingViT/
论文概述
我们深入探讨了视觉 transformer(ViT)内在的微妙但重要的挑战:这些模型的特征图显示出网格状伪影,这对 ViT 在下游任务中的性能产生了负面影响。我们的调查将这个问题追溯到输入阶段的位置编码。为解决这个问题,我们提出了一种新颖的噪声模型,该模型普遍适用于所有 ViT。具体来说,噪声模型将 ViT 输出分解为三个组成部分:一个不受噪声伪影影响的语义项和两个依赖于像素位置的伪影相关项。通过在每张图像的基础上强制跨视图特征一致性来实现这种分解,利用神经场。这种每张图像优化过程从原始 ViT 输出中提取无伪影特征,为离线应用提供干净的特征。\n\n扩大我们的解决方案的范围以支持在线功能,我们引入了一个可学习的去噪器,直接从未处理的 ViT 输出中预测无伪影特征,无需针对每张图像进行优化。我们的两阶段方法,称为去噪视觉 transformer(DVT),不需要重新训练现有的预训练 ViT,并立即适用于任何基于 Transformer 的架构。我们在各种具有代表性的 ViT(DINO,MAE,DeiT-III,EVA02,CLIP,DINOv2,DINOv2-reg)上评估我们的方法。大量评估表明,我们的 DVT 在多个数据集上的语义和几何任务中一致且显著地改善了现有的最先进的通用模型(例如,+3.84 mIoU)。我们希望我们的研究能够鼓励对 ViT 设计的重新评估,尤其是关于位置编码的简单使用
背景与动机
论文背景:
ViTs已经成为视觉相关任务的新标准,但在其输出的特征图中普遍存在噪声伪影,这些伪影不仅视觉上令人不悦,还阻碍了特征的可解释性,并破坏了语义连贯性。
过去方案
以往的研究主要集中在ViTs的性能提升上,而忽视了噪声伪影的问题。
论文的Motivation
作者希望提出一种方法,能够有效地去除预训练ViTs中的噪声伪影,而不需要重新训练模型。
核心方法:
a. 理论背景:
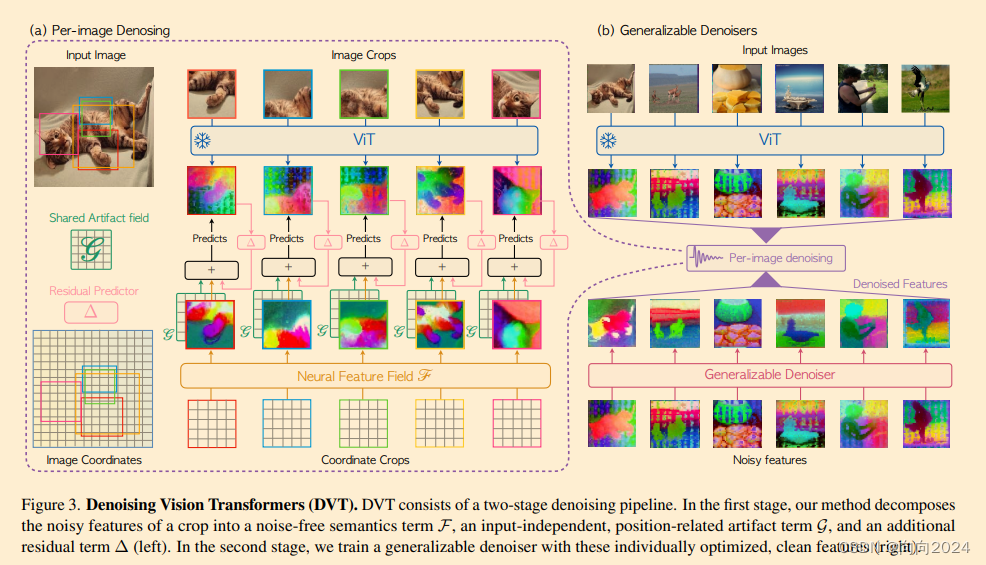
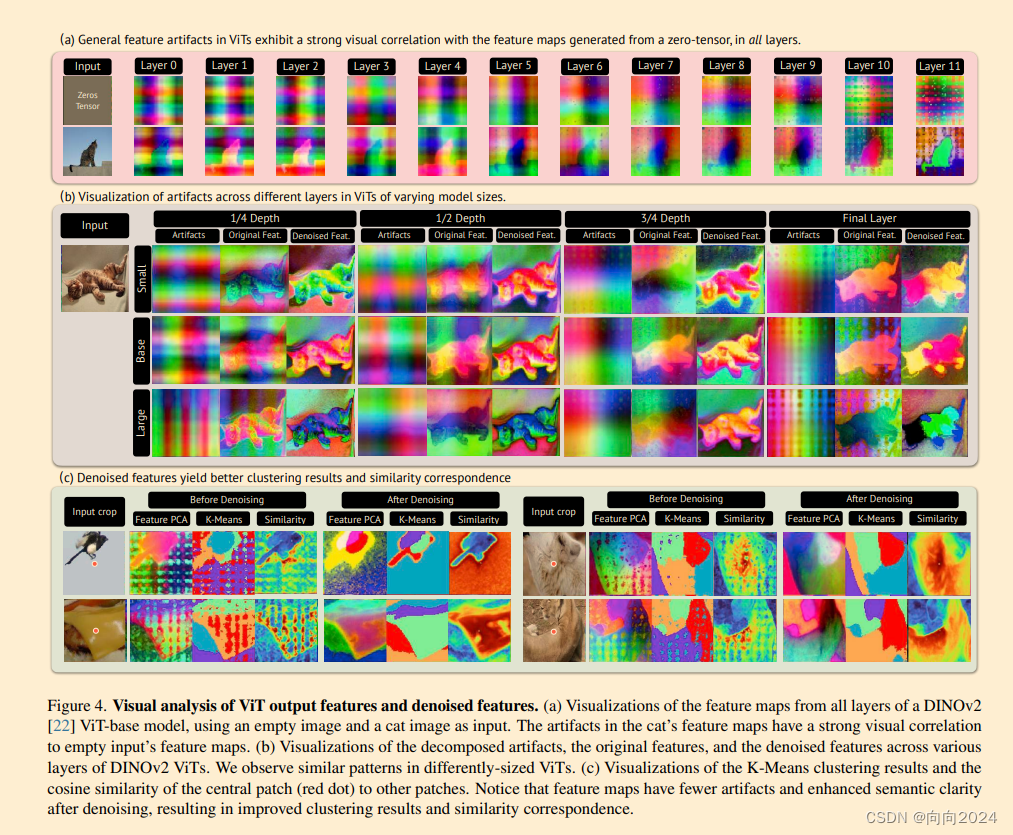
作者首先分析了ViT输出的特征图,发现存在网格状的噪声伪影,这些伪影与位置嵌入(positional embeddings)的使用有强相关性。为了解决这一问题,作者提出了一个新的噪声模型,该模型将ViT的输出分解为三个组成部分:无噪声的语义项(f(x))、与位置相关的伪影项(g(Epos)),以及考虑语义和位置共依赖的残差项(h(x, Epos))。
b. 技术路线:
- 为了实现这一分解,作者采用了神经场(neural fields)的方法。具体来说,作者定义了一个语义场F来捕捉与空间变换不变的语义内容,同时定义了一个伪影场G来编码与输入无关但与位置相关的噪声。通过最小化一个包含距离、残差和稀疏性正则化的重建损失函数,神经场能够学习到这两个场的映射。
- 在优化过程中,作者首先训练语义场F和伪影场G,使其能够捕捉ViT输出的主要部分。在优化的后半阶段,作者固定伪影场G,并继续训练语义场F和残差项h,以最小化重建损失。
c.核心贡献:
- 作者提出了一种新的去噪方法DVT,它不需要重新训练现有的预训练ViTs,并且可以立即应用于任何基于Transformer的架构。
- DVT包含两个阶段:第一阶段是针对每张图片的去噪处理,通过神经场提取出无噪声的特征;第二阶段是训练一个可学习的去噪器,该去噪器能够直接从原始ViT输出中预测无噪声特征,适用于实时应用场景。
- 通过在多个数据集和任务上的广泛评估,DVT显著提高了预训练ViTs在语义分割和深度预测等密集预测任务中的性能。
实验结果
a. 详细的实验设置
作者在多种代表性ViTs(如DINO, MAE, DeiT-III, EVA02, CLIP, DINOv2, DINOv2-reg)上评估了DVT的方法。实验包括语义分割任务(如VOC2012和ADE20k)和深度预测任务(如NYU-depth基准)。
b. 详细的实验结果
DVT在多个数据集上显著提高了预训练ViTs的性能,例如,在VOC2012数据集上,DVT处理后的DINOv2模型的mIoU提高了3.84。
总结
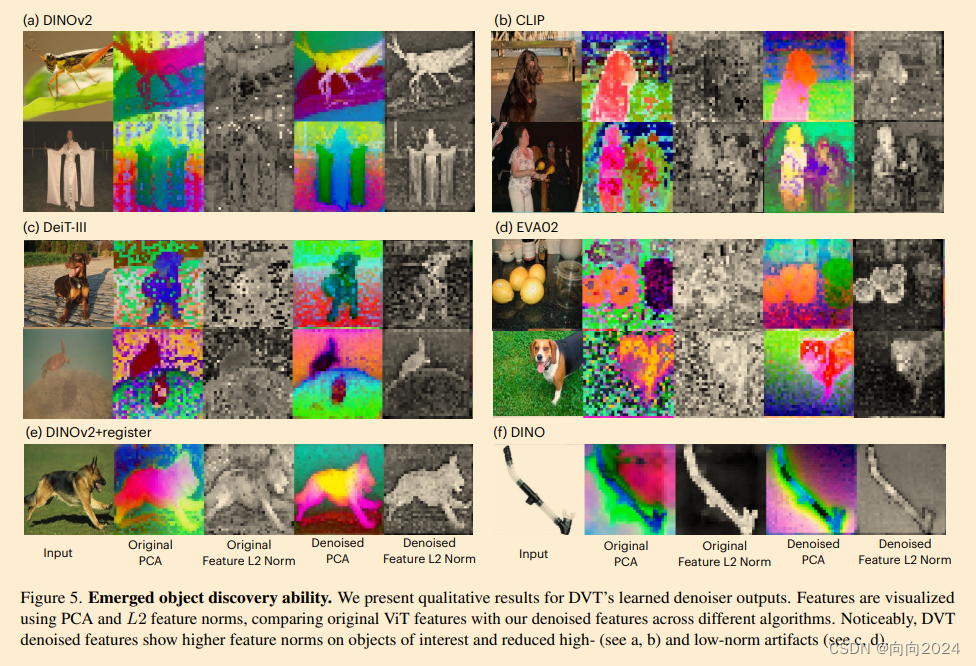
作介绍了一种名为DVT的方法,该方法利用神经场消除ViT中的特征漂移。我们确定位置嵌入是这些漂移的主要来源,即使它们在各种视觉任务中非常重要。通过使用神经场优化过程,DVT可以有效地从噪声充填的特征图的清洁特征中提取。在此基础上,我们提出了一个可扩展的特征消除器,消除了进行单独图像优化的需求。学习几个消除样本后,我们的消除器可以很好地泛化到未见过的数据上,并在密集视觉任务中极大地改进预训练的ViT。此外,我们的研究提出了未来探索的几条途径:了解位置嵌入在ViT中的作用可能会影响下一代深度学习架构的设计。在ViT中重新定义位置嵌入和Transformer中的位置嵌入定义也是一个有迫切需要的问题。最后,在未进行额外训练的情况下消除预训练ViT特征的方法是一个引人入胜的挑战。
缺陷和不足
文章中没有详细讨论噪声伪影产生的根本原因,也没有探索修改ViT设计对减少特征伪影的影响。
DVT可能需要针对不同的ViT架构进行调整,以实现最佳性能。
可以进一步改进的点:
深入研究噪声伪影的成因,以及如何通过改进ViT的架构设计来减少这些伪影。
探索DVT方法在其他类型的Transformer模型中的应用,以及如何将其扩展到其他视觉任务中。
















 1782
1782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











