







基于GAN的特征选择的过采样入侵检测技术
本文对现有过采样方法的设计原理和不足进行了综述和分析,在此基础上,从入侵检测数据集不平衡和高维的角度出发,提出了一种基于生成对抗网络和特征选择的过采样技术。
具体而言,本文基于WANG-GP对攻击的复杂高维分布建模,生成额外的攻击样本,然后根据方差分析选择代表整个数据集的特征子集,最终生成一个重新平衡的低维数据集用于机器学习训练。
文章的主要贡献:
- 1:针对入侵检测中类不平衡问题,提出了一种新的过采样方法GAN-FS。构建基于WANG-GP的攻击生成模型,生成攻击样本,然后利用方差分析对数据进行特征选择,获得重新平衡的低维数据集,永远也训练入侵检测模型
- 2:基于三种流行的入侵检测数据集,我们对几种机器学习检测模型进行了实验。实验结果表明,该方法能有效提高入侵检测模型的性能。并且,与多种流行的方法相比,我们的方法取得了更好的效果。
- 3.我们讨论并分析了我们的方法对不同数据集和不同机器学习检测模型的影响。
过采样技术GAN-FS
建立的基于WANG-GP的攻击生成模型,可以生成更高质量的样本

GAN-FS总共包含五个步骤:
框架分为五个步骤:数据预处理、数据划分、罕见类过采样、特征选择和训练测试ML模型。
(i)步骤1:对数据集进行预处理,将数据集分为训练集和测试集。
(ii)步骤2:通过数据分区将训练集分为稀有类数据和其他类数据。
(iii)步骤3:GAN模型使用稀有类数据生成样本。
(iv)步骤4:将过采样数据与步骤2中获得的其他类数据进行组合,然后进行特征选择。
(e)在特征选择步骤中得到最优特征子集和相应的新的低维训练集。
(v)步骤5:最后,使用新的训练集对机器学习(ML)模型进行训练,使用测试集对模型进行测试。
预处理
在预处理过程中有数字化和归一化:在入侵检测数据中通常包含非数字特征,例如协议和状态,需要将非数字特征转换为数字特征,非数字特征被映射到0或者s-1之间,s是符号的数字变量。归一化采用最大最小归一化。
数据分区
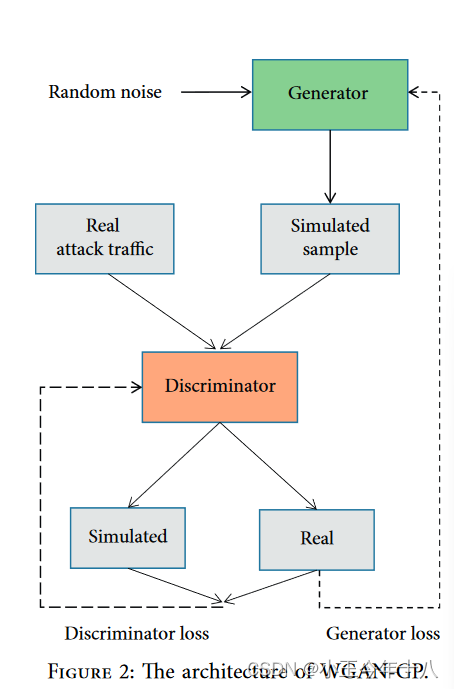
WANG-GP的结构为:
表示为:

:数据分布;
:由
隐式定义的模型分布 (生成器的输入z采样自一些简单的噪声分布)
定义了从数据分布
中采样的点对生成的分布
之间沿直线的均匀采样,
对随机样本的梯度范数进行惩罚这样,发生器和鉴频器可以在相同的速度下进行改进,避免模式崩溃,从而使训练效果和神经网络的权重得到优化,在一定程度上提高了WGAN的训练效果。
在生成样本的过程中,利用噪声和罕见类攻击训练WGAN-GP。
(训练过程开始于固定鉴别器和训练生成器模拟真实数据的分布。当鉴别器不能正确区分样本是来自真正的攻击集还是来自生成器时,固定生成器并开始训练鉴别器。
当鉴别器通过连续训练能够正确区分样本时,将鉴别器与训练生成器固定。按照这个过程进行迭代训练,最后使用生成器生成攻击样本。
(生成的攻击样本最终被添加到训练集中
特征选择
ANOVA(analysis of variance) F -test (方差分析f检验是一种常用的特征选择的方法)
使用f检验来确定某些组的平均数是否不同,并在统计上检验平均数是否相等,对于每个特征我们假设其在正类和负类样本中具有相同的均值,
,然后有:

代表分量和组内偏差
分别计算各个特征的F_value,最后根据特征的重要性对特征进行排序,得到最优子集。
训练和测试机器学习模型
数据集不平衡影响了基于机器学习的入侵检测模型的分析能力,使其分类结果偏向正常活动,导致高虚警率和漏警率。
基于WGAN-GP算法对训练集中的罕见类攻击进行过采样,然后利用方差分析特征选择方法对训练集进行下采样,最终得到一个低维重平衡训练集。
在这一步中,我们使用重平衡的低维数据集来训练机器学习模型。
当模型训练完成后,我们使用基于特征子集的测试集来测试其性能
结论
本文从入侵检测中数据集不平衡和高维的角度,提出了一种基于GAN和特征选择的过采样入侵检测技术。
首先,我们的方法提出专注于对罕见类型的攻击样本进行过采样,以提高入侵检测的有效性。
另一方面,我们使用ANOVA特征选择方法只集中于攻击样本的必要特征。
(即,获得的低维重平衡数据集用于训练入侵检测分类器。
实验结果表明,该方法提高了入侵检测模型的检测性能,优于其他基线方法。

















 3439
3439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









