







现有的研究已将top-1攻击成功率(ASR)的限制确定为评估攻击强度的指标,但仅在白盒设置中进行了研究,而我们的研究将其扩展到更实用的黑盒设置:可转移攻击。据广泛报道,更强的I-FGSM传输比简单的FGSM传输更差,这导致人们普遍认为传输性与白盒攻击强度不一致。我们的工作挑战了这一信念,结果表明,对于一般的top-k ASR来说,更强的攻击实际上转移得更好,这由攻击后的兴趣等级(ICR)表示。为了增加攻击强度,从几何角度直观分析logit梯度,我们发现常用损失的弱点在于优先考虑欺骗网络的速度,而不是最大化其强度。为此,我们提出了一种新的标准化CE损失,它引导logit朝着隐式最大化其与基本真理类的秩距离的方向更新。在各种环境下的广泛结果证明,我们提出的新损失对于top-k攻击是简单而有效的。
攻击成功率(ASR)也称为愚弄率(FR),通常用于评估白盒中的强度和黑盒攻击中的可转移性。本质上,ASR只表明一个目标类、非目标中的基础真相类或目标环境中的目标类在对抗性样本中是否排名第一。
增加T(迭代次数)可以增强top-k对手的实力和可转移性,表明top-k攻击的实力也可以转移。然而,仅仅增加T不足以导致强大的top-k攻击。我们发现,原因在于常用的交叉熵损失或C&W损失,它优先考虑愚弄网络的速度,而不是最大化其与兴趣(基本事实)类的距离。为此,我们提出了相对交叉熵(RCE)损失以增强更强的topk攻击。我们的新损失在白盒攻击中达到接近最佳top-k强度,大大超过现有损失,从而导致更强的top-k可转移攻击。
文章贡献:
我们的工作是首次尝试top-k可转移攻击任务。这项任务的一个主要障碍是人们普遍相信强度和可转移性,这是一个挑战,因为增加T可以增强两者,并且top-k攻击强度可以转移。
我们确定了现有损失的限制,并提出了在白盒和可转移黑盒设置中实现强大top-k攻击的新损失。
我们广泛验证了其在多个数据集上对top-k优势和对抗性样本的可转移性进行基准测试的有效性。
我们提出的用于评估top-k攻击的ICR度量也为非目标设置和目标设置提供了统一的视角。
本文工作特点:
我们的工作是第一次针对强大的top-k可转移攻击,即针对广泛的k(包括k=1)增加ASR-k。对于top-k攻击,以前的工作仅在白盒设置中进行研究。另一方面,以前研究可转移性的工作没有考虑top-k。有趣的是,我们注意到这两个子问题归结为增加攻击强度。通过表明攻击强度是可转移的,我们的工作旨在同时实现强大的top-k白盒攻击和top-k可转移攻击。先前的技术主要通过正则化效应提高了可转让性。与之正交和互补的是,我们的工作重点是对手实力对可转让性的影响,并试图通过增加白盒攻击强度来改善它。
α和T对转移速率的影响:
FGSM更易转移的现象通常归因于迭代攻击方法往往过于适合代理模型。然而,目前尚不清楚哪个因素是导致过度拟合的主要原因。从技术上讲,I-FGSM和FGSM之间的差异由两个因素组成:步长α和迭代次数T。为了澄清这一点,我们分析了α和T对传输速率的影响。结果表明,导致I-FGSM过度拟合的因素是α,而不是T。我们发现,如果迭代次数足够大,I-FGSM的传递比FGSM好。
ICR(Interest class rank)
ICR 直接指示攻击后的类,对于任何样本,给定ICR值,我们都可以很容易地判断它在任何给定的k是否成功。,当K<ICR就视为成功,当K>ICR 视为失败,因此无需列举出所有k,具有单个值的ICR表示全谱topk攻击强度,ICR可用于两种攻击设置,其中较大的ICR表示攻击在非目标设置中更强,在目标设置中较弱。我们强调,ICR相当于ASR@k,因为ICR可以很容易地转换为任何k的top-k。
Top-k攻击强度可转移;
在代理模型上面较高的ICR也会导致目标模型上更高的ICR ,这表明top-k的对抗强度是可以转移的
加剧top-k白盒攻击:
logit向量的一个有趣特性:
将logit向量定义为DNN分类器的pre-softmax输出,并将其表示为Z。Z具有零和性质:将logit向量定义为DNN分类器的pre-softmax输出,并将其表示为Z。
常用损失函数的梯度方向
对于非目标设置,CE、CE(LL)和CW损耗相对于Z 的导数为:,
P是后softmax概率向量,分别表示one-hot真是标签,最不可能类别的真是标签,除基本真实标签外最高类别的基本标签。
RCE(Relative CE Loss):
本文提出了一种新的损失函数公式,来增强top-k对手的实力,采用相对CE损失函数,公式为:

该公式由两部分组成,常用CE和归一化部分,其在logit向量Z上的梯度推导如下:
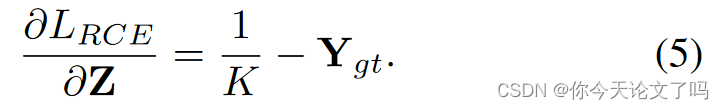
RCE损耗的梯度方向将样本推离其基本真值类最远。
logit梯度的几何解释。:
我们的设置被设计为只有三个类A、B、C。每个类分别由相应的logit值x、y和z表示。首先,我们假设对logit没有约束,因此每个logit都是完全独立的。logit空间可以用三个正交轴X、Y和Z在三维空间中表示

logit被约束在x+y+z=0的平面上(法向量为(1,1,1)),这称为(logit)决策超平面。换句话说,零和约束将三维空间的自由度降低到二维平面。在对称假设下,类A、B、C的类逻辑向量的方向可以设置为(2,−1.−1), (−1, 2, −1), (−1.−1、2)具有一定规模。
假设在步骤t,样本在决策超平面上的位置是(xt,yt,zt)。在不失去一般性的情况下,我们假设样本位于A类区域,yt>zt,这表明样本相对更接近于具有B而不是C的logit决策边界,
所有CW、CE和CE(LL)都有一个共同的属性:logit更新方向取决于决策超平面上的当前样本位置。根据样本在决策平面上的位置,CE和CW倾向于将样本移向语义相近的类,而CE(LL)loss明确地将样本移到语义较远的类。
Loss comparison through the lens of temperature.:
从图4可以观察到CE梯度方向和性能介于CW和RCE之间,这里,我们表明,通过改变温度Te,CW和我们的损耗可以被视为CE的特例。Te是一个非平凡的超参数温度,即预处理为Z=Z/Te作为softmax输入,从而得到Pe。这种温度标度法已广泛用于知识蒸馏以及防御方法。考虑到温度,CE的导数推导如下:

通常,温度Te设置为1。从几何角度来看,Te平衡了损失的偏好,以鼓励样本越过语义更接近类(即逻辑相对较高的类)的决策边界。Te越高,表示这种偏好越低。以温度Te作为控制变量,我们发现通过将Te设置为一个较小的值,CW损耗可以解释为CE损耗的特殊情况。通过将Te设置为相对较大的值,我们提出的RCE损失也可以被视为CE损失的特例。 ,增加/减少Te会使性能接近RCE CW损耗。















 799
799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









