







实现鲁棒性的一种补充方式是引入拒绝选项,允许模型不返回对不确定输入的预测,其中confidence是常用的确定性代理。
与此例程一起,我们发现置信度和校正置信度(R-Con)可以形成两个耦合的拒绝度量,这可以证明区分错误分类的输入和正确分类的输入。这一有趣的特性揭示了使用耦合策略来更好地检测和拒绝对抗性示例。我们评估了CIFAR-10、CIFAR-10-C和CIFAR-100在几种攻击(包括自适应攻击)下的纠正拒绝(RR)模块,并证明RR模块在提高鲁棒性方面与不同的对抗性训练框架兼容,几乎不需要额外计算。
true 交叉损失--反映了分类器
在x上的推广程度,因此提出了true confidece(T-Con)
即,真实标签上的预测概率视为确定性预测,如果将置信阈值设置为1/2,则T-Con可以证明错误分类的输入与正确分类的输入之间的区别。T-Con的性质是有说服力的,但不幸的是,由于没有真正的标签y,它的计算在推理过程中不可实现。因此,我们通过辅助函数纠正置信度来构造纠正置信度(R-Con),以学习预测T-Con。我们证明,如果R-Con被训练成在ξ误差范围内与T-Con对齐,其中ξ∈[0,1),那么ξ误差R-Con拒绝器和1 2-ξ置信拒绝器可以被耦合,以区分错误分类的输入和正确分类的输入。
Classification with a rejection option
具有拒绝模块M的分类器可以写成:

t是阈值,M(x)是由辅助模型或统计计算的确定性代理
拒绝什么:M的设计主要取决于我们打算拒绝的输入类型,与传统的执行拒绝不同,本文中认为更合理的做法是根据输入是否会被错误分类而不是对抗性地执行拒绝
True confidence (T-Con) as a certainty oracle
表示第l类的上的返回概率,其预测标签为:
![]() ,
,:置信度
定义为真置信度(T-Con):真实标签y上返回的概率。
Coupling confidence and T-Con
定理1:(可分性)给定置信度大于1/2的分类器,
即

如果被正确分类为
,而
被错误分类,
,则
![]()
Construction of rectified confidence (R-Con)
通过纠正confidence来学习T-Con,有助于有优化,并且有助于防止分类器和拒绝器争夺模型容量
引入由参数化的辅助函数
,校正置信度R-Con为:
![]()
纠正拒绝(RR)模块的训练目标可以写成:![]()
涉及到 的
的最优解为:
![]()
辅助函数Aφ(x)可以通过优化与分类器fθ(x)联合学习:
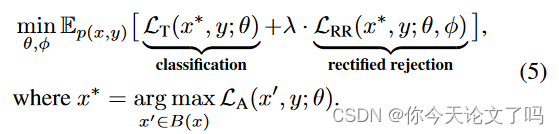
Aφ(x)的结构:我们考虑具有softmax的分类器为fθ(x)=S(Wz+b),其中z是映射的特征,W和b分别是权重矩阵和偏差向量。我们应用一个超浅网络来构造Aφ(x)=MLPφ(z)。这种双头结构几乎不会带来计算负担。也可以使用Aφ的其他更灵活的架构,例如RBF网络[40,50]或考虑路径信息的级联多块特征。注意,我们停止fθ(x)[y]流上的梯度→ BCE损失和fθ(x)[ym]→ R-Con当ym=y时。这些操作防止模型集中于正确分类的输入,同时便于fθ(x)[y]与pdata(y|x)对齐,
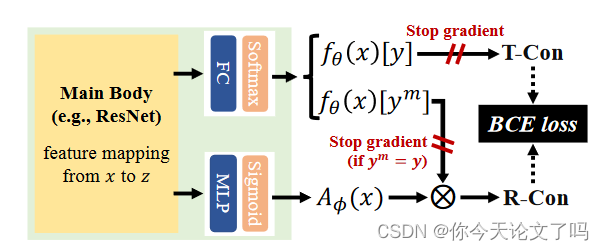
等式(4)中目标LRR的构建,用于训练RR模块,即T-Con和R-Con之间的二元交叉熵(BCE)损失。RR模块与分类器共享一个主主干,几乎不需要额外的计算。运用双头结构来建模分类器和纠正拒绝(RR)模块,以端到端的方式进行训练,RR模块通过最小化T-Con和R-Con 之间的额外BCE loss来学习,
Aφ学习得如何?在实践中,辅助函数Aφ(x)通常被训练以在一定误差内获得最优解A*φ(x)。我们引入了Aφ(x)与A*φ(x)之间之间逐点误差的定义,该定义允许两种测量方式,几何或算术:
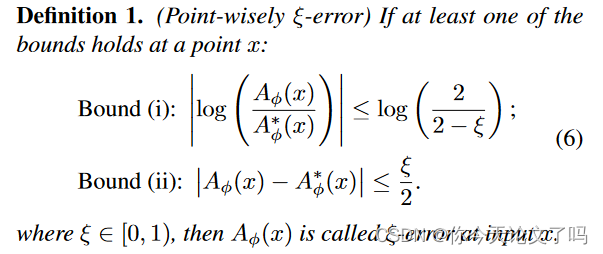
Coupling confidence and R-Con

The task of learning a ξ-error Aφ(x)

直观地说,定理2提供了一种方法来估计期望有多少测试样本满足ξ-误差条件。在相似的数据分布下,具有更多类的分类问题通常(不一定)更难学习[37]。
类似地,定理2也可以近似学习鲁棒ξ-误差aφ的难度,例如,对于围绕x的“∞-球”中的任何x′,我们使x′满足ξ-错误条件。该任务可以转化为训练认证分类器[46],实现鲁棒ξ-误差aφ的测试样本比率可以通过认证防御的性能来近似。














 415
415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









