








美国国家健康和营养检查调查(NHANES)是一项旨在评估美国成人和儿童健康和营养状况的研究计划。该调查的独特之处在于它结合了访谈和体格检查。由美国疾病控制和预防中心(CDC)负责为国家提供健康统计数据。
NHANES计划始于20世纪60年代初,并作为一系列针对不同人口群体或健康主题的调查进行。自1999年以来,对美国的人口健康状况进行了更为定期的调查。每次调查中,来自美国约3000个县中30个选定县的约10000名参与者被要求在移动检查中心(MEC)参加家庭访谈、随后的身体检查和实验室测试。
NHANES访谈包括人口统计,社会经济,饮食和健康相关问题。检查部分包括医疗,牙科和生理测量,以及由训练有素的医务人员进行的实验室测试。
一、2024年NHANES文献预览
本周PubMed数据库“标题/摘要:NHANES”搜索发现,共发表101篇NHANES论文。其中6篇一区,36篇二区。
1.外国学者文章介绍(一)

文章题目:采用集成机器学习对临床风险预测算法进行基准测试,用于非酒精性脂肪肝肝纤维化的无创诊断。
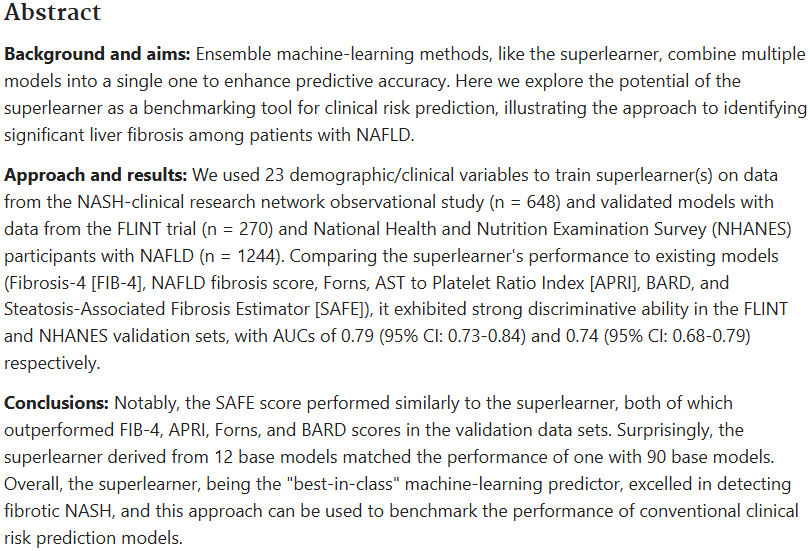
研究背景与目的:Ensemble机器学习方法,如超级学习器,将联合收割机多个模型组合成一个模型,以提高预测准确性。在这里,我们探索了超级学习者作为临床风险预测基准工具的潜力,说明了在NAFLD患者中识别显著肝纤维化的方法。
方法 :我们使用23个人口统计学/临床变量来训练来自NASH临床研究网络观察性研究(n = 648)的数据的超级学习者,并使用来自FLINT试验(n = 270)和全国健康和营养调查(NHANES)的NAFLD参与者(n = 1244)的数据验证模型。
结果:将超级学习者的性能与现有模型进行比较(纤维化-4 [FIB-4]、NAFLD纤维化评分、Forns、AST与血小板比率指数[APRI]、BARD和脂肪变性相关纤维化估计值[SAFE]),在FLINT和NHANES验证集中表现出较强的区分能力,AUC为0.79(95%CI:0.73-0.84)和0.74(95%CI:0.68-0.79)。
结论:值得注意的是,SAFE评分与超级学习者的表现相似,两者在验证数据集中的表现都优于FIB-4,APRI,Forns和BARD评分。令人惊讶的是,来自12个基本模型的超级学习者的表现与90个基本模型的表现相匹配。总体而言,超级学习者作为“同类最佳”机器学习预测器,在检测纤维化NASH方面表现出色,这种方法可用于对传统临床风险预测模型的性能进行基准测试。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1248
1248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









