






生信碱移
多模态证据筛选效应基因
目前有两种策略用于鉴定性状相关的效应基因,FLAMES 通过构建机器学习模型并将这两种策略结合进行精确预测。
GWAS 通过数据驱动的方法发现与复杂性状相关的遗传变异 SNP,极大推动了现代遗传学的发展。对于多基因表型,单个 SNP 的效应可能难以反应疾病本身。因此,大多数研究假设与性状相关的 SNP 效应源自影响 基因调控 或 基因产物 的变异(即基因级别的变化)。
最近,已经开发出整合方法,旨在结合多种不同层次的功能数据,以预测 GWAS 位点中的效应基因。目前主要有两种策略来实现这一目标。第一种策略使用基于位点的 SNP 到基因数据来优先考虑基因。此类方法的例子包括染色质相互作用映射、数量性状位点(QTLs)映射或选择与主变异体最近的基因。第二种策略假设所有 GWAS 信号汇聚到共享的、潜在的生物通路和网络中。这些方法根据在整个 GWAS 中富集的基因特征优先考虑位点中的基因 。然而,目前没有任何方法将这两种策略结合起来,以对位点中的效应基因进行良好校准的预测 。
▲ DOI: 10.1038/s41588-025-02084-7。
来自阿姆斯特丹自由大学的研究者为此开发了 FLAMES (Fine-mapping Locus Annotation and Model-based Scoring) 框架,于2025年2月10日发表于 Nature Genetics [IF: 31.7],其是一个用于预测 GWAS 效应基因的分类器框架。它结合了基于 GWAS 的基因共识信息和与效应 SNP 相关的位点生物学数据。简单来说,FLAMES 通过计算一组具有高概率为致病 SNP 的变异位点(fine-mapped credible set, FMCS)中的基因效应,帮助确定最可能的效应基因。
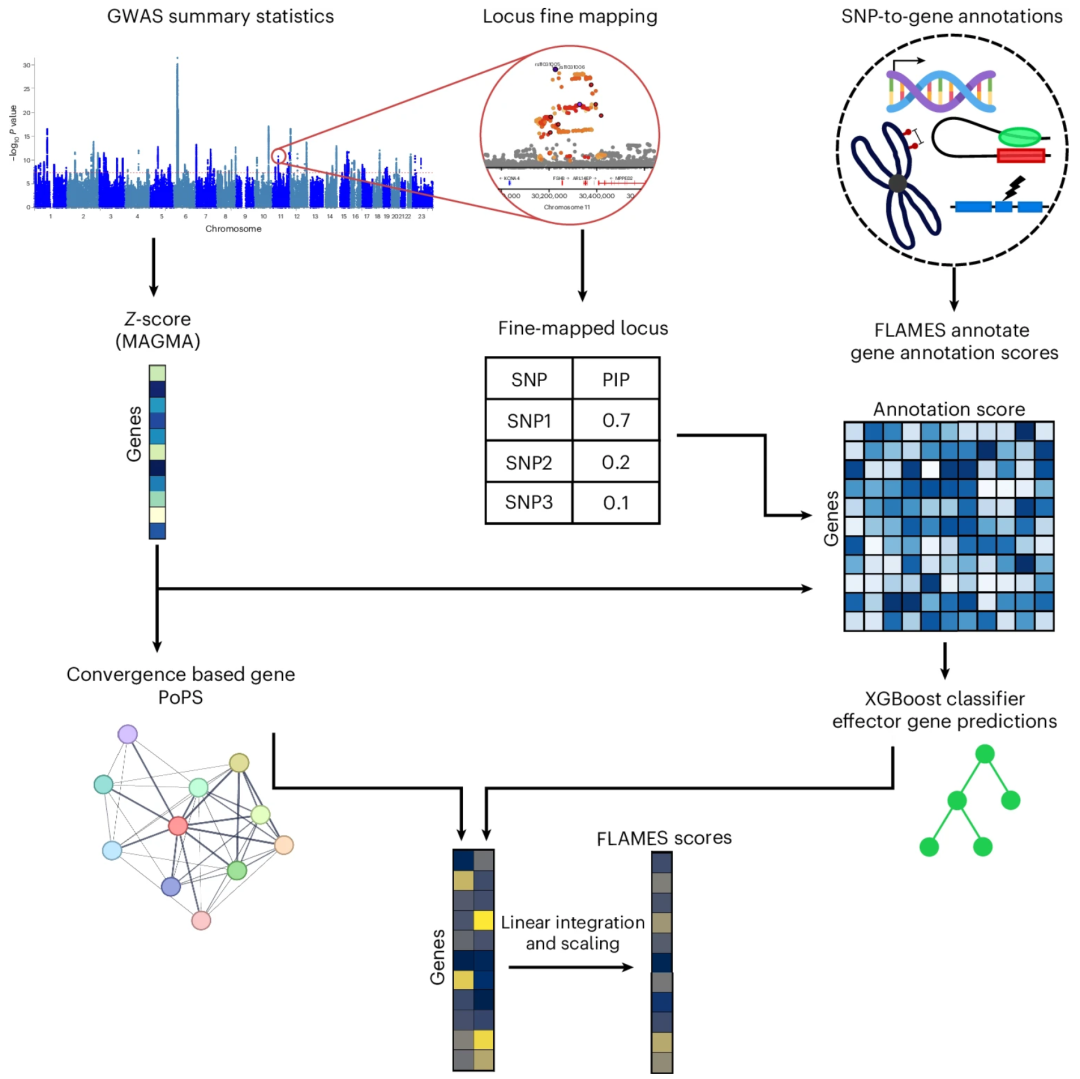
▲ FLAMES 框架示意:SNP到基因的注释得分是通过将 FMCS 与 SNP 到基因的证据结合计算得出的。用于生成注释得分的生物学数据见正文表1。除此之外,基因 Z 得分通过 MAGMA 方法计算获得,基于共识的基因优先级得分则通过PoPS方法计算得出。
FLAMES 框架的主要算法流程和关键步骤如下:
1. FLAMES框架假设
FLAMES的核心假设是每个致病SNP与一个最强的基因相关,这个基因在特定性状的表现中起到关键作用。框架结合了基因共识得分和基于位点的SNP与基因关联评分(SNP-to-gene scores)来进行预测。
2. PoPS得分计算
PoPS 是 FLAMES 用来计算基因共识的工具,于2023年发表于同一个杂志。它通过回归 GWAS Z分数(MAGMA Z-scores)来评估通路、蛋白质-蛋白质相互作用和基因共表达特征的重要性。每个特征的β系数(回归系数)会被加和,得到最终的PoPS得分。PoPS得分反映了每个基因在不同生物学网络中的重要性。
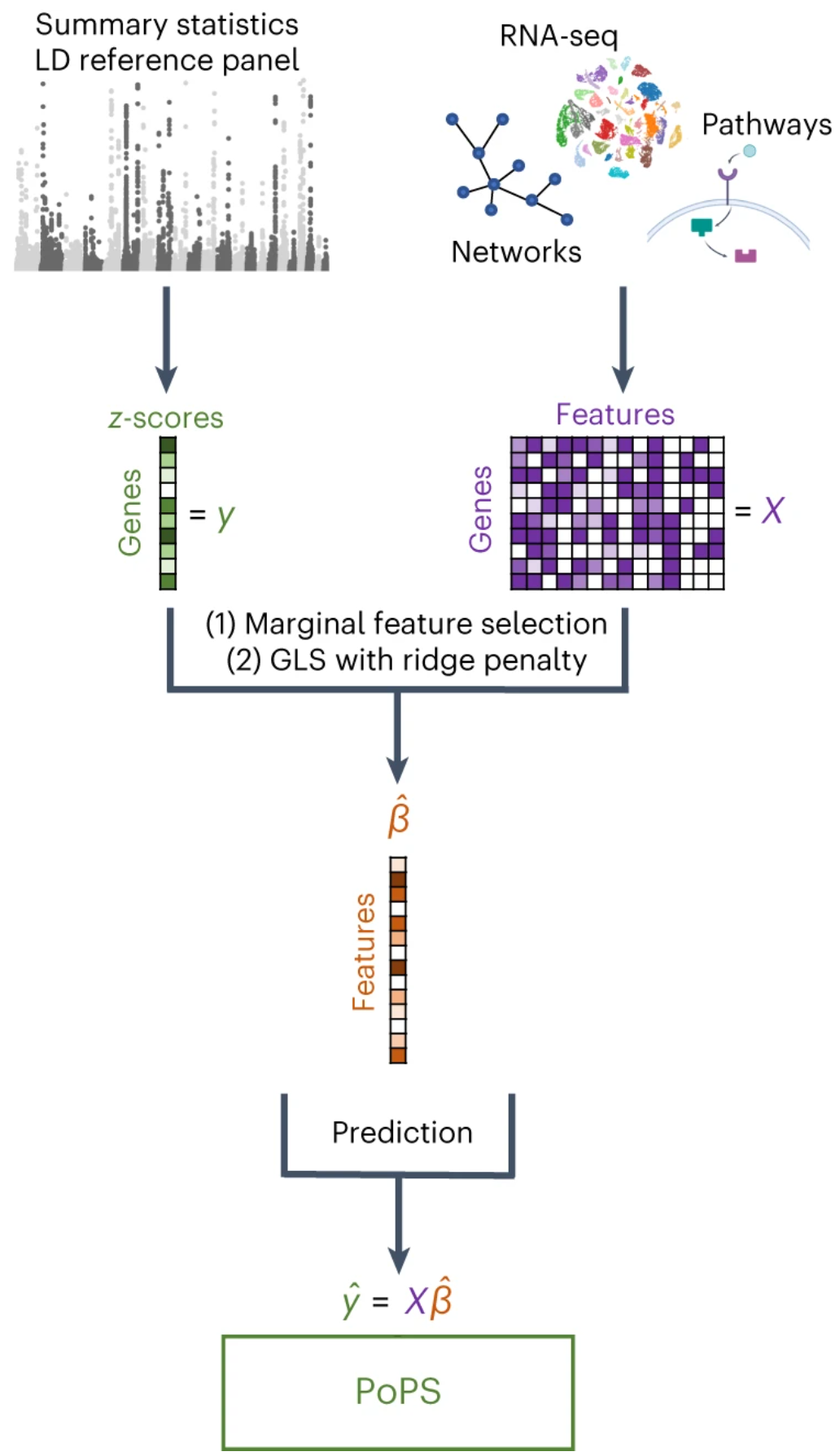
▲ PoPS 基因优先级评分工具框架:使用 MAGMA 从 GWAS 汇总数据计算了基因级的Z得分。随后,根据基因表达数据、生物学通路和预测的 PPI 网络创建了基因特征,并通过边际特征选择方法限制包含的特征,以保留最可能相关的特征。接着,使用广义最小二乘法(GLS)拟合线性模型,考虑基因特征对基因级关联的依赖关系,同时引入 L2 惩罚项防止过拟合。最终,得到了基因特征的联合多基因富集向量,用于计算基因的优先级得分。DOI: 10.1038/s41588-023-01443-6。
3. SNP与基因的定位评分
FLAMES 使用 XGBoost(一种决策树集成方法)来计算基于位点的SNP与基因的关联得分。XGBoost 分类器的输入是 FMCS,包括 SNP-to-gene 的不同注释类型:如特异性SNP注释(如eQTL)和区域性SNP注释(如增强子区域)。注释评分基于SNP的后验概率(PIP)与注释指标的乘积来计算。
注释评分计算方法:假设每个基因 的最大注释分数为 ,平均注释分数为 ,对于每个 ,其 PIP 值为 ,注释矩阵, 表示该 与基因 的关联。注释评分是根据 PIP 和注释指标的乘积来确定的。
4. FLAMES评分的计算
FLAMES 框架最终的得分是通过将 PoPS 得分和 XGBoost 得分结合来计算的。两者的得分会先进行缩放,再通过线性组合得到一个最终的 FLAMES 得分。最终得分反映了某个基因是否是可信集中的效应基因。
为了训练FLAMES模型,首先需要构建一个包含已知效应基因的训练集。此训练集通过链接 GWAS 位点与具有显著功能变异的基因(如missense或pLoF变异)来构建。此外,通过限制基因与GWAS信号的最大距离,减少了错误的基因-位点配对。训练使用了 22 个不同的XGBoost模型,这些模型分别在不同的基因组区域进行训练,并使用了交叉验证来优化超参数。
Github 链接:
-
https://github.com/Marijn-Schipper/FLAMES
方法不难理解
学习学习

















 3966
3966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









