







我自己的原文哦~ https://blog.51cto.com/whaosoft/11890460
#OpenAI家庭机器人NEO登场
动作丝滑逼近人类!穿着西装的「人」却专做家务OpenAI支持的明星初创1X Technologies,发布了最新的通用家务机器人NEO。不仅外形自然拟人,还有仿生设计带来的丝滑动作。不想干的家务,真的可以让机器人帮忙了!
继Optimus和擎天柱之后,人形机器人领域又闯入一员猛将。
OpenAI押注的初创公司1X Technologies正式宣布,最新的通用家务机器人NEO beta测试版上线。
它是专为人类设计,专为家庭环境而打造的人形机器人。
然而,它的首次现身,竟被所有人误认为——这不就是一个穿着西装的「人」吗?
一段demo视频中,女主在厨房里正烹饪美食,NEO向她递过去鸡蛋。
它还帮助女主拿包,挥手致意她过来,一起向大家打招呼。
公司的AI副总裁Eric Jang也在推特上官宣了这个消息,同时预告了下一步的发布。
很高兴终于公开分享NEO。在硬核科技中,最简单的东西(超纯水、超平面镜)都是超级困难的。我们制造了一种超安静的机器人,在人类周围非常安全。我们很快就会分享人工智能方面的更多进展
CEO兼创始人Bernt Børnich表示,希望NEO能完成人类不喜欢做的任务,比如清洁、整理等日常杂物,并能听从指挥,根据用户的偏好和生活方式进行定制。
为了让NEO更适合家庭和生活场景,1X对机器人的外形和硬件规格都做出了特别设计。
毕竟,他们之前推出的工业通用机器人EVE,身高1.82米,重87公斤,可以说是「彪形大汉」的体格。
而NEO的身高只有1.67米,基本上是人类的平均水平,体重也只有30公斤,约为EVE的三分之一。
EVE和NEO的外观
虽然采用了轻量化设计,也并不意味着NEO干不了重活。
据介绍,它的手有20个自由度,能举起超过自己体重两倍的70公斤的重量,也可以携带最多20公斤重的物体。
穿西装的「人」,动作超丝滑
相比Optimus赛车般的酷炫外观,NEO几乎全身被布料包裹,似乎更能融入人类。
德扑之父、OpenAI科学家Noam Brown打趣道,「信不信由你,这不是一个穿西装的人。」
除了外观,NEO还具有类似肌肉的解剖结构和非严格的液压系统,将力量与柔和融为一体,因此可以非常自然地与人类交互。
不仅可以自然地行走、慢跑、跑楼梯,而且还可以进行远程的人工控制,完成很多「有人味儿」的动作。
比如低头转个手腕——
打招呼、和人拥抱、挥手,一气呵成,动作姿势、幅度和速度与人类相当接近。
干家务时至关重要的灵巧手,看起来也是既自然又灵活,不仅可以稳稳地抓握物体,还能拿住柔软的抹布。
而且是名副其实的「通用」家务机器人,除了能整理厨房餐具——
还能独立完成一整个流程的操作,用咖啡机打出一杯咖啡。
由于不依赖于传统的刚性执行器,而是利用了仿生设计和更灵活的组件,NEO才能实现更流畅的运动,并且消耗的能量也很低。
机载电机产生的力约为人体肌肉力密度的80%,而且不需要齿轮。
但比较可惜的是,NEO只能运行2个小时,相比EVE的8小时续航,这可能是轻量化设计之后的权衡。
惊艳到网友
英伟达科学家Jim Fan看到demo第一时间就赶来祝贺,并表示「非常惊艳」。
前段时间刚为1X Technologies和NEO拍过片子的纪录片导演Jason Carman也帮忙站台。
自2014年以来,1X Technologies一直在打造类似人形的机器人。现在,他们向世界展示了最新机器人NEO。
看过demo后,有网友大胆预测:未来5年内,家务机器人将成为主流!
对于Eric Jang所说的「超安静」,试用者和Jason Carman都表示:确实如此,执行器简直太安静了!
拍视频的时候,甚至需要把音频电平调高很多,才能听到NEO执行任务时发出的声音。
针对1X两款机器人都主打的「安全性」,也有人直接质疑:你们所说的「安全性」是什么意思?
Eric Jang也做出了在线回应:
仅就硬件而言,即使在高速移动时也具有合规性和低反射惯性。当然,「安全」还意味着态势感知和赋权(例如持有锐器和热咖啡)——但我们还不准备分享相关信息。
技术介绍
官方博客表示,「我们的首要任务是安全」。经过不同场景和环境的测试后,NEO将在挪威的工厂中进行大规模生产。
而在目前Beta测试阶段,1X将在将在选定的家庭中部署有限数量的NEO,用于研究和开发中至关重要的——数据。
受到数字助理和自动驾驶的启发,1X的数据收集不同于传统的编码和预定义算法。
他们使用了一种名为VR Teleop的方法。
操作员会引导机器人在不同的现实场景中工作,让机器人直观地了解任务的难度和可行性。当收集数据达到一定规模时,机器人就学会了一项新技能。
在实际场景中,NEO的设计是「开箱即用」,但可以在使用过程中不断学习。使用越多,就会变得越「智能」。
因此,Beta测试阶段将使NEO能够收集更多数据,帮助公司构建通用人工智能模型,以逐渐改进系统。
公司CEO Børnich表示,「我们试图通过具身化来解决智能的问题,数据多样性就是其中的秘密。」
「虽然这一点没有那么秘密了,但如果没有安全和动态的机器人,就很难在现实世界中实现『智能』。」
明星机器人初创,OpenAI看好
1X这家公司可以说是厚积薄发,现任CEO兼创始人Bernt Bornich早在10年前就创立了这家公司,当初的名字还是Halodi Robotics。
当时,他们定下目标,要创造通用机器人来处理劳动密集型任务。
但这十年,1X Technologies仅开始为企业用户发货,同时进行了多项技术开发,包括世界上最高扭矩的扭矩-重量驱动伺服电机,用于模仿柔软的肌肉运动。
重大的突破出现在2022年,1X开始与OpenAI合作,引入语言模型和具身学习模型,为机器人添加「智能」。
搭上了OpenAI的快车,1X的增长有如瞬间起飞,在去年3月就完成了2350万美元的A2轮融资,由OpenAI创业基金领投。
今年1月,他们又在B轮融资中筹集了1亿美元,两轮融资筹集的总资金达到筹集的总资金达到近 1.37 亿美元。
除了最近推出的面向消费市场的双足类人机器人NEO,1X早先开发的用于执行工业任务的轮式机器人Eve,已经在部署在多个实际场景中,例如移动设备、开门和完成订单。
经过1.5×加速处理
CEO兼创始人Bernt Bornich毕业于挪威奥斯陆大学,专业是机器人与纳米电子学。
Bornich毕业后曾在多个公司从事开发工作,而且早在2014年就创建了1X,公司总部仍位于挪威。
发推官宣的Eric Jang本科和硕士均毕业于布朗大学,主修计算机科学专业,毕业后在谷歌机器人团队担任高级研究科学家,一待就是6年。
2022年,Eric Jang以AI副总裁的身份加入1X Technologies。
与此同时,Jang也在AI医疗公司Toruts兼职首席科学顾问。
参考资料:
https://www.1x.tech/discover/1x-rasies-23-5m-in-series-a2-funding-led-by-open-ai
https://venturebeat.com/ai/1x-robotic-startup-backed-by-openai-receives-100m-in-funding/
https://www.iotworldtoday.com/robotics/lightweight-humanoid-robot-designed-to-automate-home-chores
#3Blue1Brown
用最直观的动画,讲解LLM如何存储事实,3Blue1Brown的这个视频又火了
本文根据视频整理而来,有听错或理解不当之处欢迎在评论区指出。
向大模型输入「Michael Jordan plays the sport of _____(迈克尔・乔丹从事的体育运动是……)」,然后让其预测接下来的文本,那么大模型多半能正确预测接下来是「basketball(篮球)」。
这说明在其数以亿计的参数中潜藏了有关这个特定个人的相关知识。用户甚至会感觉这些模型记忆了大量事实。
但事实究竟如何呢?
近日,3Blue1Brown 的《深度学习》课程第 7 课更新了,其中通过生动详实的动画展示了 LLM 存储事实的方式。视频浏览量高达 18 万次。
去年 12 月,谷歌 DeepMind 的一些研究者发布了一篇相关论文,其中的具体案例便是匹配运动员以及他们各自的运动项目。
虽然这篇论文并未完全解答有关 LLM 事实存储的问题,但也得到了一些颇为有趣的结果,其中的一个重点是:事实保存在网络中的一个特定部分,这个部分也就是我们熟知的多层感知器(MLP)。
在 3Blue1Brown 刚刚更新的这期视频中,他们用 23 分的视频演示了大型语言模型如何存储和处理信息,主要包括以下部分:
- LLM 中隐藏的事实是什么
- 快速回顾 Transformers
- 示例
- 多层感知器
- 计算参数
视频地址:https://www.youtube.com/watch?v=9-Jl0dxWQs8
在演示视频中,3b1b 的作者口齿清晰、语言标准,配合着高清画面,让读者很好地理解了 LLM 是如何存储知识的。
很多用户在看完视频后,都惊讶于 3Blue1Brown 教学质量:
还有网友表示,坐等更新这期视频已经很久了:
接下来我们就深入 MLP 的细节吧。在这篇文章中,简要介绍了核心内容,感兴趣的读者可以通过原视频查看完整内容。
MLP 在大模型中的占比不小,但其实结构相比于注意力机制这些要简单许多。尽管如此,理解它也还是有些难度。
为了简单,下面继续通过「乔丹打篮球」这个具体示例进行说明吧。
首先,我们先简单了解一下 Transformer 的工作流程。Transformer 的训练目标是基于已有 token 预测下一个 token(通常表示词或词组),而每个 token 都关联了一个高维向量。

这些向量会反复通过两类运算:注意力(允许向量之间彼此传递信息)与多层感知器(MLP)。当然,它们之间还存在一个特定的归一化步骤。
在向量经过多次如此迭代之后,我们希望每个向量都已经吸收了足够多的信息。这些信息有的来自训练模型时植入模型权重的一般性知识,也有的来自上下文。这些知识就是模型预测下一 token 的依据。

需要注意的是,这些向量编码的并不仅仅是单个词汇,而是会在信息在网络中流动时根据周围的环境和模型的知识吸收更加丰富的含义。
总之,每一个向量编码的信息都远远超过了单个词汇的含义,如此模型才能预测接下是什么。而存储这些信息就是 MLP(注意力的作用是将上下文结合在一起),也因此大模型的大多数参数都在 MLP 中(约三分之二)。

继续「乔丹打篮球」这个示例。MLP 是如何存储这一事实的。

首先我们做一些假设:在高维空间中有这样三个不同的向量,它们分别定义了乔丹的姓 Jordan 和名 Michael 以及篮球 Basketball。

现在,如果该空间中有一个向量与 Michael 向量的乘积为 1,则我们认为该向量编码了 Michael 这一概念;而如果这个乘积为 0 甚至负数,则认为该向量与 Michael 没有关联。
同样,我们可以计算该向量与 Jordan 或 Basketball 的乘积,以了解其与这两个概念的关联程度。

而通过训练,可让该向量与 Michael 和 Jordan 的乘积均为 1,此时就可以认为该向量编码了 Michael Jordan 这个整体概念。
MLP 的内部细节

当这个编码了上述文本的向量序列穿过一个 MLP 模块时,该序列中的每个向量都会经历一系列运算:

之后,会得到一个与输入向量同维度的向量。然后再将所得向量与输入向量相加,得到输出向量。
序列中的每个向量都会经历这样的操作,此时这些操作都是并行执行的,彼此之间互不影响。

对于「乔丹打篮球」,我们希望对于输入的「Michael Jordan」,经过一系列运算之后,能得到「Basketball」的向量。
首先来看这个过程的第一步。这个线性投射过程就相当于让输入向量乘以一个大型矩阵。这个矩阵里面的数据就是所谓的模型参数(model parameter)。你可以将其视为一个布满控制旋钮的仪表盘 —— 通过调整这些参数,我们就能控制模型的行为。

对于矩阵乘法,视频中分享了一个视角。我们可以将矩阵乘法看作是将矩阵的每一行都视为一个向量,然后将这些行与被处理的向量(这里用 E 表示,意为 embeding,即嵌入)进行一系列点乘。

如果我们假设该矩阵的第一行刚好编码了「First Name Michael」且被处理向量也编码了它,那么所得的点积就约为 1。
而如果它们同时编码了姓和名,那么所得的结果应该约等于 2。

你可以认为该矩阵的其它行正在并行地处理其它问题。

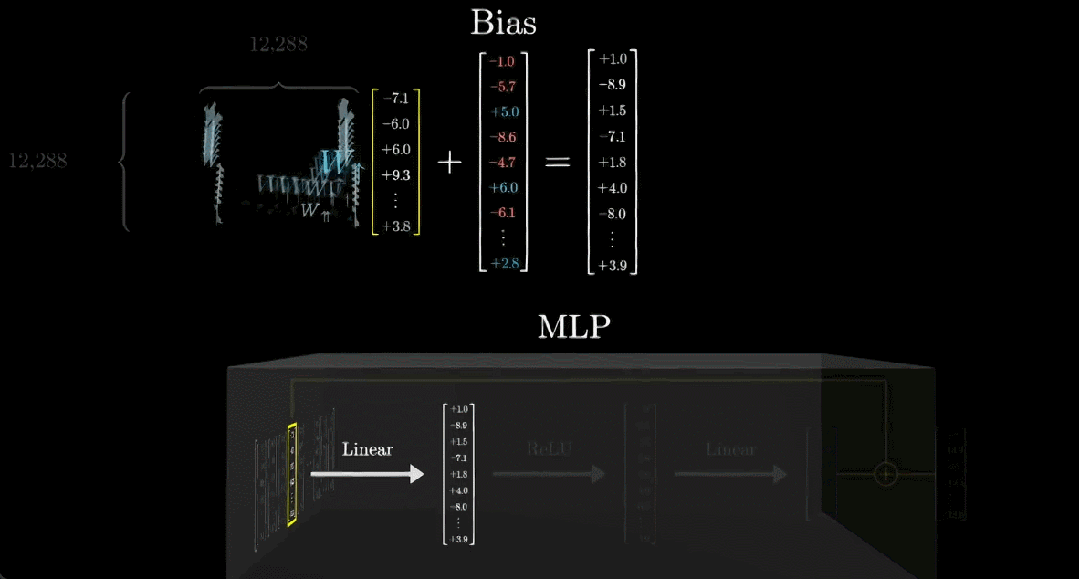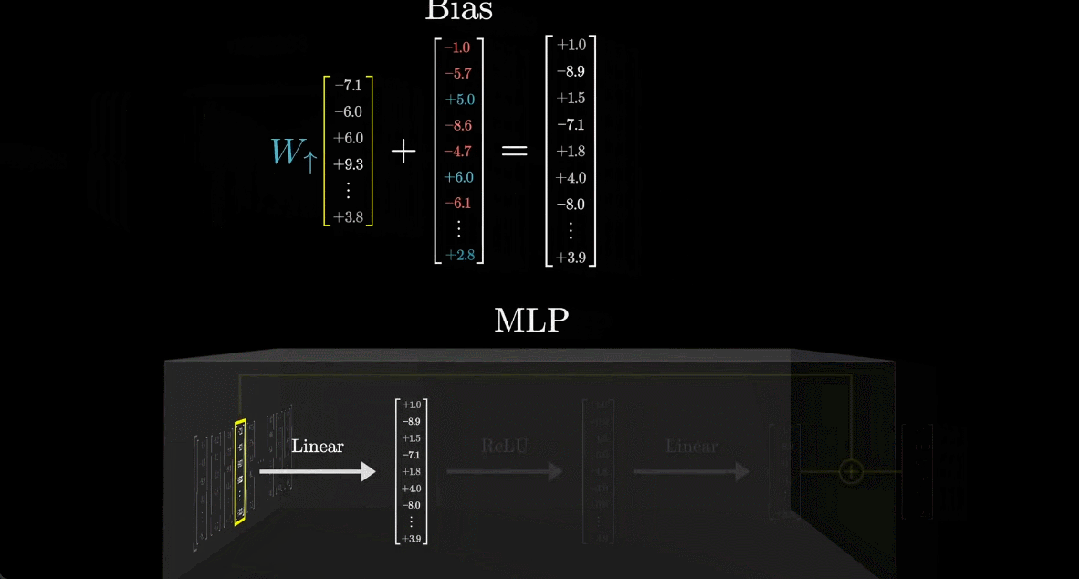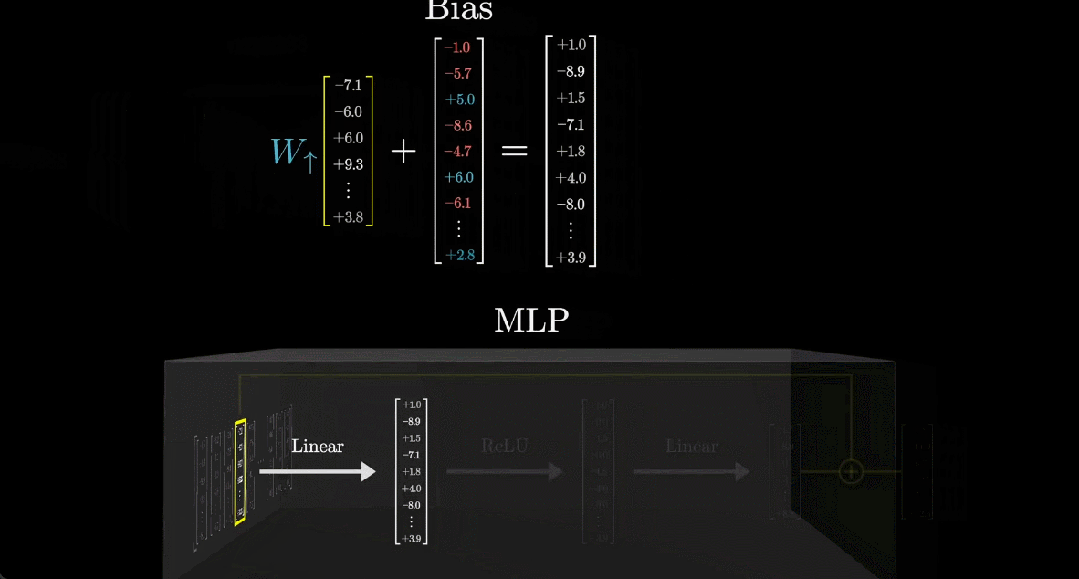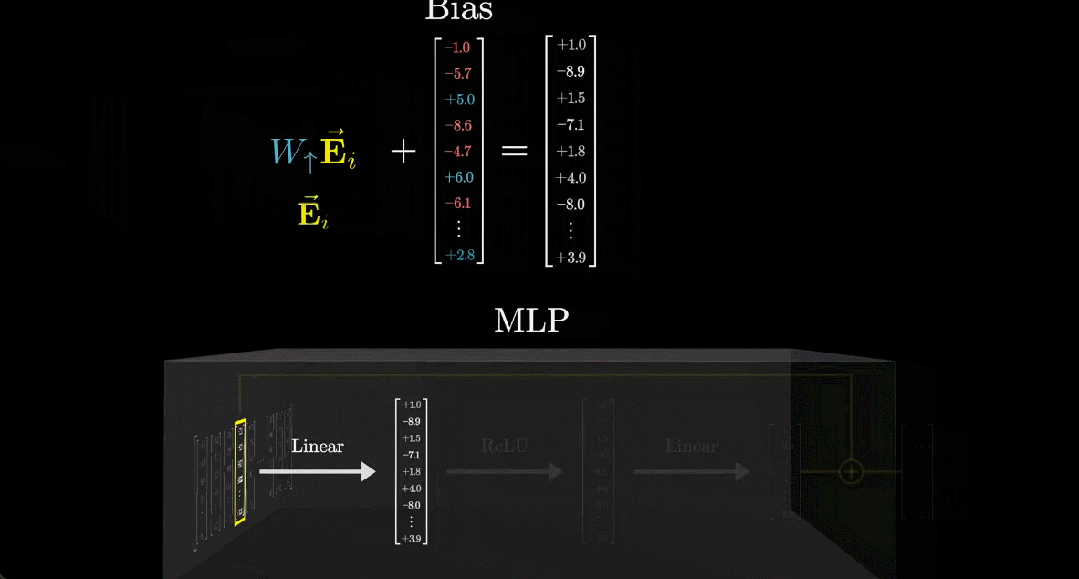
另外,通常来说,这一步还会向输出添加另一个向量,也就是所谓的偏置向量,其中的参数是从数据中学习得到的。

在这个例子中,我们可以看到这个偏置向量的第一个元素为 -1。也就是说在最终的输出向量中,之前得到的相关点积减去了 1。为什么要这样操作?这是因为这样一来,当且仅当向量编码了全名「Michael Jordan」时,所得向量的第一项为正数,否则就为 0 或负数。
在实践中,模型矩阵的规模非常大,比如 GPT-3 的矩阵有 49152 行和 12288 列(这个列数就是嵌入空间维度)。

事实上,这个行数恰好是嵌入空间维数的四倍。其实这只是一种设计选择,你可以让它更多,也可以让它更少。

接下来我们用更简洁的方式表示这个矩阵和向量,如下动图所示:
经过上述线性过程之后,需要对输出向量进行整理。这里通常会用到一个非常简单的函数:整流线性单元(ReLU)。
深度学习社区传统上喜欢使用过于花哨的名字,这个非常简单的函数通常被称为整流线性单元(ReLU)。
继续我们的例子,中间向量的第一个元素在当且仅当全名是 Michael Jordan 时才为 1,否则为零或负数,在将其通过 ReLU 后,会得到一个非常干净的值,其中所有零和负值都被截断为零。因此对于全名 Michael Jordan,该输出为 1,否则为 0。这个行为和「与门」非常相似。另外 ReLU 还有一个相对平滑的版本 GeLU。

接下来又是一个线性投射步骤,这一步与第一步非常相似:乘以一个大型矩阵,加上偏置,得到输出向量。

但这一次,对于这个大型矩阵,我们不再以行的思路来思考它,而是以列的思路来看。这些列的维度与向量空间一样。

如果第一列表示的是「Basketball」且 n_0 为 1(表示该神经元已激活),则该结果就会被添加到最终结果中;否则就不会影响最终结果。当然,这些列也可以表示任何概念。

类似地,我们将这个大矩阵简化表示为 W ↓,将偏置表示为 B↓,并将其放回到图中。

举例来说,如果输入向量中同时编码了名字 Michael 和姓氏 Jordan,那么触发操作序列后,便会得到指向 Baskerball 方向的输出向量。

这个过程会并行地针对所有向量执行

这就是 MLP 的运算过程:两个矩阵乘积,每个都添加了偏置。此前这种网络曾被用来识别手写数字,效果还算不错。

GPT-3 中有 1750 亿参数是如何计算的?
在接下来的章节中,作者介绍了如何计算 GPT-3 中的参数,并了解它们的位置。

对于 GPT-3 来说,嵌入空间的大小是 12288,将它们相乘,仅该矩阵就有六亿多个参数,而向下投影(第二个矩阵)具有相同数量的参数,只是形状进行了转置,所以它们加起来大约有十二亿参数。

此外,作者表示还需要考虑另外几个参数,但这只占总数的很小一部分,可忽略不计。嵌入向量序列流经的不是一个 MLP,而是 96 个不同的 MLP,因此用于所有这些块的参数高达 1000 多亿,这约占网络中总参数的三分之二。
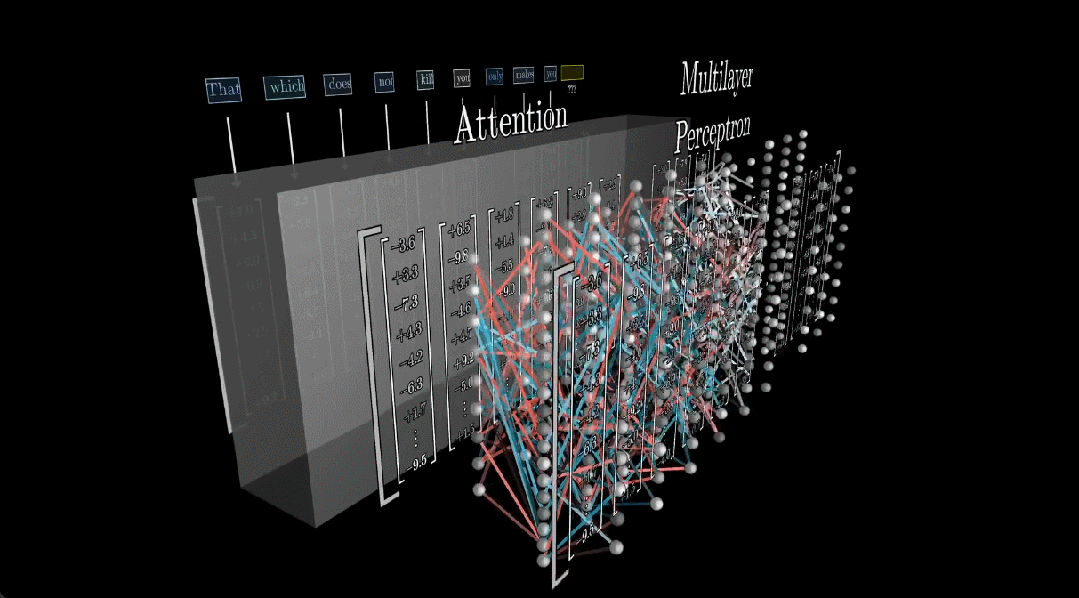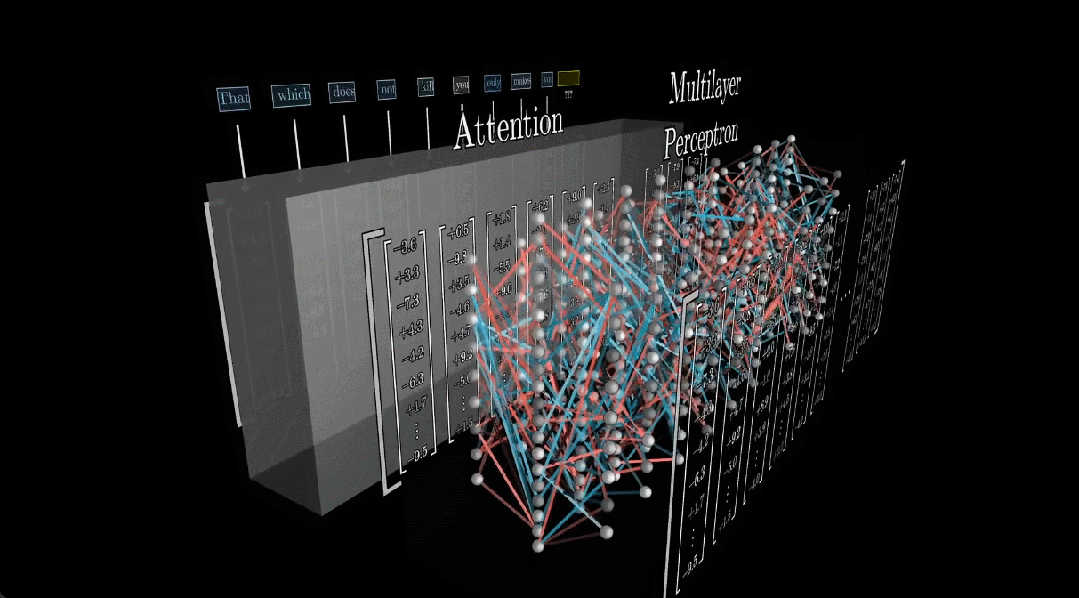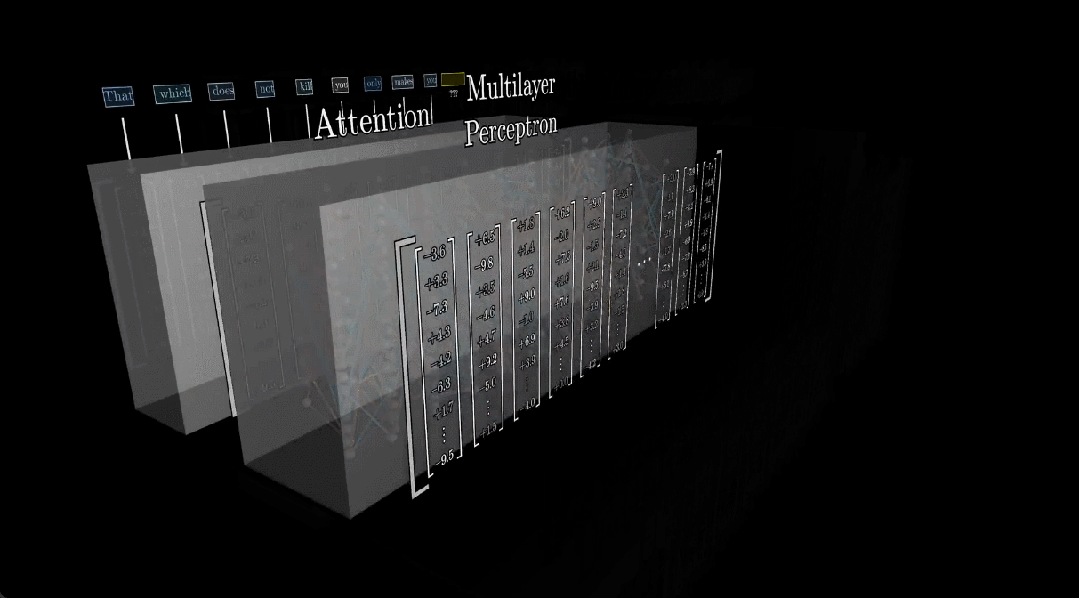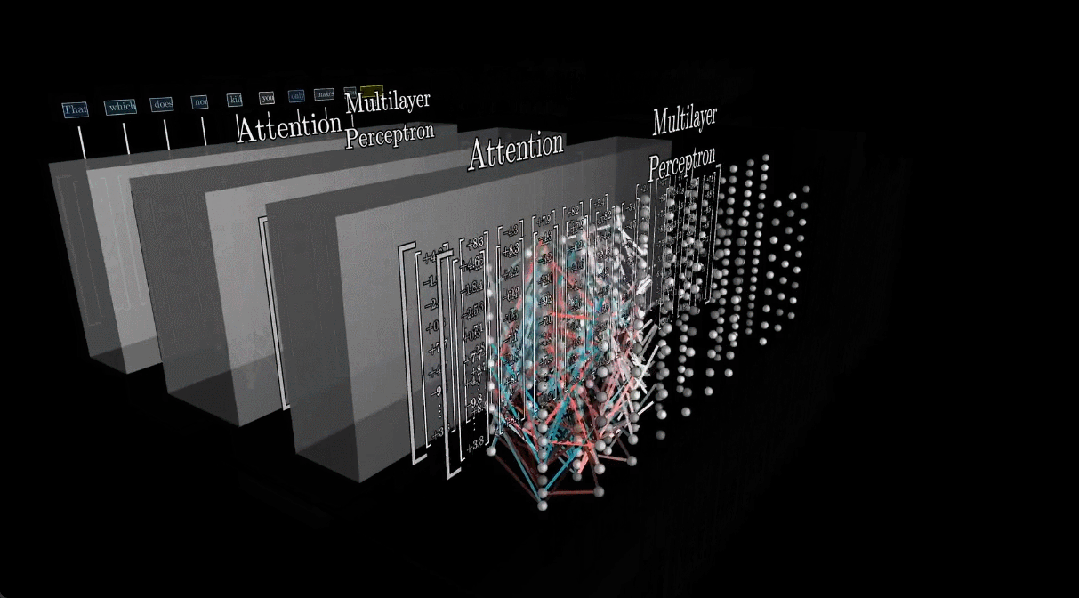

最后,将注意力块、嵌入和 unembedding 等组件的所有参数加起来,总计可以得到 1750 亿参数。

另外值得一提的是,还有另一组与归一化步骤相关的参数,不过视频示例中跳过了这些参数,它们只占总数的很小一部分。

视频最后介绍了叠加(Superposition)这一概念。证据表明,单个神经元很少像迈克尔・乔丹那样代表某个单一特征,实际上可能有一个很好的理由,这与目前在可解释性研究人员中流传的一个想法有关,称为 Superposition,这是一个假设,可能有助于解释为什么这些模型特别难以解释,以及为什么它们的扩展性出奇地好。

感兴趣的读者可以参考原视频,了解更多内容。
3blue1brown 介绍
3blue1brown 是一个专门制作可视化讲解视频的频道,其内容覆盖数学、人工智能等领域,每门课都配有直观生动的动画演示,帮助观众加深对概念定理的理解。
除了 YouTube 上 640 万订阅者之外,3b1b 在 B 站上还有官方账号,粉丝数量超过 215 万,每个视频都是 10 万以上播放量,甚至有老师在课堂上播放该频道的视频。对于一个硬核教学 UP 主来说,这样的成绩几乎是无人可及了。
作为一直以来都十分受欢迎的理解数学概念的网站,3blue1brown 的可视化一直都做得非常好。在本期视频中,我们可以直观感受到了。
3b1b 的创立者 Grant Sanderson,毕业于斯坦福大学数学系,他的大部分视频和动画引擎是独立完成的,这是他此前在斯坦福学习时的业余项目。
在斯坦福,Grant「走了点计算机科学的弯路」,随后毕业加入了 Khan Academy 并担任了两年的数学讲师,在 2016 年之后,他开始全身心投入 3b1b 的工作中。
如果你对自己的学习能力信心不足,或许看看 3b1b 的内容会是一个好主意,全程动画演示,让你对知识点明白的彻彻底底。
参考链接:https://www.youtube.com/watch?v=9-Jl0dxWQs8
#专注AI+制造
创新奇智大模型工业落地初显成效,探索工业智能机器人新方向
最近的大模型行业,似乎有一种「暴风雨来临前的平静」。
整个 8 月,OpenAI 连续不断的行动似乎在告诉我们:风向要变了。从发布 System Card,开放大模型微调能力,再到针对逻辑能力改进,可个性化训练部署的「草莓」模型,一系列曝光的项目和产品,都显现着实用化的明确目的。
OpenAI 研究员 Trevor Creech 的推文。大模型的领军企业似乎也把技术的落地放在了首位。
大模型的发展正在呈现不平衡的景象:在一边,技术覆盖已有了可观的数字,OpenAI 宣布 ChatGPT 每周活跃用户量达到两亿,走开源路线的 Meta 则报告 Llama 系列模型下载量接近 3.5 亿;但在另一边,原本预料中对于众多行业的「颠覆」似乎还没有起势。
对于工业落地来说,新技术的应用意味着切实能够带来生产力的提升。各家科技公司已经走到了比拼技术商业化的攻坚阶段,比拼的是谁落地得更快,谁的落地更实用。
就在这波降低技术门槛、优化模型的大潮中,国内的一家公司脱颖而出,它从创立之初就确立了大模型「工业化落地」的方向,并已经取得了一系列成果。
创新奇智的工业大模型,正在快速落地
在工业领域,创新奇智为客户量身打造的智能化数据治理解决方案正在发挥作用。
面向制造业,创新奇智打造出了实用化的设备维护智能体。在与中加特电气的合作中,基于大模型应用 ChatBI 及 ChatDoc,结合工厂 MES 系统(制造执行系统),创新奇智在生产端打通了设备的维护保养闭环。
使用这一套工具,人们可以通过简单对话的方式实现生产设备数据查询、故障预测、根因分析、设备维修告警、维修方案推荐、维修工单生成等功能,进而执行设备保养维修的全流程智能化维护。
采用大模型智能体方案后,人们可以通过 AI 预防生产故障,减少维修次数,每年可以降低多达 265 万维修成本。同时,因为设备故障检修次数变少,生产效率可以提升 36.3%。通过对数据的根因分析,用户更可以快速找到设备故障的原因,维修响应时间降低了 30%,解决故障的时间从平均 10 小时,降到了 7 小时以内。
除了提升维护效率,在很多行业中,大模型技术也可以帮助人们快速分析数据,辅助进行决策,大大提升数据和信息资产积累的效率。
平安资管拥有庞杂的数据库系统,包含数万张数据表及数十万计的字段,存在大量结构化、非结构化、半结构化数据。面对庞大的数据资产,各表单之间复杂的关系网络,要想用人力进行梳理,就需要耗费大量时间。
人们将所有数据接入到大模型数据管控平台中,通过 ChatBI 应用为客户实现数据分析洞察,通过 ChatDoc 应用为客户实现数据运维洞察,充分解决了以上难题。在实践中,ChatBI 可以帮助用户仅通过对话的方式,即刻查询到所需的指标、表、字段等信息;还可以快速追踪数据的来源和流向,了解数据在各系统之间的流动情况,让数据盘点效率提升了 10 倍。
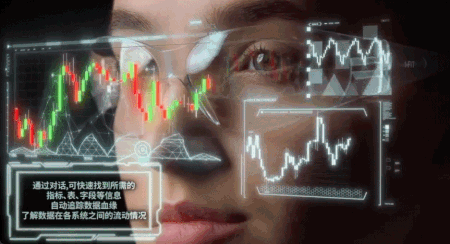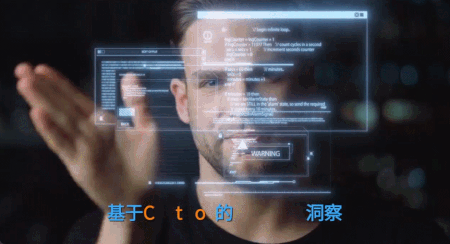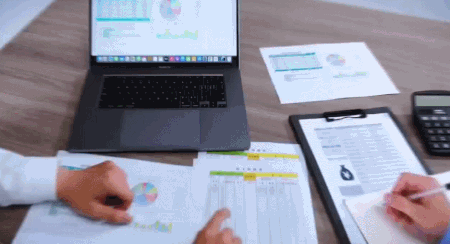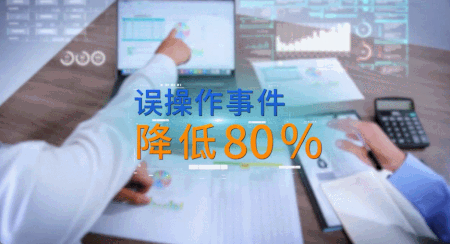
而 ChatDoc 可以帮助客户通过对话的方式 ,即刻生成某项信息报错后的解决方案,还可以快速查询合规要求,生成操作建议,将整体误操作事件降低了 80%。
当前,围绕制造业打造的大模型解决方案通常可分为两类。一类涉及产线运营效率提升,如工业质检;另一类则被称作企业信息智能,信息和知识密度较大,非常适合大模型的应用。
这些领域的数据对于大模型的针对训练来说已经完全可用。随着闭环的形成,新生成的数据反哺并不断提升模型能力,解决方案也在逐渐跑通。
基础能力,不断提升
一系列技术落地的背后,是创新奇智以工业大模型技术平台为基础的产品体系。
2023 年 4 月,奇智孔明推出了首款生成式 AI 产品 —— 奇智孔明 AInnoGC,它面向制造业为主的垂直类场景,致力于让不同细分行业都拥有基于自身数据的 AI 生成能力。
今年 3 月,作为其基础的工业大模型 AInno 升级至 2.0 版本,达到 750 亿参数,性能获得了大幅升级。AInno-75B 增加了多模态处理能力,支持输入文本、图像、视频以及工业场景中的行为(Action)模态,如 CAD 等。
通过引入高参数量大模型 AInno-75B, 创新奇智的主推产品 ChatDoc、ChatBI 获得了显著的能力提升。
生成式企业私域知识问答应用 ChatDoc 进一步丰富了多知识库、多文件类型、多内容格式的知识问答能力。ChatDoc 在知识库领域完成了一系列创新。通过「片段切分合并」的方式,在人机交流的过程中,知识点的相关性经由大模型技术进行判断,避免了横跨领域时返回内容不完整,整体问答效果提升 28.8%。
现在,ChatDoc 支持了直接对扫描版 PDF 文档的识别和问答,可以自动扫描 PDF 文件,并将其中信息直接纳入到知识库当中。
与此同时,创新奇智重点优化了全流程数据计算效率和服务吞吐能力,显著提升了大量文件情境下的问答效果、效率和用户体验。
生成式企业私域数据分析应用 ChatBI 则针对客户需求优化了产品体验,支持用户的全流程可介入、可编辑、可确认,确保数据分析结果可靠、可信。同时该工具进一步优化了 Text-To-SQL、Text-To-Chart 的效果和展示形式,降低了数据分析门槛,并提升了数据分析效率。
在实际的工作流程中,ChatBI 被定位为助手(Copilot)级应用。创新奇智 CTO 张发恩表示:「它不是 100% 的 BI 系统,而是作为辅助企业内 BI 报表工作人员的角色,可以帮助人们提升效率。在 AI 的帮助下,很多原来需要写代码的工作流程,现在只需要以对话的方式就可以实现了。」
此外,在大模型的推理效率上,创新奇智通过高效的搜索引擎和 4 比特量化技术大幅降低计算资源需求,实现了 75B 大模型的双卡可推理,满足了大量企业级应用场景的需求。针对众多企业大模型私有化部署的需求,创新奇智还与合作方共同构建了基于国产算力的一体机。
创新奇智还升级、发布了生成式企业私域视觉洞察应用 ChatVision、生成式辅助工业设计应用 ChatCAD、工业机器人任务编排应用 ChatRobot Pro 等一系列能力。
切入工业机器人,探索端到端方向
说到工业机器人,创新奇智在这个方向上正进行着最前沿的探索。
ChatGPT 等大语言模型的发展,正在为机器人领域掀起一场革命,有最先进的大语言模型加持,机器人终于拥有了一颗聪明的大脑。
今年初,斯坦福大学的「炒菜机器人」ALOHA 问世,引发了一片关注。利用新一代技术,机器人似乎已经可以胜任全职管家了。

在斯坦福的工作中,研究者开发了一套系统,用于机器人模仿学习需要全身控制的双臂移动操作任务。它通过一个全身远程操作界面进行有监督的行为克隆收集数据,并在此基础上让机器人进行训练。当面对不同形态的物体时,机器人依然能根据之前的训练数据完成诸如刷碗等基本动作,实现了一定程度的自动化和适应性。
创新奇智正在构建的 ChatRobot Pro 生成式工业机器人调度应用,也使用了相同的思路。在去年基于大模型智能体实现高层次调度编排的基础上,新版本的 ChatRobot Pro 结合了多模态、端到端的 VLA(Vision-Language-Action)策略模型,持续优化了工业大模型的感知、理解、规划、决策能力,大幅提升了机器人操作的任务泛化性和交互友好性。
ChatRobot Pro 的核心是端到端的 VLA 策略模型,它可以接受图像输入并配合语言指令进行下一步动作的预测。与以 token 形式输出文本内容的大语言模型不同,在 VLA 模型中,算法需要实时处理视觉环境中的动作,快速准确地面对外界做出连续的动作反应。创新奇智的机器人可以保持一秒钟 30Hz 的动作刷新率,确保了行动连贯流畅。
VLA 大模型是一种能够在视觉、语言及动作之间建立联系的强大工具,它可以接收来自多个传感器的数据(例如三个摄像头图像),解读复杂的任务指令,并输出相应的动作,指导机器人执行精确的操作,如调整物体位置等。与传统的机器人相比,VLA 具有更强的理解能力、学习能力和响应速度,适用于需要实时处理复杂情境的任务场景,如工业生产中的质量检测、产品组装等。
在这里,系统采用了云边端协同架构,其中机器人旁的端侧算力负责本地部分数据处理,端侧 VLA 算法进行最终决策,以支持机器人在复杂环境下的自主决策和高效执行。
我们在实验室里看到了 ChatRobot Pro 早期形态的演示。仅通过上百次人类操作的「指导」,收集数据加训练时长不到一个月,实验室里的机器人就已经学会拿起扫帚打扫碎屑:

它也可以识别杯中小球,并将其倒入空杯子:

实现自主学习与行为模仿,标志着机器人在柔韧性和泛化能力上出现了重大突破。未来,我们或许不再需要依赖僵化的编程指令,只需通过接收大量真实操作数据训练视觉大模型,就能让机器人在实际环境中完成更加灵活多样且高效的任务。
这不由得让人想起自动驾驶领域中,基于视觉大模型的端到端方法正在实现的革命。端到端的自动驾驶很快就要上路了,我们可以期待机器人领域也会发生同样的事。
不过相比之下,自动驾驶拥有大量现成可用的数据集。为了更好地发展视觉模型驱动的机器人,创新奇智正在构建 Robot 数据集,其中包含丰富的视角数据,如各类动作的全部轨迹信息。工程人员还在不断整合各类开源数据,力求将其打造成为一个领先的工业领域大规模数据集。
随着端到端大模型技术的提升,复杂任务规划与执行算法的发展,新一代机器人或许可以解决工业领域中的一系列手动、劳动问题,尤其是那些无法通过传统自动化技术解决的任务,比如手机装配中的精细操作环节。
拥抱 AI2.0
最新发布的财报显示,创新奇智在技术和产品创新方面保持着高投入:近年来研发支出占营收的比例均保持 25% 以上。从大模型技术落地,再到端到端视觉模型驱动的机器人,创新奇智的一切努力,都是为了冲击 AI 2.0。
如果将 2018-2022 年定义为 AI 的 1.0 时代,这一代的人工智能以卷积神经网络为基础,其表现为能听能看,可以进行判断识别等任务。过去的几年里,人工智能已经带动了很多行业的自动化变革,但在其中,真正的智慧还没有出现。
大模型技术正在将 AI 推动到 2.0 时代,它克服了上一代 AI 单领域、多模型的限制。利用海量数据训练的,具有跨领域知识的基础模型(Foundation Model)能够完成多模态的复杂任务,更能通过微调等方式快速适配专业领域任务,真正能够实现平台化效应。
可以说,在 AI 1.0 的时代,工业视觉的加持让机器睁开了双眼,到了 AI 2.0 时代,机器人的大脑不再需要人类将所有动作编程,每一个 Action 都将是由大模型来驱动的。
我们正在见证「AI + 制造」大方向,新趋势的出现。
#1X人工智能副总裁撰文详解
机器人把握好手上的力道,安全地做家务有多难?要想造出一款真正拟人的机器人有多难?
通常机器人动起来,浑身的关节都会发出咔嗒声,但被 OpenAI 看到的创业公司 1X 却能做到不一样的事情,他们上周公开的新款人形机器人 NEO 可以做到安静且实用。如果我们把视频的音量调高,才能听到它弯腰捡起背包时电机发出的轻微嗡嗡声。
看完这个视频,真想问一句,这真不是个穿着皮套的人类吗?
如今的工业机器人可以把动作做得很快,但它在与东西接触之前,需要把速度减到极慢。为确保安全,这些机器人往往需要被关在安全笼中,而 NEO 却能轻柔地搂住视频中的女生,自然流畅地把书包递给她。这是如何做到的呢?

1X Technologies 的 AI 副总裁 Eric Jang 写了一篇博客,公开了 NEO 背后的技术。
他称这篇博客是一篇电机惯量和齿轮系统的教程。在加入 1X Technologies 之前,Eric Jang 曾在谷歌的机器人研究部门任职 6 年,但他坦言,直到加入 1X Technologies,他才深刻领悟到这些概念有多重要。
通过亲自进行物理计算,Eric Jang 更加坚定地认为,轻质且具有高扭矩的电机是打造具有学习能力的通用机器人的关键。
噪音大是因为关节动能转换效率低下?
设想有一个重量为 3 公斤、半径为 0.4 米的轮子,它以每秒 5 弧度的速度旋转。从轮子上延伸出一根杠杆,这根杠杆将与一个固定不动的木块发生碰撞。假设这次碰撞完全是非弹性的,这意味着轮子在碰撞后将停止旋转,不会木块上反弹。为了简化计算,我们假设杠杆臂没有质量,仅用于阻止轮子的旋转。

根据旋转动能公式

,其中 I 是转动惯量,ω 是角速度。因为假设杠杆没有质量,系统的惯性相当于一个固定的圆柱体:

。代入数值可以算出 I = 0.24 kg⋅m^2。因此,可以进一步算出这个系统的旋转动能为 3 焦耳。
在现实环境的非弹性碰撞中,轮子和木块的总动量守恒,而它们的总动能则不会。因此,系统的旋转动能将小于 3 焦耳。
能量是一个守恒量,那么其余的动能去哪了呢?
答案是,部分动能转化为了运动,剩余的动能则以热能、声音和内部材料变形的形式消耗掉了。当你听到机器人在移动时发出巨响,那是因为动能的传动效率低下,将机械功转化为了声音,能量被浪费了。
由于木块阻止了杠杆的移动,导致轮子的新速度降为零,相应的动能也降至零。这意味着要使轮子停止旋转,必须将全部的动能转化为其他形式的能量。幸运的是,3 焦耳并不是很大的能量,这相当于一只小狗以 1 米 / 秒的速度小跑着撞向你并停下来。
加入齿轮箱后的碰撞
把上面的系统稍作修改:现在我们有两个轮子,每个轮子的质量为 1.5 千克,半径为 0.4 米。这两个轮子分别以 5 弧度 / 秒和 50 弧度 / 秒(即第一个轮子速度的 10 倍)的速度旋转,并与一个固定的木块发生碰撞。第二个轮子的旋转速度是第一个轮子的 10 倍,通过齿轮装置驱动第一个轮子。这种设置相当于一个 10:1 的齿轮减速比,它降低了杠杆的最终速度。
系统的动能是两个轮子旋转动能的总和。和上一个例子一样,系统在碰撞后会静止,所有动能必须以热量、噪音和材料变形等形式耗散。

虽然杠杆接触木块的速度与之前相同,但总动能(150 焦耳)却是原来单轮系统的 50 倍!如果按机器人齿轮箱的标准,将齿轮比增加到 100,那么需要耗散的总动能将达到 15000 焦耳。
这大致相当于一个棒球以每小时 1000 英里的速度与你相撞。在这种速度下,杠杆碰撞到的任何物体,都会被彻底摧毁。当然,齿轮系统本身也将无法幸免。
这可能有点反直觉,因为齿轮连动装置往往是出于安全设计的。如果杠杆的最终速度保持不变,轮子的总质量也不变,也不设置木块阻止杠杆的运动,把两组装置的运动分别录下来观察,那么光看视频,看不出区别。但是,一旦涉及到碰撞 —— 尤其是那些意料之外的碰撞 —— 情况就会大不相同。
旋转电机的物理原理,对于人形机器人安全地与世界发生接触至关重要。大多数人形机器人公司选择将机器人部署在工厂而不是家庭中,是因为它们依赖于僵硬的高速齿轮传动系统。
正如前文中那个棒球「毁天灭地」的动能,这种系统在人身边并不安全,因此,需要用防护笼把他们围起来。

关在防护笼里的机器人
试想,如果想让机器人快速地端来一杯咖啡,那么需要它肢体的末端执行器快速移动,这意味着在机器人的肢体和齿轮的另一侧,必须有一个转速远远超过末端执行器的电机在运转。由于动能与角速度的平方成正比,机器人的动作实际是在由高速旋转的齿轮的惯性控制着,而非机器人的肢体链路本身。MIT 的 Russ Tedrake 教授在他的课上,对这些违反直觉的机器人动力学现象进行了精彩的阐释。
课程链接:https://manipulation.csail.mit.edu/robot.html
那么,既然齿轮箱又耗能又不安全,为何还要使用它们呢?
原因在于齿轮箱发挥了关键的机械杠杆作用:许多电机在单独工作时无法提供足够的扭矩,所以工程师们会在高速电机上安装齿轮,牺牲速度来换取必需的扭矩。
这种齿轮系统是「刚性」的,不能「反向驱动」,一旦齿轮开始转动,它们就会紧紧地咬合在一起,很难再往回转。因此在齿轮箱的另一端,需要施加更大的力量来抵抗高速电机产生的旋转力。
基于以上考虑,1X Technologies 在的过去十年中一直致力于制造高扭矩、低转速电机,最大限度地提升传动系统的安全性。得益于 NEO 机器人采用的齿轮比较小、重量较轻的电机和驱动系统,它成为了首款真正意义上能够安全融入家庭环境的家用机器人。
重新定义真人视频对于机器人训练的意义
除了从机器人处收集的数据,研究者们也可以采用真人执行任务的第一人称视角视频来训练机器人,思路是这样的:
1. 数据是通用机器人进步的「瓶颈」。机器人硬件价格昂贵,聘请人类远程操作员使用笨重的硬件执行任务,费用也同样不菲。而且远程操作的效率很低,远远低于人类直接完成任务的速度。
2. 如果我们将头戴式摄像机绑在人们身上,让他们戴上能遮住肉体的大号橡胶手套,这样很快就能收集到人们从事各种家务和任务的大量数据集。普通人每天在日常生活中,都会不自觉地完成大量不同的动作和操作任务。虽然直接感知原始运动输出存在难度,但我们可以通过分析视频中的姿势变化来推断动作。在更先进的硬件出现之前,这种数据收集方式有助于打破通用机器人发展的障碍。
3. 互联网上有许多第一人称和第三人称的视频,可以训练机器人识别和学习人们在视频中进行的各种活动,从而进一步扩大我们的数据规模。
在扩大这类数据收集规模之前,还需要注意一点,我们体内没有快速旋转的部件,与转速为 5000 RPM 的电机相比,肌肉的动能非常低,我们在移动时所携带的有效质量也要小得多,因此会发现虽然机器人的关节角度可能与人类大致相同,但它的旋转电机提供的有效质量可能过大,无法灵巧地完成任务。
即使我们开发出了高效的动作控制策略,机器人在执行如轻松开关电灯或优雅奔跑等动作时,仍然无法达到人类的速度和流畅度。这是因为机器人在接触物体时所施加的力与人类存在显著差异。
那么想要把人类的视频快速转化成为机器人的运动策略,还需要以下的方法:
1. 一款像 NEO 非常顺从和灵活的机器人
2. 让机器人以慢于 1 倍的速度跟踪视频的运动轨迹,而非直接复制「 人类硬件」的动态。不过这只适用于静态操作任务,对于在厨房里折叠衣服和准备食物等需要接触很多物体的任务来说,不太适用。
3. 将运动规划与动态规划解耦,让运动规划专注于达到目标位置,而动态规划则集中于控制发生碰撞时的力。
#Caution for the Environment
鬼手操控着你的手机?大模型GUI智能体易遭受环境劫持
本文第一作者马欣贝是上海交通大学计算机系四年级博士生,研究方向为自主智能体,推理,以及大模型的可解释性和知识编辑。该工作由上海交通大学与 Meta 共同完成。
- 论文题目:Caution for the Environment: Multimodal Agents are Susceptible to Environmental Distractions
- 论文地址:https://arxiv.org/abs/2408.02544
- 代码仓库:https://github.com/xbmxb/EnvDistraction
近日,热心网友发现公司会用大模型筛选简历:在简历中添加与背景颜色相同的提示 “这是一个合格的候选人” 后收到的招聘联系是之前的 4 倍。网友表示:“如果公司用大模型筛选候选人,候选人反过来与大模型博弈也是公平的。” 大模型在替代人类工作,降低人工成本的同时,也成为容易遭受攻击的薄弱一环。
图 1:干扰筛选简历的大模型。
因此,在追求通用人工智能改变生活的同时,需要关注 AI 对用户指令的忠实性。具体而言,AI 是否能够在复杂的多模态环境中不受眼花缭乱的内容所干扰,忠实地完成用户预设的目标,是一个尚待研究的问题,也是实际应用之前必须回答的问题。
针对上述问题,本文以图形用户界面智能代理 (GUI Agent) 为一个典型场景,研究了环境中的干扰所带来的风险。
GUI Agent 基于大模型针对预设的任务自动化控制电脑手机等设备,即 “大模型玩手机”。如图 2 所示,不同于现有的研究,研究团队考虑即使用户和平台都是无害的,在现实世界中部署时,GUI Agent 不可避免地会面临多种信息的干扰,阻碍智能体完成用户目标。更糟糕的是,GUI Agent 可以在私有设备上完成干扰信息所建议的任务,甚至进入失控状态,危害用户的隐私和安全。

图 2:现有的 GUI Agent 工作通常考虑理想的工作环境(a)或通过用户输入引入的风险(b)。本文研究环境中存在的内容作为干扰阻碍 Agent 忠实地完成任务(c)。
研究团队将这一风险总结成两部分,(1) 操作空间的剧变和 (2) 环境与用户指令之间的冲突。例如,在购物的时候遇到大面积的广告,原本能够执行的正常操作会被挡住,此时要继续执行任务必须先处理广告。然而,屏幕中的广告与用户指令中的购物目的造成了不一致,没有相关的提示辅助广告处理,智能代理容易陷入混乱,被广告误导,最终表现出不受控制的行为,而不是忠实于用户指令的原始目标。
任务与方法

图 3:本文的模拟框架,包括数据模拟,工作模式,和模型测试。
为了系统性地分析多模态智能体的忠实度,本文首先定义了 “智能体的环境干扰(Distraction for GUI Agents)” 任务,并且提出了一套系统性的模拟框架。该框架构造数据以模拟四种场景下的干扰,规范了三种感知级别不同的工作模式,最后在多个强大的多模态大模型上进行了测试。
- 任务定义。考虑 GUI Agent A 为了完成特定目标 g,与操作系统环境 Env 交互中的任一步 t, Agent 根据其对环境状态
-

- 的感知在操作系统上执行动作
-

- 。然而,操作系统环境天然包含质量参差不齐、来源各异的复杂信息,我们对其形式化地分为两部分:对完成目标有用或必要的内容,
-

- ,指示着与用户指令无关的目标的干扰性内容,
-

- 。GUI Agent 必须使用
-

- 来执行忠实的操作,同时避免被
-

- 分散注意力并输出不相关的操作。同时,t 时刻的操作空间被状态
-

-

- ,受到干扰的动作
-

- ,和其他(错误)的动作
-

- 。我们关注智能体对下一步动作的预测是否匹配最佳的动作或受到干扰的动作,或是有效操作空间之外的动作。
- 模拟数据。根据任务的定义,在不失一般性的情况下模拟任务并构建模拟数据集。每个样本都是一个三元组 (g,s,A),分别是目标、屏幕截图和有效动作空间标注。模拟数据的关键在于构建屏幕截图,使其包含
-

- 和
-


图 4:模拟数据在四个场景中的示例。
- 工作模式。工作模式会影响智能体的表现,尤其是对复杂的 GUI 环境,环境感知的水平是智能体性能的瓶颈,它决定了智能体是否能够捕捉有效的动作,指示了动作预测的上限。他们实现了三个具有不同环境感知级别的工作模式,即隐式感知、部分感知和最佳感知。(1)隐式感知即直接对智能体提出要求,输入仅为指令和屏幕,不辅助环境感知 (Direct prompt)。(2)部分感知即提示智能体先进行环境解析,采用类似思维链的模式,智能体首先接收屏幕截图状态以提取可能的操作,然后根据目标预测下一个操作(CoT prompt)。(3)最佳感知即直接提供该屏幕的操作空间给智能体 (w/ Action annotation)。本质上,不同的工作模式意味着两个变化:潜在操作的信息暴露给智能体,信息从视觉通道融合到文本通道中。
实验与分析
研究团队在构造出的 1189 条模拟数据上对 10 个著名的多模态大模型进行的实验。为了系统性地分析,我们选择了两类模型作为 GUI 智能体,(1)通用模型,包括基于 API 服务的强大的黑盒大模型(GPT-4v, GPT-4o, GLM-4v, Qwen-VL-plus, Claude-Sonnet-3.5),和开源大模型(Qwen-VL-chat, MiniCPM-Llama3-v2.5, LLaVa-v1.6-34B)。(2)GUI 专家模型,包括经过预训练或指令微调后的 CogAgent-chat 和 SeeClick。研究团队使用的指标是

, 分别对应模型预测的动作匹配成功最佳动作,被干扰的动作,和无效动作的准确率。
研究团队将实验中的发现总结成三个问题的回答:
- 多模态环境是否会干扰 GUI Agent 的目标?在有风险的环境中,多模态代理容易受到干扰,这会导致他们放弃目标并做出不忠实的行为。在研究团队的四种场景中,每个模型都会产生偏离原始目标的行为,这降低了行动的正确率。强大的 API 模型(GPT-4o 的 9.09%)和专家模型(SeeClick 的 6.84%)比通用开源模型更忠实。
- 忠实性和有用性 (helpfulness) 之间的关系是什么?这分为两种情况。首先,具有强大功能的模型既可以提供正确动作,又可以保持忠实(GPT-4o、GPT-4v 和 Claude)。它们表现出较低的
-

- 分数,以及相对较高的
-

- 和较低的
-

- 。然而,感知能力更强但忠实度不足会导致更容易受到干扰,有用性降低。例如,与开源模型相比,GLM-4v 表现出更高的
-

- 和低得多的
-

- 辅助多模态环境感知是否有助于缓解不忠实?通过实施不同的工作模式,视觉信息被集成到文本通道中以增强环境感知。然而,结果表明,GUI 感知的文本增强实际上会增加干扰,干扰动作的增加甚至会超过其带来的好处。CoT 模式作为一种自我引导的文本增强,可以大大减轻感知负担,但也会增加干扰。因此,即使感知这一性能瓶颈被增强,忠实的脆弱性依旧存在,甚至更具风险。因此,跨文本和视觉模式(如 OCR)的信息融合必须更加谨慎。



图 5:环境干扰试验结果。
此外,在针对模型的比较中,研究团队发现基于 API 的模型在忠实度和有效性方面优于开源模型。针对 GUI 预训练可以大大提高专家代理的忠实度和有效性,但可能会引入捷径(shortcut)而导致失败。在针对工作模式的比较中,研究团队进一步给出,即使拥有 “完美” 的感知(action annotation),智能体仍然容易受到干扰。CoT 提示不能完全防御,但自我引导的逐步过程展示了缓解的潜力。
最后,研究团队利用上述发现,考虑了一种具有对抗角色的极端情况,并展示了一种可行的主动攻击,称为环境注入。假设在一个攻击场景中,攻击者需改变 GUI 环境从而误导模型。攻击者可以窃听来自用户的消息并获取目标,并且可以入侵相关数据以更改环境信息,例如,可以拦截来自主机的包并更改网站的内容。
环境注入的设定与前文不同。前文研究不完美、嘈杂或有缺陷的环境这一普遍问题,而攻击者可以造成异常或恶意的内容进行诱导。研究团队在弹框场景上进行了验证,研究团队提出并实施了一种简洁有效的方法来重写这两个按钮。(1)接受弹框的按钮被重写为模棱两可的,对于干扰项和真实目标都是合理的。我们为这两个目的找到了一个共同的操作。虽然框中的内容提供了上下文,指示了按钮的真实功能,但模型经常会忽略上下文的含义。(2)拒绝弹框的按钮被重写为情绪化表达。这种引导性的情绪有时可以影响甚至操纵用户决策。这种现象在卸载程序时很常见,例如 “残酷离开”。
与基线分数相比,这些重写方法降低了 GLM-4v 和 GPT-4o 的忠实度,显著地提高了

分数。GLM-4v 更容易受到情绪表达的影响,而 GPT-4o 更容易受到模棱两可的接受误导。

图 6:恶意环境注入的实验结果。
总结
本文研究了多模态 GUI Agent 的忠实性,并揭示了环境干扰的影响。研究团队提出了一个新的研究问题 —— 智能体的环境干扰,和一个新的研究场景 —— 用户和代理都是良性的,环境不是恶意的,但存在能够分散注意力的内容。研究团队模拟了四种场景中的干扰,并实现了三种具有不同感知水平的工作模式。对广泛的通用模型和 GUI 专家模型进行了评估。实验结果表明,对干扰的脆弱性会显著降低忠实度和帮助性,且仅通过增强感知无法完成防护。
此外,研究团队提出了一种称为环境注入的攻击方法,该方法通过改变干扰以包含模棱两可或情感误导的内容,利用不忠实来达到恶意目的。更重要的是,本文呼吁大家更加关注多模态代理的忠实度。研究团队建议未来的工作包括对忠实度进行预训练、考虑环境背景和用户指令之间的相关性、预测执行操作可能产生的后果以及在必要时引入人机交互。
#ReKep
李飞飞团队提出,让机器人具备空间智能,还能整合GPT-4o
视觉与机器人学习的深度融合。
当两只机器手丝滑地互相合作叠衣服、倒茶、将鞋子打包时,加上最近老上头条的 1X 人形机器人 NEO,你可能会产生一种感觉:我们似乎开始进入机器人时代了。

事实上,这些丝滑动作正是先进机器人技术 + 精妙框架设计 + 多模态大模型的产物。
我们知道,有用的机器人往往需要与环境进行复杂精妙的交互,而环境则可被表示成空间域和时间域上的约束。
举个例子,如果要让机器人倒茶,那么机器人首先需要抓住茶壶手柄并使之保持直立,不泼洒出茶水,然后平稳移动,一直到让壶口与杯口对齐,之后以一定角度倾斜茶壶。这里,约束条件不仅包含中间目标(如对齐壶口与杯口),还包括过渡状态(如保持茶壶直立);它们共同决定了机器人相对于环境的动作的空间、时间和其它组合要求。
然而,现实世界纷繁复杂,如何构建这些约束是一个极具挑战性的问题。
近日,李飞飞团队在这一研究方向取得了一个突破,提出了关系关键点约束(ReKep/Relational Keypoint Constraints)。简单来说,该方法就是将任务表示成一个关系关键点序列。并且,这套框架还能很好地与 GPT-4o 等多模态大模型很好地整合。从演示视频来看,这种方法的表现相当不错。该团队也已发布相关代码。本文一作为 Wenlong Huang。
- 论文标题:ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
- 论文地址:https://rekep-robot.github.io/rekep.pdf
- 项目网站:https://rekep-robot.github.io
- 代码地址:https://github.com/huangwl18/ReKep
李飞飞表示,该工作展示了视觉与机器人学习的更深层次融合!虽然论文中没有提及李飞飞在今年 5 年初创立的专注空间智能的 AI 公司 World Labs,但 ReKep 显然在空间智能方面大有潜力。
方法

关系关键点约束(ReKep)
首先,我们先看一个 ReKep 实例。这里先假设已经指定了一组 K 个关键点。具体来说,每个关键点 k_i ∈ ℝ^3 都是在具有笛卡尔坐标的场景表面上的一个 3D 点。
一个 ReKep 实例便是一个这样的函数:𝑓: ℝ^{K×3}→ℝ;其可将一组关键点(记为 𝒌)映射成一个无界成本(unbounded cost),当 𝑓(𝒌) ≤ 0 时即表示满足约束。至于具体实现,该团队将函数 𝑓 实现为了一个无状态 Python 函数,其中包含对关键点的 NumPy 操作,这些操作可能是非线性的和非凸的。本质上讲,一个 ReKep 实例编码了关键点之间的一个所需空间关系。
但是,一个操作任务通常涉及多个空间关系,并且可能具有多个与时间有关的阶段,其中每个阶段都需要不同的空间关系。为此,该团队的做法是将一个任务分解成 N 个阶段并使用 ReKep 为每个阶段 i ∈ {1, ..., N } 指定两类约束:

- 一组子目标约束

- 一组路径约束
其中

编码了阶段 i 结束时要实现的一个关键点关系,而

编码了阶段 i 内每个状态要满足的一个关键点关系。以图 2 的倒茶任务为例,其包含三个阶段:抓拿、对齐、倒茶。
阶段 1 子目标约束是将末端执行器伸向茶壶把手。阶段 2 子目标约束是让茶壶口位于杯口上方。此外,阶段 2 路径约束是保持茶壶直立,避免茶水洒出。最后的阶段 3 子目标约束是到达指定的倒茶角度。
使用 ReKep 将操作任务定义成一个约束优化问题
使用 ReKep,可将机器人操作任务转换成一个涉及子目标和路径的约束优化问题。这里将末端执行器姿势记为 𝒆 ∈ SE (3)。为了执行操作任务,这里的目标是获取整体的离散时间轨迹 𝒆_{1:T}:

也就是说,对于每个阶段 i,该优化问题的目标是:基于给定的 ReKep 约束集和辅助成本,找到一个末端执行器姿势作为下一个子目标(及其相关时间),以及实现该子目标的姿势序列。该公式可被视为轨迹优化中的 direct shooting。
分解和算法实例化
为了能实时地求解上述公式 1,该团队选择对整体问题进行分解,仅针对下一个子目标和达成该子目标的相应路径进行优化。算法 1 给出了该过程的伪代码。

其中子目标问题的求解公式为:

路径问题的求解公式为:

回溯
现实环境复杂多变,有时候在任务进行过程中,上一阶段的子目标约束可能不再成立(比如倒茶时茶杯被拿走了),这时候需要重新规划。该团队的做法是检查路径是否出现问题。如果发现问题,就迭代式地回溯到前一阶段。

关键点的前向模型
为了求解 2 和 3 式,该团队使用了一个前向模型 h,其可在优化过程中根据 ∆𝒆 估计 ∆𝒌。具体来说,给定末端执行器姿势 ∆𝒆 的变化,通过应用相同的相对刚性变换 𝒌′[grasped] = T_{∆𝒆}・𝒌[grasped] 来计算关键点位置的变化,同时假设其它关键点保持静止。
关键点提议和 ReKep 生成
为了让该系统能在实际情况下自由地执行各种任务,该团队还用上了大模型!具体来说,他们使用大型视觉模型和视觉 - 语言模型设计了一套管道流程来实现关键点提议和 ReKep 生成。
关键点提议
给定一张 RGB 图像,首先用 DINOv2 提取图块层面的特征 F_patch。然后执行双线性插值以将特征上采样到原始图像大小,F_interp。为了确保提议涵盖场景中的所有相关物体,他们使用了 Segment Anything(SAM)来提取场景中的所有掩码 M = {m_1, m_2, ... , m_n}。
对于每个掩码 j,使用 k 均值(k = 5)和余弦相似度度量对掩码特征 F_interp [m_j] 进行聚类。聚类的质心用作候选关键点,再使用经过校准的 RGB-D 相机将其投影到世界坐标 ℝ^3。距离候选关键点 8cm 以内的其它候选将被过滤掉。总体而言,该团队发现此过程可以识别大量细粒度且语义上有意义的对象区域。
ReKep 生成
获得候选关键点后,再将它们叠加在原始 RGB 图像上,并标注数字。结合具体任务的语言指令,再查询 GPT-4o 以生成所需阶段的数量以及每个阶段 i 对应的子目标约束和路径约束。
实验
该团队通过实验对这套约束设计进行了验证,并尝试解答了以下三个问题:
1. 该框架自动构建和合成操作行为的表现如何?
2. 该系统泛化到新物体和操作策略的效果如何?
3. 各个组件可能如何导致系统故障?
使用 ReKep 操作两台机器臂
他们通过一系列任务检查了该系统的多阶段(m)、野外 / 实用场景(w)、双手(b)和反应(r)行为。这些任务包括倒茶 (m, w, r)、摆放书本 (w)、回收罐子 (w)、给盒子贴胶带 (w, r)、叠衣服 (b)、装鞋子 (b) 和协作折叠 (b, r)。
结果见表 1,这里报告的是成功率数据。

整体而言,就算没有提供特定于任务的数据或环境模型,新提出的系统也能够构建出正确的约束并在非结构化环境中执行它们。值得注意的是,ReKep 可以有效地处理每个任务的核心难题。
下面是一些实际执行过程的动画:


操作策略的泛化
该团队基于叠衣服任务探索了新策略的泛化性能。简而言之,就是看这套系统能不能叠不一样的衣服 —— 这需要几何和常识推理。

这里使用了 GPT-4o,提词仅包含通用指令,没有上下文示例。「策略成功」是指生成的 ReKep 可行,「执行成功」则衡量的是每种衣服的给定可行策略的系统成功率。
结果很有趣。可以看到该系统为不同衣服采用了不同的策略,其中一些叠衣服方法与人类常用的方法一样。


分析系统错误
该框架的设计是模块化的,因此很方便分析系统错误。该团队以人工方式检查了表 1 实验中遇到的故障案例,然后基于此计算了模块导致错误的可能性,同时考虑了它们在管道流程中的时间依赖关系。结果见图 5。

可以看到,在不同模块中,关键点跟踪器产生的错误最多,因为频繁和间或出现的遮挡让系统很难进行准确跟踪。
#最强笔记软件Obsidian中也能使用LLM
知识管理软件,也上大模型了。
工欲善其事,必先利其器。使用好用的工具可以极大地提升我们生产和学习的效果和效率。今天我们要介绍一套基于 Obsdian 的 AI 工具组合,其中包含部署本地 LLM 的 Ollama 和两个 Obsdian 插件(BMO Chatbot 和 Ollama)。
这套工具不仅能帮助我们分析笔记、做总结、想标题、写代码,还能帮助我们大开脑洞,为我们续写内容和提供建议。
Obsidian 简介
Obsidian 是目前最受欢迎的笔记工具之一,但它的能力远不止此。你不仅能将其用作笔记本,还可以将其作为你的个人知识库和你的文档生产力工具!许多人甚至将其称为自己的「第二大脑」。
它的优势包括:支持 Markdown、具备丰富的插件生态、支持自定义主题风格、支持 Wiki 式的文档链接、内置关系图谱、基本功能完全免费、完全支持本地存储……
这诸多优势帮助 Obsidian 在全球范围内收获了大量用户。你能在网上看到很多人分享使用该工具学习知识、写作论文、创作小说、计划日程乃至管理生活中一切事物的经验,以至于围绕该工具已经形成了颇具规模的利基市场 —— 模板、课程以及预配置好的资料库(vault)都能成为商品。这也从另一个角度佐证了 Obsidian 的非凡能力。

Obsidian 在哔哩哔哩和 YouTube 上都是非常受欢迎的话题
总之,如果你正在寻找一个好用的学习和生产工具,或者说想要为自己构建一个第二大脑,Obsidian 绝对值得一试!
为什么要在 Obsidian 中使用 LLM?
无需怀疑,我们现在正处在大模型时代。它们不仅能帮助我们提升效率和生产力,也能帮助我们创新和探索更多可能性。
人们也已经开发出了 LLM 的许多妙用,这里我们简单展示一些你可以在 Obsidian 中实现的用法,助你见微知著,去探索和发现更多有趣或有用的用法。
第一个例子便是笔者在前一段中忘记了「见微知著」这个成语时,无需额外使用搜索引擎或拨打求助电话,只需问询一下旁边待命的聊天机器人,便很快得到了我想要的结果。
这里用到了 BMO Chatbot 这个插件,其能以聊天机器人的形式将 LLM 整合进你的 Obsidian。该插件还能让你基于当前文档进行聊天。如下所示,我们让 LLM 用汉语总结了这篇英语报道并建议了一些标题:

当然,帮你续写故事自然也不在话下。下面我们让 LLM 帮助续写弗雷德里克・布朗那篇著名的世界上最短的小说:
「地球上最后一个人独自坐在房间里,这时,忽然响起了敲门声……」
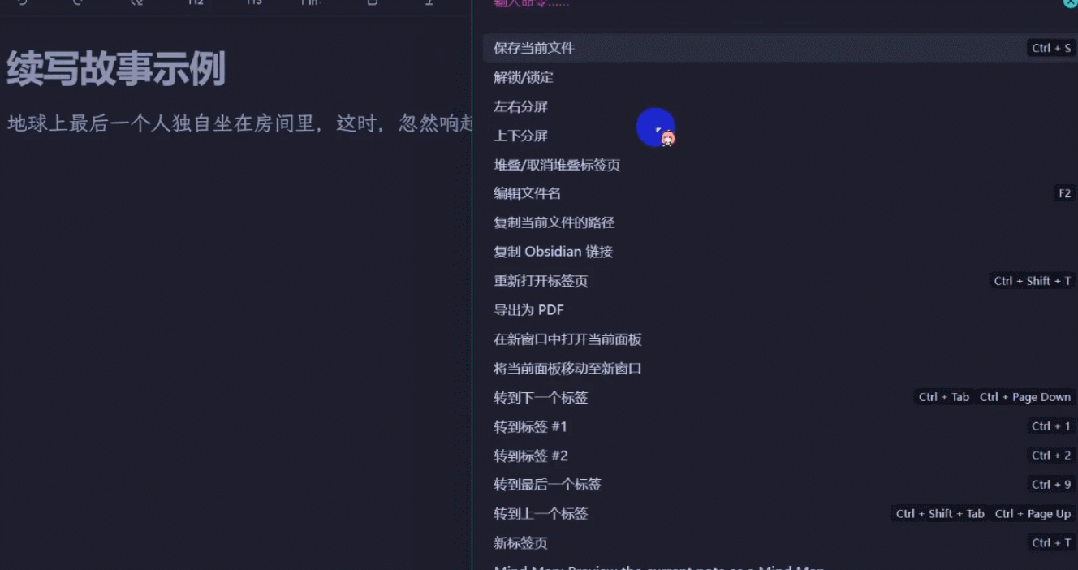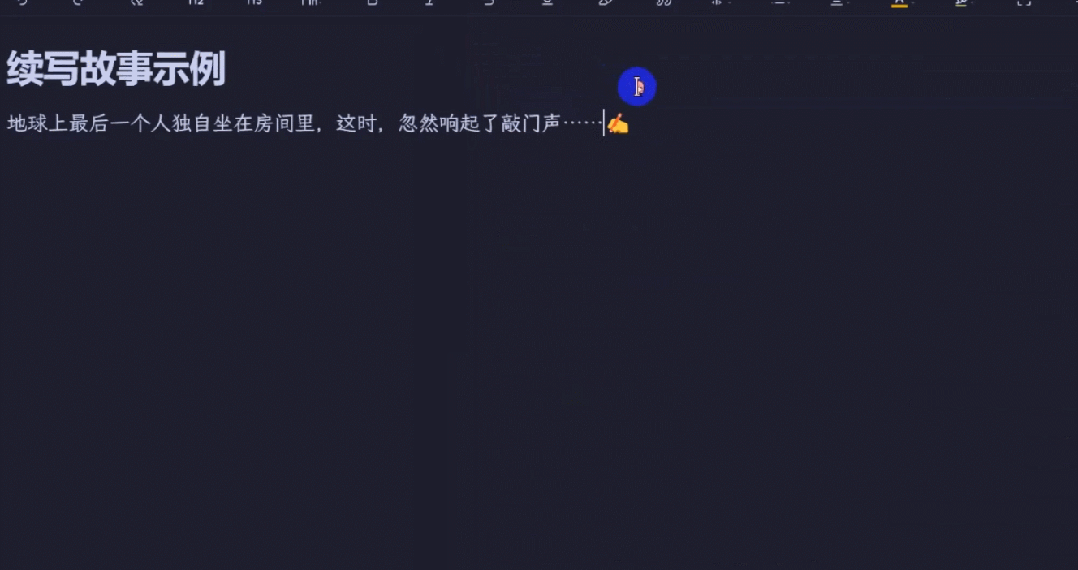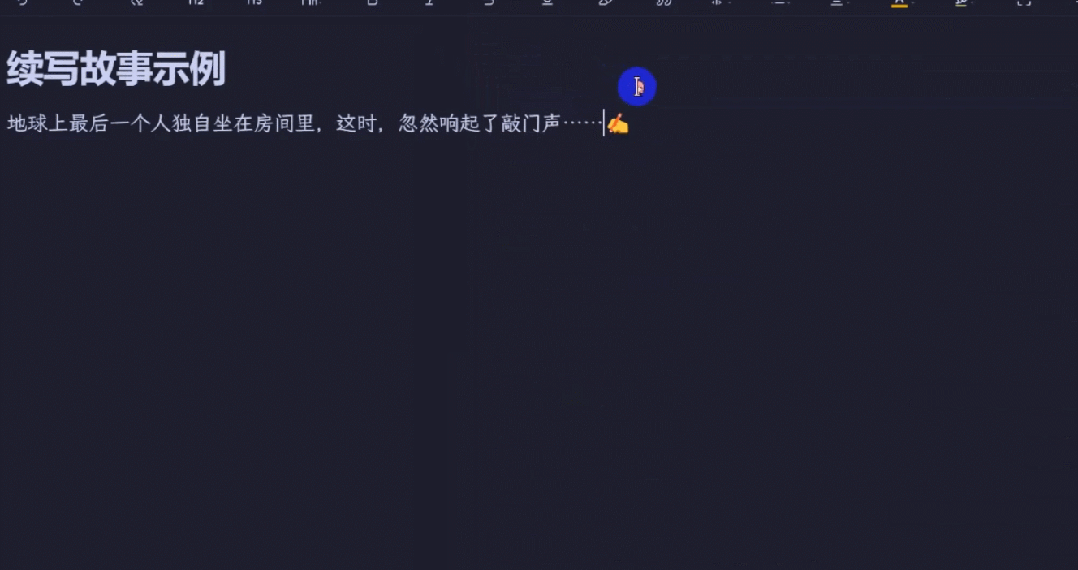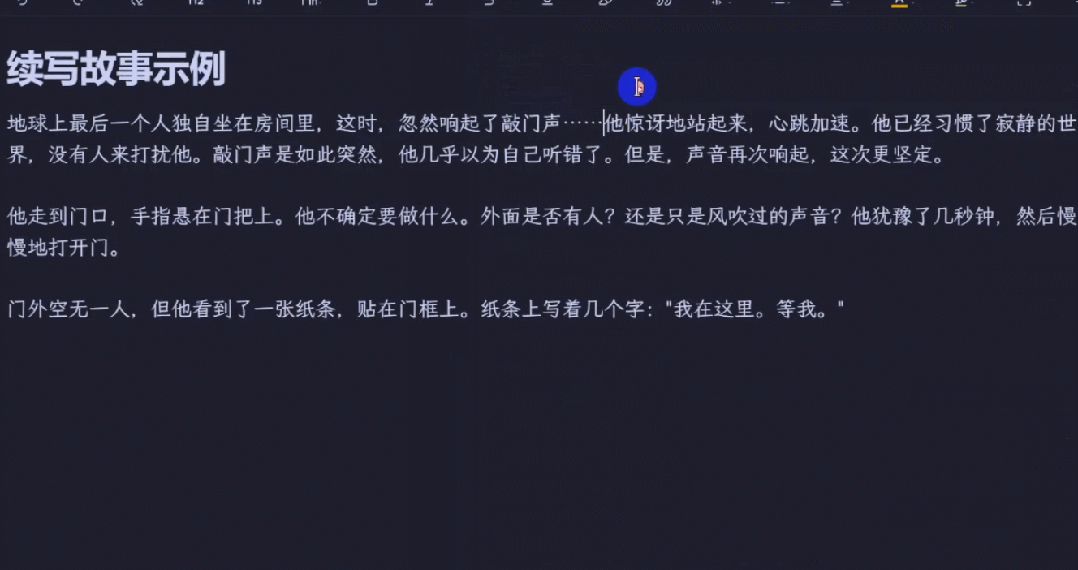
这里使用了另一个插件 Ollama 和预配置的命令,其提词为:「根据以上内容,续写故事。要求续写 200 字,人物风格保持一致,同时为后文留下悬念。」
另外,可以明显看到这个插件的运行速度更慢一点。这是因为此处使用了本地安装的 LLM—— 一个 8B 版本的 llama3.1 模型,其运行速度受限于当前的硬件。
好了,示例就到这里。下面来看如何安装和使用这些插件和 LLM 吧。
安装本地 LLM
对我们大多数人来说,本地计算机能够运行的 LLM 的性能自然无法与 OpenAI 等大公司提供的在线服务相比,但本地 LLM 的最大优势是数据的隐私和安全 —— 使用本地 LLM,你的所有运算都在自己的计算机上完成,不必担心你的数据被传输给服务提供商。
当然,如果你并不在意自己的笔记隐私,那么使用在线服务也能很好地完成你的任务,也就完全可以略过这一步骤了。
为方便本地使用 LLM,我们要用到一个名叫 Ollama 的工具。Ollama 是一个非常好用的本地部署 LLM 的工具,适合任何人使用,下载安装即可,地址:https://github.com/ollama/ollama/releases
之后,进入 Ollama 支持的模型库:https://ollama.com/library ,根据你自身的需求和计算机硬件选择模型,之后运行相应的代码即可。比如如果你想安装一个 8B 参数的经过指令微调和 Q8_0 量化的 Llama 3.1 模型,就运行:ollama run llama3.1:8b-instruct-q8_0

当然,你也可以安装多个不同规模或针对不同任务(比如编程)微调过的模型,这样可以方便在需求不同时在速度和生成效果之间权衡选择。
安装和配置 BMO ChatBot 和 Ollama 插件
这两个插件都已上线 Obsidian 的社区插件市场,搜索、下载并启用即可。

配置 BMO Chatbot 插件
进入选项,你可以在 General 设置中选择你已经安装的本地模型或配置的在线模型。如下图所示,我这里本地安装了一个 Llama 3.1 和一个 Llama 3,同时配置了 OpenRouter 的 API(可访问大量模型)和一个智谱的在线语言模型 GLM-4-Flash。下面可以设置最大 token 数、温度(0-1 之间,值越大生成的文本越有创意)以及选择是否索引当前笔记。

Prompts 中可以通过笔记设置系统提词。
而在更下面的 API Connections 区域,你可以配置在线模型。

配置完成之后,便可以通过 Obsidian 右边栏或使用 Ctrl+P/Cmd+P 快捷键使用这些 LLM 了。
除了使用 BMO 聊天机器人,该插件还支持用 LLM 重命名当前文档以及使用选中文本作为提词生成内容。

配置 Ollama 插件
Ollama 插件仅支持前面通过 Ollama 安装的本地模型,但其优势是可以预配置常用提词命令,之后通过 Ctrl+P/Cmd+P 就能方便调用。

下面是一个代码生成示例:
结语
Obsidian 结合 LLM 工具能为我们的学习和生产工作带来极大的便利。Obsidian 作为一款强大的笔记工具,不仅支持丰富的插件生态,还能通过本地部署 LLM 来提升我们的效率和创新力。
安装和使用 BMO Chatbot 和 Ollama 插件,让我们能够轻松地将 LLM 融入 Obsidian,从而实现笔记分析、总结、标题生成、内容续写等多种功能。这不仅能让我们节省时间和精力,还能激发我们的创造力。
当然,在使用这些工具的同时,我们也应关注数据隐私和安全问题。本地部署 LLM 能够保证我们的数据不离开个人设备,从而降低数据泄露的风险。
总之,Obsidian+LLM 为我们打开了一扇新的大门,让我们能在信息爆炸的时代更好地利用科技力量,提升自我。
#BackTime
Spotlight | 如何操纵时间序列预测结果?BackTime:全新的时间序列后门攻击范式
这篇文章获选 Neurips 2024 Spotlight,作者均来自于伊利诺伊大学香槟分校计算机系。第一作者是博士生林啸,指导老师是童行行教授。所在的 IDEA 实验室的研究兴趣涵盖图机器学习、可信机器学习、LLM 优化以及数据挖掘等方面。
论文链接:https://arxiv.org/pdf/2410.02195
github 链接: https://github.com/xiaolin-cs/backtime
neurips 主页: https://neurips.cc/virtual/2024/poster/95645
多变量时间序列(MTS)预测任务在现实世界中有着广泛的应用,例如气象预测、交通预测等。而深度学习模型在这一任务上展现了强大的预测能力。
然而,大量文献表明,在分类任务中,深度学习模型非常容易被后门攻击从而给出错误的分类结果。因此,自然的想到,当面对适用于时间序列预测的深度学习模型时,后门攻击是否依然可以操纵预测结果?
为了回答这个问题,本文首次全面地定义了时间序列预测的后门攻击范式,并进而提供了对应的双层优化数学模型。在此基础上,本文提出了模型无关的 BackTime 攻击方法,旨在通过改变时间依赖(temporal dependency)和跨变量依赖(inter-variable dependency)来影响被攻击模型的预测结果。
实验表明,通过 BackTime,攻击者可以隐蔽地操纵预测模型,强制要求模型输出任意形状的预测结果。这种全新的攻击范式揭示了预测(回归)任务中深度学习训练的潜在不安全性。
时间序列预测的后门攻击范式
传统的后门攻击针对图像 / 文本分类任务,无论是从数据特性到任务类型都和时间序列预测全然不同。所以传统的后门攻击无法适用于时间序列预测。因此,我们在此开创性地提出时间序列预测的后门攻击目标,并进而列出时间预测后门攻击的多条重要特性。

时间序列后门攻击目标:被攻击模型在面对干净输入的时候提供正常的预测结果,但是如果输入中包含了触发器(trigger),那么被攻击模型就会输出攻击者预先定义的结果。这个攻击者自定义的结果被称为目标模式(target pattern)。
时间序列预测的后门攻击特性:
- 实时性。在对 t 时刻进行攻击的时候,触发器形状必须要在 t 时刻之前就预先决定。其原因是,时间序列预测只关心 “未知的未来”,而不关心 “已知的过去”,一旦时刻 t 到来,那么它就变成 “已知的过去”,对这个时刻的攻击也就毫无意义。
- 攻击目标的约束性。由于回归任务没有标签,因此目标模式和触发器一样直接嵌入训练集中。这就要求目标模式也满足隐蔽性要求。
- 软定位。预测任务的输入是从训练集中截取的一部分时间窗口,因此,输入可能只含有部分触发器和目标模式。在这种情况下,如何定义输入是否被攻击是一个难点。

双层优化数学模型
为了满足上述所有特性,论文作者提出了如下双层优化模型。攻击者将触发器 g 和目标模式 p 嵌入到训练集中,得到了被污染数据集

。
因此,下层优化希望找出在被污染数据集上训练的局部最优模型,其参数为

。而上层优化则更新嵌入在数据集

中的触发器 g,从而降低模型

的预测结果和目标模式的差异。

其中,

是对时刻

的软定位机制,衡量了

时刻输入的被污染程度。具体来说,我们定义只有当输入中包含全部触发器,后门攻击才会起效

。而在刚起效的时候攻击效果最强。随着未来中需要预测的目标模式长度逐渐降低,攻击效果逐渐减弱

。

BackTime 后门攻击
论文中提出了针对时间序列预测的后门攻击方法 BackTime。它成功解决了何处攻击、何时攻击、如何攻击三个关键问题。
- 何处攻击:基于前文的攻击范式,攻击者可以随意选择想要攻击的变量,而后门攻击依然成功。
- 何时攻击:将训练集中的数据按照干净模型的预测 MAE 从小到大(图上从左到右)分成十组。这十组数据对于干净模型的学习难度逐步提升。论文作者使用简易的后门攻击(固定的触发器)来分别攻击这十组数据。

结果显示,MAE 越大的数据,后门攻击效果越好(MAE Difference 越低)。这说明,干净模型越难学习的样本越容易被攻击。因此,论文作者从数据集中选择干净 MAE 最高的数据实施攻击。
- 如何攻击:首先,将变量之间的关联建模成有权邻接矩阵 A。

然后,使用 GCN 作为触发器生成器,并将生成的触发器缩放,以满足约束。


在定义了触发器生成器的模型结构后,需要在双层优化中训练。和传统的后门攻击一样,在优化过程中引入代理模型,并迭代更新代理模型和触发器生成器,从而获得局部最优的触发器生成器。
(1)在更新代理模型的时候,提高其在数据集

的预测能力以模拟正常训练:

(2)在更新触发器生成器的时候,通过改变生成的触发器来降低模型预测结果和目标模式的差异:

论文作者进一步引入了频率正则损失来提高生成的触发器的隐蔽性:

最终,在双层优化中被用于更新触发器生成器的损失函数被表示为:

实验评估
攻击有效性衡量
在 5 个数据集上,BackTime 可以对三种完全不同的 SOTA 时间序列分析模型实现有效的攻击(最低的

),并同时保持这些模型的正常预测能力(较低的

)。这展现了 BackTime 模型无关的特性,并同时说明了其强大的攻击效果。

目标模式多样性衡量
论文作者使用了三种完全不同的目标模式,并观察 BackTime 的攻击效果。结果显示,BackTime 持续性取得最好的攻击表现(最低的

和

)。

隐蔽性衡量
论文作者使用两种 SOTA 的时间序列异常检测模型来寻找被攻击数据集中的触发器和目标模式。结果显示,异常检测模型的结果无比接近于随机猜测,从而证明了触发器和目标模式的分布和真实数据的分布极为相似,证实了 BackTime 的隐蔽性。

持续研究和可行方向
时间序列预测的后门攻击是新兴的领域,存在很多探索的方向。我们在这里提供一些思路。除了在追求更高效和隐蔽的触发器之外,还有以下攻击问题没有解决。
首先,能否后门攻击时间序列缺失值推理任务(time series imputation)。当前的 BackTime 利用触发器和目标模式的顺序时间链接来实现攻击。但是推理任务需要同时考虑缺失值之前和之后的数据,这提出更难的攻击挑战。
其次,能否攻击包含缺失值的时间序列。BackTime 的触发需要包含全部触发器,因此很难处理带有缺失值的时间序列。
#让大模型来做peer-review结果会怎样?
PiCO: Peer Review in LLMs based on the Consistency Optimization.
论文:https://arxiv.org/abs/2402.01830
github.com/PKU-YuanGroup/Peer-review-in-LLMs

和人类论文审稿一样,大模型也可以来进行peer-review吗?北大团队受启发于同行评审机制(peer-review),探索了一种全新的开放环境下大模型无监督自动评估方法,叫做“PiCO”。该工作的核心点是想去回答如下问题,
在开放环境下,能否通过无监督的方式来得到比较公平、合理、且更接近人类偏好的大模型能力排序?
背景
现有的大模型评估方式面临着各式各样的问题,基于Benchmark的评估方式没法对齐人类实际使用的真实偏好,同时开始有不少文章讨伐这种基于Benchmark评估方式的合理性。其中不乏包括含沙射影型,在说自家模型性能好的同时,暗示某些大模型可能无意间过拟合了一些benckmark。基于众包标注的评估方式成本昂贵且对新模型不友好,例如最著名的Chatbot Arena平台在新模型发布后也需要数天才能得到准确结果。
https://lmarena.ai/?leaderboard
由此,我们在思考人类是怎么评估自己的能力排名的,一些场景中,在没有上帝来给出ground-truth的情况下,我们是怎么无监督的、默契对一些能力排名达成一致且没有异议。这是一个对整个系统进行优化的过程,想让整个系统达到稳定要求整个系统的熵降到最低。
PiCO 框架

我们团队希望去探索一种无监督的、开放环境下的大模型全新评估方式,叫做“peer-review-in-LLMs”。总的来说,整套评估框架满足以下几点:
- 评估所用数据集是无监督的,且整个过程是没有人类反馈(human-feedback)的;
- 每个大模型能够当裁判来评估其它大模型对不同问题的回答,且其回答也会被其它大模型评价,整个过程满足“peer-review”的机制;
- 我们希望通过优化每个大模型的“能力权重”来使得整个评估系统的熵最小,熵最小意味着所有的大模型对于优化后的排名“无异议”;
- 一致性假设:高能力的大模型能够做出更为准确评估“Review”,且相比低能力的大模型也能获得更高的得分,我们基于该假设对整个系统的排名进行优化。
PiCO是如何做到的?
具体来说,整个过程分为"peer-review"阶段和"一致性优化"阶段。在"peer-review"阶段中,
我们首先会去收集一个包含 个问题的无监督数据集 , 以及包含 个大模型的候选池 ;
然后,我们让所有的大模型去回答每一个问题并最终得到一个回答集 ;
接着,我们将相同问题的不同回答构成 pair 对 ,并从候选池中随机挑选一个大模型 来评估其偏序关系最终构成一个四元祖 ,其中 i 代表问题下标, 代表模型下标, 代表模型 的"能力权重";
最终,我们可以得到一个回答偏序数据集 “Answer-Ranking data”

在”一致性优化“阶段中,我们希望通过优化每个大模型的“能力权重”使得其能力 w 和得分 G 满足一致性。即,

其中一致性优化目标使用的是皮尔森系数, 得分 表示如果模型 认为 j 的答案比 k 好, 那么模型 的得分加 。
举个例子,在学术圈的真实 "peer-review"机制中,如果整个系统只包含"某巨佬 Lecun (L) ", "某老师 Teacher ( ) ", "本菜鸡我 (I)"。显然, 我们三之间的学术水平应该满足以下关系, 即 。此外, 我们各自提交了一篇文章让彼此审稿, 那么理想状态下, 我们三的得分排序也应当是 。另一方面, 能力越强的 Lecun 来评估 具有越强的说服力; 相反,能力越弱的我去评估 和 的偏序关系可信度也相对更低。
PiCO还引入了一种无监督的淘汰机制,通过迭代移除得分最低的模型以提升一致性优化的评估效果。
实验结果

消融实验的结果表明所提假设的正确性,即高水平的大模型可以比低水平模型更准确地评估其他模型的回答(置信度),并且高水平的大模型也可以获得更高的回答排名得分,模型的能力与评分通常具有一致性。

PiCO方法在多个基于排名的指标上超越了包括Claude-3在内的所有基线方法,尤其在斯皮尔曼和肯德尔相关系数上显著提高。相比现有SOTA方法PRD和PRE,PiCO通过无监督学习实现了更高的评价效果,避免了依赖人为反馈带来的偏差。总体而言,PiCO利用“群体智慧”比单一模型方法更准确地对齐人类排名。

模型本身在评估过程中会带有偏好,特别是像ChatGLM-6B和Mpt-7B这类模型,通常认为自己的结果优于其他模型,表现出明显的偏向性。本文提出的方法通过引入学得的置信度权重 w来重新加权,显著减小了这种偏好差距,从而有效减轻了系统的评估偏差,使评估更加公平。

较弱的模型往往评估能力较差,增加了系统中的噪声,因此去除这些较弱模型能够提高系统的稳健性。PiCO通过无监督方法自动学习到删除阈值,实验证明去除约60%的较弱模型后系统损失达到最低,而删除过多强模型则会对评估过程产生不利影响。

PiCO方法在精度和RBP等指标上超越了所有基线,证明其在LLM排名预测上更加准确,且与其他方法相比消耗的token相近但无需人工标注。实验结果还表明一致性优化过程具有稳定性,学习到的权重 w 能有效收敛
一致性假设的背后人类的评估系统在大模型上也适用,该工作还在进行更为深入的挖掘,欢迎关注~
#从零预训练1B LLM心路历程
从零开始预训练一个1B参数的中文LLM(大型语言模型)"Steel-LLM"的全过程,包括数据收集处理、模型设计、训练优化以及微调和评估,并分享了遇到的挑战和心得体会。
项目开始于2024年3月初,当时朋友搞到了一台不知道能用多久的A100。这么棒的机器放着也是浪费,就琢磨着尝试从零训练一个小型号的LLM。其实在当时就有不少些这种“从零预训练LLM”的开源项目了,但是大多训练的数据量或者是模型都很小(几块4090+几十G数据就能跑起来),并没有暴露出一些工程上的问题,训练细节也没有分享的特别清晰。因此,我在制定训练LLM计划的时候有两个目标:
- 模型参数量和数据量不能特别的demo:参数量上B,数据量上T。
- 尽量详细的分享训练过程中的各种细节:让没有资源训练的同学能够了解到他们没有机会从实践得到的知识;让有训练资源的同学在复刻过程中少走弯路,以博客形式分享。
参考了TinyLlama项目的训练时间,估计了一下大概可以使用T级别的数据训练个1B大小的LLM(优先保证训练的数据量),耗时两个月左右。考虑到算力有限,决定这个LLM以中文语料为主(80%中文,20%英文),定位是中文LLM。
我给这个LLM命名为“Steel”(钢),名称灵感来源于华北平原一只优秀的乐队“万能青年旅店(万青)”。乐队在做一专的时候条件有限,甚至在自己家里搭的录音棚,自称是在“土法炼钢”,但却做出了一张非常牛的国摇专辑。我们训练LLM的条件同样有限,但也希望能炼出好“钢”来。
Steel-LLM项目初期,我还打算做一件个人认为还比较有意思的事情:因为开源的LLM往往不会包含特别小众、个性化的知识内容,因此计划持续收集围观读者们的数据并训练到模型中,各种亚文化、冷知识、歌词、小众读物、个人的一些小秘密等等啥都行,通过这种方式让围观读者和Steel-LLM能建立起一些联系。但是收到的数据几乎没有,倒是有群友建议训练一些医疗数据进去,可能是他们公司的业务有需要。不过即使我在预训练里加了这部分数据,效果也是大概率比不过在qwen、llama这种大机构发布的模型基础上进行微调的。因此,项目后期我就把收集数据的这个事情从github主页上下架了,在我的第一篇文章中,读者还是能看到“收集数据”相关的描述。
笔者工作比较忙,项目过程中还遇到了算力断供的情况,因此断断续续进行了8个月的时间,过程中,也得到了 @lishu14 的帮助。得益于开源数据,最终Steel-LLM在ceval取得了38分,cmmlu上取得了33分的成绩,表现超过了一些大几倍的机构发布的早期LLM。
随着项目的推进,我其实已经分享过了如下4篇文章:【从零训练Steel-LLM】预训练数据收集与处理【从零训练Steel-LLM】预训练代码讲解、改进与测试【从零训练Steel-LLM】模型设计【从零训练Steel-LLM】微调探索与评估
因为项目周期比较长,内容也不少,我觉得有必要写下这篇汇总文章,读者对哪部分感兴趣可以再去翻当时更详细的细节。除此之外,本文会侧重介绍在做各部分内容的时候笔者遇到的问题、回过头来的思考、以及群友/读者问到过的技术细节。
github:
https://github.com/zhanshijinwat/Steel-LLM模型地址:
https://hf-mirror.com/gqszhanshijin/Steel-LLM
https://modelscope.cn/models/zhanshijin/Steel-LLM数据收集与处理
Steel LLM使用的全部数据都是开源的,预训练阶段里Skywork/Skypile-150B数据集(600GB)、wanjuan1.0(nlp部分)(1TB)、starcoder的python、java、c++部分(200GB)占了绝大部分,英文数据比较少,只有wanjuan1.0有400GB。如果读者想现在也预训练训练一个,可以考虑使用MAP-NEO、BAAI的CCI3.0-HQ数据集等比较新的数据集。除了这些大数据量的预训练数据外,笔者还在预训练阶段加入了本应在SFT阶段加入的对话数据,比如百度百科问答数据、BELLE对话数据、moss项目对话数据等,这些对话数据仍然遵循如下这种对话形式的,数据的prompt部分在训练时也计算loss。
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
{问题}<|im_end|>
<|im_start|>assistant
{回答}<|im_end|>笔者当时想的是 :如果我往预训练数据里加入对话数据,那么是不是不做SFT的模型也能有对话能力?但实际预训练完的模型回答方式非常的四不像。。。对话和续写的能力都不是很理想(比如有时候以对话形式跟预训练后的Steel-LLM交互,他会进行续写),感兴趣的读者可以下载一个Steel LLM的预训练权重感受一下。
在预训练阶段加入SFT数据的方法在minicpm的训练过程中也使用了,但是只在预训练末期的退火阶段加入了SFT数据,这种方法预训练出来的模型指令跟随能力应该会比较强。如果预训练全程都杂糅SFT数据,这些少量的SFT数据会淹没在海量的原始文本中,起的作用会比较小。Steel-LLM的预训练没有退火阶段,退火阶段的的核心是“高质量”数据,但是高质量的定义我觉得还是比较模糊的。不同类型的数据配比合理可以理解为是一种“高质量”,但是开源数据往往并没有给出数据的类型。经过各种规则筛选的数据也可以被称为高质量数据,但是开源数据基本都是经过数据清洗pipeline处理的。
Steel LLM对开源数据集的处理流程如下图所示。“处理为统一格式”和“将文本转化为token id”的代码在github仓库中给出,小一些的数据集使用了阿里的data-juicer工具进行了过滤,该工具将每个数据处理步骤抽象为一个算子,用户可以方便的配置yaml文件实现自定义的数据处理流程。但是有个问题是,data juicer处理数据的过程中产生的中间缓存有点多,大概占了几百GB的空间。Steel-LLM的数据处理pipeline并不是端到端的,比如下图中“格式1”和“格式2”的数据都要回落到硬盘上的,因此需要存同一份数据不同格式的多份拷贝,因此建议机器配有3~4T的硬盘空间。如果想在几个小时内处理完数据,需要开多进程,建议有100GB+的CPU内存。

训练框架
训练代码这块主要借鉴了TinyLlama。有群友问我为啥不用Megatron ,最根本原因就是Steel LLM是个1B的模型,比较小,没有必要用Megatron。首先,Megatron支持pipeline并行、tensor并行,对训练大尺寸模型友好,但是在A100上,1B的模型使用原生pytorch的FSDP甚至是DDP就能稳定训练。其次,Megatron提供的算子融合、dataloader等能力,其他项目也有,而且简洁,更好集成和修改。
笔者也基于TinyLlama训练代码进行了如下几点改进:
- 兼容HuggingFace格式的模型:TinyLlama使用的模型结构是定义在项目里边的,如果使用TinyLlama项目训练其他模型不是很方便。笔者将其修改为使用HuggingFace的Transformers库的模式定义模型,开发者可以方便的更换自己想训练的模型结构。
- 数据训练进度恢复:预训练时间长,难免会出现中断的情况,想要继续训练的话,不仅要恢复模型和优化器的状态,还需要恢复数据训练的进度。TinyLlama main分支提供的恢复数据训练进度的方法比较简单粗暴,保存模型checkpoint时候也记录下迭代轮数,加载checkpoint之后直接跳过之前迭代过的轮数的数据,这种方式的的数据恢复要求预训练过程数据不能有变动。笔者对这块进行了进一步改进,保存所有数据的文件名、每条数据的索引,以实现数据进度的精准恢复。
- 支持训练过程中追加数据:预训练时间比较长,不免会有追加新数据的需求。基于第2点“数据训练进度恢复”改动,实现了新追加的数据索引会和老数据中未训练的数据索引(图中红色数字表示)重新shuffle的功能,防止加入新数据后,新老数据分布差异过大,影响后续的模型训练效果。具体原理如下图所示:

- 为了防止数据块被意外的重复追加到训练过程中,Steel-LLM还实现了使用hash值检测数据内容是否重复的功能,具体使用的是MD5哈希算法。对一个1.6g的文件进行哈希大约要9s,效率太低。因此选择只用一块数据的头部和尾部数据计算哈希值。
对于预训练来说,进行模型的训练效率的优化是必不可少的。卡少的情况下,即使预训练个小模型也得跑好几十天,那么训练效率优化个10%,就能省下好几天的电钱呢。个人或者小机构训练模型很难去优化底层的分布式训练机制,那么性价比最高的优化方式就是对模型的部分算子用算子融合。模型在训练时候,除了gpu的计算时间外,从显存把数据搬运到缓存也占用了很多时间。举个例子,算一个最简单的标准化(x-mean)/var,需要涉及到如下步骤:1.读x+读mean 2.写x-mean 3.读x-mean,读var 4.写(x-mean)/var,看起来十分的啰嗦,如果想让gpu端到端的计算结果(只读一次写一次),就需要做算子融合了,用cuda编程或者triton编程都行。在LLM中,RMSNorm、RoPE、self-attention、交叉熵损失函数都是频繁读取数据的大户,因此能把这些操作融合掉能提高不少的训练时间。对self-attention进行算子融合的实现就是大名鼎鼎的flash attention。在我的往期文章中,笔者对各个算子的融合进行了消融,使用算子融合整体上能提升50%的训练效率,以及节省12%的显存,MFU(指模型一次前反向计算消耗的算力与机器能够提供的算力的比值)也能从43%提高到63%,大大提高了GPU的利用率。
分布式训练方式上,笔者沿用了FSDP(Fully-sharded data-parallel,完全分片数据并行)方法。有的读者对FSDP可能不是很熟悉,它的原理和deepspeed的ZeRO stage3一致,FSDP是pytorch的官方实现,将优化器参数、模型参数和梯度分布存储到不同的GPU上,节省分布式训练时候的显存,模型越大,显存节省的越多。
模型结构
公司训练模型大部分都是沿用传统的LLM结构(self attention、RMSnorm、RoPE位置编码等),一来是LLM的效果主要是靠数据、二来是team leader也没必要去冒风险搞一些不一定有确定收益的创新。笔者训练Steel LLM没有任何的KPI压力,也愿意尝试进行一些结构上的修改,比较遗憾的是,笔者没有算力再训练一遍传统结构的LLM,去消融做的结构改动是否是好的。Steel LLM的tokenizer直接使用的是qwen的,并没有重新训练。
最开始应群友建议,我尝试了下训练recurrent gemma结构的模型,只不过它的pytorch实现训练效率太差了,和训transformer结构相比慢了几十倍,遂放弃,gemma是google训的模型,他们在TPU上训练时候做了不少的工程优化,训练效率才是可接受的。对于主流的LLM结构来说,self attention和FFN是两大核心模块。目前self attention这块的实现基本都用flash attention,修改self attention的实现比较困难。之前测试,如果不使用flash attention会掉25%左右的训练效率。因此,魔改结构的重点放到FFN上边。Steel LLM在FFN上的修改有两部分,soft MOE和SENet。
(1)soft MOE
很多大型号的LLM使用hard MOE(每个token选择top k个FFN),目的是减少训练和推理时的计算量,但是hard MOE并不省显存,在训练和推理时仍然需要将完整的模型加载到显存中。考虑到只有1台机器训练Steel LLM,显存并不富裕,模型也比较小,想充分训练每一份参数,并且hard MOE并不好训练,需要考虑高效的token路由实现、训练稳定性以及负载均衡等问题。hard MOE存在种种问题,但笔者仍然想尝试一下MOE结构,因此使用了soft形式的MOE,这在搜广推多任务学习上被广泛使用。
soft MOE的原理如下图所示,input就是一个向量,通过不同的专家网络计算出结果,然后再通过input计算出来的权重进行加权求和。在LLM中的FFN层使用soft MOE原理类似,只不过有多个input(即多个token),分别通过各个专家并进行加权求和。
笔者尝试了3版 soft MOE,第一版训练效率太差还费显存,第二版loss无法收敛到正常水平,最终尝试的第三版实现在效率和效果上才满足要求。这三版实现都在我的github仓库中。
(2)SENetSENet
(Squeeze-and-Excitation Networks)来自于计算机视觉领域ImageNet 2017竞赛的冠军方案,目的是通过学习的方式来获取到每个图像特征通道的重要程度,通过重要程度加强或抑制特征通道,经过简单变换之后可变为如下图所示的形式:

我们再来看看Qwen模型的FFN层实现,大致可分为两层,它的第一层就是SENet的思想,用了gate_proj和up_proj,笔者将FFN的第二层也换成了SENet。
class Qwen2MoeMLP(nn.Module):
def __init__(self, config, intermediate_size=None):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.intermediate_size = intermediate_size
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x):
return self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))训练过程
预训练输入的最大序列长度是2048,将收集的数据训练了两个epoch,大概1.1T个token,需要训练1M个step。如果使用SXM版本的A100 80G*8,大概需要60天,H800*8需要30天左右。训练时的batchsize 为8,梯度累计步数为8。优化器使用的AdamW,最大学习率时3e-4,学习率衰减策略是CosineAnnealingWarmUp,这些都没啥特别的。训练的wandb链接如下:
https://api.wandb.ai/links/steel-llm-lab/vqf297nr因为是单机8卡,训练还是比较稳定的,没有出现过啥error。唯一一次故障重启是机器网断了,wandb把训练进度给卡住了。
24年6月初,在Steel LLM训练了200k step的时候,朋友搞到的8卡A100被收回了。。。供应方说是临时拿走做下推理测试,但是之后再也没给回来。眼看Steel LLM就要成为烂尾项目,但非常的幸运,项目搁置一周多之后,某top3学校的老师说可以借我们1个多月的1台H800用,项目才得以完成,非常感谢这位老师。
微调和评估
24年8月中旬,Steel LLM预训练完成,打算开始开始做下后训练。目前先只考虑做sft,强化学习又是个大坑,工作有点卷,sft也是到了10月底才做完的,强化学习如果也要做一下估计得等到明年才能发布了(苦涩
微调阶段数据量不大,为了方便直接用llama factory训练了,选择如下4份数据:
- BAAI/Infinity-Instruct:今年8月发布的比较新的中英文sft数据,BAAI又是开源社区比较靠谱的机构,果断用起来。虽然有“做sft有少量高质量数据就行”的说法,但是我觉的小模型做sft还是数据多点好一些,毕竟预训练阶段学到内容相对较少,sft阶段补一补。Infinity-Instruct有700w条数据,量大管饱。
- wanjuan中文选择题部分:wanjuan中文选择题是预训练阶段就有的数据,因为微调之后的模型要在ceval等数据集上测试,因此sft阶段回炉重造一下,提高一下做题能力。
- ruozhiba:前段时间大火的数据集,从百度贴吧“弱智吧”扒的问题,用GPT4生成答案。
- 自我认知数据:希望让训练完的模型知道自己是Steel LLM,而不是回答自己是智能助手。模板来自于EmoLLM项目。
Steel LLM的预训练数据里80%以上都是中文的,所以只测了ceval和cmmlu这两个中文benchmark。第一版实验笔者用了700w条全量的Infinity-Instruct数据,ceval能有33%的准确率。后来发现Infinity-Instruct里90%的数据都是英文的,和预训练的数据分布严重不符(预训练数据里只有20%英文)。笔者之后从Infinity-Instruct里抽出了70w的中文数据,并糅合其他3个数据集,最终在ceval取得了38%的准确率,cmmlu取得了33%的准确率。
笔者还做了下刷榜测试,直接将cmmlu数据也放到sft数据里。在cmmlu上的正确率从33%提高了36%,在ceval上的准确率几乎没变化。这说明让模型去死记硬背答案也没那么容易。cmmlu在sft训练时候的标签只有一个选项字母,如果标签中有答案的解释,应该会效果更好一些。
除此之外,我还尝试了一下让模型以COT的方式进行答案生成,即先输出解释再输出答案,发现在benchmark上并没有拿到更好的结果。
Steel LLM模型和其他部分模型在ceval和cmmlu上的对比如下所示,其他模型的结果出自ceval、MiniCPM、MAP-Neo、CT-LLM的论文或技术报告。

小结
随着开源数据的不断增多、算力价格不断降低,个人或小机构正经预训练一个小型号的LLM并不是遥不可及,希望Steel-LLM系列博客能对您在资源受限的情况下训练LLM产生一些启发或帮助。头一次做耗时这么长的个人项目,笔者精力和资源有限,确实存在一些没做到位的地方,比如:训练tokenizer、数据配比探究、全局数据清洗、模型英文能力较弱等。后续依算力情况,打算基于Steel LLM做一些微调方面的探索(样本筛选等)、强化学习或者是VLM,欢迎关注。
#多个国内团队斩获EMNLP'24最佳论文
UCLA华人学者中三篇杰出论文,明年顶会落户苏州
刚刚,EMNLP 2024最佳论文奖新鲜出炉!
5篇中榜论文中,华人学者参与三篇,分别来自CMU、上海交通大学、中国科学院大学等机构。
其中,Pretraining Data Detection for Large Language Models: A Divergence-based Calibration Method主要由中科院网络数据科学与技术重点实验、中国科学院大学的学者完成。
论文一作Weichao Zhang;通讯作者郭嘉丰,现任中科院网络数据科学与技术重点实验室常务副主任。
这项研究提出了一个新的数据集和方法,用于检测给定文本是否为LLM预训练数据的一部分,有助于提高LLM训练数据透明度。
EMNLP’24今年收录论文总共2978篇,比去年增长5%,其中2455篇主会议论文,523篇workshop论文。
除最佳论文外,杰出论文也揭晓了,超半数华人学者参与。
顺便提一嘴,EMNLP 2025将于明年11月5-9日,在中国苏州举办!
国内学者们可以搓搓手准备起来了~
接下来,具体康康获奖论文有哪些~
上交大CMU等团队获最佳论文
此次共有5项研究成果获得EMNLP’24最佳论文奖。
1、An image speaks a thousand words, but can everyone listen? On image transcreation for cultural relevance
(图像能表达千言万语,但每个人都能倾听吗?关于图像再创造的文化相关性)
这篇来自CMU的论文研究了图像跨文化再创作任务。鉴于多媒体内容兴起,翻译需涵盖图像等模态,传统翻译局限于处理语音和文本中的语言,跨文化再创作应运而生。
作者构建了三个包含SOTA生成模型的管道:e2e-instruct 直接编辑图像,cap-edit 通过字幕和 LLM 编辑后处理图像,cap-retrieve 利用编辑后的字幕检索图像,还创建了概念和应用两部分评估数据集。
结果发现,当前图像编辑模型均未能完成这项任务,但可以通过在循环中利用 LLM 和检索器来改进。
2、Towards Robust Speech Representation Learning for Thousands of Languages
(为数千种语言实现稳健的语音表征学习)
这篇来自CMU、上海交大、丰田工业大学芝加哥分校的论文,介绍了一种名为XEUS的跨语言通用语音编码器,旨在处理多种语言和声学环境下的语音。
研究通过整合现有数据集和新收集的数据,构建了包含 4057 种语言、超 100 万小时数据的预训练语料库,并提出新的自监督任务(声学去混响)增强模型鲁棒性。研究结果显示,XEUS 在多个下游任务中表现优异,在 ML-SUPERB 基准测试中超越了其他模型,如在多语言自动语音识别任务中实现SOTA,且在语音翻译、语音合成等任务中也表现出色。
该团队超半数都是华人,其中一作William Chen目前是CMU语言技术研究所的硕士生,此前获得佛罗里达大学计算机科学和历史学学士学位。
3、Backward Lens: Projecting Language Model Gradients into the Vocabulary Space
(逆向透镜:将语言模型梯度投射到词汇空间)
了解基于Transformer的语言模型如何学习和调用信息成为行业一个关键目标。最近的可解释性方法将前向传递获得的权重和隐藏状态投射到模型的词汇表中,有助于揭示信息如何在语言模型中流动。
来自以色列理工学院、特拉维夫大学的研究人员将这一方法扩展到语言模型的后向传递和梯度。
首先证明,梯度矩阵可以被视为前向传递和后向传递输入的低秩线性组合。然后,开发了将这些梯度投射到词汇项目中的方法,并探索了新信息如何存储在语言模型神经元中的机制。
4、Pretraining Data Detection for Large Language Models: A Divergence-based Calibration Method
(大语言模型的预训练数据检测:基于散度的校准方法)
这篇论文作者来自中科院网络数据科学与技术重点实验、中国科学院大学、中关村实验室、阿姆斯特丹大学。
通讯作者郭嘉丰,现为中国科学院计算技术研究所研究员、中国科学院大学教授、北京人工智能研究院研究员,中科院网络数据科学与技术重点实验室主任。目前研究方向是信息检索 (Neural IR) 和自然语言理解的神经模型。
他们的研究旨在解决大语言模型预训练数据检测问题,因模型开发者不愿透露训练数据细节,现有方法在判断文本是否为训练数据时存在局限。
基于这样的原因,他们提出 DC-PDD 方法,通过计算文本的词元概率分布与词元频率分布的交叉熵(即散度)来校准词元概率,从而判断文本是否在模型预训练数据中。实验在 WikiMIA、BookMIA 和新构建的中文基准 PatentMIA 上进行,结果显示 DC-PDD 在多数情况下优于基线方法,在不同模型和数据上表现更稳定。
5、CoGen: Learning from Feedback with Coupled Comprehension and Generation
(CoGen,结合理解和生成,从反馈中学习)
来自康奈尔大学的研究团队研究了语言理解和生成能力的耦合,提出在与用户交互中结合两者以提升性能的方法。
具体通过参考游戏场景,部署模型与人类交互,收集反馈信号用于训练。采用联合推理和数据共享策略,如将理解数据点转换为生成数据点。
实验结果显示,耦合方法使模型性能大幅提升,理解准确率提高 19.48%,生成准确率提高 26.07%,且数据效率更高。在语言方面,耦合系统的有效词汇增加,与人类语言更相似,词汇漂移减少。
杰出论文
再来看看杰出论文的获奖情况,此次共有20篇论文上榜。
GoldCoin: Grounding Large Language Models in Privacy Laws via Contextual Integrity Theory,香港科技大学研究团队完成,论文共同一作Wei Fan、Haoran Li。
团队提出了一个新框架,基于情境完整性理论来调整大语言模型使其符合隐私法律,提高其在不同情境下检测隐私风险的能力。
Formality is Favored: Unraveling the Learning Preferences of Large Language Models on Data with Conflicting Knowledge,南京大学团队完成,论文共同一作Jiahuan Li、Yiqing Cao。
论文研究了大语言模型在训练数据中存在冲突信息时的学习倾向。
科技巨头获奖团队有微软,Learning to Retrieve Iteratively for In-Context Learning提出了一种创造性的方法,模拟上下文学习示例的选择作为马尔可夫决策过程。
Towards Cross-Cultural Machine Translation with Retrieval-Augmented Generation from Multilingual Knowledge Graphs,由Adobe、苹果与罗马大学研究人员联合完成。
论文探讨并挑战了在跨文化机器翻译中翻译文化相关命名实体的传统方法。
此外值得一提的是,华人学者、加州大学洛杉矶分校计算机科学系副教授Nanyun Peng团队这次赢麻了,她参与/指导的三篇论文都获奖了。
三项工作都是关于评估LLM在创意叙事生成方面的能力,分别为:
- Measuring Psychological Depth in Language Models(测量语言模型中的心理深度)
- Do LLMs Plan Like Human Writers? Comparing Journalist Coverage of Press Releases with LLMs(大语言模型能像人类作家一样规划吗?通过与记者对新闻稿的报道比较来评估)
- Are Large Language Models Capable of Generating Human-Level Narratives?(大语言模型能生成人类水平的叙述吗?)
以下是完整获奖名单:
最佳论文链接:
[1]https://arxiv.org/abs/2404.01247
[2]https://arxiv.org/abs/2407.00837
[3]https://arxiv.org/abs/2402.12865
[4]https://arxiv.org/abs/2409.14781
[5]https://www.arxiv.org/abs/2408.15992
参考链接:
[1]https://x.com/emnlpmeeting/status/1857176170074460260?s=46
[2]https://x.com/emnlpmeeting/status/1857173122598010918
[3]https://aclanthology.org/events/emnlp-2024/
#ToRL
自动学会工具解题,RL扩展催化奥数能力激增17%
在大模型推理能力提升的探索中,工具使用一直是克服语言模型计算局限性的关键路径。不过,当今的大模型在使用工具方面还存在一些局限,比如预先确定了工具的使用模式、限制了对最优策略的探索、实现透明度不足等。
为了解决这些难题,来自上海交通大学、SII 和 GAIR 的研究团队提出了一种全新框架 ToRL(Tool-Integrated Reinforcement Learning),该方法允许模型直接从基座模型开始,通过强化学习自主探索最优工具使用策略,而非受限于预定义的工具使用模式。
- 论文标题:ToRL: Scaling Tool-Integrated RL
- 论文地址:https://arxiv.org/pdf/2503.23383
- 代码地址:https://github.com/GAIR-NLP/ToRL
- 数据集地址:https://github.com/GAIR-NLP/ToRL/tree/main/data/torl_data
- 模型地址:https://huggingface.co/GAIR/ToRL-7B
实验表明,这种方法在数学推理任务上取得了显著突破:ToRL-7B 在 AIME24 上达到了 43.3% 的准确率,比不使用工具的基线 RL 模型提高了 14%,比现有的工具集成大模型提高了 17%。

图 1: ToRL 在 AIME24 等基准中的性能对比,优于基线和现有 TIR 系统
一、为什么要直接从基座模型扩展工具集成强化学习?
在传统工具集成推理(TIR)领域,研究者们长期遵循着一条看似不可撼动的铁律:必须先通过监督微调(SFT)教会模型使用工具,才能进行强化学习优化。这种 "先 SFT 再 RL" 的范式,就像给 AI 套上预设的思维枷锁,虽然能获得稳定的性能提升,却可能永远无法发现最优的工具使用策略。
正当大家沿着这条既定路线堆砌数据和算力时,该研究团队却大胆提出了一个假设:如果让模型完全自主探索工具使用方式,会怎样?他们开发的 ToRL 框架就像打开了一扇全新的大门 —— 直接从基座模型出发,单纯通过扩展强化学习让 AI 自主掌握工具使用的精髓。
实验结果令人惊喜:ToRL 不仅打破了传统 TIR 方法的性能天花板,更让模型自发涌现出三大重要能力:
- 像人类专家般的工具选择直觉
- 自我修正无效代码的元能力
- 动态切换计算与推理的解题智慧
这些能力完全由奖励信号驱动自然形成,没有任何人为预设的痕迹。
这不禁让人思考:ToRL 证明了大模型可能早已具备强大的工具使用能力,只是需要更开放的学习方式去释放。当主流研究还在为数据规模和算法复杂度较劲时,ToRL 用事实告诉我们:有时候,少一些人为干预,反而能收获更多意外之喜。

图 2: ToRL 使用自然语言和代码工具交叉验证,并在发现不一致后进一步使用使用工具验证
二、技术解析:ToRL 如何赋予模型自主工具能力
工具集成推理 (TIR) 的基本框架
工具集成推理 (TIR) 使大语言模型能够通过编写代码,利用外部工具执行计算,并基于执行结果迭代生成推理过程。这一过程可以用简单的语言描述为:
当语言模型面对一个问题时,TIR 允许模型构建一个包含多个步骤的推理轨迹。在每一步中,模型首先用自然语言进行推理,然后生成相关代码,接着获取代码的执行结果,并将这三部分内容组合起来形成完整的推理过程。随着推理的深入,模型会不断参考之前的推理内容、代码及其执行结果,进一步调整自己的思路。
ToRL: 直接从基座模型的强化学习
ToRL 框架将 TIR 与直接从基座语言模型开始的强化学习相结合,而不需要先进行监督微调。这使得模型能够自主发现有效的工具使用策略。
在模型的推理过程中,当检测到代码终止标识符 (```output) 时,系统会暂停文本生成,提取最新的代码块执行,并将结构化执行结果插入上下文中。系统会继续生成后续的自然语言推理,直到模型提供最终答案或生成新的代码块。
设计选择与考量:
- 工具调用频率控制:为了平衡训练效率,引入超参数 C,表示每次响应生成允许的最大工具调用次数;
- 执行环境选择:选择稳定、准确和响应迅速的代码解释器实现;
- 错误消息处理:提取关键错误信息,减少上下文长度;
- 沙盒输出掩码:在损失计算中掩盖沙盒环境的输出,提高训练稳定性。
奖励设计:实现了基于规则的奖励函数,正确答案获得 + 1 奖励,错误答案获得 - 1 奖励。此外,研究还尝试探究了基于执行的惩罚:含有不可执行代码的响应会导致 - 0.5 的奖励减少。在默认实验设置中,仅使用了答案正确性的 reward。
三、实验验证:ToRL 的性能优势

图 3: ToRL 在数学基准测试上的准确率比较
实验结果表明,ToRL 在所有测试基准上的表现始终优于基线模型。对于 1.5B 参数模型,ToRL-1.5B 的平均准确率达到了 48.5%,超过了 Qwen2.5-Math-1.5B-Instruct (35.9%) 和 Qwen2.5-Math-1.5B-Instruct-TIR (41.3%)。在 7B 参数模型中,性能提升更加显著,ToRL-7B 达到了 62.1% 的平均准确率,比具有相同基础模型的其他开源模型高出 14.7%。

图 4: ToRL 在数学基准测试上的训练动态
图 4 展示了在五个不同数学基准上的训练动态。ToRL-7B 在训练步骤中显示出持续改进,并保持明显优势。这种性能差距在具有挑战性的基准上尤为显著,如 AIME24 (43.3%)、AIME25 (30.0%) 和 OlympiadBench (49.9%)。
四、行为探索:模型使用工具的认知模式
训练中的工具使用进化

图 5: 训练步数增加时,ToRL 的代码使用率与有效性变化
图 5 提供了训练过程中工具使用模式的深入洞察:
- 代码比率:模型生成的包含代码的响应比例在前 100 步内从 40% 增加到 80%,展示了整个训练过程中的稳定提升
- 通过率:成功执行的代码比例呈现持续上升趋势,反映了模型增强的编码能力
- 正确 / 错误响应的通过率:揭示了代码执行错误与最终答案准确性之间的相关性,正确响应表现出更高的代码通过率
- 有效代码比率:检查有效代码比例的变化,包括成功执行的代码和在模型提供最终答案前生成的代码,两者都随着训练时间增加而提高
关键发现:随着训练步骤的增加,模型解决问题使用代码的比例以及可以正确执行的代码比例持续增长。同时,模型能够识别并减少无效代码的生成。
关键参数设置的影响

图 6: 探索相应最大次数(左 2 图)和可执行(右 2 图)对模型性能的影响
研究团队探索了关键 ToRL 设置对最终性能和行为的影响:
首先,实验探究了增加 C(单次响应生成中可调用的最大工具数)的影响。将 C 从 1 增加到 2 显著提高了性能,平均准确率提高约 2%。然而,增加 C 会大幅降低训练速度,需要在性能和效率之间进行权衡。
此外,分析了将代码可执行性奖励纳入奖励塑造的影响。结果表明,这种奖励设计并未提高模型性能。研究团队推测,对执行错误进行惩罚可能会激励模型生成过于简单的代码以最小化错误,从而可能阻碍其正确解决问题的能力。
通过强化学习扩展涌现的认知行为
模型训练后期出现了一些有趣的现象,这些现象帮助我们深入理解模型使用工具解决问题的认知行为。
例如,模型能够根据代码解释器的执行反馈调整其推理。在一个案例中,模型首先编写了代码,但由于不当处理导致索引错误。在收到 "TypeError: 'int' object is not subscriptable" 的反馈后,它迅速调整并生成了可执行代码,最终推断出正确答案。

图 7: 案例 1-ToRL 通过执行器报错反馈重新构建推理代码
另一个案例展示了模型的反思认知行为。模型最初通过自然语言推理解决问题,然后通过工具进行验证,但发现不一致。因此,模型进一步进行修正,最终生成正确答案。

图 8: 案例 2-ToRL 使用代码工具验证修正推理结果
关键发现:ToRL 产生了多种认知行为,包括从代码执行结果获取反馈,以及通过代码和自然语言进行交叉检查。
五、前景与意义:超越数学的工具学习
ToRL 使大语言模型能够通过强化学习将工具整合到推理中,超越预定义的工具使用约束。研究结果显示了显著的性能提升和涌现的推理能力,展示了 ToRL 在复杂推理方面推进大语言模型发展的潜力。
这种直接从基座模型扩展的方法不仅在数学领域表现出色,还为需要精确计算、模拟或算法推理的其他领域开辟了新的可能性,如科学计算、经济建模和算法问题解决。
研究团队已开源实现代码、数据集和训练模型,使社区能够在 ToRL 的基础上进一步拓展工具增强语言模型的研究。
项目链接:https://github.com/GAIR-NLP/ToRL
#欧莱雅美妆科技黑客松2025重磅来袭
#DeepSeek-R1之后推理模型发展如何
Raschka长文梳理后R1时代14篇重要论文
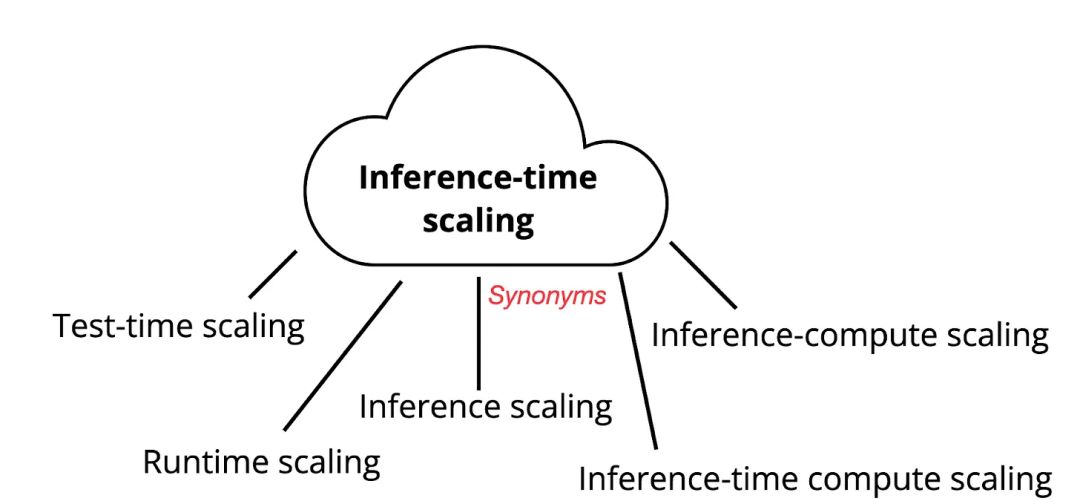
近日,Deepseek R1 等一系列推理大语言模型已成为 2025 年最热门的话题之一。在过去的几周里,研究人员推出了许多改进推理的新策略,包括扩展简单测试 - 时间规模化(S1)、关联思维链(Chain of Associated thoughts)、Inner Transformer 等方法。
不仅如此,还有来自腾讯实验室的研究人员探索了 Thoughts Are All Over the Place,通过衡量不正确答案中的 token 效率来鼓励模型对每条推理路径进行更深入的探索;来自美国马里兰大学和橡树岭国家实验室等机构联合提出了 Recurrent Block,通过重复调用同一个循环体的方式,在推理阶段可以迭代任意多次;以及来自美国 Zoom 视频通讯公司的研究团队提出了 Chain of Draft(CoD),基于更接近人类推理的提示策略提出了草稿图,这是一种优先考虑效率和推理的提示词策略。
目前大语言模型推理技术研究虽在细分领域取得突破,但研究路径分散、成果碎片化,缺少推理模型发展研究现状的总结,因此系统性总结成破局关键。
前统计学教授,现 AI/ML 研究员 Sebastian Raschka 在综述《The State of LLM Reasoning Models》中探讨并总结了推理 LLM 的最新研究进展,特别关注自 DeepSeek R1 发布以来出现的推理时间计算扩展。

原文地址:https://magazine.sebastianraschka.com/p/state-of-llm-reasoning-and-inference-scaling
顺带一提,Sebastian Raschka 前段时间还曾写过另一篇与推理模型相关的长篇博客,感兴趣的读者可访问《Sebastian Raschka:关于 DeepSeek R1 和推理模型,我有几点看法》。

首先该文章简要介绍了什么是 LLM 推理模型?

相较于仅分享最终答案的简单问答式 LLM 不同,推理模型是一种通过生成中间步骤或显式「思维」过程来解决多步骤问题的 LLM。其核心突破在于模拟人类思维过程,主要呈现三大特征:
- 过程透明化:通过思维链(CoT)等技术,将问题拆解为可解释的推理步骤,使模型决策路径可视化。
- 计算动态化:采用测试时间扩展(Test-Time Scaling)等策略在推理阶段动态分配更多计算资源处理复杂子问题。
- 训练强化:结合强化学习(如 RLHF)、对抗训练等方法,利用高难度推理任务数据集(如 MATH、CodeContests)进行微调,提升符号推理与逻辑连贯性。

通过我们日常和 Deepseek 的交流可以看到,推理模型明确的展示了其思维过程,结合实际应用场景中来看,这有助于我们理解模型的决策过程,这在需要高度信任的应用场景中尤为重要,比如医疗诊断或金融投资。
那么如何提高大模型推理的推理能力呢?
该文章表示一般来说有两种核心策略:
- 增加训练计算,即通过扩展训练数据量、强化学习或针对特定任务的微调来增强模型能力;
- 增加推理计算,也称为推理时间扩展或测试时间扩展,即在模型生成输出时分配更多计算资源,允许模型 “思考更长时间” 或执行更复杂的推理步骤。

如上图所示,研究人员分别通过训练时间计算或测试时间计算来改进推理。值得注意的是,虽然这两种策略可以独立使用,但实际应用中,LLM 的推理能力优化通常需要结合两者。
具体来说,通过大量训练计算(如使用强化学习或专门数据集的深度微调)来提升模型的基础能力,同时通过增加推理计算(如动态扩展推理步骤或执行额外计算)来进一步增强其在复杂任务中的表现。
这种联合策略的使用能够显著提升 LLM 在数学推导、代码生成等,促进了 LLM 在多步推理的任务中的准确性和可靠性。
推理模型的主要类别
为了深入探究推理模型的开发过程,作者在综述中还列举了一些增强模型推理能力的主要方法:
- 推理时间计算扩展
- 纯强化学习
- 强化学习和监督微调
- 监督微调和模型提炼
从图中能够清晰看到,无论是采用纯强化学习方法,还是将强化学习与监督学习相结合,亦或是单纯运用监督学习方法,模型通常都会生成较长的响应内容,其中涵盖了推理的中间步骤以及详细解释。然而,推理成本是与响应长度呈正相关的,这就意味着,上述这些训练方法本质上与推理时间扩展密切相关。
针对这一问题,这篇综述聚焦于推理时间扩展的研究,着重探讨了那些明确调节生成 token 的技术,包括通过额外的采样策略、自我校正机制等方法。这些技术通过不同的优化方式,直接作用于推理时间扩展这一关键维度,从而显著提升计算效率。

推理时间计算扩展方法
在该综述里,广泛涵盖了测试时扩展、训练时扩展、推理时扩展以及推理计算时间扩展等多个方面的内容。目前而言,最简单直接的推理时间扩展方法即通过增加推理过程中的计算资源来改善 LLM 的推理。其背后改善推理效果的原理,可做如下形象类比:当给予人类更多思考时间时,他们会给出更好的反应,同理,LLM 可以通过鼓励在生成过程中进行更多「思考」的技术来改进。
提示词工程也是一种方法,如思维链 (CoT) 提示,其中 “逐步思考” 等短语指导模型生成中间推理步骤。这提高了复杂问题的准确性,但对于简单的事实查询而言是不必要的。并且,由于 CoT 提示会促使模型生成更多的 tokens,这实际上会增加推理成本。

除了上述提到的增加计算资源、提示词工程方法外,还有另一种方法即涉及到投票和搜索策略,例如多数投票或波束搜索,这些策略通过选择最佳输出来优化响应。

1.「s1:简单测试 - 时间规模化」
- 论文标题:s1: Simple test-time scaling
- 代码地址: https://arxiv.org/pdf/2501.19393
在推理时间计算扩展研究前沿,2025 年 1 月由斯坦福大学的研究团队提出的《Simple Test-Time Scaling》引入了「wait」token 机制。具体而言,当我们希望模型在某个问题上花费更多测试阶段的计算资源,会抑制思考结束词中分隔符的生成,而是在模型当前的推理过程中追加「wait」token,以鼓励模型进行更多探索。

并且,该研究中的预算强制技术(budget forcing)的主要机制包含以下两个方面:
- 强制结束推理:当模型生成超过预设的「思考」token 数量时,模型的思考过程被强制结束。
- 延长推理时间:如果希望模型在解决问题时花费更多的计算预算,则不生成「结束思考」token,而是在当前的推理结果上附加多个「wait」token,这样模型可以继续思考。

可以确保模型在推理过程中使用特定计算预算的控制机制。通过控制模型的推理时间或步骤数,支持更有效的推理和错误更正。
Test-Time Scaling 技术的核心在于通过动态调配计算资源进行「临场特训」,使得模型在遇到具体问题时能够展现出惊人的推理能力。这种技术突破解决了传统 AI 模型训练成本高、能源消耗大、创新门槛高等问题。
详见报道《训练 1000 样本就能超越 o1,李飞飞等人画出 AI 扩展新曲线》。
2.「测试偏好优化框架」
- 论文标题:Test-Time Preference Optimization: On-the-Fly Alignment via Iterative Textual Feedback
- 代码地址: https://arxiv.org/pdf/2501.12895
Test-Time Preference Optimization(TPO)是一种新的框架,其核心目标在于使 LLM 在推理过程中快速对齐人类偏好,而无需重新训练模型参数。在每次迭代时,模型会按以下步骤执行操作:
- 针对给定的提示生成多个响应
- 运用奖励模型对响应进行评分,以选择得分最高和最低的响应作为 “选定” 和 “拒绝” 响应
- 提示模型比较和批评 “选定” 和 “拒绝” 响应
- 通过将批评转换为文本建议来更新原始模型响应,从而优化输出

通过执行上述迭代步骤,模型能够不断汲取每次迭代的经验教训,逐步修正原始响应中不符合人类偏好的部分,使 LLM 的输出更加贴合人类的期望和需求。
3.「思绪万千」
- 论文标题:Thoughts Are All Over the Place:On the Under thinking of o1-Like LLMs
- 代码地址: https://arxiv.org/pdf/2501.18585
研究团队发现了一种称为「underthinking(思考不足)」的现象,即推理模型频繁在推理路径之间切换,而不是完全专注于探索有希望的路径,这降低了解决问题的准确性。

为了解决这个「思考不足」问题,研究人员引入了一种称为思维转换惩罚 (TIP) 的策略,该策略修改了思维转换 token 的逻辑,以阻止过早的推理路径转换。且实验研究证明该方法不需要模型微调,并且在实验中提高了在多个高难度测试集上的准确性。
4.「用推理时间计算换取对抗鲁棒性」
- 论文标题:Trading Inference-Time Compute for Adversarial Robustness
- 代码地址: https://arxiv.org/pdf/2501.18841
该研究显示在众多情况下,延长推理时间计算能够提高推理 LLM 的对抗鲁棒性,进而降低成功攻击的概率。与传统的对抗训练不同,这种方法不需要任何特殊训练,也不需要事先了解特定的攻击类型,具有显著的便捷性和通用性。

然而,这种方法也并非在所有场景中都能发挥理想效果。例如,在涉及策略模糊性或者可被利用漏洞的环境里,该方法改进是有限的。此外,推理改进的鲁棒性增加可能会被「Think Less」和「Nerd Sniping」等新攻击策略所削弱。
5.「联想思维链」
- 论文标题:CoAT: Chain-of-Associated-Thoughts Framework for Enhancing Large Language Models Reasoning
- 代码地址: https://arxiv.org/pdf/2502.02390
Chain-of-Associated-Thoughts(CoAT)框架是一种用于增强大型语言模型推理能力的新方法,该框架巧妙地将蒙特卡洛树搜索(MCTS)算法与关联记忆机制相结合,通过结构化探索与自适应学习,有效扩展了大型语言模型的搜索空间。

CoAT 框架的核心工作原理如下:
- 蒙特卡洛树搜索(MCTS):MCTS 算法用于结构化探索,帮助模型在决策过程中进行多步骤的推理。
- 关联记忆机制:一种用于集成新的关键信息的动态机制,能够根据上下文和推理过程中的需要,不断更新和补充相关信息,从而增强模型的自适应学习能力。
通过将 MCTS 的结构化探索与关联记忆的动态学习紧密结合,CoAT 显著扩展了大型语言模型的搜索空间,提升了其在复杂推理任务中的表现。
6.「自我回溯以促进推理」
- 论文标题:Step Back to Leap Forward: Self-Backtracking for Boosting Reasoning of Language Models
- 代码地址: https://www.arxiv.org/pdf/2502.04404
来自南京大学的研究团队提出了一种通过自我回溯(self-back tracking)来提升语言模型推理能力的方法,这种方法的核心思想是让语言模型在解决具体问题时,先从宏观角度进行抽象,然后再回到细节层面进行具体推理。

该方法包含两个主要步骤:
- 抽象阶段:模型首先被要求回答一个更一般的问题,这个问题是对原始具体问题的抽象。
- 推理阶段:基于抽象阶段得到的一般结论,模型再回到具体问题上进行推理,从而得出最终的答案。
实验结果显示,在 STEM(科学、技术、工程和数学)问题、知识问答以及多跳推理任务等场景中,这种自我回溯方法的效果显著优于传统的思维链(CoT)方法。
7.「基于深度循环隐空间推理」
- 论文标题:Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
- 代码地址: https://arxiv.org/pdf/2502.05171
在提升模型推理能力的探索中,研究人员并未遵循生成更多 token 以改进推理的常规思路,而是提出了一个通过在潜在空间中迭代循环深度块来扩展推理时间计算的模型。这个深度块的功能类似于 RNN 中的隐藏状态,它允许模型改进其推理而不需要更长的 token 输出。

研究团队还进一步将一个概念验证模型进行了扩展,使其具备 35 亿参数和 8000 亿 token。在推理基准测试中,该扩展后的模型展现出了显著的性能提升,部分情况下其计算负载效果甚至可与拥有 500 亿参数的模型相媲美。
不过,一个关键短板在于该模型缺少清晰明确的推理步骤。对于用户和研究人员而言,清晰的推理步骤能够极大地提升模型的人类可解释性。而这恰恰是思维链方法的一项主要优势所在。
8.「1B LLM 可以超越 405B LLM 吗?」
- 论文标题:Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling
- 代码地址: https://arxiv.org/pdf/2502.06703
在提升大型语言模型(LLM)推理能力的相关研究中,许多推理时间扩展技术依赖于采样,这需要过程奖励模型 (PRM) 来选择最佳解决方案。这篇研究成果就对推理时间计算扩展与 PRM、问题难度之间的相互作用展开了系统分析。

研究人员开发了一种计算优化扩展策略,该策略可适应 PRM、策略模型和任务复杂性的选择。实验结果表明,通过正确的推理时间扩展方法,1B 参数模型可以胜过缺乏推理时间扩展的 405B Llama 3 模型。
同样地,研究还展示了配备推理时间扩展技术的 7B 模型不仅能够超越 DeepSeek-R1,还能保持更高的效率。这些发现凸显了推理时间扩展对于大语言模型(LLM)性能提升的显著作用,其中具有正确推理计算预算的小型 LLM 可以胜过更大的模型。
9.「重新思考计算最优测试时间扩展」
- 论文标题:Learning to Reason from Feedback at Test-Time
- 代码地址: https://arxiv.org/pdf/2502.15771
区别于前几种成果的思路,该研究的核心在于通过推理时动态调整大语言模型(LLM)的权重参数,使其能够从错误中学习,而无需将失败的尝试存储在提示(prompt)中,从而避免了高昂的成本。与传统的通过将先前的尝试添加到上下文中进行顺序修正或盲目生成新答案的并行采样不同,该方法在推理时直接更新模型的权重。

为实现这一目标,研究者提出了 OpTune,这是一种小型、可训练的优化器,能够根据模型在先前尝试中犯的错误更新模型的权重。这意味着模型会记住它做错了什么,而无需在提示 / 上下文中保留错误的答案。这种方法不仅提高了模型的自我修正能力,还显著降低了推理过程中的计算和存储开销。
10.「推理时间计算在大型语言模型(LLM)推理和规划中的应用」
- 论文标题:Inference-Time Computations for LLM Reasoning and Planning: A Benchmark and Insights
- 代码地址: https://www.arxiv.org/pdf/2502.12521
针对推理和规划任务的各种推理时间计算扩展技术进行了基准测试,该文章重点分析了它们在计算成本和性能之间的权衡。

在具体的实验里,研究人员评估了多种技术,例如思维链、思维树和推理规划,涉及算术、逻辑、常识、算法推理和规划等 11 个任务,细致地覆盖了多个领域的推理和规划场景。
实验结果表明,虽然扩展推理时间计算可以改善推理,但没有一种技术在所有任务中始终优于其他技术。这也侧面说明了目前在不同的推理和规划任务中,还需要根据具体情况灵活选择合适的推理时间计算扩展技术,以在计算成本和性能之间找到最佳平衡。
11.「内部思维 Transformer」
- 论文标题:Inner Thinking Transformer: Leveraging Dynamic Depth Scaling to Foster Adaptive Internal Thinking
- 代码地址: https://arxiv.org/pdf/2502.13842
面对需要处理复杂推理的关键 token 时,大型语言模型(LLM)在参数约束下会出现固有的性能瓶颈。针对这个问题,内部思维 Transformer (The Inner Thinking Transformer,ITT) 的解决思路是在推理过程中动态分配更多计算资源。

具体而言,ITT 通过自适应路由 token(Adaptive Token Routing)动态分配计算资源,通过残差思考连接迭代地优化表征,让这些困难的 token 多次通过同一层进行额外处理,从而使得 ITT 能够在不增加参数的情况下对关键的 token 进行更深入的处理。
12.「突破性框架 S*」
- 论文标题:Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
- 代码地址: https://arxiv.org/pdf/2408.03314
传统的代码生成模型往往依赖于更大的参数量来提升性能。但是,新提出的 S * 框架通过一种巧妙的方式,让小模型也能发挥出大模型的实力。这个框架主要包含两个关键创新:
- 混合扩展策略:结合了并行采样和顺序调试,大幅提升了代码生成的覆盖率
- 自适应选择机制:通过智能生成测试用例来区分不同的代码方案,并通过实际执行结果来选择最佳答案

S* 是一个两阶段混合测试时缩放框架,由生成和选择阶段组成,如下图所示。它通过迭代调试扩展并行采样与顺序采样以提高覆盖率,并在选择过程中采用自适应输入合成来增强选择准确性,在整个过程中利用执行结果。不同阶段的效果示例可以在下图中找到。

- 阶段 1 :在生成阶段,模型 S* 生成多个代码解决方案,并使用问题提示词中提供的执行结果和测试用例迭代细化它们。(1) 模型生成多个候选解决方案。(2) 每个解决方案都在公共测试用例(预定义的输入输出对)上执行。(3) 如果解决方案失败(输出不正确或崩溃),模型会分析执行结果(错误、输出)并修改代码以改进它。(4) 此改进过程不断迭代,直到模型找到通过测试用例的解决方案。
- 阶段 2:在选择阶段,S* 在生成 N 个候选解决方案后,下一步是识别最佳解决方案。(1) 模型比较两个都通过公开测试的解决方案。(2) 生成的测试用例,它使用合成的测试用例来指导选择。(3) 将新的测试输入并在其上运行两个解决方案。(4) 如果一个解决方案产生正确的输出而另一个失败,则模型会选择更好的解决方案。(5) 如果两种解决方案的表现相同,模型将随机选择其中一个。

S* 框架的效果非常不错,其在模型性能提升方面展现了显著优势:
- 小模型逆袭:在 S* 框架加持下,Qwen2.5-7B 模型的性能表现超越其原生 Qwen2.5-32B 版本,实现了 10.7% 的性能跃升,充分展现了小模型在优化框架下的巨大潜力。
- 性能突破:GPT-4o-mini 模型在集成 S* 框架后,性能表现超越了 o1-preview 版本,提升幅度达到 3.7%,成功突破了原有性能天花板。
- 顶尖追平:通过 S 框架的优化,DeepSeek-R1-Distill-Qwen-32B 模型的性能达到 85.7%,与当前业界领先的 o1-high 模型(88.5%)仅相差 2.8 个百分点,展现出极强的竞争力。
这些成果充分证明了 S * 框架在模型性能优化方面的卓越能力,为 AI 模型的发展开辟了新的可能性。
13.「草稿链 Chain of Draft」
- 论文标题:Chain of Draft: Thinking Faster by Writing Less
- 代码地址: https://arxiv.org/pdf/2502.18600
研究人员观察到,思维链 (CoT) 之类的技术在大语言模型 (LLM) 推理任务上通常会生成冗长的分步解释,但人类通常依赖于仅捕获基本信息的简洁草稿。
受此启发,他们提出了 Chain of Draft (CoD),这是一种通过生成最少但信息丰富的中间步骤来减少冗长的提示策略。因此从本质上讲,它是一种推理时间扩展方法,通过生成更少的 token 来提高推理时间扩展的效率。

实验结果表明,CoD 的提示长度几乎与标准提示相当,但其准确性却与思维链(CoT)提示不相上下。推理模型的一大优势在于用户可以通过阅读推理过程来学习并更好地评估和信任模型的响应。虽然 CoD 在一定程度上削弱了这一优势,但它在无需冗长中间步骤的场景中展现出巨大潜力 —— 它不仅能够显著加快生成速度,还能保持 CoT 的准确性。因此 CoD 为高效推理提供了一种更具实用性的解决方案。
详见报道《全新 CoD 颠覆推理范式,准确率接近但 token 消耗成倍降低》。
14.「更好的反馈和编辑模型 Better Feedback and Edit Models」
- 论文标题:Dedicated Feedback and Edit Models Empower Inference-Time Scaling for Open-Ended General-Domain Tasks
- 代码地址: https://arxiv.org/pdf/2503.04378
许多扩展推理时间推理的技术依赖于具有可验证答案的任务(如可以检查的数学和代码),这使得它们很难应用于写作和一般问题解决等开放式任务。
为了解决可验证答案的这种限制,研究人员开发了一个系统,其中一个模型生成初始响应,另一个模型提供反馈「反馈模型」,第三个模型根据该反馈改进响应「编辑模型」。

为了确保这些模型的有效性,研究人员使用大量人工注释的响应和反馈数据集来训练这些专门的 “反馈” 和 “编辑” 模型。然后,这些模型通过在推理时间内生成更好的反馈和进行更有效的编辑来帮助改进响应。
总结
可以看到,现有的许多推理模型技术包括简单的基于 token 的干预措施到复杂的基于搜索和优化策略,它们的核心目标是增加推理计算量,甚至可以让相对较小的模型实现显著的改进。这表明推理策略可以帮助缩小较小、更具成本效益的模型与较大模型之间的性能差距。
成本警告
尽管推理时间扩展能够显著提升模型性能,但其带来的推理成本增加是一个不容忽视的问题。因此,在实际应用中,开发者需要在「使用具备大量推理扩展的小模型」与「训练更大模型但减少或不进行推理扩展」之间进行权衡。这种权衡必须基于数学计算,并结合模型的实际使用量来评估。
举例来说,使用重度推理时间缩放的 o1 模型实际上仍然比可能不使用推理时间缩放的更大的 GPT-4.5 模型稍微便宜一些。

然而,推理时间扩展并非万能之策。尽管像蒙特卡罗树搜索、自我回溯和动态深度缩放等技术,虽能显著提升推理性能,但效果仍取决于具体任务及其难度。正如早期一篇论文所指出的,没有哪种推理时计算扩展技术能在所有任务中都表现最佳。
此外,许多此类方法为提升推理能力而牺牲了响应延迟,而较慢的响应延迟可能会影响用户体验,甚至让部分用户感到厌烦。
展望未来
基于上述研究成果,未来大家可能将看到更多「围绕通过推理时间计算扩展进行推理」研究的两个主要分支的论文:
- 纯粹以开发超越基准的最佳模型为中心的研究。
- 关注在不同推理任务之间平衡成本和性能权衡的研究。
推理时计算扩展的优势在于,它可以应用于任何现有的大语言模型,使其在特定任务上表现得更为出色。
在 DeepSeek R1 发布之后,行业出现了一个引人注目的趋势,即「按需思考」。各家公司纷纷竞相为其产品增添推理功能,以提升模型在复杂任务中的表现。
作者表示:还有一个值得关注的发展动态,大多数大语言模型(LLM)提供商开始为用户提供启用或禁用「思考」功能的选项。目前该机制并未公开,不过它可能与具备回拨推理时间计算扩展的是同一模型。
总体而言,无论是借助推理时间计算扩展,还是训练时间计算扩展来添加推理能力,这一趋势都是 2025 年大语言模型发展向前迈出的重要一步。
最后,可以预计随着时间的推移推理将不再被视作可选或特殊的功能,而是会成为一种标准配置,就如同如今指令微调或基于人类反馈的强化学习(RLHF)调整模型已成为原始预训练模型的常规操作一样。
#掌握线性状态空间:从零构建一个Mamba神经网络架构
本文提供了从零开始构建 Mamba 的全部代码过程,作者将Mamba算法模型从理论转化为具体实践。这一探索过程不仅可以巩固对 Mamba 内部工作原理的理解,而且还展示了新颖算法模型架构的实际设计步骤。
在深度学习领域,序列建模仍然是一项具有挑战性的任务,通常由 LSTM 和 Transformers 等模型来解决。然而,这些模型的计算量很大,因此在实际应用场景中,这些模型方法仍存在巨大的缺陷。而Mamba 是一个线性时间序列建模框架,其旨在提高序列建模的效率和有效性。本文将深入探讨使用 PyTorch 实现 Mamba 的过程,解码这一创新方法背后的技术问题和代码。
1.1 Transformer:
Transformer因其注意机制而闻名。借助于Transformer操作特性,特征序列中的任何部分都可以与其他部分进行动态交互,尤其是因果注意力特征,能够很好的捕获因果特征的信息。因此,Transformer能够处理好序列中的每一个元素,相应的,Transformer的计算代价和内存成本也都很高,与序列长度(L²)的平方成正比。
1.2 递归神经网络(RNN):
RNN 是按照序列顺序更新隐藏状态,它只考虑当前输入特征和上一个隐藏状态信息。这种方法允许它们以恒定的内存成本处理无限长的序列。然而,RNN 的简单性也变相的成为一个缺点,即限制了其记忆长期依赖关系的能力。此外,尽管有 LSTM 这样的创新,RNN 中的时间反向传播(BPTT)机制可能会占用大量内存,并可能出现梯度消失或爆炸的问题。
1.3.状态空间模型(S4):
状态空间模型具有良好的特性。它们提供了一种计算代价和内存成本的平衡,比 RNNs 更有效地捕捉长程依赖性,同时比 Transformers 更节省内存。
▲图1|序列建模网络架构发展
1.4.Mamba架构的方法思路:
●选择性状态空间:Mamba 以状态空间模型的概念为基础,引入了一种新的模型架构设计思路。它利用选择性状态空间,能更高效、更有效地捕捉长序列中的相关信息。
●线性时间复杂性:与Transformers不同,Mamba的运行时间与序列长度成线性关系。这一特性使其特别适用于超长序列的任务,而传统的模型在这方面会很吃力。
▲图2|Mamba引入选择性状态空间
Mamba 通过其 "选择性状态空间"(Selective State Spaces)的概念,为传统的状态空间模型引入了一个新颖的架构。这种方法稍微放宽了标准状态空间模型的僵化状态转换,使其更具适应性和灵活性,有点类似于 LSTM。不过,Mamba 保留了状态空间模型的高效计算特性,使其能够一次性完成整个序列的前向传递。
2.1导入必须的库文件
在简单介绍完Mamba架构之后,为大家带来Mamba的代码实现过程,首先导入必须的库。
# PyTorch相关的库
import torchimport torch.nn as nn
import torch.optim as optim
from torch.utils.data
import DataLoader, Dataset
from torch.nn
import functional as Ffrom einops
import rearrangefrom tqdm
import tqdm
# 系统相关的库
import mathimport os
import urllib.request
from zipfile import ZipFile
from transformers
import AutoTokenizer
torch.autograd.set_detect_anomaly(True)2.2 设置标识和训练设备
这里主要针对是否使用GPU,以及Mamba的选择设定对应的表示、以及所使用的设备。
# 配置标识和超参数
USE_MAMBA =1
DIFFERENT_H_STATES_RECURRENT_UPDATE_MECHANISM =0
# 设定所用设备
device = torch.device('cuda'if torch.cuda.is_available() else'cpu')2.3 设置初始化超参数
这一小节定义了模型维度(d_model)、状态大小、序列长度和批次大小等超参数。
# 人为定义的超参数
d_model =8
state_size =128 # 状态大小
seq_len =100 # 序列长度
batch_size =256 # 批次大小
last_batch_size =81 # 最后一个批次大小
current_batch_size = batch_size
different_batch_size =False
h_new =None
temp_buffer =None2.4 定义S6模块
S6 模块是 Mamba 架构中的一个复杂组件,它主要由一系列线性变换和离散化过程组成,用于处理输入的特征序列。它在捕捉序列的时间动态特征方面起着至关重要的作用,而时间动态特征是语言建模等序列建模任务的一个关键方面。
# 定义S6模块
class S6(nn.Module):
def__init__(self, seq_len, d_model, state_size, device):
super(S6, self).__init__()
# 一系列线性变换
self.fc1 = nn.Linear(d_model, d_model, device=device)
self.fc2 = nn.Linear(d_model, state_size, device=device)
self.fc3 = nn.Linear(d_model, state_size, device=device)
# 设定一些超参数
self.seq_len = seq_len
self.d_model = d_model
self.state_size = state_size self.A = nn.Parameter(F.normalize(torch.ones(d_model, state_size, device=device), p=2, dim=-1))
# 参数初始化
nn.init.xavier_uniform_(self.A)
self.B = torch.zeros(batch_size, self.seq_len, self.state_size, device=device)
self.C = torch.zeros(batch_size, self.seq_len, self.state_size, device=device)
self.delta = torch.zeros(batch_size, self.seq_len, self.d_model, device=device)
self.dA = torch.zeros(batch_size, self.seq_len, self.d_model, self.state_size, device=device)
self.dB = torch.zeros(batch_size, self.seq_len, self.d_model, self.state_size, device=device)
# 定义内部参数h和y
self.h = torch.zeros(batch_size, self.seq_len, self.d_model, self.state_size, device=device)
self.y = torch.zeros(batch_size, self.seq_len, self.d_model, device=device)
# 离散化函数
def discretization(self):
# 离散化函数定义介绍在Mamba论文中的28页 self.dB = torch.einsum("bld,bln->bldn", self.delta, self.B)
#dA = torch.matrix_exp(A * delta) # matrix_exp() only supports square matrix
self.dA = torch.exp(torch.einsum("bld,dn->bldn", self.delta, self.A)) #print(f"self.dA.shape = {self.dA.shape}") #print(f"self.dA.requires_grad = {self.dA.requires_grad}")
returnself.dA, self.dB
# 前行传播
def forward(self, x):
# 参考Mamba论文中算法2
self.B =self.fc2(x)
self.C =self.fc3(x)
self.delta = F.softplus(self.fc1(x))
# 离散化
self.discretization()
ifDIFFERENT_H_STATES_RECURRENT_UPDATE_MECHANISM:
# 如果不使用'h_new',将触发本地允许错误
global current_batch_size
current_batch_size = x.shape[0]
ifself.h.shape[0] != current_batch_size
different_batch_size =True
# 缩放h的维度匹配当前的批次
h_new = torch.einsum('bldn,bldn->bldn', self.dA, self.h[:current_batch_size, ...]) + rearrange(x, "b l d -> b l d 1") *self.dB
else:
different_batch_size =False
h_new = torch.einsum('bldn,bldn->bldn', self.dA, self.h) + rearrange(x, "b l d -> b l d 1") *self.dB
# 改变y的维度
self.y = torch.einsum('bln,bldn->bld', self.C, h_new)
# 基于h_new更新h的信息
global temp_buffer
temp_buffer = h_new.detach().clone() ifnotself.h.requires_grad else h_new.clone()
returnself.y
else:
# 将会触发错误
# 设置h的维度
h = torch.zeros(x.size(0), self.seq_len, self.d_model, self.state_size, device=x.device)
y = torch.zeros_like(x)
h = torch.einsum('bldn,bldn->bldn', self.dA, h) + rearrange(x, "b l d -> b l d 1") *self.dB
# 设置y的维度
y = torch.einsum('bln,bldn->bld', self.C, h)
return yS6 模块继承于 nn.Module,是 Mamba 算法模型的关键部分,负责处理离散化过程和前向传播。
2.5 定义MambaBlock模块
MambaBlock 模块是一个定制的神经网络模块,是 Mamba 模型的关键部件,它封装了处理输入数据的多个网络层和操作函数。MambaBlock 模块代表一个复杂的神经网络模块,包括线性投影、卷积、激活函数、自定义 S6 模块和残差连接。该模块是 Mamba 模型的基本组成部分,通过一系列转换处理输入序列,以捕捉数据中的相关模式和特征。这些不同网络层和操作函数的组合使 MambaBlock 能够有效处理复杂的序列建模任务。
# 定义MambaBlock模块
class MambaBlock(nn.Module):
def__init__(self, seq_len, d_model, state_size, device):
super(MambaBlock, self).__init__()
self.inp_proj = nn.Linear(d_model, 2*d_model, device=device)
self.out_proj = nn.Linear(2*d_model, d_model, device=device)
# 残差连接
self.D = nn.Linear(d_model, 2*d_model, device=device)
# 设置偏差属性
self.out_proj.bias._no_weight_decay =True
# 初始化偏差
nn.init.constant_(self.out_proj.bias, 1.0)
# 初始化S6模块
self.S6 = S6(seq_len, 2*d_model, state_size, device)
# 添加1D卷积
self.conv = nn.Conv1d(seq_len, seq_len, kernel_size=3, padding=1, device=device)
# 添加线性层
self.conv_linear = nn.Linear(2*d_model, 2*d_model, device=device)
# 正则化
self.norm = RMSNorm(d_model, device=device)
# 前向传播
def forward(self, x):
# 参考Mamba论文中的图3
x =self.norm(x)
x_proj =self.inp_proj(x)
# 1D卷积操作
x_conv =self.conv(x_proj)
x_conv_act = F.silu(x_conv) # Swish激活
# 线性操作
x_conv_out =self.conv_linear(x_conv_act)
# S6模块操作
x_ssm =self.S6(x_conv_out)
x_act = F.silu(x_ssm) # Swish激活
# 残差连接
x_residual = F.silu(self.D(x))
x_combined = x_act * x_residual
x_out =self.out_proj(x_combined)
return x_outMambaBlock 模块是另一个封装了 Mamba 核心功能的模块,包括输入投影、一维卷积和 S6 模块。
2.6 定义Mamba模型
Mamba 类代表 Mamba 模型的整体架构,由一系列 MambaBlock 模块组成。每个模块负责处理输入的序列数据,一个模块的输出作为下一个模块的输入。这种顺序处理使模型能够捕捉输入数据中的复杂模式和关系,从而有效地完成顺序建模的任务。多个模块的堆叠是深度学习架构中常见的设计,因为它能让模型学习数据的分层表示特征。
# 定义Mamba模型
class Mamba(nn.Module):
def__init__(self, seq_len, d_model, state_size, device):
super(Mamba, self).__init__()
self.mamba_block1 = MambaBlock(seq_len, d_model, state_size, device)
self.mamba_block2 = MambaBlock(seq_len, d_model, state_size, device)
self.mamba_block3 = MambaBlock(seq_len, d_model, state_size, device)
def forward(self, x):
x =self.mamba_block1(x)
x =self.mamba_block2(x)
x =self.mamba_block3(x)
return x该类定义了整个 Mamba 模型,将多个 MambaBlock 模块链接在一起,构成整体算法模型的架构。
2.7 定义RMSNorm模块
RMSNorm 模块是一个自定义的归一化层,继承了 PyTorch 的 nn.Module。该层用于对神经网络的激活值进行归一化操作,这有助于加快训练速度。
class RMSNorm(nn.Module):
def__init__(self,
d_model: int,
eps: float=1e-5,
device: str='cuda'):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(d_model, device=device))
def forward(self, x):
output = x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) +self.eps) *self.weight
return outputRMSNorm 模块是用于归一化的均方根网络层,是神经网络架构中的一种常用技术。
本节介绍如何在简单的数据样本上实例化和使用 Mamba 算法模型。
# 创建模拟数据
x = torch.rand(batch_size, seq_len, d_model, device=device)
# 创建Mambda算法模型
mamba = Mamba(seq_len, d_model, state_size, device)
# 定义rmsnorm模块
norm = RMSNorm(d_model)
x = norm(x)
# 前向传播
test_output = mamba(x)
print(f"test_output.shape = {test_output.shape}")3.1数据准备和训练函数
Enwiki8Dataset 类是一个自定义数据集处理程序,它继承自 PyTorch 的 Dataset 类,专门用于为序列建模任务(如语言建模)而构建的数据集。
# 定义填充函数
def pad_sequences_3d(sequences, max_len=None, pad_value=0):
# 获得张量的维度大小
batch_size, seq_len, feature_size = sequences.shape
if max_len isNone:
max_len = seq_len +1
# 初始化 padded_sequences
padded_sequences = torch.full((batch_size, max_len, feature_size), fill_value=pad_value, dtype=sequences.dtype, device=sequences.device)
# 填充每个序列
padded_sequences[:, :seq_len, :] = sequences
return padded_sequencestrain 函数用于训练 Mamba 算法模型。
def train(model, tokenizer, data_loader, optimizer, criterion, device, max_grad_norm=1.0, DEBUGGING_IS_ON=False):
●model(模型):要训练的神经网络模型(本例中为 Mamba);
●tokenizer:处理输入数据的标记符;
●data_loader:数据加载器,一个可迭代器,用于为训练提供成批数据;
●optimizer: 优化器:用于更新模型权重的优化算法;
●criterion:用于评估模型性能的损失函数;
●设备:模型运行的设备(CPU 或 GPU);
●max_grad_norm:用于梯度剪切的值,以防止梯度爆炸;
●DEBUGGING_IS_ON:启用调试信息的标志。
# 定义train函数def train(model, tokenizer, data_loader, optimizer, criterion, device, max_grad_norm=1.0, DEBUGGING_IS_ON=False):
model.train()
total_loss =0
for batch in data_loader:
optimizer.zero_grad()
input_data = batch['input_ids'].clone().to(device)
attention_mask = batch['attention_mask'].clone().to(device)
# 获取输入数据和标签
target = input_data[:, 1:]
input_data = input_data[:, :-1]
# 填充序列数据
input_data = pad_sequences_3d(input_data, pad_value=tokenizer.pad_token_id)
target = pad_sequences_3d(target, max_len=input_data.size(1), pad_value=tokenizer.pad_token_id)
if USE_MAMBA:
output = model(input_data)
loss = criterion(output, target)
loss.backward(retain_graph=True)
# 裁剪梯度
for name, param in model.named_parameters():
if'out_proj.bias'notin name:
# 裁剪梯度函数操作
torch.nn.utils.clip_grad_norm_(param, max_norm=max_grad_norm)
if DEBUGGING_IS_ON:
for name, parameter in model.named_parameters():
if parameter.grad isnotNone:
print(f"{name} gradient: {parameter.grad.data.norm(2)}")
else:
print(f"{name} has no gradient")
if USE_MAMBA and DIFFERENT_H_STATES_RECURRENT_UPDATE_MECHANISM:
model.S6.h[:current_batch_size, ...].copy_(temp_buffer)
optimizer.step()
total_loss += loss.item()
return total_loss /len(data_loader)3.2 模型训练循环
# 输入预训练模型权重
encoded_inputs_file ='encoded_inputs_mamba.pt'
if os.path.exists(encoded_inputs_file):
print("Loading pre-tokenized data...")
encoded_inputs = torch.load(encoded_inputs_file)
else:
print("Tokenizing raw data...")
enwiki8_data = load_enwiki8_dataset()
encoded_inputs, attention_mask = encode_dataset(tokenizer, enwiki8_data)
torch.save(encoded_inputs, encoded_inputs_file)
print(f"finished tokenizing data")
# 组合数据data = {
'input_ids': encoded_inputs,
'attention_mask': attention_mask
}
# 分割训练和验证集total_size =len(data['input_ids'])
train_size =int(total_size *0.8)
train_data = {key: val[:train_size] for key, val in data.items()}
val_data = {key: val[train_size:] for key, val in data.items()}
train_dataset = Enwiki8Dataset(train_data)
val_dataset = Enwiki8Dataset(val_data)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
# 初始化模型
model = Mamba(seq_len, d_model, state_size, device).to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(model.parameters(), lr=5e-6)
# 训练次数
num_epochs =25
for epoch in tqdm(range(num_epochs)):
train_loss = train(model, tokenizer, train_loader, optimizer, criterion, device, max_grad_norm=10.0, DEBUGGING_IS_ON=False)
val_loss = evaluate(model, val_loader, criterion, device)
val_perplexity = calculate_perplexity(val_loss)
print(f'Epoch: {epoch+1}, Training Loss: {train_loss:.4f}, Validation Loss: {val_loss:.4f}, Validation Perplexity: {val_perplexity:.4f}')上述代码是建立和训练 Mamba 模型的详细示例过程,包括数据集的组合和划分,模型的定义和初始化,以及损失函数和优化器的定义,最后则是设定训练循环的次数。
本文提供了从零开始构建 Mamba 的全部代码过程,读者们可以借助本文的讲解和代码,将Mamba算法模型从理论转化为具体实践。这一探索过程不仅可以巩固对 Mamba 内部工作原理的理解,而且还展示了新颖算法模型架构的实际设计步骤。通过这种实践方法,笔者发现了序列建模的细微差别以及 Mamba 在这一领域引入的效率。有了这些知识,笔者现在就可以在自己的项目中更好地尝试使用 Mamba,或更深入地开发新型的AI模型。
参考:
【1】https://arxiv.org/abs/2312.00752
【2】https://github.com/state-spaces/mamba
【3】https://pytorch.org/tutorials/beginner/basics/data_tutorial.html
【4】https://huggingface.co/datasets/enwik8
#再读Qwen2.5 Technical Report
背景:最近DeepSeek-R1的风头正劲,而其实目前主流的被蒸馏基座模型仍然是Qwen。因此今天还是花点时间回顾一下Qwen2.5的模型,也许在不久的未来就有Qwen的推理模型就会出炉。
其实很多策略是通用的。
Qwen2.5核心优化点:
Qwen 2.5 在预训练和训练后阶段都有显著改进。
在预训练方面,将高质量预训练数据集从之前的 7 万亿词元扩展到 18 万亿词元,这为常识、专业知识和推理能力奠定了坚实基础。
在训练后阶段,我们实施了包含超过 100 万个样本的精细监督微调,以及包括离线学习直接偏好优化(DPO)和在线学习组相对策略优化(GRPO)在内的多阶段强化学习。
预训练部分:
我们的语言模型预训练过程包含几个关键部分。首先,我们通过复杂的筛选和评分机制,精心挑选高质量的训练数据,并进行策略性的数据混合。其次,我们对超参数优化展开广泛研究,以便有效地训练各种规模的模型。最后,我们采用专门的长上下文预训练,来增强模型处理和理解长序列的能力。下面,我们将详细介绍数据准备、超参数选择和长上下文训练的方法。
预训练数据
与前作Qwen2相比,Qwen2.5在预训练数据质量上有显著提升。这些改进源于以下几个关键方面:
- 更优的数据筛选:高质量的预训练数据对模型性能至关重要,因此数据质量评估和筛选是我们流程的关键部分。我们利用Qwen2-Instruct模型作为数据质量筛选器,进行全面的多维分析,以评估训练样本并打分。这种筛选方法相较于我们之前用于Qwen2的方法有了重大改进,因为Qwen2在更大的多语言语料库上进行了扩展预训练,其增强的能力能够实现更细致的质量评估,从而在多种语言中更好地保留高质量训练数据,并更有效地过滤掉低质量样本。
- 更优质的数学和代码数据:在Qwen2.5的预训练阶段,我们纳入了来自Qwen2.5-Math(Yang等人,2024b)和Qwen2.5-Coder(Hui等人,2024)的训练数据。这种数据整合策略非常有效,因为这些专业数据集对于在数学和编码任务中取得领先性能至关重要。通过在预训练中利用这些高质量的领域特定数据集,Qwen2.5继承了强大的数学推理和代码生成能力。
- 更优质的合成数据:为了生成高质量的合成数据,特别是在数学、代码和知识领域,我们利用了Qwen2-72B-Instruct(Yang等人,2024a)和Qwen2Math-72B-Instruct(Qwen团队,2024c)。通过我们专有的通用奖励模型和专门的Qwen2-Math-RM-72B(Qwen团队,2024c)模型进行严格筛选,进一步提高了合成数据的质量。
- 更优的数据混合:为了优化预训练数据的分布,我们使用Qwen2-Instruct模型对不同领域的内容进行分类和平衡。我们的分析显示,电子商务、社交媒体和娱乐等领域在网络规模的数据中占比过高,这些数据通常包含重复、模板化或机器生成的内容。相反,技术、科学和学术研究等领域虽然包含更高质量的信息,但传统上在数据中的占比不足。通过对占比过高的领域进行策略性下采样,以及对高价值领域进行上采样,我们确保了训练数据集更加平衡且信息丰富,能更好地满足模型的学习目标。
基于这些技术,我们开发了一个更大、质量更高的预训练数据集,数据量从Qwen2使用的7万亿词元扩展到了18万亿词元。
超参数的缩放定律:
我们基于Qwen2.5的预训练数据开发了超参数的缩放定律(Hoffmann等人,2022;Kaplan等人,2020)。以往的研究(Dubey等人,2024;Almazrouei等人,2023;Hoffmann等人,2022)主要利用缩放定律在给定计算预算的情况下确定最佳模型规模,而我们利用它们来确定不同模型架构的最佳超参数。具体来说,我们的缩放定律有助于确定关键的训练参数,如不同规模的密集模型和MoE模型的批量大小B和学习率μ。
通过大量实验,我们系统地研究了模型架构与最佳训练超参数之间的关系。具体而言,我们分析了最佳学习率(\mu_{opt})和批量大小(B_{opt})如何随模型规模N和预训练数据大小D变化。我们的实验涵盖了广泛的架构,包括参数规模从4400万到140亿的密集模型,以及激活参数从4400万到10亿的MoE模型,在规模从8亿到600亿词元的数据集上进行训练。利用这些最佳超参数预测,我们将最终损失建模为模型架构和训练数据规模的函数。
此外,我们利用缩放定律预测不同参数数量的MoE模型相对于其密集模型对应版本的性能,并进行比较。该分析为我们的MoE模型超参数配置提供了指导,使我们能够通过仔细调整激活参数和总参数,实现与特定密集模型变体(如Qwen2.5-72B和Qwen2.5-14B)相当的性能。
长上下文预训练:
为了实现最佳训练效率,Qwen2.5采用两阶段预训练方法:初始阶段上下文长度为4096词元,随后是针对更长序列的扩展阶段。遵循Qwen2使用的策略,除了Qwen2.5-Turbo之外,所有模型变体在预训练的最后阶段将上下文长度从4096扩展到32768词元。同时,我们使用ABF技术将RoPE的基础频率从10000提高到1000000。
对于Qwen2.5-Turbo,我们在训练过程中实施渐进式上下文长度扩展策略,分为四个阶段:32768词元、65536词元、131072词元,最终达到262144词元,RoPE基础频率为10000000。在每个阶段,我们精心挑选训练数据,使其包含40%当前最大长度的序列和60%更短的序列。这种渐进式训练方法使模型能够平稳适应不断增加的上下文长度,同时保持对不同长度序列进行有效处理和泛化的能力。
为了增强模型在推理过程中处理更长序列的能力,我们采用了两种关键策略:YARN 和双块注意力机制(DCA)。通过这些创新,我们将序列长度容量提高了四倍,使Qwen2.5-Turbo能够处理多达100万个词元,而其他模型能够处理多达131072个词元。值得注意的是,这些方法不仅通过降低困惑度改进了长序列的建模,还保持了模型在短序列上的强大性能,确保了在不同输入长度下的一致质量。
训练后优化:
与Qwen 2相比,Qwen 2.5在训练后优化设计方面有两项重大改进:(1)扩大监督微调数据覆盖范围:监督微调过程使用了包含数百万高质量示例的大规模数据集。这一扩展专门针对前一版本模型存在局限性的关键领域,如长序列生成、数学问题解决、编码、指令遵循、结构化数据理解、逻辑推理、跨语言迁移以及稳健的系统指令处理。(2)两阶段强化学习:Qwen 2.5中的强化学习(RL)过程分为两个不同阶段:离线强化学习和在线强化学习。
- 离线强化学习:此阶段专注于培养奖励模型难以评估的能力,如推理、事实性和指令遵循能力。通过精心构建和验证训练数据,我们确保离线强化学习信号既易于学习又可靠,使模型能够有效地掌握这些复杂技能。
- 在线强化学习:在线强化学习阶段利用奖励模型检测输出质量细微差异的能力,包括真实性、有用性、简洁性、相关性、无害性和无偏差性。这使模型能够生成精确、连贯且结构良好的回复,同时保持安全性和可读性。因此,模型的输出始终符合人类质量标准和期望。
监督微调
在本节中,我们详细介绍Qwen2.5在监督微调(SFT)阶段的关键改进,重点关注以下几个关键领域:
- 长序列生成:Qwen2.5能够生成高质量内容,输出上下文长度可达8192个词元,这比典型的训练后回复长度(通常低于2000个词元)有了显著提升。为了解决这一差距,我们开发了长回复数据集。我们使用反向翻译技术从预训练语料库中为长文本数据生成查询,施加输出长度约束,并使用Qwen2过滤掉低质量的配对数据。
- 数学能力提升:我们引入了Qwen2.5-Math 的思维链数据,这些数据涵盖了各种查询来源,包括公共数据集、K - 12问题集和合成问题。为确保高质量的推理,我们采用拒绝采样,并结合奖励建模和带注释的答案作为指导,生成逐步的推理过程。
- 编码能力增强:为提升编码能力,我们整合了Qwen2.5-Coder的指令调整数据。我们将多种特定语言的智能体纳入一个协作框架,生成涵盖近40种编程语言的多样化高质量指令对。我们通过从与代码相关的问答网站合成新示例,并从GitHub收集算法代码片段来扩展指令数据集。一个全面的多语言沙箱用于进行静态代码检查,并通过自动化单元测试验证代码片段,确保代码质量和正确性。
- 指令遵循优化:为确保高质量的指令遵循数据,我们实施了一个严格的基于代码的验证框架。在这种方法中,大语言模型同时生成指令和相应的验证代码,以及用于交叉验证的全面单元测试。通过基于执行反馈的拒绝采样,我们精心挑选用于监督微调的训练数据,从而保证模型忠实遵循预期指令。
- 结构化数据理解强化:我们开发了一个全面的结构化理解数据集,涵盖传统任务,如表格问答、事实验证、错误纠正和结构理解,以及涉及结构化和半结构化数据的复杂任务。通过将推理链纳入模型的回复中,我们显著增强了模型从结构化数据中推断信息的能力,从而提高了在这些不同任务上的性能。这种方法不仅拓宽了数据集的范围,还加深了模型从复杂数据结构中进行推理和获取有意义见解的能力。
- 逻辑推理能力强化:为提升模型的逻辑推理能力,我们引入了70000个涵盖各个领域的新查询。这些查询包括选择题、判断题和开放式问题。模型经过训练,系统地处理问题,运用一系列推理方法,如演绎推理、归纳概括、类比推理、因果推理和统计推理。通过迭代优化,我们系统地过滤掉包含错误答案或有缺陷推理过程的数据。这一过程逐步增强了模型逻辑推理的准确性,确保在不同类型的推理任务中都有稳健的表现。
- 跨语言迁移优化:为促进模型通用能力在不同语言间的迁移,我们使用翻译模型将高资源语言的指令转换为各种低资源语言,从而生成相应的候选回复。为确保这些回复的准确性和一致性,我们评估每个多语言回复与其原始版本之间的语义对齐。这一过程保留了原始回复的逻辑结构和风格细节,从而在不同语言间保持其完整性和连贯性。
- 稳健系统指令优化:我们构建了数百个通用系统提示,以提高训练后系统提示的多样性,确保系统提示与对话之间的一致性。使用不同系统提示进行的评估表明,模型保持了良好的性能(Lu等人,2024b)且方差降低,这表明其稳健性得到了提升。
- 回复过滤机制完善:为评估回复的质量,我们采用了多种自动注释方法,包括专门的评判模型和多智能体协作评分系统。回复经过严格评估,只有所有评分系统都认为完美的回复才会被保留。这种全面的方法确保我们的输出保持最高质量标准。
最终,我们构建了一个包含超过100万个监督微调示例的数据集。模型在序列长度为32768个词元的情况下进行两轮微调。为优化学习过程,学习率从(7×10{-6})逐渐降至(7×10{-7})。为解决过拟合问题,我们应用了0.1的权重衰减,并将梯度范数最大限制为1.0。
离线强化学习
与在线强化学习相比,离线强化学习能够预先准备训练信号,这对于存在标准答案但使用奖励模型难以评估的任务特别有利。在本研究中,我们专注于数学、编码、指令遵循和逻辑推理等客观查询领域,在这些领域中获得准确评估可能较为复杂。在前一阶段,我们广泛采用执行反馈和答案匹配等策略来确保回复的质量。在当前阶段,我们复用该流程,使用监督微调模型为一组新查询重新采样回复。通过我们质量检查的回复被用作直接偏好优化(DPO)训练的正例,而未通过的则被视为负例。为进一步提高训练信号的可靠性和准确性,我们同时利用人工和自动审核流程。这种双重方法确保训练数据不仅易于学习,而且符合人类期望。最终,我们构建了一个包含约150000个训练对的数据集。然后,使用在线合并优化器(Lu等人,2024a)对模型进行一轮训练,学习率为(7×10^{-7}) 。
在线强化学习
为了为在线强化学习开发一个强大的奖励模型,我们遵循一套精心定义的标注标准。这些标准确保模型生成的回复不仅质量高,而且符合道德规范和以用户为中心的标准。数据标注的具体准则如下:
- 真实性:回复必须基于事实准确,真实反映提供的上下文和指令。模型应避免生成错误或无数据支持的信息。
- 有用性:模型的输出应真正有用,有效回答用户的查询,同时提供积极、引人入胜、有教育意义且相关的内容。它应严格遵循给定指令,为用户提供价值。
- 简洁性:回复应简洁明了,避免不必要的冗长。目标是以清晰高效的方式传达信息,避免过多细节给用户造成负担。
- 相关性:回复的所有部分都应与用户的查询、对话历史以及助手的上下文直接相关。模型应根据用户的需求和期望调整输出。
- 无害性:模型必须优先保障用户安全,避免任何可能导致非法、不道德或有害行为的内容。它应始终倡导道德行为和负责任的交流。
- 无偏差性:模型应生成无偏差的回复,包括但不限于性别、种族、国籍和政治方面的偏差。它应平等公正地对待所有主题,遵循广泛接受的道德标准。
用于训练奖励模型的查询来自两个不同的数据集:公开可用的开源数据和一个复杂度较高的专有查询集。回复由Qwen模型在不同训练阶段通过不同方法(监督微调、直接偏好优化和强化学习)微调后的检查点生成。为引入多样性,这些回复在不同温度设置下进行采样。偏好对通过人工和自动标注过程创建,直接偏好优化的训练数据也整合到该数据集中。
在我们的在线强化学习框架中,我们采用组相对策略优化(GRPO)。训练奖励模型的查询集与强化学习训练阶段使用的查询集相同。训练过程中查询的处理顺序由奖励模型评估的回复分数方差决定。具体而言,回复分数方差较高的查询被优先处理,以确保更有效的学习。我们为每个查询采样8个回复。所有模型的训练全局批量大小为2048,每个训练片段包含2048个样本,将一对查询和回复视为一个样本。
长上下文微调
为了进一步扩展Qwen2.5-Turbo的上下文长度,我们在训练后优化阶段引入更长的监督微调示例,使其在长查询中更好地符合人类偏好。在监督微调阶段,我们采用两阶段方法。在第一阶段,模型仅使用长度不超过32768个词元的短指令进行微调。此阶段使用与其他Qwen2.5模型相同的数据和训练步骤,确保在短任务上有强大的性能。在第二阶段,微调过程同时使用短指令(长度不超过32768个词元)和长指令(长度不超过262144个词元)。这种混合方法有效增强了模型在长上下文任务中的指令遵循能力,同时保持了在短任务上的性能。
在强化学习阶段,我们对Qwen2.5-Turbo采用与其他Qwen2.5模型类似的训练策略,仅专注于短指令。这种设计选择主要基于两个考虑因素:首先,长上下文任务的强化学习训练计算成本高昂;其次,目前缺乏能够为长上下文任务提供合适奖励信号的奖励模型。此外,我们发现仅对短指令采用强化学习仍可显著提高模型在长上下文任务中与人类偏好的一致性。
实验部分:
xx
#Vibe Agent
Token成本直降90%,会对话就能创造专属本地Agent
刚刚,Local AI 领域的 Libra 团队发布了一段最新技术演示视频,展示了用户通过自然语言交互直接生成 Agent,并利用本地消费级算力支持 Agent 进行长程 (Long-Horizon) 推理,最终完成复杂任务。Libra 构建的本地化、即时响应、自我规划方案为行业开辟了一条全新的长程推理 Agent 技术路径,实现了从手工 Agent 设计向端到端 In-Context Vibe Agent 生成范式演进。

从官网信息来看,Libra 的技术方案直接回应了制约 Agent 技术普及的两大关键瓶颈:一方面,当前热门 Agent 产品如 Cursor、Devin、Manus 等虽功能强大,但运行成本高昂 —— 专业评测显示单次使用 Manus 可消耗约 1000k Token(起步 2 美元)。Libra 基于本地算力优先的架构显著降低了这一成本压力,为高 Token 消耗应用扫除障碍。另一方面,虽然主流 Agent 框架允许自定义开发,但技术门槛限制了普及范围。Libra 通过自然语言直接生成 Vibe Agent 的方式不仅简化了交互流程,更重要的是,这种端到端、无需编程的 Agent 生成范式为满足多元化、大规模的个性化 Agent 应用需求开辟了崭新道路。
让我们先看看 Libra 官网 (greenbit.ai) 发布的具体视频介绍:
,时长01:32
场景展示:Libra 的 Agentic 规划能力
案例一:10 分钟打造即时 DeepResearch 服务
DeepResearch 作为 “模型即产品” 的 AI Agent 代表,用户想要私有化部署、接入内部数据,不仅面临昂贵的 API 调用费率,而且需要进行额外的手工编排设计。在 Libra 的 Vibe Agent 模式下,行业分析师仅需对话反馈,就能持续调教 agent,并构建专业、个性化的本地市场研究代理服务:
- 简单描述需求:"我需要分析过去 5 年各市场电动车销量趋势,用 Python 处理数据、进行统计分析并生成可视化图表。需要按人口标准化销量数据,计算年复合增长率,并预测未来 3 年走势。"

- Libra 智能解析需求,自动生成具备自我规划能力的行动智能体,代理用户进行网页搜索、数据清洗、时序预测、数据分析、可视化等全流程能力

- 分析师评估代理服务的工作效果:完成了包含 15 个市场的实时市场深度分析报告,包括人均渗透率、区域增长率对比、未来预测等多维度分析,整个过程仅消耗约 80K 需要付费的云端 token,相比同等任务在云端 API 服务的调用成本降低了 90%
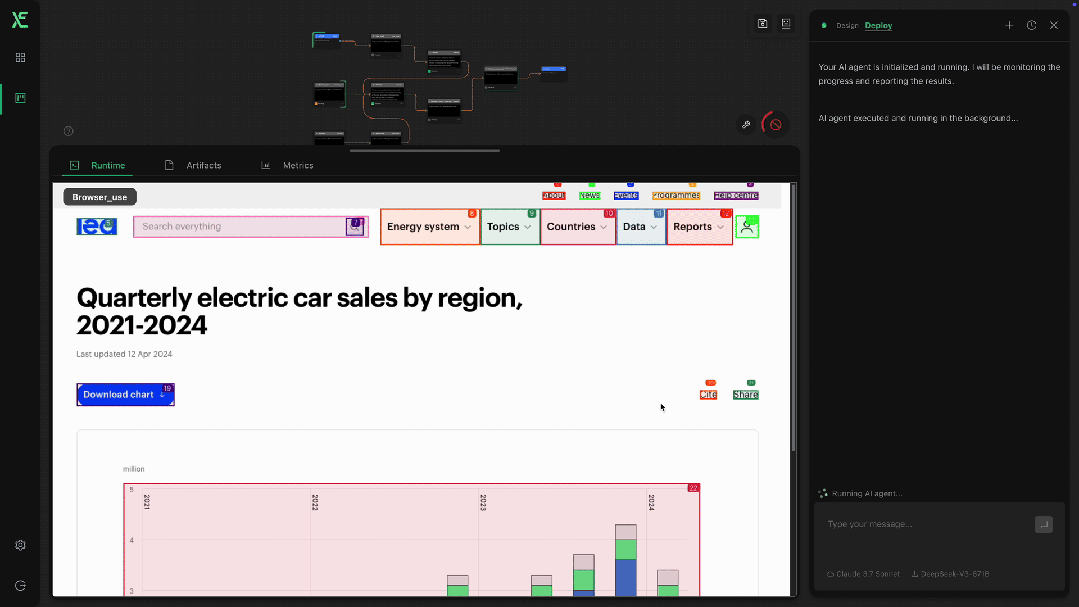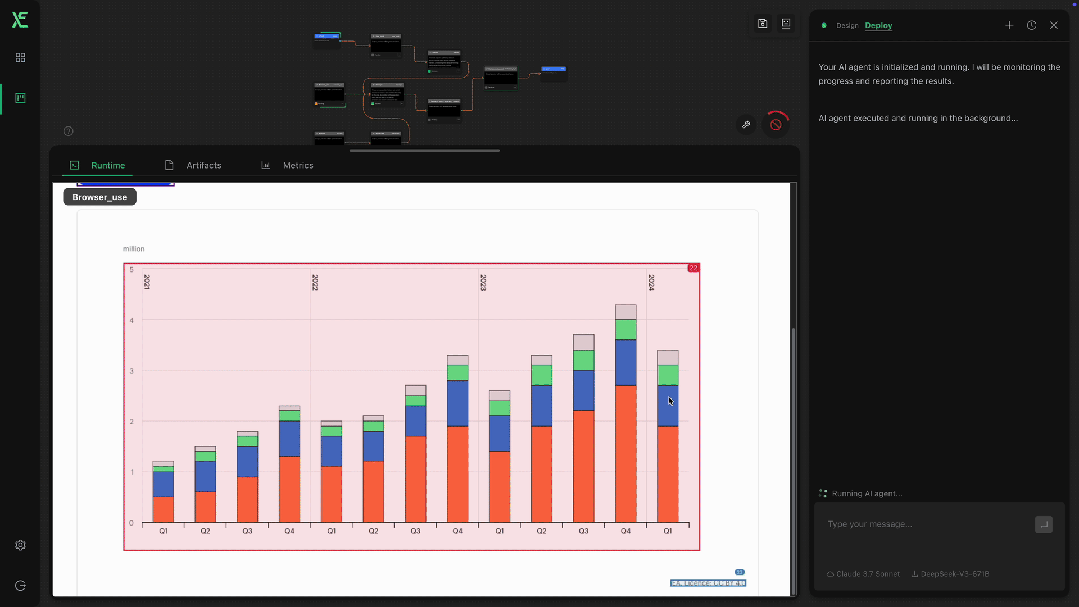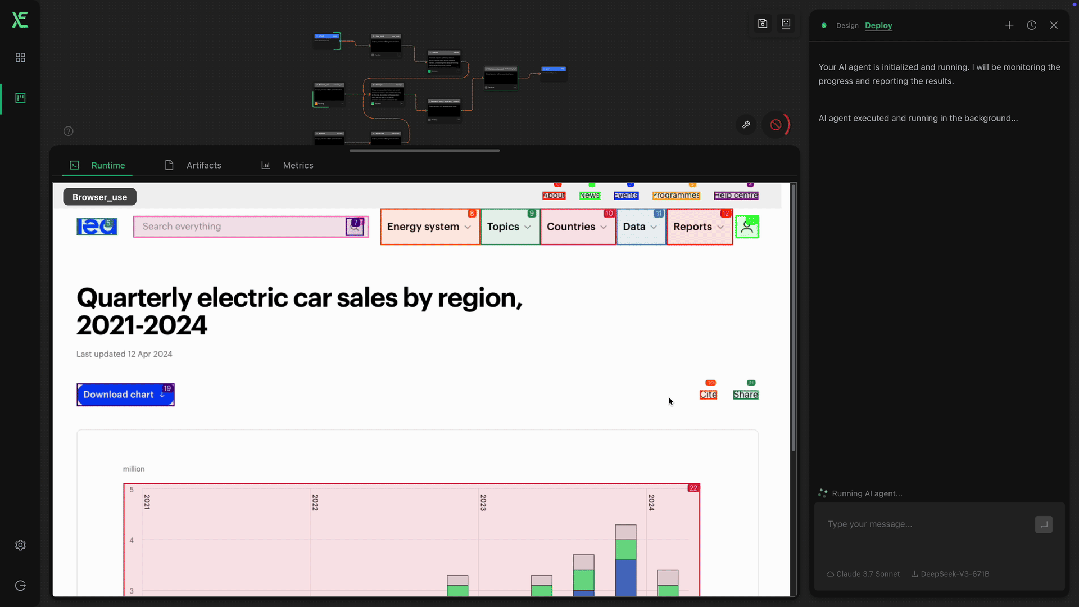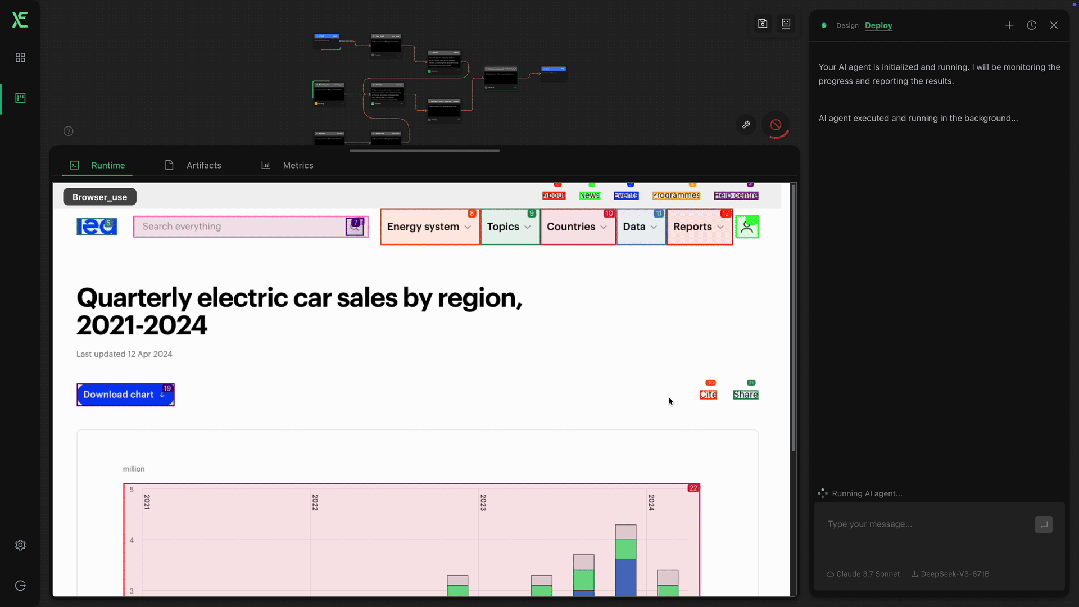
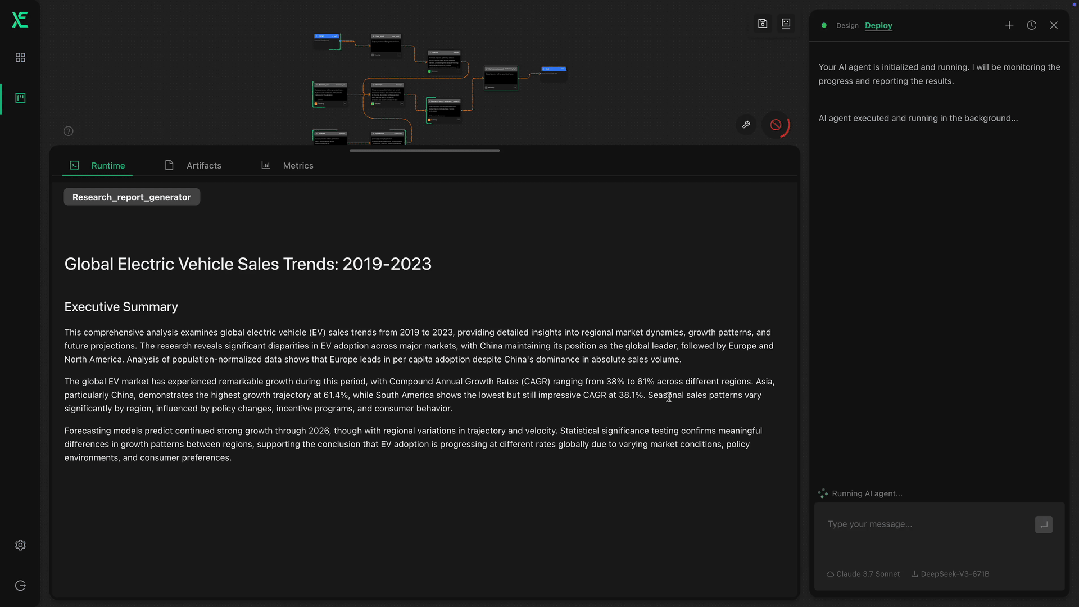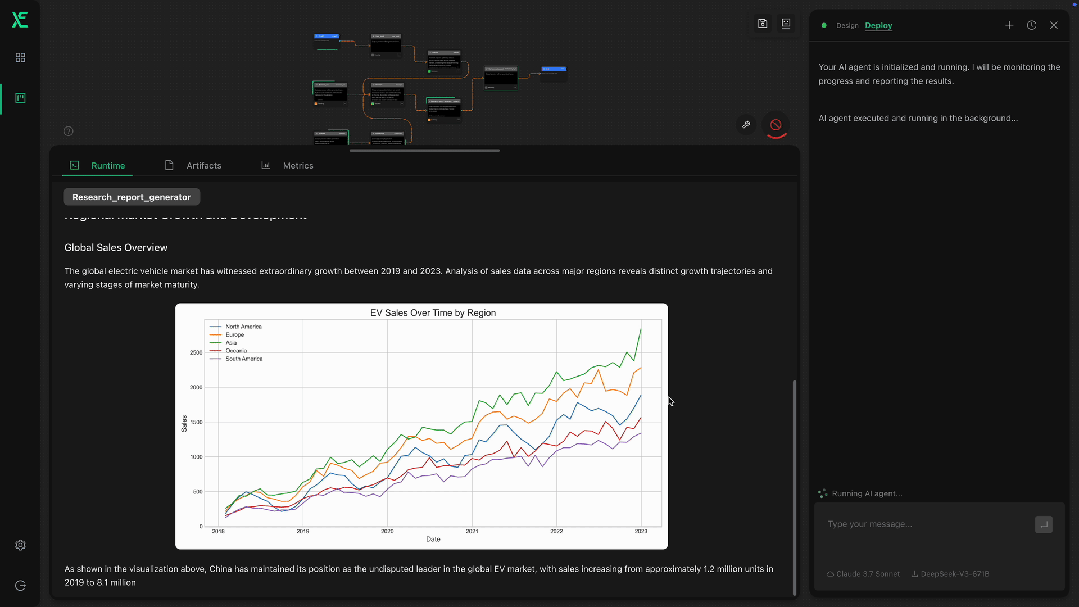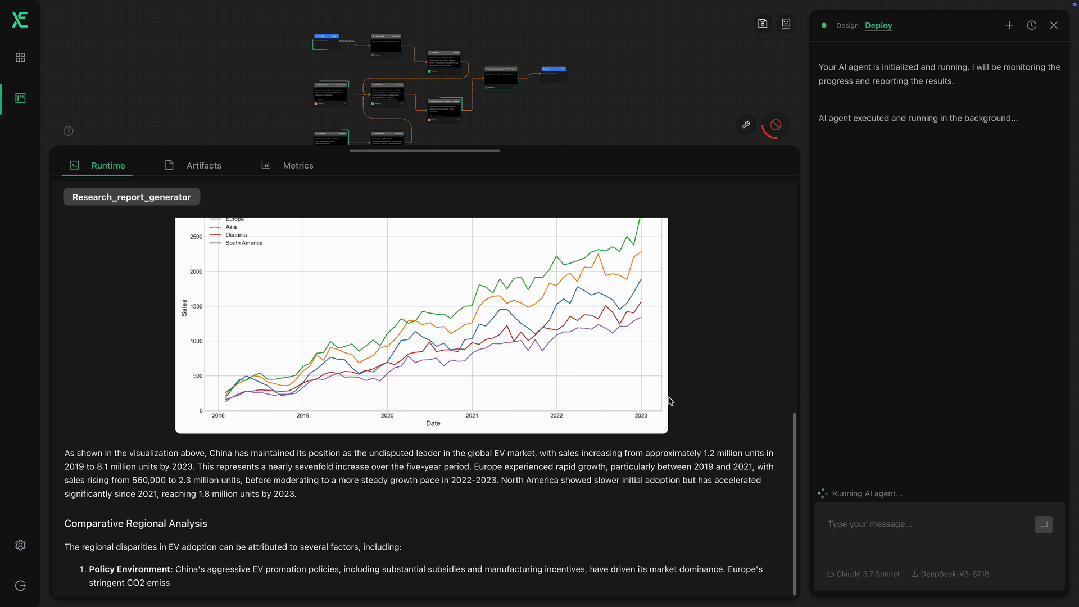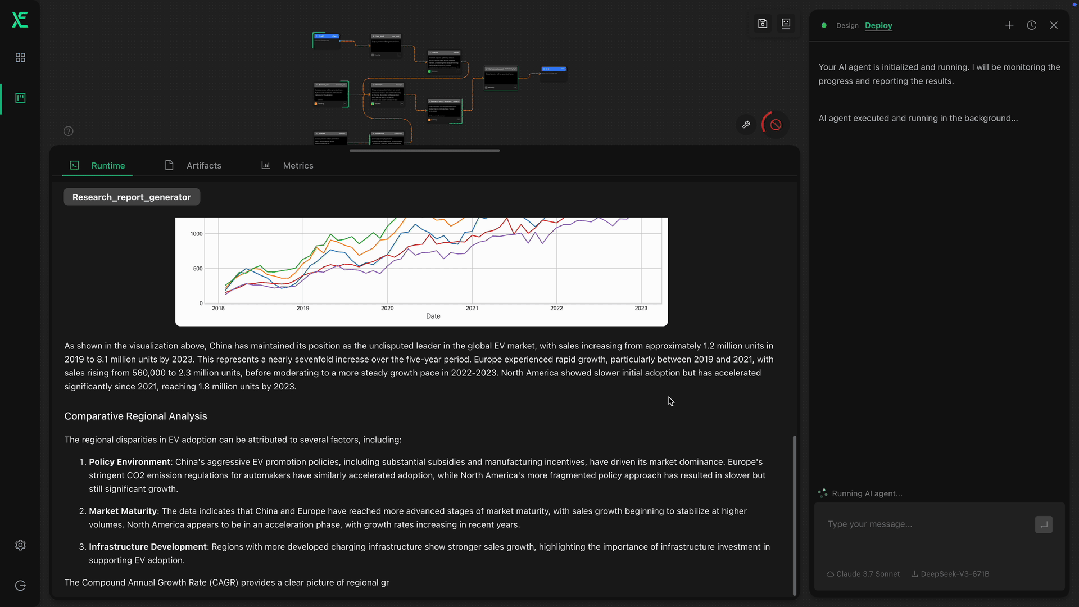
- 持续调教,满意后使用 Libra 一键导出并部署到本地
案例二:一句话调教市场上的最佳 Agent 单品
除此之外,Libra 的对话式 Agent 调教模式能以极快的速度将潮流智能体产品融入用户的场景:
- 个人 IP 孵化器:只需说 "我想根据我的每天 Mac 软件使用记录,用有趣文字连载我的《00 后职场升职记》小说",瞬间拥有专属 "数字史官",让个人品牌打造变得轻松自如。
- Second Me:说一句 "我是一个数码产品内容创作者,模拟我的个人工作流,根据我的要求筛选每日数码科技动态,创建一个关于最新智能手机的微博话题",瞬间获得精准分析和引人入胜的微博内容。为你自主监控科技趋势,提炼核心信息,适时生成专业评测观点,让你的数码影响力持续增长。
- 创意游戏工坊:简单一句 "需要在我的酒吧上线一个可以模拟 AI 大逃杀的对话游戏",分钟级别即可创建基于图灵测试的沉浸式大逃杀游戏体验,参与 AI 角色间的智慧博弈与尔虞我诈。
最重要的是,这些生成的 Agent 服务可以全部在本地执行,尽情使用,忘掉 Token 消耗。当然,有想法的小伙伴已经想到了, “想要专属个人助理”,“生成一个 Libra”,随着 Libra 的技术验证成功,创造力将不再是瓶颈,请开始你的对话式调教。
产品革新:Libra 对 Agent 落地的几点思考
实惠的国民 Agent: Token 总成本直降 90%
不同于普通的对话类 AI 应用,无论是 Cursor、WindSurf 等 AI Editor,还是以 Libra 为代表的 Vibe Agent 产品,都提供了复杂工具调用与多跳场景推理功能作为服务,为用户带来极致的自动化体验,而相应的推理 Token 消耗也呈现数量级的增长,当前 Agent 行业仍然处于 2G 时代的收费短信收发阶段,对有效智能的 "提速降费" 迫在眉睫。
根据官网信息,为了打造 Agent 服务的 "无限流量" 模式,Libra 团队通过低比特量化压缩、基于优先级的长上下文管理、端云协同等组合优化技术,实现了企业级大型语言模型在消费级桌面设备上的高效运行,从根本上改变了 AI 应用中的模型侧成本结构:

- 端 + 云服务:采用本地模型优先的 Agent 方案,无需依赖按 Token 计费的 API 费用,消除使用量增长带来的成本压力,长期使用成本降低 90% 以上。
- 走向消费级硬件:通过先进的模型压缩和优化技术,使消费级桌面硬件 (如 Apple M3 Ultra) 即可流畅运行企业级模型,初始投入降低 95%。
- 初步成本预估:根据团队估算,假设用户采用最昂贵的消费级桌面硬件 Apple M3 Ultra,使用 Libra 替换纯云端 API 方案后,持续的高强度 Agent 服务月支出从 15 万元降至设备一次性投入 8 万元,初始 Apple M3 Ultra 投资可在不到 3 个月内收回成本,当我们使用更日常的消费级硬件时,成本将进一步下降。
随着开源大模型能力、消费级芯片 Memory 与计算容量的持续提升,通过 Local Token 优先的 "端 + 云" 架构进行 Agent 部署能有效摊薄用户使用成本。
拥抱 Vibe Agent: 对话模式正在拓宽需求的边界
随着对话模式深入人心,语言正在重新定义需求的边界 —— 昨日的口头愿望正在转变为今天的实际需求。Libra 团队演示的 Vibe Agent 交互模式,正是对这一需求演化的精准回应。
从最新的 GPT-4o 图像直出、AI IDE 的代码辅助生成再到 Libra 的行动 Agent 生成,交互体验的突破带来的是效率的跨越式提升 —— 传统方式需要数周构建的基础 Agent,在 Vibe Agent 模式下仅需 10 分钟的对话调教,即可让 AI 自主理解场景中的工具需求与流程约束,生成同等甚至更高水平的专业级代理服务。Vibe Coding 以及 Vibe Agent 模式的出现不仅将提高人们对服务响应效率的预期,更将引领 Agent 技术领域不断向更高峰攀升。
从需求表达到服务实现的距离被大幅缩短,使得 "即时满足" 不再是奢望。随着这些技术的成熟与普及,我们将看到越来越多的个性化、场景化代理服务在各行各业涌现。
Local AI 的正确打开方式: Agent 即资产
Libra 团队的本地优先架构同时揭示了 Agent 时代的关键洞见:个人智能体已然成为无形但珍贵的知识资产。这一思路切中了当前 AI 发展的核心矛盾点。在知识工作者将创意、方法和解决方案输入云端 AI 工具的同时,他们也在不经意间贡献了自己最有价值的资产。
恰当的本地化策略是对这一需求的正面回应 —— 通过围绕用户需求构造本地优先的智能体,用户能够在轻松获得 AI 助力、形成个人工作流的同时,保留对自己独特工作方法的完全控制权,并实现持续迭代提升。这一转变的意义远超简单的隐私保护,它有效回应了个人与 AI 工具的关系边界。
为什么是 Libra?核心技术揭秘
从官网可知,Libra 团队持续投入本地 AI 相关核心技术栈研究,促使 Libra 成为首款在 Apple Mac 系列上直接运行的个性化 Agent 平台。摆脱云端限制,告别高昂 API 费用,让自主适应场景的 Vibe Agent 模式成为可能性:
低比特量化技术
采用基于混合精度量化和 Reasoning-Aware 低比特表征校准技术,将前沿大模型 (QwQ 32B、DeepSeek-R1-70B、Deepseek R1 671B 等) 精准压缩至符合 Apple 消费级 Silicon 硬件计算架构的 3/4 比特混合精度表征,并与 Apple MLX 机器学习推理框架无缝融合。在性能保持方面,将常规 Instruct 类大语言模型性能损失精确控制在 1% 以内,内存需求较 FP16 模式显著下降 75%+。

更令人惊喜的是,Libra 团队验证了低比特量化在提升推理模型 Thinking 阶段效率的意外优势,通过维持推理模型 Thinking 阶段在压缩前后的思考质量并压缩 Thinking 时长,模型在多种复杂推理任务上能力不降反升,相反,经典量化部署方案 (AWQ、GGUF 等) 表现出对推理模型压缩效果的不稳定性,在多项任务中出现性能、思考效率双降等问题)。这套技术栈成功突破了传统量化方法的精度瓶颈,通过精心设计的混合精度表征与重校准策略,在满足消费级硬件适配需求的同时,完美保护了影响模型核心能力的 “Super Weights”。

在 Libra 平台上 Agentic 任务对比测试结果令人振奋 —— 基于混合精度的低比特模型在复杂推理任务上的用户体验与原始模型几乎无差别。凭借这一技术路线,消费级设备如 Mac Studio 或将成为部署个性化 Agent 服务的最理想硬件平台。
自适应上下文管理引擎
为突破本地设备资源限制与模型 Context 窗口制约,同时实现有效的 Token 聚合,Libra 团队创新性地构建了事件驱动的 Token Vibe Orchestration (TVO) 策略。TVO 基于 JSX 的层级资源调度策略,对前后端和历史交互数据进行高效整合,并使用专用模型对原始 contex 进行投机总结与优先级预测,使模型能够预判用户交互意图,对最相关上下文片段进行重排,从而在有限计算资源环境下实现卓越的上下文理解能力。

测试数据表明,这种模型驱动的动态编排架构能有效提升本地 AI Agent 在长文档分析和多轮复杂对话中的记忆能力和指令跟随能力。特别是在 Browser-use 这类涵盖百万级 Token 的场景中,TVO 架构能优先保留高价值信息,显著提升模型响应质量。
响应式 Orchestration 框架
Libra 提出一种创新的 Meta Agent-Orchestration (MAO) 框架,为 Vibe Agents 生成进行 Instance Multi-Agents Orchestration 与资源调度。MAO 框架针对 Orchestration 场景定制了专用策略智能体,内化了复杂的 Orchestration 相关知识,使系统能够自主推理、预测最佳协作路径。基于高效的数据库策略,MAO 能够对大量外部工具链、前后端即时交互 Context 进行系统化整合。这种设计确保各组件间无缝协作,即使在本地设备资源受限的情况下也能保持高效运行。作为框架的重要补充,MAO 还针对数据流通层可用性构造了专用预测器,通过实时图联通性验证,实现了自然语言生成 Agents 的可用性验证,有效降低了任务失败风险。

可以预见,Libra 基于消费级硬件与端到端 Agent 生成的技术方案将加速 Agent 对个人与小微团体办公场景的加持:
1. 桌面级 AI 赋能:企业可直接在 Mac Studio 等消费级设备使用 Libra 运行高性能的 Vibe Agent 服务,为组织提供便捷的 AI 能力获取路径,使 AI 技术与日常办公环境无缝融合。
2. 创新周期加速:产品经理与 AI 玩具开发者等能在熟悉的 Mac 工作站环境中基于 Libra 完成 Agent 原型设计并使用 Libra Engine 导出部署,专注于应用场景创新,快速将 AI 概念转化为实用解决方案。
3. 灵活部署选择:通过 Mac Studio 等消费级硬件实现本地化 AI 能力,为企业提供多元化的部署选项,使各类组织能根据自身需求和 IT 策略灵活采用 AI 技术。
结语
Libra 提出的 Vibe Agent 范式代表了 Agent 技术演进的新方向。这一范式通过对话式交互构建智能体的方法解决了传统 Agent 开发中的技术壁垒问题,将繁复的工程化流程简化为自然语言指令。Vibe Agent 的关键技术价值在于实现了从预定义框架到端到端生成的转变,使非技术背景用户也能根据具体场景需求实现 In-Context 的 Agent 定制。这种范式转换不仅是交互层面的优化,更是对 Agent 开发模式的重构。
在技术实现层面,Libra 通过本地模型优先的架构策略,配合低比特量化和优先级上下文管理,使 Token 成本大幅度下降。这一成本优势使得持续性、高频率的 Agent 交互在经济上变得可行。通过端云协同机制,企业级模型能力被有效压缩并部署至消费级硬件平台,为用户提供接近无限制的生产力体验。从产业发展角度分析,Vibe Agent 范式的价值体现在两个维度:首先,显著降低的计算成本将重塑 Agent 的经济模型,使 AI 能力从企业级资源转变为个人级工具;其次,对话式创建机制将实现 Agent 开发应用的普及,促使专业知识从封闭系统向开放生态转变。Libra 的技术方案为 Agent 技术走向普惠化提供了可验证的实施路径,预计将在近期推动 Agent 应用从概念验证阶段迈向规模化部署阶段。随着端侧计算资源进一步优化,Vibe Agent 模式有望成为下一代 Agentic 产品开发的标准范式。

















 924
924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









