







我自己的原文哦~ https://blog.51cto.com/whaosoft/12661268
#还是回谷歌好
创业一年半,胖了30斤,AI大佬感叹
回到大厂,和老领导重聚。
「由于工作强度和不健康的生活方式,我已胖了 15 公斤。」
本周一,知名 AI 学者、前谷歌大脑高级研究科学家 Yi Tay 在短短一年半的创业之后官宣回到谷歌,他显得很高兴。

在初创企业世界探索了一年半之后,我决定回归我研究事业的出发点。
我将回到谷歌 DeepMind 从事人工智能研究。我很高兴能探索与 LLM 相关的令人兴奋的研究方向,并找到改变研究游戏规则的新方法。
我将以高级研究科学家的身份向我之前的经理 Quoc Le 汇报工作。
这是我回来的第一周,我非常兴奋。
Yi Tay 这次回到谷歌,成为了 DeepMind 旗下的一名高级研究员。此前,他是创业公司 Reka AI 的首席科学家和联合创始人。而在成为这家初创公司联合创始人之前,他是 Google Brain 的高级研究员,从事大型语言模型和人工智能研究。再往前,他是 Google Research 美国研究团队的技术主管,负责 Transformer 架构和扩展。
这是 Yi Tay 的头像照片。
创办 Reka 之前,在谷歌大脑工作的 3 年多的时间里,他总共参与撰写了大约 45 篇论文,是其中 16 篇的一作。一作论文包括 UL2、U-PaLM、DSI、Synthesizer、Charformer 和 Long Range Arena 等。
很多知名的大模型背后都有他的贡献,包括 PaLM、UL2、Flan-U-PaLM、LaMDA/Bard、ViT-22B、PaLI、MUM 等等。
然而就是这样一位科研牛人,出去创业不久之后也表示自己「悟」了。
AI 领域的创业究竟有多卷?Yi Tay 在回看这段经历之余,分享了在短短一年多创业时间里他的一些工作、生活瞬间。
的确肉眼可见地越来越胖。
在最新的一篇博客中,Yi Tay 对他近一年半的经历进行了复盘。
《重返 Google DeepMind》
关于 Reka 的反思
我很感谢在加入 Reka 并与他人共同创建 Reka 的过程中学到和经历的一切。
在技术上,我学到了很多谷歌之外的基础架构知识,学会了使用 Pytorch/GPU 和其他外部基础架构。我和 Reka 创始团队的其他成员一起,还以成本最优的方式建立了非常好的模型。我还学会了如何应对不可靠的 GPU、供应商和计算资源(参考报道:《「还是谷歌好」,离职创业一年,我才发现训练大模型有这么多坑》)。
基于我的经验,我还在 WebConf LLM 日主题演讲和越南 GenAI 峰会上发表了技术、反思和个人演讲。此外,我还要特别感谢 swyx 在 latentspace pod 上邀请我讲述我的探险经历,以及 TechInAsia 为我提供的有趣的炉边谈话。
同时,作为初创企业的联合创始人,我还经历了许多有趣的事件,如果我一直待在谷歌的话,我永远也不会有机会经历这些。这是一次大开眼界的经历。我学到了很多关于初创企业、业务和从头开始创建公司的过程的知识。尽管如此,我仍然更认同自己是一名科学家 / 研究员,因此我决定回归本源。
我为我们取得的成就感到骄傲,尤其是在 Reka 的早期。五月份,我们的 Reka Core 在 Lmsys 上首次进入前五名。实际模型排名第 7,我们实现了超越 GPT-4 早期版本的目标。与其他实验室相比,我们拥有的资源(资金、计算和人力)要少得多,因此我们的成绩令人印象深刻。我们筹集了 1 亿多美元的 lifetime funding,这与其他团队相比仍然相对较少。
此外,这还是由一个不到 15 人的技术团队完成的。
对个人来说,这又是一段神经紧张的时期,尤其是在我开始创业之旅时,也是我离开谷歌之后,我和妻子即将迎来我们的第一个孩子。为了同时兼顾这么多事情,我的身体和精神健康都受到了很大的影响,由于工作强度和不健康的生活方式,我的身体胖了 15 公斤。
好的一面是,我现在正积极努力地调养自己,使自己恢复到完全健康的状态,也许下次我还会写一篇关于我的这段疗伤经历的文章。
对我来说,这是一次狂野而有意义的旅程。我感谢大家给了我这段美妙的旅程。我非常享受与大家共事的过程,也非常享受在迪拜、京都和巴厘岛等有趣的地方举行的团队活动。
我有过一段美好的时光,我相信公司会在 Reka 雇用的这么多有才华、有能力的人的帮助下发展得很好!
这是一次很好的休假 / 学习经历。
现在是时候回到谷歌从事研究工作了。
特别声明
这可能有点随意,但对我个人来说,放弃舒适的生活环境而去创业真的很可怕。
我很感谢在这段时间里一直与我保持联系的所有谷歌朋友。即使在我转型成为一名 Xoogler 并更多地融入初创企业生活的过程中,我也为拥有这样一个支持网络而感到幸运。特别要感谢(排名不分先后)Vinh、Derek、Denny、Steven、Siamak、Mostafa、Don、Divy 和 Quoc,还有 Xoogler 的其他朋友,如 Jason、Jerry、Hyung Won 和 Afroz,他们在我离开后仍保持联系。
有趣的是,在这段时间里,我和你们中的很多人都见了面!在新加坡的某个时刻,我还和 Derek、Vinh、Jason、Jerry、Quoc、Divy、Sanket、Swaroop 和 Neil 一起玩耍过。此外,邀请我去越南演讲的 Thang Luong 也非常好!
感谢大家对我的热情 / 支持,感谢大家低调地提醒我应该回来。最后,也是最重要的一点,我感谢 Quoc 在这 1 年半的时间里对我的关心和友谊;感谢 Jeff Dean 在新加坡与我共进晚餐(并提醒我谷歌很棒!);感谢我的招聘人员 Katelyn 在这 1 年多的时间里一直与我保持联系!
我很高兴能回来。
始于热情,终于疲惫:大厂人才回流,风向又变了?
2023 年 3 月份,Yi Tay 宣布离开谷歌,参与创办了 Reka 并担任该公司的首席科学家,主攻大型语言模型。
我们知道当时 ChatGPT 刚推出不久,在这个时间段,选择趁大模型热潮辞职创业的人很多,离开的原因很多样:对大模型方向前景的看好,对经济复苏的推断,投资人的推动,还有就是,很多人提到了积重难返的大公司病。
许多从谷歌离开的员工都发过「小作文」,表示谷歌问题的根源不是「技术」,而是在于「文化」,比如员工的使命感不足,公司为了避免风险设置了繁琐的系统和流程。
和 Yi Tay 前后脚离职的 AppSheet 创始人 Praveen Seshadri 就写过一篇《Google 出了什么问题》,直言「如今的谷歌与当年的微软一样,正在逐步走向衰落。」
然而一年半过去了,我们发现很多 AI 人才都在「回流」大厂。
除去因为种种原因创业受阻的一批人之外,其他人想回去的原因可能很简单:创业真太累了。
今年 8 月,李沐也复盘了自己创业一年的体会:
在 Amazon 呆到第五年的时候就想着创业了,但被疫情耽搁了。到第 7 年半的时候,觉得太痒了,就提了离职。现在想来,如果有什么事这一辈子总要试下的,就蹭早。因为真开始后会发现有太多新东西要学,总感叹为啥没能早点开始。
即使拿到了融资,拿到了做 LLM 的入场券,这其中也包含了常人很难经历的「大起大落」:
运气不错,很快拿到了种子投资。但钱还不够买卡,得去拿第二轮。这一轮领头是一家非常大的机构,做了几个月文档、商讨条款。但在签字前一天,领头说不投了,直接导致了跟投的几家退出。
在回到母校上海交大的演讲中,他也提到了创业给自己带来的健康方面的影响:
创业不好的地方就是婴儿般的睡眠,每三个小时醒一次,怀疑自己是不是快混不下去了。为此,我还问过很多人,包括张一鸣,以及世界首富级别的人,向他们取经。
在公司步入正轨之后,李沐仍然觉得自己当时「脑子抽了」:
去年跟宿华在斯坦福散步,他拍着我肩膀说:“跟我说句实话,你为什么想创业呀?” 当时候不以为然:“就是想换个事情做做”。然后宿华笑了笑。
现在我懂了,因为他经历了创业酸甜苦辣。如果今天再来回答这个问题,我会说:“我就是脑子抽了”。但也庆幸当时没想到会那么不容易,所以一头扎进来了。否则,大家看到的可能是「工作十年反思」。我觉得今天我写的故事更有意思些。
品尝完创业的艰辛之后,知名的学者也会发出感叹。
对此,你怎么看?
参考内容:
https://www.yitay.net/blog/returning-to-google-deepmind
#aisuite
吴恩达出手,开源最新Python包,一个接口调用OpenAI等模型
在构建应用程序时,与多个提供商集成很麻烦,现在 aisuite 给解决了。
用相同的代码方式调用 OpenAI、Anthropic、Google 等发布的大模型,还能实现便捷的模型切换和对比测试。
刚刚,AI 著名学者、斯坦福大学教授吴恩达最新开源项目实现了。

吴恩达在推文中宣布了这一好消息开源新的 Python 包:aisuite!
这个工具可以让开发者轻松使用来自多个提供商的大型语言模型。
在谈到为何构建这个项目时,吴恩达表示构建应用时,发现与多个提供商集成非常麻烦。aisuite 正是为了解决这个问题而诞生的,用户只需通过更改一个字符串(如 openai:gpt-4o、anthropic:claude-3-5-sonnet-20241022、ollama:llama3.1:8b 等),即可选择不同提供商的模型。

项目地址:https://github.com/andrewyng/aisuite
项目一上线,大家纷纷表示「这对开发人员来说非常有用。」
「超级方便!简化集成总是有益的,非常好的研究!」
统一接口设计,支持多个 AI 提供商的模型
aisuite 使开发者能够通过标准化的接口轻松使用多个 LLM。其接口与 OpenAI 的类似,aisuite 可以很容易地与最流行的 LLM 交互并比较结果。
aisuite 是一个轻量级的包装器,它基于 Python 客户端库构建,允许用户在不修改代码的情况下,轻松切换并测试来自不同 LLM 提供商的响应。
目前,这个项目主要集中在聊天补全功能,未来将扩展到更多使用场景。
当前,aisuite 支持的提供商包括:
OpenAI
Anthropic
Azure
AWS
Groq
Mistral
HuggingFace
Ollama
为了确保稳定性,aisuite 使用 HTTP 端点或 SDK 来与提供商进行调用。
安装
安装过程有多种选择。
下面是只安装基础包,而不安装任何提供商的 SDK。
pip install aisuite带 Anthropic 支持的安装方式
pip install 'aisuite [anthropic]'下面是将安装所有特定于提供商的库。
pip install 'aisuite [all]'设置
开始使用时,你需要为打算使用的提供商获取 API 密钥。API 密钥可以作为环境变量设置,具体的使用方式可以参考 aisuite 的 examples 文件夹。
如果大家还不是很明白,可以参考下面简短的示例展示,即如何使用 aisuite 生成来自 GPT-4o 和 Claude-3-5-Sonnet 的聊天补全响应。
先设置 API 密钥:
export OPENAI_API_KEY="your-openai-api-key"
export ANTHROPIC_API_KEY="your-anthropic-api-key"使用 Python 客户端:
import aisuite as ai
client = ai.Client ()
models = ["openai:gpt-4o", "anthropic:claude-3-5-sonnet-20240620"]
messages = [
{"role": "system", "content": "Respond in Pirate English."},
{"role": "user", "content": "Tell me a joke."},
]
for model in models:
response = client.chat.completions.create (
model=model,
messages=messages,
temperature=0.75
)
print (response.choices [0].message.content)想要尝试的读者可以跟着原项目进行配置。如今,我们身处大模型时代,对于开发者而言,用一个统一的接口就能调用各种大模型,这给开发者们节省了大量的时间成本。
#XGrammar
陈天奇团队LLM结构化生成新引擎:百倍加速、近零开销
现在,大语言模型的结构化生成有了一个更加高效、灵活的引擎。
不管是编写和调试代码,还是通过函数调用来使用外部工具,又或是控制机器人,都免不了需要 LLM 生成结构化数据,也就是遵循某个特定格式(如 JSON、SQL 等)的数据。
但使用上下文无关语法(CFG)来进行约束解码的方法并不高效。针对这个困难,陈天奇团队提出了一种新的解决方案:XGrammar。

XGrammar 是一个开源软件库,可实现高效、灵活且可移植的结构化生成。该团队在博客中表示:「我们毫不妥协地实现了这三个目标,并致力于一个核心使命:将灵活、零开销的结构化生成带到任何地方。」
- 论文标题:XGrammar: Flexible and Efficient Structured Generation Engine for Large Language Models
- 论文地址:https://arxiv.org/pdf/2411.15100
- 代码地址:https://github.com/mlc-ai/xgrammar
对于结构化生成,一种常用方法是约束解码。在每个解码步骤中,约束解码都会检查词表,并通过将无效 token 的概率设置为零来过滤掉违反指定结构的 token。为了支持多种多样的结构格式,需要一种灵活的机制来指定和检查这些约束。

使用 JSON 方案实现约束解码
上下文无关语法(CFG)就能提供一种通用方法,即通过一组规则来定义结构。其中每条规则都包含一个字符序列或其他规则,并允许递归组合来表示复杂的结构。相比于正则表达式等其它格式,CFG 由于支持递归结构,因而能提供更大的灵活性,使其适合描述 JSON、SQL 和领域特定语言(DSL)等常见语言。
下图展示了一个用于数组和字符串的 CFG,可以清楚地看到其中的递归结构。

但是,也正因为 CFG 很灵活,所以直接将其应用于约束解码的效率并不高。首先,每个解码步骤都需要对词表中每个可能的 token 解释 CFG,在 Llama 3.1 中,这个词表的大小可能高达 128k。此外,CFG 解释需要一个堆栈状态来跟踪之前匹配的递归规则,因此无法提前计算和缓存堆栈模式的所有组合。最后,LLM 生成结果中的每个 token 都包含多个字符,这些字符可能会跨越语法元素的边界,并在运行时执行期间导致进一步的递归或堆栈弹出。这种未对齐的边界问题很棘手,需要在语法执行期间小心处理它们。
XGrammar 便是为解决上述难题而生的,并且效果卓越:相比于之前的 SOTA 方法,XGrammar 可以将上下文无关语法的每 token 延迟减少多达 100 倍!此外,他们还基于 Llama3.1 模型实验了集成了 XGrammar 的 LLM serving 引擎;在 H100 GPU 上,这能将通过结构化输出实现端到端 LLM serving 的速度提升 80 倍!
该团队表示:「我们正在开源 XGrammar 并将其集成到主要的开源 LLM 框架中。」
XGrammar 概览
如图 1 所示,Grammar 利用了字节级下推自动机(byte-level pushdown automaton)来解释上下文无关语法。

这种字节级设计允许每个字符边缘包含一个或多个字节,处理不规则的 token 边界并支持包含 sub-UTF8 字符的 token 。该自动机的结构经过优化以加快匹配速度。
在预处理阶段,会生成一个自适应 token 掩码缓存,它会通过预先计算与上下文无关的 token 来加快运行时的掩码生成。上下文扩展(context extension)能进一步提升这种缓存的有效性。
在运行时,token 掩码缓存会快速生成大部分掩码,而持续性执行堆栈会高效处理其余的上下文相关 token。
此外,掩码生成和 LLM 推理是互相重叠的,以最大限度地减少约束解码的开销。一旦 LLM 在掩码约束下生成新 token,就会使用此 token 来更新下推自动机的堆栈状态,以进行下一次掩码生成。
具体来说,陈天奇团队首先得到了一个见解:虽然无法预先计算下推自动机(PDA)无限多个状态的完整掩码,但可以预先计算掩码中相当一部分(通常超过 99%)的 token。因此,可将这些 token 分成两类:
- 上下文无关 token:仅通过查看 PDA 中的当前位置而不是堆栈即可确定其有效性的 token。
- 上下文相关 token:必须使用整个堆栈来确定其有效性的 token。
下图展示了一组上下文相关和无关 token 的示例。大多数情况下,上下文无关 token 占大多数。我们可以预先计算 PDA 中每个位置的上下文无关 token 的有效性,并将它们存储在自适应 token 掩码缓存中。此过程称为语法编译(grammar compilation)。

下图则展示了自适应存储格式。

在运行时,首先检索来自缓存的上下文无关 token 的有效性。然后,高效地执行 PDA 来检查其余的上下文相关 token。通过跳过运行时检查大多数 token,便可以显著加快掩码生成速度。XGrammar 执行时间的整体工作流程见图 1。
此外,他们还设计了一组额外的算法和系统优化方法,以进一步提高掩码生成速度并减少预处理时间,包括上下文扩展、持续性执行椎栈、下推自动机结构优化、并行式语法编译。
上下文扩展
该团队提出的方法是检测语法中每个规则的额外上下文信息,并将其用于减少上下文相关 token 的数量,并进一步加快运行时检查速度。

持续性执行堆栈
为了加快由于多种可能的扩展路径而导致的拆分和合并期间多个并行堆栈的维护速度,他们设计了一个基于树的数据结构,可以有效地同时管理多个堆栈。

它还可以存储以前的状态并实现高效的状态回滚,从而加快上下文相关 token 的运行时检查速度。
下推自动机结构优化
研究者进行了额外的优化,以改进下推自动机的结构,加快最终执行的效率。这些优化借鉴了传统的编译器优化概念,它们对于高效约束解码特别有用。
一是规则内联。在指定的上下文无关语法中,可能有许多片段规则,即只有少数元素的规则,然后在下推自动机中将其转换为小的 FSA(有限状态自动机)。
为了解决这个问题,研究者为片段规则引入了一种自动内联策略。他们迭代地选择不引用其他规则的规则并将它们内联到父规则中。为了避免自动机大小的爆炸式增长,研究者将内联规则和内联结果的大小限制为常量。该内联过程几乎消除了片段规则,从而提高了 token 检查的效率并增强了上下文扩展的有效性。
二是下推自动机节点合并。对于下推自动机,在许多情况下,歧义来自具有相同标签的节点的多个外向边。在匹配 token 时,如果到达此节点,并且下一个字符恰好与标签匹配,则匹配堆栈将被拆分为多个堆栈,每个外向边一个。堆栈数量增多会增加计算量,这是因为需要检查每个堆栈的上下文相关 token 并合并 token 掩码。
为了减少这种歧义,节点合并算法会合并满足以下两个条件的后续节点,a)它们由来自同一点的具有相同标签的边指向,b)它们没有被其他边指向。
以上两种优化保留了自动机的等效性,但减少了节点和边的数量。运行时,减少了堆栈的数量和 token 检查所需的计算量,从而加快了掩码的生成过程。
重叠掩码生成和 LLM 推理
通过上述优化,token 掩码生成过程显著加快,但仍需要 CPU 计算。为了进一步消除约束解码的开销,研究者将 mask 生成计算与 LLM 推理过程重叠,如下图 8 所示。

研究者观察到,mask 生成过程和 LLM 推理过程可以重叠,原因在于 mask 生成只需要 CPU,并且只依赖于之前生成的 token。LLM 推理过程(除采样阶段外)只需要 GPU,并且也只依赖于之前生成的 token。因此可以将 CPU 上的 mask 生成过程与 GPU 上的 LLM 推理过程并行化。
评估结果
研究者利用 12,000 行核心 C++ 代码来实现 XGrammar,并提供了 Python 捆绑包以方便与 LLM 推理框架无缝集成。他们在评估 XGrammar 过程中回答以下几个问题:
- XGrammar 能否高效支持约束解码的每个步骤?
- XGrammar 能否在 LLM serving 中实现端到端结构化生成的最小开销?
- XGrammar 能否部署在更广泛的平台上?
语法引擎效率
本节中评估了语法引擎的性能。研究者在 Llama-3.1-8B Instruct 上评估了他们的方法和基线,该模型能够遵循人类的指令。
结果如下图 9 所示,在 JSON 模式设置中,XGrammar 可以实现高达 3 倍的加速;在 JSON 语法用例下,可以实现超过 100 倍的加速。与 JSON 模式(更受限制)相比,JSON 的上下文无关语法包含更复杂的规则,因为它可以包含递归列表和字典,导致语法引擎更难有效地执行它。
在这两种情况下,XGrammar 都可以在不到 40 微秒的时间内生成每个 token 的掩码,使其成为低延迟 LLM 推理的理想选择。

端到端 LLM 引擎评估
本节在 LLM serving 设置下来评估 XGrammar。研究者将 XGrammar 集成到端到端 LLM 推理框架中,并与其他 LLM serving 框架进行效率比较。同时,他们还与其他支持结构化生成的 LLM 引擎进行效率比较,包括集成 Outlines 的 vLLM (v0.6.3) 和内置语法引擎的 llama.cpp。
实验结果如下图 10 所示,XGrammar 在 CFG 和 JSON 模式的所有基线中实现了最佳的 TTFT 和 TPOT。vLLM 和 llama.cpp 的计算受到其语法引擎更长预处理和每个 token 处理时长的阻碍。
在批量较大的情况下,vLLM 中 TPOT 速度的下降尤为明显。与现有解决方案相比,XGrammar 引擎总体上可以将输出 token 的速度提高 80 倍。这种加速来自 XGrammar 带来的性能优化。

研究者还在下表 1 中研究了语法处理的开销问题。由于 token 掩码生成效率和语法 GPU 重叠,语法过程在 TPOT 中几乎不产生任何开销。

跨平台部署
本节探讨如何将 XGrammar 引入各种平台。研究者利用 Emscripten 将 XGrammar 编译成 WebAssembly 并构建 JavaScript 捆绑包。他们进一步将 web-binding 与浏览器内 LLM 推理框架 WebLLM 集成,以实现结构化生成。
研究者使用 JSON-mode-eval 数据集评估端到端性能,在装有 Google Chrome 的 MacBook Pro M3 Max(macOS 14.5)上使用 4 位量化模型 Llama-3.1-8B-Instruct,并在装有 Safari 的 iPhone 14 Pro Max(iOS 18)上使用 Qwen2.5-0.5B-Instruct。
结果如下图 11 所示,研究者比较了使用 XGrammar 进行结构化生成和非结构化生成时的第一个 token 时间 (TTFT) 和每个输出 token 时间 (TPOT),同时确保生成的 token 数量相同。结果表明,XGrammar 在两种设置下都几乎实现了零开销,在支持未来高性能端侧智能体方面具有巨大潜力。

#毕昇一号
DNA活字存储喷墨打印机来了,低成本、高效率、全自动的DNA存储
2024 年 11 月 18 日,中科院北京基因组研究所(国家生物信息中心)陈非团队、计算所处理器全国重点实验室谭光明、卜东波团队、中科计算技术西部研究院段勃团队、微生物所杨怀义团队、武汉所刘翟团队以及吉林大学李全顺团队等在知名国际学术期刊《Advanced Science》上发表了题为 “Cost-Effective DNA Storage System with DNA Movable Type” 的论文,借鉴毕昇活字印刷术的思想,提出了“DNA活字存储”新思路,并实现了具有完全自主知识产权的全自动、低成本、高效率的DNA 活字存储喷墨打印机“毕昇一号”。
- 论文标题:Cost-Effective DNA Storage System with DNA Movable Type
- 论文地址:https://onlinelibrary.wiley.com/doi/10.1002/advs.202411354
,时长01:44
1. 什么是 DNA 存储?
数据指数级增长,磁带、磁盘、光盘、U 盘不敷使用,怎样才能存得下?
存到 DNA 中吧!存到 DNA 中是一种有潜力的方案!
互联网时代的到来, 数字化和信息化浪潮使知识与数据都经历着爆炸式的增长。海量数据给现有的数据存储技术带来了巨大的挑战:现有的硬盘、磁带存储模式存在保存时长有限(最长约 30 年)、占用空间大、转运不方便、电能损耗大等缺点,无法满足数据指数形式增长的需求。
DNA 存储技术是一种新兴的大数据存储技术。简要地说,DNA 存储技术突破了传统的以硅基介质(如 U 盘等)为媒介的存储方式,而是利用 DNA 碱基天然的信息存储能力,依据一定规则将文本、图片、声音、影像文件等传统数据 0-1 二进制编码转换为 DNA 核苷酸四进制编码(A、T、C、G 组合),然后通过人工合成特定序列的 DNA 来存储数据。相比于现有的数据信息存储方式,DNA 存储技术具有数据密度高、保存时间长、配套设备能耗低、便于携带、运输隐蔽性高和便于多重加密等优点。

图 1. DNA 存储技术及其优势
鉴于 DNA 存储技术的巨大潜力,美国微软公司陆续投资近亿美元,与华盛顿大学于 2015 年成立 DNA 存储项目组,于 2018 年 3 月完成了约 200MB 数据的保存,其中包括古登堡计划数据库中的 100 部世界名著,创造了 DNA 存储领域的新纪录。2019 年,他们构建了端到端全流程原型机,实现了 “hello” 单词的完整写读。
2. 什么是 DNA 活字存储?
现有的 DNA 存储技术 “一次合成、一次使用”,价格昂贵,怎样才能降低成本?
用 DNA 活字吧!DNA 活字存储是一种有潜力的方案!
“庆历中,有布衣毕昇,又为活板。其法:用胶泥刻字,薄如钱唇,每字为一印,火烧令坚…… 欲印,则以一铁范置铁板上,乃密布字印,满铁范为一板,持就火炀之,药稍镕,则以一平板按其面,则字平如砥。若止印三二本,未为简易;若印数十百千本,则极为神速”。这是沈括写的《活板》中的一段话 ---《活板》被选作初中课文,是以举凡在中国读过初中者,想必对毕昇发明活字印刷术的故事皆耳熟能详。《活板》有言:“有奇字素无备者,旋刻之,以草火烧,瞬息可成”,活字印刷术相较于雕版印刷术之优势可见一斑。
那什么是 DNA 活字存储呢?所谓 DNA 活字存储,就是 “DNA 版本的活字印刷术”。目前的 DNA 存储技术方案,多采用化学合成法,一次合成,一次使用,可比作雕版印刷术;而 DNA 活字能够一次合成,多次使用,可比作活字印刷术。
具体来说,DNA 活字存储采用酶连反应替代部分化学合成步骤完成数据写入,每个活字可重复使用多达一万次,从而将数据存储成本降低至每兆字节仅 122 美元,成为当前业内最具成本效益的存储解决方案。

图 2. 毕昇发明的活字印刷术与 DNA 活字存储。以唐诗《行路难・其一》为例,我们将每个字符及其位置索引转换成 DNA 活字,用酶联技术连接成 DNA 片段,最终转导入大肠杆菌中长期存储
3. “毕昇一号”--- 全自动的 DNA 活字存储喷墨打印机
DNA 活字存储包括选活字、酶联活字、酶联后的 DNA 片段转导入大肠杆菌中长期存储等多个环节。如何提高存储效率呢?联合团队研发了 DNA 活字喷墨打印机 “毕昇一号”,全自动完成上述诸多环节,显著提升了数据写入效率 --- 研究团队将这台打印机命名为 “毕昇一号”,以表达对毕昇的崇敬之意。

图 3. “毕昇一号”--- 全自动的 DNA 活字存储喷墨打印机
“毕昇一号” 系统使用 350 个 DNA 活字,成功存储并精准检索了 43.7 KB 的多媒体数据,包括文本、图像、音频和视频,充分证明了其技术的可行性和应用潜力。这项工作为 DNA 数据存储技术的未来产业化提供了全新的思路与可能性。
毕昇一号 DNA 活字存储系统的工作流程包括四个主要步骤:
第一步,编码:将目标文件(如《十四行诗》第 12 首)分割为 100 字节 / 字符的片段,每个片段进一步划分为 20 个数据切片。每个切片包含 5 字节的有效载荷和 4 字节的地址,形成数据条带。例如,图中展示了第四条数据条带的 20 个连续数据切片(第 0–19 行),这些切片覆盖了第 300 到第 399 个字符的内容(如 “ed up...question ma”),其中第 8 个切片在第 340 个位置编码了单词 “white”。此外,通过列校验和(第 20–29 行)和行校验和(第 9 列)提供了额外的错误检测和纠正功能。
第二步,打印:利用 “毕昇一号” DNA-MT 喷墨打印机,将 4 个地址活字(AMTs)、5 个有效载荷活字(PMTs)和 1 个校验活字(CMT),以及连接酶和预切割载体打印到每个试管中,通过酶促连接形成包含 DNA-MT 块的质粒。
第三步,存储:组装完成的重组质粒可以以液体或冻干形式进行体外保存,或者转化至大肠杆菌中实现长期体内存储。
第四步,解码:通过高通量测序对 DNA 活字块进行测序,获得的 DNA 序列根据编码表解码为对应活字,从而还原原始数据。例如,解码一个 250 个碱基的序列可以恢复第 340 个位置的单词 “white”。最终,解码后的有效载荷活字根据地址活字的顺序排列,完成对原始文件的重建。

图 4. 毕昇一号 DNA 活字存储系统的工作流程
毕昇一号 DNA 活字存储的成本约为 122 $/MB,明显低于现有的 DNA 存储技术。该团队表示,后续研究通过增加活字连接段数和减小反应体系,可将存储成本降低至 0.06 $/MB,伴随着编码技术的进步,如集成高密度喷泉码和改进校验的 DNA 活字,成本将进一步降低,有望进一步推动 DNA 存储的商业化进程。

图 5. DNA 活字存储技术可显著降低存储成本
4. 展望
DNA 存储技术是生物技术与信息处理技术的碰撞与交叉。它开辟了一种新的存储模式,从根本上改变了数据、信息的保存及传递方式,是大数据存储模式的新篇章。
北宋时,毕昇发明了活字印刷术,尽扫雕版印刷术之弊;而时至今日,古老的活字印刷术与现代的 DNA 存储相互激发,相互交叉,碰撞出 “DNA 活字存储” 这一新思维。
“发挥旧事重增焕”。我们期待:“毕昇一号” DNA 活字存储喷墨打印机将像毕昇的 “活板” 一样,另辟蹊径,开创新篇!
图 6. 研究团队部分人员。左起:张心茹、范婷文、邢晶、段勃、陈非、卜东波、刘翟、杨怀义、马灌楠、魏征、魏迪、王晨阳、王佩、侯鹏飞、涂朝仕。
#LLM 可以从简单数据中学习吗?
在 10 月份的一次周会结束后,我提到 SFT 训练后的 Loss 曲线呈现阶梯状,至于为什么,并没有人有合理的解释,加上当时的重心是提升次日留存率,Loss 曲线呈现阶梯状与次日留存率的关系还太远,即使有问题,起码次日留存率是逐渐在提升。
幸运的是,在一次逛论坛时发现了一篇博客 Can LLMs learn from a single example?,也是我这篇博客的标题名称由来,在其基础上结合了公司业务的一些现状和我个人的思考。
可以清楚地看到每个 epoch 的终点——loss 突然向下跳。我们以前也见过类似的损失曲线,但都是由于错误造成的。例如,在评估验证集时,很容易意外地让模型继续学习——这样在验证之后,模型就会突然变得更好。因此,开始寻找训练过程中的错误。
发现该“问题”的时间,恰好与单句重复问题同一时期(9 月份),于是推测是不是 context length 从 2k 变到 4k 所致,以及 Transformers 库和 RoPE 位置编码的问题。在开始逐步修改代码的同时,在 Alignment Lab AI Discord 上看到他人反馈的类似的奇怪 loss 曲线,并且每个回复的人也都在使用 Trainer,这在当时加深了我认为 Transformers 库存在问题的猜测,甚至我还去询问了同事李老师是否有同样的问题,以及 load model 时的 warning。
9 月中旬,老板要求我们加上验证 loss,于是出现了如下图所示的 eval loss 曲线。
该问题在 Discord 上讨论得越来越激烈,也有人反映在不使用 Trainer 的情况下,也会出现阶梯状的 loss 曲线。
查阅资料,看到一种假设:即这些训练曲线实际上显示了过拟合。起初,这似乎是不可能的。这意味着模型正在学习识别来自一个或两个示例的输入。如果回过头来看我们展示的第一条曲线,就会发现 loss 在第二和第三个 epoch 期间,它根本没有学习到任何新东西。因此,除了在第一个 epoch 开始时的初始学习(学习了多轮对话的对齐方式)外,几乎所有表面上的学习都是(根据这一理论)对训练集的记忆。此外,对于每个问题,它只能获得极少量的信号:它对答案的猜测与真实标签的比较。
资料提到了一项实验:使用以下学习率计划,对 Kaggle 模型进行了两个 epoch 的训练:
如今,这种 schedule 并不常见,但莱斯利-史密斯(Leslie Smith)在 2015 年发表的论文《训练神经网络的循环学习率》(Cyclical Learning Rates for Training Neural Networks)中讨论了这种方法,并取得了很大成功。
下面就是我们因此而看到的看起来很疯狂的训练和验证损失曲线:
到目前为止,我们唯一能完全解释这种情况的方法就是假设是正确的:模型正在快速学习识别实例,即使只看到一次。让我们依次查看 loss 曲线的各个部分:
- 从第一个 epoch 来看,这是一条非常标准的 loss 曲线。在第一个 10% 的 epoch 中,学习率开始升温,一旦达到温度后,训练和验证 loss 就会迅速降低;然后按照余弦曲线逐渐下降,两者都会放缓。
- 第二个 epoch 才是我们感兴趣的地方。我们并没有在 epoch 开始时重新 shuffle 数据集,因此第二个 epoch 的第一批数据是学习率仍在预热的时候。这就是为什么在我们展示的第一条 loss 曲线中,没有看到像从 epoch 2 到 epoch 3 那样的直接阶跃变化——这些批次只有在学习率较低时才会出现,所以它学不到太多东西。在 epoch 2 开始 10% 时,训练 loss 急剧下降,因为在第一个 epoch 中看到这些批次时,学习率很高,模型已经知道了它们的样子,因此它可以非常自信地猜出正确答案。但在此期间,验证 loss 会受到影响。这是因为虽然模型变得非常自信,但实际上它的预测能力并没有提高。它只是记住了数据集(早期没有清洗掉训练数据中的保底回复以及一些涉及到公司信息的关键词,模型会输出这些内容,甚至会将原样的超时保底回复输出),但并没有提高泛化能力。过于自信的预测会导致验证损失变大,因为损失函数会对更自信的错误进行更高的惩罚。
- 曲线的末端是特别有趣的地方。训练 loss 开始变得越来越大,而这是绝对不应该发生的!事实上,我还从未在使用合理的学习率时遇到过这种情况。根据记忆假说,这完全说得通:这些批次是模型在学习率再次下降时看到的,因此它无法有效地记忆这些批次。但模型仍然过于自信,因为它刚刚得到了一大堆几乎完全正确的批次,还没有适应现在看到的批次没有机会学得那么好这一事实。它会逐渐重新校准到一个更合理的置信度水平,但这需要一段时间,因为学习率越来越低。在重新校准的过程中,验证 loss 会再次下降。
记忆假说很有可能是真的。按照先前小模型时代的训练经验,我们往往需要大量的数据来让模型学习输入分布和模式。使用随机梯度下降法(SGD)导航的损失面太崎岖,无法一下子跳得很远。不过,有些东西可以让损失面变得更平滑,比如使用残差连接,如经典论文《可视化神经网络的损失景观》(Li et al,2018)中所示。
很可能的情况是,预训练的大语言模型在接近最小损失的区域具有极其平滑的损失面,而开源社区所做的大量微调工作都是在这一区域。这是基于最初开发微调通用语言模型的基本前提。简单来说,我们的训练数据并不能够让模型跳出该平滑的损失面,只是让模型记住了 BOT 的回复、以及通过几个数据就让模型学到了说话风格。
如果以上猜测都属实,这不是什么糟糕的事情,拥有一个学习速度非常快、且能够举一反三的模型是一件非常棒的事情。同时,这也佐证了《LIMA:Less Is More for Alignment》、《A Few More Examples May Be Worth Billions of Parameters》、《Maybe only 0.5% Data is Needed: A Preliminary Exploration of Low Training Data Instruction Tuning》等一系列证明少量优质、多样性丰富的指令数据就能让模型有很强指令遵循的论文的有效性。以及最近出现的一系列关于指令数据集子集选择的论文,例如《Smaller Language Models are capable of selecting Instruction-Tuning Training Data for Larger Language Models》、《LESS: Selecting Influential Data for Targeted Instruction Tuning》。这些论文提到经过他们方法挑选出来的子集,在该子集上训练出来的模型比在全量数据集上微调的模型效果要更好。
我统计了从 7 月 到 11 月份所训练模型的 Loss 曲线是否呈现阶梯状,正常表示平滑下降,不正常表示阶梯下降(在每个 epoch 交界处骤降)。早期训练的模型的 loss 曲线都是正常,可惜的是早期的训练数据被删了,无法准确地判断是数据质量的因素,还是基底模型的因素。
早期训练遵循多阶段的方式,即先在 continual pretrain 得到的 base 模型上用 GPT4all 数据集以及一个闲聊场景的对话集进行训练,然后再用高质量的对话数据集再次微调。以此得到的模型表现平常,虽不会犯错,但也没有新意,不能提升平均对话轮数,因此后续我们不再进行 base model -> GPT4all + 闲聊数据集 -> 高质量对话数据集的多段式 SFT,而是直接在 base model 上用高质量对话数据集进行 SFT。在这之后训练的模型的 loss 曲线都是阶梯状,按照记忆假说和先前分析的内容来看,llama2、vicuna-13b-v1.5 等模型的对话、闲聊能力得到了提升(也有可能是 GPT4all 数据集让模型闲聊能力下降),在我们所认为的“高质量”数据集上进行训练,模型只是记住了对话内容,而非真正意义上地学习(训练数据集对于模型来说非常简单)。
PS:我没有否认和贬低这种方式,当模型的“脑容量”(记忆力)大到能够将我们提供的优质回复都记住,并且在合适的场景输出,这在业务上完全没有问题。在复读机问题上,将高质量数据集从 4k 扩充至 26k 后,的确减少了该问题的频次。一个可解释的原因是数据集的多样性增加,能够囊括更多的对话场景以及角色。
一个猜想:当模型的学习速度如此之快时,灾难性遗忘问题可能会突然变得明显得多。例如,如果一个模型看到了十个非常常见关系的示例,然后又看到了一个不太常见的反例,那么它很可能会记住这个反例,而不仅仅是稍微降低它对原来十个示例的记忆权重。
在 6 月下旬时,老板询问我为什么模型的效果不太好时,我想了想说是灾难性遗忘(找的理由)。现在看来,似乎的确大概率是这个原因。沿着 base model -> GPT4all + 闲聊数据集 -> 高质量数据集训练的路径,希望模型能够不断地进化,但实际上 base model 原先的知识和 GPT4all 数据集中的内容都遗忘得差不多。因此,不要多阶段 SFT,而是将每个阶段的训练数据进行混合,可以减少灾难性遗忘的影响,这或许就是后来尝试数据混合方案后,能够提升次日留存率的一个原因?
此外,我们还需要审视,对于模型来说,什么是高质量的数据集。
#QuadMamba
该研究通过分析Transformer模型中的反向传播矩阵,提出了一种新的方法来理解语言模型(LM)如何学习和记忆信息。论文提出了将梯度矩阵映射到词汇空间的技术,揭示了LM在学习新知识时的内在机制,并探讨了梯度的低秩性以及“印记与偏移”的知识存储与模型编辑机制。
近年来,状态空间模型(State Space Models)中的Mamba取得了显著的进展,在性能上超过了主导的Transformer模型,尤其是在降低计算复杂度方面,从二次降到了一次。然而,由于视觉数据的独特特性,如图像中的空间局部性和邻接关系以及视觉 Token 的信息粒度变化很大,Mamba从语言任务转换到视觉任务时存在困难。现有的视觉Mamba方法要么将 Token 扁平化为在光栅扫描方式下的序列,这破坏了图像的局部邻接关系,要么手动将 Token 分区到窗口,这限制了它们的远程建模和泛化能力。
为了解决这些限制,作者提出了一种新的视觉Mamba模型,称为QuadMamba,它通过基于四叉树(quadtree)的图像分区和扫描有效地捕获了不同粒度局部依赖性。
具体来说,作者的轻量级四叉树扫描模块学习到在学习的窗口四角内保持空间区域2D局部性。模块根据每个 Token 的特征估计局部性分数,然后适当地将 Token 分区到窗口四角。作者还引入了一种全方位窗口平移方案,以捕获不同局部区域之间的更多完整和有用的特征。为了使离散化的四叉树分区端到端可训练,作者进一步设计了一种基于Gumbel-Softmax及其直接导数序列 Mask 策略。大量实验表明,QuadMamba在各种视觉任务中实现了最先进的性能,包括图像分类、目标检测、实例分割和语义分割。
代码已在https://github.com/VISION-SJTU/QuadMamba。
1 Introduction
结构化状态空间模型(SSMs)的架构在近年来得到了显著的普及。SSMs为序列建模提供了一种灵活的方法,在计算效率和模型灵活性之间实现了平衡。受到Mamba在语言任务中成功的影响,越来越多地使用SSMs进行各种视觉任务。这些应用范围从设计通用的 Backbone 模型 到推进图像分割 和合成(如[17])等领域。这些进步突显了Mamba在视觉领域的适应性和潜力。
尽管在长序列建模方面,SSMs具有令人满意的线性复杂度,但直接将SSMs应用于视觉任务只能带来微小的改进,这相对于常见的CNN和视觉Transformer模型。在本文中,作者试图扩大Mamba模型在计算机视觉领域的适用性。作者观察到语言和视觉领域之间的差异可能会在将Mamba应用于后者时带来巨大的障碍。
这些挑战源于图像数据的两个自然特性:
1)图像数据具有严格的2D空间依赖性,这意味着将图像块平铺成序列可能会破坏高级理解。
2)自然视觉信号具有严重的空间冗余性--例如,无关的图像块不会影响物体的表示。为了解决这两个问题,作者开发了一种专用的扫描方法,为视觉Mamba构建1D Token 序列。通常,视觉Mamba模型需要将2D图像转换为1D序列进行处理。
如图1(a)所示,直接将空间数据平铺成1D Token 会破坏自然局部2D依赖关系。LocalMamba通过将图像分割成多个窗口来提高局部表示,如图1(b)所示。每个窗口在单独扫描后,在窗口之间进行遍历,确保相同2D语义区域内的 Token 被紧密地处理在一起。然而,手工制作的窗口分割缺乏处理不同物体尺度的灵活性,并且无法忽略信息较少的区域。

在本研究中,作者提出了一种名为QuadMamba的新的Mamba架构,该架构通过关注更多具有信息性的区域来提高局部表示,从而实现局部感知序列建模的改进。如图1(c)所示,QuadMamba的核心在于可学习的窗口划分,该划分能够自适应地以粗粒度到细粒度的方式建模局部依赖关系。作者提出在视觉Mamba模型中的多个轻量级预测模块,用于评估每个空间 Token 的局部邻接关系。得分最高的四分之一区域进一步以递归的方式分割为子四分之一区域进行细粒度扫描,而其他区域(可能包含信息性较弱的 Token )保持粗粒度。这一过程导致了从二维图像特征中分得的不同粒度的窗口四分之一区域。
值得注意的是,直接从基于索引的二维窗口图像特征中进行采样是非可微分的,这使得学习窗口选择变得不可行。为了解决这个问题,作者采用了Gumbel-Softmax,从分区间得分映射中生成一个序列 Mask 。然后,作者使用全可微分运算符(即Hadamard乘法和逐元素求和),从序列 Mask 和局部窗口构造一维 Token 序列。这导致了端到端可训练的流水线,计算开销可以忽略不计。对于跨越两个相邻四分之一窗口的有用 Token ,作者在连续块中应用了全方位位移方案。在两个方向上移动二维图像特征允许四分之一窗口分区间在任意位置出现的目标建模更加灵活。
1 相关工作
Generic Vision Backbones
卷积神经网络(CNNs)[10; 30; 31]和视觉 Transformer (ViT)[7]是计算机视觉领域两种主导的后备网络。它们在广泛的计算机视觉任务中,包括但不局限于图像分类[29; 53; 55; 20; 23; 21; 74; 4; 12],分割[44; 19],目标检测[36; 79],视频理解[28; 76],生成[11]等方面,都证明了自己是通用的视觉 Backbone 网络。与CNNs的受限制的感知域不同,视觉 Transformer (ViT)[7; 42; 61]从语言任务中借用,在全局上下文建模方面具有优势。后来,为了更好地适应视觉领域,提出了许多视觉特定的修改,如引入层次特征[42; 61],优化训练[58],以及将CNN元素集成[5; 54]。因此,视觉 Transformer 在各种视觉应用中表现出色。然而,这以注意力操作的平方时间复杂度和内存复杂度为代价,尽管提出了[42; 61; 72; 57]的补救措施,但其可扩展性仍然受到阻碍。
近年来,状态空间模型(SSMs)作为一种强大的范式,在语言任务中建模顺序数据。先进的SSM模型与最先进的视觉 Transformer (ViT)架构相比,在性能上甚至更优,同时具有线性复杂度。它们在视觉任务上的初步成功,更重要的是,惊人的计算效率,暗示了SSM作为CNN和Transformer的有前途的通用后端替代品的潜力。
2 State Space Models
状态空间模型(SSMs)[16; 15; 18; 35] 是一类用于序列建模的完全循环架构。最近的研究 使得 SSMs 的性能达到了 Transformer Level ,同时其复杂度呈线性增长。作为一项重大突破,Mamba [13] 革新了传统的 SSM,采用了输入相关的参数化方法,并支持可扩展的、面向硬件优化的计算,使其在涉及顺序 1D 数据的多种任务中,与高级 Transformer 模型相媲美或表现更优。
随着Mamba的成功,ViM [80]和VMamba [41]将Mamba的1D扫描转换为双向和四向的2D交叉扫描,以便处理图像。此后,SSMs已迅速应用于视觉任务(语义分割[51; 65; 46],目标检测[26; 3],图像修复[17; 52],图像生成[9],等)以及其他模态的数据(例如,视频[67; 32],点云[40; 73],图[2],以及跨模态学习[60; 6]。
在将Mamba适应非一维数据时,一个基本考虑因素是设计一个路径,该路径遍历并映射所有图像块到一个SSM友好的1D序列。在这个方向上,初步的工作包括ViM中的双向ZigZag扫描[80],VMamba中的4个方向交叉扫描[41],以及PlainMamba和ZigMa中的蛇形扫描[66;22],这些工作都是在高度和宽度轴所覆盖的空间域中进行的。其他工作[52;75;33]将扫描扩展到额外的通道[52;33]或时间[75;33]维度。然而,这些扫描策略在遍历块时忽视了空间局部性的重要性。LocalMamba[26]部分地缓解了这一固有弱点,它将块分成窗口并在每个窗口内进行遍历。
然而,由于整个图像域的单一致局部细粒度,由任意的窗口大小控制,很难确定最优粒度。LocalMamba选择DARTS [38]以分别搜索每个层的最佳窗口大小和最佳扫描方向,这使得方法变得更加复杂。另一方面,所有现有方法都涉及硬编码的扫描策略,这些策略可能是次优的。与所有这些方法不同,本文引入了一种可学习的四叉树结构来扫描具有不同局部细粒度的图像块。
3 Preliminaries
状态空间模型(SSMs)[16;15;18;35]本质上是一种线性时不变系统,它通过隐藏状态 (序列长度 和状态大小 )将一维输入序列 循环映射到输出响应序列 (其中 和

其中, 矩阵 包含了演化参数; 和 是投影矩阵。然而, 在实际中, 通过零阶保持 (ZOH) 规则[16], 方程 1 通常被转化为离散形式[18], 其中 的值在样本间隔

在上述内容中, 和 是 和 的离散表示: , 并且 . 为实现高效计算, 方程 2 中的迭代计算可以并行执行, 同时进行全局卷积操作。

其中 表示卷积运算符,
选择状态空间模型(S6)。 传统状态空间模型(SSMs)具有输入无关的参数。为了改进这一点,提出了选择状态空间模型(S6)或“Mamba”,它们具有输入相关的参数,使得 和 变得可学习。为了弥补并行性困难,还进行了硬件感知的优化。在本工作中,作者特别研究了Mamba架构在视觉任务中的有效适应性。
早期的工作,如ViM [80]和V Mamba [41],通过将2D图像转换为以光栅扫描方式的一维序列来探索直观的适应性。作者认为简单的光栅扫描并不是最优设计,因为它破坏了图像的局部邻域。在作者的工作中,提出了一种基于四叉树的新颖可学习扫描方案。
4 Method
General Architecture
QuadMamba 共享了与许多卷积神经网络(CNNs)[20; 64; 23]和视觉 Transformer (Vision Transformers) 相似的多尺度背身设计。如图2所示, 一张大小为 的图像首先被分割成大小为 的patch, 从而得到 个视觉tokens。一个线性层将这些视觉tokens映射到具有维度
与在语言建模中使用的Mamba结构不同, QuadVSS块遵循了 Transformer 块的流行结构 , 68], 如图2(b)所示。QuadMamba由四个阶段的QuadVSS块组成,其中阶段 有

Quadtree-based Visual State Space Block
如图2所示,作者的QuadVSS块采用了视觉Transformer的元架构[68],由一个 Token 运算符、一个 FFN (FFN)和两个残差连接组成。Token 运算符包括一个位移模块、一个分区映射预测器、一个基于四叉树扫描器和一个Mamba Layer。在 Token 运算符内部,一个轻量级预测模块首先在特征 Token 上预测一个分区映射。四叉树策略然后通过递归地将二维图像空间分成四个象限或窗口来对它进行细分。根据粗粒度分区映射的得分,跳过较不具有信息量的细粒度子窗口。
因此,一个多尺度、多粒度的1D Token 序列被构建,在更具有信息量的区域捕获更多的局部性,同时保留其他区域的全球上下文建模。QuadVSS块的关键组件如下:
分区映射预测。图像特征 ,包含 个嵌入 Token,首先被投影为得分嵌入

φs 是一个轻量级的 Projector ,具有规范线性 GELU 层。为了更好地评估每个 Token 的局部性,作者利用每个象限内的本地嵌入和上下文信息。具体而言,作者首先在通道维度上对 xs 进行拆分,得到局部特征 xs^local 和全局特征 xs^global:

因此, 作者得到了聚合得分嵌入 , 并将其输入到线性 GELU 层 中, 用于预测分段得分:where Interpolate 是双线性插值运算符,将上下文向量插值到空间大小为
从而, 作者得到了聚合得分嵌入 , 并将其输入到线性 GELU 层

其中 表示在空间坐标 的 Token 的配分。基于四叉树(Quadtree)的窗口划分。在预测每个特征 Token 的划分得分
四叉树基策略将图像特征在粗粒度 Level 划分为 个子窗口, 在细粒度 Level 划分为
因此, 作者选择在粗粒度 Level 具有最高平均局部邻域得分的顶点

其中, 包含在粗粒度窗口和细粒度窗口中的样本,并发送到 SS2D 块进行序列建模。
为了考虑最具有信息量的 Token 跨越相邻的两个窗口四分之一,作者借用了Swin Transformer [42]中的移位窗口方案。不同之处在于,Swin Transformer在窗口内的每个 Token 内部都忽略了空间局部性,而Mamba窗口内的 Token 序列仍然具有方向性。
因此,在后续的VSS模块中,作者添加了额外的移位方向,如图4所示,与Swin Transformer中只有一个方向移位相比。

Model Configuration
值得注意的是,QuadMamba模型的容量可以通过调整输入特征维度和(Q)VSS层数量来定制。在本研究中,作者构建了四种具有不同容量的QuadMamba架构变体,分别为QuadMamba-Li/T/S/B:
值得注意的是,QuadMamba-S在目标检测上比EfficientVMamba-B(一种基于Mamba的 Backbone 网络,以其更高的效率而著称)提高了3.0%的mAP,在实例分割上提高了2.2%,使用相似的参数。此外,QuadMamba-S能够跟上并甚至超越LocalVMamba-T(一种局部Mamba Backbone 网络)的表现,同时避免了表2的复杂性测量所反映的架构和扫描搜索的麻烦。
这些结果表明,QuadMamba可以作为一种实用且功能强大的视觉 Backbone 网络,在计算复杂度、设计成本和性能之间实现平衡。

Semantic Segmentation on ADE20K
如图3所示,在可比的网络复杂度和效率下,QuadMamba相较于基于ConvNet的ResNet-50/101 [20]和ConvNeXt [43],基于Transformer的DeiT [58]和Swin Transformer [42],以及大多数基于Mamba的架构 [80, 49, 66],实现了显著更高的分割精度。
例如,QuadMamba-S在 的mloU下报告了优越的分割精度,超过了Vim-S ( ), LocalVim-S (46.4%), EfficientVMamba-B (46.5%),以及PlainMamba-L2 (46.8%),并且与 VMamba-T (
值得注意的是,LocalMamba是由神经架构搜索(NAS)技术设计的,该技术依赖于数据,并且与其他数据模式和数据源缺乏灵活性。

Ablation Studies
作者从多个角度进行了消融实验来验证QuadMamba设计选择的正确性。除非另有说明,所有实验都使用了QuadMamba-T。
Mamba中局域性的影响。 作者在构建一维 Token 序列时,考虑了粗粒度和细粒度局部性建模对模型性能的影响。具体而言,作者将[80, 41]中的原始窗口无损平铺策略与三个尺度(即28x28、14x14、2x2)的窗口划分(即特征局部性的三个粒度 Level )进行了比较。在实际中,作者将QuadMamba-T模型中的QuadVSS块替换为[41]中的简单VSS块。
为了排除填充操作的负面影响,作者在第一个模型阶段只划分了空间尺寸为56x56的特征。如表4所示,原始扫描策略导致与采用窗口扫描相比,目标检测和实例分割性能显著降低。局部窗口的规模也显著影响了模型性能,这表明在给定图像分辨率的情况下,太大的或太小的窗口可能是次优的。

基于四叉树的分区分辨率。作者探讨了在双层四叉树分区间策略中分区分辨率的选取。表格5中配置的分区分辨率在第一阶段两个模型中应用,特征分辨率为{56×56, 28×28, 14×14}。实验中作者推导出粗粒度窗口和细粒度窗口的最优分辨率为{1/2, 1/4}。这种手工配置的设置可能在未来的工作中被更灵活和可学习的设置所替代。
分层模型阶段的层模式 作者研究了在分层模型 Pipeline 中的层模式设计选择。从图5可以看出,层模式LP2在减少了0.2%的准确率上超过了层模式LP1。这可能是因为局部建模效果在较浅的阶段比在较深的阶段更明显,以及第三阶段的填充操作产生了负面影响。LP3在第一和第二阶段将QuadVSS模块以交错方式放置,实现了最佳性能,并作为作者的模型设计。

必要性多向窗口平移。与Swin Transformer [42]中的单向平移不同,图5显示了在添加互补平移方向时,准确率提高了0.2%。这可以预见,因为Transformer中的注意力是非因果的,而Mamba中的一维序列具有因果性质,因此它们对相对位置非常敏感。在处理信息区域跨越相邻窗口的情况时,多向平移操作也是必不可少的。图6进一步可视化了在不同层级的层次结构中学习的细粒度四象限中的平移,这些四象限在不同层适当地关注不同的空间细节。
每个阶段使用的(Quad)VSS模块数量 作者进行了实验来评估每个阶段不同数量(Quad)VSS模块的影响。表6呈现了遵循图5中设计规则LP3的四个配置,固定通道维度为96。作者发现,庞大的第二或第四阶段会导致与第三阶段设计相比性能下降,而将(Quad)VSS模块在第二和第三阶段之间分配得更加均匀,可以获得与有利的复杂性相当甚至更好的性能。这些证据可以作为未来模型设计的一条基本规则,尤其是在模型扩展时。

6 Conclusion
在本文中,作者提出了一种名为QuadMamba的视觉Mamba架构,作为一种通用且高效的后端,用于诸如图像分类和密集预测等视觉任务。
QuadMamba通过可学习的四叉树扫描有效地捕获了不同粒度的局部依赖关系,同时适应地保留了图像数据的固有局部性,且计算开销极低。
QuadMamba的有效性已经通过大量实验和消融研究得到证明,其性能优于流行的卷积神经网络(CNNs)和视觉 Transformer (ViTs)。
然而,QuadMamba的一个局限性是窗口分级的深度尚未探索,这可能特别适用于处理密集预测视觉任务和高分辨率数据,如遥感图像。细粒度分区的区域刚性且缺乏针对任意形状和大小的区域的灵活性,这留待作者未来研究。
作者希望作者的方法能激发进一步将Mamba应用于更多样化和复杂的视觉任务的研究。
#天工大模型4.0
国产大模型首发中文逻辑推理,o1版来了
没想到,技术发展得竟然这么快。最近,人们已经开始畅想 AI 时代后的生活了。
上周末,摩根大通 CEO 杰米・戴蒙(Jamie Dimon)表示,由于人工智能技术,未来几代人每周可以只工作三天半,活到一百岁。
一些研究认为,生成式 AI 等技术可以让目前占用人们工作时间 60-70% 的任务实现自动化。这些变革需要的技术从何而来?那一定是突破性 AI,有人整理出了各位 AI 领域大佬对通用人工智能(AGI)出现时间的预测。DeepMind 的哈萨比斯就认为,我们距离 AGI 的出现还差两到三个重大技术创新。
像 OpenAI CEO 山姆・奥特曼,甚至认为 AGI 明年就会出现。想来想去,如此自信的原因可能在于最近人们让大模型学会了「推理」的方法。
就在 9 月份,OpenAI 正式公开前所未有的复杂推理大模型 o1,这是一个重大突破,新模型既具有通用的能力,也可以解决比此前的科学、代码和数学模型能做到的更难问题。实验结果表明,在绝大多数推理任务中,o1 的表现明显优于 GPT-4o。

o1 在具有挑战性的推理基准上比 GPT-4o 有了很大的改进。
OpenAI 为大模型的能力开启了新方向:「能不能像人一样思考与推理」已经成为了评判它们能力的重要指标。厂商发布的新模型要是不带点思维链,恐怕都不好意思拿出手了。
不过直到如今,o1 的正式版仍然迟迟没有推出。AI 社区尤其是国内大模型公司正在向 o1 的霸主地位发起冲击,并开始在一些权威评测中取得领先。
今天,国内首款具备中文逻辑推理能力的 o1 模型来了,它便是由昆仑万维推出的「天工大模型 4.0」 o1 版(英文名:Skywork o1)。这也是近一个月来,该公司在大模型及相关应用上的第三次大动作,此前天工 AI 高级搜索、实时语音对话 AI 助手 Skyo 先后亮相。
自即日起,Skywork o1 将开启内测,想要体验的小伙伴赶紧申请起来了。
申请地址:www.tiangong.cn
三款模型并举
角逐推理新战场
此次,Skywork o1 包含了以下三款模型,既有回馈开源社区的开放版本,也有能力更强的专用版本。
其中,开源版本的 Skywork o1 Open 参数为 8B,在各项数学和代码指标上实现显著提升,并将 Llama-3.1-8B 的性能拉到同生态位 SOTA,超越了 Qwen-2.5-7B instruct。同时,Skywork o1 Open 还解锁了 GPT-4o 等更大量级模型无法完成的数学推理任务(如 24 点计算)。这也为推理模型在轻量级设备上的部署提供了可能性。


另外,昆仑万维还将开源两个针对推理任务的 Process-Reward-Model(PRM),分别是 Skywork o1 Open-PRM-1.5B 和 Skywork o1 Open-PRM-7B。此前开源的 Skywork-Reward-Model 仅能对整个模型回答打分,而 Skywork o1 Open-PRM 可以细化到对模型回答中的每个步骤进行打分。
相较于开源社区现有的 PRM,Skywork o1 Open-PRM-1.5B 能达到 8B 的模型效果,例如RLHFlow 的 Llama3.1-8B-PRM-Deepseek-Data、OpenR 的 Math-psa-7B。Skywork o1 Open-PRM-7B 更强,能同时在大部分基准上接近甚至超越 10 倍量级的 Qwen2.5-Math-RM-72B。
据介绍,Skywork o1 Open-PRM 还是第一款适配代码类任务的开源 PRM。下表为以 Skywork-o1-Open-8B 作为基础模型,使用不同 PRM 在数学和代码评测集上的评估结果。


注:除 Skywork-o1-Open-PRM 外,其他开源 PRM 均未针对代码类任务上进行专门优化,故不进行代码任务的相关对比。
详细技术报告也将在不久后发布。目前模型和相关介绍已在 Huggingface 开源。
开源地址:https://tinyurl.com/skywork-o1
Skywork o1 Lite 具备了完整的思考能力,达到了更快的推理与思考速度,在中文逻辑和推理、数学等问题上表现尤为突出。Skywork o1 Preview 是此次完整版推理模型,搭配自研的线上推理算法,对比 Lite 版本可以呈现更多样和深度的思考过程,做到了更完善和更高质量的推理。
也许你会问,当前复现 o1 模型的工作都在推理层面下足了功夫,Skywork o1 又有什么与众不同呢?
昆仑万维表示,该系列模型在模型输出上内生了思考、计划和反思等能力,在慢思考中一步步地进行推理、反思与验证,解锁了「深思熟虑」等典型的进阶版复杂人类思考能力,确保了回答的质量和深度。
当然,Skywork o1 的成色如何,我们还是得看实战效果。
一手实测
这次 Skywork o1 彻底拿捏住了推理
提前拿到了测试资格,对 Skywork o1 系列模型,尤其是 Lite 和 Preview 版本的推理能力进行了全方位的考察。下图为 Skywork o1 Lite 的界面展示。

我们先让 Skywork o1 Lite 自报家门,可以看到,模型并没有直接给出答案,而是将包括问题定位、自我能力剖析等在内的完整思考过程直观展现给用户,并且会显示思考时间,这也是如今推理模型的显著特点。

接下来正式进入测试环节,我们搜罗了各种类型的推理问题,看究竟能不能绕晕 Skywork o1。
比大小、数「r」问题,不再翻车
此前,大模型在面对一些看起来非常简单的比大小、数数问题时往往翻车。现在这些问题再也难不倒 Skywork o1 Lite 了。
在比较 13.8 与 13.11 孰大孰小时,Skywork o1 Lite 给出了完整的思维链路,找出解题的关键在于小数位大小。同时模型还自我反思,二次检查自己得出的结论,并提醒容易答错的点。

同样地,在正确回答「Strawberry 中有多少个 “r”?」时,Skywork o1 Lite 也是思考、验证、确认的完整链路。

在回答具有扰乱项的问题时,Skywork o1 Lite 很快厘清思路,不受干扰因素的影响。
玩转脑筋急转弯,不陷入语言陷阱
大模型有时会被中文语境下的脑筋急转弯问题搞糊涂,导致给出错误的答案。这次 Skywork o1 Lite 可以轻松拿下这类问题。

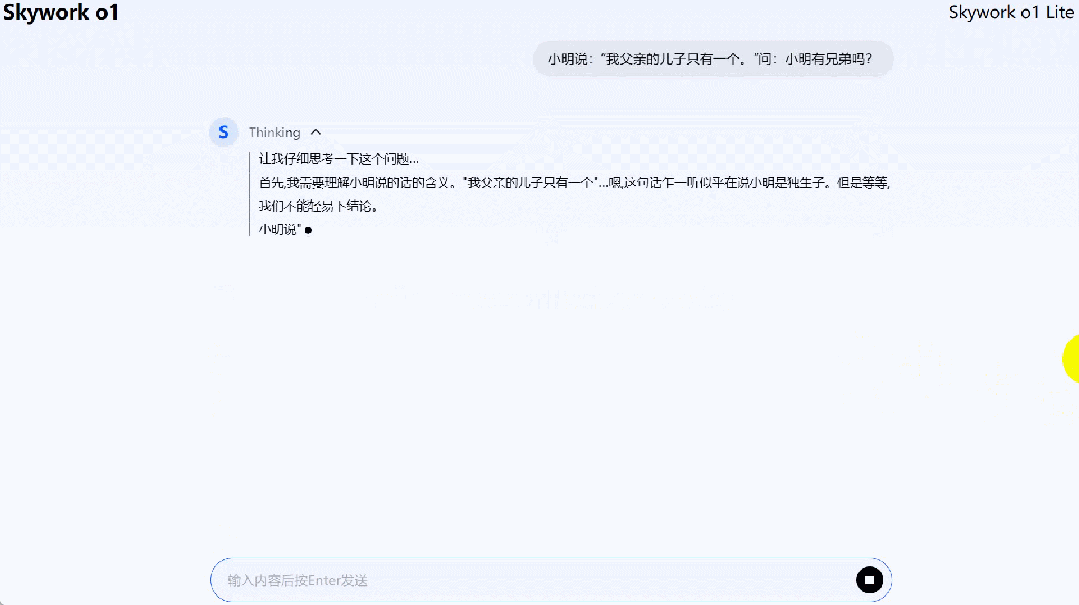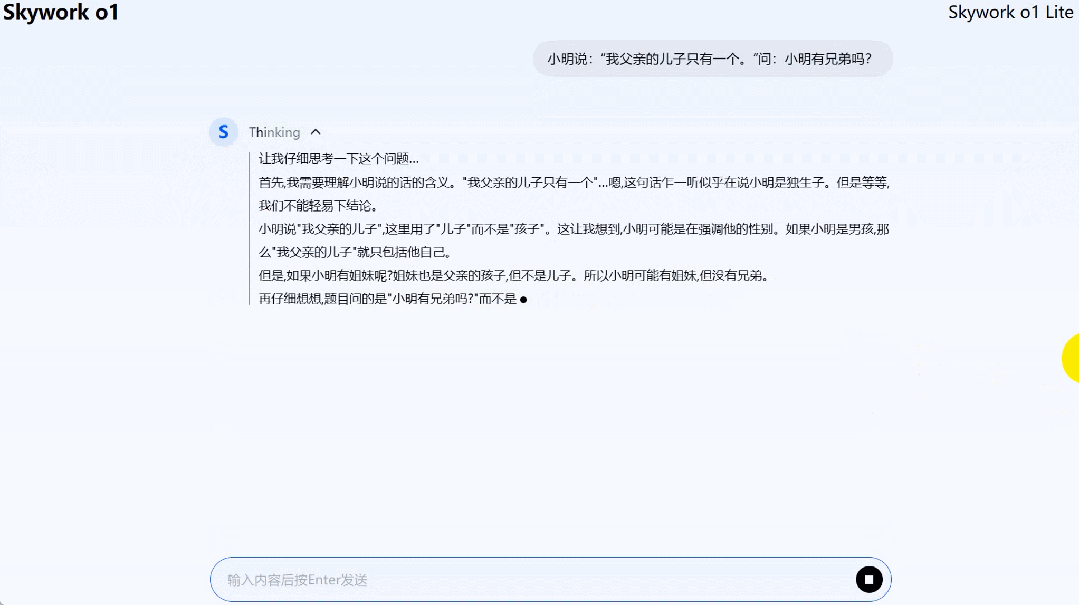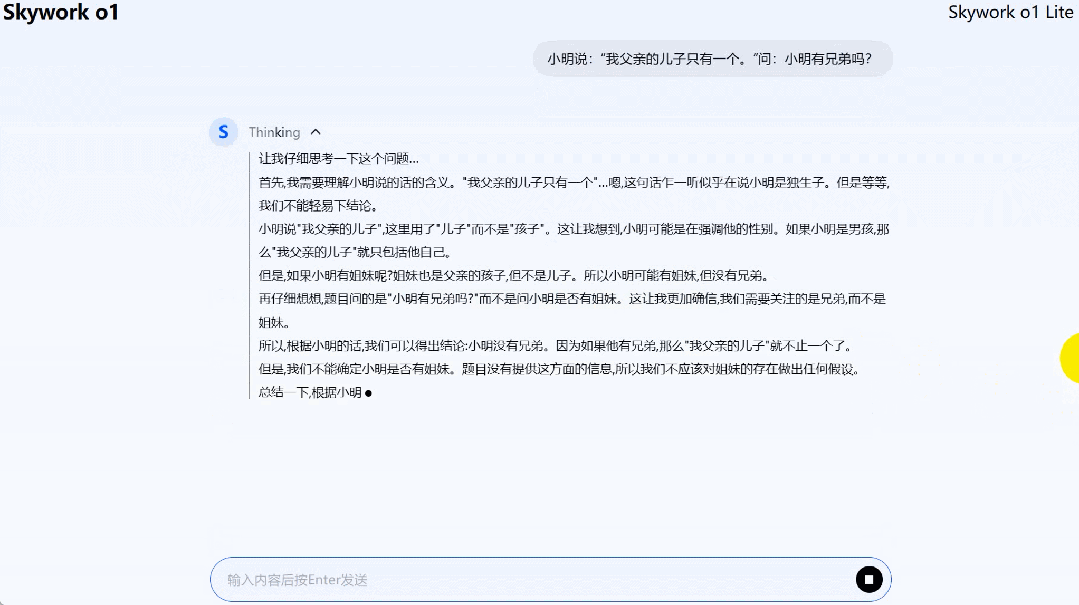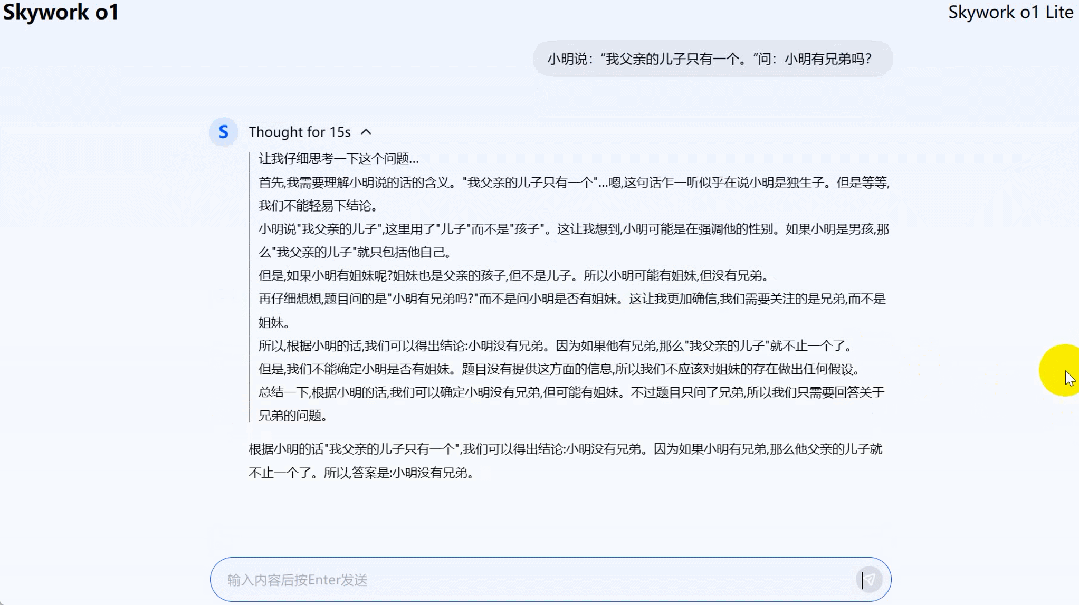
两对父子只钓到三条鱼,却每人都分到了一条,Skywork o1 Lite 能弄明白是怎么回事。

掌握各种常识,告别智障属性
大模型能不能在常识推理层面接近人类水平,是提高其自身可信度、增强决策能力、拓展多领域应用的重要指标之一。Skywork o1 Lite 和 Preview 在这点上都表现不错。
比如长度(英寸、厘米、码)与质量单位(公斤)的区分。

比如盐水冰块为什么比纯水冰块更容易融化。

再比如一个人站在完全静止的船上,当向后跳跃时船向前运动。Skywork o1 Lite 解释清楚了现象背后的物理知识。
化身做题小能手,高考题也不在话下
数学推理是解决复杂任务的基础能力,具备强大数学推理能力的大模型有助于用户高效地解决跨学科复杂任务。
在求解序列问题「2, 6, 12, 20, 30... 这个序列的第 10 项是多少?」时,Skywork o1 Lite 观察数字排列特点、找到规律、验证规律,最终给出了正确答案。

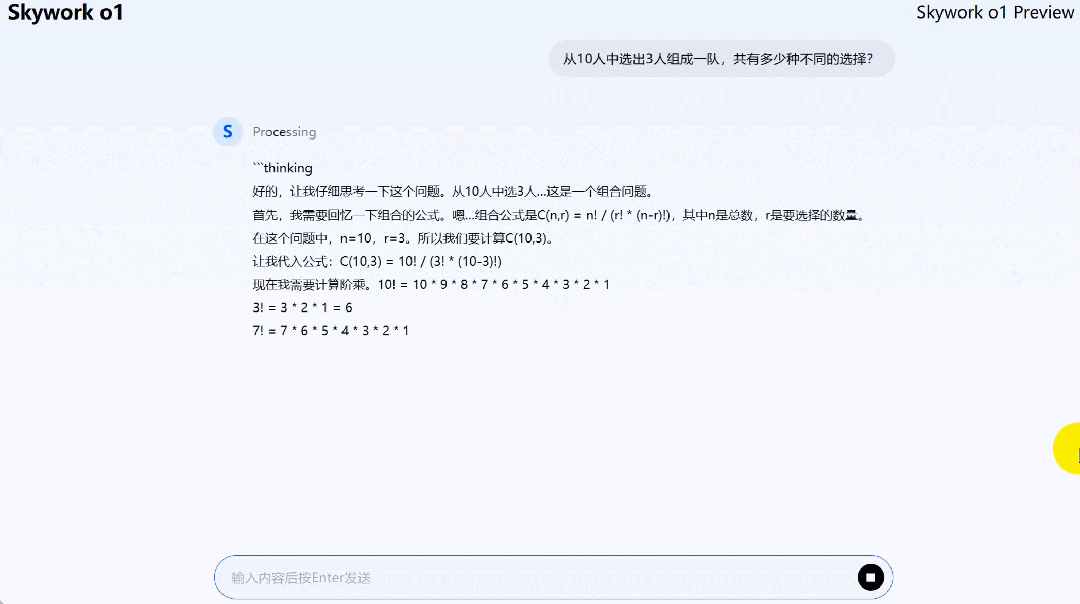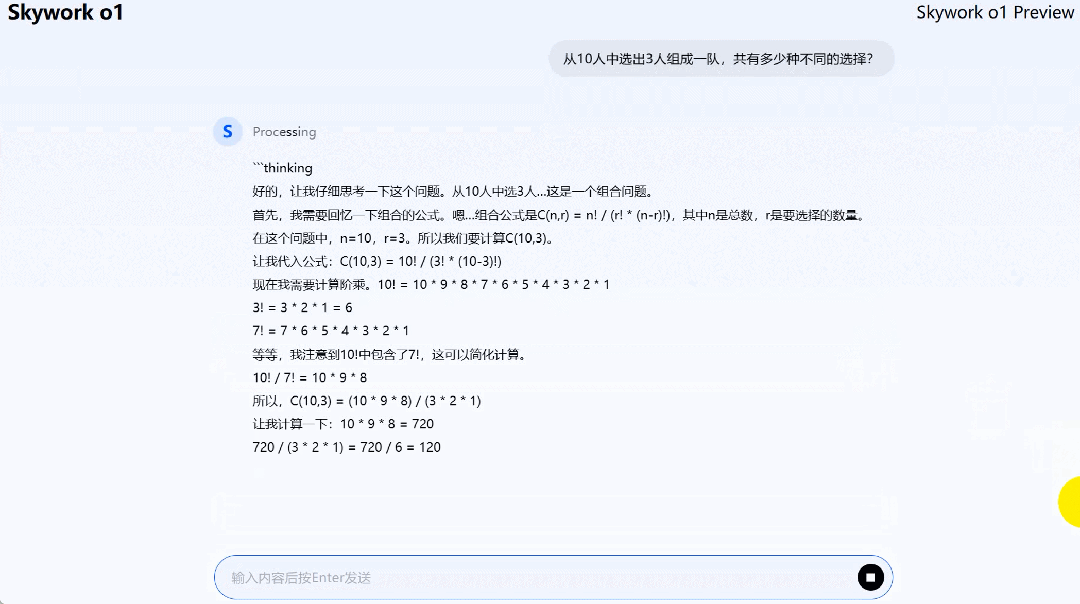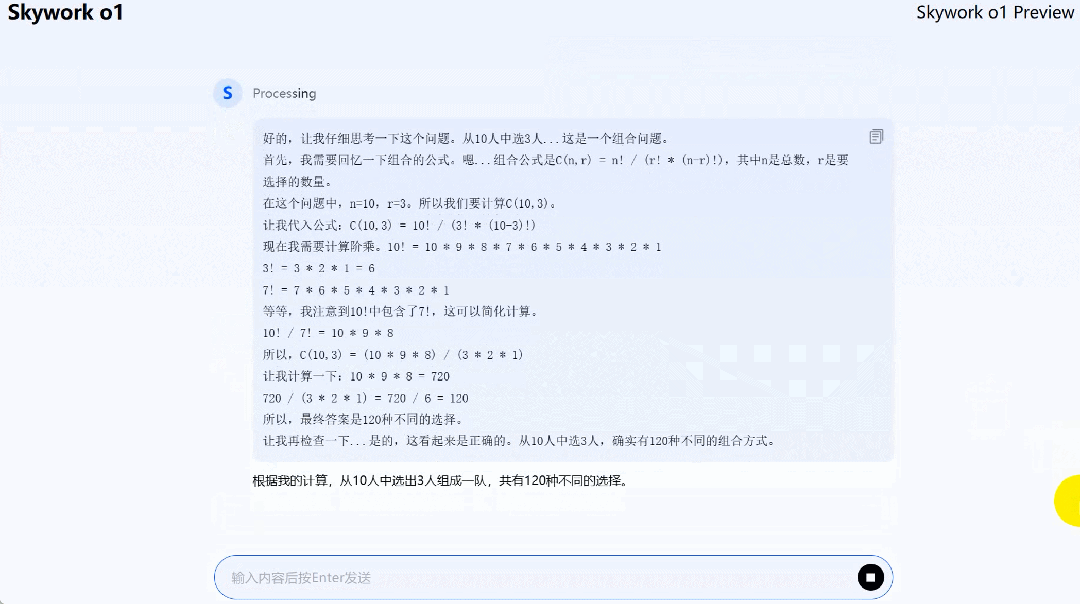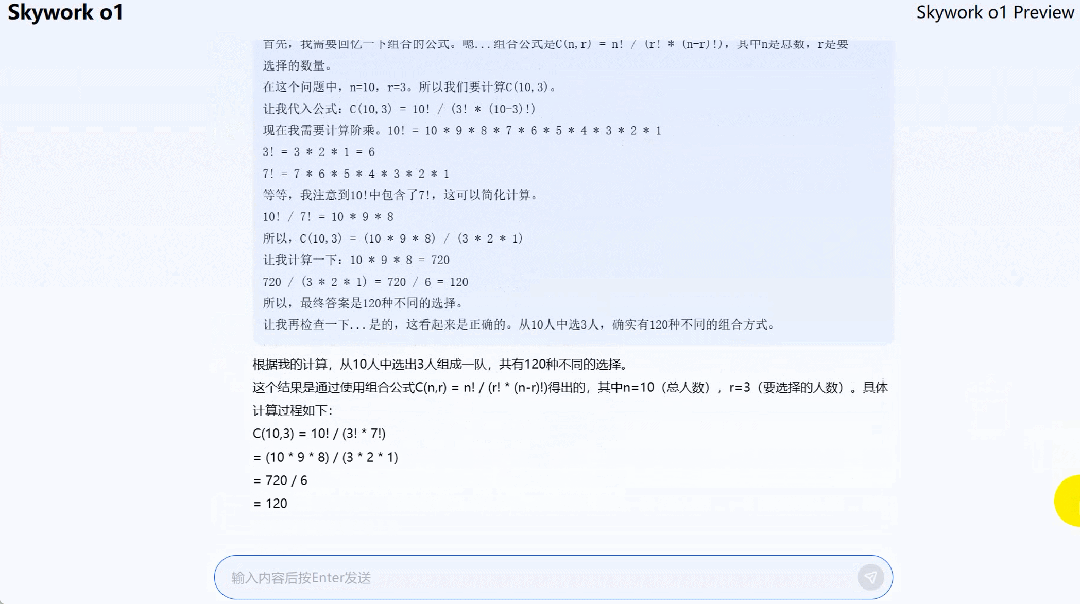
在求解组合(从 10 人中选出 3 人组成一队,共多少种选择)问题时,Skywork o1 Preview 在全链路思考过后,答案正确。
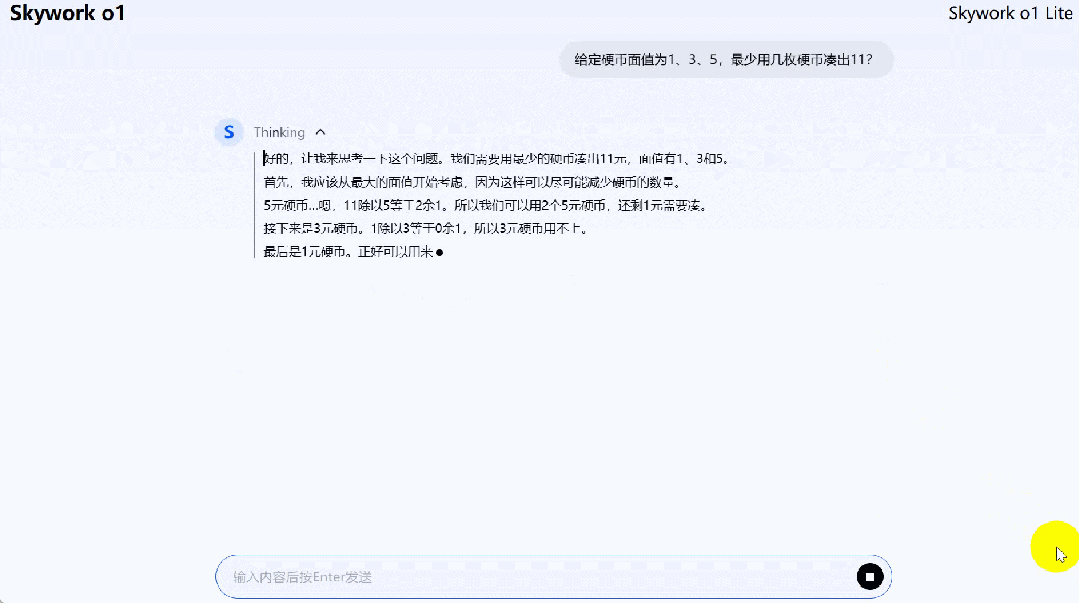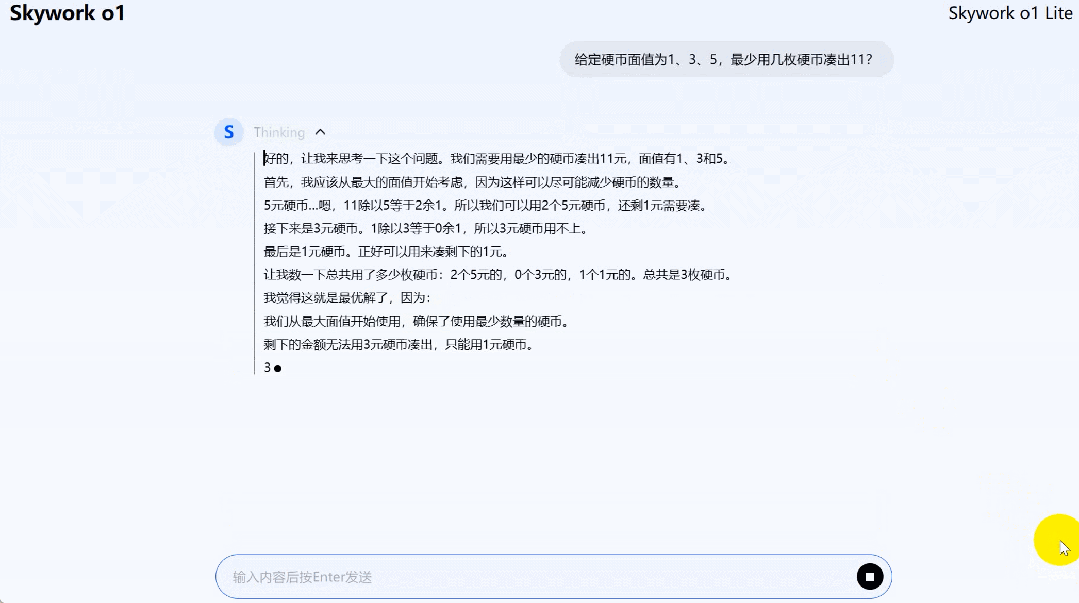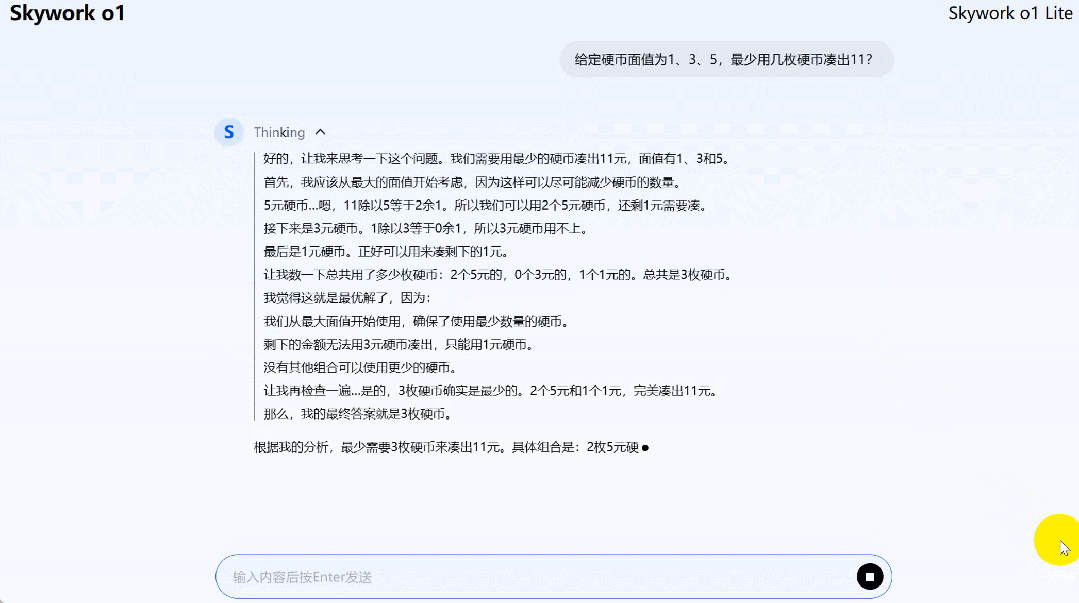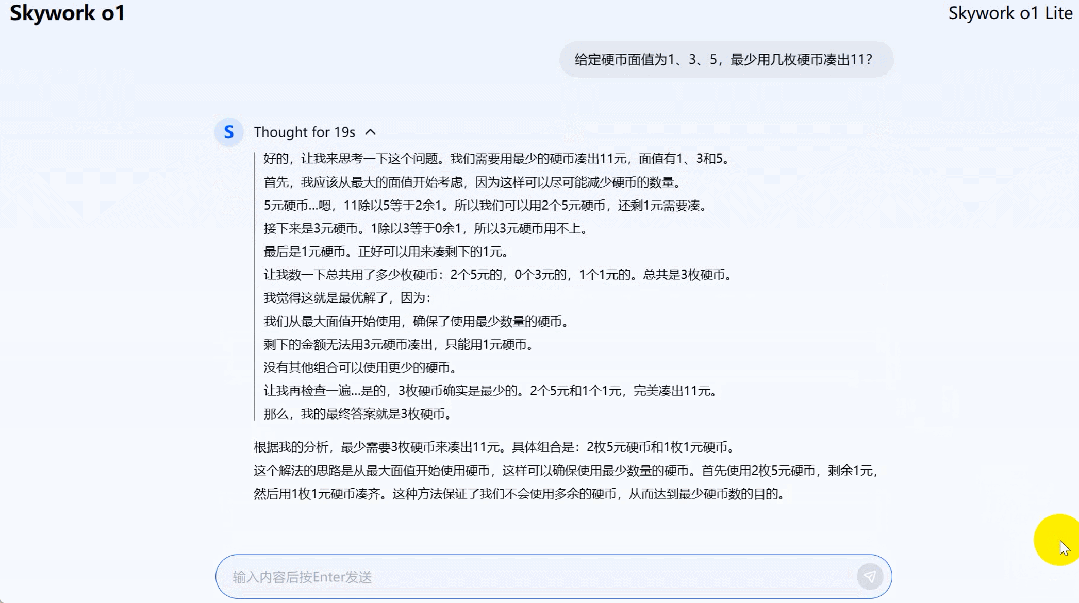
再来一道动态规划(硬币面值 1、3、5,最少几枚硬币凑出 11?)问题,Skywork o1 Lite 给出了最优解。
我们接下来给 Skywork o1 Lite 上上难度,考它两道高考数学题,题目出自 2024 年高考全国甲卷数学(文)。
首先是一道概率题(甲、乙、丙、丁四人排成一列,丙不在排头,且甲或乙在排尾的概率是多少),Skywork o1 Lite 很快给出了正确答案。

然后是函数题(

),Skywork o1 Lite 解题思路、答案一气呵成。

心思缜密,逻辑思辨能力很强
大模型的逻辑推理是实现更强通用人工智能的核心能力之一,而 Skywork o1 Lite 在解答这类问题时颇有心得。比如经典的说谎问题,Skywork o1 Lite 从逻辑自洽的角度分辨出谁说实话、谁在说谎。

对于悖论问题,Skywork o1 Lite 也没有被蒙蔽头脑。

面对道德困境,做到不偏不倚
伦理决策很大程度上是保证人工智能安全发展、遵守社会道德规范、增强用户信任与接受度的重要因素,大模型更要谨言慎行。
关于「救老婆还是救老妈」这个千古难题,Skywork o1 Lite 没有给出绝对答案,而是权衡利弊,并给出了合理的建议。

还有「救多救少」的两难取舍问题,Skywork o1 Preview 也没有轻易下结论,而是提出了一些更深层次的思考。

弱智吧考验,也能 hold 住
弱智吧问题常常用来考验大模型的智力水平,Skywork o1 Lite 能够轻松应答这类问题,比如高考满分 750、考上 985 的区别。

再比如「午餐肉能不能在晚上吃」,Skywork o1 Lite 显然没有受到食物名称的误导。

代码问题也能搞定
Skywork o1 Lite 能够解决一些代码问题,比如 LeetCode 上的孤岛个数(Number of islands)问题。
题目为「给定一个 2 维网格图,其中 “1”(陆地) 和 “0”(水),计算岛屿的数量。岛屿被水包围,通过水平或垂直连接相邻的陆地形成,你可以假设网格的四边都被水包围着。」
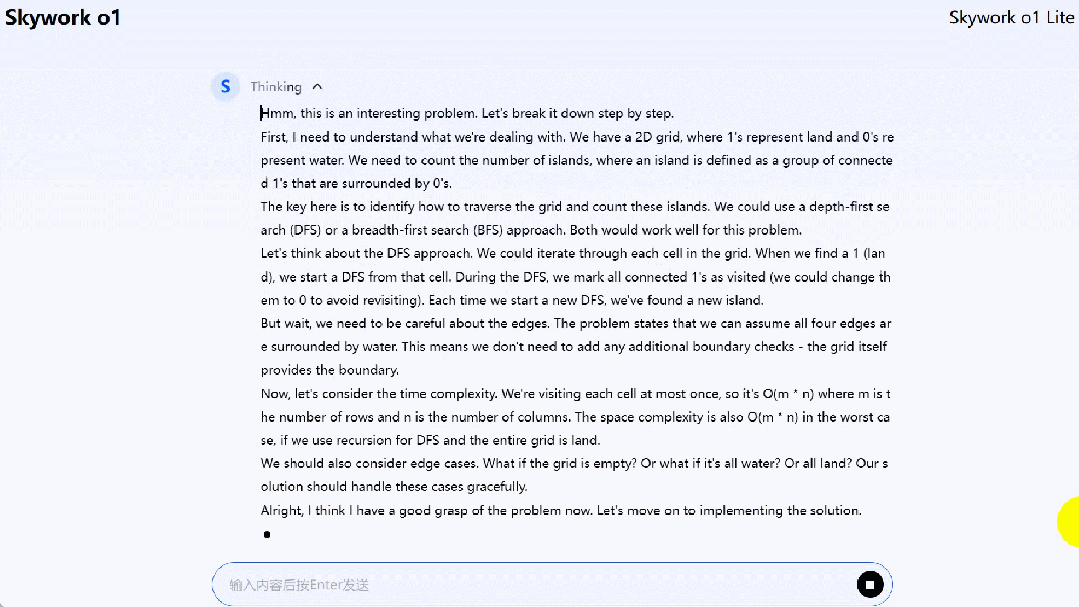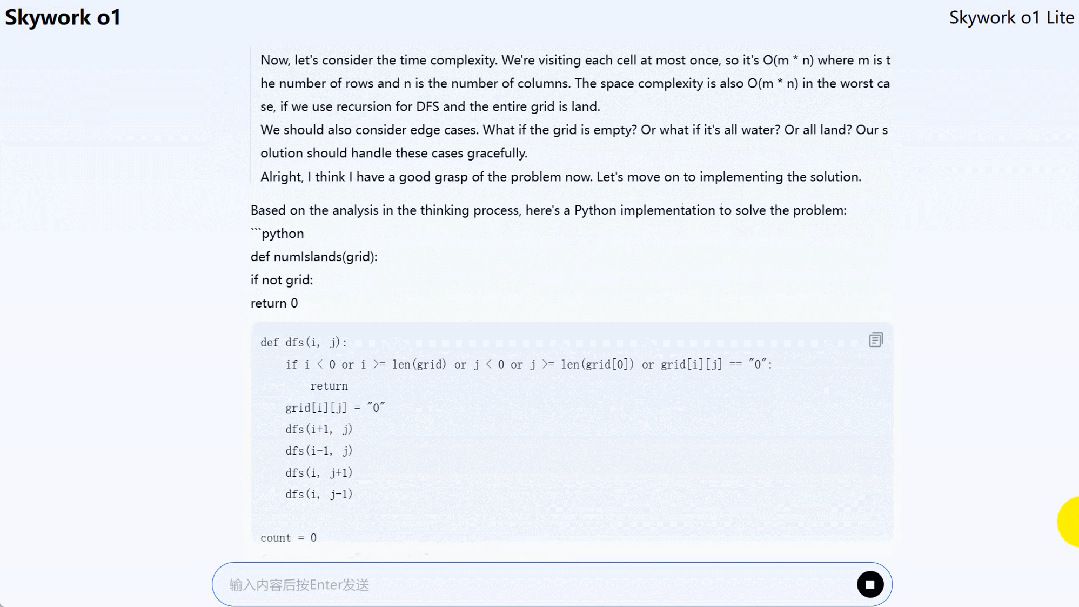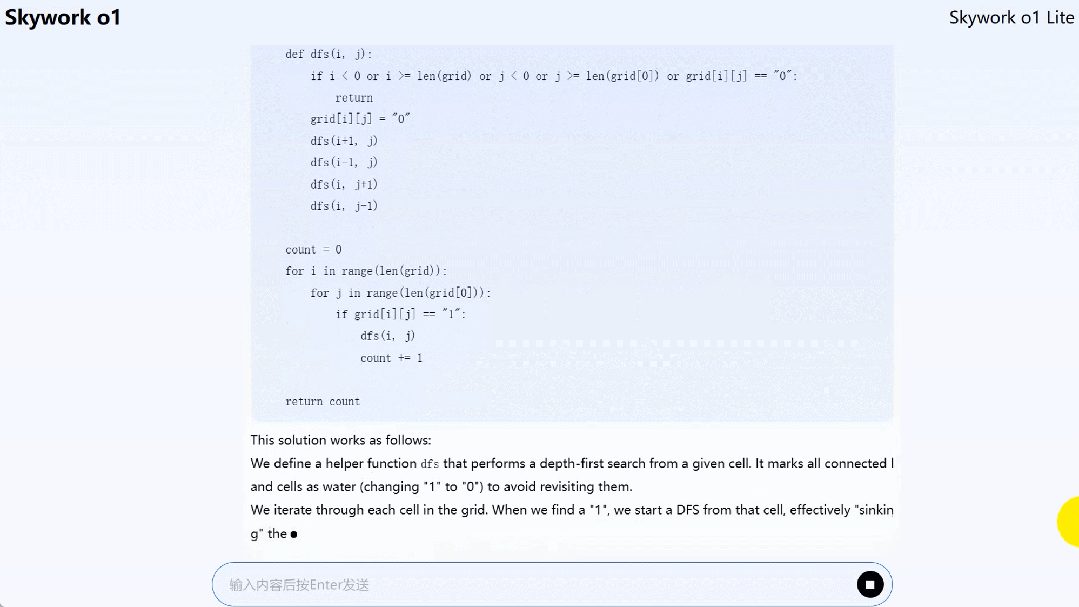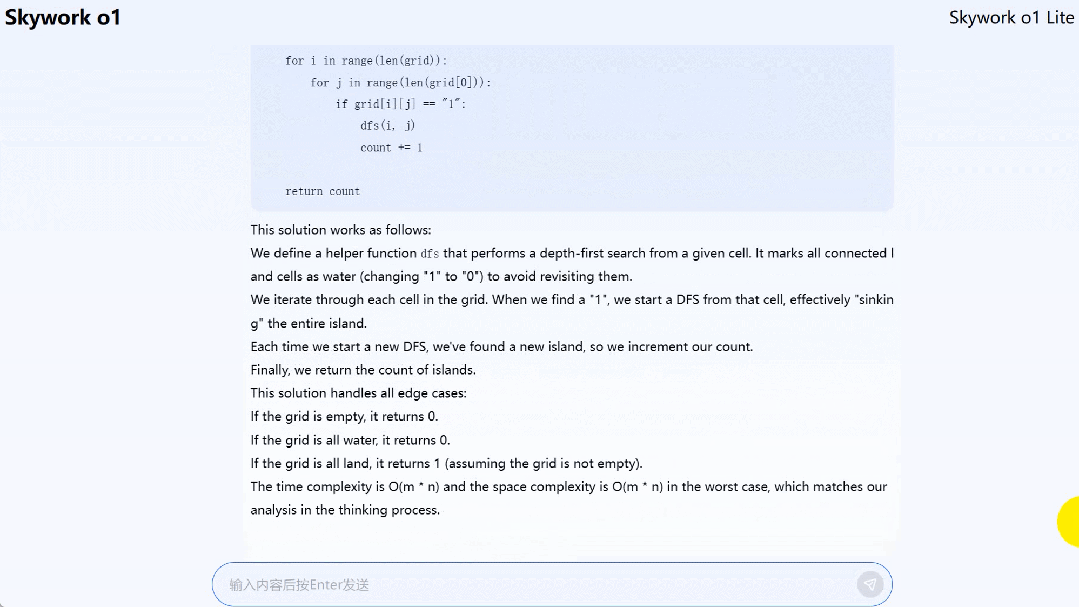
到这里,我们可以下一波结论了:
一方面,以往大模型经常翻车的「小」问题,在推理能力加持下的 Skywork o1 眼里都是小菜一碟。另一方面,通过完整的思考与规划、自我反思以及自我验证链路,Skywork o1 在复杂问题场景同样具备缜密的思辨能力,可以更加准确、高效地输出结果。
如此一来,相较以往强得多的推理能力将激发 Skywork o1 在更多样垂类任务和领域的应用潜力,尤其是容易翻车的逻辑推理和复杂的科学、数学任务。同时上线天工之后,也势必将进一步优化在创意写作等高质量内容生成与深度搜索领域的任务效果。
国产 o1 模型
自研技术驱动
此前,我们已经见证过昆仑万维提出的一系列生成式 AI 垂直类应用,包括但不限于搜索、音乐、游戏、社交、AI 短剧等方向。在这背后,在大模型基础技术的研发上,昆仑万维早有布局。
自 2020 年起,昆仑万维开始持续加码 AI 大模型投入,ChatGPT 刚上线一个月后,该公司就发布了自己的 AIGC 模型系列。在很多垂直领域,昆仑万维都已经推出了应用,包括全球首款 AI 流媒体音乐平台 Melodio、AI 音乐创作平台 Mureka、AI 短剧平台 SkyReels 等等。
在基础技术层面上,昆仑万维目前已经构建起「算力基础设施 — 大模型算法 —AI 应用」的全产业链布局,其中「天工」系列大模型是其核心。
去年 4 月,昆仑万维发布自主研发的「天工 1.0」大模型。到今年 4 月,天工大模型升级到了 3.0 版本,采用 4 千亿级参数 MoE 混合专家模型,并同步选择开源。如今,天工 4.0 版本又基于智能涌现的方法实现了逻辑推理任务上的能力提升。
在技术上,Skywork o1 在逻辑推理任务上性能大幅提升,要得益于天工三阶段自研的训练方案,包括如下:
一是推理反思能力训练。Skywork o1 通过自研的多智能体体系构建了高质量的分步思考、反思和验证数据,并辅以高质量、多样性的长思考数据对基座模型进行继续预训练和监督微调。
二是推理能力强化学习。Skywork o1 团队研发了最新的适配分步推理强化的 Skywork o1 Process Reward Model(PRM),不仅可以有效捕捉到复杂推理任务中间步骤和思考步骤对最终答案的影响,而且结合自研分步推理强化算法进一步加强了模型推理和思考能力。
三是推理 planning。基于天工自研的 Q * 线上推理算法配合模型在线思考,并寻找最佳推理路径。这也是全球首次将 Q * 算法实现和公开,在 MATH 等数据集上可以显著提升 LLM 的推理能力,并降低计算资源的需求。

在 MATH 数据集上,Q * 帮助 DeepSeek-Math-7b 提升至 55.4% 的准确率,超越了 Gemini Ultra。
Q * 算法论文地址:https://arxiv.org/abs/2406.14283
可以看出,昆仑万维的技术已经达到了业界的领先水平,在竞争激烈的生成式 AI 领域,逐渐站稳了一席之地。
相对于目前生成式 AI 应用的百花齐放,在基础技术层面上,研究已经开始走进「深水区」。只有那些经过长期积累的公司,才能构建起改变我们生活的新一代应用。
期待昆仑万维在未来给我们带来更多、更强大的技术。
#Scaling Laws for Neural Language Models
遗憾不?原来百度2017年就研究过Scaling Law,连Anthropic CEO灵感都来自百度
原来早在 2017 年,百度就进行过 Scaling Law 的相关研究,并且通过实证研究验证了深度学习模型的泛化误差和模型大小随着训练集规模的增长而呈现出可预测的幂律 scaling 关系。只是,他们当时用的是 LSTM,而非 Transformer,也没有将相关发现命名为「Scaling Law」。
在追求 AGI 的道路上,Scaling Law 是绕不开的一环。
如果 Scaling Law 撞到了天花板,扩大模型规模,增加算力不能大幅提升模型的能力,那么就需要探索新的架构创新、算法优化或跨领域的技术突破。
作为一个学术概念,Scaling Law 为人所熟知,通常归功于 OpenAI 在 2020 年发的这篇论文:
- 论文标题:Scaling Laws for Neural Language Models
- 论文链接:https://arxiv.org/pdf/2001.08361
论文中详细地论证了模型的性能会随模型参数量、数据量、计算资源增加而指数提升。后来的几年里,OpenAI 作为整个大模型领域的技术引领者,也将 Scaling Law 充分地发扬光大。
但关于我们今天所谈论的 Scaling law,它是怎么被发现的,谁最早发现的,又是哪个团队最早验证的,似乎很少有人去考据。
近日,Anthropic 的 CEO Dario Amodei 在播客中讲述了一个出人意料的版本。

图源:https://xueqiu.com/8973695164/312384612。发布者:@pacificwater
我们可能更了解 Dario 在 2016 年之后的经历。他加入了 OpenAI,担任研究副总裁,负责公司的安全工作,并领导团队开发了 GPT-2 和 GPT-3。
然而,2020 年底,由于对 OpenAI 的发展方向产生分歧, Dario 选择离开,并于 2021 年 2 月与妹妹共同创立了 Anthropic。
如今,Anthropic 推出的 Claude 已成为挑战 GPT 系列霸主地位的最有力竞争者。
不过,Dario 原本的研究方向是神经回路,他第一次真正进入 AI 领域是在百度。
从 2014 年 11 月到 2015 年 10 月,Dario 在百度工作了一年 —— 正好是吴恩达在百度担任首席科学家,负责「百度大脑」计划的时期。
他们当时在研发语音识别系统。Dario 表示,尽管深度学习展示了很大潜力,但其他人仍然充满疑虑,认为深度学习还不足以达到预期的效果,且距离他们所期待的与人类大脑相匹配的框架还有很长的距离。
于是,Dario 开始思考,如果把百度用于语音的循环神经网络做得更大,增加更多的层数会怎样?同时扩大数据量又会怎样呢?
在不断的尝试中,Dario 观察到了随着给模型投入越多的数据、计算和训练,它们的表现就越好,「那时我没有精确地测量,但与同事们一起,我们非常直观地能感受到。」
但 Dario 和同事们也没深究,Dario 觉得:「也许这只对语音识别系统有效,也许这只是一个特定领域的特殊情况。」
直到 2017 年,他在 OpenAI 第一次看到 GPT-1 的训练结果时,他才意识到这种「越多越好」的规则同样适用于语言数据。而计算资源的增加,托起了 Scaling Law 生效的底层逻辑。
真理是不会只属于一个人的,最终它会被每个人发现。
当时有一批人都意识到了 Scaling Law 的存在,比如 Ilya Sutskever、「RL 教父」Rich Sutton、Gwern Branwen。
百度也在 2017 年发了一篇论文:「DEEP LEARNING SCALING IS PREDICTABLE, EMPIRICALLY」,展示了在机器翻译、语言建模、图像处理和语音识别等四个领域中,随着训练集规模的增长,DL 泛化误差和模型大小呈现出幂律增长模式。

《NLP with Transformers》的作者 Lewis Tunstall 发现,OpenAI 在 2020 发表的《Scaling Laws for Neural Language Models》引用了百度论文一作 Joel Hestness 在 2019 年的后续研究,却没发现 Hestness 早在 2017 年就研究过同类问题。

DeepMind 的研究科学家 @SamuelMLSmith 表示,原来在 NeurIPS 和 Hestness 线下交流过。但两年后 Scaling Laws 论文发表时,他对关注过这个问题,但没发论文的自己很生气。

而同期注意到 Scaling Law 的 Gwern Branwen,也经常提起百度的这篇论文确实被忽视了。

百度 2017 年的论文写了啥?
这篇题为「DEEP LEARNING SCALING IS PREDICTABLE, EMPIRICALLY(深度学习扩展的可预测性:经验性研究)」发布于 2017 年。当时,机器学习先驱 Rich Sutton 还没有发布他的经典文章《苦涩的教训》(发布时间是 2019 年)。

论文链接:https://arxiv.org/abs/1712.00409
论文提到,当时,深度学习社区已经通过遵循一个简单的「配方」在不同的应用领域取得了具有影响力的进展。这个「配方」如今大家已非常熟悉,即寻找更好的模型架构、创建大型训练数据集以及扩展计算。
通过分解「配方」,百度的研究者注意到,寻找更好的模型架构困难重重,因为你要对建模问题进行复杂或创造性的重构,这就涉及大规模的超参数搜索。所以,架构方面的创新很多时候要依赖「顿悟」,具有极大的偶然性。如果只把精力放在这上面,风险势必很高。
为了降低风险,百度的研究者提到,「配方」的另外两个部分 —— 创建大型训练集和扩展计算 —— 是非常值得去研究的,因为这两个方面的进展明显更加可控。而且,「只需使用更多数据来训练更大的模型,就能提高准确率」已经成为一个共识。不过,百度想更进一步,分析训练集规模、计算规模和模型准确性提高之间的关系。他们认为,准确预测泛化误差随训练集规模扩大的变化规律,将提供一个强大的工具,以估计推进 SOTA 技术所需的成本,包括数据和计算资源的需求。
在此之前,也有不少研究者进行了类似研究,分析了达到期望泛化误差所需的样本复杂度,但论文中提到,这些结果似乎不足以准确预测实际应用中的误差 scaling 规律。还有一些研究从理论上预测泛化误差「学习曲线」呈幂律形式,即 ε(m) ∝
![]()
。在这里,ε 是泛化误差,m 是训练集中的样本数量,α 是问题的一个常数属性。β_g= −0.5 或−1 是定义学习曲线陡峭度的 scaling 指数 —— 即通过增加更多的训练样本,一个模型家族可以多快地学习。不过,在实际应用中,研究者发现,β_g 通常在−0.07 和−0.35 之间,这些指数是先前理论工作未能解释的。
在这篇论文中,百度的研究者提出了当时最大规模的基于实证的学习曲线特征描述,揭示了深度学习泛化误差确实显示出幂律改进,但其指数必须通过实证进行预测。作者引入了一种方法,能够准确预测随着训练集规模增加而变化的泛化误差和模型大小。他们使用这种方法来估计四个应用领域(机器翻译、语言建模、图像分类和语音识别)中的六个深度神经网络模型的 scaling 关系。
他们的结果显示,在所有测试的领域中都存在幂律学习曲线。尽管不同的应用产生了不同的幂律指数和截距,但这些学习曲线跨越了广泛的模型、优化器、正则化器和损失函数。改进的模型架构和优化器可以改善幂律截距,但不影响指数;单一领域的模型显示出相同的学习曲线陡峭度。最后,他们发现模型从小训练集区域(主要由最佳猜测主导)过渡到由幂律 scaling 主导的区域。有了足够大的训练集,模型将在主要由不可约误差(例如贝叶斯误差)主导的区域达到饱和。

此外,他们还描述了可预测的准确度和模型大小 scaling 的重要意义。对于深度学习从业人员和研究人员来说,学习曲线可以帮助调试模型,并为改进的模型架构预测准确性目标。
百度的研究者在论文中表示,他们的研究结果表明,我们有机会加倍努力,从理论上预测或解释学习曲线指数。在操作上,可预测的学习曲线可以指导一些决策,如是否或如何增加数据集。最后,学习曲线和模型大小曲线可用于指导系统设计和扩展,它们强调了持续扩展计算的重要性。

神经机器翻译学习曲线。

单词语言模型的学习曲线和模型大小结果和趋势。

字符语言模型的学习曲线和模型大小结果和趋势。

ResNet 图像分类任务上的学习曲线和模型大小结果和趋势。

DS2 和注意力语音模型的学习曲线(左),以及不同 DS2 模型尺寸(1.7M ~ 87M 参数)的学习曲线(右)。
关于这篇论文的细节,感兴趣的读者可以去阅读原文。
对于百度而言,早期对 Scaling Law 的研究未能及时转化为广泛的实践应用,这在公司的发展史上或许算得上是一个不小的遗憾。
参考链接:
https://x.com/jxmnop/status/1861473014673797411
https://arxiv.org/abs/1712.00409
#如何在Transformer中实现最好的位置编码
HuggingFace工程师亲授
一个有效的复杂系统总是从一个有效的简单系统演化而来的。——John Gall
在 Transformer 模型中,位置编码(Positional Encoding) 被用来表示输入序列中的单词位置。与隐式包含顺序信息的 RNN 和 CNN 不同,Transformer 的架构中没有内置处理序列顺序的机制,需要通过位置编码显式地为模型提供序列中单词的位置信息,以更好地学习序列关系。
位置编码通常通过数学函数生成,目的是为每个位置生成一个独特的向量。这些向量在嵌入空间中具有特定的性质,比如周期性和连续性。
在最近的一篇文章中,HuggingFace 机器学习工程师 Christopher Fleetwood 介绍了逐步发现 Transformer 模型中最先进位置编码的方法。为此,作者会讲述如何不断改进位置编码方法,最终形成旋转位置编码 (RoPE),并在最新的 LLama 3.2 版本和大多数现代 Transformer 中使用。在读这篇文章前,你需要掌握一些基本的线性代数、三角学和自注意力的知识。
问题陈述
与所有问题一样,最好首先了解我们想要实现的目标。Transformer 中的自注意力机制用于理解序列中 token 之间的关系。自注意力是一种集合运算,这意味着它是置换等变的。如果我们不利用位置信息来丰富自注意力,就无法确定许多重要的关系。
举例说明最能说明这一点。
考虑一下这个句子,其中同一个单词出现在不同的位置:
「这只狗追赶另一只狗」
直观地看,「狗」指的是两个不同的实体。如果我们首先对它们进行 token 化,映射到 Llama 3.2 1B 的真实 token 嵌入,并将它们传递给 torch.nn.MultiheadAttention ,会发生什么。
import torchimport torch.nn as nnfrom transformers import AutoTokenizer, AutoModelmodel_id = "meta-llama/Llama-3.2-1B"tok = AutoTokenizer.from_pretrained(model_id)model = AutoModel.from_pretrained(model_id)text = "The dog chased another dog"tokens = tok(text, return_tensors="pt")["input_ids"]embeddings = model.embed_tokens(tokens)hdim = embeddings.shape[-1]W_q = nn.Linear(hdim, hdim, bias=False)W_k = nn.Linear(hdim, hdim, bias=False)W_v = nn.Linear(hdim, hdim, bias=False)mha = nn.MultiheadAttention(embed_dim=hdim, num_heads=4, batch_first=True)with torch.no_grad(): for param in mha.parameters(): nn.init.normal_(param, std=0.1) # Initialize weights to be non-negligibleoutput, _ = mha(W_q(embeddings), W_k(embeddings), W_v(embeddings))dog1_out = output[0, 2]dog2_out = output[0, 5]print(f"Dog output identical?: {torch.allclose(dog1_out, dog2_out, atol=1e-6)}") #True可以看到,如果没有任何位置信息,那么(多头)自注意力运算的输出对于不同位置的相同 token 是相同的,尽管这些 token 显然代表不同的实体。
让我们开始设计一种利用位置信息增强自注意力的方法,以便它可以确定按位置编码的单词之间的关系。
为了理解和设计最佳编码方案,让我们探讨一下这种方案应具备的一些理想特性。
理想特性
属性 1 :每个位置的唯一编码(跨序列)
每个位置都需要一个无论序列长度如何都保持一致的唯一编码 - 无论当前序列的长度是 10 还是 10,000,位置 5 处的标记都应该具有相同的编码。
属性 2 :两个编码位置之间的线性关系
位置之间的关系在数学上应该是简单的。如果知道位置 p 的编码,那么计算位置 p+k 的编码就应该很简单,这样模型就能更容易地学习位置模式。
如果你想一想如何在数线上表示数字,就不难理解 5 距离 3 是 2 步,或者 10 距离 15 是 5 步。同样的直观关系也应该存在于编码中。
属性 3:可泛化到比训练中遇到的序列更长的序列上
为了提高模型在现实世界中的实用性,它们应该在训练分布之外泛化。因此,编码方案需要有足够的适应性,以处理意想不到的输入长度,同时又不违反任何其他理想特性。
属性 4:由模型可以学习确定性过程生成
如果位置编码能从一个确定的过程中产生,那将是最理想的。这样,模型就能有效地学习编码方案背后的机制。
属性 5:可扩展至多个维度
随着多模态模型成为常态,位置编码方案必须能够自然地从 1D 扩展到 nD。这将使模型能够使用像图像或脑部扫描这样的数据,它们分别是 2D 和 4D 的。
现在我们知道了理想的属性(以下简称为

),让我们开始设计和迭代编码方案吧。
整数位置编码
我们首先想到的方法是将 token 位置的整数值添加到 token 嵌入的每个分量中,取值范围为 0→L,其中 L 是当前序列的长度。

IntegerEncoding
在上面的动画中,我们为索引中的 token 创建了位置编码向量,并将其添加到 token 嵌入中。这里的嵌入值是 Llama 3.2 1B 中真实值的子集。可以观察到,这些值都集中在 0 附近。这样可以避免在训练过程中出现梯度消失或爆炸的情况,因此,我们希望在整个模型中都能保持这种情况。
很明显,目前的方法会带来问题,位置值的大小远远超过了输入的实际值。这意味着信噪比非常低,模型很难从位置信息中分离出语义信息。
有了这一新知识,一个自然的后续方法可能是将位置值归一化为 1/N。这就将数值限制在 0 和 1 之间,但也带来了另一个问题。如果我们选择 N 为当前序列的长度,那么每个长度不同的序列的位置值就会完全不同,这就违反了

。
有没有更好的方法来确保我们的数字介于 0 和 1 之间呢?如果我们认真思考一段时间,也许会想到将十进制数转换为二进制数。
二进制位置编码
我们可以将其转换为二进制表示法,并将我们的值(可能已归一化)与嵌入维度相匹配,而不是将我们的(可能已归一化的)整数位置添加到嵌入的每个分量中,如下图所示。

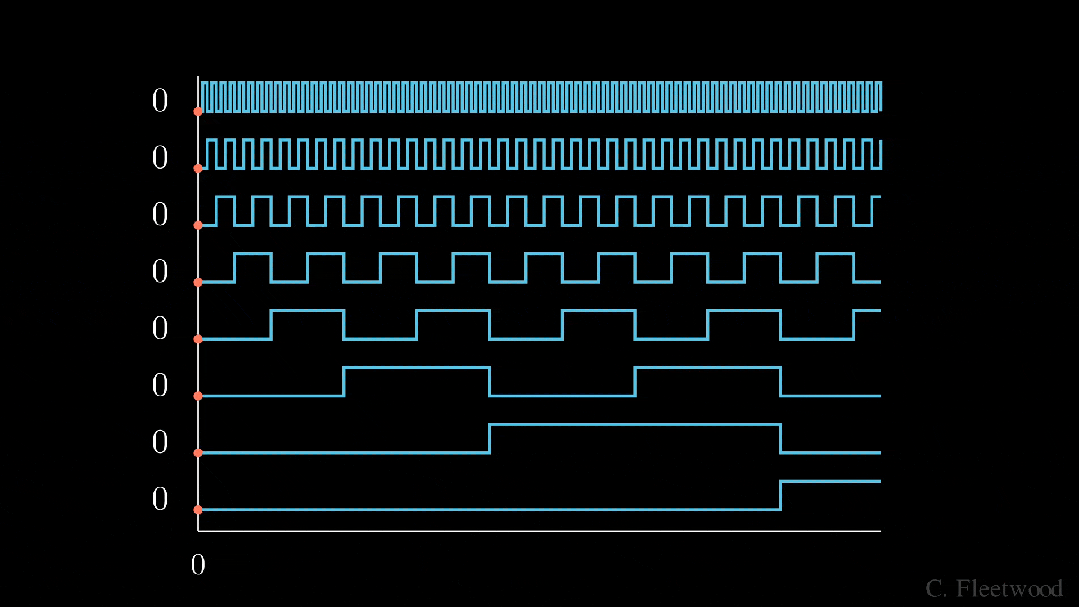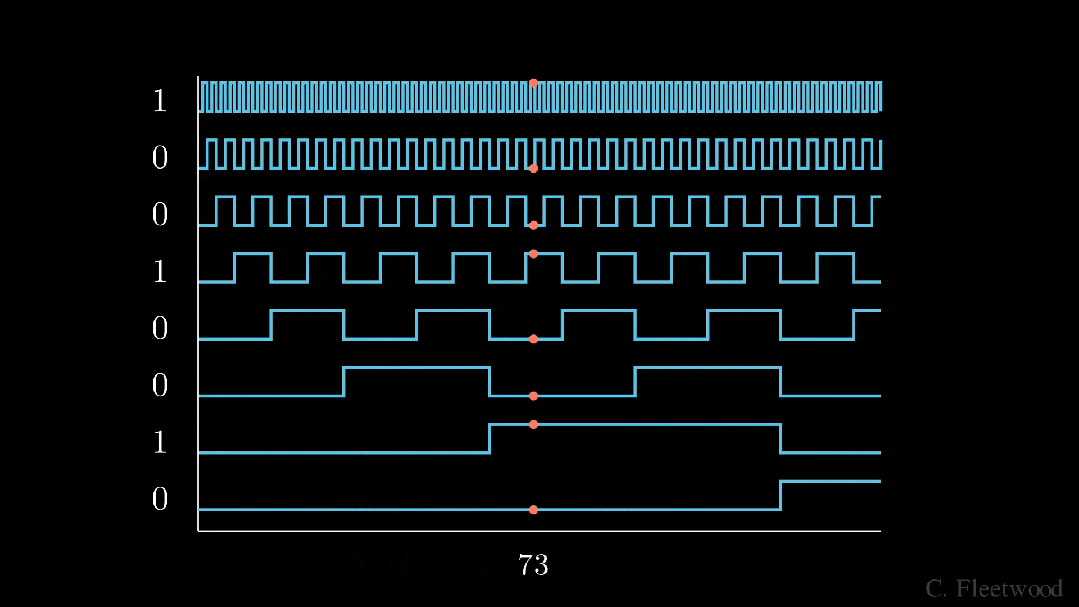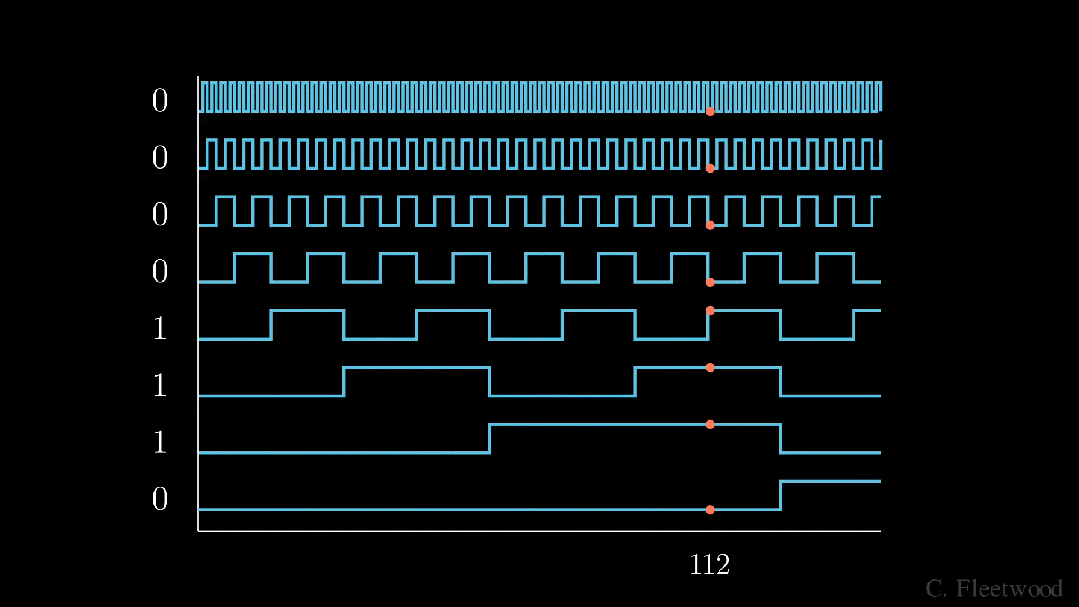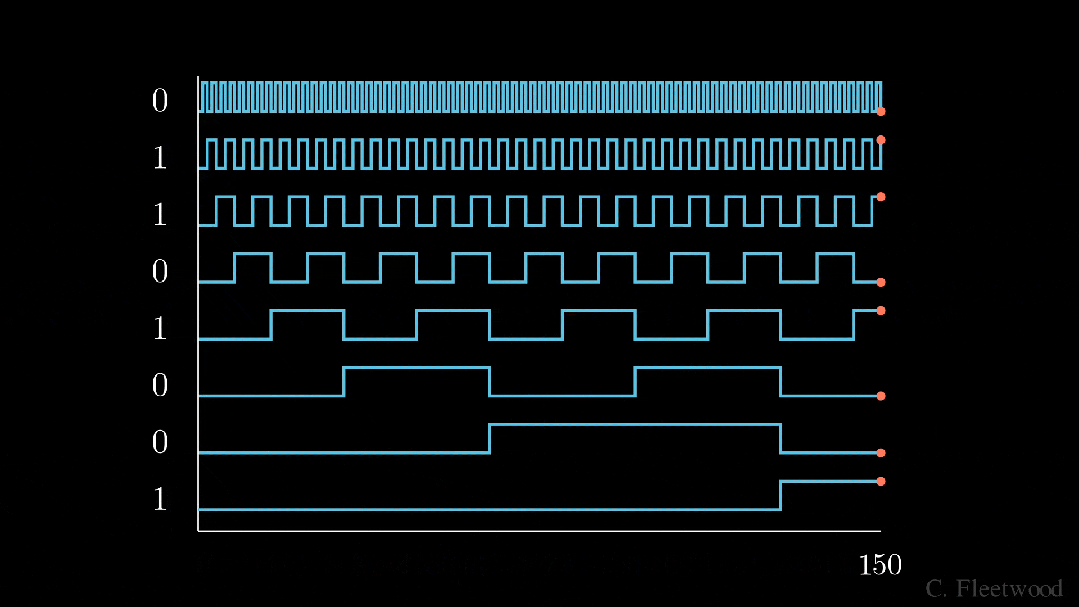
BinaryEncoding
我们将感兴趣的位置(252)转换为二进制表示(11111100),并将每一位添加到 token 嵌入的相应组件中。最小有效位(LSB)将在每个后续标记的 0 和 1 之间循环,而最大有效位(MSB)将每 2^(n-1) 个 token 循环一次,其中 n 是位数。你可以在下面的动画中看到不同索引的位置编码向量。
我们已经解决了数值范围的问题,现在我们有了在不同序列长度上保持一致的唯一编码。如果我们绘制 token 嵌入的低维版本,并可视化不同值的二进制位置向量的加法,会发生什么情况呢?
可以看到,结果非常「跳跃」(正如我们对二进制离散性的预期)。优化过程喜欢平滑、连续和可预测的变化。那么有哪些具有类似取值范围的函数是平滑连续的吗?
如果我们稍加留意,就会发现 sin 和 cos 都符合要求!
正弦位置编码

上面的动画形象地展示了我们的位置嵌入,如果每个分量都是由波长逐渐增加的 sin 和 cos 交替绘制而成。如果将其与之前的动画进行比较,你会发现两者有惊人的相似之处。
现在,我们已经掌握了正弦波嵌入的方法,这最初是在《Attention is all you need》论文中定义的。让我们来看看方程式:

其中,pos 是词块位置索引,i 是位置编码向量中的分量索引,d 是模型维度。10,000 是基本波长(下文简称为 θ),我们根据分量索引的函数对其进行拉伸或压缩。我鼓励大家输入一些实际值来感受这种几何级数。
这个等式有几个部分乍看之下令人困惑。作者是如何选择 10,00 的?为什么偶数和奇数位置分别使用 sin 和 cos?
看来,使用 10000 作为基本波长是通过实验确定的。破解 sin 和 cos 的用法涉及的问题较多,但对我们的迭代理解方法至关重要。这里的关键是我们希望两个编码位置之间存在线性关系 (

)。要理解正弦和余弦如何配合使用才能产生这种线性关系,我们必须深入学习一些三角学知识。
考虑一串正弦和余弦对,每对都与频率 ω_i 相关联。我们的目标是找到一个线性变换矩阵 M,它能将这些正弦函数移动一个固定的偏移量 k:

频率 ω_i 随维度指数 i 递减,其几何级数为:

要找到这个变换矩阵,我们可以将其表示为一个包含未知系数 u_1、v_1、u_2 和 v_2 的一般 2×2 矩阵:

根据三角加法定理,我们可以将右边的公式扩展为:

通过匹配系数,此展开式为我们提供了两个方程的系统:

通过比较两边的 sin (ω_ip) 和 cos (ω_ip) 项,我们可以解出未知系数:

这些解决方案为我们提供了最终的变换矩阵 M_k:

如果你以前做过游戏编程,你可能会发现我们的推导结果非常熟悉。没错,这就是旋转矩阵。
因此,早在 2017 年,Noam Shazeer 在《Attention is all you need》论文中设计的编码方案就已经将相对位置编码为旋转。从正弦编码到 RoPE 又花了 4 年时间,尽管旋转已经摆在桌面上......
绝对 vs 相对位置编码
在了解了旋转在这里的重要性之后,让我们回到我们的激励样本,尝试为下一次迭代发现一些直觉。

在上面,我们可以看到 token 的绝对位置,以及从 chased 到其他 token 的相对位置。通过正弦编码,我们生成了一个单独的向量来表示绝对位置,并使用一些三角函数技巧来编码相对位置。
当我们试图理解这些句子时,这个单词是这篇博文的第 2149 个单词重要吗?还是我们关心它与周围单词的关系?一个单词的绝对位置对其意义来说很少重要,重要的是单词之间的关系。
上下文中的位置编码
从这一点出发,在自注意力的背景下考虑位置编码是关键。重申一下,自注意力机制使模型能够衡量输入序列中不同元素的重要性,并动态调整它们对输出的影响。

在我们以前的迭代中,我们已经生成了一个单独的位置编码向量,并在 Q、 K 和 V 投影之前将其添加到我们的 token 嵌入中。通过将位置信息直接添加到 token 嵌入中,我们正在用位置信息污染语义信息。我们应该尝试在不修改规范的情况下对信息进行编码。转向乘法是关键。
使用字典类比,当查找一个词 (查询) 在我们的字典 (键) ,附近的词应该比遥远的词有更多的影响。一个 token 对另一个 token 的影响是由 QK^T 点积决定的 —— 所以这正是我们应该关注位置编码的地方。

上面显示的点乘的几何解释给了我们一个洞察:我们可以通过增加或减小两个向量之间的夹角来调整我们的两个向量的点积的结果。此外,通过旋转向量,我们对向量的范数完全没有影响,这个范数编码了我们 token 的语义信息。
因此,现在我们知道注意力集中在哪里,并且从另一个角度看到了为什么旋转可能是一个合理的「通道」,在其中编码我们的位置信息,让我们把它们放在一起。
旋转位置编码
RoForm 的论文中定义了旋转位置编码或 RoPE (苏剑林在他的博客中独立设计了它)。如果你直接跳到最终结果,这看起来像是巫术,通过在自注意力 (更具体地说是点积) 的背景下思考正弦编码,我们可以看到它是如何整合在一起的。
就像在 Sinusoidal Encoding 一样,我们把向量 (q 或 k,而不是预先投影 x) 分解成 2D 对 / 块。我们没有直接编码绝对位置,而是加入一个我们从频率缓慢递减的正弦函数中提取的矢量,我们切入 chase,通过将每对旋转矩阵相乘来编码相对位置。
设 q 或 k 是位置为 p 的输入向量。我们创建了一个块对角矩阵,其中 M_i 是该组件对所需旋转的对应旋转矩阵:

与正弦编码非常相似,M_i 是简单的:


在实践中,我们不使用矩阵乘法来计算 RoPE,因为使用这样一个稀疏的矩阵会导致计算效率低下。相反,我们可以利用计算中的规则模式,将旋转直接应用于独立的元素对:

就是这样!通过巧妙地将我们的旋转应用于点积之前的 q 和 k 的 2D 块,并从加法转换为乘法,我们可以在评估中获得很大的性能提升。
将 RoPE 扩展到 n 维
我们已经探讨了 1D 情况下的 RoPE,这一点,我希望你已经获得了一个直观的理解,公认的非直观组成部分的 transformer。最后,让我们探索如何将其扩展到更高的维度,例如图像。
第一直觉可能是直接使用图像中的

坐标对。这可能看起来很直观,毕竟,我们之前几乎是任意地对组件进行配对。然而,这会是一个错误!
在 1D 情况下,我们通过从输入向量旋转一对值来编码相对位置 m-n。对于 2D 数据,我们需要编码水平和垂直的相对位置,比如 m-n 和 i-j 是独立的。RoPE 的优势在于它如何处理多个维度。我们没有尝试在一个旋转中编码所有位置信息,而是将同一维度内的组件配对并旋转它们,否则我们将混合使用 x 和 y 偏移量信息。通过独立处理每个维度,我们保持了空间的自然结构。这可以根据需要推广到任意多个维度!
位置编码的未来
RoPE 是位置编码的最终化身吗?DeepMind 最近的一篇论文(https://arxiv.org/pdf/2410.06205)深入分析了 RoPE,并强调了一些基本问题。
我预计未来会有一些突破,也许会从信号处理中获得灵感,比如小波或者分层实现。随着模型越来越多地被量化用于部署,我也希望在编码方案中看到一些创新,这些编码方案在低精度算术下仍然具有鲁棒性。
参考链接:https://fleetwood.dev/posts/you-could-have-designed-SOTA-positional-encoding
#LLM2CLIP
跨模态大升级!少量数据高效微调,LLM教会CLIP玩转复杂文本
在当今多模态领域,CLIP 模型凭借其卓越的视觉与文本对齐能力,推动了视觉基础模型的发展。CLIP 通过对大规模图文对的对比学习,将视觉与语言信号嵌入到同一特征空间中,受到了广泛应用。
然而,CLIP 的文本处理能力被广为诟病,难以充分理解长文本和复杂的知识表达。随着大语言模型的发展,新的可能性逐渐显现:LLM 可以引入更丰富的开放时间知识、更强的文本理解力,极大提升 CLIP 的多模态表示学习能力。
在此背景下,来自同济大学和微软的研究团队提出了 LLM2CLIP。这一创新方法将 LLM 作为 CLIP 的强力 「私教」,以少量数据的高效微调为 CLIP 注入开放世界知识,让它能真正构建一个的跨模态空间。在零样本检索任务上,CLIP 也达成了前所未有的性能提升。
- 论文标题:LLM2CLIP: POWERFUL LANGUAGE MODEL UNLOCKS RICHER VISUAL REPRESENTATION
- 论文链接:https://arxiv.org/pdf/2411.04997
- 代码仓库:https://github.com/microsoft/LLM2CLIP
- 模型下载:https://huggingface.co/collections/microsoft/llm2clip-672323a266173cfa40b32d4c
在实际应用中,LLM2CLIP 的效果得到了广泛认可,迅速吸引了社区的关注和支持。
HuggingFace 一周内的下载量就破了两万,GitHub 也突破了 200+ stars!

值得注意的是, LLM2CLIP 可以让完全用英文训练的 CLIP 模型,在中文检索任务中超越中文 CLIP。
此外,LLM2CLIP 也能够在多模态大模型(如 LLaVA)的训练中显著提升复杂视觉推理的表现。
代码与模型均已公开,欢迎访问 https://aka.ms/llm2clip 了解详情和试用。

LLM2CLIP 目前已被 NeurIPS 2024 Workshop: Self-Supervised Learning - Theory and Practice 接收。
研究背景
CLIP 的横空出世标志着视觉与语言领域的一次革命。不同于传统的视觉模型(如 ImageNet 预训练的 ResNet 和 ViT)依赖简单的分类标签,CLIP 基于图文对的对比学习,通过自然语言的描述获得了更丰富的视觉特征,更加符合人类对于视觉信号的定义。
这种监督信号不仅仅是一个标签,而是一个富有层次的信息集合,从而让 CLIP 拥有更加细腻的视觉理解能力,适应零样本分类、检测、分割等多种任务。可以说,CLIP 的成功奠基于自然语言的监督,是一种新时代的 「ImageNet 预训练」。
虽然 CLIP 在视觉表示学习中取得了成功,但其在处理长文本和复杂描述上存在明显限制。而大语言模型(LLM)例如 GPT-4 和 Llama,通过预训练掌握了丰富的开放世界知识,拥有更强的文本理解和生成能力。
将 LLM 的这些能力引入到 CLIP 中,可以大大拓宽 CLIP 的性能上限,增强其处理长文本、复杂知识的能力。借助 LLM 的知识扩展,CLIP 在图文对齐任务中的学习效率也得以提升。

原始的 LLM 无法给 CLIP 带来有意义的监督
事实上,将 LLM 与 CLIP 结合看似简单粗暴,实际并非易事。直接将 LLM 集成到 CLIP 中会引发「灾难」,CLIP 无法产生有效的表示。
这是由于 LLM 的文本理解能力隐藏在内部,它的输出特征空间并不具备很好的特征可分性。
于是,该团队设计了一个图像 caption 到 caption 的检索实验,使用 COCO 数据集上同一张图像的两个不同 caption 互相作为正样本进行文本检索。
他们发现原生的 llama3 8B 甚至无法找到十分匹配的 caption,例如 plane 和 bat 的距离更近,但是离 airplane 的距离更远,这有点离谱了,因此它只取得了 18.4% 的召回率。
显然,这样的输出空间无法给 CLIP 的 vision encoder 一个有意义的监督,LLM 无法帮助 CLIP 的进行有意义的特征学习。

图像描述对比微调是融合 LLM 与 CLIP 的秘诀
从上述观察,研究团队意识到必须对提升 LLM 输出空间对图像表述的可分性,才有可能取得突破。
为了让 LLM 能够让相似的 caption 接近,让不同图像的 caption 远离,他们设计了一个新的图像描述对比微调 ——Caption-Contrastive(CC)finetuning。
该团队对训练集中每张图像都标注了两个以上 caption,再采用同一个图像的 caption 作为正样本,不同图像的 caption 作为负样本来进行对比学习,来提升 LLM 对于不同画面的描述的区分度。

实验证明,这个设计可以轻易的提升上述 caption2caption 检索的准确率,从上述 cases 也可以看出召回的例子开始变得有意义。
高效训练范式 LLM2CLIP
让 SOTA 更加 SOTA
LLM2CLIP 这一高效的训练范式具体是怎么生效的呢?
首先,要先使用少量数据对 LLM 进行微调,增强文本特征更具区分力,进而作为 CLIP 视觉编码器的强力 「教师」。这种设计让 LLM 中的文本理解力被有效提取,CLIP 在各种跨模态任务中获得显著性能提升。
实验结果表明,LLM2CLIP 甚至能在不增加大规模训练数据的情况下,将当前 SOTA 的 CLIP 性能提升超过 16%。

英文训练,中文超越,CLIP 的语言能力再拓展
一个令人惊喜的发现是,LLM2CLIP 的开放世界知识不仅提升了 CLIP 在英文任务中的表现,还能赋予其多语言理解能力。
尽管 LLM2CLIP 仅在英文数据上进行了训练,但在中文图文检索任务上却超越了中文 CLIP 模型。这一突破让 CLIP 不仅在英文数据上达到领先水平,同时在跨语言任务中也展现了前所未有的优势。

提升多模态大模型的复杂视觉推理性能
LLM2CLIP 的优势还不止于此。当该团队将 LLM2CLIP 应用于多模态大模型 LLaVA 的训练时,显著提升了 LLaVA 在复杂视觉推理任务中的表现。
LLaVA 的视觉编码器通过 LLM2CLIP 微调后的 CLIP 增强了对细节和语义的理解能力,使其在视觉问答、场景描述等任务中取得了全面的性能提升。
总之,该团队希望通过 LLM2CLIP 技术,推动大模型的能力反哺多模态社区,同时为基础模型的预训练方法带来新的突破。
LLM2CLIP 的目标是让现有的预训练基础模型更加强大,为多模态研究提供更高效的工具。
除了完整的训练代码,他们也逐步发布了经过 LLM2CLIP 微调的主流跨模态基础模型,期待这些模型能被应用到更多有价值的场景中,挖掘出更丰富的能力。
#一手实测科研专用版「DeepSeek」
论文读得慢,可能是工具的锅
「未来,99% 的 attention 将是大模型 attention,而不是人类 attention。」这是 AI 大牛 Andrej Karpathy 前段时间的一个预言。这里的「attention」可以理解为对内容的需求、处理和分析。也就是说,他预测未来绝大多数资料的处理工作将由大模型来完成,而不是人类。

身为经常接触大量文档和文案的开发者、研究者,相信你对 Karpathy 的这一预言有着深刻的共鸣。如今,当我们拿到一篇论文时,将其交给 AI 进行初步总结,已然成为了一种常规操作。至于选择哪款 AI,顶尖的模型似乎在基础功能上表现得都相差无几。然而,如果想要实现更多功能,例如深入精读或做笔记、存档,很多 AI 就难以满足需求了,因为目前真正为研究场景量身定制的 AI 助手并不多见。
这也是为什么「心流 AI 助手」用起来感觉如此与众不同。

这种感觉就像「你可以用便签纸写博士论文,但这肯定不是最优解」。同样的,你可以用任意一款 AI 助手读论文,但未必每个都适合长期用。
从「心流 AI 助手」的一系列设计中,我们能感觉到这是一个可以长期用的工具。比如它接入了 DeepSeek 满血版,支持论文图谱、一键直达引文、自定义知识库问答,还能随时随地就整篇或局部段落与 AI 对话并将对话保存为笔记并导出,甚至生成播客…… 这一系列功能考虑到了科研工作者对于知识获取的高效性和知识管理系统性的需求,提供了其他通用 AI 助手尚未提供的差异化体验。而且,它还是免费的。
为了了解「心流 AI 助手」究竟对研究者有多大帮助,进行了一手实测,一起来看看效果如何。
读论文的那些难处
心流 AI 助手给梳理明白了
我们首先体验的是「心流 AI 助手」左边栏的「阅读」功能。这是一个可以检索论文的界面。只要输入论文标题或作者,我们就能找到相应的论文,并选择「AI 精读」。

打开后的精读界面如下所示。在这个界面读论文的过程中我们发现,如果你是一个某研究领域的初学者,你会觉得很多设计非常贴心,比如划重点,划词解读、提问,一键翻译全文,一键导读……

心流 AI 助手的论文精读页面。

心流 AI 助手的「导读」功能。


心流 AI 助手的划词解读。
在翻译对照界面,点击译文的某一段,原文的对应段落就会被高亮显示,不用像之前用翻译工具一样自己去查找。

心流 AI 助手的原文 - 译文对照阅读模式。
而这些刚刚学会的知识点,或刚刚划下来需要记住的东西,通通可以放入笔记,分门别类保存,方便下次查看。


心流 AI 助手无处不在的「笔记」功能,划出的重点、划词之后的解读、自己写的笔记、AI 给出的总结等均可添加为「笔记」。
不过,除了这些基础功能,对于领域资深研究者来说,引文直达和论文「图谱」可能更具吸引力。
如图所示,我们拿来测试的这篇论文引用了 DeepSeek R1。如果是直接在 arXiv 上阅读,我们需要点击这个引文,跳转到文末的引用文献列表,然后根据列表中给出的相关信息去浏览器搜索。但是在心流 AI 助手的论文精读界面,我们可以一键直达,而且链接到的 DeepSeek R1 论文依然可以精读,这种「套娃」链接模式简直不要太方便。


心流 AI 助手的引文直达功能。
而点开「图谱」这个按钮,我们还发现了新的惊喜 —— 所有引文都被编织在了一张「网」里,每个节点都可以点击(也是直达论文并支持精读)。这就是心流 AI 助手特有的「论文图谱」功能,它不仅包含所引用的论文,还把论文作者的其他论文也网罗了进去,方便我们追根溯源。

另外,和其他 AI 助手类似,我们可以就这篇论文与心流 AI 助手背后的大模型展开对话,并且可以将对话内容导出为 PDF、markdown 等格式的文件,方便后续导入其他平台进行分享或处理(如把 AI 写的代码导入 Notion,作为笔记或博客的一部分)。



知识库、脑图、播客
读论文也可以私人订制
在论文精读界面,我们会看到右上角有一个「加入知识库」。这就是心流 AI 助手的另一个特色功能,它可以让大家把读过的论文存储成一个一个的文件夹,然后在想要回顾的时候去相应文件夹提问。


心流 AI 助手精读页面的「加入知识库」功能。
比如,在这个「后训练相关论文」文件夹里,我们可以导入多篇论文(精读页面导入、网页链接导入、本地导入均可),在回顾时,每篇都可以选择「速读」和「精读」。所以,即使我们忘了自己存的论文写了什么内容,也能通过这些功能快速回想起来。
心流 AI 助手知识库的速读功能,满足回顾时的快速预览需求。
如果不确定哪篇论文可以解答自己的问题,或者问题比较综合,可以选中文件夹里的所有论文,和大模型展开对话。此时,这些论文都可以作为与大模型聊天的上下文,非常方便。这可能才是 RAG 在科研场景的正确打开方式?

心流 AI 助手的知识库问答功能。
此外,我们注意到,每轮问答的右侧都会附带两个特色功能 —— 脑图和播客。
在我们的测试中,心流 AI 助手生成的脑图结构非常清晰,适合预览和回顾,而且还能下载为图片、Xmind、Markdown 等格式保存。
播客的生成效果给了我们一些惊喜,因为它能深入浅出地概括论文的核心内容,还穿插了一些形象化的说法来帮助理解。如果你只是想通过播客预览论文,这个功能绝对够用。
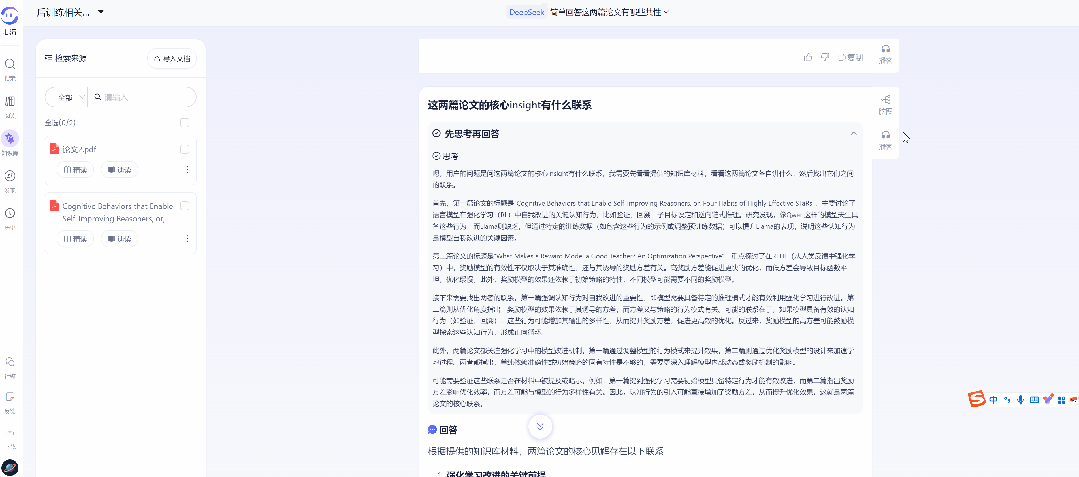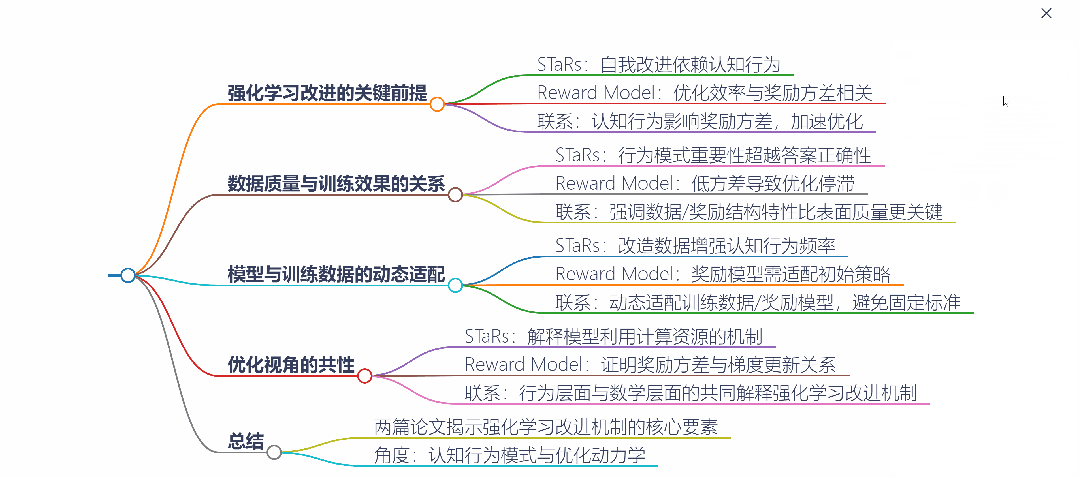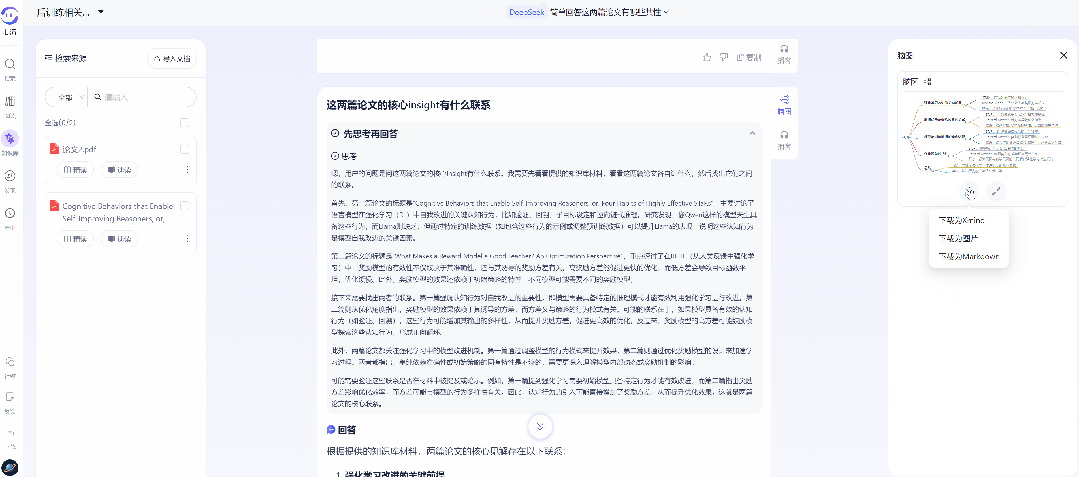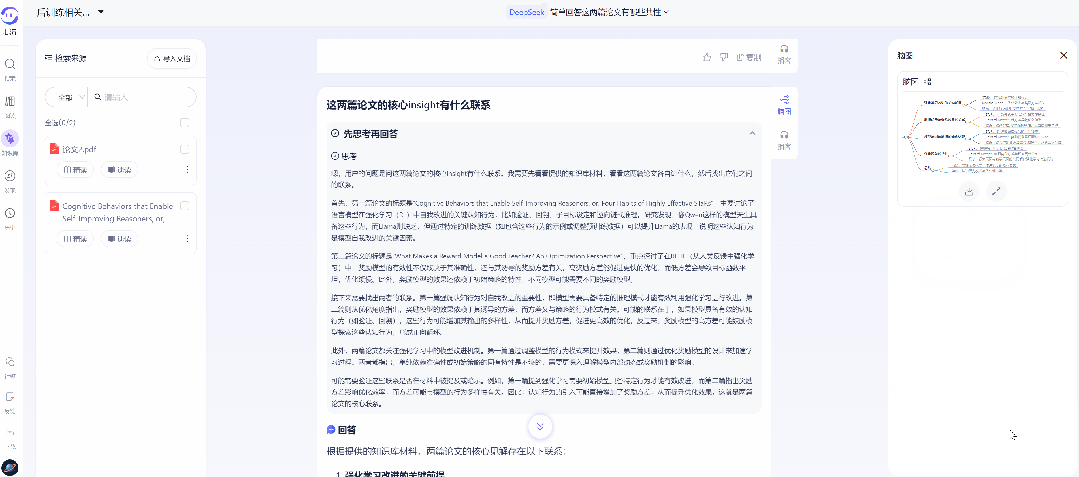
论文:为什么准确的奖励模型不work
论文:为什么Qwen能自我改进推理
当然,以上这些功能不仅可以用来读论文,把一些有用的公众号文章放进去,同样可以建立一个知识库。利用自己建立的知识库去深度阅读,知识的获取会更加个性化,效率也会更高。


科研专用 DeepSeek
心流 AI 助手未来可期
除了论文精读和知识库,我们还体验了心流 AI 助手的搜索功能。我们发现,这个功能针对不同场景进行了设计 —— 如果我们的问题对信息来源的权威性要求比较高,那可以选择「专业模式」;而如果问题对推理能力要求比较高,我们可以选联网的 DeepSeek 满血版。
在两种模式下,我们都可以清晰地看到模型所引用的内容源,并一键跳转到原网站。如果被引用的内容是论文,我们还可以在精读模式下阅读这篇论文。


此外,这个搜索框还有一个对科研非常有帮助的功能——多轮深度搜索(打开「深度搜索」选项即可激活)。也就是说,对于我们问的问题,AI大模型会反复思考,反思自己的答案是否全面、正确,最终给出简洁但足够有信息量的答案。这种不吝惜 token 的做法在追求严谨的科研场景可能非常必要。
整体体验下来,「心流 AI 助手」的设计理念已经非常清晰,他们就是要为科研工作者打造一个专用的 DeepSeek 级别的 AI 工具。在这个工具里,我们可以高效地完成知识的获取和沉淀,所有思考痕迹都能像实验室笔记般完整保存。毕竟对研究者来说,灵感的脉络往往比结论更珍贵。
当然,这个工具只是初具雏形,还有很多可以改进的功能,比如播客的音色、停顿有时还不够自然,链接到的论文有时不支持直接精读(需要一个上传的操作)…… 相信在未来的版本中,这些小问题都会被一一解决。
#反向传播、前向传播都不要
这种无梯度学习方法是Hinton想要的吗?
Noprop:没有反向传播或前向传播,也能训练神经网络。
「我们应该抛弃反向传播并重新开始。」早在几年前,使反向传播成为深度学习核心技术之一的 Geoffrey Hinton 就发表过这样一个观点。

而一直对反向传播持怀疑态度的也是 Hinton。因为这种方法既不符合生物学机理,与大规模模型的并行性也不兼容。所以,Hinton 等人一直在寻找替代反向传播的新方法,比如 2022 年的前向 - 前向算法。但由于性能、可泛化性等方面仍然存在问题,这一方向的探索一直没有太大起色。
最近,来自牛津大学和 Mila 实验室的研究者向这一问题发起了挑战。他们开发了一种名为 NoProp 的新型学习方法,该方法既不依赖前向传播也不依赖反向传播。相反,NoProp 从扩散和流匹配(flow matching)方法中汲取灵感,每一层独立地学习对噪声目标进行去噪。
- 论文标题:NOPROP: TRAINING NEURAL NETWORKS WITHOUT BACK-PROPAGATION OR FORWARD-PROPAGATION
- 论文链接:https://arxiv.org/pdf/2503.24322v1
研究人员认为这项工作迈出了引入一种新型无梯度学习方法的第一步。这种方法不学习分层表示 —— 至少不是通常意义上的分层表示。NoProp 需要预先将每一层的表示固定为目标的带噪声版本,学习一个局部去噪过程,然后可以在推理时利用这一过程。
他们在 MNIST、CIFAR-10 和 CIFAR-100 图像分类基准测试上展示了该方法的有效性。研究结果表明,NoProp 是一种可行的学习算法,与其他现有的无反向传播方法相比,它实现了更高的准确率,更易于使用且计算效率更高。通过摆脱传统的基于梯度的学习范式,NoProp 改变了网络内部的贡献分配(credit assignment)方式,实现了更高效的分布式学习,并可能影响学习过程的其他特性。
在看了论文之后,有人表示,「NoProp 用独立的、无梯度的、基于去噪的层训练取代了传统的反向传播,以实现高效且非层次化的贡献分配。这是一项具有开创性意义的工作,可能会对分布式学习系统产生重大影响,因为它从根本上改变了贡献分配机制。
其数学公式中涉及每层特定的噪声模型和优化目标,这使得无需梯度链即可进行独立学习。其优势在于通过让每一层独立地对一个固定的噪声目标进行去噪,从而绕过了反向传播中基于顺序梯度的贡献分配方式。这种方式能够实现更高效、可并行化的更新,避免了梯度消失等问题,尽管它并未构建传统的层次化表示。」

还有人表示,「我在查看扩散模型架构时也产生过这样的想法…… 然而,我认为这可能是一种非最优的方法,所以它现在表现得如此出色让我感到很神秘。显而易见的是其并行化优势。」


为什么要寻找反向传播的替代方案?
反向传播虽是训练神经网络的主流方法,但研究人员一直在寻找替代方案,原因有三:
- 生物学合理性不足:反向传播需要前向传递和后向传递严格交替,与生物神经系统运作方式不符。
- 内存消耗大:必须存储中间激活值以计算梯度,造成显著内存开销。
- 并行计算受限:梯度的顺序传播限制了并行处理能力,影响大规模分布式学习,并导致学习过程中的干扰和灾难性遗忘问题。
目前为止,反向传播的替代优化方法包括:
- 无梯度方法:如直接搜索方法和基于模型的方法
- 零阶梯度方法:使用有限差分近似梯度
- 进化策略
- 基于局部损失的方法:如差异目标传播(difference target propagation)和前向 - 前向算法
但这些方法因在准确性、计算效率、可靠性和可扩展性方面的限制,尚未在神经网络学习中广泛应用。
方法解析
NoProp
设 x 和 y 是分类数据集中的一个输入 - 标签样本对,假设从数据分布 q₀(x,y) 中抽取,z₀,z₁,...,zₜ ∈ Rᵈ 是神经网络中 T 个模块的对应随机中间激活值,目标是训练该网络以估计 q₀(y|x)。
定义两个分布 p 和 q,按以下方式分解:

p 分布可以被解释为一个随机前向传播过程,它迭代地计算下一个激活值 zₜ,给定前一个激活值 zₜ₋₁ 和输入 x。实际上,可以看到它可以被明确表示为一个添加了高斯噪声的残差网络:

其中 Nᵈ(・|0,1) 是一个 d 维高斯密度函数,均值向量为 0,协方差矩阵为单位矩阵,aₜ,bₜ,cₜ 是标量(如下所示),bₜzₜ₋₁ 是一个加权跳跃连接,而 ûθₜ(zₜ₋₁,x) 是由参数 θₜ 参数化的残差块。注意,这种计算结构不同于标准深度神经网络,后者没有从输入 x 到每个模块的直接连接。遵循变分扩散模型方法,也可以将 p 解释为给定 x 条件下 y 的条件隐变量模型,其中 zₜ 是一系列隐变量。可以使用变分公式学习前向过程 p,其中 q 分布作为变分后验。关注的目标是 ELBO,这是对数似然 log p (y|x)(即证据)的下界:

遵循 Sohl-Dickstein 和 Kingma 等人的方法,将变分后验 q 固定为一个易于处理的高斯分布。在这里使用方差保持的 Ornstein-Uhlenbeck 过程:

其中 uᵧ 是类别标签 y 在 Rᵈ 中的嵌入,由可训练的嵌入矩阵 W (Embed) ∈ Rᵐˣᵈ 定义,m 是类别数量。嵌入由 uᵧ = {W (Embed)}ᵧ 给出。利用高斯分布的标准性质,我们可以得到:
![]()
其中 ᾱₜ = ∏ₛ₌ₜᵀαₛ,μₜ(zₜ₋₁,uᵧ) = aₜuᵧ + bₜzₜ₋₁,aₜ = √(ᾱₜ(1-αₜ₋₁))/(1-ᾱₜ₋₁),bₜ = √(αₜ₋₁(1-ᾱₜ))/(1-ᾱₜ₋₁),以及 cₜ = (1-ᾱₜ)(1-αₜ₋₁)/(1-ᾱₜ₋₁)。为了优化 ELBO,将 p 参数化以匹配 q 的形式:
![]()
其中 p (z₀) 被选为 Ornstein-Uhlenbeck 过程的平稳分布,ûθₜ(zₜ₋₁,x) 是由参数 θₜ 参数化的神经网络模块。给定 zₜ₋₁ 和 x 对 zₜ 进行采样的结果计算如残差架构(方程 3)所示,其中 aₜ,bₜ,cₜ 如上所述。最后,将此参数化代入 ELBO(方程 4)并简化,得到 NoProp 目标函数:

其中 SNR (t) = ᾱₜ/(1-ᾱₜ) 是信噪比,η 是一个超参数,U {1,T} 是在整数 1,...,T 上的均匀分布。我们看到每个 ûθₜ(zₜ₋₁,x) 都被训练为直接预测 uᵧ,给定 zₜ₋₁ 和 x,使用 L2 损失,而 p̂θout (y|zₜ) 被训练为最小化交叉熵损失。每个模块 ûθₜ(zₜ₋₁,x) 都是独立训练的,这是在没有通过网络进行前向或反向传播的情况下实现的。
实现细节
NoProp 架构如图 1 所示。

在推理阶段,NoProp 架构从高斯噪声 z₀开始,通过一系列扩散步骤转换潜变量。每个步骤中,潜变量 zₜ通过扩散动态块 uₜ演化,形成序列 z₁→z₂→...→zₜ,其中每个 uₜ都以前一状态 zₜ₋₁和输入图像 x 为条件。最终,zₜ通过线性层和 softmax 函数映射为预测标签ŷ。
训练时,各时间步骤被采样,每个扩散块 uₜ独立训练,同时线性层和嵌入矩阵与扩散块共同优化以防止类别嵌入崩溃。对于流匹配变体,uₜ表示 ODE 动态,标签预测通过寻找与 zₜ在欧几里得距离上最接近的类别嵌入获得。
训练所用的模型如图 6 所示,其中左边为离散时间情况的模型,右边为连续时间情况的模型。

作者在三种情况下构建了相似但有区别的神经网络模型:
- 离散时间扩散:神经网络 ûθt 将图像 x 和潜变量 zt−1 通过不同嵌入路径处理后合并。图像用卷积模块处理,潜变量根据维度匹配情况用卷积或全连接网络处理。合并后的表示通过全连接层产生 logits,应用 softmax 后得到类别嵌入上的概率分布,最终输出为类别嵌入的加权和。
- 连续时间扩散:在离散模型基础上增加时间戳 t 作为输入,使用位置嵌入编码并与其他特征合并,整体结构与离散情况相似。
- 流匹配:架构与连续时间扩散相同,但不应用 softmax 限制,允许 v̂θ 表示嵌入空间中的任意方向,而非仅限于类别嵌入的凸组合。
所有模型均使用线性层加 softmax 来参数化相应方程中的条件概率分布。
对于离散时间扩散,作者使用固定余弦噪声调度。对于连续时间扩散,作者将噪声调度与模型共同训练。
实验结果
作者对 NoProp 方法进行了评估,分别在离散时间设置下与反向传播方法进行比较,在连续时间设置下与伴随敏感性方法(adjoint sensitivity method)进行比较,场景是图像分类任务。
结果如表 1 所示,表明 NoProp-DT 在离散时间设置下在 MNIST、CIFAR-10 和 CIFAR-100 数据集上的性能与反向传播方法相当,甚至更好。此外,NoProp-DT 在性能上优于以往的无反向传播方法,包括 Forward-Forward 算法、Difference Target 传播以及一种称为 Local Greedy Forward Gradient Activity-Perturbed 的前向梯度方法。虽然这些方法使用了不同的架构,并且不像 NoProp 那样显式地对图像输入进行条件约束 —— 这使得直接比较变得困难 —— 但 NoProp 具有不依赖前向传播的独特优势。

此外,如表 2 所示,NoProp 在训练过程中减少了 GPU 内存消耗。

为了说明学习到的类别嵌入,图 2 可视化了 CIFAR-10 数据集中类别嵌入的初始化和最终学习结果,其中嵌入维度与图像维度匹配。

在连续时间设置下,NoProp-CT 和 NoProp-FM 的准确率低于 NoProp-DT,这可能是由于它们对时间变量 t 的额外条件约束。然而,它们在 CIFAR-10 和 CIFAR-100 数据集上通常优于伴随敏感性方法,无论是在准确率还是计算效率方面。虽然伴随方法在 MNIST 数据集上达到了与 NoProp-CT 和 NoProp-FM 相似的准确率,但其训练速度明显较慢,如图 3 所示。

对于 CIFAR-100 数据集,当使用 one-hot 编码时,NoProp-FM 无法有效学习,导致准确率提升非常缓慢。相比之下,NoProp-CT 仍然优于伴随方法。然而,一旦类别嵌入与模型联合学习,NoProp-FM 的性能显著提高。
作者还对类别概率
![]()
的参数化和类别嵌入矩阵 W_Embed 的初始化进行了消融研究,结果分别如图 4 和图 5 所示。消融结果表明,类别概率的参数化方法之间没有一致的优势,性能因数据集而异。对于类别嵌入的初始化,正交初始化和原型初始化通常与随机初始化相当,甚至优于随机初始化。


#MoCha
开启自动化多轮对话电影生成新时代
本文由加拿大滑铁卢大学魏聪、陈文虎教授团队与 Meta GenAI 共同完成。第一作者魏聪为加拿大滑铁卢大学计算机科学系二年级博士生,导师为陈文虎教授,陈文虎教授为通讯作者。
近年来,视频生成技术在动作真实性方面取得了显著进展,但在角色驱动的叙事生成这一关键任务上仍存在不足,限制了其在自动化影视制作与动画创作中的应用潜力。现有方法多聚焦于 Talking Head 场景,仅生成面部区域,且高度依赖辅助条件(如首帧图像或精确关键点),导致生成内容在动作幅度与连贯性方面受限,难以展现自然流畅的全身动态与丰富的对话场景。此外,已有方法通常仅支持单角色说话,无法满足多角色对话与交互的生成需求。
为此,研究团队提出了 MoCha,首个面向Talking Characters任务的视频生成方法,致力于仅基于语音(Speech)与文本 (text) 输入,直接生成完整角色的对话视频,无需依赖任何辅助信号,突破了现有技术仅限于面部区域生成(Talking Head)及动作受限的局限,为自动化叙事视频生成提供了全新解决方案。
该方法面向角色近景至中景(close shot to medium shot)的全身区域,支持 一个或多个人物在多轮对话场景中的动态交互。为实现语音与视频内容的精准同步,MoCha 设计了Speech-Video Window Attention机制,有效对齐语音与视频的时序特征,确保角色口型与身体动作的一致性。同时,针对大规模语音标注视频数据稀缺的问题,研究团队提出了联合训练策略,充分利用语音标注与文本标注的视频数据,显著提升了模型在多样角色动作与对话内容下的泛化能力。此外,团队创新性地设计了结构化提示模板,引入角色标签,使 MoCha 首次实现了多角色、多轮对话的生成,能够驱动 AI 角色在上下文连贯的场景中展开具备电影叙事性的对话。通过大量定性与定量实验,包括用户偏好调研与基准对比,研究团队验证了 MoCha 在真实感、表现力、可控性与泛化性方面的领先性能,为 AI 驱动的电影叙事生成树立了新标杆。
- 论文链接:https://arxiv.org/pdf/2503.23307
- Hugging face 论文地址:https://huggingface.co/papers/2503.23307
- 项目地址:https://congwei1230.github.io/MoCha/
目前,该研究在 X 平台上引起了广泛的关注与讨论,相关热帖已经有一百多万的浏览量。

性能展示
MoCha 能够实现基于角色对话驱动的叙事视频生成。以下为研究团队基于 MoCha 生成的视频样例,并通过简单剪辑制作成宣传视频,以展示未来自动化电影生成的可行性与潜力。
,时长01:39
MoCha 能够生成 高度准确的唇动同步效果,展现出精细的语音 - 视频对齐能力。
情绪可控性:MoCha能够根据输入文本灵活控制角色情绪,自动生成符合语境的角色表情与情绪动作,同时保证 唇动同步 与 面部表情与上下文的一致性。
动作可控性:MoCha支持通过文本提示灵活控制角色动作,生成符合语境的动态表现,同时确保 唇动同步 与 面部表情与上下文的协调性。
Zero-shot中文对话生成(无间道台词):尽管MoCha未在中文语音数据上进行训练,模型仍展现出良好的跨语言泛化能力,能够生成同步较为自然的中文对话视频。
,时长00:24
多角色对话生成:MoCha支持多角色对话生成,能够在单角色发言时,保证所角色的动作与表现合理连贯,整体对话场景保持视觉一致性与叙事连贯性。
多角色多轮对话生成:MoCha支持多角色、多轮对话(Turn-based Dialog)生成,能够实现镜头切换与多角色动态对话的自然衔接,突破现有方法仅支持单角色发言的局限,生成具有镜头语言与剧情连贯性的复杂对话视频。
,时长00:22
核心方法
下图展示了 MoCha 的整体框架。

端到端训练,无需辅助条件:与现有方法(如 EMO、OmniHuman-1、SONIC、Echomimicv2、Loopy 和 Hallo3)不同,这些方法通常依赖参考图像、骨骼姿态或关键点等外部控制信号,MoCha实现了 完全基于语音与文本的端到端训练,无需任何辅助条件。这一设计有效简化了模型架构,同时显著提升了动作多样性与泛化能力。

Speech-Video Window Attention 机制:研究团队提出了一种创新性的注意力机制 —— Speech-Video Window Attention,通过局部时间条件建模有效对齐语音与视频输入。 该设计显著提升了唇动同步准确率与语音 - 视频对齐效果。

联合语音 - 文本训练策略:针对大规模语音标注视频数据稀缺的问题,研究团队提出了联合训练框架,充分利用语音标注与文本标注的视频数据进行协同训练。该策略有效提升了模型在多样化角色动作下的泛化能力,同时实现了基于自然语言提示的通用可控性,支持在无需辅助信号的前提下,对角色的表情、动作、交互以及场景环境等进行细粒度控制。

多角色对话生成与角色标签设计:MoCha首次实现了多角色动态对话生成,突破了现有方法仅支持单角色的限制,能够生成连贯、具备镜头切换与剧情连贯性的多轮对话视频。为此,研究团队设计了结构化提示模板,明确指定对话片段数量,并引入角色描述与标签,通过角色标签简化提示,同时保证对话清晰可控。MoCha利用 视频 Token 的自注意力机制,有效保持角色身份与场景环境的一致性,同时通过语音条件信号自动引导模型在多角色对话中的镜头切换与发言时机。
总结
总体而言,本研究首次系统性地提出了Talking Characters 生成任务,突破传统Talking Head合成方法的局限,实现了面向完整角色、支持多角色动态对话的视频生成,仅需语音与文本输入即可驱动角色动画。为解决这一挑战性任务,研究团队提出了MoCha框架,并在其中引入了多项关键创新,包括:用于精确音视频对齐的Speech-Video Window Attention机制,以及结合语音标注与文本标注数据的联合训练策略,有效提升模型的泛化能力。此外,团队设计了结构化提示模板,实现了多角色、多轮对话的自动生成,具备上下文感知能力,为可扩展的电影级 AI 叙事生成奠定了基础。通过系统的实验评估与用户偏好研究,研究团队验证了 MoCha 在真实感、表现力与可控性等方面的优越性能,为未来生成式角色动画领域的研究与应用提供了坚实基础。
#PartRM
铰链物体的通用世界模型,超越扩散方法
基于当前观察,预测铰链物体的的运动,尤其是 part-level 级别的运动,是实现世界模型的关键一步。尽管现在基于 diffusion 的方法取得了很多进展,但是这些方法存在处理效率低,同时缺乏三维感知等问题,难以投入真实环境中使用。
清华大学联合北京大学提出了第一个基于重建模型的 part-level 运动的建模——PartRM。用户给定单张输入图像和对应的 drag ,PartRM 能生成观测物体未来状态的三维表征 ,使得生成数据能够真正服务于机器人操纵等任务。实验证明 PartRM 在生成结果上都取得了显著的提升。该研究已入选CVPR 2025。
- 论文题目:PartRM: Modeling Part-Level Dynamics with Large Cross-State Reconstruction Model
- 论文主页:https://partrm.c7w.tech/
- 论文链接:https://arxiv.org/abs/2503.19913
- 代码链接:https://github.com/GasaiYU/PartRM
研究动机
世界模型是一种基于当前观察和动作来预测未来状态的函数。该模型的研发使得计算机能够理解物理世界中的复杂规律,在机器人等领域得到了广泛应用。近期,对 part-level 的动态建模的兴趣日益增长,给定当前时刻的观察并给与用户给定的拖拽,预测下一时刻的铰链物体各个部件的运动受到越来越多的关注,这种类型的世界模型对于需要高精度的任务,例如机器人的操纵任务等,具有重要的意义。
然而,我们对这个充满前景的领域的调研表明,目前的前沿研究(如 Puppet-Master)通过对预训练的 大规模视频扩散模型进行微调,以实现增加拖拽控制的功能。尽管这种方法有效地利用了预训练过程中 学习到的丰富运动模式,但在实际应用中仍显不足。其中一个主要局限是它仅输出单视角视频作为表示,而模拟器需要三维表示来从多个视角渲染场景。此外,扩散去噪过程可能需要几分钟来模拟单个拖 拽交互,这与为操作策略(Manipulation Policies)提供快速试错反馈的目标相悖。
因此,我们需要采用三维表征,为了实现从输入单视角图像的快速三维重建,我们利用基于三维高斯泼溅(3DGS)的大规模重建模型,这些模型能以前馈方式从输入图像预测三维高斯泼溅,使重建时间从传 统优化方法所需的几分钟减少到仅需几秒钟。同时,通过将用户指定的拖拽信息加入到大规模三维重建 网络中,我们实现了部件级别的动态建模。在这个问题中,我们认为联合建模运动和几何是至关重要的,因为部件级运动本质上与每个部件的几何特性相关联(例如,抽屉在打开时通常沿其法线方向滑动)。这种集成使我们能够实现更真实和可解释的部件级动态表示。
同时,由于我们是第一个做这个任务的,在这个任务上缺少相关的数据集,因此我们基于 PartNet- Mobility 构建了 PartDrag-4D 数据集,并在这个数据集上建立了衡量对部件级别动态建模的基准(Benchmark),实验结果表明,我们的方法在定量和定性上都取得了最好的效果。

PartDrag-4D 数据集的构建
我们首先定义 PartRM 需要完成的任务,给定单张铰链物体的图像 ot 和用户指定的拖拽 at ,我们需要设计 一个模型,完成

其中
![]()
是 Ot 在 at 作用下的三维表征。
现有的数据集分为两种, 一种是只含有

数据对,但是缺乏对应的三维表征(比如 DragAPart 中提出的 Drag-a-Move 数据集)。还有一种是通用数据集,比如 Objaverse 中的动态数据,这种数据不止还有部件级别的运动,还会含有物体整体的变形等运动,不适合我们训练。
因此,我们基于提供铰链物体部件级别标注的 PartNet-Mobility 数据集构建了 PartDrag-4D 数据集。我们选取了 8 种铰链物体(其中 7 种用于训练, 1 种用于测试),共 738 个 mesh。对于每个 mesh,如图所示,我们使其中某个部件在两种极限状态(如完全闭合到完全开启)间运动至 6 个状态,同时将其他部分状态 设置为随机,从而产生共 20548 个状态,其中 20057 个用于训练,491 个用于测试。为渲染多视角图像,我们利用 Blender 为每个 mesh 渲染了 12 个视角的图像。对于两个状态之间拖拽数据的采样,我们在铰链物体运动部件的 Mesh 表面选取采样点,并将两个状态中对应的采样点投影至 2D 图像空间,即可获得对应的拖拽数据。
PartRM 方法
方法概览

上图提供了 PartRM 方法的概述,给定一个单视角的铰链物体的图像 ot 和对应的拖拽 at,我们的目标是生 成对应的 3D 高斯泼溅
![]()
。我们首先会利用多视角生成模型 Zero123++ 生成输入的多视角图像,然后对输入的拖拽在用户希望移动的 Part 上进行传播。这些多视角的图像和传播后的拖拽会输入进我们设计的网络中,这个网络会对输入的拖拽进行多尺度的嵌入,然后将得到的嵌入拼接到重建网络的下采样层中。在训练过程中,我们采用两阶段训练方法,第一阶段学习 Part 的运动,利用高斯库里的 3D 高斯进行 监督,第二阶段学习外观,利用数据集里的多视角图像进行监督。
图像和拖拽的预处理
图像预处理:由于我们的主网络是基于 LGM 设计的, LGM 需要多视角的图像作为输入,所以我们需要将 输入的单视角图像变成多视角,我们利用多视角图像生成网络 Zero123++,为了使得 Zero123++ 生成的 图像质量更高,我们会在训练集上对其进行微调。

拖拽传播:如果用户只输入一个拖拽,后续网络可能会对拖拽的区域产生幻觉从而出错,因此我们需要 对拖拽进行传播到需要被拖拽部分的各个区域,使得后续网络感知到需要被拖拽的区域,为此我们设计了一个拖拽传播策略。如图所示,我们首先拿用户给定的拖拽的起始点输入进 Segment Anything 模型中得到对应的被拖拽区域的掩码,然后在这个掩码区域内采样一些点作为被传播拖拽的起始点,这些被传播的拖拽的强度和用户给定的拖拽的强度一样。尽管在拖动强度大小的估计上可能存在不准确性,我们后续的模型仍然足够稳健,能够以数据驱动的方式学习生成预期的输出。
拖拽嵌入

PartRM 重建网络的 UNet 部分沿用了 LGM 的网络架构,为了将上一步处理好的拖拽注入到重建网络中, 我们设计了一个多尺度的拖拽嵌入。具体地,对于每一个拖拽,我们会将它的起始点和终止点先过一个 Fourier 嵌入,然后过一个三层的 MLP:

其中

代表第 i 个拖拽在第 l 层的嵌入,其余部分设为 0。F 代表 Fourier 嵌入和 MLP ,
![]()
代表在 channel 维度上连接。得到第 l 层的嵌入后,我们将
![]()
和网络第 l 层的输出 Ol 在 channel 维度上连接,并过一个卷积层,作为 Ol 的残差加到 Ol 上作为下一层的输入,具体地:

其中卷积层的参数全零初始化,
![]()
为第 l + 1 层的输入。
两阶段训练流程
为了保证对静态 3D 物体外观和几何的建模能力,我们在预训练的 LGM 基础上构建了 PartRM。但直接在新数据集上微调会导致已有知识灾难性遗忘,从而降低对真实场景数据的泛化能力。为此,我们提出了 两阶段学习方法:先专注于学习之前未涉及的运动信息,再训练外观、几何和运动信息,以确保更好的性能。
运动学习阶段:在运动学习阶段,我们期望模型能够学到由输入的拖拽引起的运动。我们首先利用在我 们的数据集上微调好的 LGM 去推理每个状态 Mesh 对应的 3D 高斯泼溅表征,拿这些作为监督数据我们第 一阶段的训练。对于两个 3D 高斯之间的对应,我们利用 LGM 输出的是一个 splatter image 这一优势,即 LGM 会对 2D 图像的每一个像素点学一个高斯泼溅,我们可以直接对监督数据和 PartRM 网络预测的输出 做像素级别的 L2 损失,即:

其中 i 代表在 splatter image 里的坐标, GSi 和 GSj 均为每个像素点对应的 14 维高斯球参数。
外观学习阶段: 在运动学习阶段之后,我们引入了一个额外的阶段来联合优化输出的外观,几何以及部 件级别的运动。这个阶段我们会渲染我们输出的 3D 高斯,利用数据集中提供的多视角图像计算一个损失,具体地:

实验结果
实验设置
我们在两个数据集上来衡量我们提出的 PartRM 方法,这两个数据集包括我们提出的 PartDrag-4D 数据集 以及通用数据集 Objaverse-Animation-HQ。因为 Objaverse-Animation-HQ 数据量比较大,我们只从其中采样 15000 条数据,然后手动拆分训练集和测试集。验证时,我们对输出的 3D 高斯渲染 8 个不同的视角,在这 8 个视角上算 PSNR ,SSIM 和 LPIPS 指标。
我们选用 DragAPart , DiffEditor 和 Puppet-Master 作为我们的 baseline。对于不需要训练的 DiffEditor 方法,我们直接拿它官方的训练权重进行推理。对于需要训练的 DragAPart 和 Puppet-Master,我们在训练 集上对他们进行微调。
由于现有的方法只能输出 2D 图像,不能输出 3D 表征,为了和我们的任务对齐,我们设计了两种方法。第一种称为 NVS-First,即我们首先对输入的单视角图像利用 Zero123++ 生成多视角图像,再分别对每个视角结合每个视角对应的拖拽进行推理,生成对应的图像后再进行 3D 高斯重建;第二种称为 Drag-First,
即我们首先先对输入视角进行拖拽,然后对生成的结果利用 Zero123++ 进行多视角生成,最后进行 3D 高斯重建。我们采用了两种 3D 高斯重建方法,第一种为直接用 LGM (下图中两个时间的第一个)进行重建,第二种利用基于优化的 3D 高斯泼溅进行重建(下图中两个时间的第二个)。
定性比较


在视觉效果方面, PartRM 通过对外观,几何和运动的联合建模,能够在抽屉开合等场景中生成物理合理的三维表征。相比之下, DiffEditor 由于缺乏三维感知,导致部件形变错位; DragAPart 虽然能够处理简 单的关节运动,但在生成微波门板时出现了明显的伪影等问题,同时在通用数据集上表现不佳;Puppet- Master 在外观的时间连续性和运动部分的建模方面表现不佳。

在 in the wild 质量方面,我们从互联网上采了一些数据,手动设置拖拽,利用我们在 PartDrag-4D 上训练 好的 PartRM 进行推理。图中可以看到,我们的方法在一些和训练数据分布差别不大的数据上可以取得较 好的效果;但是在一些分布差别较大的数据上效果欠佳。
,时长00:04
定量比较

定量评估中, PartRM 在 PSNR、SSIM、 LPIPS 指标上较基线模型均有提升;同时大幅提升了生成效率, PartRM 仅需 4 秒即可完成单次生成,而传统方案需分步执行 2D 形变与三维重建。
总结
本文介绍了 PartRM ,一种同时建模外观、几何和部件级运动的新方法。为了解决 4D 部件级运动学习中的数据稀缺问题,我们提出了 PartDrag-4D 数据集,提供了部件级动态的多视角图像。实验结果表明,我们的方法在部件运动学习上优于以往的方法,并且可应用于具身 AI 任务。然而,对于与训练分布差异较大的关节数据,可能会遇到挑战。
#CLIP被淘汰了?
LeCun谢赛宁新作,多模态训练无需语言监督更强!
LeCun谢赛宁等研究人员通过新模型Web-SSL验证了SSL在多模态任务中的潜力,证明其在扩展模型和数据规模后,能媲美甚至超越CLIP。这项研究为无语言监督的视觉预训练开辟新方向,并计划开源模型以推动社区探索。
最近AI圈最火的模型非GPT-4o莫属,各种风格图片持续火爆全网。 如此强悍的图片生成能力,得益于GPT-4o本身是一个原生多模态模型。
从最新发布的LLM来看,多模态已经成为绝对的主流。
在多模态领域,视觉表征学习正沿着两条采用不同训练方法的路径发展。
其中语言监督方法,如对比语言-图像预训练(CLIP),利用成对的图像-文本数据来学习富含语言语义的表示。
自监督学习(SSL)方法则仅从图像中学习,不依赖语言。
在刚刚发布的一项研究中,杨立昆、谢赛宁等研究人员探讨了一个基本问题:语言监督对于多模态建模的视觉表征预训练是否必须?
论文地址:https://arxiv.org/pdf/2504.01017
研究团队表示,他们并非试图取代语言监督方法,而是希望理解视觉自监督方法在多模态应用上的内在能力和局限性。
尽管SSL模型在传统视觉任务(如分类和分割)上表现优于语言监督模型,但在最近的多模态大语言模型(MLLMs)中,它们的应用却较少。
部分原因是这两种方法在视觉问答(VQA)任务中的性能差距(图1),特别是在光学字符识别(OCR)和图表解读任务中。
除了方法上的差异,两者在数据规模和分布上也存在不同(图1)。
CLIP模型通常在网络上收集的数十亿级图像-文本对上进行训练,而SSL方法则使用百万级数据集,如ImageNet,或具有类似ImageNet分布的数亿规模数据。
图1结果表明,通过适当扩展模型和数据规模,视觉SSL能够在所有评估领域(甚至包括OCR和图表任务)中匹配语言监督模型的性能
作为本文共同一作的David Fan兴奋的表示,他们的研究表明,即便在OCR/Chart VQA上,视觉SSL也能具有竞争力!
正如他们新推出的完全在网页图像上训练、没有任何语言监督的Web-SSL模型系列(1B-7B参数)所展示的。
为了进行公平比较,研究团队在数十亿级规模网络数据上训练SSL模型,与最先进的CLIP模型相同。
在评估方面,主要使用VQA作为框架,采用了Cambrian-1提出的评估套件,该套件评估了16个任务,涵盖4个不同的VQA类别:通用、知识、OCR和图表、以及Vision-Centric。
研究团队使用上述设置训练了一系列参数从1B到7B的视觉SSL模型Web-SSL,以便在相同设置下与CLIP进行直接且受控的比较。
通过实证研究,研究团队得出了以下几点见解:
- 视觉SSL在广泛的VQA任务中能够达到甚至超越语言监督方法进行视觉预训练,甚至在与语言相关的任务(如OCR和图表理解)上也是如此(图3)。
- 视觉SSL在模型容量(图3)和数据规模(图4)上的扩展性良好,表明SSL具有巨大的开发潜力。
- 视觉SSL在提升VQA性能的同时,仍能保持在分类和分割等传统视觉任务上的竞争力。
- 在包含更多文本的图像上进行训练尤其能有效提升OCR和图表任务的性能。探索数据构成是一个有前景的方向。
研究人员计划开源Web-SSL视觉模型,希望激励更广泛的社区在多模态时代充分释放视觉SSL的潜力。
视觉SSL 1.0到2.0
研究人员介绍了本文的实验设置。相比之前的研究,他们做了以下扩展:
(1) 把数据集规模扩展到十亿级别;
(2) 把模型参数规模扩展到超过1B;
(3) 除了用经典的视觉基准测试(比如ImageNet-1k和ADE20k)来评估模型外,还加入了开放式的VQA任务。
这些变化能在大规模上研究视觉SSL,观察到之前小规模实验看不到的规模效应趋势
扩展视觉SSL
研究团队探讨了视觉SSL模型在模型规模和数据规模上的扩展表现,这些模型只用MC-2B的图片数据来训练。
- 扩展模型规模:研究团队把模型规模从10亿参数增加到70亿参数,同时保持训练数据固定为20亿张MC-2B图片。他们用现成的训练代码和方法配方,不因模型大小不同而调整配方,以控制其他变量的影响。
- 扩展看到的数据量:研究团队把焦点转向固定模型规模下增加总数据量,分析训练时看到的图片数量从10亿增加到80亿时,性能如何变化。
扩展模型规模
扩展模型规模的目的有两个:一是找出在这种新数据模式下视觉SSL的性能上限,二是看看大模型会不会表现出一些独特的行为。
为此,研究团队用20亿张无标签的MC-2B图片(224×224分辨率)预训练了DINOv2 ViT模型,参数从10亿到70亿不等。没有用高分辨率适配,以便能和CLIP公平比较。
研究团队把这些模型称为Web-DINO。为了对比,他们还用同样数据训练了相同规模的CLIP模型。
他们用VQA评估每个模型,结果展示在图3中。
研究团队表示,据他们所知,这是首次仅用视觉自监督训练的视觉编码器,在VQA上达到与语言监督编码器相当的性能——甚至在传统上高度依赖文字的OCR & 图表类别上也是如此。
Web-DINO在平均VQA、OCR & 图表、以及Vision-Centric VQA上的表现,随着模型规模增加几乎呈对数线性提升,但在通用和知识类VQA的提升幅度较小。
相比之下,CLIP在所有VQA类别的表现到30亿参数后基本饱和。
这说明,小规模CLIP模型可能更擅长利用数据,但这种优势在大规模CLIP模型上基本消失。
Web-DINO随着模型规模增加持续提升,也表明视觉SSL能从更大的模型规模中获益,超过70亿参数的扩展是个有前景的方向。
在具体类别上,随着模型规模增加,DINO在Vision-Centric VQA上越来越超过CLIP,在OCR & 图表和平均VQA上也基本追平差距(图3)。
到了50亿参数及以上,DINO的平均VQA表现甚至超过CLIP,尽管它只用图片训练,没有语言监督。
这表明,仅用视觉训练的模型在CLIP分布的图片上也能发展出强大的视觉特征,媲美语言监督的视觉编码器。
Web-DINO模型在所有类别上都展现出新的「扩展行为」,尤其在OCR & 图表和Vision-Centric领域,CLIP模型的扩展收益有限,性能在中等规模时就饱和了
扩展所见数据量
研究团队研究了增加看到的数据量会怎样影响性能,在MC-2B的10亿到80亿张图片上训练Web-DINO ViT-7B模型。 如图4所示,通用和知识类VQA性能随着看到的数据量增加逐步提升,分别在40亿和20亿张时饱和。
Vision-Centric VQA 性能从10亿到20亿张时提升明显,超过20亿张后饱和。
相比之下,OCR & 图表是唯一随着数据量增加持续提升的类别。
这说明,模型看到更多数据后,学到的表征越来越适合文字相关任务,同时其他能力也没明显下降。
另外,和同规模的CLIP模型(ViT-7B)相比,Web-DINO在相同数据量下的平均VQA表现始终更强(图 4)。
尤其在看到80亿张样本后,Web-DINO在OCR & 图表VQA任务上追平了CLIP的表现差距。
这进一步证明,视觉SSL模型可能比语言监督模型有更好的扩展潜力。
随着训练数据从10亿增至80亿张图片,Web-DINO-7B在OCR和图表任务中持续提升,而通用和视觉任务在20亿张后收益递减。总体上,Web-DINO在平均性能上稳步提高,并始终优于同规模的CLIP模型
Web-SSL系列模型
研究团队在表3里展示了他们的视觉编码器跟经典视觉编码器对比所取得的最佳结果,涉及VQA和经典视觉任务。 Web-DINO在VQA和经典视觉任务上都能超越现成的MetaCLIP。
即便数据量比SigLIP和SigLIP2少5倍,也没语言监督,Web-DINO在VQA上的表现还是能跟它们打平手。
总体来看,Web-DINO在传统视觉基准测试中碾压了所有现成的语言监督CLIP模型。
虽然研究人员最好的Web-DINO模型有70亿参数,但结果表明,CLIP模型在中等规模的模型和数据量后就饱和了,而视觉SSL的性能随着模型和数据规模的增加会逐步提升。
Web-DINO在所有VQA类别中也超过了现成的视觉SSL方法,包括DINOv2,在传统视觉基准上也很有竞争力。
Web-DINO ViT-7B在没有语言监督的情况下,在VQA任务上与CLIP模型表现相当,在传统视觉任务上超过了它们
研究人员还额外对Web-DINO微调了2万步,分别测试了378和518分辨率,以便跟更高分辨率的现成SigLIP和DINO版本对比。
从224到378再到518分辨率,Web-DINO在平均VQA表现上稳步提升,尤其在OCR和图表任务上有明显进步。
经典视觉任务的表现随着分辨率提高略有提升。在384分辨率下,Web-DINO稍微落后于SigLIP;到了518分辨率,差距基本被抹平。
结果表明,Web-DINO可能还能从进一步的高分辨率适配中获益。
作者介绍
David Fan
David Fan是Meta FAIR的高级研究工程师,研究方向是自监督学习和视频表征。
曾在亚马逊Prime Video担任应用科学家,从事视频理解和多模态表征学习的研究,重点关注自监督方法。
此前,他在普林斯顿大学以优异成绩(Magna Cum Laude)获得计算机科学理学工程学士学位,导师是Jia Deng教授。
Shengbang Tong
Peter Tong(Shengbang Tong,童晟邦)是NYU Courant CS的一名博士生,导师是Yann LeCun教授和谢赛宁教授。研究兴趣是世界模型、无监督/自监督学习、生成模型和多模态模型。
此前,他在加州大学伯克利分校主修计算机科学、应用数学(荣誉)和统计学(荣誉)。并曾是伯克利人工智能实验室(BAIR)的研究员,导师是马毅教授和Jacob Steinhardt教授。
参考资料:
https://x.com/DavidJFan/status/1907448092204380630
https://arxiv.org/abs/2504.01017
#In Context Editing
突破传统微调的知识编辑新范式!北京通用人工智能研究院、中科大、北大提出
北京通用人工智能研究院BIGAI联合中科大、北大提出In Context Editing,这是一种突破传统微调,从自诱导分布中学习知识的知识编辑新范式!该方法通过优化模型在上下文学习中的分布对其,而非依赖one-hot目标,创新性地将附加知识内化于原始参数空间,保持模型完整性的同时有效地增强知识编辑的鲁棒性。相关成果已被ICLR2025接收。
在不断发展的世界中,更新大型语言模型 (LLM) 以纠正过时的信息并整合新知识至关重要。此外,随着个性化设备和应用程序变得越来越普遍,不断编辑和更新模型的能力是必不可少的。这些设备需要能够调整个人用户的偏好、行为和新获得的知识的模型,确保其响应的相关性和准确性。更新大型语言模型 (LLM) 提出了一个重大挑战,因为它通常需要从头开始重新训练——这个过程在计算上既令人望而却步又不切实际。与人类可以快速且增量地适应不同,现有的 LLM 微调范式并非旨在促进高效、增量更新,从而追求这些模型的适应性特别困难。
为了解决这些限制,引入了 Consistent In-Context Editing (ICE),这是一种新方法,它学习上下文分布来有效地内化新知识。具体来说,ICE 引导模型的输出分布 p_θ (x|q) 与由包含目标知识的上下文 c 引起的上下文分布 p_θ (x|[c,q]) 对齐。ICE最小化了这两个分布之间的 KL 散度,鼓励模型内化新知识。
然而,初始上下文分布可能并不总是与所需的更新目标完美对齐,因此需要在优化过程中动态调整它。通过将上下文损失与原始微调损失相结合来实现这一点。由于微调损失最小化,输出分布和上下文输出分布都引导到所需的目标。上下文损失作为正则化项,限制了这些修改的程度,从而保证了模型的完整性并防止意外退化。这种方法允许模型在保持其原始行为的同时适应所需的更新,如下图所示。

论文题目:In-Context Editing: Learning Knowledge from Self-Induced Distributions
论文链接:https://arxiv.org/abs/2406.11194
数据&代码:https://github.com/bigai-ai/ICE
In Context Editing的亮点:
- 引入了上下文编辑(ICE),这是一种新颖的知识编辑方法,它学习上下文分布而不是 one-hot 目标,为传统的微调提供了更稳健的替代方案。
- 开发了一个优化框架,它使用基于梯度的算法细化目标上下文分布,从而能够动态适应模型以正确合并新知识。
- 提供了经验证据,证明了ICE的有效性,展示了它在保持现有知识完整性的同时无缝集成新信息,展示了其在持续编辑方面的潜力。
知识编辑问题定义
知识编辑的目标是通过查询-响应对 将新事实合并到语言模型 中。这里 是触发从 检索事实知识的查询,例如"美国总统是", 是编辑后的预期响应,例如"唐纳德特朗普"。这种集成通常是通过最大化概率 来完成的。传统上,知识编辑算法在四个关键维度上进行评估。
Edit Success 衡量模型为查询 生成编辑响应 的能力。令 表示查询-响应对, 为指示函数,度量定义为:

Portability评估模型在多大程度上概括了编辑范围 中改写或逻辑相关查询的知识。对于上述示例,相关查询可以是“美国的第一位女士是”,目标是“Melania Trump”而不是“Jill Biden”。

Locality评估模型是否为编辑范围之外的查询维护原始预测:

Fluency 估计后期编辑模型输出的语言质量,由 bi- 和 tri-gram 熵的加权和给出,给定 作为 n-gram 分布:

Consistent In-Context Editing (ICE)方法
我们引入了一个一致性条件,即更新后的模型参数 θ 应该满足:

这个条件意味着,在更新后,模型的预测是否应该与上下文 相同,这表明来自 的知识已被内化。为了实现这一点,我们将上下文编辑损失 定义为:

为了确保模型生成正确的目标序列 ,我们还包括微调损失:

其中 λ是平衡两个损失项的超参数。
优化 :上下文编辑损失 涉及两个依赖于模型参数 的分布,使得直接优化具有挑战性。直接通过两个分布传播损失是不可取的,因为我们的目标是单向优化:我们不打算向 绘制 。为了解决这个问题,我们采用了一种迭代的,基于梯度的方法。在每个优化步骤 中,我们将 视为固定的目标分布(使用当前参数 ),并更新模型参数以最小化到 的散度。这个过程形式化为:

通过迭代更新 ,我们确保模型的预测有和没有上下文收玫,满足等式 中的一致性条件。
优化组合损失 :为了优化等式 中定义的总损失,我们从以 为条件的模型中对序列 进行采样,并最大化组合序列 的可能性。这个过程相当于优化组合损失 。如果采样不以目标为条件,我们将仅优化 。这种方法在算法上很方便,为了防止模型偏离初始参数太远(从而保留不相关的知识),我们采用了受约束微调方法启发的梯度裁剪技术。详细算法如算法 1 所示。

实验与结果实验数据集

我们使用来自 KnowEdit的四个数据集评估 ICE 的性能,这些数据集通常用于知识插入和修改。所选数据集的详细统计数据见表1。在数据集中,WikiBio数据集不包括评估可移植性度量所需的相关跳跃问题数据。
实验结果
Accuracy: ICE 在所有数据集上始终达到近乎完美的编辑精度,优于大多数基线并匹配最强基线 FT-M 的性能。


Locality and Portability:随着准确性的提高,由于引入的固有扰动,局部性往往会降低。此外,模型局部性和可移植性之间往往存在负相关关系;局部性意味着模型的变化最小,而可移植性要求模型泛化到相关知识的能力。尽管有这一趋势,ICE 不仅达到了与 FT-M 相当近乎完美的准确度,而且在局部性和可移植性方面也始终优于基线方法。虽然将近乎完美的准确度与 FT-M 匹配,但 ICE 显示出比基线方法更好的局部性和可移植性。与 ROME、MEMIT 和 FT-T 相比,ICE 在 WikiData 和 WikiData 数据集上表现出更高的可移植性大约 30%。这种差异强调,通过利用上下文学习来适应上下文分布,ICE 实现了更好的泛化。此外,ICE 在两个数据集上的局部性方面的表现优于 15% 以上,通过增强基于梯度的调整的鲁棒性来保留不相关的知识。WikiBio 数据集上观察到 99.88% 的轻微性能下降。这可以归因于跨数据集的多样性,这可以在可接受的范围内引入性能的轻微变化。
Fluency and :为了评估语言质量,我们计算了流利度和困惑度。ICE表现出相当好的流畅性,经常名列前茅。虽然其他方法可能在单次编辑中显示稍高的流畅性,但ICE在连续编辑情况下实现了明显更高的流畅性。此外,ICE始终表现出较低的困惑,表明更好和更自然的语言模型性能。它在编辑新知识的同时保持现有信息的完整性,从而在所有度量标准中保持健壮的性能。

消融实验
使用动态目标,我们发现困惑度显着降低,突出了动态目标在生成自然和有意义的句子中的重要性。在比较有和没有上下文的结果时,我们可以看到添加上下文通常可以提高泛化能力。这些消融结果证实了动态训练目标和包含 ICE 中的上下文信息的重要性。

此外,我们检查了超参数 λ 的影响。表 5 中显示的结果表明,简单地设置 λ 到 1.0 会产生模型的最佳性能,这对应于直接最大化目标组合序列的可能性和采样序列。

持续编辑

上图说明了模型在持续编辑期间的性能。大多数基线方法(例如 MEMIT、ROME、FT-L)随着时间的推移,准确性和一般性能都显着下降。这种趋势尤其明显,因为应用了更多的更新,导致模型响应中的灾难性遗忘和减少局部性等问题。

表6给出了所有四个数据集的ICE结果。结果表明,在对整个数据集进行处理后,ICE保持了较高的精度和较低的困惑度。模型的完整性得到了保留,正如流畅性和PPLr指标与基本知识编辑场景保持一致所表明的那样,这表明了对持续编辑的承诺。请注意,尽管FL-L实现了非常低的困惑,但这个结果没有意义,因为准确性非常低,这表明没有合并新的目标信息(这通常会增加困惑)。
收敛性

上图的左侧显示了在一定温度范围内优化步骤的损耗曲线。虽然两种优化方案都表现出收敛性,但静态目标始终表现出较高的平衡损失。这一结果可归因于高温环境中固有的方差增加,当采用静态目标时,这会使模型拟合复杂化。相比之下,动态目标促进了迭代改进过程,使模型预测和目标分布逐渐对齐,从而实现较低的平衡损失。
上图的右侧通过一个示例提供了进一步的见解,在这个示例中,与静态目标相比,动态目标促进了对令牌预测的更有效的自适应调整。具体来说,动态目标在优化步骤中减少了重复标记模式的频率,而静态目标保持了重复标记的更高概率。动态目标对重复的抑制对于提高生成文本的流畅性尤为重要。
总结
本文介绍了上下文编辑(In Context Editing, ICE),这是一种新颖的方法,通过针对上下文分布而不是单一热点目标来解决传统知识编辑微调的脆弱性。ICE增强了基于梯度的知识编辑调优,并在准确性、局部性、泛化和语言质量方面表现出色。在四个数据集上的实验证实了它在常识编辑和持续编辑设置中的有效性和效率。总的来说,ICE为语言模型的知识编辑提供了一个新的视角和一个简单的框架。
#Q-Insight
首次引入强化学习!火山引擎让画质理解迈向深度思考
Q-Insight不再简单地让模型拟合人眼打分,而是将评分视作一种引导信号,促使模型深度思考图像质量的本质原因。有了会思考的“大脑”,视频云技术栈不仅得以重塑也让用户体验有了跃迁。
从 GPT-4o 吉卜力风、即梦的 3D 动画、再到苹果 Vision Pro,AI 视觉创作正迎来生产力大爆炸。一个重要问题随之浮现:如何评估机器生成的画质符合人眼审美?人眼能瞬间辨别图像优劣,但教会机器理解「好看」却充满挑战。
视觉革命,呼唤新的画质「评估师」
作为人们日常内容消费的核心载体,音视频在过去几十年间经历了从低分辨率、有限色彩到超高清沉浸体验的技术跃迁。这场视觉革命的背后,音视频相关技术始终是其中的技术支柱,支撑着内容从生产、处理、编码、传输到消费的全链路运作。
随着生成式人工智能与多模态大模型的发展,用户视频体验有了深刻变革。
首先,内容生产将从 UGC/PGC 发展到 AIGC,伴随视频生成模型与智能工具的普及,极大的降低了视频生产的门槛。同时,AIGC 也推动「音视频」成为新的「通用」语言,为用户提供了更多元、更生动的交流方式。
其次,得益于 AI 的深度学习能力及其自我进化的特性,交互方式正从以往的人机交互、人人交互,迈向人与 AI 融合交互的新时代。
最后,用户的交互空间也在从 2D、3D、VR,逐步拓展到虚实融合的全新空间,这带来了更沉浸的交互体验,让实时互动更加「身临其境」。
面对多模态大模型对视频生态以及技术架构影响,视频云作为底层基础设施正面临机遇和挑战。

Q-Insight:深度思考,「看懂」画质
在音视频链路中,采集、压缩、处理、传输、播放等环节大多都基于一个核心问题展开,即人眼的画质感知。多模态大模型的快速发展为新时代的音视频技术带来了新的机遇,面对人眼感知的画质理解提供了一种全新的解决方案。
以往的画质理解的方法主要分为两类:(1)评分型方法,这类方法通常只能提供单一的数值评分,缺乏明确的解释性,难以深入理解图像质量背后的原因;(2)描述型方法,这类方法严重依赖于大规模文本描述数据进行监督微调,对标注数据的需求巨大,泛化能力和灵活性不足。
针对上述问题,北京大学与火山引擎多媒体实验室的研究人员联合提出了基于强化学习训练的多模态大模型图像画质理解方案 Q-Insight。

论文链接:https://arxiv.org/pdf/2503.22679
与以往方法不同的是,Q-Insight 不再简单地让模型拟合人眼打分,而是将评分视作一种引导信号,促使模型深度思考图像质量的本质原因。通过这种创新思路,Q-Insight 在质量评分、退化感知、多图比较、原因解释等多个任务上均达到业界领先水平,具备出色的准确性和泛化推理能力,并且不依赖大量高成本的文本数据标注。

Q-Insight 首次将强化学习引入图像质量评估任务,创造性地运用了「群组相对策略优化」(GRPO)算法,不再依赖大量的文本监督标注,而是挖掘大模型自身的推理潜力,实现对图像质量的深度理解。如图所示,Q-Insight 不仅输出单纯的得分、退化类型或者比较结果,而是提供了从多个角度综合评估画质的详细推理过程。
实验结果充分验证了 Q-Insight 在图像质量评分、退化检测和零样本推理任务中的卓越表现:在图像质量评分任务上,Q-Insight 在多个公开数据集上的表现均超过当前最先进的方法,特别是在域外数据上的泛化能力突出,并能够提供完整详细的推理过程。

在退化感知任务上,Q-Insight 的表现显著优于现有的退化感知模型,尤其是在噪声和 JPEG 压缩退化类型识别的准确性上。

在零样本图像比较推理任务上,Q-Insight 无需额外监督微调,即可准确、细致地分析和比较图像质量,展示出强大的泛化推理能力。

大脑升级,重塑视频云技术栈
以多模态画质理解大模型 Q-insight 作为基石之一,火山引擎视频云已经围绕多媒体链路搭建起基于大模型的解决方案。

大模型算法能力包含有生成式画质增强大模型、沉浸音频大模型、生成式视频编码大模型、多模态内容理解大模型等。此外,已有的传统媒体处理能力也与大模型能力方案形成有机结合与互补,其中包括软件编解码 BVC 系列、硬件编码器、处理增强能力、分析和理解能力等。
通过基于 MLLM 实现的多媒体智能体,可以面向不同复杂的业务场景与用户需求,做到感知理解、智能决策规划和输出算法能力方案。相比传统依据经验调控的方案,多媒体智能体具有链路更智能、算法效果上限更高,并且更贴近实际业务和人眼感知等优势。
此外,结合视频云自研多媒体处理框架 BMF 以及大规模多媒体实验仿真平台 VLAB 等工程支持,进一步提高了大模型媒体服务的稳定性和效率,有效降低了部署成本。
超越技术,体验跃迁
火山视频云产品正在把用户从流畅、实时、高清的数字视频世界带入更智能、更交互、更沉浸的 AI 视频世界。这不仅意味着技术的飞跃,更代表着体验方式的一场变革。
在大模型和生成式 AI 技术的强劲推动下,音视频处理的底层技术正经历着深刻的变革。
首先对算力层的要求尤为显著。生成式 AI 技术大幅降低了视频生成的门槛,导致视频数据以惊人速度增长。所以也对计算成本和处理效率提出了严峻的挑战。
在算法层,编解码、处理、分析等音视频处理的核心技术,正在与大模型不断的深度融合。这种融合不仅提升了编解码效率以及画质表现,更为用户带来了更加优质的视频体验。
在框架层,随着视频生成大模型和预处理所需的计算需求日益增长,我们需要构建更强大、更灵活的多媒体处理框架,不仅要能够支持大模型的高效运行,还要能够满足日益复杂的音视频处理需求,以应对生成式 AI 带来的挑战。

火山引擎多媒体实验室是字节跳动旗下的研究团队,致力于探索多媒体领域的前沿技术,参与国际标准化工作,其众多创新算法及软硬件解决方案已经广泛应用在抖音、西瓜视频等产品的多媒体业务,并向火山引擎视频云的企业级客户提供技术服务。实验室成立以来,多篇论文入选国际顶会和旗舰期刊,并获得数项国际级技术赛事冠军、行业创新奖及最佳论文奖。
火山引擎视频云,以「体验」为核心,基于字节跳动亿级 DAU 打磨的音视频技术融合 AI / 大模型技术,打造集视频直播、企业直播、视频点播、智能处理、实时音视频、云游戏、云手机、veImageX 等于一体的一站式音视频服务,帮助企业端到端提升视频能力,实现播放体验、画质体验、交互体验、性能体验的全面提升与创新。

















 2196
2196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









