







我自己的原文哦~ https://blog.51cto.com/whaosoft/13766166
#Scaling Law百度最早提出?
OpenAI/Claude都受它启发,Ilya出现在致谢名单中
什么?Scaling Law最早是百度2017年提的?!
Meta研究员翻出经典论文:
大多数人可能不知道,Scaling law原始研究来自2017年的百度,而非三年后(2020年)的OpenAI。
此研究由吴恩达主持,来自百度硅谷人工智能实验室 (SVAIL) 系统团队。
他们探讨了深度学习中训练集大小、计算规模和模型精度之间的关系,并且通过大规模实证研究揭示了深度学习泛化误差和模型大小的缩放规律,还在图像和音频上进行了测试。
只不过他们使用的是 LSTM,而不是Transformer;也没有将他们的发现命名为「Law」。
再回头看,其中一位作者Gregory Diamos给自己当年在百度的介绍还是LLM Scaling Law Researcher。
又有一网友发现,OpenAI论文还引用了2019年这位作者Gregory Diamos等人的调查。但却不知道他们2017年就有了这么一项工作。
网友们纷纷表示这篇论文非常值得一读,而且完全被低估。
来赶紧看看这篇论文。
深度学习Scaling是可预测的
在深度学习领域,随着模型架构的不断探索、训练数据集的不断增大以及计算能力的不断提升,模型的性能也在不断提高。
然而,对于训练集大小、计算规模和模型精度之间的具体关系,一直缺乏深入的理解。
本文通过大规模的实证研究,对多个机器学习领域(如机器翻译、语言建模、图像分类和语音识别)进行了测试,发现了一些规律:
泛化误差(模型在新数据上的表现误差)与训练集大小呈现幂律关系,即随着训练集的增大,泛化误差会以一定的幂次下降。
模型大小与与数据大小也存在Scaling(缩放)关系,通常模型大小的增长速度比数据大小的增长速度慢。
具体来说,结合以往工作,团队将注意力集中在准确估计学习曲线和模型大小的缩放趋势上。
按照一般测量方法,是选择最先进的SOTA模型,并在训练集的更大子集(碎片)上训练这些模型的 “超参数缩减 ”版本,以观察模型的准确性如何随着训练集的大小而增长。
因此针对这四个领域,机器翻译、语言建模、图像分类和语音识别,找到了他们在大型数据集上显示出 SOTA 泛化误差的模型架构。
这里的 “大型数据集 ”是指规模可以缩小 2-3 个数量级,但仍足以进行有价值的模型架构研究的训练集。他们为某些 ML 领域选择了一种以上的模型架构,以比较它们的扩展行为。
机器翻译
团队注意到,随着训练集规模的增大,优化变得更加困难,而且模型会出现容量不足的情况,因此经验误差会偏离幂律趋势。
词语言模型
这一结果表明,最佳拟合模型随训练分片大小呈次线性增长。
字符级语言模型
为了测试字符级语言建模,他们训练了深度为 10 的循环高速公路网络(RHN),结果发现该网络在十亿单词数据集上能达到最先进的(SOTA)准确率。
图像分类。
图像分类同样呈现出幂律学习曲线和模型大小的缩放关系。并且还表明,在非常小的训练集上,准确率会在接近随机猜测的水平上趋于平稳。
语音识别。
团队训练了一系列跨度较大的模型尺寸,所以针对每个训练数据大小得出的模型尺寸缩放结果,其意义不像在语言模型(LMs)或图像分类中那么明显。
随着数据量的增加,大多数模型会经历幂律泛化改进,直至数据量接近其有效容量。在这种情况下,参数为 170 万的模型的准确率在大约 170 小时的音频数据时开始趋于平稳,而参数为 600 万的模型在大约 860 小时的音频数据时趋于平稳(也就是说,大约是前者的 5 倍,这与模型尺寸的差异情况类似)。更大的模型(例如,参数为 8700 万的模型)在更大的数据集规模下,其泛化误差也更接近最佳拟合趋势。
最后对于这一发现,他们表示,这些比例关系对深度学习的研究、实践和系统都有重要影响。它们可以帮助模型调试、设定准确度目标和数据集增长决策,还可以指导计算系统设计,并强调持续计算扩展的重要性。
博客致谢中还有Ilya的名字
此次研究主要是由当年吴恩达主持下,百度硅谷人工智能实验室 (SVAIL) 系统团队。
当时的一群合著者们已经各自去到各个机构实验室、大厂继续从事大模型相关的研究。
在当年博客致谢中,还出现了Ilya的名字,感谢他们参与了这一讨论。
两年后,也就是2019年,其中一位作者Gregory Diamos又带领团队探讨了深度学习的计算挑战。
后面的OpenAI论文正是引用了这篇论文的调查讨论了Scaling Law。
值得一提的是,Anthropic CEODario Amodei在百度研究院吴恩达团队工作过,他对Scaling Law的第一印象也是那时研究语音模型产生的。
Amodei刚开始研究语音神经网络时有一种“新手撞大运”的感觉,尝试把模型和数据规模同时扩大,发现模型性能随着规模的增加而不断提升。
最初,他以为这只是语音识别系统的特例。但到了2017年,看到GPT-1的结果后意识到这种现象在语言模型上同样适用。
当年(2015年)他一作发表的论文Deep Speech,合著者中这位Sharan Narang正是两年后这篇论文的主要作者之一。如今后者先后去到了谷歌担任PaLM项目TL大模型负责人,然后现在是Meta当研究员。
如今这一“冷知识”再次出现在大家的视野,让不少人回溯并重温。
这当中还有人进一步表示:真正的OG论文使用了seq2seq LSTM,并且确定了参数计算曲线。
当年的一作正是Ilya Sutskever。
参考链接:
[1]https://arxiv.org/abs/1512.02595 [2]https://arxiv.org/abs/1909.01736
[3]https://research.baidu.com/Blog/index-view?id=89
[4]https://www.linkedin.com/in/gregory-diamos-1a8b9083/ [5]https://www.linkedin.com/in/dario-amodei-3934934/
[6]https://x.com/jxmnop/status/1861473014673797411?s=46&t=iTysI4vQLQqCNJjSmBODPw
#MemoryFormer
推理计算量减小10倍!MemoryFormer:华为提出存储代替计算的Transformer新架构
本文介绍了MemoryFormer,一种新型的Transformer模型,它通过使用存储空间来替代传统的全连接层,显著降低了推理时的计算复杂度。MemoryFormer利用哈希算法和局部敏感哈希索引方法,在保持模型性能的同时,减少了模型的计算量,为大模型的高效推理提供了新的解决方案。
论文链接:https://arxiv.org/abs/2411.12992
引言
在大模型快速发展的今天,深度学习模型的规模不断增大。然而,随着模型规模的提升,对于计算资源的消耗也随之剧增,这使得模型的部署和推理面临巨大挑战。近期,一篇来自北京大学和华为的研究人员共同合作的论文提出了一种创新性的方法——MemoryFormer,通过巧妙地利用存储空间来替代传统的密集计算的全连接层,显著降低了推理时的计算复杂度(FLOPs)。这一思路为大模型的高效推理提供了全新的解决方案。
用存储来替代全连接层
传统的Transformer模型中,计算资源的开销不仅来自于多头自注意力模块,还来自于模型内部的全连接层。针对这一特点,MemoryFormer提出了一种“记忆层”(Memory Layer)来代替这些计算量庞大的全连接层,从而极大地减少了模型的计算复杂度。具体来说,Memory Layer通过哈希算法来对输入特征进行离散化,并在内存中构建查找表,将原本需要的矩阵乘法替换为在计算上更轻量的哈希查找。这种设计使得MemoryFormer能够在推理时大幅降低所需的计算量,并且几乎不影响模型的性能。
MemoryFormer不仅简单地引入哈希查找表,还设计了一种基于局部敏感哈希(LSH)的极简索引方法,使得哈希表中的每一个存储的向量都可以在训练中根据梯度动态更新。这种设计确保了哈希表中存储的特征能够不断适应输入数据,并在推理阶段根据输入特征的相似性高效检索出近似的输出结果,实现全连接层所需的特征变换功能。此外,MemoryFormer通过多表分块和向量分段的方式来控制哈希表的存储规模,使得内存需求不会因哈希表的引入而暴增。
Memory Layer结构示意图
方法:可学习的局部敏感哈希
Memory Layer的具体实现方式如下:在一层Memory Layer内设置K个哈希表 、,每个哈希表中存储 τ 个d维向量(τ=d/k),对于一个输入的d维token embedding向量x,首先对其进行分段操作切分为k段τ维向量:
![]()
接下来对每段子向量 进行局部敏感哈希操作,分别求得k个哈希表的对应索引,使用的极简哈希函数为:
其中sign()函数对每一位只取符号位,integer()函数首先将输入中的-1变为0再将二值化向量转换为对应的十进制数。然后将K个哈希表的检索结果 进行加权聚合得到该Memory Layer层的输出:
其中 为各个哈希表的归一化权重,表征了embedding切分后的第k段子向量与第k个哈希表索引结果的契合程度,其计算方式为
其中
![]()
sim函数表示 向量与第 个hash bucket的相关程度,如下图中的二维坐标系示意图所示,sim函数既考虑了 与sign 之间的夹角、又考虑了 本身的幅值,在对第k个哈希表内所有 τ 个位置进行类似softmax形式的归一化后,我们即可得到每个哈希表 的检索结果在聚合时的加权系数:

函数将整数i(0≤i< )转换为对应的符号向量{-1, +1}∈ τ。
考虑数学形式上的2个等价变化:
可进一步简化为

Memory Layer最终的输出为

Memory Layer对于相似的输入 和 具有相似的输出,且通过设置多个哈希表与加权聚合的方式丰富了单层的特征表达能力。MemoryFormer将Baseline Transformer中的q_proj、k_proj、k_proj等Linear Layer全部替换为Memory Layer。对于原模型中的FFN模块,我们用2个连续的且容量scale up的Memory Layer进行替代,来模拟原FFN中多个Linear Layer“先升维后降维”的特点。因此,MemoryFormer中每个Block的计算过程为:
我们移除了FFN模块中的非线性函数,取而代之的是每个Memory Layer之前都有一个Norm Layer以保证输入的向量在分布上是zero-centered的,也就是说在sign()函数的结果中出现-1和+1的概率是均等的。
MemoryFormer Block示意图
在Baseline Transform中,每个block的计算量为:
在MemoryForm中,每个block的计算量为:
实验:
论文基于Pythia训练框架,在多个公开的自然语言处理基准测试中验证了MemoryFormer的性能,包括PIQA、WinoGrande、WSC、ARC-E、ARC-C、LogiQA等任务。我们在每种setting下都保持2种模型的层数和token维度是一致的、且保持Attention部分的计算量一致。实验结果表明,在多种模型尺寸下,MemoryFormer几乎消除了注意力模块之外的计算量,大幅减少了推理时模型的总计算量,且总体性能不逊于baseline Transformer模型,例如MemoryFormer将Pythia-410M模型的Attention之外per-block计算量从25.8GFLOPs降低至1.6GFLOPs,展示出更优的计算效率。
我们还将MemoryFormer与其他基于“局部自注意力”方案的Efficient Transformer进行了性能于计算量方面的对比(保持层数于embedding维度一致):
消融实验
不同分表设置下的存储占用和模型性能:
增加FFN模块中哈希表的容量,存储消耗与模型性能收益之间的关系:
是否移除了FFN模块中的非线性函数:
哈希过程可视化
我们还对不同Memory Layer(Q、K、V、FFN)中的多个哈希表中每个位置的命中情况进行了可视化,结果表明在推理过程中,大部分哈希表中的不同位置都会以相似的概率被hash到,少数哈希表中会出现个别位置被大量token embedding都hash到的情况。
总结:
MemoryFormer为实现高效的Transformer模型提供了全新的思路,用存储取代计算、哈希表替代全连接层的设计,减少了模型推理时的计算复杂度,为大模型的高效部署、尤其是边缘设备和CPU设备的部署、带来了新的契机,为大模型的多方面可持续发展提供了新的可能性。
#长期主义者Zilliz如何全球突围
向量数据库的中场战事
命运齿轮转动的开始,源于 2023 年的 3 月 23 日的 OpenAI 一次日常更新。
这一天,OpenAI ChatGPT 发布了一个名叫 chatgpt-retrieval-plugin 的插件功能。而在官方 plugin 给出的标准案例中,OpenAI 专门提到,向量数据库是大模型产品形成长期记忆一个必不可少的组件。
无独有偶,三天前的 NVIDIA GTC 2023 大会上,英伟达创始人黄仁勋也重点提及向量数据库,一家过去名不见经传的向量数据库创业公司 Zilliz 在此期间,被三次邀请上台演讲。向量数据库与大语言模型,成为这一年的 GTC 上,除芯片之外讨论度最高的关键词。
也是自这一天起,海内外的各大开源社区以及创投市场,所有向量数据库项目的关注度瞬间画出了一条陡峭的增长曲线。
老牌玩家 Zilliz 旗下 Milvus 的 GitHub 的 Star 在接下来的两年时间迅速从一万增长至三万。原本略显荒芜的赛道中,仅仅一个多月,就有 Pinecone,Weaviate 各种 “专用向量数据库” 如雨后春笋冒了出来,数十亿热钱被打到创业公司的户头。
烈火烹油,鲜花着锦,与热情一同狂奔而来的是粗放的管理:
谷歌开发专家兼 YouTube 频道 Fireship 的创建者 Jeff Delaney,在 0 收入、0 商业计划甚至 0 展示代码的情况下,就能凭借 Rektor 向量数据库初创项目将公司估值推升至 4.2 亿美元。明星创业公司公开承认产品只是在 ClickHouse 和 HNSWlib 基础上,加上了向量检索与 Python 封装,就推向市场。
二级市场,哪怕传统的数据库运维公司,只要放出一个正在研发向量数据库的消息,就立刻在被转化为股票走势中连续的 20cm 涨停。甚至有大厂,从立项到完成产品化仅用时三个月不到,就推出了自研的向量数据库产品。
那时,所有人都相信,每个时代都有自己的代表性基础设施:如果工业革命时期的水电煤;信息时代的 IOE+wintel;手机时代是高通 + 安卓 + Snowflake,那么到了 AI 时代,为什么不会是 GPU + 大模型 + 向量数据库?
手握向量数据库的源代码,排入的是通往 AI 时代千亿市值的繁华梦之队。
却唯独忘记了,残暴的欢愉终将以残暴收尾,就如同历史上反复上演的数据库战争一般 —— 在一个极具规模效应的市场里,二八原则早已为所有玩家的未来写下结局的注脚。
一、一个新的千亿蓝海市场
在理解市场对向量数据库的狂热之前,我们需要先对其概念及其与大模型的关系,做一个清楚的阐释。
所谓向量数据库,顾名思义,用户存储、管理向量的数据库。与之并列的概念,则是甲骨文、MySQL 为代表的传统关系型数据库,以及 Web 2.0 时期兴起的 PostgreSQL、MongoDB 等为代表的 NoSQL 数据库。
与后两者相比,向量数据库更擅长存储、管理的数据类型,是我们常见的图片,视频,音频,文档等无法用表格(结构化方式)进行精确描述的非结构化数据。
在传统数据库里,我们对数据的管理和查找,类似于常见的 Excel,主要依靠对数据进行分门别类后,进行精确查找与运算,比如在超市货架中找到所有的 “巧克力”,非常的容易。但如果要找到具有某一类型特征的商品,比如 “可以快速补充血糖的商品”,那么基于关键词的精准搜索就帮不上忙了。
而向量数据库对数据的存储与管理,是基于其 “特征” 的相似度,比如一张巧克力的照片,经过 AI 模型对其进行特征提取,存储在向量数据库中,就会变成一系列独特的如 “高脂肪”“零食”“高糖”“褐色”“原产中南美洲” 等 “特征码”,进而响应 “补充血糖” 这样的特征检索需求。
也是因此,与传统的数据库相比,向量数据库与时下大火的大模型的关系也更为密切。
一个典型的应用方向是 RAG。
RAG,全称 Retrieval-Augmented Generation,中文可以理解为 “检索增强生成”,一般被广泛用于垂类知识库的构建,用以解决大模型的幻觉、垂类知识缺乏,以及知识动态更新的困境。
过去几年中,ChatGPT 为代表,大模型的出现让人工智能的通识水平以及推理能力有了飞跃性的提升。然而大模型最大的缺陷在于,缺乏专业领域知识以及长期记忆,并且容易出现幻觉。因此,我们经常可以看到大模型可以写复杂的程序,却被小学生奥数题难倒,再比如,一些大模型在学习了错误、“有毒” 的数据素材后,会分不清 “南唐” 与 “唐朝”,也会对李白的作品有哪些等问题张冠李戴。
与此同时,在金融等领域,我们通常需要最新的一手数据与知识进行分析,然而大模型在训练完成后,所拥有的知识就已经被固定,缺乏对行情为代表的知识与信息的动态补充能力。
通过向量数据库,企业可以将自身的垂类知识、企业专属知识等内容以 RAG 模式接入大模型,进而使其迅速掌握医药、法律、汽车等专业领域的知识之外,也能够实时进行知识的动态更新。
也是因此,大模型撬动市场对向量数据库的需求;向量数据库成为大模型通往智能之路的催化剂。市场就像滚雪球一样,在这个永动机式的扩张中越变越大。
但向量数据库的潜力远不止于此,大模型之外,个性化多模态内容搜索、推荐系统、精准营销、风控、欺诈检测、网络安全、自动驾驶、虚拟药物筛选同样也是向量数据库应用的核心场景。
下游应用的爆发带来了市场规模的进一步扩张:DB-Engines 数据显示,过去三年中,向量数据库一直是最受欢迎的数据库类别;Gartner 也预测,到 2026 年,30% 的企业将把向量数据库集成到其生成式 AI 模型中。
东北证券则对市场规模做了进一步测算,到 2030 年,全球向量数据库市场规模有望达到 500 亿美元,国内向量数据库市场规模有望超过 600 亿人民币。
历史已经告诉我们,一切风口之中,卖铲子才是最稳赚不赔的生意。
而向量数据库,就是大模型时代那把通往未来的金铲子。
二、向量数据库的江湖派系
如果不出意外,在这个赛道中,诞生千亿级别的企业,只是时间的早晚问题。
也正是在这种无法抗拒的诱惑下,市场随之迅速被划分为三大派别:
第一派玩家,独立的向量数据库创业公司。
其优势在于产品化,相比传统单机插件式数据库,向量数据库的检索规模可以提升十倍,支持百万级每秒查询(QPS)的峰值能力,同时延迟控制在毫秒级。
不足则是由于部分创业公司成立时间较短,缺乏各种数据库应该具备的基础性能力,例如:备份 / 恢复 / 高可用、批量更新 / 查询操作,事务 / ACID 等。此外,数据跨库带来的不同步也是个不容忽视的问题。比如如果用户在最原始的 PostgreSQL 中删除了某一条数据后,没有在向量数据库中实时同步,就会出现数据不一致,在生产环境中带来影响。
第二派,传统数据库玩家:如甲骨文 和 MongoDB 等,通过在传统数据库上加上一个具备向量检索能力的插件,从而使得传统数据库具备了向量的检索能力。
其优势在于数据不再需要在多个数据库之间同步、流转、处理。劣势则在传统数据库对海量非结构化数据的处理与支持存在一定的缺陷。比如建一个图库类应用,对 10 亿级别图片进行以图搜图,每张图片对应 128 维 Float 向量,需要的服务器内存将高达 480GB ,早已超出单机内存的极限。也就是说,百万以及千万级的数据中,传统数据库做加法,可以支撑一定的用户的需求,如果要做到亿级乃至 10 亿的数据规模,就需要专业的企业级分布式向量数据库了。
第三派玩家,云服务巨头。以 AWS 和 Microsoft 为代表,他们会在云服务的产品体系中,加入自研的向量数据库产品,优势在于 “买一赠一”、服务连续,缺点则在于云服务巨头们往往同时在做大模型、应用、云服务、向量数据库,既做裁判又做运动员的情况下,企业如何放心将私密的知识库放在云上,就成了新的问题。
至此,天下三分。传统数据库玩家在 noSQL、图数据库、关系型数据库、向量数据库多个战场四面开花;云服务巨头卡位流量端,让向量数据库成为整体业务上运中买一赠一中的赠品;而创业公司则以产品与压强式投入见长,在性能与服务上独领风骚。
三、向量数据库的中场战报
就在各大玩家还在低着头蒙眼狂奔同期,今年三季度,Forrester 已经通过一张 “Forrester Wave™ 向量数据库报告”,从产品能力、商业策略、市场表现三大方向的 25 大维度,为 14 家头部向量数据库排好了彼此的身家位次。

在 Forrester 的座次表中,进入领导者象限的,是第一派玩家 —— 向量数据库创业公司的代表 Zilliz;第二梯队,则以 Oracle、Microsoft、AWS、Pinecone 为代表;第三梯队,则是 MongoDB 等玩家。
整体来说,向量数据库创业公司的整体座次与入围数量最为占优;第二派传统数据库玩家以及第三派云服务巨头的表现各有千秋。
如何对不同玩家进行座次排布,Forrester 也表述的很直白:优秀的向量数据库供应商,应当具备以下能力:1、向量索引、元数据管理、向量检索和混合搜索等各种完整的向量数据库功能;2、完整的数据管理功能,包括向量存储、实时数据更新、数据集成、资源优化、数据完整性和一致性、并发控制和弹性可扩展性;3、用户友好的 UI 设计以及全面好用的 API;4、面对亿级数据规模的可扩展性,对 GPU 集成的支持。

以此次进入领导者象限的老牌玩家,也是向量数据库的开创者 Zilliz 为例。Forrester 对其作出的评价是,Zilliz 整体在管理海量向量数据方面表现突出。尤其在向量维度、向量索引、性能和可扩展性上表现出色,因此尤其适合那些优先考虑高性能和低延迟访问大量向量数据以用于高级 AI 应用程序的客户。
具体展开来说,在 Forrester 最关心的向量索引层面,以 Zilliz 为代表的原生向量数据库相比在普通数据库上做加法的产品,在基础的向量索引、元数据管理、向量检索和混合搜索方面,具备先天的优势。
完整的数据管理功能方面,Milvus 与 Zilliz Cloud 更是市面上为数不多可以提供(向量存储、实时数据更新、数据集成、资源优化、数据完整性和一致性、并发控制和弹性可扩展性)等功能的产品,与之形成鲜明对比的是部分市面上宣传的向量数据库产品,在相当长一段时间里,连最基本的备份恢复功能都不具备。
UI 与 API 等用户使用体验方面,Zilliz Cloud 可以提供开箱即用的向量数据库服务。
可扩展性上,Milvus 能够处理数百万乃至数十亿级的向量数据,是最受欢迎的开源向量数据数据库之一;而 Zilliz Cloud 能为用户提供百亿级向量数据毫秒级检索能力。与此同时,GPU 集成上,GTC 2024 上,Zilliz 还与英伟达联手发布了全球首个 GPU 加速向量数据库,由英伟达 CUDA 加持,性能实现 50 倍提升。
产业侧,Zilliz 除了是 OpenAI 官方首批 plugin 合作的向量数据库之外,全球的客户与合作伙伴数量也已经超过万家,并在图片检索、视频分析、自然语言理解、推荐系统、定向广告、个性化搜索、智能客服、欺诈检测、网络安全和新药发现等领域实现落地。
总结来说,Milvus 与 Zilliz Cloud 是市面上为数不多,做到了向量管理等基础功能之外,能够对海量数据支持、完整数据库功能做好产品级支持的玩家。
而对另外两派玩家的点评,可以从其对 AWS 以及 Oracle 的点评中一窥 Forrester 的态度。
对于 Oracle,产品能力、商业策略上的优势不必多提,但报告开篇,Forrester 也直白指出,传统数据库在向量维度和相似性搜索方面存在局限性。
关于 AWS,Forrester 则认为其在向量维度、数据库管理、API 支持、数据安全性和向量搜索等方面颇有建树,而最大的不足则在于,这些服务仅限于 AWS 云。
没有人会不喜欢一个完整的生态,但是如果选择生态的代价是将最核心的数据资源与之绑定,那么决策的天平也会就此倾斜。
尾声
一个被低估的市场
在向量数据库的割据暗流涌动之时,一个时间锁已经清晰出现在眼前。
历史上,围绕数据库发生的战争,这已经是第三次。
上世纪八十年代,以美国军方的需求为牵引,数据库的老牌玩家甲骨文就此在 IBM 的铜墙铁壁包围下诞生,使用关系型数据库处理结构化数据成为此后三十年间数据库产业的主流。
到了 2010 年前后,互联网的成熟,使得人类历史所产生的数据量飞速膨胀,与此同时,我们对数据的需求,也在关系型数据库的 “行列” 运算的基础上演变,存储、读取,高并发成为这一时期的典型特色,由此,非关系型数据库(简称 NoSQL)诞生,MongoDB 成为这一时期的代表性玩家。
再到 2022 年底,大模型技术成熟,传统的基于字段的精准搜索之外,基于向量的相似性搜索需求瞬间爆发,向量数据库一时之间炙手可热。过程中,一大批新的 “大卫” 开始向巨人歌利亚发起挑战,淘汰与玩家梯队也在两年间迅速产生阶段性成果。
为什么阶段性的胜出者会是 Zilliz 为代表创业公司?
答案很简单 —— 尊重市场。
尊重的第一层,是尊重时代的机遇。与过去的任何一次技术浪潮都不同,站在开源的肩膀上,大模型的诞生与普及,让全世界所有企业都站在了同一起跑线。也是因此,全球化成为了这一批企业的共同代名词 —— 在 Zilliz 成立之初,所有的新品与技术发布,是面向全球的,团队的构成也同样遍布中国、美国、欧洲、日本、新加坡全球各处。
尊重的第二层,是尊重客观的用户需求,以及非结构化数据的差异性和巨大潜力。面对用户的需求,Zilliz 既有在 GitHub 上 3W 星的开源项链数据库 Milvus,同样有主打开箱即用的 Zilliz Cloud 。敢于从 0 做起,构建全新的产品以及服务,而不是简单的成熟产品做加法。
这种尊重的第三层,也是最重要的一环则是坚持。作为最早一批向量数据库企业,Zilliz 早在大模型尚未成为显学的 2019 年,就敲下了全世界范围内向量数据库的第一行代码,即是市场的开创者,也是长期的布道者,这也为后来 Zilliz 登上英伟达与 OpenAI 的生态大船,埋下伏笔。
未来,谁会是下一个从大风大浪里走出来的 IOE,市场还需要时间验证,但天平已经在慢慢向长期主义选手倾斜。
#智源研究院实现数字孪生心脏电功能超实时仿真
世界首次!
心脏,作为重要器官之一,其功能正常与否直接影响人类的生命延续。电生理特性反映了心脏的健康和疾病状态。心脏电生理活动的异常,往往会导致心律失常,从而引至心脏泵血功能衰竭等严重健康问题。因此,深入理解和研究心脏的电生理过程,对于提高心脏病的诊断和治疗水平至关重要。
传统的心脏电生理研究多依赖于实验室内的动物模型和临床数据,但这类方法往往受限于伦理问题、实验条件和数据获取的复杂性。随着计算技术的发展,计算机仿真成为了一种新兴且强大的研究工具。通过建立数学模型和计算机程序,研究人员可构建数字孪生心脏,能够在虚拟环境中仿真并重现心脏器官的电生理活动(虚拟生理心脏),分析其动态特性,并进行不同生理与病理条件下的实验。
虚拟心脏电生理仿真对计算资源要求极高,即使是几毫秒的仿真,也需要累积求解数十亿次微分方程。使用复杂的虚拟心脏模型进行研究时,重现 1 秒钟的心脏电活动也可能需要数小时或更长。这给虚拟生理心脏的临床应用与药物研发带来重大挑战。
为解决这一问题,智源研究院开发了一套实时心脏电生理仿真系统。该系统不仅能够实时模拟心脏的 3D 电活动,还能通过多种参数的调节,深入探讨不同生理、病理因素对心脏功能的影响。
这一实时心脏仿真平台,一方面可在医学基础研究领域发挥作用,帮助临床医生和研究人员更直观地理解心脏的电生理过程,探究心律失常产生机制、预测猝死发生率等;另一方面,可用于构建虚拟药物安全性评估平台,对推动药物安全评估发展具有重要意义;更重要的是,可以在临床应用中提供手术方案预演与决策支持,比如射频消融方案规划,心脏起搏器最佳植入方案规划等。该技术的推进将为医学研究和临床治疗提供新的范式。
1 虚拟心脏仿真发展史
虚拟生理心脏的构建可利用生理组学的研究方法,综合分子生物学、生物化学、生理学、解剖学及临床医学的最新成果,数学化以及模式化地整合从基因、蛋白质、细胞、组织到器官的解剖(多物理尺度:空间尺度跨越 10^9 量级,跨时间尺度:时间尺度跨越 10^15 量级,如图 1 所示)、生理和生化信息,应用计算机强有力的计算和图形显示能力,通过赋予其心脏所具有的动力学特性、生化特性和各种生理病理特点,使之从形态、结构和功能等方面逼真地再现心脏的生理和病理活动过程。

图注 1:构建虚拟生化生理人体的时间和空间尺度。时间尺度横跨由分子事件(µs)、细胞信号传导(ms)、细胞功能(s)到人体寿命 (decades) 的 10^15 跨度。空间尺度横跨由分子(nm)、细胞(µm)、器官(cm)到躯干 (m) 的 10^9 跨越。
虚拟生理心脏研究可追溯与上世纪五十年代。1952 年诺贝尔奖得主 Hodgkin 和 Huxley 建立了世界上第一个细胞计算模型 — 乌贼神经元细胞模型 [1],开创了用计算模型研究生物问题的先河。1960 年 Denis Noble [2] 在 Nature 杂志上发表了第一个心肌细胞计算模型 — 浦肯野心肌细胞模型,开创虚拟生理心脏模型的先例。此后几十年的研究中,不断有研究人员研发针对不同物种、心脏不同组织、复杂精密的心肌细胞电生理模型 [3]。1991 年,Peter Hunter 等人 [4] 基于犬实验数据构建了第一个心脏解剖结构模型,融合多物理尺度与电生理的虚拟心脏模型研究进入新阶段。此后,多尺度、多物理模态的心脏计算模型陆续出现,并被成功应用于心脏功能研究与药物安全性评估 [5-8]。
在早期虚拟生理心脏研究中,心脏一个生物秒的电生理活动往往需要数日甚至数月来仿真计算。随着显存技术的发展,这个时间缩短到数天。近年,有研究致力于提升虚拟生理心脏的计算速度。比如通过将三维心脏空间划分为矩形子区域来实现并行心脏模拟 [9],使运算速度大大提升。另一项研究通过 WebGL 将高性能心脏模拟扩展到普通计算机上 [10],甚至有 GPU 的手机也可以模拟三维心室的电动态。一些研究试图通过自适应时间步长来提高运行速度 [11,12],结果表明,固定时间步长比自适应时间步长方法具有更好的效率 [11]。
但这些研究仅能达到「准实时运算」,离真正意义上的「实时运算」,即仿真时间与生物时间比达到 1:1,还有难以逾越的距离,更不用说仿真精度的提升带来的运算量爆炸式增长。高计算复杂度带来的海量运算,使得虚拟生理心脏模型难以实现实时计算,阻碍其大规模应用。
2 实时计算
为了在更高分辨率、更高精度和更大规模的心脏模型上实现实时仿真,智源研究院开发了具有精确细胞电生理与解剖结构的人心室模型。该模型包含了 19 种细胞生理状态变量和 70 多个公式,能够实现复杂的心脏电生理与病理仿真,为临床与医药工业应用提供丰富的场景。
为实现实时计算,智源对模型底层计算进行了深度优化。针对心脏仿真中计算强度大和 I/O 密集等瓶颈问题,智源充分结合 A100 平台的硬件特点,设计了多种优化策略,如量化和循环展开。这些措施有效降低了计算复杂度和 I/O,使得在更大规模和更高复杂度的心脏模型上实现了 180 倍的速度提升。
最终,智源虚拟心脏仿真系统实现了对心脏电生理功能的实时仿真,达到生物时间与计算时间比为 1:0.84。这一成果不仅提升了心脏仿真系统的性能,还为更广泛的医学研究和临床应用提供了强有力的支持,标志着心脏仿真技术的又一重大里程碑进展。

图注 2:实时心脏计算概览图。
2.1 技术路线
在 GPU 的架构设计中,顺序访问内存(如连续的数据访问)相较于随机访问具有更高的性能。此外,在执行顺序访问时,通常会采用预取技术提前加载数据,以进一步提高访问效率。
同时,在虚拟心脏模型中,大约有 2/3 的物理空间位置是空余腔体空间,有效心肌组织仅占 1/3 的物理空间。心脏仿真的主要计算和 I/O 操作都集中在对有效心肌组织中的每一个单细胞中的离子通道和细胞膜电位进行时间上的精细更新,同时考虑邻近细胞的电耦合影响。
基于 GPU 访存特点和心脏解剖结构的特殊性,我们设计了适合稀疏数据的数据结构。利用顺序访存提升 I/O 速度,确保并行线程仅处理有效细胞,从而最大限度地提高 GPU 内存的利用率。通过这种创新的结构,显著优化了计算性能,使得心脏仿真能够在 IO 访存上达到最优效果。

图注 3:心脏模型有效数据在 GPU 内存上的排布。
在计算层面,采用量化策略,有效简化模型中的对数和指数等复杂计算,从而显著降低了计算复杂度。
此外,为进一步减少 I/O 操作次数,采用循环展开策略,实现在一次读取中进行多次计算,大大降低 I/O,显著提升 SM 核心的计算利用率。
基于 A100 平台,我们设计了高效的 P2P 通讯方式,利用 GPU 直连实现在节点内快速的数据交换,确保数据传输的低延迟与高带宽。在节点之间,采用 RDMA(远程直接内存访问),进一步增强跨节点数据传输的效率,充分发挥硬件平台的并行计算与通讯能力。

图注 4:技术路线图。
2.2 仿真结果
我们测试了不同优化策略对仿真 2 生物秒心脏功能所用计算时间的影响,结果如下图所示。对 2 生物秒心脏功能的模拟,基准模型在未优化的情况下 A100 单卡需要计算时间为 304.25 秒。在采用分布式、量化、循环展开策略后,其所用时间分别是 9.75、3.93、1.68 秒。其中采用循环展开后,计算时间达到 2 秒内,达到计算时间 / 生物比小于 1,实现实时 / 超实时计算的要求。其中,分布式计算对于系统仿真速度影响最大,达到了 32 倍提速。量化策略和循环展开策略分别将仿真速度提升了 2.48 和 2.34 倍。在同时采用分布式、量化、循环展开策略的情况下,系统仿真速度整体提升了 181 倍。

图注 5:不同优化策略的计算时间。

图注 6:不同优化策略的速度提升。
2.2.1 拓展曲线

图注 7:不同优化策略的拓展曲线。
如图 7 扩展曲线所示,随着 GPU 卡数的增加,基准模型和优化后的模型仿真时间都在减少。基准模型在增加到 48 卡后,计算时间不再减小。此时的生物:计算时间比为 1:5。再采用量化和循环展开策略后,32 张卡即可实现实时计算,生物:计算时间比达到 1:0.84。
2.2.2 主要 GPU 指标

图注 8:不同优化策略的计算密度和计算强度。

图注 9:不同优化策略的内存和 SM 利用率。
通过 GPU 指标可以看出(图 8,图 9)量化策略通过提升 IO 同时降低计算的方式提高整体计算性能;循环展开通过大幅度降低 I/O 同时提高计算密度的方式提高计算性能。
2.2.3 计算精度
我们统计了加速前与加速后的结果误差,仿真的膜电位 V 的时程差别 < 2 ms (0.6%),模电位平均误差为 0.72mV (0.4%),均满足生理准确度要求。优化前后主要离子通道的仿真曲线吻合(如图 10 所示)。

图注 10:仿真前后细胞主要离子通道电流与胞内离子浓度在一心律节拍间的变化。
3 总结
智源研究院从心脏模型的解剖结构、心肌细胞电生理的计算特点及计算系统的硬件架构出发,设计了心脏仿真系统的数据结构和优化策略,以提高计算效率。我们采用先进的并行处理方法,充分利用现代 GPU 设备的强大计算能力,优化数据传输和通讯方式,以减少延迟并提高数据吞吐量。通过这些策略,不仅提升了仿真系统的计算速度,还保证了在可接受误差范围内的计算精度,最终成功实现了心脏仿真的实时计算目标,达到超实时计算结果。这一成果为进一步研究心律失常产生的离子通道与分子机制等关键医学问题,也为手术规划如房颤射频消融方案等临床应用,以及新药研发与其心脏安全性筛选奠定了坚实基础,同时也为其它超大复杂物理系统的实时仿真提供坚实基础。
#SANA
rebuttal真的有用!这篇ICLR论文,所有审稿人都加了2分,直接跃升排名第9
最近,正处于评议阶段的 ICLR 2025 论文真是看点连连,比如前些天爆出的 ICLR 低分论文作者硬刚审稿人的事件以及今天我们要介绍的这个通过 rebuttal(反驳)硬是将自己的平均分拉高 2 分,直接晋升第 9 名的论文。


ICLR 2025 论文评分分布图,图源:https://papercopilot.com/statistics/iclr-statistics/iclr-2025-statistics/
顺带一提,不知道是不是因为 ICLR 2025 审稿过程状况连连,官方此前还决定将论文讨论过程延长 6 天。

下面我们就来看看这篇「咸鱼翻身」的论文究竟研究了什么以及它的评审和反驳之路。
- 论文标题:SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
- 论文地址:https://arxiv.org/abs/2410.10629
- OpenReview:https://openreview.net/forum?id=N8Oj1XhtYZ
- 项目地址:https://nvlabs.github.io/Sana/
- 代码地址:https://github.com/NVlabs/Sana
论文主要内容
这篇论文提出的 Sana 是一种高效且经济地训练和合成高质量图像的工作流程,并且支持 1024×1024 到 4096×4096 的分辨率。下图展示了 Sana 生成的一些图像样本及其推理延迟情况。

作者表示:「据我们所知,除了 PixArt-Σ 之外,还没有直接探索 4K 分辨率图像生成的已发表研究成果。然而,PixArt-Σ 仅能生成接近 4K 分辨率(3840×2160)的图像,并且生成这种高分辨率图像的速度相对较慢。」
那么,这个来自英伟达、MIT 和清华大学的研究团队是如何做到这一点的呢?
具体来说,他们提出了多项核心设计。
深度压缩自动编码器
该团队提出了一种新的自动编码器(AE),可将缩放因子(scaling factor)大幅提升至 32!
过去,主流的 AE 仅能将图像的长度和宽度压缩 8 倍(AE-F8)。与 AE-F8 相比,新提出的 AE-F32 输出的潜在 token 量可减少 16 倍。这对高效训练和生成超高分辨率图像(例如 4K 分辨率)至关重要。
下表 1 展示了不同 AE 的重建能力。

图 3 则展示了对新提出的深度压缩自动编码器进行消融实验的结果。该结果证明了新 AE 各项设计的重要性。

高效的线性 DiT

该团队还提出使用一种新型的线性 DiT 来替代原生的二次注意力模块,如上右图所示。
原始 DiT 的自注意力的计算复杂度为 O (N²)—— 在处理高分辨率图像时,这个复杂度会二次级增长。该团队将原生注意力替换成线性注意力后,计算复杂度便从 O (N²) 降至 O (N)。

该团队表示:「我们认为,通过适当的设计,线性注意力可以实现与原生注意力相当的结果,并且还能更高效地生成高分辨率图像(例如,在 4K 时加速 1.7 倍)。
同时,他们还提出了 Mix-FFN,其作用是将 3×3 深度卷积集成到 MLP 中以聚合 token 的局部信息。
Mix-FFN 的直接好处是不再需要位置编码(NoPE)。该团队表示:「我们首次删除了 DiT 中的位置嵌入,并且没有发现质量损失。」
使用仅解码器小 LLM 来作为文本编码器
为了提升对用户提示词的理解和推理能力,该团队使用了最新版的 Gemma 作为文本编码器。
尽管这些年来文生图模型进步很大,但大多数现有模型仍然依赖 CLIP 或 T5 进行文本编码,而这些模型通常缺乏强大的文本理解和指令遵从能力。仅解码器 LLM(例如 Gemma)表现出的文本理解和推理能力很强大,还能有效遵从人类指令。
下表比较了不同文本编码器的效果。

通过直接采用 LLM 作为文本解码器,训练不稳定的问题得到了解决。
另外,他们还设计了复杂人类指令(CHI),以充分理解 LLM 那强大的指令遵从、上下文学习和推理能力,进而更好地对齐图像与文本。从下图可以看到,有无 CHI 的输出结果差异非常明显。

高效的训练和推理策略
为了提升文本和图像的一致性,该团队提出了一套自动标注和训练策略。
首先,对于每张图像,使用多个 VLM 来重新生成描述。虽然这些 VLM 的能力各不相同,但它们的互补优势可提高描述的多样性。
他们还提出了一种基于 Clip Score 的训练策略,即对于一张图像的多个描述,根据概率动态选择具有高 Clip Score 的描述。实验表明,这种方法可以提高训练收敛性和文本图像对齐程度。下表比较了训练期间不同的图像 - 文本对采样策略的效果。

此外,他们也提出了一种 Flow-DPM-Solver,相比于广泛使用的 Flow-Euler-Solver,这种新的求解器可将推理采样步骤从 28-50 步减少到 14-20 步,同时还能实现更好的结果。见下图。

实验结果
总体实验下来,该团队的新模型 Sana-0.6B 表现可谓极佳。在生成 4K 图像时,速度比当前最佳(SOTA)的 FLUX 方法快 100 多倍(见下图 2)。在生成 1K 分辨率图像时,也快 40 倍(见下图 4)。同时,Sana-0.6B 的效果在许多基准上都能与 FLUX 比肩!


不仅如此,他们还训练了一个参数量更大的 Sana-1.6B 模型。下表更详细地展示了这两个模型的性能表现,可以看到,对于 512 × 512 分辨率,Sana-0.6 的吞吐量比大小相近的 PixArt-Σ 快 5 倍,并且在 FID、Clip Score、GenEval 和 DPG-Bench 方面表现明显优于后者。对于 1024 × 1024 分辨率,Sana 比大多数模型强得多。这些结果说明 Sana 确实实现了低延迟、高性能的图像生成。

此外,他们还为 Sana 打造量化版本,并将其部署到了边缘设备上。
在单台消费级 4090 GPU 上,该模型生成 1024×1024 分辨率图像只需 0.37 秒,是一个非常强大的实时图像生成模型。

下面展示了 Sana-1.6B 模型的一些输出结果以及部署量化版模型的笔记本电脑。

rebuttal 真的有用?
很多时候,在审稿人的第一印象已经确定的情况下,rebuttal 能够改变的不多。
正如知名长文《审稿 CVPR 而致的伤痕文学(续):关于 Rebuttal 的形而上学》所说,从审稿人的角度来看,收到 rebuttal 时,可能早就已经忘了当时为什么会给这个审稿意见,对这篇文章的唯一记忆就是「我要拒掉它」。

引自 https://zhuanlan.zhihu.com/p/679556511 作者 @Minogame
那么,SANA 到底拿出了一份怎样的 rebuttal,四个审稿人看过后不再「已读不回」,反倒不约而同地加了 2 分呢?
第一位审稿人和第三位审稿人的意见比较相似,他们认为 SANA 的原创性有些不足。具体来说,第一位审稿人在缺点部分写道:
- SANA 的三个主要组件在文献中已有探讨:深度自编码器在 [1] 中有涉及,线性 DiT 在 [2] 中已有研究,[3, 4] 中已经使用了 LLM 作为文本编码器。将这些组件结合起来并不构成一个真正具有创新性的想法。
- 作者没有充分解释他们的 CHI 流程是否与 [5] 中的相同。如果相似,那么这甚至会进一步削弱该工作的创新性。

第三位审稿人则希望作者们补一些消融实验,逐个组件分析,明确 SANA 相较于 PixArt-Σ 和 Playground v3 等类似的模型有什么创新之处。

SANA 的研究团队首先详细地说明了站巨人的肩膀上创新和做学术裁缝的区别。
比如,LinFusion 中的线性注意力是蒸馏策略的一部分,而作者们把 SANA 作为一个基础生成模型,从头开始设计、训练。为了让线性注意力在所有层中代替原来的自注意力,他们做出了 Mix-FFN 解码器。
这样,相比其他方法将所有 token 映射到一个低秩的 NxN 状态中,SANA 更接近于直接的 O (N) 注意力计算,这是以前的研究未能有效解决的问题。
对比同样提交给 ICLR 2025 的「DC-AE」,SANA 解决了未涉及的独特问题,比如简单地在潜在空间中增大通道(F8C4→F32C32)会使得训练收敛速度大大减慢,他们设计了线性注意力 + Mix-FFN 块加速收敛。
而此前 LLM 作为文本编码器的方法,更多只是简单地用 LLM 替代了 T5/Clip,并未像 SANA 一样深入研究了如何激发 LLM 的推理能力。
针对审稿人的问题,作者补充了一系列消融实验,比较了 LiDiT 和 SANA 的 CHI 效果,并逐个组件地展示了 SANA 在 PixArt-Σ 基础上的进展。

这两位审稿人也是给出了一个提分的大动作:


第二位审稿人更在意技术细节,他觉得 SANA 如何搭建的线性注意力模块还可以说得更清楚。
具体来说,需要明确一下,他们是如何实现线性注意力能全局替代传统自注意力,同时保持足够的上下文信息和依赖关系建模的,还要补 4096*4096 分辨率的图像与其他方法的实验对比。

在一通极其详细的解释之下,这位(可能不清楚目前没有 4K 版本 InceptionNet 的)审稿人也把分数也提了 2 分。

第四位审稿人则给出了 10 分的最高分评价。

一开始,该审稿人指出了这篇论文的一些缺点,包括表 9 中的 Gemma2-2B-IT 模型需要解释、需要进一步比较 Gemma2 和 T5-XXL 以及缺乏对 UltraPixel 等引用等等。
然后,作者对该审稿人的四个问题逐一进行了详细解答,并为论文内容做了进一步的补充。此后,又是关于 ClipScore 的几个来回讨论。

最后,审稿人被作者说服,表示:「我再也看不到这篇论文中任何明显的缺点了。因此,我提高了我的评分。这项工作确实应该作为会议的亮点!很出色的工作!」

从这些审稿人与作者的互动可以看到,建设性的讨论和修正确实可以帮助改善审稿人对一篇论文的看法。
在多次交流中,审稿人对论文中不清晰或薄弱的部分提出了具体改进建议,而作者也根据反馈进行了细致的修改。这种积极的互动不仅使论文的质量得到了提升,也促进了审稿人与作者之间的理解与信任。最终,审稿人对论文的评审意见变得更加正面,并愿意为作者提供更多的指导。
对此,你有什么看法?
#YOPO_MLLM_Pruning
12%计算量就能媲美原模型,Adobe、罗切斯特大学等提出YOPO剪枝技术
本篇论文的核心作者包括罗切斯特大学的博士研究生张泽良,指导教师徐辰良副教授,以及来自Adobe的研究员赵文天,万锟和李宇哲。
尽管近期 Qwen2-VL 和 InternVL-2.0 的出现将开源多模态大模型的 SOTA 提升到了新高度,但巨大的计算开销限制了其在很多场景下的应用。近日,Adobe 研发团队联合罗切斯特大学系统性得研究了主流多模态大模型在参数和计算模式层面的冗余,并提出了名为 YOPO(You Only Prune Once)的一系列剪枝方案。实验结果表明 LLaVA-1.5 只需保留 12% 的计算量即可获得与原始模型同等的性能,并且实验团队还验证了这些计算冗余在 Qwen2-VL 和 InternVL-2.0 同样普遍存在。这为高效处理密集视觉 token 提供了新路径。
目前代码、模型和项目主页均已放出。
- 论文:Treat Visual Tokens as Text? But Your MLLM Only Needs Fewer Efforts to See
- 论文链接:https://arxiv.org/abs/2410.06169
- 开源代码 & 模型:https://github.com/ZhangAIPI/YOPO_MLLM_Pruning/tree/main?tab=readme-ov-file
背景介绍
近期多项研究表明,随着模型规模和输入图像分辨率的增加,多模态大模型的能力也随之提升。然而,使用更大的模型或引入更多视觉 tokens 会带来显著的计算负担。大部分多模态大模型视觉 token 数量在几百到几千不等,通常远大于文本 token 的数量。这种巨大的不平衡带来了一个关键挑战:模型的计算成本随着总输入 token 的数量的平方而增加,从而限制了多模态大模型的可扩展性。尽管近期一些工作提出了对视觉 token 做削减的解决方案,如 FastV,SparseVLM, Pyramid-drop 等,但这类方法不可避免得在判断削减哪些视觉 token 时引入了额外的计算量。为此研究团队提出了在不引入额外计算量的前提下对模型参数和计算模式进行更高效剪枝,并在多个 benchmark 上实现了 SOTA。
方法

1 邻域感知视觉注意力:研究团队发现尽管多模态大模型中存在大量的视觉 tokens,但在

的注意力计算中,大多数注意力是稀疏的,且显著的注意力权重主要集中在相邻的视觉 tokens 上。为减少由这种冗余引起的计算负担,研究团队提出了一种简单而有效的剪枝方法,选择性地消除视觉 token 之间的非必要注意力计算。具体而言,研究团队对注意力机制进行了修改,使得只有相邻的视觉 token 彼此关注,而文本 token 则保留了在视觉 token 和文本 token 之间自由关注的能力。修改后的视觉注意力计算过程如下:

在应用了此剪枝方案后,模型的计算复杂度由和视觉 token 数量的二次方成正比降为了和其数量成正比。
2 非活跃注意力头剪枝:研究团队以 LLaVA-1.5 作为研究对象,随机选取了 100 个视觉问答样本,可视化了视觉 token 的不同注意力头的权重,实验发现大约有一半数量的注意力头都没有被激活。由此可见这部分注意力头的相关计算同样存在大量冗余并可以被剪枝。
3 选择性层丢弃:研究团队通过可视化 LLaVA-1.5 不同层的视觉 token 跨模态注意力权重发现,大权重集中在前 20 层,在第 20 层到 40 层之间权重接近于 0。

这项结果表明靠后的 20 层的视觉计算存在大量冗余。这一观察启发了研究团队在靠后的层中直接跳过所有与视觉相关的计算,从而减少计算开销。具体来说,对于层 l>L−N,视觉注意力和跨模态注意力计算都被省略,使得注意力计算可以简化如下:

4 在 FFN 中进行稀疏视觉投影:通过剪枝大部分视觉注意力计算,模型的视觉表示变得高度稀疏。为了有效利用这种稀疏性,研究团队提出在每个 transformer 模块内的 FFN 隐藏层中随机丢弃 p% 的神经元。
实验结果

研究团队在众多常见基准上评估了他们提出的方法在剪枝 LLaVA-1.5-7B 和 LLaVA-1.5-13B 模型中的效果。由表中得知,在相同的计算预算(即相同的 FLOPs)下,团队提出的剪枝方法在四个样本较多的基准测试上一致性得取得了最佳结果,分别在 GQA、VQAv2、POPE 和 MMB 上比第二优方法平均高出 3.7%、1.1%、2.2% 和 0.45%。
为了展示此种方法在剪枝视觉计算冗余方面的可扩展性,团队在两个最大的基准测试 VQAv2 和 GQA 上,以不同的剪枝粒度,将他们提出的策略与 token 剪枝代表性工作 PyramidDrop 和 FastV 进行比较。可以观察到,随着视觉计算的 FLOPs 减少,剪枝模型的性能也随之下降。具体来说,对于使用 FastV 剪枝的模型,将 FLOPs 从 75% 减少到 19% 导致在两个基准测试上的平均性能从 71.35% 降至 66.63%。相比之下,团队提出的方法并未直接剪枝 token,而是针对参数和计算模式层面的冗余计算进行剪枝,从而仅导致 0.5% 的性能下降。

为了进一步印证文中观察到的大量视觉计算冗余是普遍存在的,团队将该方法应用于其他模型包括 Qwen2-VL-7B 和 InternVL-2.0 4B/8B/26B。团队在 GQA 和 POPE 基准上评估了性能,并调整剪枝粒度以在保持原始模型性能的同时尽量减少 FLOPs。如图所示,即使在未微调的情况下,以适当比例剪枝这些模型的视觉计算也不会影响其性能。此外,更大的模型能够适应更高的剪枝比例,这从不同模型规模下对 InternVL-2.0 的剪枝结果中得到了验证。

讨论
为什么不直接同时剪枝视觉和文本的参数?研究团队专注于减少视觉 token 计算中的冗余,从而降低其开销,同时保留文本 token 的计算。为了探讨文本 token 是否也存在类似的冗余,团队进行了一个实验,分别对仅视觉 token 和视觉与文本 token 同时剪枝 20 个注意力头。在未进行微调的情况下,仅剪枝视觉 token 在 VQAv2、GQA、SQA 和 TextVQA 上的平均性能为 67.1%,而同时剪枝视觉和文本 token 的性能则大幅下降至 4.3%。这表明在当前多模态大模型中,视觉计算中的冗余显著高于文本计算中的冗余。
对 token 剪枝和计算模式剪枝的效率分析。研究团队对不同输入视觉 token 数量下各方法的效率进行了比较。结果表明,与基于 token 剪枝的方法相比,从计算模式层面解决视觉计算冗余问题在处理较长视觉序列时具有更大的效率优势。这种方法有效缓解了处理大量视觉 token 所带来的计算开销上升问题,展现了其在处理视觉序列方面的可扩展性。

总结
研究团队针对剪枝多模态大模型以实现高效计算的挑战进行了研究。与文本不同,视觉信息具有高度稀疏性和冗余性。以往的研究主要集中在减少视觉 token 数量;而本篇工作则分析了参数和计算模式中的冗余性。团队提出的策略包括:邻域感知的视觉注意力、非活跃视觉注意力头的剪枝、FFN 中的稀疏视觉投影以及选择性层丢弃。这些方法将 LLaVA-1.5 的计算开销减少了 88%,同时大幅保留了其性能。针对 Qwen2-VL-7B 和 InternVL-2.0 4B/8B/26B 的额外实验进一步证实,视觉计算冗余在多模态大模型中普遍存在。
#MSSP
LLM破局泛化诊断难题,MSSP刊登北航PHM实验室健康管理大模型交叉研究
论文作者来自杭州北航国新院、北航,主要作者:陶来发、刘海菲、宁国澳、曹文燕、黄博昊、吕琛(通讯作者)。吕琛教授:国家级领军人才、英国皇家航空学会会士;陶来发教授:国家级青年人才。
近日,《Mechanical System and Signal Processing》(MSSP)在线发表刊登北航 PHM 团队最新研究成果:基于大语言模型的轴承故障诊断框架(LLM-based Framework for Bearing Fault Diagnosis)。
- 这是北航 PHM 实验室在健康管理大模型领域的成功尝试,研究团队提出了基于大语言模型的轴承故障诊断框架,提升预训练大模型对振动数据的解析与泛化能力。
- 以轴承为例,他们探索并打通了基于预训练大语言模型解决泛化故障诊断难题的技术路线,初步展现了对跨工况、小样本、跨对象等泛化诊断任务的综合解决能力。
- 北航 PHM 实验室为业界学者应对故障诊断领域泛化痛点问题提供了新思路,也是深入开展大模型与健康管理交叉研究并建立健康管理大模型的重要基础与参考。
- 论文原文:https://doi.org/10.1016/j.ymssp.2024.112127(MSSP 期刊)
- https://arxiv.org/abs/2411.02718(arXiv 预印)
背景介绍
健康管理(Prognostics and Health Management,PHM)是避免设备故障导致人员安全和经济财产损失的重要技术手段,而算法模型泛化性不足等瓶颈问题严重制约着 PHM 技术的发展应用。作为健康管理的重要环节,传统故障诊断也面临着跨工况适应能力、小样本学习能力和跨对象泛化能力等诸多挑战。
大语言模型(LLM)通过千亿级参数化的先验知识与深层次的模式识别能力,为提升故障诊断模型的泛化性提供了新的可能性。因此,团队整合 LLM 与传统故障诊断技术优势,以轴承为例探索并打通基于预训练大语言模型解决泛化故障诊断难题的可能性和技术路线,初步展现了对跨工况、小样本、跨对象等泛化诊断任务的综合解决能力。
分别开展了单数据集跨工况实验和全量及少量样本的跨数据集迁移实验,验证所提出框架同时完成三种泛化故障诊断任务的能力,证明 LLM 对输入的模式和形式具有良好的适应性。
主要创新及成果
为解决泛化诊断难题,论文提出基于 LLM 的轴承故障诊断框架,创新点主要包括振动数据特征的文本化处理和预训练模型微调方法。

针对轴承故障诊断中振动数据难以挖掘语义信息的问题,基于传统故障诊断的统计学分析框架,提出了一种融合时域和频域特征提取的信号特征量化方法,将时序数据进行文本化处理,旨在通过精简的特征选择高效学习小样本和多工况下的共性特征。

针对 LLM 在解析振动数据特征时泛化能力不足的问题,该团队采用基于 LoRA 和 QLoRA 的振动数据微调方法,有效利用预训练模型的深层语义理解能力,提高故障诊断的精确度并增强模型的泛化性能。
针对创新点的实验验证。通过单数据集实验、单数据集跨工况实验以及全量、少量跨数据集实验,该团队证明了所提出框架同时具备跨工况、小样本、跨数据集故障诊断能力。

研究团队采用 CWRU、MFPT、JNU、PU 四个轴承故障诊断公开数据集,分别针对基于特征的 LLM 故障诊断和基于数据的 LLM 故障诊断方法进行验证。


案例实验验证了所提出框架在三种泛化任务上的适应性,且经过跨数据集学习的模型同比获得 10% 左右的精度提升。
未来研究方向
1. 该框架更多地在特征提取和故障模式判别阶段将 LLM 与故障诊断相结合,未来可充分利用诊断领域知识和大模型架构知识,实现大模型与装备故障诊断的深度融合。
2. 论文以轴承为例,探索了预训练 LLM 解决泛化故障诊断难题新思路。未来可将其作为基础与参考,特异性设计模型结构,将框架拓展至其他领域对象,如动力、控制系统的电源、功能电路等。
3. 论文以故障诊断为例展示了 LLM 对传统健康管理手段的扩展能力,未来还可将技术延拓到预测、评估等典型健康管理领域,打通 PHM 开发方案生成、数据生成、能力生成、解决方案生成、验证评价、方案更新等技术流程,支撑装备 PHM 设计、诊断、评估、预测、决策、推荐、验证、更新等下游任务。
4. 论文利用 LLM 的文本处理能力及泛化性能,初步实现了基于预训练 LLM 的泛化故障诊断功能;未来将在此基础上,构建以健康管理领域多模态信息为基础、以 PHM 各种功能需求为主要业务、以生成涌现能力为目标的垂直领域健康管理大模型,实现以通用化、判别式、实战性为主要特点的健康管理领域新生态及根本性技术转变(参考 An Outline of Prognostics and Health Management Large Model: Concepts, Paradigms, and Challenges, https://arxiv.org/abs/2407.03374)。
也欢迎关注北航 PHM 团队提出的健康管理大模型进阶研究范式 roadmap!
- 论文链接:https://arxiv.org/abs/2407.03374
#基于Pytorch做深度学习
简单分为几步
基础:Python 、 Numpy、 Pandas 、 Pytorch
理论:简单了解 MLP,CNN 、 Transformer 为主,再考虑 RNN 的基础
模型:AlexNet、 VGG 、 ResNet、 Yolo 、 SSD 是里任选两个自己手写代码,标记数据、训练一下就好了。如果你真的有志于此,那我建议你手写完整的 Transformer 模型,这现在看是未来的所有。
完成上面几步,这样你就是一个不错的入门选手了。再看看书,就是一个只需要你部就班就能成为高手的路!
基础
首先,作为一名深度学习从业者,掌握 Python 是基础。Python 除了语法简洁外,其生态系统中包含了大量用于数据处理和科学计算的库,这些是进行深度学习研究和应用开发的必备工具。下面这几个是必须的:
Numpy:这是一个强大的科学计算库,提供了大量的数学函数处理以及对大型多维数组和矩阵的支持,是深度学习中进行数学运算的基石。
Matplotlib:这是一个用于创建静态、交互式和动画可视化的库。在深度学习中,它常用于数据可视化,如绘制训练过程中的损失曲线和准确率曲线。
Pandas:这是一个强大的数据分析和操作工具,特别适合用来处理和分析结构化数据。它在数据预处理阶段非常有用,特别是当你需要对数据进行清洗、转换和准备工作时。
在深度学习框架方面,PyTorch 和 TensorFlow 是两个主流选择。
PyTorch:由于其易于理解的编程风格和动态计算图,PyTorch 在研究领域特别受欢迎。它的直观性使得开发新算法和实验新想法变得简单。
TensorFlow:相比之下,TensorFlow 在工业界更为流行,尤其是在需要大规模部署的场景中。TensorFlow 提供了一个全面的生态系统,包括用于生产部署的工具和资源。
理论(完全以编码为假设条件)
简单了解 MLP,CNN 、 Transformer ,再考虑 RNN 的基础。至少你要懂下面的东西。
- 多层感知机(MLP):
- 基础:MLP是神经网络的最基本形式,包含输入层、若干隐藏层和输出层。每一层都由一系列神经元组成,这些神经元与上一层的每个神经元相连接。
- 卷积神经网络(CNN):
- 核心:CNN在图像处理和计算机视觉领域非常成功。它的关键在于使用卷积层来自动和有效地提取图像的特征。
- 结构:一个典型的CNN包括卷积层、池化层和全连接层。卷积层通过卷积核提取局部特征;池化层则负责降低特征的空间维度;最后,全连接层用于分类或回归任务。
- 应用:CNN广泛应用于图像识别、视频分析和自然语言处理等领域。
- Transformer:
- 创新:Transformer模型在自然语言处理领域引起了革命。其核心是“自注意力”(Self-Attention)机制,允许模型在处理序列数据时关注序列中的任何部分。
- 优势:与RNN和LSTM相比,Transformer在处理长距离依赖方面更有效,且计算更可并行化。
- 应用:它是许多现代NLP模型的基础,如BERT、GPT、 LLaMa系列等。
- 循环神经网络(RNN):
- 特点:RNN是处理序列数据的一种经典方法。它通过在序列的每个步骤传递隐藏状态来保存过去信息。
- 局限:标准的RNN在处理长序列时遇到梯度消失或爆炸问题,这限制了其在长序列上的性能。
- 改进:LSTM(长短期记忆)和GRU(门控循环单元)是改进的RNN变体,设计用来解决这些问题。
这里我没有详细展开大模型LLM,因为我发现有个简单丝滑的途径,就是知乎知学堂的 AI 大模型公开课,特别适合代码水平不高,但是又想做深度学习或者入局 AI 大模型的人,这个课其实是一份非常有意思的AI大模型的系统性入门课程,而且现在还免费,入口我给大家要过来了,直接听就可以↓
对了,课程里关于Transformer 的原理、使用Fine-Tuning进行模型微调的技术一定要仔细听,这是深度学习里非常重要的理论和实操教程,代码水平不高也没关系,跟着老师的指导走就行了。
模型与实际操作
在深度学习和计算机视觉领域,AlexNet、VGG、ResNet、Yolo和SSD都是极为重要的模型,各自代表了图像识别和对象检测领域的重要进展。为了深入理解这些模型的工作原理和应用,手写代码并亲自进行数据标记和训练是一个非常有效的学习方法。
- AlexNet 和 VGG 是两个很好的起点:
- AlexNet:作为深度学习历史上的里程碑,AlexNet 在2012年的ImageNet挑战赛中大放异彩。它的结构相对简单,包含5个卷积层和3个全连接层。手写AlexNet并在数据集上进行训练,可以帮助你理解卷积神经网络的基本构件和工作原理。
- VGG:VGG网络以其简单和高效著称,特别是VGG-16和VGG-19。这些网络通过重复使用相同大小的小卷积核,展示了深层网络结构的强大能力。尝试手写VGG并训练它,将加深你对网络深度如何影响性能和特征学习的理解。
- 手写Transformer模型:
- 如果你对深入学习人工智能有长远的打算,那么手写完整的Transformer模型将是一个有意思的挑战。Transformer自2017年被提出以来,已经成为自然语言处理领域的核心模型,并且其影响力也扩展到其他领域如计算机视觉和音频处理。
- Transformer模型的核心在于自注意力机制,这使得模型能够在处理序列数据时捕捉长距离依赖关系。此外,Transformer的层次结构和并行处理能力使其在处理大型数据集时更为高效。
- 手写Transformer模型不仅需要理解其复杂的架构和自注意力机制,还需要深入掌握如何有效地训练这样的大型模型。这个过程将极大地提升你在深度学习领域的理解和技能。
- 如果你懂了前三点,那你的 Transformer 的理解真是很到位了。
无论选择哪种模型,关键是通过实际操作来深入理解模型的工作原理。这包括了解模型的架构、学习如何处理和准备数据、了解训练过程以及如何调整参数以获得最佳性能。这种实践经验对于深入理解深度学习的原理和发展是非常宝贵的。
同时还有最重要的一点!如果你不看书,那还是对于这些是一个片面的认知,所以坚持 看书吧。李沐的《Dive into Deep Learning》、或者《understanding deep learning》从头看到尾就好了,但是不动手是真的不成啊。
#多项式激活函数替代方案出炉
不用Softmax好像也可以?
本文提出了Transformer模型中Softmax激活函数的替代方案,即多项式激活函数,并理论证明了这些激活函数能有效正则化注意力矩阵的Frobenius范数。实验结果表明,这些多项式激活函数在多种视觉和NLP任务中的表现与Softmax相当或更优,为Transformer的注意力机制提供了新的视角。
本文挑战了传统观念,即 Transformer 中的softmax注意力主要因为能生成注意力分配的概率分布而有效。相反,作者从理论上证明,其成功在于在训练过程中能隐式地正则化注意力矩阵的Frobenius范数。
然后作者探索了其他能正则化注意力矩阵的Frobenius范数的激活函数,证明了某些多项式激活函数可以实现这一效果,使其适合注意力基础架构。
实验结果显示,这些激活函数在各种计算机视觉和语言任务中的性能可与softmax相当或更好,表明除了softmax之外,注意力机制还有新的可能性。
1 Introduction
变形器架构已成为各种领域(如自然语言处理(NLP);计算机视觉;机器人学等领域的最先进模型架构。变形器架构的关键组件是softmax注意力模块,使得变形器在输出生成过程中评估单个输入元素的重要性。这一特性使得变形器在训练过程中能够有效地关注多样化的输入元素,从而有效地捕获序列数据中的空间依赖关系。与传统的循环神经网络(RNNs)和卷积神经网络(CNNs)不同,变形器能够在不显著降低性能的情况下扩展到大型数据集。这一特性使他们成为处理大规模机器学习任务的理想架构。
softmax 广泛认可其在注意力机制中的有效性,原因在于其能够生成满足三个关键条件的注意力矩阵:(i)非负性,(ii)行归一化后和为1,(iii)稀疏性。普遍认为,非负性保证了注意力权重保持正数,有助于模型为各种输入元素赋予重要性。归一化约束确保所有输入元素的注意力权重之和为1,使权重可解释为概率。
此外,稀疏性有助于模型关注少数几个关键元素,从而提高效率。有人认为,这些属性对于使注意力机制能够关注输入序列的相关部分,同时有效过滤无关细节至关重要。然而,这种关注方法已经变得有些教条,因为它主要受到经验结果的影响,而没有理论基础。尽管在几项研究中探索了其他激活方式,但 softmax 注意力仍然主导地位,主要原因在于其可解释性。
在本文中,作者通过提出软max的效力源于其在对训练时注意矩阵的Frobenius范数进行隐式正则化,从而防止注意权重变得过大或过小,来质疑这一观点。然后作者推导出一个理论框架,该框架产生的多项式激活故意违反之前提到的三个条件之一,但能够在对注意权重的Frobenius范数进行训练时进行正则化。作者的发现表明,这些激活可以实现与softmax相当或甚至优于softmax的各种视觉和自然语言处理(NLP)任务,尽管它们似乎与作者理解到的注意力相矛盾。
作者建议读者,本文并未遵循通常追求创建最先进的 Transformer 架构以在基准数据集上实现最先进结果的做法。相反,作者的重点是批判性地审视softmax注意力,以确定其有效性是否是真正的可解释性结果,还是一个更细微的正则化机制的结果。通过挑战既定的观点,作者旨在揭示 Transformer 架构的更深层次洞察,可能引领更广泛的应用和更好的理解。
然而,作者在多个基于 Transformer 的任务上验证了作者的理论,包括图像分类、分割、目标检测和自然语言处理,通常实现的结果与softmax注意力的结果相匹配或超过。作者的主要贡献是:
作者质疑软max在注意力机制中广泛接受的有效性仅源于其产生归一化稀疏注意力权重的能力这一观念。相反,作者从理论上证明软max对注意力具有规范化作用,并认为这在软max的成功中发挥了关键作用。
作者探索了故意偏离传统softmax注意力条件的激活。这些激活在训练过程中发现可以规范注意力矩阵的Frobenius范数,类似于softmax,并在各种视觉和NLP任务上表现出可比的或优越的性能。
2 Related Work
许多研究探讨了 Transformer 中注意机制的替代激活方法。沈等人(2023年)研究了ReLU激活,发现在具有长序列的任务(如文档翻译)中,它们超过了softmax。
班纳吉等人(2020年)研究了softmax的泰勒级数近似,显示了在图像分类中比softmax更好的性能。王等人(2021年)提出了softmax的周期性替代方法,旨在为注意力机制提供更好的梯度,并在图像分类的简单网络中取得了比softmax更好的结果。科胡帕伊和Pirsiavash(2024年)证明了将归一化应用于线性注意力机制可以实现与softmax相当的性能。
作者的工作与这些工作不同,因为作者识别出注意力矩阵的Frobenius范数规模与输入序列长度之间存在明确的理论关系。利用这一洞察,推导出可以与softmax媲美的潜在激活方法。
3 Preliminaries and Notation
在本节中,作者通过 Transformer 块定义了 Transformer ,并设定了未来各节中使用的各种数学量的表示法。关于 Transformer 的更多信息,读者可以参阅Vaswani等人(2017年)和Dosovitskiy等人(2020年)。
Transformer 架构由 Transformer 块组成,定义如下。Transformer 块是一个映射 ,其中 和 分别为输入和输出的维度。
是一个具有残差连接的前馈 MLP(多层感知机)和 是一个注意力头。注意力头 A 定义如下:它由三个可学习的矩阵组成,Query 、键 和值 由以下公式定义: 对于输入序列 ,其中 、, 。然后, 注意力头 被定义为:
在这篇论文中, 作者将关注自注意力机制, 即最常用的相似变换 (也称为点积): 。最常用的激活函数 是softmax。这导致了注意力头的最常见形式, 由

softmax函数是矩阵软max映射,按行应用常规的softmax函数:

《1/√d》这一因素,如Vaswani等人(2017年)所述,是为了防止softmax的梯度变得过小而引入的缩放因子。在本论文的理论分析中,作者将仅使用点积相似度qk^T,并将N×N矩阵softmax(qk^T)称为_softmax自注意力矩阵。在实验部分,第5节,作者将通过实证方式在更一般的softmax注意力块上验证作者的理论框架。
对于通用Transformer架构,使用1到n的多个头。每个注意力头由方程3.3定义,然后将每个注意力头的所有输出拼接在一起,然后进入前馈层。
作者需要符号表示矩阵softmax映射的导数,该映射由方程3.4定义。
对于矩阵 , 作者可以对矩阵映射softmax在 处求导, 得到梯度线性映射 , 该映射的公式为:

给定矩阵 ,作者用 表示其 Frobenius 范数。另外,作者用 表示随机变量的期望, 具体考虑的随机变量将在上下文中明确。
4 Theoretical Analysis
Implicit regularization of Softmax
本文段提出了一种理论结果,表明softmax激活以一种指数级的方式对自注意力矩阵的Frobenius范数施加控制,而这种控制与输入序列的 Token 长度呈亚线性增长。此外,作者还证明了softmax关于自注意力矩阵的梯度也具有类似的规律性。
尽管以前的工作通过Lipschitz常数的角度分析了softmax自注意力的一致性,但作者的定理通过直接将Frobenius范数规律性与 Token 长度联系起来,提供了一个新的视角。这为作者理解自注意力激活如何随着 Token 长度的变化而调整以保持训练过程中的稳定性,尤其是基于梯度下降的算法,提供了启示。
定理4.1: 设 softmax: 为由方程3.4定义的矩阵softmax映射, 且 表示 softmax 在 处的梯度。那么,作者有以下关于Frobenius范数的界

定理4.1的关键推论是,在具有softmax自注意力机制的 Transformer 训练过程中,每个softmax自注意力矩阵的Frobenius范数始终保持在一个随着增长的价值范围内。这确保了通过自注意力矩阵权重反向传播不会导致过大的梯度。证明的关键在于,softmax内嵌的行归一化有效控制了Frobenius范数。详见附录A.1.1的详细证明。
Polynomial activations for self-attention
在第4.1节中,作者证明了softmax隐式地正则化了自注意力矩阵的Frobenius范数。在此基础上,作者现在证明,通过缩放特定多项式激活,可以在期望值上实现对Frobenius范数的类似正则化效果,这几乎完全复制了softmax的影响。
定理4.2: 设 为独立同分布的随机变量, 分别按照 和 分布。对于 , 作者计算 矩阵 的 Frobenius 范数的期望。

通过将这种激活函数乘以,作者可以得到一个的界。
4.3推论:设4.2定理中的条件相同。

推论4.3证明了, 形式为 的激活函数在期望上提供了一种类似于softmax在自注意力矩阵上的正则化水平。推论4.2的证明可以在附录A.1.2中找到。作者接下来要证明的下一个性质与4.1中得到的梯度界类似。由于自注意力矩阵的参数由 Query 和键 (Vaswani等人, 2017)给出, 这意味着在 Transformer 训练过程中, 只有 和 矩阵是自注意力矩阵得到更新的部分。因此, 作者计算关于 和 导数的正则化结果。
定理4.4: 设 均为独立同分布随机变量, 分布分别为 , 。则当 时, 矩阵 的 参数矩阵的期望为 。

上述定理 then 表明, 如果作者以 的比例将多项式 进行缩放, 那么 导数的增长将呈现 的形式。
4.5 推论:设与定理4.4相同的条件。

类似的估计也适用于关于K矩阵的导数。4.4定理的证明可参见附录A.1.2。
4.3和4.5的推论表明, 具有形式 (其中 )的多项式激活在应用于自注意力矩阵时, 可以达到与softmax相当的表现。
在5节中, 作者通过实证比较这些激活与softmax, 观察到它们在各种transformer任务上都优于 softmax。作者专注于 和 , 因为这些多项式显然违反了 softmax基于注意力的一些关键方面, 例如归一化行、正性和稀疏性。对于较大的 值, 性能下降是由于当 较大时, 的函数在 0 附近的梯度较小, 这导致训练困难。
5 Experiments
在本节中, 作者在各种 Transformer 任务上验证第4节中的理论。作者对第4节中提到的两个主要激活进行实证验证, 即立方多项式激活 和线性多项式 。
目标是证明, 通过适当缩放这些激活, 利用第 4 节中的理论, 作者可以实现与softmax相比具有竞争力的性能。在本节剩余部分,作者将简单地用 和 表示这些激活。
Image classification
5.1.1 ViT-Tiny on Tiny-Imagenet:
在本节中,作者测试了在Tiny-Imagenet数据集(Le和Yang,2015)上从零开始训练的ViT-Tiny架构(Steiner等人,2021)的理论(Steiner等人,2021)。
作者的第一个实验是为了测试在输入序列长度和4.3和4.5节中预测的缩放因子都使用激活函数x^3时,Top-1%的准确率如何变化。根据第4节发展的理论,当作者将X^3按1/√N进行缩放时,Frobenius范数按O(√N)进行缩放。因此,随着序列长度的减小,作者应看到对数尺度上的缩放量减少。
图1展示了该实验的结果。作者考虑了四种不同的输入序列长度,大小分别为256、64、16和8。作者运行了多种ViT-Tiny架构,这些架构的缩放形式为,其中N的范围在序列长度以下到以上。从图1可以看出,随着序列长度变小,在x轴上以对数表示的所需的缩放量减小,这验证了第4.2节中的理论。

第二项实验比较了激活函数 和 , 以及缩放版本 和 与Tiny-ViT架构在Tiny-Imagenet上的softmax。由于序列长度为 ,作者决定将 作为多项式激活函数的缩放比例。实验使用了 4 个patch大小的特征图, 3 个attention头和 12 层,如Steiner等人(2021年) 所述。表1中的结果表明, 超过了 softmax, 而未缩放版本表现较差。同样, 未缩放版本的 在竞争中表现良好,且未进行缩放时性能显著下降。
图2显示了在ViT-Tiny的层2和12中, 对五个激活进行自注意力矩阵的Frobenius范数训练时的结果, 所有 Head 的平均值。 和 的范数高于softmax, 但通过将它们乘以 进行缩放, 可以将它们降低到更稳定的水平, 从而提高训练稳定性。图3显示了Jacobian的Frobenius范数, 缩放同样使范数更接近softmax, 以确保更稳定的梯度。附录A.2.2中包含其他层的进一步图表。


表格1:在Tiny-Imagenet上,软max和多项式激活方法在Top-1%精度上的对比。当应用正确的缩放比例时,立方激活方法优于软max。同样,线性激活方法只有在最优缩放时才具有竞争力。
5.1.2 Larger vision transformers on ImageNet-1k
在本次实验中,作者使用来自ImageNet-1k数据集的各种不同视觉 Transformer 进行了图像分类任务。作者发现,比例为1/14对于x^3和x都取得了最佳效果。
作者从头训练所有模型在ImageNet-1k数据集上,并在验证集上报告Top-1精度。作者使用PyTorch Paszke等人 和Timm Wightman(2019年)库来训练作者的模型,设置与He等人 和Liu等人(2021年)相似。作者检查了作者的方法与以下三种Transformer架构一起,以展示其泛化能力:
ViT:Dosovitskiy等人(2020年)的开创性工作将图像解释为一系列 Patch ,并通过NLP中使用的标准Transformer编码器对其进行处理。这种简单但可扩展的策略,在与大型数据集的预训练相结合时,表现出惊人的效果。作者使用ViT-Small,具有以下设置:Patch 大小=16,嵌入维度=384,头数=6,层数=12。此外,作者还使用ViT-Base,具有以下设置:Patch 大小=16,嵌入维度=768,头数=12,层数=12。
DeiT: Touvron等人(2021年)提出了一种基于ViT的 Transformer 模型。除了作者没有使用DeiT中强制的蒸馏 Token 外,它与ViT非常相似。作者使用的是DeiT-Small,它具有以下设置:patch size = 16,嵌入维度 = 384,head数量 = 6,层数 = 12。此外,作者还使用了DeiT-Base,它具有以下设置:patch size = 16,嵌入维度 = 768,head数量 = 12,层数 = 12。
Swin Transformer: 刘等(2021年)提出了一个层次化的特征表示,并提出了基于位移窗口的自注意力机制,该机制在视觉问题上被证明是有效和高效的。作者在第一阶段的隐藏层中使用Swin-Small(96通道)和Swin-Base(128通道)。默认为设置窗口大小M=7,每个 Head 的 Query 维度d=32,所有实验的层数为2,2,18,2。
XciT:Xiong等人(2021年)提出的视觉 Transformer 架构与标准ViT不同,它包含两个不同的组件。首先,在每个块中具有局部patch交互,包括一个深度可分离的3x3卷积后接 BatchNorm 、GELU,以及另一个深度可分离的3x3卷积。其次,它使用交叉协方差注意力,其中注意力图是从计算在 Token 和 Query 投影的token特征上的关键和 Query 协方差矩阵得到的。作者使用了XCiT-S12,其patch大小为16,以及XCiT-M24,其patch大小为24。
表格 2 中的结果如下。激活函数 在 ViT 和 Swin Transformer 上表现最好, 而 softmax 在 DeIT 架构上表现最好。在附录 A.2.1 中,可以找到不同尺度和激活函数的进一步消融实验结果。
图4展示了ViT-Small架构中, 训练时层2和层12中每个头中自注意力矩阵的Frobenius范数。通过将激活值 和 乘以 ,作者可以控制自注意力矩阵的Frobenius范数的规模,并得到与 softmax的规模相当的规模。同样, 图5展示了层2和层12中自注意力矩阵的Jacobian范数在训练时的Frobenius范数, 平均值在所有头中。通过将激活值 和 乘以 , 作者可以控制 Jacobian范数的规模, 并在训练时得到与softmax的规模相当的规模。该架构其他层在训练时的 Frobenius范数图在附录A.2.2中给出。


5.1.3 Visualizing self-attention with ViT-Base
作者绘制了在收敛后使用 和softmax 激活的Self-Attention矩阵的热力图, 覆盖了两个层和 8 个头。在固定大小为 128 的训练批次的平均下, 图 6 显示了层 2 , 头 8 , 突出了注意力模式的不同, 其中 包含正负值。同样, 图7的层12, 头6展示了每个激活的显著模式。总体而言, ViT-Base架构在 下表现出与softmax 显著不同的Self-Attention模式。


作者观察了自注意力矩阵如何针对图像的不同区域进行定位。作者使用了ImageNet-1k验证集的一张图像,提取了类 Token ,将其 Reshape 为(14,14)的网格,代表196个 Patch ,然后使用最近邻插值将其映射回原始图像大小。图8显示了输入图像,而图9说明了ViT-Base架构在收敛后,第12层, Head 6的自注意力矩阵对于不同激活值的关注区域。

Object Detection and Instance Segmentation
在本节中, 为了检验作者模型的迁移学习能力, 作者通过在目标检测和分割任务上微调作者的 ImageNet预训练XCiT模型来展示作者的方法。作者的实验在COCO 2017数据集(Lin等人, 2014年)上进行,该数据集有 118 K训练图像和 验证图像,包含 80 个类别。作者将XCiT架构作为Mask R-CNN(He等人,2017年)检测器的 Backbone,并与特征金字塔网络(FPN)相结合。由于XCiT固有的列状设计, 作者通过从各种层提取特征来适应FPN的兼容性, 这些特征具有一致的步长为 16 。然后, 作者将特征分辨率调整为 的步长。这种下采样通过最大池化实现, 而通过单层反向卷积实现上采样。模型使用AdamW优化器训练 36 个周期, 学习率为 , 权重衰减率为 0.05 , 批大小为 16 。在表 3 中, 作者在具有激活 和 softmax的XCiT-S12模型上进行了实验。作者发现在这个任务上, 作者无法很好地训练激活 和 , 因此只报告其他激活。

Natural language processing(NLP)
为了评估作者的方法在NLP任务上的有效性, 作者在Long Range Arena(LRA)套件中的五个基准测试(Tay等人, 2020年)上训练了模型:ListOps, 文本分类, 检索, 图像分类和 Pathfinder。作者将激活 和 与softmax进行比较, 发现 和 在自己的训练上效果不佳, 因此只呈现这些缩放激活和softmax的结果。作者的实现遵循了Xiong等人(2021年)的指南。结果汇总于表4。

6 Limitations
尽管作者的工作引入了具有挑战性的新激活,这些激活对传统的softmax方法提出了质疑,但仍需解决一些限制。作者的理论框架主要是为点积自注意力设计的,可能无法立即扩展到其他注意力机制,尽管作者的实证结果表明,在不同的架构中,作者的激活相对于softmax具有竞争力的性能。此外,作者观察到,尽管作者的激活在视觉任务上表现良好,但在NLP任务上的表现不够稳定,这表明可能需要一种更精细的理论方法来处理这些应用。
7 Conclusion
这项工作挑战了传统观点,即自注意力机制中的 Transformer 激活必须产生稀疏概率分布。
作者引入了一个理论框架,分析自注意力矩阵的Frobenius范数,该框架揭示了注意力机制中激活的关键缩放性质。
作者证明了特定多项式激活,其行为与softmax大不相同,满足这些性质。
通过在视觉和NLP任务上的广泛实验,作者证明了这些替代激活不仅与softmax竞争,而且有时可以超过softmax,为 Transformer 中的注意力机制提供了全新的视角。
#AI现场发了2万红包
打开了大模型Act时代
我们需要的是「真正解放双手的智能体」。
最近一段时间,大模型领域正在经历智能体(AI Agent)引发的革命。Anthropic 推出的升级版 Claude 3.5 Sonnet,一经推出即引爆了 AI 圈。
作为新一代 AI 智能体,它跨过了大模型的次元壁,能够像人一样直接操纵电子设备,根据你给出的自然语音指令移动光标、点击相应位置以及通过虚拟键盘输入信息,模仿人类与计算机的交互方式。大家都在自发探索智能体的使用方法,比如有人已经在用智能体自动代肝崩铁每日任务了。
除了打游戏,在工作环境中智能体还可以接管很多日常事务,比如撰写邮件、安排会议、整理文件等等,据说从科研到写代码样样都行。
有人表示,智能体工具的出现标志着全新人机交互范式踏出了新的一步。
没过多久,国内公司就拿出了对标的产品,而且还更进一步,一次性实现了手机、PC、AI 原生硬件的覆盖。
今天上午,智谱 Agent 宣布升级,开放「百万内测」申请,翻开了人机交互体验的新一页。
这是智谱第一个产品化的智能体 Agent,可以做到让 AI 通过语音直接操纵硬件设备,还能跨不同 App 全局操作。
在发布会现场,智谱 CEO 张鹏展示了一番智能体的能力。让 Agent 与现场观众建面对面群聊。
发一个总计两万块钱的红包。
AI 发的红包瞬间就抢空了。不得不说谢谢张总,谢谢 AI Agent。
深入手机、PC,能自己做主
智谱智能体的手机版 AutoGLM 与电脑版 GLM-PC,内测阶段覆盖部分常用的 App 及应用。AutoGLM 支持包括微信、抖音、小红书、微博等社交平台、美团、饿了么、等美食平台、淘宝、京东、拼多多等购物平台、高德和百度地图等出行平台、以及 12306、去哪儿、携程等旅游订票平台。
用户打开 AutoGLM 后,只需要动动嘴(当然也支持文字输入),就能让智能体接管自己的手机,并在上面这些 App 上自动执行任何指令任务,比如在微信上对某个公众号的文章进行摘要总结、在高德地图上为你规划出行路线,等等。
此次,智谱给 AutoGLM 进行了一系列能力升级。基于这些新能力,我们看到了一些新玩法。
一是「更长」,即 AutoGLM 可以理解、遵循并自主完成超长、复杂的指令,支持超过 50 步的无打断连贯操作。在长任务上执行的速度比人类实操还要快。
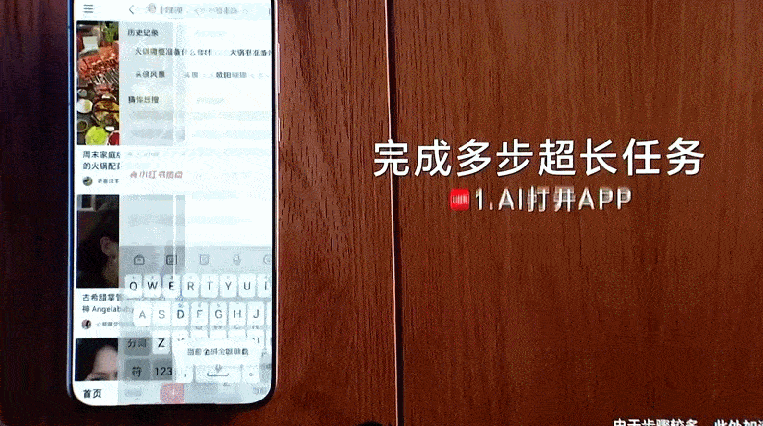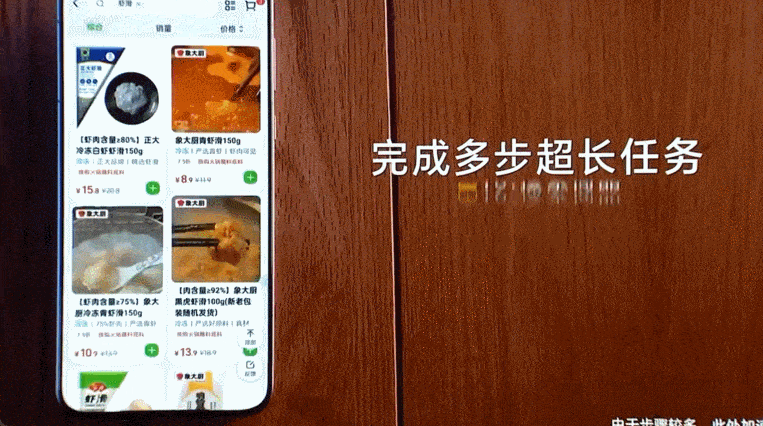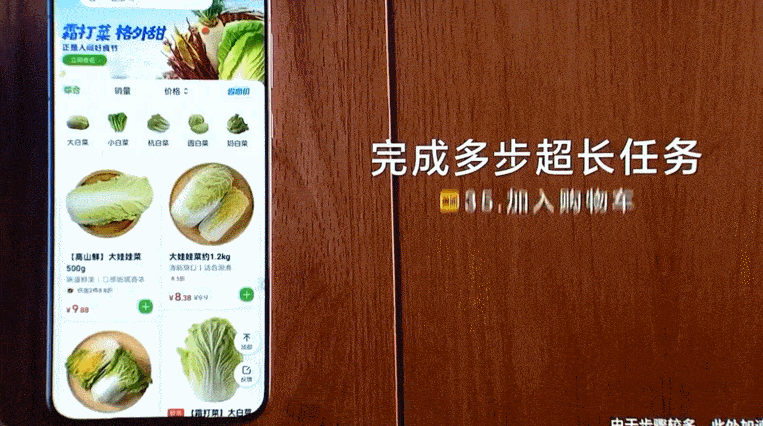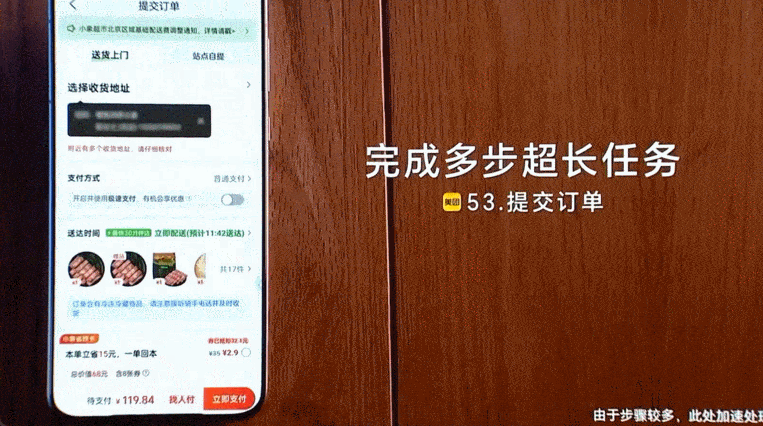
二是「跨 App」,即 AutoGLM 在更强大泛化能力和思维链的加持下,支持复杂任务的跨 App 操作。有了这个智能体,用户与应用之间多了一个可以自动执行的调度层,省去了在不同 App 之间来回切换的麻烦,实现了这些 App 之间的协同操作。
我们以不同 App 之间的信息分享为例,命令 AutoGLM「在小红书上种草几款单反相机,然后分享到微信的『编辑部之插科打诨』群」,操作很丝滑。
再比如跨不同 App 购物,AutoGLM 也能一气呵成。
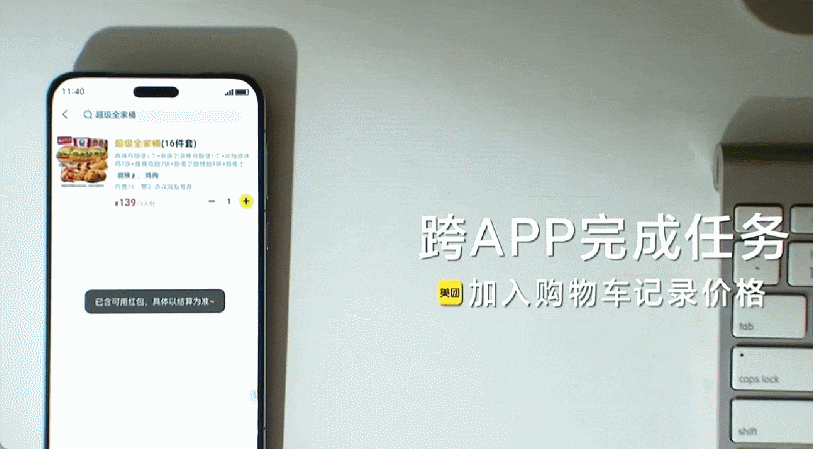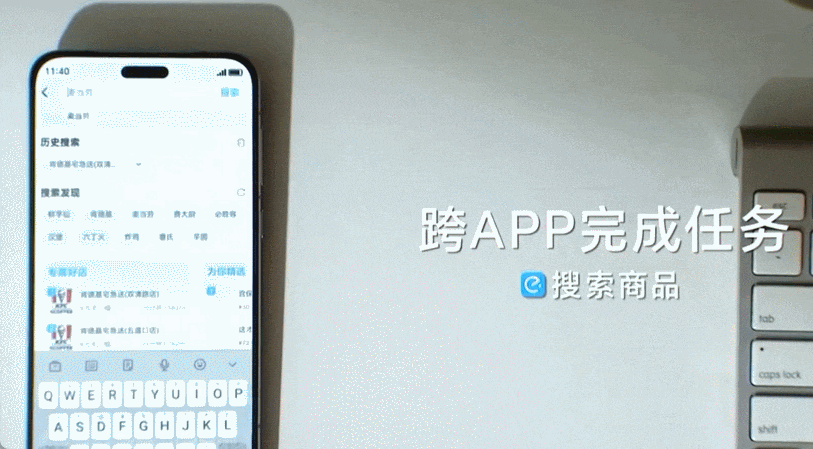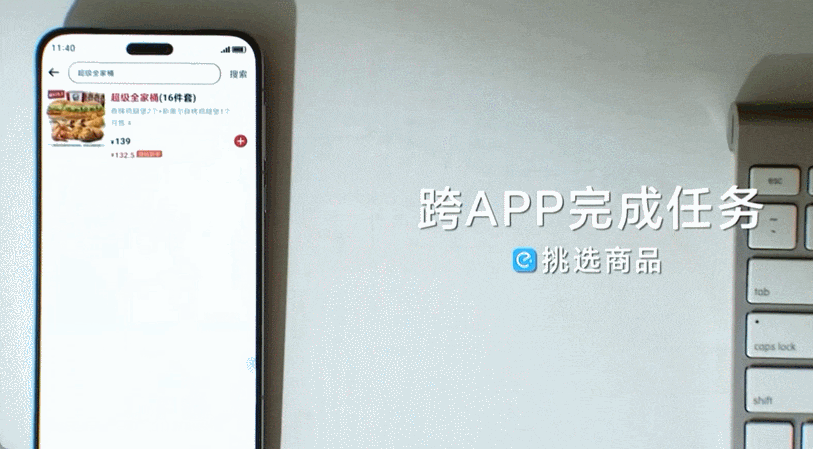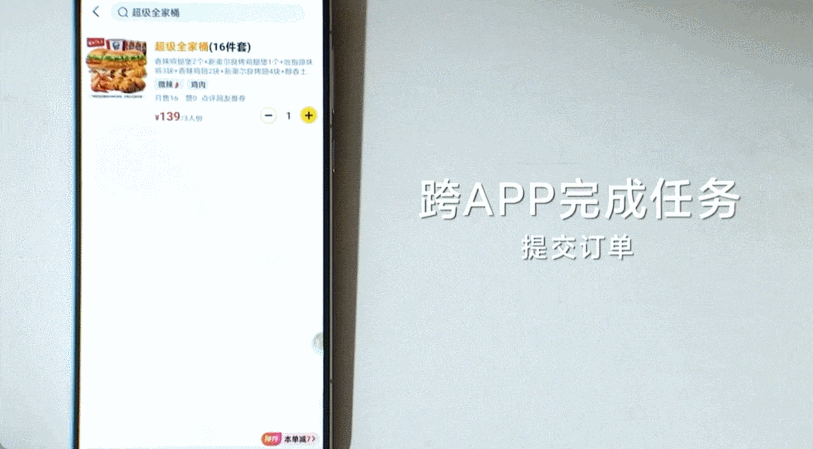
更多新玩法进一步拓展了 AutoGLM 的功能,包括「短口令」,类似于手机上的快捷指令。在这种模式下,AutoGLM 可以一键存储用户自定义的快捷短口令,在触发该指令后自动发起并执行关联长任务。
更有意思的还有「开盲盒」,AutoGLM 会默认跳过对话步骤,对于用户发出的模糊指令,让 AI 主动帮你完成选择。过程中只有在涉及重要操作(比如支付)时才会进行二次确认。

AutoGLM 的自主执行能力还扩展到了网页端。智谱在浏览器(Google Chrome 和 Microsoft Edge)的智谱清言插件上提供了 AutoGLM-Web 功能。该功能适配了知乎、微博、X 和豆瓣等社媒网站,百度、谷歌和必应等搜索引擎,百度学术、谷歌学术和 arXiv 等学术网站,以及 GitHub 代码托管网站和资讯类网站。
在这些网站上,智能体遵循用户指令,可以自动执行站内搜索、内容总结、生成 arXiv 日报、搭建 GitHub 仓库、在微博超话签到等个性化功能,可玩性不错。如下所示,我们可以让它自动帮我们在微博分享新鲜事。
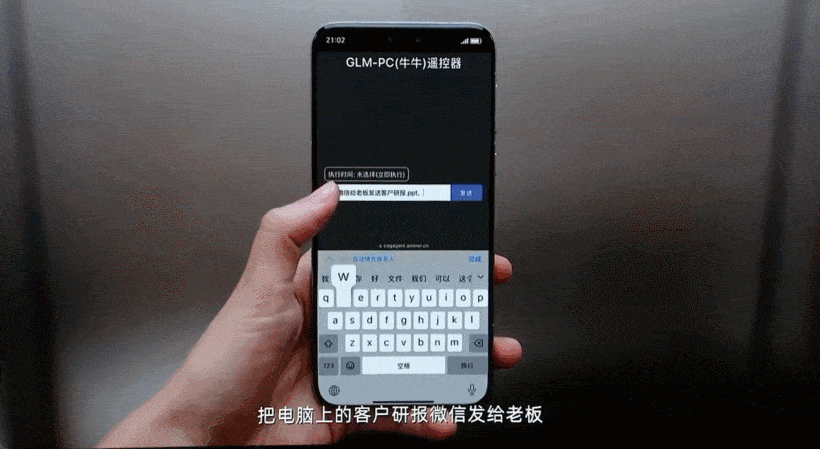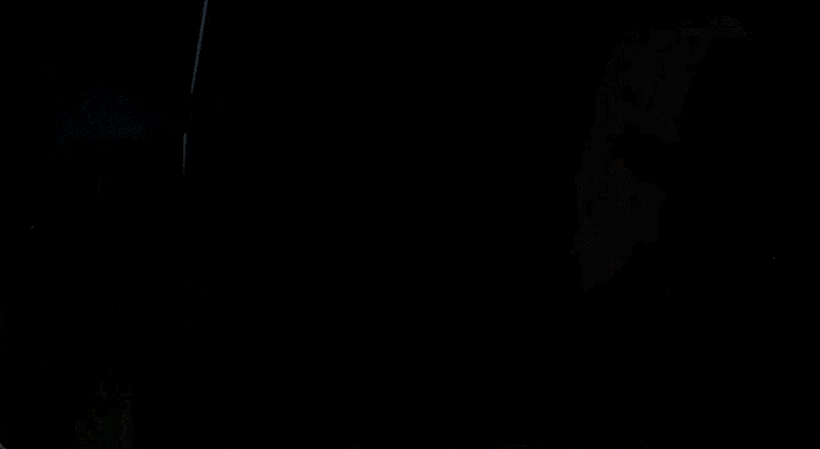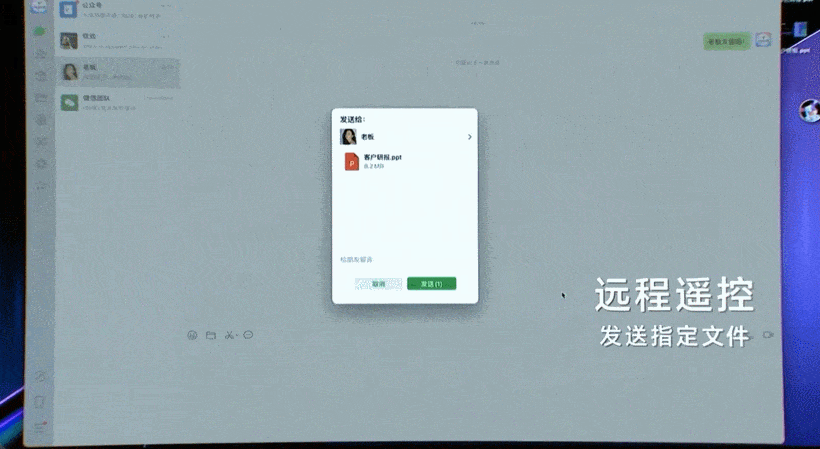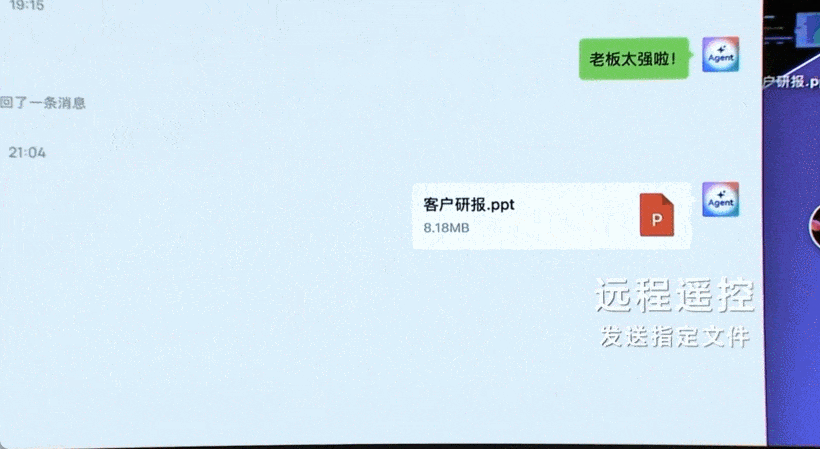
在桌面端,智谱同样推出了像人一样操作计算机软件的应用 GLM-PC,它基于通用视觉大模型 CogAgent 的理解与任务规划能力,让用户通过简单的一句话指令执行复杂任务。

比如查询并总结网页上的信息,并通过微信发送给别人:
在淘宝上买 XL 码的羽绒服并购买:
即将上线的隐形屏幕功能更加科幻。AI 可以在不打扰你的情况下提供帮助,解放屏幕使用权给人,自己在另外一个隐形屏幕上完成工作。
从实现原理来讲,GLM-PC 在充分理解用户指令后对任务进行规划,然后识别电脑界面中的窗口、图形、文字等信息,然后自动操作电脑。另外,这个 AI 助手在使用过程中可以根据页面信息更改计划并自我纠错,从而更好地完成任务。
据介绍,GLM-PC 尤为擅长处理办公场景,可以在微信、飞书、钉钉、腾讯会议等平台执行多样性任务,比如发送信息、预定和参与会议。同时支持浏览器网页搜索以及网页内容的阅读总结、翻译,还能进行多种文档处理,包括下载、发送和总结。
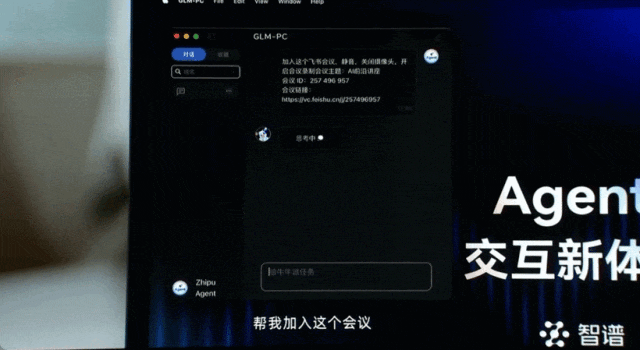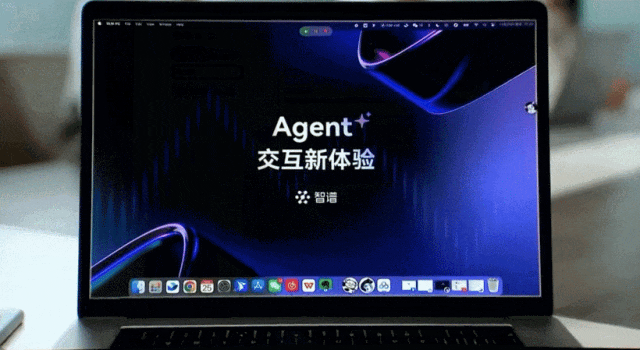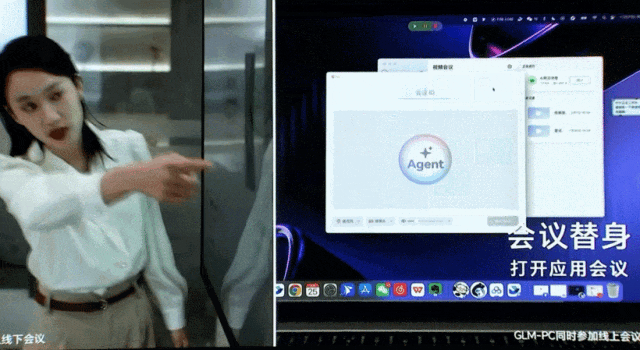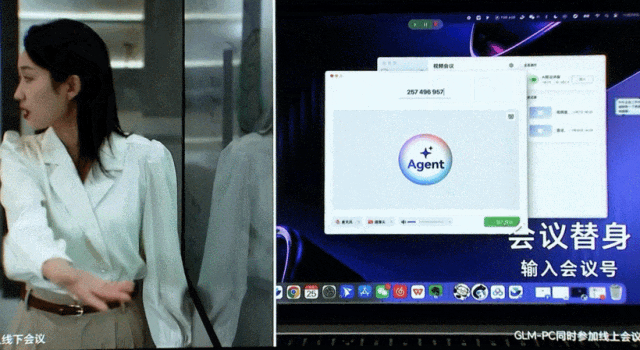
打开并加入飞书会议。
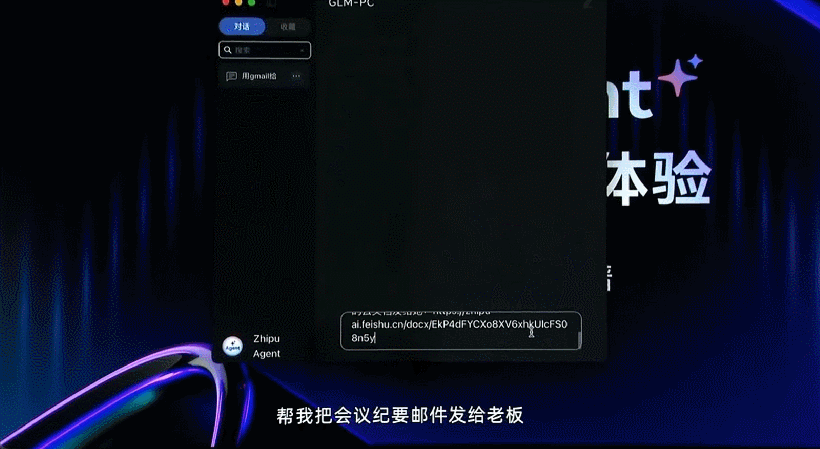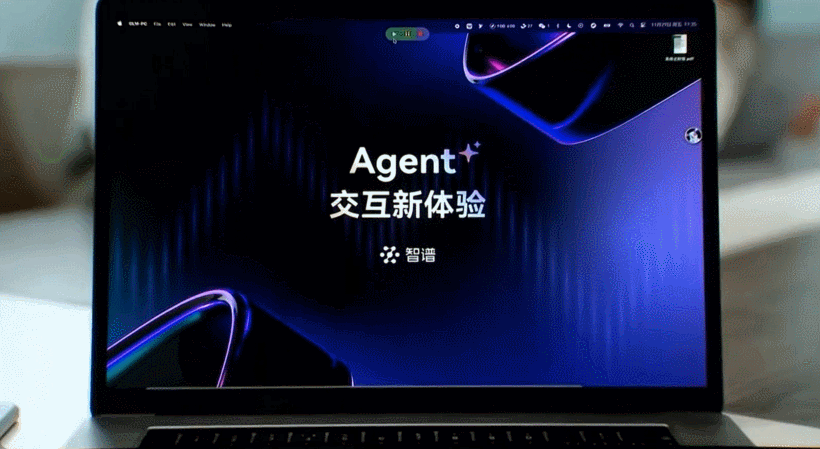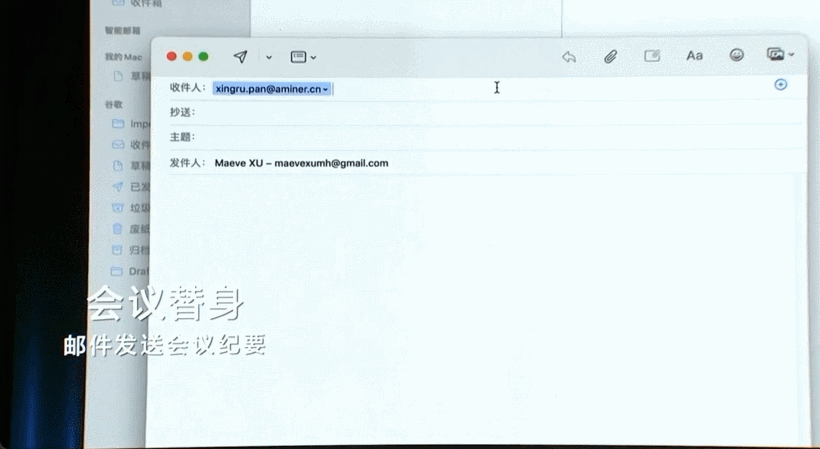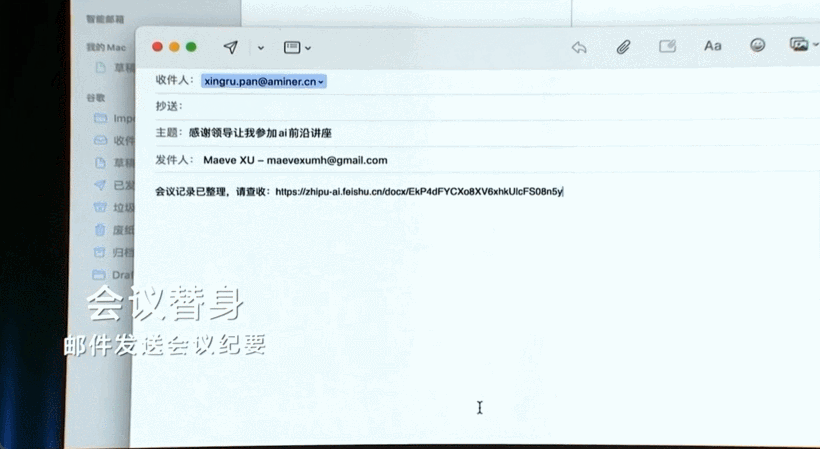
邮件发送会议纪要。
不仅如此,智谱还实现了 GLM-PC 与手机端的联动。用户现在可以在手机上远程向 GLM-PC 发消息,让它自动进行电脑端操作。
最后,智谱在发布会现场表示,要对十个亿级 App 进行免费 Auto 升级。荣耀、华硕、小鹏汽车等大厂,高通、英特尔等硬件、芯片厂商也纷纷站台,介绍了与智谱的合作。
随着端到端、多模态、视频等新能力的大模型出现,大模型已经初步具备了和物理世界互动的能力。
我们能够逐渐想象出山姆·奥特曼口中「前所未有的自然交互」的样子,但眼前能够接触到的很多落地产品,却似乎总是差点意思。这可能是因为想要构建颠覆性的产品,需要的不止是大模型能力,还有对于技术方向的提前预判,以及完整系统的优化。
其实在发展大模型基础技术之外,智谱最近还一直在推进另一件事:构建体系。

我们能够逐渐想象出山姆・奥特曼口中「前所未有的自然交互」的样子,但眼前能够接触到的很多落地产品,却似乎总是差点意思。这可能是因为想要构建颠覆性的产品,需要的不止是大模型能力,还有对于技术方向的提前预判,以及完整系统的优化。
智谱在大模型 Agent 方向上的研究由来已久。自 2023 年 4 月,智谱就陆续提出了 AgentTuning、AgentBench、CogAgent 等大模型智能体工作,今年智谱又连续发布了AutoWebGLM、AutoGLM 等成果。智谱针对 AutoGLM、GLM-PC 的研发工作也经历了一年半以上的时间。
在探索大模型智能体能力边界的过程中,智谱逐渐获得了两个重要的观察。首先,智能体和推理本质上服从着同大模型训练类似的 Scaling Law。智能体通过和环境交互,模型获得来自环境的反馈监督信号,具有类似的规模扩展效应。这说明,通过扩展计算规模,我们可以持续地提升大模型智能体的表现水平。在新的 Scaling Law 背后,智谱设计了 WebRL,一个自进化在线课程强化学习算法框架。通过引入大模型特有的自进化演化策略,并利用课程学习实现智能体由易到难进行泛化,并最终借助在线 off-policy 强化学习,AutoGLM 实现了在在线环境中的智能体扩展规律。其次,智谱进一步的探索发现了 Agent 存在 Emergent Ability,即能力涌现。10 月发布之初,AutoGLM 尚只能在单个应用、短距离任务上展现能力。然而,随着工程师们进一步训练和规模的扩展,最新版本的 AutoGLM 已初步具备跨应用、长距离任务的胜任水平,甚至能够能遵从复杂指令在从未见过的 App 应用中操作。
其实在发展大模型基础技术之外,智谱最近还一直在推进另一件事:构建体系。

由于多模态大模型的出现,现在的 AI 已经具备了语义理解、屏幕内容解析和行为语义理解等能力。接下来要做的似乎就是找到一种机制,让大模型能够一步一步地解题。
智能体(AI Agent)就是用来执行这样复杂的任务的。它既具有自主性,又能进行环境交互,可以分解复杂任务进行规划,使用专业的模型或外部工具来提升自身能力,还拥有远超大模型本身的记忆能力。
这意味着加入智能体之后,手机这样的设备可以利用相对轻量级的模型,承载起更加复杂的自动化任务。
此前在业内,一些科技大厂、创业公司和手机厂商已在 PC、AI 手机上构建了智能体能力,并获得了不错的效果。但从技术发展的角度来看,这往往是各自产品路线的延伸。智谱提供的解决方案在此基础上还会覆盖汽车、智能眼镜、智能音箱,甚至具身智能的机器人等 AI 原生硬件,体现出了另一种思路。
智谱认为,将来不同的硬件设备都可能由统一体系的 AI 智能体来操作,这样才能实现人机交互的提升。为此,他们也在芯片、应用 App、操作系统 OS 和模型侧进行了提前布局。
包括与芯片、终端厂商持续合作,从硬件底层进行优化,持续优化端侧大模型的能力。在 10 月高通骁龙 8 至尊版发布时,智谱就宣布已联合高通对最新一代端侧视觉大模型 GLM-4V 进行了深度适配和推理优化。在端侧部署后,今年的新一代旗舰手机已经可以支持丰富的多模态交互方式,让人们获得更加情境化、个性化的终端侧智能体验。
智谱也和众多手机、电脑厂商合作,在 AI PC、手机端智能助手领域给大模型进行落地。率先亮出 AI 智能体操作手机的荣耀,就在九月份与智谱达成了 AI 大模型技术的战略合作。
本周,智谱还与英特尔、机械革命联合发布了专为程序员设计的 CODE AI 程序员笔记本,预装了基于端侧的智能编程助手。
通过端侧芯片性能优化和端云一体架构,智谱的大模型智能体技术,不久后将出现在越来越多的设备上。
Agent 的尽头是什么?
尽管目前的技术还在初期,但 AI 智能体已经展现出了前景。
再往更深的层次想,过去键盘鼠标、触控屏幕这样物理交互的形式,从 DOS、Windows 再到 iOS、安卓等操作系统,都是为了让人更好地与机器沟通。
大模型正在走一条相反的路,让我们无需花费大量时间去理解各种应用的复杂界面,减少机械的劳动,反过来让机器适应人类。
智谱 CEO 张鹏在发布会上表示:「目前的 Agent 能力更像是在用户和应用、设备之间增加一个智能的调度层。可以看做是大模型通用操作系统 LLM-OS 的一种雏形。这已经对人机交互形式产生极大的影响。更重要的是,我们看到了一种大模型操作系统 LLM-OS 的可能,基于大模型智能能力,有机会实现原生的人机交互。」
#Deep Reinforcement Learning Without Experience Replay, Target Networks, or Batch Updates
流式深度学习终于奏效了!强化学习之父Richard Sutton力荐
自然智能(Natural intelligence)过程就像一条连续的流,可以实时地感知、行动和学习。流式学习是 Q 学习和 TD 等经典强化学习 (RL) 算法的运作方式,它通过使用最新样本而不存储样本来模仿自然学习。这种方法也非常适合资源受限、通信受限和隐私敏感的应用程序。
然而,在深度强化学习中,学习器(learners )几乎总是使用批量更新和重放缓冲区,这种方式使得它们在计算上很昂贵,并且与流式学习不兼容。
研究认为批量深度强化学习之所以普遍,是因为它的样本效率高。流式深度强化学习存在样本效率问题,经常出现不稳定和学习失败的情况。这一现象称为流式障碍。
就像下图展示的,流式强化学习需要从即时单个样本进行更新,而无需存储过去的样本,而批量强化学习则依赖于存储在重放缓冲区中的过去样本的批量更新。

为了解决流式障碍,本文来自阿尔伯塔大学等机构的研究者提出了 stream-x 算法,这是第一类深度强化学习算法,用于克服预测和控制流式障碍,并匹配批量强化学习的样本效率。
论文地址:https://openreview.net/pdf?id=yqQJGTDGXN
项目地址:https://github.com/mohmdelsayed/streaming-drl
论文标题:Deep Reinforcement Learning Without Experience Replay, Target Networks, or Batch Updates
论文作者还提供了 stream-x 算法的最小实现(大约 150 行代码),感兴趣的读者可以参考原项目。
本文证明了 stream-x 算法能够克服流式障碍。
在电力消耗预测任务、MuJoCo Gym、DM Control Suite、MinAtar 和 Atari 2600 上的结果证明,该方法能够作为现成的解决方案,克服流式障碍,提供以前无法通过流式方法实现的结果,甚至超越批量 RL 的性能。特别是,stream AC 算法在一些复杂的环境中达到了已知的最佳性能。
如下所示,经典的流方法(例如 Classic Q )和批处理 RL 方法的流式版本(例如 PPO1)由于流式障碍而表现不佳。相比之下, stream-x 算法(例如 stream Q )克服了流式障碍,并与批处理 RL 算法竞争,证明了其稳定性和鲁棒性。

这项研究得到了强化学习之父 Richard Sutton 的转发和评论:
「最初的强化学习(RL)算法受自然学习的启发,是在线且增量式的 —— 也就是说,它们是以流的方式进行学习的,每当新的经验增量发生时就学习,然后将其丢弃,永不再次处理。
流式算法简单而优雅,但在深度学习中,RL 的首次重大成功并非来自流式算法。相反,像 DQN(深度 Q 网络)这样的方法将经验流切割成单独的转换(transitions),然后以任意批次进行存储和采样。随后的一系列工作遵循、扩展并完善了这种批量方法,发展出异步和离线强化学习,而流式方法却停滞不前,无法在流行的深度学习领域中取得良好效果。
直到现在,阿尔伯塔大学的研究人员已经证明,在 Atari 和 Mujoco 任务上,流式强化学习(Streaming RL) 算法可以与 DQN 一样有效。
在我看来,他们似乎是第一批熟悉流式强化学习算法的研究人员,认真地解决深度强化学习问题,而不受批量导向的软件和批量导向的监督学习思维方式的过度影响。」

还有网友表示,流式算法确实塑造了强化学习的格局。

方法介绍
本文通过引入流式深度强化学习方法 ——Stream TD (λ)、Stream Q (λ) 和 Stream AC (λ),这些统称为 stream-x 算法,并利用资格迹,来解决流式障碍问题。
该方法无需使用重放缓冲区、批量更新或目标网络,即可从最新的经验中进行学习。与普遍认知相反,本文证明了流式深度强化学习可以是稳定的,并且在样本效率上可与批量强化学习相当。
由于流式学习方法在使用样本后必须将其丢弃,因此可能会导致样本效率低下。为此,本文提出了两种技术来提高流式学习方法的样本效率:1)稀疏初始化,2)资格迹。
算法 1 展示了本文提出的稀疏初始化技术 — SparseInit。此稀疏初始化方案可用于全连接层和卷积层。

算法 3 展示了如何构建一个优化器,该优化器使用有效步长这一条件来控制更新大小。

下面为 stream-x 算法伪代码。为了提高算法可读性,作者使用了以下颜色编码:紫色表示层归一化,蓝色表示观测规一化,橙色表示奖励缩放,青色表示步长缩放,棕色表示稀疏初始化。



实验结果
为了演示 Stream-x 算法的有效性,该研究首先展示了在不同环境中经典方法失败的流式障碍,而 Stream-x 算法克服了这一障碍,并且与其他批处理方法性能相当。
克服流式障碍
流式深度强化学习方法经常会遇到不稳定和学习失败的情况,称为流式障碍。图 2 显示了三个不同的具有挑战性的基准测试任务中的流障碍:MuJoCo、DM Control 和 Atari。

Stream-x 算法的样本效率
该研究通过比较不同算法的学习曲线来研究 stream-x 方法的样本效率。图 3 显示了不同深度 RL 方法在四个连续控制 MuJoCo 任务上的性能。

图 4 展示了流 Q (0.8) 与其对应经典方法以及 DQN1 和 DQN 在 MinAtar 任务上的性能。

Stream-x 算法在扩展运行中的稳定性
接下来,研究团队探究了 Stream-x 算法在长时间运行时的稳定性,以有效地揭示方法是否可以长时间运行而不出现任何问题。实验结果如下图 5 所示:

图 6 显示了不同智能体在总共经历 2 亿帧的 Atari 游戏上的性能:

感兴趣的读者可以阅读论文原文,了解更多研究内容。
#Llama 4在测试集上训练
内部员工、官方下场澄清,LeCun转发
大家翘首以盼的 Llama 4,用起来为什么那么拉跨?
Llama 4 这么大的节奏,Meta 终于绷不住了。
本周二凌晨,Meta Gen AI 团队负责人发表了一份澄清说明(针对外界质疑「在测试集上训练」等问题),大佬 Yann LeCun 也进行了转发。

很高兴能让大家用上 Llama 4,我们已经听说人们使用这些模型取得了很多出色的成果。尽管如此,我们也听到一些关于不同服务质量参差不齐的报告。由于我们在模型准备就绪后就推出了它们,因此我们预计所有公开部署都需要几天时间才能完成。我们将继续努力修复错误并吸引合作伙伴。
我们还听说有人声称 Llama 4 在测试集上进行训练,这根本不是事实,我们永远不会这样做。我们愿意理解为:人们看到的不稳定是由于需要稳定部署。相信 Llama 4 模型是一项重大进步,期待与社区的持续合作以释放它们的价值。
当前 Llama 4 性能不佳是被部署策略给拖累了吗?
权威的大模型基准平台 LMArena 也站出来发布了一些 Llama 4 的对话结果,希望部分解答人们的疑惑。

链接:https://huggingface.co/spaces/lmarena-ai/Llama-4-Maverick-03-26-Experimental_battles
可以看到,其中很多同问题的回答上,不论是跟哪家大模型比,Llama 4 的效果都是更好的。
但这究竟是模型真的好,还是 Meta 为了拯救口碑而进行的一系列公关活动?我们需要一起来梳理一下这一事件的发展脉络。
Llama 4:买家秀 vs. 卖家秀
Llama 4 是 Meta 在 4 月 6 日发布的模型,分为 Llama 4 Scout、Llama 4 Maverick 和 Llama 4 Behemoth 这几个版本。Meta 官方宣称新模型可以实现无与伦比的高智商和效率。

在大模型竞技场(Arena),Llama 4 Maverick 的总排名第二,成为第四个突破 1400 分的大模型。其中开放模型排名第一,超越了 DeepSeek;在困难提示词、编程、数学、创意写作等任务中排名均为第一;大幅超越了自家 Llama 3 405B,得分从 1268 提升到了 1417;风格控制排名第五。


这样的成绩让开源社区以为又迎来一个新王,于是纷纷下载尝试。但没想到的是,这个模型并没有想象中好用。比如网友 @deedydas 发帖称,Llama 4 Scout(109B)和 Maverick(402B)在 Kscores 基准测试中表现不佳,不如 GPT-4o、Gemini Flash、Grok 3、DeepSeek V3 以及 Sonnet 3.5/7 等模型。而 Kscores 基准测试专注于编程任务,例如代码生成和代码补全。
另外还有网友指出,Llama 4 的 OCR、前端开发、抽象推理、创意写作等问题上的表现能力也令人失望。(参见《Meta Llama 4 被疑考试「作弊」:在竞技场刷高分,但实战中频频翻车》)
于是就有人质疑,模型能力这么拉跨,发布时晒的那些评分是怎么来的?
内部员工爆料
Meta 工程师原贴对线
在关于该模型表现反差的猜测中,「把测试集混入训练数据」是最受关注的一个方向。
在留学论坛「一亩三分地」上,一位职场人士发帖称,由于 Llama 4 模型始终未达预期,「公司领导层建议将各个 benchmark 的测试集混合在 post-training 过程中」,ta 因无法接受这种做法而辞职,并指出「Meta 的 VP of AI 也是因为这个原因辞职的」(指的是在上周宣布离职的 Meta AI 研究副总裁 Joelle Pineau)。

由于发帖者没有实名认证信息,我们无法确认这一帖子的可靠性,相关信息也缺乏官方证实和具体证据。
不过,在该贴的评论区,有几位 Meta 员工反驳了楼主的说法,称「并没有这种情况」,「为了刷点而 overfit 测试集我们从来没有做过」。


其中一位还贴出了自己的真名 ——「Licheng Yu」。领英资料显示,Licheng Yu 是 Facebook AI 的研究科学家主管,已经在 Meta 全职工作了五年多,其工作内容包括支持 Llama 4 的后训练 RL。
如前文所诉,Meta Gen AI 团队负责人也发推反驳了用测试数据训练模型的说法。
不过,有些测试者发现了一些有意思的现象。比如普林斯顿大学博士生黄凯旋指出,Llama 4 Scout 在 MATH-Perturb 上的得分「独树一帜」,Original 和 MATH-P-Simple 数据集上的表现差距非常大(两个数据集本身非常相似,后者只在前者的基础上进行了轻微扰动),这点很令人惊讶。

这是没有做好数据增强的问题吗?或许也可以认为他们的模型为了标准测试做了「过度」优化?
虽然在数学方面,这个问题还没有答案。不过,在对话方面,Meta 的确指出他们针对对话做了优化。他们在公告中提到,大模型竞技场上的 Maverick 是「实验性聊天版本」,与此同时官方 Llama 网站上的图表也透露,该测试使用了「针对对话优化的 Llama 4 Maverick」。

针对这个版本问题,大模型竞技场官方账号也给出了回应,称 Meta 的做法是对平台政策的误读,应该更清楚地说明他们的模型是定制模型。此外,他们还将 Meta 在 HuggingFace 上发布的版本添加到了竞技场进行重新测试,结果有待公布。
大模型竞技场公布对战数据
最后,不论训练策略和 Deadline 的是与非,Llama 4 是否经得起考验,终究还是要看模型本身的实力。目前在大模型竞技场上,Llama 4 展示了一系列问题上的 good case。其中不仅有生成方案的:

也有生成网页代码的:

看起来,Llama 4 也支持更多种类的语言。

在推特的评论区里我们可以看到,人们对于这一系列展示仍然褒贬不一。
虽然 LM Arena 表示未来会将 HuggingFace 上的 Llama 4 版本引入进行比较,但已有人表示,现在我已经很难相信大模型竞技场了。
无论如何,在人们的大规模部署和调整之后,我们会很快了解 Llama 4 的真实情况。
#Vision-R1
类R1强化学习迁移到视觉定位!全开源Vision-R1将图文大模型性能提升50%
图文大模型通常采用「预训练 + 监督微调」的两阶段范式进行训练,以强化其指令跟随能力。受语言领域的启发,多模态偏好优化技术凭借其在数据效率和性能增益方面的优势,被广泛用于对齐人类偏好。目前,该技术主要依赖高质量的偏好数据标注和精准的奖励模型训练来提升模型表现。然而,这一方法不仅资源消耗巨大,训练过程仍然极具挑战。
受到基于规则的强化学习(Rule-Based Reinforcement Learning)在 R1 上成功应用的启发,中科院自动化研究所与中科紫东太初团队探索了如何结合高质量指令对齐数据与类 R1 的强化学习方法,进一步增强图文大模型的视觉定位能力。该方法首次在 Object Detection、Visual Grounding 等复杂视觉任务上,使 Qwen2.5-VL 模型实现了最高 50% 的性能提升,超越了参数规模超过 10 倍的 SOTA 模型。
目前,相关工作论文、模型及数据集代码均已开源。
- 论文标题:Vision-R1: Evolving Human-Free Alignment in Large Vision-Language Models via Vision-Guided Reinforcement Learning
- 论文地址:https://arxiv.org/pdf/2503.18013
- Github 仓库:https://github.com/jefferyZhan/Griffon/tree/master/Vision-R1
- Huggingface 仓库:https://huggingface.co/collections/JefferyZhan/vision-r1-67e166f8b6a9ec3f6a664262
引言
目标定位任务要求模型能够精准识别用户输入的任意感兴趣目标,并给出精确的目标框,对图文大模型的细粒度感知和空间理解能力提出了严峻挑战。当前,图文大模型通常将目标定位建模为文本序列预测任务,并通过大规模预训练和指令数据的监督微调,以 Next Token Prediction 实现对不同粒度目标描述的精准定位。尽管在指代表达理解等任务上已超越传统视觉专家模型,但在更复杂、目标密集的场景中,其视觉定位与目标检测能力仍与专家模型存在显著差距。
R1 的成功应用推动了对基于规则的任务级别奖励监督的探索,使模型摆脱了对人工偏好数据标注和奖励模型训练的依赖。值得注意的是,视觉定位指令数据本身具有精准的空间位置标注,并与与人类对精准目标定位偏好高度一致。基于这些优势,Vision-R1 通过设计类 R1 的强化学习后训练框架,在任务级别监督中引入基于视觉任务评价指标的反馈奖励信号,为增强图文大模型的细粒度视觉定位能力提供了创新突破方向。

Vision-R1 关键设计示意图
Vision Criteria-Driven Reward Function
聚焦图文大模型目标定位问题
在文本序列的统一建模和大规模数据的自回归训练下,图文大模型在目标定位任务上取得了显著的性能提升。然而,其进一步发展仍受到三大关键问题的限制:(1)密集场景中的长序列预测易出现格式错误,(2)有效预测目标的召回率较低,(3)目标定位精度不足。
这些问题制约了模型在更复杂视觉任务上的表现。在自回归 Token 级别的监督机制下,模型无法获得实例级别的反馈,而直接在单目标场景下应用 GRPO 训练方法又忽视了视觉定位任务的特性及 Completion 级别监督的优势。
为此,研究团队结合图文大模型在视觉定位任务中面临的挑战,提出了一种基于视觉任务评价准则驱动的奖励函数,其设计包括以下四个核心部分:
- 框优先的预测匹配:与仅针对单个目标进行设计的方法不同,Vision-R1 采用多目标预测的统一建模方式。为了计算包含多个目标预测的奖励,Vision-R1 首先对文本序列化的预测结果进行反序列化,提取出每个目标的预测框及其标签,并将预测结果与真实标注进行匹配,以确保奖励机制能够全面衡量多目标场景下的定位质量。
- 双重格式奖励:该奖励项旨在解决密集场景下长序列预测的格式错误问题。对于每个预测文本序列,模型需满足指定的模板格式(如 Qwen2.5-VL 采用的 JSON 格式),并确保目标坐标的数值正确性。仅当预测结果同时满足格式和内容要求时,模型才能获得奖励 1,从而引导其生成符合标准的预测输出。
- 召回奖励:该奖励项针对有效预测目标召回率低的问题,鼓励模型尽可能多地识别目标。具体而言,针对每个预测目标及其匹配的真实目标(GT),当两者的 IoU 超过预设阈值 ζ 时,视为该预测有效。对于一个预测序列,其召回奖励定义为有效预测目标数量与实际需要预测目标数量的比例,以此激励模型提高目标的覆盖率。

- 精度奖励:精度奖励与召回奖励协同作用,形成「1+1>2」的优化效果。其中,召回奖励提升模型对目标的全面识别能力,而精度奖励则确保预测的准确性。精度奖励从单实例角度衡量预测质量,其核心目标是鼓励模型生成高质量的边界框。具体地,精度奖励被定义为所有有效预测的平均 IoU 值,以直接激励模型优化目标框的精确度:


Vision-R1 整体框架
Progressive Rule Refinement Strategy
实现持续性能提升
在目标定位任务中,预测高质量(高 IoU)的目标框始终是一个挑战,尤其是在密集场景和小目标情况下。这种困难可能导致模型在同组预测中奖励差异较小,从而影响优化效果。针对这一问题,研究团队提出了渐进式规则调整策略,该策略通过在训练过程中动态调整奖励计算规则,旨在实现模型的持续性能提升。该策略主要包括两个核心部分:
差异化策略:该策略的目标是扩大预测结果与实际奖励之间的映射差异。具体而言,通过惩罚低召回率(Recall)和低平均 IoU 的预测,并对高召回率和高 IoU 的预测给予较高奖励,从而鼓励模型生成更高质量的预测,尤其是在当前能够达到的最佳预测上获得最大奖励。这一策略引导模型在训练过程中逐渐提高预测精度,同时避免低质量预测的奖励过高,促进其优化。具体实现如下:

阶段渐近策略:类似于许多有效的学习方法,给初学者设定容易实现的目标并逐步提升奖励难度是一个常见且行之有效的策略。在 Vision-R1 中,训练过程被划分为初学阶段和进阶阶段,并通过逐步调整阈值 ζ 来实现奖励规则的逐渐变化。具体来说:
- 初学阶段(Beginner Phase): 在这一阶段,设置较低的 ζ 阈值(0.5/0.75),给予模型相对宽松的奖励标准,帮助其快速入门并学习基础的定位能力。
- 进阶阶段(Advanced Phase): 随着训练的深入,逐步提高 ζ 阈值,增加标准要求,以促使模型达到更高的准确度,避免模型依赖简单策略,从而持续推动模型性能的提升。
不同模型的域内外目标检测评测
为全面评估 Vision-R1 的效果,研究团队选择了近期定位能力大幅提升的 Qwen2.5-VL-7B 模型和定位能力突出的 Griffon-G-7B 模型,在更有挑战的经典目标检测数据集 COCO 和多样场景的 ODINW-13 上进行测试,以展现方法对不同定位水平模型的适用性。

经典 COCO/ODINW 数据集上 Vision-R1 方法相较于基线模型性能的提升
实验结果表明,无论基础性能如何,与基线模型相比这些模型在 Vision-R1 训练后性能大幅提升,甚至超过同系列 SOTA 模型,进一步接近了定位专家模型。
研究团队还在模型没有训练的域外定位数据集上进行测试,Vision-R1 在不同模型的四个数据集上取得了平均 6% 的性能提升,充分论证了方法的泛化性。

域外数据集上 Vision-R1 方法相较于基线模型性能的提升
模型通用问答能力评测
研究团队进一步评估了模型在非定位等通用任务上的性能,以验证方法是否能在少量影响模型通用能力的情况下,大幅度提升模型的视觉定位能力。研究团队发现,Vision-R1 近乎不损失模型的通用能力,在通用问答、图表问答等评测集上模型实现了与基准模型基本一致的性能。

通用问答数据集上 Vision-R1 方法与基线模型性能的比较
可视化分析
研究团队提供了在 Qwen2.5-VL-7B 模型上使用 Vision-R1 后在多个场景下的目标检测可视化结果。如结果所示,Vision-R1 训练后,模型能够更好召回所感兴趣的物体,并进一步提升定位的精度。

Vision-R1 训练模型与基准模型检测结果可视化
#斯坦福2025 AI Index报告来了
DeepSeek在全文中被提到45次
刚刚,斯坦福大学正式发布了《2025 AI Index》报告。
在过去的一段时间里,人工智能领域经历了一场蓬勃的发展,但与此同时,也有人说「人工智能是一个泡沫」。其他的讨论话题包括但不限于:人工智能的现有技术和架构将不断取得突破;人工智能走在一条不可持续的道路上;人工智能将取代你的工作;人工智能最擅长的就是把你的家庭照片变成吉卜力工作室风格的动画图像……
每一年的斯坦福 AI Index 报告都会对领域的发展进行系统的梳理,今年也是如此。《2025 AI Index》报告总共 400 多页,涵盖了研发、技术性能、负责任的人工智能、经济影响、科学和医学、政策、教育和公众舆论等主题的图表和数据。
报告地址:https://hai.stanford.edu/ai-index/2025-ai-index-report
目录如下:

除了谷歌、OpenAI 之外,中国公司 DeepSeek 也成为报告关注的焦点,在 PDF 全文中被提到了 45 次。
关于今年 AI Index 报告的核心内容,我们通过 12 张图片来了解:
美国公司的遥遥领先

虽然衡量国家在人工智能竞赛中「领先」的方式多种多样(如期刊文章发表或引用数量、专利授权等),但一个直观的评估指标是观察哪些国家发布了具有影响力的模型。研究机构 Epoch AI 拥有一个从 1950 年至今的重要人工智能模型数据库,AI Index 从中提取了相关数据进行分析。
数据显示,去年美国发布了 40 个知名模型,中国发布了 15 个,欧洲仅有 3 个(均来自法国)。另有数据表明,2024 年发布的这些模型几乎全部来自产业界,而非学术界或政府部门。关于 2023 年至 2024 年知名模型发布数量减少的现象,AI Index 认为可能是由于技术复杂度提高和训练成本持续攀升所致。
说到训练成本……

在这方面,AI Index 缺乏精确数据,因为许多领先的人工智能公司已停止公开其训练过程信息。斯坦福研究人员与 Epoch AI 合作,基于训练时长、硬件类型和数量等详细信息,估算了部分模型的成本。在可评估的模型中,最昂贵的是谷歌的 Gemini 1.0 Ultra,训练成本约达 1.92 亿美元。训练成本的全面上涨与报告中的其他发现相符:模型在参数数量、训练时间和训练数据量等方面持续规模化扩张。
值得注意的是,DeepSeek 并未包含在这一分析中。这家公司在 2025 年 1 月声称仅用 600 万美元训练出了 DeepSeek-R1,引发金融市场震动,虽然部分行业专家对此说法持怀疑态度。
AI Index 指导委员会联合主任 Yolanda Gil 在接受 IEEE Spectrum 采访时表示,她认为 DeepSeek「非常令人印象深刻」,并指出计算机科学历史上充满了早期低效技术被更优雅解决方案取代的案例。她补充道:「我不是唯一一个相信某个时点会出现更高效版本大语言模型的人。我们只是不知道谁会构建它以及如何构建。」
使用人工智能的成本正在下降

尽管大多数 AI 模型的训练成本持续攀升,但报告中强调了几个积极趋势:硬件成本降低、硬件性能提升及能源效率提高。
这使得推理成本(即查询已训练模型的费用)正在急剧下降。这张使用对数比例的图表展示了 AI 性能每美元的发展趋势。报告指出,蓝线表明每百万 tokens 的成本从 20 美元降至 0.07 美元;粉线则显示在不到一年时间内,成本从 15 美元降至 0.12 美元。
人工智能的显著碳足迹

虽然能源效率提高是一个积极的趋势,但存在一个不容忽视的问题:尽管效率有所提升,整体能耗仍在增长,这意味着处于人工智能热潮中心的数据中心留下了巨大的碳足迹。AI Index 基于训练硬件、云服务提供商和地理位置等因素,估算了特定 AI 模型的碳排放,发现前沿人工智能模型的训练碳排放量呈稳步增长趋势 —— 其中 DeepSeek 模型是个例外。
数据显示,最大的排放源是 Meta 的 Llama 3.1 模型,估计产生了 8930 吨二氧化碳排放,相当于约 496 个美国人一年的生活碳排放量。这一显著的环境影响解释了为何人工智能公司正积极采用核能作为可靠的零碳能源来源。
人工智能模型性能差距持续缩小

美国在已发布的知名模型数量上仍然保持领先地位,但中国模型在质量方面正在迅速赶上。数据显示,在聊天机器人基准测试上的性能差距正在不断缩小。2024 年 1 月,顶尖美国模型的表现比最优中国模型高出 9.26%;到 2025 年 2 月,这一差距已缩小至仅 1.70%。报告在推理、数学和编程等其他基准测试中也发现了类似趋势。
人类最后的考试

今年的报告指出了一个不可忽视的事实:用于评估人工智能系统能力的众多基准测试已经「饱和」—— 人工智能系统在这些测试上获得的分数如此之高,以至于它们不再具有区分价值。这种现象已在多个领域出现:通用知识、图像推理、数学、编程等。
Gil 表示,她惊讶地目睹一个又一个基准测试逐渐失去参考意义。她指出:「我一直认为性能会趋于平稳,会达到一个需要新技术或根本不同架构才能继续取得进展的临界点。但事实并非如此。」
面对这种局面,执着的研究人员不断设计新的基准测试,以期挑战人工智能系统。其中一项是「人类的最后考试」,它由来自全球 500 个机构的专业领域专家贡献的极具挑战性问题组成。到目前为止,即使对最顶尖的人工智能系统而言,这项测试仍然难以攻克:OpenAI 的推理模型 o1 目前以 8.8% 的正确答案率位居榜首。业界正密切关注这种局面能持续多久。
公共数据面临的威胁

当今生成式 AI 系统通过训练海量从互联网抓取的数据获得智能,这导致了一个经常被提及的观点:「数据是 AI 经济的新石油」。随着人工智能公司不断挑战可输入模型的数据量极限,业界开始担忧「数据峰值」问题,以及何时会耗尽这种关键资源。一个问题是,越来越多的网站正在限制机器人爬取并抓取其数据(可能是因为担忧人工智能公司从其数据中获利,同时破坏其商业模式)。网站通过机器可读的 robots.txt 文件声明这些限制。
数据显示,顶级网络域名中 48% 的数据现已被完全限制访问。然而,Gil 指出,人工智能领域可能会出现新方法,终结对庞大数据集的依赖。她认为:「预计在某些时候,数据量将不再如此关键。」
企业资金持续涌入人工智能领域

过去五年,企业界已为人工智能投资敞开了资金闸门。虽然 2024 年的全球总体投资未能达到 2021 年的疯狂高峰,但值得注意的是,私人投资规模达到了前所未有的水平。在 2024 年 1500 亿美元的私人投资中,相关指数的另一项数据表明,约 330 亿美元流向了生成式 AI 领域。
企业等待人工智能投资的巨大回报

理论上,企业投资人工智能是因为期望获得可观的投资回报。在这个话题上,人们常以激昂语气讨论人工智能的变革性本质和前所未有的生产力提升。然而,企业尚未见到能带来显著成本节省或实质性新收益的转变。
麦肯锡调查数据显示,在报告成本降低的企业中,大多数节省幅度不足 10%;在因人工智能获得收入增长的企业中,大多数报告的增长幅度不到 5%。巨大的回报可能仍在路上,从投资数据来看,众多企业正在押注于此,但目前尚未实现。
AI 医生或将很快接诊

科学与医疗领域的人工智能应用是人工智能浪潮中的一个重要分支。报告列举了多个新发布的基础模型,这些模型旨在协助材料科学、天气预报和量子计算等领域的研究人员。众多公司正尝试将人工智能的预测和生成能力转化为盈利性药物研发。OpenAI 的 o1 推理模型最近在医学执照考试问题集 MedQA 的基准测试中取得了 96% 的得分。
然而,这似乎仍是一个潜力巨大但尚未转化为显著实际影响的领域 —— 部分原因可能是人类尚未完全掌握如何有效使用这项技术。2024 年的一项研究测试了医生在使用 GPT-4 作为常规资源补充时是否能做出更准确的诊断。结果表明,这既未提高诊断准确性,也未加快诊断速度。值得注意的是,单独使用的 GPT-4 表现却优于人机团队和单独的人类医生。
美国的人工智能政策行动转向州级层面

这张图表显示,美国国会虽有大量关于人工智能的讨论,但实际行动寥寥无几。报告指出,美国的政策制定已转移至州级层面,2024 年共有 131 项法案在各州获得通过。其中 56 项与深度伪造(deepfake)相关,禁止在选举中使用深度伪造技术或借此传播未经同意的私密图像。
美国之外,欧洲已通过《人工智能法案》(AI Act),该法案要求开发被认定为高风险的人工智能系统的公司承担新的责任义务。然而,全球主要趋势是各国联合发表关于人工智能应在世界上扮演何种角色的全面但无约束力的声明。因此,实质性监管行动相对有限,而讨论却十分广泛。
人类是乐观主义者

无论你是股票摄影师、营销经理还是卡车司机,关于人工智能是否以及何时会取代你的工作,社会上已有广泛讨论。然而,最近一项关于人工智能态度的全球调查显示,大多数人并不感到受到人工智能的威胁。
来自 32 个国家的 60% 受访者认为人工智能将改变他们的工作方式,但仅有 36% 的人预期会被替代。「这些调查结果确实让我感到惊讶,」Gil 表示,「人们认为『人工智能将改变我的工作,但我仍将创造价值』,这种观点非常令人鼓舞。」让我们拭目以待,看看我们能否都通过管理人工智能团队来持续创造价值。
更多细节,可参考报告原文。
#DeepRetrieval
颠覆传统信息搜索,效果是之前SOTA的三倍?UIUC韩家炜、孙冀萌团队开源,让模型端到端地学会搜索!
在信息检索系统中,搜索引擎的能力只是影响结果的一个方面,真正的瓶颈往往在于:用户的原始 query 本身不够好。
尤其在专业搜索场景(如文献、数据库查询)中,用户往往无法用精确、完整的表达描述他们的需求。
那么问题来了:能不能教大模型优化原始 query 的表达方式,从而让已有检索系统的能力被最大化激发?
来自 UIUC 的 Jiawei Han 和 Jimeng Sun 团队的一项最新工作 DeepRetrieval 就是针对这个问题提出了系统性解法,只需 3B 的 LLM 即可实现 50 个点以上的提升。
- 论文标题:DeepRetrieval: Hacking Real Search Engines and Retrievers with Large Language Models via Reinforcement Learning
- 论文地址:https://arxiv.org/pdf/2503.00223
- 开源代码:https://github.com/pat-jj/DeepRetrieval
- 开源模型:https://huggingface.co/DeepRetrieval
一句话概括:DeepRetrieval 是一个基于强化学习(RL)的 query 优化系统,训练 LLM 在不同检索任务中优化原始查询,以最大化真实系统的检索效果。
它不是训练一个新的 retriever,也不是让模型直接回答问题,而是:
在不改变现有搜索系统的前提下,通过优化原始 query,让「提问方式」变得更聪明,从而获取更好的结果。
更多有意义的讨论请读原文正文和附录的 Discussion 部分。

方法细节

方法要点
- 输入:原始查询 q
- 输出:改写后的查询 q′(自然语言、布尔表达式或 SQL)
- 环境反馈:使用 q′ 去检索系统中查询 → 返回结果 → 与 groundtruth 对比,计算 reward,reward 为 task-specific 检索表现(如 Recall@K、NDCG@K、SQL accuracy)使用 PPO 进行训练,并加入格式奖励(format correctness)与 KL-regularization 保证训练稳定,优化目标如下:

其中,π_ref 是参考策略(reference policy),通常指的是在强化学习开始之前的初始模型。β 是一个合适的 KL 惩罚系数,用于控制正则化的强度。KL 散度项的作用是惩罚当前策略与参考策略之间的过大偏离,从而在强化学习训练过程中保证策略更新的稳定性。
实验结果
真实搜索引擎的文献搜索

首先在真实的搜索引擎上进行实验,文中用到了专业搜索引擎 PubMed 和 ClinicalTrials.gov。无需改动搜索引擎或其它任何检索器,仅通过端到端地优化 query 表达,DeepRetrieval 就可以让结果获得 10 倍提升,远超各个商业大模型和之前的 SOTA 方法 LEADS(蒸馏 + SFT 方法)。
Evidence-Seeking 检索:通用搜索引擎的革新潜力
DeepRetrieval 在 Evidence-Seeking 检索任务上的优异表现令人瞩目。如表 1 所示,结合简单 BM25,这个仅有 3B 参数的模型在 SQuAD、TriviaQA 和 NQ 数据集上超越了 GPT-4o 和 Claude-3.5 等大型商业模型。
Evidence-Seeking 任务的核心是找到支持特定事实性问题答案的确切文档证据,在通用搜索引擎环境中,这一能力尤为关键。作者团队指出,将 DeepRetrieval 应用到 Google、Bing 等通用搜索引擎的 Evidence-Seeking 场景将带来显著优势:
- 精准定位事实文档:通用搜索引擎包含海量信息,用户难以构建能精确定位证据段落的查询。DeepRetrieval 可将简单问题转化为包含关键术语、同义词和限定符的复杂查询,显著提高找到权威证据的概率。
- 克服知识时效性限制:模型能够将「2024 年奥运会金牌榜前三名」等超出 LLM 知识截止日期的问题转化为精确搜索表达,使检索系统能够找到最新事实证据。
- 多源验证能力:通过优化查询帮助搜索引擎找到多个独立来源的事实证据,从而交叉验证信息准确性,这是纯 LLM 问答无法实现的关键优势。
作者团队表示会将这部分的延伸作为 DeepRetrieval 未来主要的探索方向之一。
Classic IR(Sparse / Dense)

在 BM25 和 dense retriever 下,DeepRetrieval 提供了平均 5~10 点 NDCG 提升,并且:BM25 + DeepRetrieval 和多数 dense baseline 水平相当。
结合极快的检索速度(BM25 vs dense:352s vs 12,232s),展示了一个现实可部署、性能不俗的高效方案。
SQL 检索任务
在 SQL 检索任务中,DeepRetrieval 摆脱了对 groundtruth SQL 的依赖,直接利用生成 SQL 的执行成功率优化模型,通过生成更精准的 SQL 语句,使得模型在 Spider、BIRD 等数据集上的执行正确率均超过对比模型(包括 GPT-4o 和基于 SFT 的大模型)。

探索胜于模仿:RL 为何超越 SFT
DeepRetrieval 的实验揭示了强化学习(RL)在搜索优化上相比监督微调(SFT)的独特优势。实验数据令人信服:在文献搜索上,RL 方法的 DeepRetrieval(65.07%)超过 SFT 方法 LEADS(24.68%)近三倍;在 SQL 任务上,从零开始的 RL 训练(无需任何 gold SQL 语句的监督)也优于使用 GPT-4o 蒸馏数据的 SFT 模型。
这种显著差异源于两种方法的本质区别:SFT 是「模仿学习」,试图复制参考查询,而 RL 是「直接优化」,通过环境反馈学习最优查询策略。SFT 方法的局限在于参考查询本身可能不是最优的,即使是人类专家或大模型也难以直观设计出最适合特定搜索引擎的查询表达。
论文中的案例分析进一步证实了这一点。例如,在 PubMed 搜索中,DeepRetrieval 生成的查询如「((DDAVP) AND (Perioperative Procedures OR Blood Transfusion OR Desmopressin OR Anticoagulant)) AND (Randomized Controlled Trial)」融合了医学领域的专业术语和 PubMed 搜索引擎偏好的布尔结构,这种组合很难通过简单模仿预定义的查询模板获得。
相反,RL 允许模型通过尝试与错误来探索查询空间,发现人类甚至未考虑的有效模式,并直接针对最终目标(如 Recall 或执行准确率)进行优化。这使 DeepRetrieval 能够生成高度适合特定搜索引擎特性的查询,适应不同检索环境的独特需求。
这一发现具有重要启示:在追求最佳检索性能时,让模型通过反馈学习如何与检索系统「对话」,比简单模仿既定模式更为有效,这也解释了为何参数量较小的 DeepRetrieval 能在多项任务上超越拥有更多参数的商业模型。
模型 Think&Query 长度分析

通过分析 DeepRetrieval 在训练过程中模型思考链和查询长度的变化,可以发现以下关键洞见:
思考链长度演变
与「aha moment」相反,DeepRetrieval 的思考链长度随训练呈下降趋势,而非增长。这与 DeepSeek-R1 报告的「aha moment」现象形成鲜明对比,后者的思考链会随训练进展变得更长。图 4(a) 清晰地展示了 Qwen 模型思考链从初始约 150 tokens 逐渐降至稳定的 50 tokens 左右,而 Llama 模型的思考链更短,甚至降至接近 25 tokens。
查询长度特征
实验揭示了思考过程对查询长度的显著影响。无思考过程的模型容易陷入次优解,如图 4(b) 所示,Qwen 无思考版本生成极长查询(500-600 tokens),表现出过度扩展的倾向。相比之下,有思考过程的模型保持更为适中的查询长度,Qwen 约 150 tokens,Llama 约 100 tokens。有趣的是,不同模型采用不同长度策略,但能达到相似性能,表明查询生成存在多样有效路径。
性能与思考过程关系
思考过程对检索性能有决定性影响。图 4(c) 表明,具备思考能力的模型性能显著提升,有思考的模型 Recall@3K 能达到 65%,而无思考模型仅 50% 左右。此外,训练效率也明显提高,有思考的模型更快达到高性能并保持稳定。论文附录 D.1 的分析表明,思考过程帮助模型避免简单地通过增加查询长度和重复术语来提升性能,而是引导模型学习更有效的语义组织策略。
关键结论
DeepRetrieval 展示了思考过程在信息检索中扮演「探索促进器」的关键角色。与数学或编程问题不同,检索任务不需要像「aha moment」那样的突然顿悟现象。相反,检索优化遵循「先详细思考,后逐渐精简」的模式,模型在内化有效策略后,不再需要冗长思考。这表明检索任务中思考链的主要功能是探索,一旦策略稳定便可简化。
这种分析表明,适当的思考过程设计对于构建高效的检索优化系统至关重要,能够在不增加模型参数的情况下显著提升性能,为未来的 LLM 应用于搜索任务提供了重要设计思路。
结论
DeepRetrieval 的贡献在于揭示了一个常被忽视但至关重要的事实:检索效果的上限不仅在于检索器本身,更在于如何「提问」。
通过强化学习教 LLM 改写原始查询,DeepRetrieval 不仅摆脱了对人工标注数据和大模型蒸馏的依赖,还在多个任务上证明了改写 query 的巨大潜力。这项工作为搜索与信息检索领域带来了新的思考:未来的检索优化,不仅是提升引擎算法,更是如何让用户「问得更好」,从而激发出检索系统的全部潜力。
#RoboVerse
迈向机器人领域ImageNet,大牛Pieter Abbeel领衔国内外高校共建RoboVerse,统一仿真平台、数据集和基准
大规模数据集和标准化评估基准显著促进了自然语言处理和计算机视觉领域的发展。然而,机器人领域在如何构建大规模数据集并建立可靠的评估体系方面仍面临巨大挑战。
一方面,采集真实世界的机器人数据需要消耗大量资源(如时间、硬件成本),且效率低下;另一方面,在现实场景中测试机器人性能面临复杂的环境配置,难以控制变量并标准化。
虽然合成数据和仿真模拟被视为潜在解决方案,但目前仍存在数据质量不足、多样性有限,缺乏统一的评估标准等问题。
目前,机器人仿真领域还处于相对碎片化的状态 —— 不同的仿真器标准不一、接口割裂,极大限制了研究集成与社区协作的效率。
为了应对这些挑战,一个致力于跨越隔阂、统一标准的全新平台应运而生。来自 UC 伯克利、北京大学等机构的研究人员打造了 RoboVerse,一个统一的平台、数据集与评测体系,专为可扩展、可泛化的机器人学习而生。
- 论文标题:RoboVerse: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning
- 论文主页:https://roboverseorg.github.io/
- Github 链接: https://github.com/RoboVerseOrg/RoboVerse
团队作者有我们熟悉的机器人和强化学习领域大牛、UC 伯克利教授 Pieter Abbeel,以及同样来自 UC 伯克利的计算机视觉与机器人领域泰斗 Jitendra Malik 教授。
,时长00:47
这项研究在 X 上引起了广泛讨论:「机器人需要 MMLU 基准时刻,打造真实高质量的机器人仿真极端困难,RoboVerse 令人激动地提供了统一的仿真平台,数据集和测试基准!」

「RoboVerse 解决了机器人仿真领域长期存在的分散化,发展缓慢的问题,使得构建,测试,scale up 都变得更容易!」

RoboVerse 介绍
核心亮点一:MetaSim —— 让仿真不再 “各说各话”
RoboVerse 团队设计了 MetaSim:一个通用的配置系统 (configuration system) 与标准接口 (standard interface),能够无缝对接目前主流的机器人仿真器。

这意味着,同一段代码,可以在多个仿真平台上运行!无论你用的是 MuJoCo、IsaacLab、Genesis 还是其他平台,都可以在 MetaSim 的框架下顺畅集成。整个社区的努力,从此可以更好地整合到统一的框架。
核心亮点二:统一的大规模数据集与标准评测体系
RoboVerse 还构建了一个前所未有的大规模合成数据集,涵盖多种任务类型,兼具数据质量和多样性,是目前最具代表性的大规模仿真数据集之一。

同时,平台也提出了适用于模仿学习与强化学习的标准化评测体系,实现跨平台、跨基准的可比性 —— 让算法的性能得到更完整的展现。

核心亮点三:混合仿真 —— 真正 “强强联合”,实现更高保真度
得益于统一的接口,RoboVerse 还解锁了一个 “超能力”:混合仿真(Hybrid Simulation)。
基于 RoboVerse, 你可以用 MuJoCo 提供精准的物理引擎,同时搭配 Isaac Lab 实现高质量的图像渲染 —— 实现物理与视觉的强强组合。它不仅让仿真看起来更像现实世界,更极大提升了真实环境中的迁移效果,让机器人从仿真走进现实。
遥操作 (Teleoperation) 也不再复杂:RoboVerse 支持多种遥操作方式,并实现了高度的可拓展性与易用性。团队专门开发了一款移动端 App,借助手机内置传感器,让用户可以直接通过手机进行机器人远程控制,操作自然流畅、毫无障碍。
此外,RoboVerse 还支持多种其他遥操作设备,包括 Mocap 动作捕捉系统、VR 头显、键盘、手柄等,最大程度上兼顾了不同用户的控制习惯与实验需求。
Real2Sim 工具链:RoboVerse 支持从现实世界单目视频中重建可用于仿真的 3D 资产,基于 3DGS(3D Gaussian Splatting)等先进技术,打通从现实到仿真的通道,大大降低了仿真环境构建的门槛。
AI 自动生成任务(AI-Generate Tasks):借助 MetaSim 的统一任务配置能力,RoboVerse 还探索了利用大语言模型(LLM)进行任务创作。它能够自动组合数据集中的资产并生成全新任务,展现出 LLM 在机器人任务生成上的巨大潜力。
原生支持 GPU 并行训练:RoboVerse 对任务和基准系统进行了深度优化,让过去难以并行扩展的仿真任务,可以轻松迁移到 GPU 上进行大规模并行强化学习训练,大大提高了研究效率与实验规模。
RoboVerse 平台和数据集在模型训练上展现了强大的能力。使用 RoboVerse 提供的大规模高质量数据集,训练 Vision-Language-Action (VLA) Model 可以无需真机样本直接泛化到未见过的真机场景:
RoboVerse 跨模拟器的能力进一步支持了 Sim2Sim2Real 的 humanoid 部署。在 RoboVerse 平台上训练的机器人,可以实现无缝仿真切换,支持训练,验证,部署全流程。
注:以上部分视频,GIF有倍速
在 AI 与机器人技术飞速发展的今天,RoboVerse 的出现,无疑为机器人社区带来了更好的资源整合机会和更大的协同发展潜力。无论你是研究者、开发者,还是对机器人充满好奇的探索者,都值得关注这个正在快速成型的 “机器人宇宙”!
#UI-R1
仅136张截图,vivo开源DeepSeek R1式强化学习,提升GUI智能体动作预测
基于规则的强化学习(RL/RFT)已成为替代 SFT 的高效方案,仅需少量样本即可提升模型在特定任务中的表现。
该方法通过预定义奖励函数规避人工标注成本,如 DeepSeek-R1 在数学求解中的成功应用,以及多模态领域在图像定位等任务上的性能突破(通常使用 IOU 作为规则 reward)。
vivo 与香港中文大学的研究团队受到 DeepSeek-R1 的启发,首次将基于规则的强化学习(RL)应用到了 GUI 智能体领域。
论文标题:UI-R1: Enhancing Action Prediction of GUI Agents by Reinforcement Learning
论文地址:https://arxiv.org/abs/2503.21620
项目主页:https://yxchai.com/UI-R1/
项目代码:https://github.com/lll6gg/UI-R1
简介
本研究创新性地将规则 RL 范式拓展至基于低级指令的 GUI 动作预测任务。具体实现中,多模态大语言模型为每个输入生成包含推理标记和最终答案的多条响应轨迹,在训练和测试时的 prompt 设计如下:

随后通过我们设计的奖励函数评估每条响应,并采用 GRPO 等策略优化算法更新模型参数。该奖励函数包含三个维度:
- 动作类型奖励:根据预测动作与真实动作的匹配度计算;
- 动作参数奖励(聚焦点击操作):通过预测坐标是否落入真实边界框评估;
- 格式规范奖励:评估模型是否同时提供推理过程和最终答案。
数据制备方面,仅依据难度、多样性和质量三原则筛选 130 余个移动端训练样本,展现出卓越的数据效率。实验表明,UI-R1 在桌面端和网页平台等跨领域(OOD)数据上均取得显著性能提升,印证了规则 RL 处理跨领域复杂 GUI 任务的潜力。
方法:强化学习驱动的 GUI 智能体

我们提出的 UI-R1 模型采用了三个关键创新:
1. 独特的奖励函数设计
研究团队设计了专门针对 GUI 任务的奖励函数:R = R_T + R_C + R_F
R_T:行为类型奖励(点击、滑动、返回等)
R_C:坐标准确度奖励(点击位置是否准确)
R_F:格式奖励(输出的格式是否正确)
2. 精心筛选的高质量数据
与其使用大量普通数据,我们提出采用了「质量优先」的策略,从三个维度精选训练数据:
质量:选择标注准确、对齐良好的样本
难度:专注于基础模型难以解决的「困难」样本
多样性:确保涵盖各种行为类型和元素类型
最终只使用了 136 个高质量样本,比传统方法少了几百甚至上千倍,就能够训练得到比 SFT 方式更优的效果。
3. 群体相对策略优化算法
UI-R1 采用了一种名为 GRPO(Group Relative Policy Optimization)的算法。这种算法不需要额外的评论家模型,而是通过比较同一问题的多个不同回答来学习什么是「好」的回答。
实验结果
1. 域内效果提升明显

在 AndroidControl 基准测试上,UI-R1-3B 与基础模型 Qwen2.5-VL-3B 相比:
- 行为类型准确率提高了 15%
- 定位准确率提高了 10.3%
2. 域外泛化能力惊人


UI-R1 在从未见过的桌面 PC 端和网页界面上表现同样出色:
- 在 ScreenSpot 测试中,UI-R1-3B 的平均准确率达到 78.6%,超越 CogAgent-18B 等大模型。
- 在专业高分辨率环境 ScreenSpot-Pro 测试中,UI-R1-3B 达到 17.8% 的平均准确率,提升了与使用 76K 数据训练的 OS-Atlas-7B(18.9%)性能相当。
分析
我们关于 UI-R1 做了一系列分析,研究发现:在 GRPO 的强化学习微调的方式下,数据质量比数据数量重要:

- 困难样本更有价值:按难度选择的方法比随机选择的性能显著更好。
- 数据增长收益递减:随着训练数据量增加,性能提升趋于平缓。
- 精选小数据集比大数据集更有效:三阶段数据选择方法优于使用整个数据集或者随机筛选相同数量的子集。
此外,我们还发现动作预测的难度与思考的长度之间存在关联:思考长度越长,准确率越低(说明问题越难),但通过 UI-R1 形式的强化学习微调之后,对于难样本的成功率提升也更加明显。

这一现象证明了强化微调的价值,通过让模型自主思考来提升难样本的准确率,这个特性是之前的监督微调所难以获得的。
未来探索方向
UI-R1 初步探索了大模型强化学习和推理技术在 GUI Agent 领域的应用。下一步,我们将尝试将 UI-R1 从 RFT 拓展到 SFT + RFT 的组合,实现大规模 UI 数据下统一的思考、决策、规划的 GUI Agent 大模型。
#MAYE
从零搭一套可复现、可教学、可观察的RL for VLM训练流程
自 Deepseek-R1 发布以来,研究社区迅速响应,纷纷在各自任务中复现 R1-moment。
在过去的几个月中,越来越多的研究尝试将 RL Scaling 的成功应用扩展到视觉语言模型(VLM)领域 —— 刷榜、追性能、制造 “Aha Moment”,整个社区正高速奔跑,RL for VLM 的边界也在不断被推远。
但在这样一个节奏飞快、聚焦结果的研究环境中,基础设施层面的透明性、评估的一致性,以及训练过程的可解释性,往往被忽视。
这会带来三个问题:
- 当底层实现依赖封装复杂的 RL 库时,整体流程往往难以看清,理解和修改成本高,不利于方法的教学与传播;
- 缺乏一致、鲁棒的评估标准,不同方法之间难以公平比较,也难以积累长期洞察;
- 训练过程行为不可观测,模型如何学习、学习出了什么能力、训练过程中出现了哪些行为变得难以分析。
于是,来自上海交通大学、MiniMax、复旦大学和 SII 的研究团队选择按下暂停键,进行了一次关于 RL Scaling 的重新思考(Rethinking):
他们提出 MAYE —— 一个从零实现的 RL for VLM 框架与标准化评估方案,希望为该领域奠定一个透明、可复现、可教学的研究起点。
- 论文标题:Rethinking RL Scaling for Vision Language Models: A Transparent, From-Scratch Framework and Comprehensive Evaluation Scheme
- 论文地址:https://arxiv.org/pdf/2504.02587
- 代码地址:https://github.com/GAIR-NLP/MAYE
- 数据集地址:https://huggingface.co/datasets/ManTle/MAYE
三大核心贡献
重塑 RL+VLMs 的研究范式
1. 简洁透明的 RL for VLM 训练架构:轻依赖、强可控
MAYE 的实现很「干净」:
- 没有 Ray / DeepSpeed / TRL / Verl / OpenRLHF / AReaL
- 从零实现,无黑箱封装,无多余抽象
- 基于 Transformers / FSDP2 / vLLM 搭建,专为 VLM 设计
- 支持灵活改动,适合教学与研究场景
这样的设计不仅提升了训练过程的可解释性,也极大降低了 RL for VLM 的入门门槛:每一行代码、每一个环节都可见、可查、可改,研究者可以更清晰地理解模型是如何学习的,又为何能收敛。
我们并未采用当前 VLM-RL 社区常用的 GRPO,而是选择探索 Reinforce++ 的替代可能性。整个项目的灵感来源于 OpenAI Spinning Up,我们希望 MAYE 能成为 VLM-RL 研究中的一个轻量、透明、可教学的入门底座。
相比市面上黑盒化程度较高的 RL 框架,MAYE 更像是一个透明的「教学级实验框架」:既可直接运行,也可任意插拔、修改各个组件,非常适合用于方法对比、原理教学,甚至作为新手入门的第一课。
我们将完整的训练流程解构为 4 个轻量模块:
数据流动(data flow) → 响应采集 (response collection) → 轨迹构造 (trajectory generation)→ 策略更新 (policy update)
每一步都通过清晰的接口呈现,可以像乐高一样自由拼接、替换,将原本复杂封装的黑盒流程彻底 “白盒化”。
训练过程不再是只能看 loss 和 accuracy 的黑箱,而是变成一条可以观察、分析、干预的路径。

RL for VLM,只需四步:结构清晰,可拆可查
2. 标准化评估方案:看清训练过程,看懂模型行为
RL 研究中,一直存在两个老大难问题:训练过程不稳定,评估过程不透明。
尤其在 VLM 场景下,很多 RL 工作只关注 “最后结果”,缺乏对学习曲线、行为演化的系统性观察与分析。
那么 —— 模型究竟是如何学会的?反思能力是如何出现的?长输出真的等于更强推理吗?过去缺乏统一的方式来回答这些问题。
为此,MAYE 提出了一整套细致、可复现的标准化评估方案(evaluation scheme),用于系统追踪训练动态和模型行为演化:
训练集指标:
- accuracy curve(准确率曲线)
- response length(响应长度)
- 多次独立运行取均值,展现真实学习趋势
验证 & 测试集指标:
- pass@1 与 pass@8,在不同温度设置下评估泛化能力
- 提供平均值 + 最大值,全面覆盖性能变化
反思行为指标:
- 反思词使用频率统计(e.g., re-check, think again, verify)
- 五个比例指标,量化反思是否真正带来了正确率提升
这些指标覆盖了训练全过程,既能用于算法开发,也适合横向比较、机制研究。
无论你是做方法、做分析,还是做认知能力探测,MAYE 都能提供一套清晰可复现的过程视角。

准确率曲线、输出长度、反思指标——三类视角还原 RL 全貌
3. 实证发现与行为洞察:RL 不止有效,更值得被理解
MAYE 不只是一个框架和评估工具,也是一套可以产出研究发现的实验平台。
研究团队在多个主流 VLMs(如 Qwen2 / Qwen2.5-VL-Instruct)和两类视觉推理数据集(文本主导 / 图像主导)上开展系统实验,复现实验足够稳健:所有结果均基于 3 次独立运行,并报告均值与标准差。
在此基础上,我们观察到了一些有代表性的现象:
- 输出长度会随着模型架构、数据分布、训练随机种子而显著变化,是判断模型推理策略演化的重要观测信号;
- 反思行为(Reflection)频率与输出长度高度相关,但大多数性能提升仍来源于非反思型推理。输出变长 ≠ 模型变强。长文本可能意味着更丰富的推理,也可能只是训练过程中的随机漂移或复读堆叠。只有当 “更长” 带来 “更准”,才值得被认为是有效行为;
- Aha Moment 并不是 RL 训练凭空生成的,而是在 VLM 模型本身能力基础上被进一步激发和强化;

在多个模型和数据集上,系统追踪了训练动态与反思行为
在相同高质量监督数据(来自 textbook-style CoT)下,RL 在验证集和测试集上均显著优于 SFT,且具有更强的 OOD 泛化能力。即便是 Qwen2.5-VL 这类强基座模型,也能从 RL 中获得额外提升。

验证集与测试集全维度对比:RL 展现出更强的泛化能力

验证集与测试集全维度对比:RL 展现出更强的泛化能力
这些实证结果不仅揭示了 RL 对模型行为的真实影响,也为后续研究者提供了稳定、可对照的 baseline 实验结果。我们也呼吁社区更多采用多次独立运行报告结果,推动 RL for VLM 从 “能跑通” 迈向 “可分析、可信任”。
结语
MAYE 并不是一项追求极致性能的框架优化工程,而是一套面向研究者与教学场景的基础设施尝试。
我们希望它能成为 RL-VLM 研究中一块干净的起点,帮助社区更透明地理解训练过程、更一致地衡量行为变化、也更高效地探索 RL Scaling for VLM 的边界。
这只是一个起步,希望它对你的工作有所帮助。欢迎反馈、改进、复用。论文与代码资源全面开源,欢迎研究者探索和复现。

















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









