







我自己的原文哦~ https://blog.51cto.com/whaosoft/11930709
#将 MOE 塞到 LoRA
在传统的 LoRA 中加入一个 Mixer 矩阵,进行混个不同子空间的信息。
Nothing will work unless you do. --Maya Angelou
本文主要介绍一篇论文是怎么诞生。
文章的基本信息是:
标题:Mixture-of-Subspaces in Low-Rank Adaptation
链接:https://arxiv.org/pdf/2406.11909
代码:https://github.com/wutaiqiang/MoSLoRA
简介:在传统的 LoRA 中加入一个 Mixer 矩阵,进行混个不同子空间的信息。设计非常简单:
最初的想法
说来也是巧合,之前有很多的文章尝试将 LoRA 和 MoE 结合起来,他们基本上都是把 LoRA 当做 MoE 的 Expert,然后塞到 MoE 结构之中,之前也介绍过一些,如文章 https://zhuanlan.zhihu.com/p/676782109、 https://zhuanlan.zhihu.com/p/676557458、 https://zhuanlan.zhihu.com/p/676268097、https://zhuanlan.zhihu.com/p/675186369。这些文章无疑都是将 LoRA 看作 MoE 的 expert,一来缺乏动机,二来影响了 LoRA 的可合并性,三来 训练还慢。
闲来与同事聊天,同事说没见过有文章把 MoE 塞到 LoRA 里面,我当时愣了一下。啊?MoE 塞到 LoRA 里面,意思是说把 MoE 的那种 gate+多专家去做 LoRA 的 lora_A 和 lora_B ?
最直观的设计就是:
有点抽象,但稍微知道点 MoE 和 LoRA 的应该都能懂
其实想出这种设计还是很直接的,毕竟 lora 和 MoE 都是很成熟,很简单的设计。
先不谈有没有动机,反正水文章嘛,都能找到点。就说这个设计,其实有点不合适,为什么呢?
核心就在于 Gate 这玩意,MoE 是希望尽可能训多点参数但计算量不要大太多,因此整了多个Expert 选用一部分并设计了 Gate Router 的机制。但是,LoRA 本身参数量就不大,且rank 大又不一定效果好,堆这个参数属实没必要。此外,LoRA 的好处就在于可以 Merge 回原来的权重,infer 的时候 0 延迟。这个Router Gate 因为和输入 x 耦合,因此没法 merge 回去了。这就带来了推理延迟。
去掉Gate,直接上
有了上面的分析,下一步自然就是要去掉 Gate 了。为了确保能合并,因此所有的 expert 都得用,此时就变成了:
仿佛在拼积木
有了这个设计以后,同时又出现了一些 concern:虽然说 infer 的时候,大家都可以合并到原始权重,都是 0 延迟。但是训练的时候,比如我这个图画的,训的参数是之前的 3 倍多。(在当今这个大环境下,怕是要被审稿人喷)
所以说,要说公平,那就不能设置为 r,每个模块还是得设置成r/k,上图的 case 对应的就是 r/3,这样训练的参数没变,同时 infer 都是 0 延迟。
这也就是论文里面的two-subspace-mixing 的方法的由来。
'多头注意力'的视角
既然把每个专家设置成了 r/k 的大小,这玩意就很像是多头注意力了,有 维度切分+并行操作+最后合并 的操作。这不禁让我思考,这和多头注意力有什么关系?原始的 LoRA 能不能等价拆开?
说到拆开,有两个量可以拆,一个是 rank,一个是输入的维度 d。若是直接说多头,可能大家想到的都是直接把 d 拆开,而不是把 rank拆开。那么这两种拆开我们都可以分析:
i) 把 d 拆开的视角 :
一如既往的抽象,熟悉矩阵运算的应该能一眼看明白
图中展示的是 d拆分2 个 d/2 的 case,为了好理解,我刻意画了矩阵视角。从矩阵运算角度来看,在 d 维度 切分以后,相当于过了两个 A,求和,然后再过两个 B,最后拼接在一起。这三个视角都是等价的。
说实话,要说改进这个,真就没啥好改的。
ii) 把 r 拆开的视角 :
这个视角去看,就挺好的,也比较简介
类似地,也可以将 rank 去拆开。上图展示了将 rank 拆开成两个子块的过程。可以看出,等价于两条支路,每个支路 rank=r/2,最后求和。明显比上面的拆分 d 的方法更优雅。
在这个视角下,一个很简单的改进,就呼之欲出了:
思路很简单的,其实就是将中间的平行支路扭在一起,从公式的角度来看,从A1B1+A2B2 变成了 (A1+A2)(B1+B2)=A1B1+A2B2+A1B2+A2B1.
这么来,相当于多了两项。暂且称这个为扭麻花方案吧。
阶段性结果,但还不够
有了上面的分析,那么就开始做实验了:
微调 LLaMA3做 commonsense reasoning,发现还是有提高的。
不过,这么做还有个问题,那就是 代码效率其实不高。划几条并行的线然后扭个麻花很简单,但是实现起来得看怎么去实现。我初始化了两个 expert 依次去 forward,因此计算效率不高。当然,也可以学习 MHA 的代码,先整个 infer,然后再拆分向量(相当于 A1和A2两个线性层拼在一起 forward,得到结果后再将向量拆开)。
这就启发了另外一个思考,也就是说,这一通操作有很多的线性层的拆分与合并操作,我们之前的分析都是从 linear 层的拆分合并去考虑的,没有考虑向量的拆分合并操作。向量角度等价于:
核心在于中间的 r 向量进行一系列操作(切分,求和,复制)
之前提到的扭麻花操作,等价于中间的 r维度的向量,拆分,逐位相加成一半长度,然后复制,再拼接,获得最终的r'。从这个视角去看,这种多 expert 的扭麻花本质就是在 r 维的向量上加一套组合拳。
混合矩阵的引入
既然是加一套组合拳,这个组合拳 (r维度的向量,拆分,逐位相加成一半长度,然后复制,再拼接)用矩阵来看,是什么呢?
一番分析下来,不难得到相当于中间加了一个固定的蝴蝶矩阵因子(关于蝴蝶矩阵因子,可以参考:https://weld.stanford.edu/2019/06/13/butterfly/ )。
既然如此,那么有没有可能模仿 Tri Dao 的做法, 引入一堆蝴蝶矩阵因子?想想还是没啥必要,因为lora 本身计算量不大,无需这样的拆分,其次就是延迟可能变大很多 (此外,调研发现,蝴蝶矩阵序列在 OFT 系列里面是有应用的,也就是 BOFT)。
不往蝴蝶矩阵序列走,另外一个直观的想法就是把这个矩阵升级为可学习的矩阵了。我在论文中把这个矩阵称为 Mixer 矩阵,那么:
原始的 LoRA 相当于使用固定的单位矩阵 做 Mixer,中间的扭麻花方案相当于插入固定的蝴蝶因子矩阵做 Mixer,论文里升级为可学习的 Mixer,且矩阵全部元素可学习,也就是所提出的MoSLoRA方法。
注1:这种形式和 AdaLoRA 还是蛮像的,不过 AdaLoRA 中间是一个 SVD 分解的特征值,且前后矩阵都加上了正交化约束。注2:我在写论文的时候,发现了 Arxiv 有个优秀的同期工作 FLoRA: Low-Rank Core Space for N-dimension,他们的论文是从 Tucker 分解的角度去切入的,思路很巧妙,也很优雅,感兴趣的也可以看看他们文章和解读。
回到MoE的视角
回到 MoE 的视角去看,也就是回到论文最开始的图:
我们可以简单地将 Mixer 理解为 MoE 的 Gate 生成的 weight,此外这个 Gate有几个特性:
这个 weight 和输入无关,进而确保可合并性
这个 weight 是稠密的,意思是所有的 expert 都用上,而不是 MoE 的那种选取 top-k
原始的 vanilla LoRA 可以看作是 这个 Mixer 矩阵固定为单位矩阵。
看到这,还可以看明白另外一件事,也就是:
【多个并行的LoRA分支 选 top-k个输出 最后求和】 这种常规 LoRA+MoE 设计,本质上相当于 Mixer 具备:i)每行都是同一个元素 ii)部分行全行为 0 iii) 非 0 行的元素由输入来确定 iv) 不可合并 这些性质或者特点。
后记
写到这里,其实也把整个思维的推进过程都说清楚了。当然,论文不可能这么写,太冗长且难以理解。知乎上尚且没几个人有耐心看完,更别说审稿人了。不过整个的思考过程还是收获很多的,可能一个东西刚开始想的时候复杂,换个角度以后,竟然会如此简单。
补充证明
这点也正如@dt3t的评论,直觉上来说,中间插一个 W,如果把 AW 合并看作 A',那岂不是和直接学 A‘B 效果是一样的?
其实,并不是一回事,就算是初始化等价,不代表后续优化的路径是一致的。正如重参数化,虽然看起来是等价的,但是学的结果就是不一样。这个角度去看,Mixer 也可以看作是重参数化分支的形式:

其中 I 是固定的不学习的矩阵。这样就相当于原始 LoRA的旁边加了一个并行分支,和 RegVGG等重参数化一致了。
当然,这里也给出一个【后续优化的路径是不一致的】的简单证明:
https://github.com/wutaiqiang/MoSLoRA/blob/main/MoSLoRA_proof.pdf
也可以直接看图:
只有当 W 是固定的正交矩阵 ,才是等价的,不然就算初始化一致,优化过程也会有差异。
在 MoSLoRA 中,W 是可学习的,且我们分析了初始化对结果的影响。
#FID
FID 指标简介与修正 TorchEval FID 计算接口经历分享
分享有关 FID 计算的知识以及我调试 TorchEval 的经历,并总结用 pytorch-fid, torch-fidelity, TorchEval 算 FID 的方法。
FID 是一种衡量图像生成模型质量的指标。对于这种常见的指标,一般都能找到好用的 PyTorch 计算接口。然而,当我用 PyTorch 的官方库 TorchEval 来算 FID 指标时,却发现它的结果和多数非官方库无法对齐。我花了不少时间,总算把 TorchEval 的 FID 计算接口修好了。在这篇文章中,我将分享有关 FID 计算的知识以及我调试 TorchEval 的经历,并总结用 pytorch-fid, torch-fidelity, TorchEval 算 FID 的方法。文章最后,我还会分享一个偶然发现的用于反映模型训练时的当前 FID 的方法。
FID 指标简介
FID 的全称是 Fréchet Inception Distance,它用于衡量两个图像分布之间的差距。如果令一个图像分布是训练集,再用生成模型输出的图像构成另一个分布,那么 FID 指标就表示了生成出来的图片和训练集整体上的相似度,也就间接反映了模型对训练集的拟合程度。FID 名字中的 Fréchet Distance 是一种描述两个样本分布的距离的指标,其定位和 KL 散度一样,但某些情况下会比 KL 散度更加合适。FID 用来算 Fréchet Distance 的样本来自预训练 InceptionV3 模型,它名称中的 Inception 由此而来。
计算 FID 的过程如下:
准备两个图片文件夹。一般一个是训练集,另一个存储了生成模型随机生成的图片。
用预训练的 InceptionV3 模型把每个输入图片转换成一个 2048 维的向量。
计算训练集、生成集上输出向量的均值、协方差。
把均值、协方差代入进下面这个算 Fréchet Distance 的公式,就得到了 FID。
实际上,在用 FID 的时候我们完全不用管它的原理,只要知道它的值越小就越好,并且会调用相关接口即可。需注意的是,由于 FID 是一种和集合相关的指标,算 FID 时一定要给足图片。在构建自己模型的输出集合时,至少得有 10000 张图片,推荐生成 50000 张。否则 FID 的结果会不准确。
用 PyTorch 计算 FID 的第三方库
由于 FID 的计算需要用到一个预训练的 InceptionV3 模型,只有在模型实现完全一致的情况下,FID 的输出结果才是可比的。因此,所有论文汇报的 FID 都基于提出 FID 的作者的官方实现。这份官方实现是用 TensorFlow 写的,后来也有完全等价的 PyTorch 实现。在这一节里,我们就来学习如何用这些基于 PyTorch 的库算 FID。
GitHub 上点赞最多的 PyTorch FID 库是 pytorch-fid。这个库被 FID 官方仓库推荐,且 Stable Diffusion 论文也用了这个库,结果绝对可靠。使用该库的方法很简单,只需要先安装它。
pip install pytorch-fid再准备好两个用于计算 FID 的文件夹,将文件夹路径传给脚本即可。
python -m pytorch_fid path/to/dataset1 path/to/dataset2另一个较为常见的用 PyTorch 算指标的库叫做 torch-fidelity。它用起来和 pytorch-fid 一样简单。一开始,需要用 pip 安装它。
pip install torch-fidelity之后,同样是准备好两个图片文件夹,将文件夹路径传给脚本。
fidelity --gpu 0 --fid --input1 path/to/dataset1 --input2 path/to/dataset2除了命令行脚本外,torch-fidelity 还提供了 Python API。我们可以在 Python 脚本里加入算 FID 的代码。
import torch_fidelity
metrics_dict = torch_fidelity.calculate_metrics(
input1='path1',
input2='path2',
fid=True
)
print(metrics_dict)torch-fidelity 还提供了其他便捷的功能。比如直接以某个生成模型为 API 的输入 input1,而不是先把图像生成到一个文件夹里,再把文件夹路径传给 input1。同时,torch-fidelity 还支持计算其他指标,我们只需要在命令行脚本或者 API 里多加几个参数就行了。
修正 TorchEval 里的 FID 计算接口
尽管这些第三方库已经足够好用了,我还是想用 PyTorch 官方近年来推出的指标计算库 TorchEval 来算 FID 指标。原因有两点:
- 我的项目其他地方都是用 PyTorch 官方库实现的 (torch 以及 torchvision),算指标也用官方库会让整体代码风格更加统一。我已经用 TorchEval 算了 PSNR、SSIM,使用体验还可以。
- 目前,似乎只有 TorchEval 支持在线更新指标的值。也就是说,我可以先生成一部分图片,储存算 FID 需要的中间结果;再生成一部分图片,最终计算此前所有图片与训练集的 FID。这种计算方法的好处我会在文章后面介绍。
以前我都是用 pytorch-fid 来算 FID。而当我换成用 TorchEval 后,却发现结果对不齐。于是,漫长的调试之路开始了。
当你有两块时间不一样的手表时,应该怎样确认时间呢?答案是,再找到第三块表。如果三块表中能有两块表时间一样,那么它们的时间就是正确的。一开始,我并不能确定是哪个库写错了,所以我又测试了 torch-fidelity 的结果。实验发现,torch-fidelity 和 pytorch-fid 的结果是一致的。并且我去确认了 Stable Diffusion 的论文,其中用来计算 FID 的库也是 pytorch-fid。看来,是 TorchEval 结果不对。
像 FID 这么常见的指标,大家的中间计算过程肯定都没错,就是一些细微的预处理不太一样。抱着这样的想法,我随意地比对了一下二者的代码,很快就发现 TorchEval 把输入尺寸调成 [299, 299] 了,而 pytorch-fid 没做。可删掉这段代码,程序直接报错了。我深入阅读了 pytorch-fid 的代码,发现它的写法和 TorchEval 不一样,把调整尺寸为 [299, 299] 写到了另一个地方。且通过调查发现,InceptionV3 网络的输入尺寸必须是 [299, 299] 的,是我孤陋寡闻了。唉,看来这次的调试不能太随意啊。
我准备拿出我的真实实力来调 bug。我认真整理了一下算 FID 的步骤,将其主要过程总结为以下几步:
- 用预训练权重初始化 InceptionV3
- 用 InceptionV3 算两个数据集输出的均值、协方差
- 根据均值、协方差算距离
最后那个算距离的过程不涉及任何神经网络,输出该是什么就是什么。这一块是最不容易出错,且最容易调试的。于是,我决定先排除第三步是否对齐。我把 TorchEval 得到的均值、协方差存下来,用 pytorch-fid 算距离。发现结果和原 TorchEval 的输出差不多。看来算距离这一步没有问题。
接下来,我很自然地想到是不是均值和协方差算错了。我存下了两个库得到的均值、协方差,算了两个库输出之间的误差。结果发现,均值的误差在 0.09 左右,协方差的误差在 0.0002 左右。图像的数据范围在 0~1 之间,0.09 算是一个很大的误差了。可见,第一步和第二步一定存在着无法对齐的部分。
模型输出不同,最容易想到的是模型权重不同。于是,我尝试交换使用二者的模型权重,再比较输出的 FID。两个库的模型定义不太一样,不能直接换模型文件名。我用强大的代码魔改实力强行让新权重分别都跑起来了。结果非常神奇,算上之前的两个 FID,我一共得到了 4 个不一样的 FID 结果。也就是说,A 库 A 模型、B 库 B 模型、A 库 B 模型,B 库 A 模型,结果均不一样。
我被这两个库气得不行,决定认真研究对比二者的模型定义。眼尖的我发现初始化 pytorch-fid 的 InceptionV3 时有一个参数叫 use_fid_inception。作者对此的注释写道:「如果设置为 true,则用 TensorFlow 版 FID 实现;否则,用 torchvision 版 Inception 模型。TensorFlow 的 FID Inception 模型和 torchvision 的在权重和结构上有细微的差别。如果你要计算 FID,强烈推荐将此值设置为 true,以得到和其他论文可比的结果。」总结来说,TorchEval 用的是 torchvision 里的标准 PyTorch 版 InceptionV3,而 pytorch-fid 在标准 PyTorch 版 InceptionV3 外又封装了一层,改了一些模块的定义。为什么要改这些东西呢?这是因为原来的 FID Inception 模型是在 TensorFlow 里实现的,需要改一些结构来将 PyTorch 模型对齐过去。除了模型结构外,二者的权重也有一定差别。大家都是用 TensorFlow 版模型算 FID,一切都应该以 pytorch-fid 的为准。这个 TorchEval 太离谱了,我也懒得认真修改了,直接注释掉 TorchEval 里原 FIDInceptionV3 的定义,然后大笔一挥:
from pytorch_fid.inception import \
InceptionV3 as FIDInceptionV3按理说,这下权重和模型结构都对齐了。FID 计算的第一、第二步绝对不会有错。而开始的结果表明,FID 计算的第三步也没有错。那么,两个库就应该对齐了。我激动地又测了 TorchEval 的结果,发现结果还是无法对齐!
这不应该啊?难道哪步测错了?人生就是在不断自我怀疑中度过的。而怀疑自我,首先会怀疑最久远的自我。所以,我感觉是最早测第三步的时候有问题。之前我是把 TorchEval 的均值、协方差放到 pytorch-fid 里,结果与 TorchEval 自己的输出一致。这次我反过来,把 pytorch-fid 的均值、协方差放到 TorchEval 的算距离函数里算。这次,我第一次见到 TorchEval 输出了正确的 FID。由此可见,第三步没错。难道是均值和协方差又没对齐了?
自我怀疑开始进一步推进,我开始怀疑第二步输出的均值、协方差还是没有对齐。我再次计算了 pytorch-fid 和 TorchEval 的输出之间的误差,发现误差这次仅有 1e-16,可以认为没有区别。我花了很多时间复习协方差的计算,想找出 TorchEval 里的 bug。可是越学习,越觉得 TorchEval 写得很对。这一回,我找不到错误了。
调试代码,不怕到处有错,而怕「没错却有错」。「没错」,指的是每一步中间步骤都找不到错误;「有错」,指的是最终结果还是错了。没有错误,就得创造错误。我开启了随机乱调模式,希望能触发一个错误。回忆一下,算 FID 要用到两个数据集,一般一个是训练集,一个是模型输出的集合。在 TorchEval 最后一步算距离时,我乱改代码,让一个集合的均值、协方差不变,即来自原 TorchEval 的 Inception 模型的输出;而让另一个的集合的均值、协方差来自 pytorch-fid。理论上说,如果两个库的均值、协方差是对齐的,那么这次输出的 FID 也应该是正确的。欸,这回代码报错了,运行不了。报错说数据精度不统一。原来,TorchEval 的输出精度是 float32,而 pytorch-fid 的输出精度是 float64。之前测试距离计算函数时,数据要么全来自 TorchEval,要么全来自 pytorch-fid,所以没报过这个错。可是这个错只是一个运行上的错误,稍微改改就好了。
我把 pytorch-fid 相关数据的精度统一成了 float32。这下代码跑起来了,可 FID 不对了。调试过程中,如果上一次成功,而这一次失败,则应该想办法把代码退回上一次的,再次测试。因此,我又修改了最后用 TorchEval 计算距离的数据来源,让所有数据都来自 pytorch-fid。可是,修改后,FID 输出没变,还是错的。
为什么两轮测试之前,我全用 pytorch-fid 的输出、TorchEval 的距离计算函数没有错,这次却错了?到底是哪里不同?当测试两份差不多的代码后,一份对了,一份错了,那么错误就可以定位到两份代码的差异处。仔细回顾一下我的调试经历,相信你可以推理出 bug 出自哪了。
没错!我仔细比对了当前代码和我记忆中两轮测试前的代码,仅发现了一处不同——我把 pytorch-fid 的输出数据的精度改成了 float32。把精度改回 float64 就对了。同样,如果把 TorchEval 的输出数据的精度改成 float64,再扔进 TorchEval 的距离计算函数里算,结果也是对的。问题出在 TorchEval 的距离计算函数的数据精度上。
定位到了 bug 的位置,再找出 bug 的原因就很简单了。对比 pytorch-fid 的距离计算函数和 TorchEval 的,可以发现二者描述的计算公式完全相同。然而,pytorch-fid 是用 NumPy 算的,而 TorchEval 是用 PyTorch 算的。算 FID 的距离时,会涉及矩阵特征值等较为复杂的运算,它们对数据精度要求较高。像 NumPy 这种久经考验的库应该会自动把数据变成高精度再计算,而 PyTorch 就没做这么多细腻的处理了。
汇总一下我调试的结论。TorchEval 在权重初始化、模型计算、距离计算这三步中均有错误。前两步没有让 InceptionV3 模型和普遍使用的 TensorFlow 版对齐,最后一步没有考虑输入精度,用了不够稳定的 PyTorch API 来做复杂矩阵运算。要用 TorchEval 算出正确的 FID,需要做以下修改:
- 安装 pytorch-fid 和 TorchEval
- 打开 torcheval/metrics/image/fid.py
- 注释掉 FIDInceptionV3 类,在文件开头加上 from pytorch_fid.inception import InceptionV3 as FIDInceptionV3
- 在 FrechetInceptionDistance 类的构造函数中,在定义所有浮点数据时加上 dtype=torch.float64
这里点名批评 TorchEval。开源的时候吹得天花乱坠,结果根本没人用,这么简单的有关 FID 的 bug 也发现不了。我发了一个修正此 bug 的相关 issue https://github.com/pytorch/torcheval/issues/192,截至目前还是没有官方人员回复。这个库的开发水平实在太逆天了,希望他们能尽快维护好。
在线计算 FID
前文提到,我用 TorchEval 的原因是它支持在线计算 FID。具体来说,可以建立一个 FID 管理类,之后用 update 方法来不断往某个集合加入新图片,并随时使用 compute 方法算出当前所有图片的 FID。我之前写代码忘了清空旧图片的中间结果时发现了一个相关应用。经我使用下来,这种应用非常有用,我们可以用它高效估计训练时的当前 FID。
回顾一下,要得到准确的 FID 值,一般需要 50000 张图片。而训练图像生成模型时,如果每次验证都要生成这么多图片,则大部分时间都会消耗在验证上了。为了加快 FID 的验证,我发现可以用一种 「全局 FID」来近似表示当前的模型拟合情况。具体来说,我先用训练集的所有图片初始化 FID 的集合 1 的中间结果,再在模型训练中每次验证时随机生成 500 张图片,将其中间结果加到 FID 的集合 2 中,并输出一次当前 FID。这样,随着训练不断推进,算 FID 的图片的数量会逐渐满足 50000 张的要求,但是这些图片并不是来自同一个模型,而是来自不同训练程度的模型。这样得到的 FID 仅能大致反映当前的真实 FID 值,有时偏高、有时偏低。但经我测试发现,这种全局 FID 的相对关系很能反映最终的真实 FID 的相对关系。训练两个不同超参的模型时,如果一个全局 FID 较大,那它最终的 FID 一般也会较大。同时,如果训练一切正常,则全局 FID 会随验证轮数单调递减(因为图片数量变多,且拟合情况不会变差)。如果某一次验证时全局 FID 增加了,则模型也一定在这段时间里变差了。通过这种验证方式,我们能够大致评估模型在训练中的拟合情况。这应该是一种很容易想到的工程技巧,但由于分享自己训练生成模型的经验帖较少,且重要性不足以写进论文,我没有在任何地方看到有人介绍这种技巧。
总结
FID 是评估图像生成模型的重要指标。通过 pytorch-fid 等库,我们能轻松地用 PyTorch 计算两个图像分布间的 FID。而通过计算输出分布和训练分布之间的 FID,我们就能评估当前模型的拟合情况。
FID 的计算本身是很简单的。所以在介绍 FID 的计算方法之外,我分享了我调试 TorchEval 的漫长过程。这段经历很有意思,我学到了不少调 bug 的新知识。此前我从来没想到过数据精度竟然会大幅影响某个值的结果。这段经历启示我们,做一些复杂运算时,不要用 PyTorch 算,最好拿 NumPy 等更稳定的库来计算。如果你调 bug 的经验不足,这段经历也能给你许多参考。
文章最后我分享了一种算全局 FID 的方法。它可以高效反映生成模型在训练时的拟合情况。该功能很容易实现,感兴趣的话可以自己尝试一下。
#Unveiling-Deep-Shadows
深度揭秘阴影世界:深度学习时代图像与视频阴影的检测、去除与生成全面综述
胡枭玮博士及其团队成员邢正昊、王天宇等作者,在阴影分析领域长期耕耘,共同撰写了题为《深度揭秘阴影世界:深度学习时代图像与视频阴影的检测、去除与生成全面综述》的重要综述论文。
该论文汇集了来自上海人工智能实验室、香港中文大学和Adobe研究院等顶尖机构的研究力量,深入探讨了过去十年中深度学习在阴影分析处理领域的进展。
通过详尽的深度模型、数据集以及评估指标的综合性论述,该论文为研究人员和从业者提供了一个宝贵的参考平台,特别是通过搭建标准化实验平台,显著提高了不同阴影分析方法间的可比性。
这篇综述是理解当前阴影分析领域的重要资源,为研究人员和从业者提供了公开的资源,包括经过训练的模型、结果和评估指标,以支持这一领域的进一步研究和发展。
论文链接:https://arxiv.org/abs/2409.02108
资源库:https://github.com/xw-hu/Unveiling-Deep-Shadows
1 引言
“阴影是你在地球存在的证据,灵魂是你拥有神性存在的证明。”——马修纳·德利维奥(Matshona Dhliwayo)
光与物体的交互产生了阴影,阴影是我们在地球存在的有形证据,同时也暗示了内在的神性。尽管这一交汇富有诗意,但在科学领域,阴影是在光线遇到障碍物时形成的光照减弱区域。这些由遮挡物投射的阴影揭示了光照方向、几何形态以及物体与其周围环境之间关系的相互作用。
在计算机视觉和多媒体处理中,对阴影的探索从诗意延伸到实用性。图像和视频中的阴影检测、去除与生成是一个不断发展的研究领域,具有广泛的应用前景。准确的阴影检测通过提供关键的视觉线索来增强场景理解,改进图像质量,并确保视觉一致性。阴影去除技术在视觉传达中不可或缺,尤其是在摄影领域,美学效果尤为重要。阴影生成则是打造沉浸式虚拟环境和令人信服的内容的关键。
深度学习的出现显著提高了阴影检测、去除与生成的性能。然而,由于研究的广泛性和模型数量繁多,理解和比较最新的设计核心原理对研究人员和从业者来说是一项挑战。
在过去的十年里,还没有关于基于深度学习的图像和视频阴影检测、去除与生成技术的全面综述。为此,该综述提供了一个深入的调查,涵盖了任务、深度模型、数据集、评估指标等方面的内容,并通过标准化实验比较,为研究人员提供了一个公平的比较平台。
1.1 历史与范围
阴影图像的分析一直是计算机视觉中的基础性挑战,并且长久以来都是研究的重点。对计算机图形学中阴影的探索已有半个世纪之久,主要目标是提高计算机合成图像的逼真度。
到了20世纪80年代,研究的焦点开始转向研究物体(如建筑物)与其阴影之间的关系。
90年代,研究扩展到2D图像中的阴影检测与去除,多个研究对此做出了贡献。
进入21世纪,研究领域扩展到了图像和视频,探索了更多复杂的场景。随着时间的推移,机器学习算法与手工特征逐渐成为阴影检测与去除的主流。
自2014年以来,基于深度学习的算法表现出卓越的性能,逐渐成为这一领域的主要方法。
该综述总结了过去十年间图像和视频中基于深度学习的阴影检测、去除与生成的研究进展。需要注意的是,该综述并不涵盖使用雷达、可见光和红外数据等不同输入模态的遥感中的阴影分析。如需了解遥感中的详细综述,请参考相关文献。
1.2 相关的以往综述
早期综述主要回顾了计算机图形学中阴影类型和生成算法。随后的综述涵盖了视频中的阴影检测方法,包括确定性模型与非模型方法、统计参数化与非参数化方法。
进入2010年代,有关阴影检测与去除的综述逐渐增多,这些综述分别从不同的角度和方法对阴影处理技术进行了详细探讨。
最近的综述开始聚焦于遥感和卫星图像中阴影检测的深度学习方法,以及单张图像的阴影去除技术。然而,这些研究忽略了视频、人脸和文档阴影去除以及其他与阴影相关的任务。此外,研究没有包含最新的数据集、阴影掩码和评估指标,也没有在统一的设置下重新训练深度模型进行实验比较。
至今,还没有一篇涵盖过去十年间图像与视频中基于深度学习的阴影检测、去除与生成的全面综述。
1.3工作的贡献
该综述的主要贡献总结如下:
阴影分析深度学习时代的全面综述。该综述在对现有文献进行广泛调研的基础上,构建了一个系统的知识体系,涵盖了阴影检测、去除与生成的各个方面。论文详细介绍了不同监督水平下的深度学习模型,并对各种学习范式进行了分类和比较,帮助研究者全面掌握当前的技术现状及其应用场景。
实验比较的标准化。目前,对现有方法的比较存在输入大小、评估指标、数据集和实现平台的不一致性。该综述通过标准化实验设置,并在各种方法上进行实验,确保了公平的比较。此外,实验还将在新的精细数据集上进行,这些数据集中已纠正了噪声标签。
性能与效率的权衡分析。在深度学习模型的开发过程中,模型的规模、推理速度与性能之间的权衡始终是一个难题。论文通过详细的实验分析,揭示了这一领域中存在的复杂权衡,并为模型设计提供了重要的参考依据。
跨数据集的泛化能力研究。为了验证模型在不同数据集上的鲁棒性,作者设计了跨数据集泛化实验,考察了模型在不同场景下的表现。这一研究为理解深度学习模型的泛化能力提供了新的视角,并为未来的数据集设计和模型改进提供了重要参考。
AIGC与大模型时代的阴影分析展望。随着人工智能生成内容(AIGC)和大型视觉/语言模型的发展,阴影分析面临新的机遇与挑战。论文对这一领域中的开放问题进行了深入探讨,并提出了未来可能的研究方向,例如如何更好地集成大模型与阴影分析任务,以及在AIGC中的应用前景。
公开可用的结果、训练模型与评估指标。该综述在公平比较设置下提供了结果、训练好的模型和评估指标,这些资源均可在https://github.com/xw-hu/Unveiling-Deep-Shadows上公开,旨在支持未来的研究并推动这一领域的发展。
该综述的后续章节将分别介绍阴影检测、实例阴影检测、阴影去除和阴影生成的全面综述,每一章都包括对深度模型、数据集、评估指标和实验结果的介绍。第六章将深入探讨阴影分析的最新进展,突出该领域中的开放问题与研究挑战。
2 阴影检测
阴影检测预测输入图像或视频中的阴影区域,并生成相应的二值掩码。通过定位阴影,可以实现阴影区域的编辑,并利用这些信息进行更高级的计算机视觉任务,如物体检测和跟踪。在深度学习的推动下,阴影检测技术取得了显著进展,特别是在图像和视频处理的各种应用场景中,极大地提高了检测的准确性和效率。
2.1 用于图像阴影检测的深度模型
在图像阴影检测中,研究人员提出了多种深度学习模型。这些模型通常利用卷积神经网络(CNN)来预测阴影区域,并且随着技术的发展,模型的复杂性和精度逐渐提高。
早期的方法依赖于单一的深度学习模型来生成阴影特征,并通过统计建模方法(例如条件随机场CRF)生成最终的阴影掩码。然而,随着深度学习的快速发展,逐步涌现了各种端到端的深度神经网络,这些网络能够直接从输入的阴影图像中生成阴影掩码。
近年来,研究者们还探讨了多任务学习方法,即在检测阴影的同时,还能够执行其他相关任务,如阴影去除。这些多任务学习方法利用阴影图像的互补信息,能够同时提升多个任务的性能。
为了帮助读者更好地理解这些方法的具体实现,表格(下方)详细列出了近年来各种用于图像阴影检测的深度学习模型,包括其出版年份、主要方法、出版物、骨干网络、监督水平和学习范式等关键信息。这些方法的设计思想和实现方式为后续的研究提供了丰富的借鉴。

2.1.1 组件学习
早期的图像阴影检测方法主要采用卷积神经网络(CNN)来生成阴影特征,随后通过统计建模方法(如条件随机场CRF)生成平滑的阴影轮廓。
例如,CNN-CRF方法通过多个CNN模型学习超像素级别的特征以及物体边界的特征,然后使用CRF模型生成平滑的阴影轮廓。此外,Stacked-CNN方法则采用全卷积神经网络(FCN)生成图像级别的阴影先验图,随后通过补丁CNN生成局部阴影掩码,最后将多个预测结果加权平均融合。
其他方法见原文。
这些基于组件学习的早期方法在一定程度上推动了阴影检测领域的发展,但由于它们在复杂场景中的局限性,逐渐被更加端到端的深度学习方法所取代。
2.1.2 单任务学习
随着深度学习技术的发展,研究人员提出了端到端的深度模型,这些模型能够直接从输入的阴影图像中预测出阴影掩码。单任务学习方法的优势在于它们能够更有效地利用图像信息,从而提高阴影检测的准确性。
例如,scGAN是一种条件生成对抗网络,它通过引入一个可调节的灵敏度参数来控制预测阴影掩码中的阴影像素量。DSC方法则提出了方向感知空间上下文(DSC)模块,该模块通过分析图像上下文信息生成多尺度阴影掩码,并最终将这些掩码融合为最终的阴影掩码。
其他方法见原文。
在这些单任务学习方法的推动下,阴影检测技术取得了显著进展,特别是在处理复杂场景时,这些方法展示出了强大的鲁棒性和高精度。
2.1.3 多任务学习
多任务学习方法不仅关注阴影掩码的预测,还能够同时执行其他相关任务,如生成无阴影图像以进行阴影去除。这些方法通过共享信息和相互促进,能够同时提升多个任务的性能。
例如,ST-CGAN使用了两个顺序的条件生成对抗网络,其中第一个网络预测阴影掩码,第二个网络则通过将阴影图像和阴影掩码作为输入,生成无阴影图像。ARGAN方法则进一步发展了这一思想,通过引入注意力机制和逐步细化的生成策略,在阴影检测和去除任务上取得了良好的效果。其他方法见原文。
这些多任务学习方法不仅提高了阴影检测的准确性,还为阴影去除和生成任务提供了有力的支持。
2.1.4 半监督学习
深度模型的训练通常需要大量的标注数据,然而在阴影检测任务中,标注阴影掩码的难度较大,限制了可用的训练数据量。因此,研究人员提出了半监督阴影检测方法,以利用标注数据和未标注数据共同训练模型,从而提升模型在复杂场景中的表现。
例如,ARGAN+SS方法采用了一种半监督的生成对抗网络,通过使用未标注的数据进行对抗训练,增强了模型的泛化能力。MTMT-Net方法则基于教师学生架构,通过多任务学习来实现半监督阴影检测,在保留细节信息的同时,显著提高了模型的泛化能力。
其他方法见原文。
2.1.5 自监督学习
自监督学习通过利用数据本身作为监督信息,能够在无需大量标注数据的情况下,学习到深度特征。在阴影检测任务中,自监督学习的方法通常利用现有的训练数据或额外的数据来提升模型的表现。
例如,FDRNet方法提出了一种特征分解与重加权方案,通过使用亮度调整后的图像作为监督,来学习与亮度相关和无关的特征,并最终通过累积学习来增强特征。在这些自监督学习方法的帮助下,阴影检测模型能够更好地适应不同的场景和光照条件。
其他方法见原文。
2.1.6 视觉大模型
现代视觉大模型在通用视觉任务中展示了令人印象深刻的性能。比如,Segment Anything(SAM)在图像分割任务中表现出色。然而,处理复杂背景和场景中的阴影仍然是一个挑战。因此,研究人员提出了各种方法来微调SAM模型,以提高其在阴影检测任务中的表现。
例如,SAM-Adapter通过在SAM编码器的每一层中引入两个多层感知机(MLP)作为适配器,增强了模型的性能。ShadowSAM则通过伪掩码生成策略和光照纹理引导的更新策略,进一步提高了SAM在阴影检测任务中的表现。
这些大型视觉模型在阴影检测任务中展示出了强大的潜力,尤其是在处理复杂场景和多样化光照条件时,能够保持较高的检测精度。
2.2 用于视频阴影检测的深度模型

视频阴影检测需要处理动态场景中的阴影,并保证视频帧之间的阴影掩码一致性。这一任务的难点在于,模型不仅需要准确检测每一帧中的阴影,还需要在时间维度上保持检测结果的稳定性。
例如,TVSD-Net方法是第一个基于深度学习的视频阴影检测方法,通过采用三重平行网络,协同获取视频内部和视频之间的判别表示。STICT方法则结合了半监督学习,通过时空插值一致性训练,提高了模型在视频阴影检测任务中的表现。
其他方法见原文。
这些视频阴影检测方法为处理动态场景中的复杂阴影问题提供了有效的解决方案。通过引入时间信息和时序一致性约束,这些方法能够在多帧视频中实现高精度的阴影检测。
2.3 阴影检测数据集
该综述接下来将讨论用于模型训练和评估的广泛使用的数据集,这些数据集在推动阴影检测技术发展方面起到了重要作用。
2.3.1 图像阴影检测数据集
SBU数据集是一个用于训练和评估深度学习方法的大规模阴影数据集,包含4087张训练图像和638张测试图像; SBU-Refine修正了SBU中的噪声标签。ISTD数据集则是第一个引入阴影图像、无阴影图像和阴影掩码的数据集,设计用于阴影检测和去除任务。CUHK-Shadow 是目前最大的图像阴影检测数据集。
2.3.2 视频阴影检测数据集
ViSha数据集包含120个带有像素级阴影注释的视频,用于评估视频阴影检测方法的性能。RVSD数据集从ViSha中选择了86个视频,重新标注了阴影实例及其对应的自然语言描述。
2.4 评估指标
阴影检测的评估通常使用多种指标来衡量模型的性能,包括平衡误差率(BER)、Fβ-测量、交并比(IoU)等。这些指标不仅可以衡量模型的总体准确性,还能反映其在阴影检测任务中的鲁棒性和泛化能力。时间稳定性 (TS) 通过计算相邻帧之间的光流变形 IoU 来评估视频阴影检测的稳定性,往往被之前的工作忽略。
2.5 实验结果与分析
在这一节中,作者通过实验分析了不同阴影检测模型在各大数据集上的表现,并探讨了模型大小、推理速度与检测精度之间的平衡问题。
随着阴影检测技术的不断发展,模型在特定数据集上的表现往往无法准确反映其在真实世界中的实际应用效果。因此,跨数据集的泛化能力评估成为衡量模型鲁棒性的重要标准。
为了深入研究当前深度学习模型在阴影检测任务中的泛化能力,该综述设计并实施了跨数据集评估实验。多数模型在跨数据集评估中表现出了明显的性能下降,尤其是在处理复杂背景或低对比度场景时,误检和漏检问题显著增加。
实验结果表明,在复杂场景下开发高效且鲁棒的阴影检测模型仍然是一个亟待解决的挑战。

ViSha数据集用于评估视频阴影检测方法的性能,实验结果显示,各方法在帧级精度、时间稳定性、模型复杂度和推理速度上存在显著的权衡。在视频阴影检测中如何在帧级精度、时间稳定性、模型复杂度和推理速度之间实现最佳平衡,仍然是一个具有挑战性的问题。

3 实例阴影检测
除了传统的阴影检测任务,近年来,实例阴影检测也逐渐成为研究热点。实例阴影检测不仅需要识别阴影区域,还要将其与投影物体进行关联,从而实现对阴影与物体的联合检测与处理。该任务的提出极大地丰富了阴影分析的研究维度,尤其在图像和视频编辑、虚拟现实等应用场景中具有重要意义。

3.1 用于图像实例阴影检测的深度模型
图像实例阴影检测的主要挑战在于如何在检测阴影的同时,准确识别投影物体,并建立二者之间的关联关系。为此,研究人员提出了多种深度学习模型,并在不同的数据集上进行了广泛的实验验证。
例如,LISA通过结合光照方向预测,识别可能包含阴影/物体实例及其关联的区域。SSIS则采用了一种单阶段的全卷积网络架构,通过双向关系学习模块实现了对阴影和物体实例的直接端到端学习。
其他方法见原文。这些方法在处理复杂场景、阴影与物体关系时,展现了较高的鲁棒性和检测精度,为实例阴影检测任务奠定了坚实的基础。
3.2 用于视频实例阴影检测的深度模型
视频实例阴影检测相较于图像实例阴影检测,进一步增加了时间维度的挑战。模型不仅需要识别每一帧中的阴影和物体实例,还需在视频序列中跟踪这些实例及其关联关系,并检索偶然丢失的部分阴影或物体实例。这就要求模型在处理动态场景时,能够保持高效的时间一致性和空间一致性。
ViShadow是一个半监督框架,它结合了图像和未标注的视频序列进行训练,利用中心对比学习方法增强了跨帧的关联检测能力。此外,该方法还引入了循环一致性损失,进一步提高了在视频中处理复杂阴影和物体关联的准确性。
通过对现有视频实例阴影检测方法的评估,可以看出在动态场景中保持高效且稳定的检测结果,仍然是该领域的主要研究难题之一。
3.3 实例阴影检测数据集与评估指标
为了推动实例阴影检测的研究,多个专门的数据集被提出,用于模型的训练和评估。
例如,SOBA数据集是首个图像实例阴影检测数据集,包含了精确标注的阴影-物体关联实例。SOBA-VID数据集则进一步扩展到视频领域,提供了帧级别的精确标注以及部分无标注数据,用于视频实例阴影检测任务的研究。
在评估指标方面,SOAP(Shadow-Object Average Precision)用于衡量图像实例阴影检测的性能,而SOAP-VID则通过时空IoU替代传统的IoU,用于评估视频实例阴影检测的时空一致性表现。
3.4 实例阴影检测结果


实验结果表明,尽管SSISv2在阴影和物体实例分割中性能最佳,但速度较慢,且所有方法在复杂场景中的性能有限。跨数据集测试中结果表明不同方法的性能趋势与在SOBA测试集上的一致,且性能无明显下降,证明了这些阴影实例检测方法具有较强的泛化能力。如何开发一个高效的模型以准确分割阴影和物体实例仍是一个具有挑战性的问题。
4 阴影去除
阴影去除任务旨在从图像或视频中移除阴影,生成无阴影的清晰画面。这一过程涉及对阴影区域内物体颜色和纹理的精确恢复。随着深度学习的引入,阴影去除技术取得了革命性进展,从传统的物理模型方法过渡到基于数据驱动的端到端学习方法。
4.1 用于图像阴影去除的深度模型

4.1.1 全监督学习
全监督学习方法通常依赖于标注数据集,即配对的有阴影图像和无阴影图像,用以训练模型。早期的方法主要利用卷积神经网络(CNN)来识别和去除阴影。随着网络结构的复杂化和精细化,这类方法逐渐发展为多分支网络,能够更好地捕捉图像中的阴影特征。
例如,DeshadowNet提出了一个端到端的网络结构,由三个子网络组成,分别用于提取图像的全局和局部特征,从而生成无阴影的图像。SP+M-Net通过一个双分支网络分别预测阴影参数和阴影磨砂层,最终合成无阴影图像。
随着技术的发展,DHAN+DA设计了一种层次化聚合注意力模型,通过引入上下文信息和注意力损失,提高了阴影去除的精度。此外,Inpaint4shadow引入了基于图像修补的数据集预训练,以减少阴影残留,并通过双编码器架构生成无阴影图像。
生成对抗网络(GAN)在图像阴影去除中发挥了重要作用。这类方法通过生成器和判别器的相互博弈,不断优化生成器的性能,从而生成更加逼真的无阴影图像。
例如,ST-CGAN采用了两个条件生成对抗网络,一个用于检测阴影,另一个用于去除阴影。ARGAN通过生成注意力图来标记阴影区域,并递归地恢复阴影较浅或无阴影的图像。
同时,RIS-GAN提出了一种多生成器和多判别器的结构,通过生成负残差图像、中间阴影去除图像、反向光照图以及精细化的阴影去除图像,进一步提高了阴影去除的效果。
随着Transformer在计算机视觉任务中的广泛应用,越来越多的研究开始将其应用于图像阴影去除任务中。Transformer模型的自注意力机制能够有效捕捉图像中的全局上下文信息,极大地提升了阴影去除的精度。
例如,CRFormer结合了CNN和Transformer的优势,通过区域感知的跨注意力机制聚合阴影区域的特征。ShadowFormer通过通道注意力编码器-解码器框架和阴影交互注意力机制,分析阴影和非阴影区域之间的关联,提高了去除阴影的精度。
此外,SpA-Former 通过联合傅里叶变换残差块和双轮空间注意力机制,进一步提升了阴影去除的效果。
扩散模型在生成图像领域表现出色,近期也被引入到图像阴影去除任务中。ShadowDiffusion(G) 通过退化和扩散生成先验逐步细化输出,并作为扩散生成器的辅助模块,提升了阴影掩码估计的准确性。
DeS3利用自适应注意力和ViT相似性机制,在去除硬阴影、软阴影和自阴影方面表现出了强大的能力。LFG-Diffusion通过在潜在特征空间中学习无阴影的先验知识,在阴影去除任务中取得了高效的表现。更多方法见原文。
4.1.2 无监督学习
无监督学习方法在阴影去除任务中具有重要的优势,特别是它不依赖于配对的有阴影和无阴影图像,因此可以在更广泛的未标注数据上进行训练。无监督学习通过探索数据本身的内在结构和相似性,逐步去除阴影区域。
例如,Mask-ShadowGAN 是一种创新性的无监督方法,通过生成对抗网络(GAN)架构,在没有配对数据的情况下去除阴影。DC-ShadowNet则通过对比学习增强了网络对阴影和背景的区分能力,从而提升了阴影去除的精度。LG-ShadowNet引入了光照引导模块,该模块通过模拟不同光照条件下的阴影变化,在无监督的框架下有效去除复杂场景中的阴影。
4.1.3 弱监督学习
弱监督学习方法旨在减少对完全标注(配对)数据集的依赖,从而在阴影去除任务中取得高效的表现。此类方法通常只利用阴影图像来指导模型学习阴影去除的过程。
例如,Param+M+D-Net 采用了一种参数化建模和特征分解的混合策略,在弱监督学习框架下,通过对阴影区域的参数化建模来捕捉阴影的结构和形状特征,并利用特征分解技术将阴影区域与背景区分开来,从而生成无阴影图像。
4.1.4 单张图像自监督学习
单张图像自监督学习方法利用图像本身的信息作为监督信号,避免了对大量数据的依赖。这类方法通常通过分析和利用图像中的内在属性,如亮度、颜色、纹理等,来逐步去除阴影。
例如,Self-ShadowGAN 是一种典型的单张图像自监督学习方法,它利用单张图像中的阴影信息,通过自监督学习框架生成无阴影图像。
4.2 用于文档阴影去除的深度模型
文档阴影去除旨在提升数字文档的视觉质量和可读性。由于文档图像的独特性,通用阴影去除方法在处理文档阴影时面临挑战,尤其是需要大量配对数据集,以及缺乏对文档特定属性的考虑。
文档阴影去除的代表性方法包括 BEDSR-Net,这是第一个专门用于文档图像阴影去除的深度网络,通过估计背景颜色和生成注意力图来去除阴影。
BGShadowNet 采用两阶段过程,先通过背景特征生成初步结果,再通过细节增强模块修正光照不一致问题。FSENet 则将图像分为低频和高频分量,通过 Transformer 和卷积操作分别调整光照和增强纹理。

4.3 用于面部阴影去除的深度模型
面部阴影去除涉及去除外部阴影、柔化面部阴影并平衡光照。这一任务在面部光照处理和人脸关键点检测的鲁棒性提升中起到关键作用。
Zhang等人提出了首个专为面部阴影去除设计的深度学习方法,使用两个独立模型分别去除外部和面部阴影;
He等人则引入了无监督方法,将阴影去除框架化为图像分解问题,通过生成无阴影图像和阴影掩码实现去除;
GS+C方法将阴影去除分为灰度处理和着色两个阶段,并在视频处理中通过时间共享模块保证一致性。
4.4 用于视频阴影去除的深度模型
相比于图像阴影去除,视频阴影去除任务的挑战在于需要同时处理时间和空间维度的连续性。
现有的视频阴影去除模型通常通过结合多个视频帧的信息,实现更加平滑和自然的去除效果。PSTNet是一种结合物理、空间和时间特征的视频阴影去除方法,使用无阴影图像和掩码进行监督。
通过物理分支实现自适应曝光和监督注意力机制,并通过空间和时间分支保证分辨率和一致性。特征融合模块用于精细化输出,而 S2R 策略能够使在合成数据上训练的模型适应真实世界的应用场景,无需重新训练。
4.5 阴影去除数据集
ISTD(ISTD+)和 SRD 是用于训练和评估阴影去除模型的常用数据集,提供了多种场景下的阴影图像和无阴影对照图像。USR 数据集则支持无监督学习,涵盖了多种复杂场景,为无配对数据的阴影去除研究提供了支持。更多数据集见原文。
4.6 阴影去除评估指标
常用的评估指标包括 RMSE、PSNR、SSIM 以及 LPIPS,用于衡量模型的阴影去除效果和图像质量。此外,运行时间和推理速度也是重要的性能衡量标准,尤其在实时应用中。
4.7 阴影去除结果

对多个图像阴影去除方法进行了全面的性能评估,在 256×256 和 512×512 分辨率下重新训练各方法,并修正了有些方法在评测过程中评测函数实现细节错误,使用标注掩码图像污染评测数据等问题。
结果表明,早期的方法(如 DSC 和 ST-CGAN)在多个评估指标上表现优于后来的方法,而无监督方法在 SRD 和 ISTD+ 数据集上表现与监督方法相当,可能是由于训练和测试集的背景纹理相似,Mask-ShadowGAN 在效果和效率之间达到了最佳平衡;小型模型如BMNet在不显著增加模型大小的情况下提供了有竞争力的性能,且大多数方法在更高分辨率下表现出更好的结果。
跨数据集评估揭示了现有模型在复杂场景中的局限性,强调了更具代表性数据集和适应性模型的必要性,尤其在应对现实世界复杂阴影场景的时候。
实验结果表明,如何开发一个鲁棒的模型并准备一个具有代表性的数据集,以在复杂场景中实现图像阴影去除的高性能,仍然是一个具有挑战性的问题。
5 阴影生成
阴影生成任务在计算机视觉和图形学中具有重要意义,通常用于以下三个主要目的:
- 图像合成,即为插入或重新定位在图像中的物体生成投射阴影,从而提高场景的真实性;
- 数据增强,通过在图像中创建投射阴影,增加对阴影检测或去除任务有益的配对数据的数量;
- 素描生成,为手绘素描生成阴影,以加快绘图过程,并提高素描图像的视觉表现力。

5.1 用于图像阴影生成的深度模型
图像阴影生成的主要挑战在于如何通过计算生成与场景几何和光照条件相匹配的自然阴影。近年来,生成对抗网络(GAN)在这一任务中表现出色。
例如,ShadowGAN 通过条件对抗网络架构,在场景信息和物体几何的基础上生成逼真的阴影图像。该方法在增强现实(AR)应用中尤为有效,通过模拟虚拟物体的阴影,使得虚拟与现实的融合更加自然。ARShadowGAN 则专为单光源场景设计,通过物理一致性模块确保阴影的生成符合光照条件,大大提升了增强现实中的视觉体验。
PixHt-Lab 引入了像素高度映射技术,通过将二维图像中的像素映射到三维空间,生成具有高度真实感的阴影效果,从而进一步提高了图像合成中的光照逼真度。
总体而言,这些模型通过不同的创新方法,在图像合成任务中生成了高质量的阴影,显著提升了图像的视觉真实感和物理一致性。
在阴影去除任务中,生成阴影作为中间结果是提高去除效果的重要手段。Mask-ShadowGAN 是一种创新性的生成对抗网络,专注于生成用于阴影去除的中间阴影掩码,通过在无配对数据的情况下生成逼真的阴影掩码,显著减少了对标注数据的依赖。模型利用生成的阴影掩码有效地提升了阴影去除的效果,使得阴影去除更加精确和自然。
阴影生成在艺术创作中也扮演着重要角色,特别是在为手绘素描添加逼真的光影效果方面。Zheng等人提出了一种从手绘素描中生成艺术阴影的方法,利用指定的光照方向和三维建模技术生成符合素描线条和结构的阴影。
这一方法自动渲染自阴影和边缘光效果,使得素描作品在视觉上更加真实和生动。SmartShadow 是一个数字绘图工具,专为帮助艺术家为线条画添加阴影而设计。它提供了阴影笔刷、阴影边界控制以及全局阴影生成器等功能,帮助艺术家在创作过程中更加高效地生成复杂的阴影效果,同时保持艺术创作的灵活性和创造性。
这些模型和工具极大地提高了数字艺术创作的效率和质量,为艺术家提供了更为强大的创作手段。
5.2 阴影生成数据集
高质量的数据集在阴影生成任务中至关重要,为训练和评估模型提供了必要的基础。用于图像合成的阴影生成数据集,如Shadow-AR,专门为增强现实中的阴影生成任务设计,包含了丰富的场景和光照条件,通过提供多样化的数据支持,帮助研究人员训练和评估模型的表现。
DESOBA 数据集则基于现有的 SOBA 数据集,通过移除阴影生成地面实况,用于训练和评估模型的阴影生成能力。
RdSOBA 数据集则利用 Unity 渲染引擎创建了丰富的三维场景和物体组合,为研究人员提供了在复杂光照条件下训练和评估模型的宝贵资源。
这些数据集的设计和应用使得阴影生成技术得以在多样化的场景中得到验证和改进,推动了这一领域的发展。
5.3 评估指标
为了有效地评估阴影生成模型的性能,研究人员提出了多种评估指标,包括结构相似度指数(SSIM)、峰值信噪比(PSNR)和人眼感知一致性(LPIPS)等。这些指标从不同角度量化了模型生成阴影的质量。
5.4 讨论
不同的方法由于其独特的模型设计和应用场景,需要特定的训练数据。例如,SGRNet需要前景阴影掩码和目标阴影图像来进行图像合成;相比之下,Mask-ShadowGAN只需未配对的阴影和无阴影图像即可进行阴影去除。
ARShadowGAN利用真实阴影及其遮挡物的二值图进行训练,用于增强现实场景中虚拟物体的阴影生成。
SmartShadow则依靠艺术家提供的线条画和阴影配对数据来训练深度网络,从而生成线条画上的阴影。
由于篇幅限制,建议读者深入了解每个应用的结果,以理解这些方法的有效性和适用性。
然而,目前的阴影生成方法主要集中在图像中的单个物体上,如何在视频中为多个物体生成一致的阴影仍是一个挑战。此外,除了为缺乏阴影的物体生成阴影外,通过调整光照方向来编辑各种物体的阴影也具有更广泛的实际应用潜力。
6 总结与未来研究方向
总之,该综述通过回顾一百多种方法,并标准化实验设置,推动了深度学习领域中阴影检测、去除与生成的研究。探讨了模型规模、速度与性能之间的关系,并通过跨数据集研究评估了模型的鲁棒性。
下面进一步提出未解决的问题和未来的研究方向,特别强调AIGC和大模型的发展对推动该领域学术研究和实际应用的重要性。
统一的阴影和物体检测、去除与生成模型是一个有前景的研究方向。现有的大多数方法只专注于阴影检测、去除或生成的某一方面。
然而,所有与阴影相关的任务本质上是相互关联的,理论上可以从共享的洞察中受益,尤其是在物体与阴影之间的几何关系方面。开发一个统一的模型可能会揭示潜在的关系,并最大化训练数据的使用,从而增强模型的泛化能力。
物体的语义和几何信息在阴影分析中仍未得到充分挖掘。现代的大型视觉和视觉语言模型,拥有庞大的网络参数和海量的训练数据,在分析图像和视频中的语义与几何信息方面表现出了良好的潜力,并具备了显著的零样本能力。
例如,Segment Anything能够提供像素级的分割标签;Depth Anything可以估计任何图像输入的深度;而ChatGPT-4o则能够描述图像和视频帧中的故事。利用语义和几何洞察来进行阴影感知,可能会显著提升阴影分析与编辑的效果,甚至有助于分离重叠的阴影。
物体与阴影的关系对于图像和视频编辑任务具有重要作用。实例阴影检测生成了物体和阴影实例的掩码,从而方便了图像修复、实例克隆和阴影修改等编辑任务的进行。
例如,图像扩展通过分析已观测到的物体及其阴影来推断未观测到的物体的布局。这些应用被集成到手机的图像和视频编辑功能中既简单又具有显著益处。现代智能手机配备了多摄像头和高动态范围功能,如何利用这些摄像头增强阴影与物体的编辑效果是一个值得探索的新研究方向。
阴影是区分人工智能生成视觉内容与真实内容的有效工具。随着人工智能生成内容(AIGC)的快速发展,越来越多样化的图像和视频得以生成。
然而,这些AI生成的内容往往忽视了几何方面的因素,导致阴影特性与真实环境不符,从而破坏了图像的三维感知。实例阴影检测技术被用于分析物体与阴影的关系,当光源对齐与物体几何形状不一致时,这些技术揭示了图像的合成特性。AI生成的视频(例如Sora)同样需要遵循几何关系。
因此,未来研究应重点关注AI生成内容中的阴影一致性问题,并评估潜在的不一致性。此外,阴影作为一种自然且隐蔽的对抗性攻击方式,能够破坏机器学习模型的正常运行。
#SPiT
超像素驱动的非规则ViT标记化,实现更真实的图像理解
Vision Transformer(ViT) 架构传统上采用基于网格的方法进行标记化,而不考虑图像的语义内容。论文提出了一种模块化的超像素非规则标记化策略,该策略将标记化和特征提取解耦,与当前将两者视为不可分割整体的方法形成了对比。通过使用在线内容感知标记化以及尺度和形状不变的位置嵌入,与基于图像块的标记化和随机分区作为基准进行了对比。展示了在提升归因的真实性方面的显著改进,在零样本无监督密集预测任务中提供了像素级的粒度,同时在分类任务中保持了预测性能。
论文: A Spitting Image: Modular Superpixel Tokenization in Vision Transformers
论文地址:https://arxiv.org/abs/2408.07680
论文代码:https://github.com/dsb-ifi/SPiT
Introduction
在卷积架构之后,Vision Transformers(ViTs) 已成为视觉任务的焦点。在最初的语言模型的Transformer中,标记化是一个至关重要的预处理步骤,旨在基于预定的熵度量最佳地分割数据。随着模型被适配于视觉任务,标记化简化为将图像分割为正方形的图像块。这种方法被证明是有效的,很快成为了标准方法,成为架构的一个重要组成部分。
尽管取得了明显的成功,论文认为基于图像块的标记化存在固有的局限性。首先,标记的尺度通过固定的图像块大小与模型架构严格绑定,忽视了原始图像中的冗余。这些局限性导致在较高分辨率下计算量显著增加,因为复杂度和内存随标记数量呈平方级增长。此外,规则的分割假设了语义内容分布的固有均匀性,从而高效地降低了空间分辨率。
随后,若干研究利用注意力图来可视化类标记的归因,以提高可解释性,这常应用于密集预测任务。然而,正方形分割产生的注意力图在图像块表示中会引起分辨率的丧失,进而无法本质上捕捉原始图像的分辨率。对于像素级粒度的密集预测,需要一个单独的解码器进行放大处理。
Motivation
论文从原始的ViT架构中退一步,重新评估基于图像块的标记化的作用。通过关注架构中这个被忽视的组件,将图像分割定义为一个自适应模块化标记器的角色,这是ViTs中未被充分利用的潜力。

与正方形分割相比,超像素提供了一个机会,通过允许尺度和形状的适应性,同时利用视觉数据中的固有冗余来缓解基于图像块的标记化的缺陷。超像素已被证明与图像中的语义结构更好地对齐,这为在视觉Transformer架构中的潜在用途提供了依据。论文将标准ViTs中的经典正方形标记化与超像素标记化模型(SPiT)进行比较,并使用随机Voronoi标记化(RViT)(明确定义的数学对象,用于镶嵌平面)作为对照,后者因其作为平面镶嵌的数学对象而被选中,三种标记化方案在图1中进行了说明。
Contributions
论文的研究引出了三个具体的问题:(a)对正方形图像块的严格遵守是否必要?(b)不规则分割对标记化表示有什么影响?(c)标记化方案是否可以设计为视觉模型中的一个模块化组件? 经过实验验证,论文得到了以下结论:
Generalized Framework:超像素标记化作为模块化方案中推广到了ViTs,为视觉任务提供更丰富的Transformer空间,其中Transformer主干与标记化框架是独立的。
Efficient Tokenization:提出了一种高效的在线标记化方法,该方法在训练和推理时间上具有竞争力,同时在分类任务中表现出色。
Refined Spatial Resolution:超像素标记化提供了语义对齐的标记,具有像素级的粒度。与现有的可解释性方法相比,论文的方法得到更显著的归因,并且在无监督分割中表现出色。
Visual Tokenization:论文的主要贡献是引入了一种新颖的方法来思考ViTs中的标记化问题,这是建模过程中的一个被忽视但核心的组成部分。
论文的主要目标是评估ViTs的标记化方案,强调不同标记化方法的内在特性。为了进行公平的比较分析,使用基础的ViT架构和既定的训练协议进行研究。因此,论文设计实验以确保与知名基线进行公平比较,且不进行架构优化。这种受控的比较对于将观察到的差异归因于标记化策略至关重要,并消除了特定架构或训练方案带来的混杂因素。
Methodology
为了评估和对比不同的标记化策略,需要对图像进行分割并从这些分割中提取有意义的特征。虽然可以使用多种深度架构来完成这些任务,但这些方法会给最终模型增加一层复杂性,从而使任何直接比较标记化策略的尝试失效。此外,这也会使架构之间的有效迁移学习变得复杂。基于这一原因,论文构建了一个有效的启发式超像素标记化器,并提出了一种与经典ViT架构一致的非侵入性特征提取方法,以便进行直接比较。
- Notation
定义 表示一个空间维度为 的图像的坐标, 并让 为映射 的索引集。将一个 通道的图像视为信号 , 定义向量化操作符 vec: , 并用 表示函数的组合。
Framework
论文通过允许模块化的标记化器和不同的特征提取方法, 来对经典 ViT 架构进行泛化。值得注意的是, 经典的 ViT 通常被呈现为一个由三部分组成的系统, 包括一个标记嵌入器 、一个由一系列注意力块组成的主干网络 , 以及一个后续的预测头 。实际上, 可以将图像块嵌入模块重写为一个由三个部分组成的模块化系统, 包含一个标记化器 、一个特征提取器 和一个嵌入器 , 使得 。

这些是原始架构中的固有组件,但在简化的标记化策略下被掩盖了。这为模型作为一个五部分系统提供了更完整的评估。

其中 表示模型的可学习参数集合。在标准的 ViT 模型中, 标记化器 将图像分割为固定大小的方形区域。这直接提供了向量化的特征, 因为这些图像块具有统一的维度和顺序, 因此在标准的 ViT 架构中, 。嵌入器 通常是一个可学习的线性层, 将特征映射到特定架构的嵌入维度。另一种做法是, 将 视为一个卷积操作, 其卷积核大小和步幅等于所需的图像块大小 。
Partitioning and Tokenization
语言任务中的标记化需要将文本分割为最优信息量的标记,这类似于超像素将空间数据分割为离散的连通区域。层级超像素是一种高度可并行化的基于图的方法,适合用于在线标记化。基于此,论文提出了一种新方法,该方法在每一步中进行批量图片图的完全并行聚合,此外还包括对大小和紧凑性的正则化。在每一步产生不同数量的超像素,动态适应图像的复杂性。

- Superpixel Graphs
设 表示在 下的四向邻接边。将超像素视为一个集合 , 并且如果对于 中的任意两个像素 和 ,存在一个边的序列 ,使得 和 ,则认为 是连通的。如果对于任意两个不同的超像素 和 ,它们的交集 ,并且所有超像素的并集等于图像中所有像素位置的集合,即 ,那么一组超像素就形成了图像的分割 。
设 表示图像的所有分割的空间,并且有一系列分割 。如果对于 中的所有超像素 ,存在一个超像素 使得 ,则认为分割 是另分割 的细化,用 来表示。目标是构造一个像素索引的 级层级分割 , 使得每个超像素都是连通的。
为了构造 , 通过并行边收缩(用一个顶点代替多个顶点, 被代替的点的内部边去掉, 外部边由代替的顶点继承) 的方式逐步连接顶点, 以更新分割 。通过将每个层级视为图 来实现, 其中每个顶点 是分割 中一个超像素的索引,每条边 代表在 层级中相邻的超像素。因此, 初始图像可以表示为一个网格图 , 对应于单像素分割 。
- Weight function
为了应用边收缩, 定义一个边权重函数 。保留图中的自环(超像素包含的节点互指, 合并后表现为超像素指向自身。这里保留自环是因为不一定每一次都需要加入新像素, 自环权重高于其它节点时则不加), 通过相对大小对自环边进行加权作为正则化器, 对区域大小的方差进行约束。对于非自环边, 使用平均特征 并应用相似性函数 作为权重。自环的权重使用在层级 时, 区域大小的特征均值 和特征标准差 进行加权。
整体权重计算如下:

紧凑性可以通过计算无穷范数密度来选择性地进行调节:

其中 是包围超像素 和 的边界栣的周长。这突出了两个相邻的超像素 和 在其边界框内的紧密程度, 从而得出了一个正则化的权重函数。

其中 作为紧凑性的超参数。
- Update rule
使用贪婪的并行更新规则进行边收缩, 使得每个超像素与具有最高边权重的相邻超像素连接, 包括所有 中的自环, 适用于 。设 表示在第 层中索引为 的超像素的相邻顶点的邻域, 构造一个中间边集:

然后, 传递闭包 (传递闭包是指多个二元关系存在传递性, 通过该传递性推导出更多的关系, 比如可从 和 中推导出 , 这里即是 的连通分量) 可明确地得出一个映射 , 使得

其中 表示在 中顶点 的连通分量。这个分区更新规则确保了在 层的每个分区都是一个连通区域, 因为它是通过合并具有最高边权重的相邻超像素形成的, 如图 3 中所示。
- Iterative refinement
重复计算聚合映射、正则化边权重和边收缩的步骤, 直到达到所需的层级数 。在每一层, 分区变得更加粗糙, 表示图像中更大的同质区域。层级结构提供了图像的多尺度表示, 捕捉了局部和全局结构。在第 层, 即可获得一系列分区 , 其中每一层的分区在层级 时是一个连通区域,并且对所有 有 。
在经典的 ViT 分词器中, 论文尝试验证不同的 和图像块大小 分别产生的标记数量之间的关系。设 和 分别表示SPiT 分词器和 ViT 分词器的标记数量, 这种关系为 ,无论图像大小如何。
Feature Extraction with Irregular Patches
虽然ViT架构中选择正方形图像块是出于简洁性的考虑,但这自然也反映了替代方案所带来的挑战。非规则的图像块是不对齐的,表现出不同的形状和维度,并且通常是非凸的(形状非常不规则)。这些因素使得将非规则图像块嵌入到一个共同的内积空间中变得不容易。除了保持一致性和统一的维度外,论文还提出任何此类特征需要捕捉的最小属性集;即颜色、纹理、形状、尺度和位置。
- Positional Encoding
ViTs 通常为图像网格中的每个图像块使用可学习的位置嵌入。论文注意到这对应于下采样图像的位置直方图, 可以通过使用核化方法将可学习的位置嵌入扩展到处理更复杂的形状、尺度和位置,对每个 分区的超像素 的坐标应用联合直方图。首先,将位置归一化, 使得所有 都落在 范围内。设定固定 为每个空间方向上的特征维度, 特征由高斯核 提取:

通常, 带宽 取值较低, 范围为 。这样,实际上就编码了图像块在图像中的位置,以及其形状和尺度。
- Color Features
为了将原始像素数据中的光强信息编码到特征中, 使用双线性插值将每个图像块的边界框插值到固定分辨率 , 同时屏蔽其他周围图像块中的像素信息。这些特征本质上捕捉了原始图像块的原始像素信息, 但经过重采样并缩放到统一的维度。将特征提取器 称为插值特征提取器, RGB 特征也被归一化到 并向量化, 使得 。
- Texture Features
梯度算子提供了一种简单而稳健的纹理信息提取方法。基于改进的旋转对称性和离散化误差, 论文选择使用 Scharr 提出的梯度算子。将该算子归一化, 使得 ,其中最后两个维度对应于梯度方向 和 。与位置特征的处理过程类似, 在每个超像素 内部对梯度应用高斯核构建联合直方图, 使得 。
最终特征模态被拼接为 。虽然论文提出的梯度特征与标准的 ViT 架构相同, 但它们代表了额外的信息维度。因此, 论文评估了包括或省略梯度特征的效果。对于那些省略这些特征的模型, 即 , 称该提取器 为不包括梯度的提取器。
Generalization of Canonical ViT
在设计上, 论文的框架是对标准 ViT 标记化的一个概括, 等同于使用固定图像块大小 和排除梯度的插值特征提取的标准图像块嵌入器。
设 表示一个固定图像块大小 的标准 ViT 标记化器, 表示一个排除梯度的插值特征提取器, 和 表示具有等效线性投影的嵌入层, 其中 。设 表示在 分割下的联合直方图位置嵌入矩阵。那么, 对于维度 , 由 给出的嵌入与由 给出的标准 ViT 嵌入在数量上是等效的。
Experiments and Results





#SAM2Point
3D分割里程碑!SAM2Point联合SAM2,首次实现任意3D场景,任意Prompt的分割!
本文通过SAM 2,首次在3D领域实现Segment Anything的方案,可以zero-shot的泛化到绝大多数3D场景(object, indoor scene, outdoor scene, raw LiDAR),并支持各种3D prompt(3D point, box, mask)。
文章链接:https://arxiv.org/pdf/2408.16768
在线Demo: https://huggingface.co/spaces/ZiyuG/SAM2Point
Code链接:https://github.com/ZiyuGuo99/SAM2Point

图 1 SAM2POINT的分割范式
重点概述:
1.无需投影到2D的SAM 2分割方案:SAM2POINT 通过将 3D 数据体素化为视频格式,避免了复杂的 2D至3D 的投影,实现了高效的零样本 3D 分割,同时保留了丰富的空间信息。
2.支持任意用户提示(Prompt):该方法支持 3D 点、3D框和Mask三种提示类型,实现了灵活的交互式分割, 增强了 3D 分割的精确度和适应性。
3.泛化任何3D场景:SAM2POINT 在多种 3D 场景中表现出优越的泛化能力,包括单个物体、室内场景、室外场景和原始 LiDAR 数据, 显示了良好的跨领域转移能力。
SAM2POINT,是3D可提示分割领域的初步探索,将 Segment Anything Model 2(SAM 2)适配于零样本和可提示的3D分割。SAM2POINT 将任何 3D 数据解释为一系列多方向视频,并利用 SAM2 进行3D空间分割,无需进一步训练或 2D至3D 投影。SAM2POINT框架支持多种提示类型,包括 3D 点、 3D框和3D Mask,并且可以在多种不同场景中进行泛化,例如 3D 单个物体、室内场景、室外场景和原始激光雷达数据( LiDAR)。在多个3D 数据集上的演示,如 Objaverse、S3DIS、ScanNet、Semantic3D 和 KITTI,突出了 SAM2POINT 的强大泛化能力。据我们所知,这是SAM在3D中最忠实的实现,可能为未来可提示的3D分割研究提供一个起点。
SAM2Point的动机与方法创新
Segment Anything Model(SAM)已经建立了一个卓越且基础的交互式图像分割框架。基于其强大的迁移能力,后续研究将SAM扩展到多样的视觉领域,例如个性化物体、医学影像和时间序列。更近期的Segment Anything Model 2(SAM 2)提出了在视频场景中的印象深刻的分割能力,捕捉复杂的现实世界动态。

表 1:SAM2POINT与以往基于SAM的3D分割方法的比较。SAM2POINT是SAM在3D中最忠实的实现,展示了在3D分割中的卓越实施效率、可提示的灵活性和泛化能力。
尽管如此,如何有效地将SAM适应于3D分割仍然是一个未解决的挑战。表1列举了前期工作的主要问题,这些问题阻碍了充分利用SAM的优势:
2D到3D投影的效率低。 考虑到2D和3D之间的领域差距,大多数现有工作将3D数据表示为其2D对应输入给SAM,并将分割结果反向投影到3D空间,例如使用额外的RGB图像、多视图渲染或神经辐射场。这种模态转换引入了显著的处理复杂性,阻碍了有效的实施。
3D空间信息的退化。 依赖2D投影导致了精细的3D几何形态和语义的丢失,多视图数据常常无法保留空间关系。此外,3D物体的内部结构不能被2D图像充分捕获,显著限制了分割精度。
提示灵活性的丧失。 SAM的一个引人注目的优点是通过各种提示替代品的交互能力。不幸的是,这些功能在当前方法中大多被忽视,因为用户难以使用2D表示来精确指定3D位置。因此,SAM通常用于在整个多视图图像中进行密集分割,从而牺牲了交互性。
有限的领域迁移能力。 现有的2D-3D投影技术通常是为特定的3D场景量身定制的,严重依赖于领域内的模式。这使得它们难以应用于新的环境,例如从物体到场景或从室内到室外环境。另一个研究方向旨在从头开始训练一个可提示的3D网络。虽然绕过了2D投影的需要,但它需要大量的训练和数据资源,可能仍受训练数据分布的限制。
相比之下,SAM2POINT将SAM 2适应于高效、无投影、可提示和零样本的3D分割。 作为这一方向的初步步骤,SAM2POINT的目标不在于突破性能极限,而是展示SAM在多种环境中实现强大且有效的3D分割的潜力。
效果展示
图2-图7展示了 SAM2POINT 在使用不同 3D 提示对不同数据集进行 3D 数据分割的演示,其中3D提示用红色表示,分割结果用绿色表示:

图2 使用SAM2POINT在Objaverse数据集上进行3D物体分割

图3 使用SAM2POINT在S3DIS数据集上进行3D室内场景分割

图4 使用SAM2POINT在ScanNet数据集上进行3D室内场景分割

图5 使用SAM2POINT在Semantic3D数据集上进行3D室外场景分割

图 6使用SAM2POINT在KITTI上进行3D原始激光雷达数据分割
SAM2Point的3D物体的多方向视频:
SAM2Point的3D室内场景多方向视频:
SAM2Point的3D室外场景多方向视频:
SAM2Point的3D原始激光雷达的多方向视频:
SAM2POINT方法详述
SAM2POINT 的详细方法如下图所示。下面介绍了 SAM2POINT 如何高效地处理 3D 数据以适配 SAM 2, 从而避免复杂的投影过程。接下来, 以及详细说明了支持的三种 3D 提示类型及其相关的分割技术。最后, 展示了 SAM2POINT 有效解决的四种具有挑战性的 3D 场景。

图8 SAM2POINT的具体方法
3D 数据作为视频
对于任何物体级或场景级的点云, 用 表示, 每个点为 。本文的目标是将 转换为一种数据格式, 这种格式一方面能使 SAM 2 以零样本的方式直接处理, 另一方面能够很好地保留细粒度的空间几何结构。为此, SAM2Point 采用了 3D 体素化技术。与 RGB 图像映射、多视角渲染和 和神经辐射场(NeRF)等先前工作相比,体素化在 3D 空间中的执行效率更高,且不会导致信息退化和繁琐的后处理。
通过这种方式, 获得了 3D 输入的体素化表示, 记作 , 每个体素为 。为了简化, 值根据距离体素中心最近的点设置。这种格式与形状为 的视频非常相似。主要区别在于, 视频数据包含在 t 帧之间的单向时间依赖性, 而 3D 体素在三个空间维度上是各向同性的。考虑到这一点, SAM2Point 将体素表示转换为一系列多方向的视频, 从而启发 SAM 2 以与处理视频相同的方式来分割 3D 数据。
可提示分割
为了实现灵活的交互性, SAM2POINT 支持三种类型的 3D 提示, 这些提示可以单独或联合使用。以下详细说明提示和分割细节:
- 3D 点提示, 记作 。首先将 视为 3D 空间中的针点, 以定义三个正交的 2D 截面。从这些截面开始, 我们沿六个空间方向将 3D 体素分为六个子部分, 即前、后、左、右、上和下。接着, 我们将它们视为六个不同的视频,其中截面作为第一帧, 被投影为 2D 点提示。应用 SAM 2 进行并行分割后,将六个视频的结果整合为最终的 3D mask 预测。
- 3D 框提示, 记作 ,包括 3D 中心坐标和尺寸。我们采用 的几何中心作为针点,并按照上述方法将 3D 体素表示为六个不同的视频。对于某一方向的视频, 我们将 投影到相应的 2D 截面,作为分割的框点。我们还支持具有旋转角度的 3D 框,例如 ,对于这种情况,采用投影后的 的边界矩形作为 2D 提示。
- 3D mask提示,记作,其中 1 或 0 表示mask区域和非mask区域。使用mask提示的质心作为锚点,同样将3D空间分为六个视频。3D mask提示与每个截面的交集被用作 2D mask提示进行分割。这种提示方式也可以作为后期精炼步骤, 以提高先前预测的 3D mask的准确性。
任意3D场景
通过简洁的框架设计,SAM2POINT在不同领域表现出卓越的零样本泛化性能,涵盖从物体到场景,从室内到室外环境。以下详细介绍四种不同的 3D 场景:
- 3D 单个物体, 如 Objaverse, 拥有广泛的类别, 具有不同实例的独特特征, 包括颜色、形状和几何结构。对象的相邻组件可能会重叠、遮挡或与彼此融合, 这要求模型准确识别细微差别以进行部分分割。
- 3D室内场景, 如 S3DIS和 ScanNet, 通常以多个物体在有限空间内(如房间)排列的特点为主。复杂的空间布局、外观相似性以及物体之间不同的方向性,为模型从背景中分割物体带来挑战。
- 3D 室外场景, 如 Semantic3D, 与室内场景主要不同在于物体(建筑、车辆和人)之间的明显大小对比以及点云的更大规模(从一个房间到整条街道)。这些变化使得无论是全局还是细粒度层面的物体分割都变得复杂。
- 原始激光雷达数据(LIDAR), 例如用于自动驾驶的KITTI(Geiger等人,2012),与典型点云不同,其特点是稀疏分布和缺乏RGB信息。稀疏性要求模型推断缺失的语义以理解场景,而缺乏颜色则强迫模型只依靠几何线索来区分物体。在SAM2POINT中,我们直接根据激光雷达的强度设置3D体素的RGB值。
讨论与洞察
基于SAM2POINT的有效性,文章深入探讨了3D领域中两个引人注目但具有挑战性的问题,并分享了作者对未来多模态学习的见解。
如何将2D基础模型适应到3D?
大规模高质量数据的可用性显著促进了语言和视觉-语言领域大型模型的发展。相比之下,3D领域长期以来一直面临数据匮乏的问题,这阻碍了大型3D模型的训练。因此,研究人员转而尝试将预训练的2D模型转移到3D中。
主要挑战在于桥接2D和3D之间的模态差距。如PointCLIP V1及其V2版本和后续方法等开创性方法,将3D数据投影成多视角图像,这遇到了实施效率低和信息丢失的问题。另一条研究线,包括ULIP系列、I2P-MAE及其他,采用了使用2D-3D配对数据的知识蒸馏。虽然这种方法由于广泛的训练通常表现更好,但在非域场景中的3D迁移能力有限。
近期的努力还探索了更复杂且成本更高的解决方案,例如联合多模态空间(例如Point-Bind & Point-LLM),大规模预训练(Uni3D)和虚拟投影技术(Any2Point)。
从SAM2POINT我们观察到,通过体素化将3D数据表示为视频可能提供了一个最佳解决方案,提供了性能和效率之间的平衡折衷。这种方法不仅以简单的转换保留了3D空间中固有的空间几何形状,还呈现了一种2D模型可以直接处理的基于网格的数据格式。尽管如此,仍需要进一步的实验来验证并加强这一观察。
SAM2POINT在3D领域的潜力是什么?
SAM2POINT展示了SAM在3D中最准确和全面的实现,成功继承了其实施效率、可提示的灵活性和泛化能力。虽然之前基于SAM的方法已经实现了3D分割,但它们在可扩展性和迁移到其他3D任务的能力方面往往表现不足。相比之下,受到2D领域SAM的启发,SAM2POINT展现了推进各种3D应用的重大潜力。
对于基本的3D理解,SAM2POINT可以作为一个统一的初始化主干,进一步微调,同时为3D物体、室内场景、室外场景和原始激光雷达提供强大的3D表示。在训练大型3D模型的背景下,SAM2POINT可以作为自动数据标注工具,通过在不同场景中生成大规模分割标签来缓解数据稀缺问题。对于3D和语言视觉学习,SAM2POINT天生提供了一个跨2D、3D和视频领域的联合嵌入空间,由于其零样本能力,这可能进一步增强模型的效果,如Point-Bind。此外,在开发3D大语言模型(LLMs)的过程中,SAM2POINT可以作为一个强大的3D编码器,为LLMs提供3D Tokens,并利用其可提示的特征为LLMs装备可提示的指令遵循能力。
总结
SAM2Point, 利用 Segment Anything 2 (SAM 2) 实现了零样本和可提示的3D分割框架。通过将 3D 数据表示为多方向视频, SAM2POINT 支持多种类型的用户提供的提示 (3D 点、3D框和3D mask), 并在多种 3D 场景(3D 单个物体、室内场景、室外场景和原始稀疏激光雷达)中展现出强大的泛化能力。作为一项初步探索,SAM2POINT为有效和高效地适应SAM 2以理解3D提供了独特的见解。希望SAM2Point能成为可提示3D分割的基础基准,鼓励进一步的研究,以充分利用SAM 2在3D领域的潜力。
#CPRFL
基于CLIP的新方案,破解长尾多标签分类难题
本文提出了一种新颖的提示学习方法,称为类别提示精炼特征学习(CPRFL),用于长尾多标签图像分类(LTMLC)。这是首次利用类别语义关联来缓解LTMLC中的头尾不平衡问题,提供了一种针对数据特征量身定制的开创性解决方案。
现实世界的数据通常表现为长尾分布,常跨越多个类别。这种复杂性突显了内容理解的挑战,特别是在需要长尾多标签图像分类(LTMLC)的场景中。在这些情况下,不平衡的数据分布和多物体识别构成了重大障碍。为了解决这个问题,论文提出了一种新颖且有效的LTMLC方法,称为类别提示精炼特征学习(CPRFL)。该方法从预训练的CLIP嵌入初始化类别提示,通过与视觉特征的交互解耦类别特定的视觉表示,从而促进了头部类和尾部类之间的语义关联建立。为了减轻视觉-语义领域的偏差,论文设计了一种渐进式双路径反向传播机制,通过逐步将上下文相关的视觉信息纳入提示来精炼提示。同时,精炼过程在精炼提示的指导下促进了类别特定视觉表示的渐进纯化。此外,考虑到负样本与正样本的不平衡,采用了非对称损失作为优化目标,以抑制所有类别中的负样本,并可能提升头部到尾部的识别性能。

论文地址:https://arxiv.org/abs/2408.08125
论文代码:https://github.com/jiexuanyan/CPRFL
Introduction
随着深度网络的快速发展,近年来计算机视觉领域取得了显著的进展,尤其是在图像分类任务中。这一进展在很大程度上依赖于许多主流的平衡基准(例如CIFAR、ImageNet ILSVRC、MS COCO),这些基准具有两个关键特征:1)它们提供了在所有类别之间相对平衡且数量充足的样本,2)每个样本仅属于一个类别。然而,在实际应用中,不同类别的分布往往呈现长尾分布模式,深度网络往往在尾部类别上表现不佳。同时,与经典的单标签分类不同,实际场景中图像通常与多个标签相关联,这增加了任务的复杂性和挑战。为了应对这些问题,越来越多的研究集中在长尾多标签图像分类(LTMLC)问题上。
由于尾部类别的样本相对稀少,解决长尾多标签图像分类(LTMLC)问题的主流方法主要集中在通过采用各种策略来解决头部与尾部的不平衡问题,例如对每个类别的样本数量进行重采样、为不同类别重新加权损失、以及解耦表示学习和分类头的学习。尽管这些方法做出了重要贡献,但它们通常忽略了两个关键方面。首先,在长尾学习中,考虑头部和尾部类别之间的语义相关性至关重要。利用这种相关性可以在头部类别的支持下显著提高尾部类别的性能。其次,实际世界中的图像通常包含多种对象、场景或属性,这增加了分类任务的复杂性。上述方法通常从全局角度考虑提取图像的视觉表示。然而,这种全局视觉表示包含了来自多个对象的混合特征,这阻碍了对每个类别的有效特征分类。因此,如何在长尾数据分布中探索类别之间的语义相关性,并提取局部类别特定特征,仍然是一个重要的研究领域。
最近,视觉-语言预训练(VLP)模型已成功适应于各种下游视觉任务。例如,CLIP在数十亿对图像-文本样本上进行预训练,其文本编码器包含了来自自然语言处理(NLP)语料库的丰富语言知识。文本编码器在编码文本模态中的语义上下文表示方面展示了巨大的潜力。因此,可以利用CLIP的文本嵌入表示来编码头部和尾部类别之间的语义相关性。此外,在许多研究中,CLIP的文本嵌入已成功作为语义提示,用于将局部类别特定的视觉表示与全局混合特征解耦。
为了应对长尾多标签分类(LTMLC)固有的挑战,论文提出了一种新颖且有效的方法,称为类别提示精炼特征学习(Category-Prompt Refined Feature Learning,CPRFL)。CPRFL利用CLIP的文本编码器的强大的语义表示能力提取类别语义,从而建立头部和尾部类别之间的语义相关性。随后,提取的类别语义用于初始化所有类别的提示,这些提示与视觉特征交互,以辨别与每个类别相关的上下文视觉信息。
这种视觉-语义交互可以有效地将类别特定的视觉表示从输入样本中解耦,但这些初始提示缺乏视觉上下文信息,导致在信息交互过程中语义和视觉领域之间存在显著的数据偏差。本质上,初始提示可能不够精准,从而影响类别特定视觉表示的质量。为了解决这个问题,论文引入了一种渐进式双路径反向传播(progressive Dual-Path Back-Propagation)机制来迭代精炼提示。该机制逐步将与上下文相关的视觉信息积累到提示中。同时,在精炼提示的指导下,类别特定的视觉表示得到净化,从而提高其相关性和准确性。
最后,为了进一步解决多类别中固有的负样本与正样本不平衡问题,论文引入了在这种情况下常用的重新加权(Re-Weighting,RW)策略。具体来说,采用了非对称损失(Asymmetric Loss,ASL)作为优化目标,有效抑制了所有类别中的负样本,并可能改善LTMLC任务中头部与尾部类别的性能。
论文贡献总结如下:
提出了一种新颖的提示学习方法,称为类别提示精炼特征学习(CPRFL),用于长尾多标签图像分类(LTMLC)。CPRFL利用CLIP的文本编码器提取类别语义,充分发挥其强大的语义表示能力,促进头部和尾部类别之间的语义关联的建立。提取的类别语义作为类别提示,用于实现类别特定视觉表示的解耦。这是首次利用类别语义关联来缓解LTMLC中的头尾不平衡问题,提供了一种针对数据特征量身定制的开创性解决方案。
设计了一种渐进式双路径反向传播机制,旨在通过在视觉-语义交互过程中逐步将与上下文相关的视觉信息融入提示中,从而精炼类别提示。通过采用一系列双路径梯度反向传播,有效地抵消了初始提示带来的视觉-语义领域偏差。同时,精炼过程促进了类别特定视觉表示的逐步净化。
在两个LTMLC基准测试上进行了实验,包括公开可用的数据集COCO-LT和VOC-LT。大量实验不仅验证了方法的有效性,还突显了其相较于最近先进方法的显著优越性。
MethodsOverview

CPRFL方法包括两个子网络,即提示初始化(PI)网络和视觉-语义交互(VSI)网络。首先,利用预训练的CLIP的文本嵌入来初始化PI网络中的类别提示,利用类别语义编码不同类别之间的语义关联。随后,这些初始化的提示通过VSI网络中的Transformer编码器与提取的视觉特征进行交互。这个交互过程有助于解耦类别特定的视觉表示,使框架能够辨别与每个类别相关的上下文相关的视觉信息。最后,在类别层面计算类别特定特征与其对应提示之间的相似性,以获得每个类别的预测概率。为了减轻视觉-语义领域偏差,采用了一个逐步的双路径反向传播机制,由类别提示学习引导,以细化提示并在训练迭代中逐步净化类别特定的视觉表示。为进一步解决负样本与正样本的不平衡问题,采用了重加权策略(即非对称损失(ASL)),这有助于抑制所有类别中的负样本。
Feature Extraction
给定来自数据集 的输入图像 , 首先利用一个主干网络提取局部图像特征 , 其中 分别表示通道数、高度和宽度。论文采用了如 ResNet-101 的卷积网络, 并通过去除最后的池化层来获取局部特征。之后, 添加一个线性层 , 将特征从维度 映射到维度 , 以便将其投影到一个视觉-语义联合空间, 从而匹配类别提示的维度:

利用局部特征,我们在它们与初始类别提示之间进行视觉-语义信息交互,以辨别类别特定的视觉信息。
Semantic Extraction
形式上, 预训练的 CLIP 包括一个图像编码器 和一个文本编码器 。为了论文的目的, 仅利用文本编码器来提取类别语义。具体来说, 采用一个经典的预定义模板 " a photo of a [ CLASS ]" 作为文本编码器的输入文本。然后, 文本编码器将输入文本(类别 , 映射到文本嵌入 , 其中 表示类别数, 表示嵌入的维度长度。提取的文本嵌入作为初始化类别提示的类别语义。
Category-Prompt Initialization
为了弥合语义领域和视觉领域之间的差距,近期的研究尝试使用线性层将语义词嵌入投影到视觉-语义联合空间。论文选择了非线性结构来处理来自预训练CLIP文本嵌入的类别语义,而不是直接使用线性层进行投影。这种方法能够实现从语义空间到视觉-语义联合空间的更复杂的投影。
具体来说, 论文设计了一个提示初始化(PI)网络, 该网络由两个全连接层和一个非线性激活函数组成。通过 PI 网络执行的非线性变换, 将预训练 CLIP 的文本嵌入 映射到初始类别提示 :

其中, 、、 和 分别表示两个线性层的权重矩阵和偏置向量, 而 表示非线性激活函数。这里, 是控制隐藏层维度的扩展系数。通常情况下, 被设置为 0.5 。
PI网络在从预训练CLIP的文本编码器中提取类别语义方面发挥了至关重要的作用,利用其强大的语义表示能力,在不依赖真实标签的情况下建立不同类别之间的语义关联。通过用类别语义初始化类别提示,PI网络促进了从语义空间到视觉-语义联合空间的投影。此外,PI网络的非线性设计增强了提取类别提示的视觉-语义交互能力,从而改善了后续的视觉-语义信息交互。
Visual-Semantic Information Interaction
随着Transformer在计算机视觉领域的广泛应用,近期的研究展示了典型注意力机制在增强视觉-语义跨模态特征交互方面的能力,这激励论文设计了一个视觉-语义交互(VSI)网络。该网络包含一个Transformer编码器,以初始类别提示和视觉特征作为输入。Transformer编码器执行视觉-语义信息交互,以辨别与每个类别相关的上下文特定视觉信息。这个交互过程有效地解耦了类别特定的视觉表示,从而促进了每个类别的更好特征分类。
为了促进类别提示与视觉特征之间的视觉-语义信息交互, 将初始类别提示 与视觉特征 进行连接, 形成一个组合嵌入集 , 输入到VSI 网络中进行视觉-语义信息交互。在 VSI 网络中, 每个嵌入 通过 Transformer 编码器固有的多头自注意力机制进行计算和更新。值得注意的是, 仅关注更新类别提示 , 因为这些提示代表了类别特定视觉表示的解耦部分。注意力权重 和随后的更新过程计算如下:

其中, 分别是查询、键和值的权重矩阵, 是变换矩阵, 是偏置向量。为了简化 VSI 网络的复杂度, 选择了单层 Transformer 编码器而不是堆叠层。VSI 网络的输出结果和类别特定的视觉特征分别记作 和 。在自注意力机制下, 每个类别提示嵌入综合考虑了其对所有局部视觉特征和其他类别提示嵌入的注意力。这种综合注意力机制有效地辨别了样本中的上下文相关视觉信息,从而实现了类别特定视觉表示的解耦。
Category-Prompt Refined Feature Learning
在通过 VSI 网络实现视觉特征与初始提示的交互后, 得到的输出 作为分类的类别特定特征。在传统的基于 Transformer 的方法中, 从 Transformer 获得的具体输出特征通常通过线性层投影到标签空间, 用于最终分类。与这些方法不同, 将类别提示 作为分类器, 并计算类别特定特征与类别提示之间的相似性, 以在特征空间内进行分类。类别 的分类概率 可以通过以下计算:

在多标签设置中,由于数据特性的独特性,需要计算每个类别的类别特定特征向量与相应提示向量之间的点积相似度来确定概率(softmax一下),这种计算方法体现了绝对相似性。而论文偏离了传统的相似性模式,而是使用类别特定特征向量与所有提示向量之间的相对测量。这种做法的原因在于减少了计算冗余,因为计算每个类别的特征向量与无关类别提示之间的相似度是不必要的。

初始提示缺乏关键的视觉上下文信息,导致在信息交互过程中语义域与视觉域之间存在显著的数据偏差。这种差异导致初始提示不准确,从而影响类别特定视觉表示的质量。为了解决这个问题,论文引入了一种由类别提示学习引导的渐进式双路径反向传播机制。该机制在模型训练过程中涉及两个梯度优化路径(如图2a所示):一条通过VSI网络,另一条直接到PI网络。前者路径还优化VSI网络,以增强其视觉语义信息交互的能力。通过采用一系列双路径梯度反向传播,提示在训练迭代中逐渐得到优化,从而逐步积累与上下文相关的视觉信息。同时,优化后的提示指导生成更准确的类别特定视觉表示,从而实现类别特定特征的渐进净化。论文将这一整个过程称为“提示精炼特征学习”,反复进行直到收敛,如图2b所示。
Optimization
为了进一步解决多类别中固有的负样本与正样本不平衡问题, 论文整合了在这种情况下常用的重新加权(Re-Weighting, RW)策略。具体而言, 采用不对称损失 (Asymmetric Lo ss, ASL ) 作为优化目标。ASL 是一种焦点损失 ( focal loss) 的变体, 对正样本和负样本使用不同的 值。给定输入图像 , 模型预测其最终类别概率 , 其真实标签为 。
使用ASL训练整个框架,如下所示:

其中, 是类别的数量。 是 ASL 中的硬阈值, 表示为 。 是一个用于过滤低置信度负样本的阈值。默认情况下, 设置 和 。在论文的框架中, ASL 有效地抑制了所有类别中的负样本, 可能改善了 LTMLC 任务中的头尾类别性能。
Experiments



#Vec2Face
首次!用合成的人脸数据集训练的识别模型性能高于真实数据集
此工作提出的Vec2Face模型首次实现了从特征向量生成图片的功能,并且向量之间的关系,如相似度,和向量包含的信息,如ID和人脸属性,在生成的图片上也会得到继承。
1. 亮点
- 此工作提出的Vec2Face模型首次实现了从特征向量生成图片的功能,并且向量之间的关系,如相似度,和向量包含的信息,如ID和人脸属性,在生成的图片上也会得到继承。
- Vec2Face模型可以用于生成大型人脸识别训练集 (300k个ID和15M张图片),并且精度有进一步的提升。
- 用Vec2Face生成的HSFace10k训练的模型,首次在人脸识别的年龄测试集 (CALFW) 上实现了性能超越同尺度的真实数据集 (CASIA-WebFace[1])。另外,当合成数据集的ID数量大于100k后,训练的人脸识别模型在毛发测试集 (Hadrian) 和曝光度测试集 (Eclipse) 上也同样超越了 CASIA-WebFace。
论文链接: https://arxiv.org/abs/2409.02979
代码链接: https://github.com/HaiyuWu/Vec2Face
Demo链接: https://huggingface.co/spaces/BooBooWu/Vec2Face
1. 研究动机
一个高质量的人脸识别训练集要求ID有高的分离度(Inter-class separability)和类内的变化度(Intra-class variation)。然而现有的方法普遍存在两个缺点:1)实现了大的intra-class variation,但是inter-class separability很低,2)实现了较高的inter-class separability,但是intra-class variation需要用额外的模型来提高。这两点要么使得在合成的人脸数据集训练的模型性能表现不佳(见 Table 1 基于GAN的方法),要么难以合成大型数据集(见 Table 3)。因此,我们通过让提出的Vec2Face模型学习如何将特征向量转化为对应的图片,并且在生成时对随机采样的向量加以约束,来实现高质量训练集的生成。这一方法不但可以轻松控制inter-class separability和intra-class variation,而且无需额外的模型进行辅助。此外,这一方法还可以用来生成大型训练集。
在性能上,我们生成的0.5M图片规模的训练集在5个测试集(LFW, AgeDB-30, CFP-FP, CALFW和CPLFW)上实现了state-of-the-art的平均精度(92%),并且在CALFW上超越了真实数据集(CASIA-WebFace)的精度,见Table 1。当我们将数据集规模提升到15M的时候,精度达到了93.52%(见Table 2)。
2. Vec2Face训练和生成方法Vec2Face训练
数据集:从WebFace4M[2]中随机抽取的5万个人的图片。

statistical_information
为了让模型充分理解特征向量里的信息,我们的输入仅有用预训练的人脸识别模型提取出来的特征向量(IM feature)。随后将由特征向量扩展后的特征图(Feature map)输入到feature masked autoencoder(fMAE)里来获取能够解码成图片的特征图。最后用一个图片解码器(Image decoder)来生成图片。整个训练目标由4个损失函数组成。
用于缩小合成图()和原图()之间的差异:

用于缩小合成图和原图对于人脸识别模型的相似度:

感知损失[3]和GAN损失 用于提高合成图的图片质量。我们使用patch-based discriminator[4,5]来组成GAN范式训练.
生成
因为Vec2Face仅需输入特征向量(512-dim)来生成人脸图片并且能够保持ID和部分人脸属性的一致,所以仅需采样ID vector并确保 即可保证生成的数据集的inter-class separability。至于intra-class variation,我们仅需在ID vector加上轻微的扰动 就能够在ID一致的情况下实现图片的多样性。
然而,由于在训练集里的大部分图像的头部姿态都是朝前的(frontal),这使得增加随机扰动很难生成大幅度的头部姿态(profile)。因此,我们提出了Attribute Operation(AttrOP)算法。它通过梯度下降的方法调整ID vector里的数值来使得生成的人脸拥有特定的属性。

Eq. 5:

3. 实验性能对比
我们在5个常用的人脸识别测试集,LFW[6],CFP-FP[7],AgeDB[8],CALFW[9],CPLFW[10],上和现有的合成数据集进行对比。使用的损失函数是ArcFace[11],网络是SE-IResNet50[12]。

Table 1: Comparison of existing synthetic datasets on five real-world test sets. †, *, and ◊ represent diffusion, 3D rendering, and GAN approaches, respectively, for constructing these datasets. We also list the results of training on a real-world dataset CASIA-WebFace.
结果总结如下:1)Vec2Face生成的HSFace10K数据集达到了state-of-the-art的平均精度;2)HSFace10K首次实现了,在同等数据规模下,在CALFW上的精度超越了真实数据集;3)HSFace10K首次实现了GAN范式训练超越其他范式。
扩大数据集规模的有效性
我们将HSFace数据集的规模从0.5M扩大到了15M,达到了现有最大人脸合成训练集的12.5倍。这也使平均精度提高了1.52%。同时,添加了HSFace10K的数据后,CASIA-WebFace数据集在最终的平均识别精度上提高了0.71%。

Table 2: Impact of scaling the proposed HSFace dataset to 1M images (20K IDs), 5M images (100K IDs), 10M images (200K IDs), 15M images (300K IDs). Continued improvement is observed. We also list the performance obtained by training on the real-world dataset CASIA-WebFace and its combination with HSFace10K. The latter combination yields even higher accuracy.
计算资源对比
我们与Arc2Face,state-of-the-art模型,进行了计算资源上的对比。首先Arc2Face的模型是Vec2Face的5倍。其次,Arc2Face在使用LCM-LoRA的前提下,Vec2Face在一个Titan-Xp GPU上速度达到了Arc2Face的311倍。最后,Vec2Face在重建LFW (in-the-wild)和Hadrian(indoor)图片上也实现了更好的FID。

Table 3: Computing cost and FID measurement of Arc2Face and Vec2Face.
其他实验
AttrOP的影响

衡量现有合成数据集的ID分离度

扰动采样中 对于精度的影响

ID分离度对于精度的影响 (Avg. ID sim越大,分离度越小)

在其他识别测试集上HSFace和CASIA-WebFace的性能对比

#mPLUG-DocOwl2
OCR-free多页文档理解新SOTA,单页视觉token仅324!
为了进行不依赖OCR的文档图片理解,目前多模态大模型主要通过增加图片的分辨率来提升文档问答的性能。然而,不断增加的图片分辨率也导致了视觉编码的token数量显著增加,一张A4大小的文档图片在LLM端往往消耗掉上千的token数量。这不仅导致了过高的显存占用,也大大增加了首包的时间,严重限制了其在多页文档理解方面的应用。
为了平衡多页文档理解场景中的问答效果和资源消耗,阿里巴巴通义实验室mPLUG团队近期提出mPLUG-DocOwl2(mPLUG-DocOwl2: High-resolution Compressing for OCR-free Multi-page Document Understanding),具备多页文字解析,多页文档问答以及多页论文结构解析等能力,在多页文档理解benchmark上达到OCR-free的新SOTA,并且每页文档图片仅消耗324token,首包时间降低50%,单个A100-80G最多能放下60张高清文档图片。
论文链接: https://arxiv.org/abs/2409.03420
代码链接: https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl2

模型结构
NLP领域对于文本总结和压缩已经有了很多研究。考虑到文档图片的主要信息都是布局和文字信息,且现有的多模态大模型普遍通过一个vision-to-text模块将视觉特征映射到语言特征空间,作者提出文档图片特征在和大模型特征空间对齐之后,也可以像文本特征一样进行压缩同时保留住布局信息和文字信息。
为此,在已有多模态大模型结构的基础上,作者提出一个高分辨率文档图片压缩模块High-resolution DocCompressor缩减视觉特征的token数量。DocOwl2模型整体结构如下图所示:

模型整体延续了DocOwl 1.5的结构,对于每一张高清文档图片会采用Shape-adaptive Cropping模块进行切片,同时将原图放缩为一个低分辨率全局图,随后每个切片和全局图会单独经过High-resolution Visual Encoding进行编码,包括ViT提取特征,以及H-Reducer水平合并4个特征并将纬度对齐到LLM。之后,DocOwl2采用High-resolution DocCompressor对视觉特征进行压缩。
考虑到同一个布局单元的文字信息语义连贯,更容易进行语义总结,作者希望进行文档图片特征压缩的时候以布局相关特征作为指导。低分辨率全局图上文字难以辨认但布局信息得到保留,因此作者采用低分辨率的全局图片特征作为压缩指导(query),以高分辨率切片特征作为压缩对象(key/value),通过cross-attention进行压缩。
此外,低分辨率全局图片的每一个特征只编码了部分区域的布局信息,如果让每个低分辨率特征都关注所有高分辨率特征不仅增加压缩难度,而且大大增加了计算复杂度。
为此,作者对于每一个query都从切片特征中挑选了相对位置一致的一组高分辨率特征作为压缩对象,其数量和切片的数量一致,并可能来自不同的切片。经过该压缩模块之后,任意形状的文档图片的token数量都缩减为了全局图片的token数量。DocOwl2的单个切片以及全局图片都采用了504x504的分辨率,因此,最终单个文档图片的token数量为(504x504)/(14x14)/4=324个。
模型训练
DocOwl2由3个阶段进行训练:单页预训练,多页预训练,以及多任务指令微调。
为了充分训练模型对于文档图片的压缩以及信息的保留能力,单页预训练采用了DocOwl1.5的结构化解析数据DocStruct4M,其任务为输入文档图片,解析出图片中所有的文字信息。
之后,为了训练模型区分多页文档特征的能力,多页预训练阶段设计了Multi-page Text Parsing任务和Multi-page Text Lookup任务。前者对于多页文档图片,要求模型解析指定的1-2页的文字内容,后者则给定文字内容,要求模型给出文字所在的页码。
经过两轮预训练之后,作者整合了单页文档理解和多页文档理解的问答数据进行联合训练。即包含简洁回复,又包含给出具体解释和答案依据的指令微调数据。
实验结果
DocOwl2在以更少视觉token、更快的首包时间的前提下达到了多页文档理解的SOTA效果。

同时,在单页文档理解任务上,相比相似训练数据和模型结构的DocOwl1.5,DocOwl2缩减了>80%的token,维持了>90%的性能。即使相比当下最优的MLLM,DocOwl2也在常见的单页数据集(DocVQA, ChartQA, TextVQA)上以更少的token和更快的首包时间的前提下达到了>80%的性能。

从样例中可以看出,对于A4大小的文档图片,即使只用324个token编码,DocOwl2依然能够清晰的识别图片中的文字。

对于文档问答,模型不仅能给出答案,还能给出详细的解释以及相关的页码。

除了文档,DocOwl2也能理解文字丰富的新闻视频。
总结
mPLUG-DocOwl 2聚焦多页文档理解,在大幅缩减单页视觉token的前提下实现了多页文档理解的SOTA效果,兼顾效果和效率,验证了当下多模态大模型对于文档图片的视觉表征存在冗余和资源的浪费。
mPLUG团队会持续优化DocOwl在多页文档理解上的能力并进行开源,同时希望更多的研究人员关注到多模态大模型对于高清文档图片的冗余编码问题
#梯度下降是门手艺活
梯度下降法作为大家耳熟能详的优化算法,极易理解。但虽然和的一些方法比起来在寻找优化方向上比较轻松,可是这个步长却需要点技巧。本文作者通过简单的函数举例说明梯度下降中容易出现的问题。
机器学习所涉及的内容实在是太多了,于是我决定挑个软柿子捏起,从最基础的一个优化算法开始聊起。这个算法就是梯度下降法,英文Gradient Descent。
什么是梯度下降法
作为大众耳熟能详的优化算法,梯度下降法受到的关注不要太多。梯度下降法极易理解,但凡学过一点数学的童鞋都知道,梯度方向表示了函数增长速度最快的方向,那么和它相反的方向就是函数减少速度最快的方向了。对于机器学习模型优化的问题,当我们需要求解最小值的时候,朝着梯度下降的方向走,就能找到最优值了。
那么具体来说梯度下降的算法怎么实现呢?我们先来一个最简单的梯度下降算法,最简单的梯度下降算法由两个函数,三个变量组成:
函数1:待求的函数
函数2:待求函数的导数
变量1:当前找到的变量,这个变量是“我们认为”当前找到的最好的变量,可以是函数达到最优值(这里是最小值)。
变量2:梯度,对于绝大多数的函数来说,这个就是函数的负导数。
变量3:步长,也就是沿着梯度下降方向行进的步长。也是这篇文章的主角。
我们可以用python写出一个最简单的梯度下降算法:
def gd(x_start, step, g): # gd代表了Gradient Descent
x = x_start
for i in range(20):
grad = g(x)
x -= grad * step
print '[ Epoch {0} ] grad = {1}, x = {2}'.format(i, grad, x)
if abs(grad) < 1e-6:
break;
return x
关于python的语法在此不再赘述了,看不懂得童鞋自己想办法去补课吧。优雅的步长
好了,算法搞定了,虽然有点粗糙,但是对于一些问题它是可以用的。我们用一个简单到爆的例子来尝试一下:
def f(x):
return x * x - 2 * x + 1
def g(x):
return 2 * x - 2这个函数f(x)就是大家在中学喜闻乐见的,大家一眼就可以看出,最小值是x=1,这是函数值为0。为了防止大家对这个函数没有感觉(真不应该没感觉啊……)我们首先把图画出来看一下:
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-5,7,100)
y = f(x)
plt.plot(x, y)
然后我们就看到了:
一个很简单的抛物线的函数有木有?x=1是最小点有木有?
来让我用梯度下降法计算一下:
gd(5,0.1,g)
于是我们得到了下面的输出:[ Epoch 0 ] grad = 8, x = 4.2
[ Epoch 1 ] grad = 6.4, x = 3.56
[ Epoch 2 ] grad = 5.12, x = 3.048
[ Epoch 3 ] grad = 4.096, x = 2.6384
[ Epoch 4 ] grad = 3.2768, x = 2.31072
[ Epoch 5 ] grad = 2.62144, x = 2.048576
[ Epoch 6 ] grad = 2.097152, x = 1.8388608
[ Epoch 7 ] grad = 1.6777216, x = 1.67108864
[ Epoch 8 ] grad = 1.34217728, x = 1.536870912
[ Epoch 9 ] grad = 1.073741824, x = 1.4294967296
[ Epoch 10 ] grad = 0.8589934592, x = 1.34359738368
[ Epoch 11 ] grad = 0.68719476736, x = 1.27487790694
[ Epoch 12 ] grad = 0.549755813888, x = 1.21990232556
[ Epoch 13 ] grad = 0.43980465111, x = 1.17592186044
[ Epoch 14 ] grad = 0.351843720888, x = 1.14073748836
[ Epoch 15 ] grad = 0.281474976711, x = 1.11258999068
[ Epoch 16 ] grad = 0.225179981369, x = 1.09007199255
[ Epoch 17 ] grad = 0.180143985095, x = 1.07205759404
[ Epoch 18 ] grad = 0.144115188076, x = 1.05764607523
[ Epoch 19 ] grad = 0.115292150461, x = 1.04611686018
可以看到,经过20轮迭代,我们从初始值x=5不断地逼近x=1,虽然没有完全等于,但是在后面的迭代中它会不断地逼近的。
好像我们已经解决了这个问题,感觉有点轻松啊。高兴之余,突然回过神来,那个步长我设的好像有点随意啊,迭代了20轮还没有完全收敛,是不是我太保守了,设得有点小?俗话说的好,人有多大胆,地有多大产。咱们设个大点的数字,让它一步到位!(豪迈的表情)
gd(5,100,g)
这回设得够大了,来看看结果:[ Epoch 0 ] grad = 8, x = -795
[ Epoch 1 ] grad = -1592, x = 158405
[ Epoch 2 ] grad = 316808, x = -31522395
[ Epoch 3 ] grad = -63044792, x = 6272956805
[ Epoch 4 ] grad = 12545913608, x = -1248318403995
[ Epoch 5 ] grad = -2496636807992, x = 248415362395205
[ Epoch 6 ] grad = 496830724790408, x = -49434657116645595
[ Epoch 7 ] grad = -98869314233291192, x = 9837496766212473605
[ Epoch 8 ] grad = 19674993532424947208, x = -1957661856476282247195
[ Epoch 9 ] grad = -3915323712952564494392, x = 389574709438780167192005
[ Epoch 10 ] grad = 779149418877560334384008, x = -77525367178317253271208795
[ Epoch 11 ] grad = -155050734356634506542417592, x = 15427548068485133400970550405
[ Epoch 12 ] grad = 30855096136970266801941100808, x = -3070082065628541546793139530395
[ Epoch 13 ] grad = -6140164131257083093586279060792, x = 610946331060079767811834766548805
[ Epoch 14 ] grad = 1221892662120159535623669533097608, x = -121578319880955873794555118543211995
[ Epoch 15 ] grad = -243156639761911747589110237086423992, x = 24194085656310218885116468590099187205
[ Epoch 16 ] grad = 48388171312620437770232937180198374408, x = -4814623045605733558138177249429738253595
[ Epoch 17 ] grad = -9629246091211467116276354498859476507192, x = 958109986075540978069497272636517912465605
[ Epoch 18 ] grad = 1916219972151081956138994545273035824931208, x = -190663887229032654635829957254667064580655195
[ Epoch 19 ] grad = -381327774458065309271659914509334129161310392, x = 37942113558577498272530161493678745851550384005
我去,这是什么结果!不但没有收敛,反而数字越来越大!这是要把python的数字撑爆的节奏啊!(实际上python的数字没这么容易撑爆的……)
需要冷静一下……为什么会出现这样的情况?不是说好了是梯度下降么?怎么还会升上去?这个问题就要回到梯度这个概念本身来。
实际上梯度指的是在当前变量处的梯度,对于这一点来说,它的梯度方向是这个方向,我们也可以利用泰勒公式证明在一定的范围内,沿着这个梯度方向走函数值是会下降的。但是,从函数中也可以看出,如果一步迈得太大,会跳出函数值下降的范围,反而会使函数值越变越大,造成悲剧。
如何避免这种悲剧发生呢?简单的方法就是将步长减少,像我们前面那样设得小点。另外,还有一些Line-search的方法可以避免这样的事情发生,这些方法以后有机会在慢慢聊。
现在,我们要镇定一下,看样子我们只能通过修改步长来完成这个问题了。这时候我们可以开一个脑洞:既然小步长会让优化问题收敛,大步长会让优化问题发散,那么有没有一个步长会让优化问题原地打转呢?
我们还是从x=5出发,假设经过一轮迭代,我们求出了另一个x值,再用这个值迭代,x值又回到了5。我们用中学的数学能力建一个方程出来:
x=5, g(x)=8, 新的值x'=5 - 8 * step
g(x')=2 * (5-8*step) - 2,回到过去:x' - g(x') * step = x = 5
合并公式求解得,step=1
也就是说step=1时,求解会原地打转,赶紧试一下:
gd(5,1,g)[ Epoch 0 ] grad = 8, x = -3
[ Epoch 1 ] grad = -8, x = 5
[ Epoch 2 ] grad = 8, x = -3
[ Epoch 3 ] grad = -8, x = 5
[ Epoch 4 ] grad = 8, x = -3
[ Epoch 5 ] grad = -8, x = 5
[ Epoch 6 ] grad = 8, x = -3
[ Epoch 7 ] grad = -8, x = 5
[ Epoch 8 ] grad = 8, x = -3
[ Epoch 9 ] grad = -8, x = 5
[ Epoch 10 ] grad = 8, x = -3
[ Epoch 11 ] grad = -8, x = 5
[ Epoch 12 ] grad = 8, x = -3
[ Epoch 13 ] grad = -8, x = 5
[ Epoch 14 ] grad = 8, x = -3
[ Epoch 15 ] grad = -8, x = 5
[ Epoch 16 ] grad = 8, x = -3
[ Epoch 17 ] grad = -8, x = 5
[ Epoch 18 ] grad = 8, x = -3
[ Epoch 19 ] grad = -8, x = 5
果然不出我们所料,打转了……
好了,现在我们基本明白了,当步长大于1会出现求解发散,而小于1则不会,那么对于别的初始值,这个规则适用么?
gd(4,1,g)[ Epoch 0 ] grad = 6, x = -2
[ Epoch 1 ] grad = -6, x = 4
[ Epoch 2 ] grad = 6, x = -2
[ Epoch 3 ] grad = -6, x = 4
[ Epoch 4 ] grad = 6, x = -2
[ Epoch 5 ] grad = -6, x = 4
[ Epoch 6 ] grad = 6, x = -2
[ Epoch 7 ] grad = -6, x = 4
[ Epoch 8 ] grad = 6, x = -2
[ Epoch 9 ] grad = -6, x = 4
[ Epoch 10 ] grad = 6, x = -2
[ Epoch 11 ] grad = -6, x = 4
[ Epoch 12 ] grad = 6, x = -2
[ Epoch 13 ] grad = -6, x = 4
[ Epoch 14 ] grad = 6, x = -2
[ Epoch 15 ] grad = -6, x = 4
[ Epoch 16 ] grad = 6, x = -2
[ Epoch 17 ] grad = -6, x = 4
[ Epoch 18 ] grad = 6, x = -2
[ Epoch 19 ] grad = -6, x = 4
果然试用,这样一来,我们可以“认为”,对于这个优化问题,采用梯度下降法,对于固定步长的算法,步长不能超过1,不然问题会发散!
好了,下面我们换一个函数:,对于这个问题,它的安全阈值是多少呢?不罗嗦了,是0.25:
def f2(x):
return 4 * x * x - 4 * x + 1
def g2(x):
return 8 * x - 4
gd(5,0.25,g2)[ Epoch 0 ] grad = 36, x = -4.0
[ Epoch 1 ] grad = -36.0, x = 5.0
[ Epoch 2 ] grad = 36.0, x = -4.0
[ Epoch 3 ] grad = -36.0, x = 5.0
[ Epoch 4 ] grad = 36.0, x = -4.0
[ Epoch 5 ] grad = -36.0, x = 5.0
[ Epoch 6 ] grad = 36.0, x = -4.0
[ Epoch 7 ] grad = -36.0, x = 5.0
[ Epoch 8 ] grad = 36.0, x = -4.0
[ Epoch 9 ] grad = -36.0, x = 5.0
[ Epoch 10 ] grad = 36.0, x = -4.0
[ Epoch 11 ] grad = -36.0, x = 5.0
[ Epoch 12 ] grad = 36.0, x = -4.0
[ Epoch 13 ] grad = -36.0, x = 5.0
[ Epoch 14 ] grad = 36.0, x = -4.0
[ Epoch 15 ] grad = -36.0, x = 5.0
[ Epoch 16 ] grad = 36.0, x = -4.0
[ Epoch 17 ] grad = -36.0, x = 5.0
[ Epoch 18 ] grad = 36.0, x = -4.0
[ Epoch 19 ] grad = -36.0, x = 5.0
好了,这个故事讲完了。为什么要讲这个故事呢?
这个故事说明了梯度下降法简单中的不简单(划重点啊),虽然和的一些方法比起来在寻找优化方向上比较轻松,可是这个步长真心需要点技巧,即使这样一个一维的优化问题都有这些问题,对于现在大火的深度学习,CNN优化(没错,说得就是你),一个base_lr基础学习率+gamma学习衰减率真的可以轻松跳过像上面这样的坑么?说实话还是需要一定的尝试才能找到感觉。
最后多说一句,对于上面的一元二次函数,有没有发现步长阈值和二阶导数的关系呢?
本文的全部代码可以在https://github.com/hsmyy/zhihuzhuanlan/blob/master/gd.ipynb阅览。
#EdgeTAM
加快22倍!Meta提出EdgeTAM:基于SAM 2的高效视频分割模型,性能与速度兼得!
Meta提出了EdgeTAM,这是一个基于SAM 2的高效视频分割模型。EdgeTAM通过引入2D空间感知器和知识蒸馏流水线,显著降低了计算成本,同时保持了与SAM 2相当的性能,能够在iPhone 15 Pro Max上以16 FPS运行,速度比SAM 2快22倍。
在 Segment Anything 模型 (SAM) 之上,SAM 2 通过记忆bank 机制进一步扩展了其从图像到视频输入的能力,并获得了与以往方法相比的卓越性能,使其成为视频分割任务的基础模型。在本文中,我们旨在使 SAM 2 更加高效,甚至可以在移动设备上运行,同时保持可比的性能。尽管有许多工作优化了 SAM 以获得更好的效率,但我们发现它们对 SAM 2 来说是不够的,因为它们都集中于压缩图像编码器,而我们的基准测试表明,新引入的记忆注意力块也是延迟瓶颈。
基于这一观察,我们提出 EdgeTAM,它利用一种创新的 2D 空间感知器来降低计算成本。具体来说,所提出的 2D 空间感知器使用一种轻量级 Transformer 来编码密集存储的帧级别记忆,该 Transformer 包含一组可学习的查询。鉴于视频分割是一个密集预测任务,我们发现保持记忆的空间结构对于将查询分成全局级别和片级别组至关重要。我们还提出了一种蒸馏流水线,进一步提高了性能,而无需推理开销。结果,EdgeTAM 在 DAVIS 2017、MOSE、SA-V val 和 SA-V test 上分别实现了 87.7、70.0、72.3 和 71.7 J &F,同时在 iPhone 15 Pro Max 上以 16 FPS 运行。
1. 引言
Segment Anything Model (SAM) [31] 是第一个可提示图像分割的基础模型。各种研究表明它在零样本泛化和迁移学习方面具有卓越的能力 [8, 39, 55, 70]。在 SAM 之上,最近,SAM 2 [48] 扩展了原始 SAM,以处理图像和视频输入,并具有记忆银行机制,并使用新的大规模多粒度视频跟踪数据集 (SA-V) 进行训练。

图 1. iPhone 15 Pro Max 和 NVIDIA A100 上的速度与性能权衡。EdgeTAM 在边缘设备上比 SAM 2 快得多,与其它 VOS 方法相比,它在具有挑战性的 SA-V val 数据集上也更准确。请注意,EdgeTAM 在 iPhone 15 Pro Max 上可以达到 16 FPS。
尽管 SAM 2 在与以前的视频对象分割 (VOS) 模型相比取得了惊人的性能,并允许更广泛的用户提示,但作为服务器端的基础模型,它对设备端推理效率不高。例如,最小的 SAM 2 变体在 iPhone 15 Pro Max 1 上仅运行速度约为 1 FPS。此外,现有的方法 [71, 83, 86],这些方法优化了 SAM 以获得更好的效率,仅考虑了其图像编码器,因为掩码解码器非常轻量级。然而,如图 2 所示,这对于 SAM 2 来说是不够的,即使将图像编码器替换为更紧凑的视觉支架,例如 ViT-Tiny [58] 和 RepViT [64],由于 SAM 2 中引入的计算量大的内存注意力块,延迟并没有得到显著改善。
尤其是,SAM 2 使用内存编码器对过去帧进行编码,这些帧级别内存与对象级别指针(从掩码解码器获得)一起构成内存银行。然后,这些与当前帧的特征通过内存注意力块融合。由于这些内存被密集编码,因此在当前帧特征和内存特征之间进行跨注意力时,会产生巨大的矩阵乘法。因此,尽管内存注意力块的参数数量相对较少,但内存注意力的计算复杂度对于设备端推理来说是不可承受的。Fig. 2 进一步证明了这一假设,其中减少内存注意力块的数量几乎线性地降低了总解码延迟,并且在每个内存注意力块中,删除跨注意力提供了最大的速度提升。

图 2. iPhone 单帧延迟 (ms)。(a) 中,我们展示仅用更紧凑的骨干替换图像编码器是不够的,因为解码器也是一个瓶颈。(b) 中,通过减少内存注意力块的数量和删除某些模块,我们发现跨注意力 (CA) 是根本原因。
为了使这种基于视频的跟踪模型在设备上运行,在EdgeTAM中,我们关注如何利用视频中的冗余信息。为了在实践中实现这一点,我们提出在执行记忆注意力之前压缩原始帧级别的信息。我们首先使用朴素的空间池化,并观察到性能显著下降,尤其是在使用低容量的骨干网络时。 为了缓解这个问题,我们转向基于学习的压缩器,如Perceiver [29, 30],它使用一组小固定的学习查询来总结密集特征图。然而,即使是朴素地将Perceiver纳入其中,也导致性能严重下降。我们假设,作为一种密集预测任务,视频分割需要保留记忆银行的空间结构,而朴素的Perceiver则会丢弃这种结构。
鉴于这些观察结果,我们提出了一种创新的轻量级模块,该模块压缩了帧级别的内存特征图,同时保留了二维空间结构,名为 2D Spatial Perceiver。具体来说,我们将可学习的查询分为两组,其中一组的功能类似于原始 Perceiver,即每个查询都对输入特征执行全局注意力并输出一个向量作为帧级别的总结。在另一组中,查询具有二维先验,即每个查询仅负责压缩一个非重叠的局部区域,因此输出同时保持空间结构并减少总的 token 数量。作为插件模块,2D Spatial Perceiver 可以与 SAM 2 的任何变体集成,并且通过 8 倍的速度加快内存注意力,同时具有可比的性能。例如,使用 RepViT-M1 [64] 作为骨干网络和两个内存注意力块时,利用 2D Spatial Perceiver 在 iPhone 上可以获得 16 FPS,这比基线快 6.4 倍,并且在具有挑战性的 SA-V val 集中甚至超过它,达到 0.9 I&F。
除了架构改进之外,我们还进一步提出了一种蒸馏流水线,将强大的教师模型 SAM 2 的知识转移到我们的学生模型中,从而在不增加推理开销的情况下提高准确率。具体而言,SAM 2 的训练过程分为两个阶段,首先,模型使用 SA-1B [31] 中的可提示图像分割任务进行训练,同时断开与内存相关的模块,然后在第二阶段,模型包含所有模块,使用可提示视频分割任务在 SA-1B 和 SA-V [48] 数据集上进行训练。我们发现,在两个阶段,从原始 SAM 2 的图像编码器中对齐特征有益于性能。此外,我们还对教师 SAM 2 和我们的学生模型之间的内存注意力输出进行对齐,以便除了图像编码器之外,与内存相关的模块也可以从 SAM 2 教师那里接收监督信号。结果,通过提出的蒸馏流水线,我们在 SA-V val 和测试集上分别将提高了 1.3 和 3.3。
汇聚起来,我们提出了一种名为 EdgeTAM(边缘设备上的 Track Anything 模型),它采用 2D 空间感知器以提高效率,并采用知识蒸馏以提高准确性。我们的贡献可以总结如下:
• 通过全面的基准测试,我们发现延迟瓶颈在于内存注意力模块。• 鉴于延迟分析,我们提出了一种2D空间感知器,它显著降低了内存注意力计算成本,同时具有可与任何SAM 2变体相媲美的性能,可以与任何SAM 2变体集成。
• 我们实验了一个蒸馏流水线,该流水线在图像和视频分割阶段都与原始 SAM 2 进行特征级对齐,观察到在推断期间没有额外成本的情况下,性能有所提高。
• The resulting EdgeTAM 可以以 16 FPS 在 iPhone 上运行,这明显比现有的视频对象分割模型更快,并且与之前的最先进方法相当或优于。我们的知识表明,它是第一个在设备上运行的,用于统一分割和跟踪任务的模型。
2. 相关工作
**视频对象分割 (VOS)**。VOS 任务的目标是,给定第一帧的地面真实 (GT) 对象分割掩码,在视频后续帧中跟踪和预测对象掩码。在线学习方法 [4, 7, 26, 38, 40, 41, 45, 46, 49, 52, 61, 69] 将该任务表述为一个半监督学习问题,在测试期间,模型会使用第一帧的 GT 掩码进行微调。然而,这项工作通常会遭受推理效率低、对输入敏感以及难以随着大量训练数据进行扩展的问题。为了避免测试期间的训练,离线训练的模型提出利用模板匹配 [10, 27, 43, 62, 74, 75, 77, 79] 或记忆银行 [34, 44] 来跟踪标注和预测帧中的身份信息。在网络架构方面,一些工作采用循环神经网络进行空间-时间编码 [32, 33, 60, 72],而最近,基于 Transformer 的模型 [3, 11, 12, 14, 19, 32, 51, 66, 68, 76, 78, 80, 84] 表现更好。
Segment Anything Model (SAM)。SAM [31] 定义了一个新的基于提示的分割任务,其中用户提示可以是点、框和掩码。SAM 2 [48] 将任务扩展到视频输入,即提示式视频分割 (PVS)。与 VOS 不同,用户可以在任意帧和多个时间步长提供标注,并使用 SAM 提示的任何组合,使 VOS 成为 PVS 的一个特殊情况。SAM 和 SAM 2 都遵循相同的元架构,即图像编码器和基于提示的掩码解码器,但为了捕捉时间信息,SAM 2 补充了一个记忆银行机制。得益于在各种大型数据集上的训练,SA-1B [31] 和 SAV [48],SAM 在通用感知和下游任务方面表现出色 [8, 9, 39, 55, 70, 81]。为了使 SAM 更加高效且更适合低容量设备,一些工作 [63, 71, 83, 85, 86] 建议将其图像编码器压缩为更紧凑的视觉支架,并采用知识蒸馏和/或掩码图像预训练。然而,通过我们的基准测试,我们发现,除了图像编码器之外,SAM 2 中新引入的与记忆相关的模块也是速度瓶颈;因此,替换图像编码器已经不再足够。因此,我们提出了一种新的插件模块来加速记忆融合以解决该问题,并结合了为视频输入而设计的蒸馏管道。
3. 方法论
在这一部分,我们首先简要介绍 Segment Anything 模型 2 (SAM 2),我们的模型基于它。然后,我们分别提出我们的架构级改进和知识蒸馏流程。
3.1. 预备:SAM 2
总体而言,SAM 2 由四个组件组成,包括图像编码器 ,掩码解码器 ,内存编码器 和内存注意力 ,前两者几乎与原始 SAM 相同,仅区别在于两者之间的跳跃连接。尤其是, 是一种分层骨干网络 Hiera[50],它输出具有三个不同步距的特征图,分别为 和 16 ,分别表示为 。
其中, 是当前的帧输入。然后, 与来自前 帧的记忆特征 融合,通过记忆注意力 进行融合。记忆注意力本质上是 Transformer[59]块的堆叠。在这种设置中, 作为查询,而记忆特征,沿着时间维度连接,提供键和值:
其中, 是基于记忆的图像特征。接下来,掩码解码器 编码用户提示,并根据提示嵌入 和图像特征 解码掩码预测 :
最后, 和 被融合并使用内存编码器 编码,然后以先进先出(FIFO)的方式排入内存银行:
3.2. EdgeTAM
Na¨ıve Adaptations. 如图 3 所示,SAM 2 的元架构紧随 SAM 之后,其图像编码器是参数和计算方面最重的组件。虽然新引入的与内存相关的模块只占总参数的一小部分,但我们的基准测试 (图 2) 表明,内存注意力也是一个延迟瓶颈。因此,为了追求更高的效率,一种朴素的技术是使用紧凑的骨干网络替换图像编码器,并减少内存注意力块的数量。为此,我们遵循 EdgeSAM [86] 的做法,选择 RepViT-M1 [64] 作为骨干网络,并将内存注意力从 4 个块减少到 2 个块。然而,在移动设备上部署时,推理吞吐量仍然令人满意,仅为 2.5 FPS (在 iPhone 15 Pro Max 上)。

图 3. EdgeTAM 的总体架构。EdgeTAM 的元架构遵循 SAM 2,主要区别在于提出的插件模块,2D 空间感知器,标记为橙色虚线框。
Taking a closer look, we observe that each memory feature has the same size as the image feature , where denote channels, height and width respectively. With frames in the memory bank, the computational complexity of memory attention becomes , which translates to a huge matrix multiplication that mobile devices with limited scale of parallelism perform inefficiently. While is already relatively small compared to other VOS methods, reducing it will lead to the degradation of temporal consistency and occlusion handling. On the other hand, videos are known to be information redundant. Thus, we propose to summarize the memory spatially before performing memory attention. Global Perceiver. Inspired by Perceiver [29, 30], we encode each memory feature with a stack of attention modules to compress the densely stored memories into a small set of vectors , where is the number of learnable latents and Specifically, we denote the latents as and perform single-head cross attention (CA) between and , followed by self attention (SA) as follows:

和 分别表示 CA 中查询,键和值的投影。 是中间特征, 表示位置嵌入[53]。在这里,每个潜在的表示可以全局地关注记忆特征并将其总结为一个向量。虽然全局感知器引入了可忽略的推理成本,但它将记忆注意力的复杂度降低到 。然而,尽管在全局感知器的输入中添加了位置嵌入,但生成的压缩记忆仅包含隐式的空间信息,因为输出没有保持其空间结构。同时,作为密集预测任务,视频对象分割需要更明确的位置信息[48]和局部特征[51]。因此,我们进一步提出了一种 2D 空间感知器用于此目的。
2D 空间感知器。与全局感知器类似,2D 空间感知器共享相同的网络架构和参数。然而,我们为可学习的潜在变量 分配了空间先验,并限制每个潜在变量仅关注局部窗口。具体而言,我们执行窗口分割[36]将记忆特征图分割为 个非重叠的块,并将位置嵌入 从输入移动到输出 :

不同的 Global 和 2D 空间感知器设计鼓励不同的行为,其中全局潜在变量 具有一定的冗余性(多个潜在变量关注相同的输入)并且可以动态分布在整个图像上,而 2D 潜在变量 则被迫处理局部区域。两者都具有总结特征的良好优点。因此,我们通过沿空间维度进行展平并沿展平维度进行连接来组合它们。请注意,我们的实现堆叠了 Eq. 5 和 Eq. 6 中的块两次。总而言之,在应用所提出的模块时,内存注意力复杂性从 减少到 。在实践中,我们控制速度提升比例约为 倍,即 ,以便内存注意力中的自注意力块和交叉注意力块具有相似的复杂度。

图 4. EdgeTAM 中的蒸馏流水线。在图像预训练阶段,我们对教师和学生的图像编码器特征进行对齐。在视频训练阶段,我们进一步对记忆注意力模块输出的特征进行教师和学生之间的对齐。对于这两个阶段,都使用任务特定的损失函数。
3.3. 蒸馏流水线
如图 4 所示,SAM 2 的训练流程可以分为图像分割预训练阶段 和视频分割训练阶段 。先前的方法[71,83,86]表明,在 上进行知识蒸馏有助于提高图像的性能。在此,我们将这一思想扩展到视频领域,并将蒸馏损失作为辅助损失,这意味着在训练过程中也同时实施了任务特定的损失。
特别是, 中,我们采用与任务相关的损失函数 ,与 SAM 相同(包括用于掩码预测的 Dice loss [54]和 focal loss[35]以及用于掩码置信度预测的 L1 loss),同时,我们使用 MSE loss 将图像编码器特征图( 在 Eq. 1 中)在教师模型和学生模型之间对齐。预训练损失 可以表示为:
其中, 是从方程 1 和方程 3 获得的掩码预测。由于缺乏内存银行,因此省略方程 。这里, 和 分别表示真实标签,损失权重,教师和学生图像编码器特征。
最后,在第 阶段,任务特定的损失包括一个额外的 BCE 损失用于遮挡预测。此外,为了让学生的记忆相关模块从教师那里获得监督,除了 ,我们添加了另一个 MSE 损失 来对齐教师和学生( 和 )(Eq.2)。最终的总损失变为:
使用 和 作为损失权重。
4.实验证明
4.1. 实施细节
训练。一般来说,EdgeTAM的训练过程遵循SAM 2。我们将输入分辨率设置为 。在图像分割预训练阶段,我们使用SA-1B数据集进行训练,共 2 个epoch,批大小为 128 。我们使用AdamW[37]作为优化器 ,并将学习率设置为 ,并使用倒数平方根调度器[82]。我们对 梯度进行截断,值为 0.1 ,并将权重衰减设置为 0.1 。骰子,焦点, 和 的损失权重分别为 和 1 。对于每个训练样本,最多允许 64 个对象,并迭代地添加 7 个修正点。在这一阶段,仅进行水平随机翻转的数据增强。对于视频分割训练,我们使用SA-V,即SA-1B的 随机抽样子集,包括DAVIS,MOSE和 YTVOS,进行训练 130 K次迭代,批大小为 256 。大多数配置遵循前一阶段,除了图像编码器学习率等于 ,其他部分学习率等于 ,并使用余弦调度器。骰子的损失平衡因子为 20 和 1 ,焦点,IoU,遮挡, 和 的平衡因子分别为 和 1 。每个视频样本包含 8 帧,几乎有 3 个对象,并使用水平翻转,颜色抖动,仿射和灰度变换进行增强。
渐进式微调,使用更长的训练样本。类似于 SAM 2.1,我们对训练好的 EdgeTAM 模型进行微调,使用 16 帧序列。在微调过程中,我们冻结图像编码器,不进行蒸馏。训练集与视频分割训练阶段相同,但总迭代次数减少到原始计划的 1/3。此外,由于 EdgeTAM 的 VRAM 消耗量远低于 SAM 2,我们能够使用 32 帧的训练样本,按照相同的计划对 16 帧模型进行进一步微调。请注意,内存银行大小保持不变,只有训练样本变长,因此推理成本不变。

图 5. 在离线和在线设置下,零样本 PVS 准确率在 9 个数据集上的表现。

表 1. 在 SA 任务上的零样本准确率,涵盖 23 个数据集。我们报告 1 (5) 点击 mIoU 结果。FPS 在 iPhone 上测量。我们的混合数据集不包含 SAM 2 使用的内部数据集。
Model. 默认情况下,我们使用在 ImageNet 上预训练的 RepViT-M1 [64] 作为图像编码器。我们还尝试使用在 ImageNet 上预训练的 ViT-Tiny [58],并使用 MAE [24]。内存注意力块的数量为 2,并且为全局感知器和 2D 空间感知器分配了 256 个可学习的潜在空间。帧级别记忆和对象指针的内存银行大小分别为 7 和 16,遵循 SAM 2。全局感知器和 2D 空间感知器的位置嵌入是正弦,分别是 2DRoPE [53]。我们使用 SAM2-HieraB 作为教师,并使用公开可用的 checkpoint3。
4.2. 数据集
训练。我们使用 SA-1B[31],SA-V[48],DAVIS[47],MOSE[18]和 YTVOS[73]数据集进行训练。SA- 1B 包含 1100 万张图像,带有 110 亿个 mask 标注,具有多种粒度(在部分级别和对象级别)。SA-1B中图像的平均分辨率为 像素。到目前为止,它是可用的最大的数据集,用于图像分割任务。SA-V 遵循 SA-1B 的标准,并收集了 190.9 万个 masklet 标注,涵盖 50.9 万个视频,平均时长为 14秒,室内/室外场景比例为 ,并重采样到 24 FPS。请注意,标注帧率是 6 FPS。此外,从 155个视频中的 293 个 masklet 和从 150 个视频中的 278 个 masklet 作为 SA-V 的 val/test 分割集保留,这些视频是手动选择的,以关注具有快速运动,复杂遮挡和消失的困难情况。
评估。 我们的评估可以分为三个设置:(1)提示式视频分割(PVS),用户可以点击视频中的任意帧以指示感兴趣的对象;(2)任何分割(SA),与 PVS 相同但适用于图像;(3)半监督视频对象分割(VOS),在推理过程中,第一帧上的真实掩码可用。对于视频任务,我们报告 [47]和 [73]作为指标,对于图像,我们使用 mloU。
评估。我们的评估可以分为三个设置:(1) 提示式视频分割 (PVS),用户可以点击视频中的任意帧以指示感兴趣的对象;(2) 任何分割 (SA),与 PVS 相同但适用于图像;(3) 半监督视频对象分割 (VOS),在推理过程中,第一帧上的真实掩码可用。对于视频任务,我们报告 [47] 和 [73] 作为指标,对于图像,我们使用 mIoU。
对于PVS,我们使用零样本协议在9个数据集(包括在线和离线模式)中进行评估。对于SA,我们在SA-23 [31] 上进行评估,该数据集由23个开源数据集(包括视频(每个帧被视为图像)和图像领域)组成。最后,对于VOS,我们提供了在流行的DAVIS 2017 [47]、MOSE [18] 和 YouTubeVOS [73] val集以及具有挑战性的SA-V val/test集 [48]上的性能。

表 2. VOS 任务上的性能。我们报告了 YTVOS 的 值和“其他数据集”的 值。在 A100 上获得的 FPS 是使用 torch compile 获得的。请注意,对于 SAM 2、SAM 2.1 和 EdgeTAM,我们使用相同的模型评估所有数据集。

表 3. 试验消融研究。__(a) 每项拟议组件的有效性。

(b) 2D Perceiver 的潜在值分配。
4.3. 提示式视频分割 (PVS)
EdgeTAM 的一个关键特性是它遵循 SAM 2 的相同元架构,这使得它能够使用各种用户输入在任何帧上进行可提示的视频分割。如图 5 所示,我们遵循了与 SAM 2 相同的在线和离线 PVS 设置,这模拟了真实世界中的用户交互。离线模式允许多次回放,仅在出现较大错误的帧上添加修正点,而在线模式仅在单次前向传递中注释帧。与 和 Cuite 相比,EdgeTAM 在所有设置下均有显著优势。此外,由于以端到端方式进行训练并使用 SAM 2 教师进行蒸馏,因此随着标注帧数量的增加,差距越来越大。此外,即使与原始 SAM 2 相比,EdgeTAM 也能实现可比结果,尽管它在尺寸和速度方面明显更小更快。
4.4. Segment Anything (SA)
Both SAM 2 和 EdgeTAM 可以作为具有分离内存模块的图像分割模型运行。如图 1 所示,EdgeTAM 在与 SAM 和 SAM 2 相比,尤其是在具有更多输入点的情况下,可以实现可比的 mIoU 性能。例如,在五个输入点的情况下,EdgeTAM 甚至超过了专门用于图像分割的 SAM-H (81.7 v.s. 81.3)。请注意,我们的 EdgeTAM 没有使用 SAM 2 和 SAM 2.1 使用的内部数据集进行训练。鉴于其实时速度,EdgeTAM 可作为图像和视频的统一本地分割模型使用。

图 6. EdgeTAM 与 SAM 2 的定性结果。在第一个示例中,我们展示了从同一类别中跟踪多个实例,这些实例也彼此靠近。我们的 EdgeTAM 提供的遮罩质量与 SAM 2 相似。在第二个示例中,我们展示了一个快速移动的对象,具有较大的失真。虽然总的来说,EdgeTAM 能够很好地捕捉边界,但其输出的粒度与 SAM 2 不同,未能跟踪鸟的脚。
4.5. 视频对象分割 (VOS)
While EdgeTAM 仅使用 SA-V 和 SA1B 数据集进行训练,如表 2 所示,在 MOSE、DAVIS 和 YTVOS 上,它与或超过了在这些数据集上训练的以往最先进的 VOS 模型。这表明 EdgeTAM 在零样本设置下的鲁棒性。更重要的是,在设备上部署多个模型,每个模型针对某些类型的数据,在实践中不可行。
此外,由于在 SA-V 上进行训练,EdgeTAM 在 SA-V val 和 test 上超越了所有其同类产品,仅次于 SAM 2 和 SAM 2.1。请注意,SA-V val/test 中的掩码具有不同的粒度,而其他数据集的掩码则在对象级别。这表明 EdgeTAM 的灵活性。此外,为了速度基准测试,我们的主要目标是在边缘设备上进行推理,我们观察到,即使使用 torch 编译,EdgeTAM 的流式多处理器利用率仍然相对较低。通过 Torch profile,我们发现,在高端 GPU 上,CPU(CUDA 内核启动)成为 EdgeTAM 的瓶颈。因此,我们鼓励关注边缘设备延迟,而 EdgeTAM 旨在为此服务。
4.6. 试验结果分析
对于所有消融研究,我们使用原始训练计划的 (43k 步)进行训练。如图 3(a)所示,我们首先消融了每个拟议组件的有效性。在表中,我们将基线设置为具有两个记忆注意力块的 RepViTM1,并将其与仅使用降采样空间记忆而不是使用 2D Perceiver 进行比较。实验表明,2D Spatial Perceiver 比基线和 平均池化更快速,更准确(0.4 到 2.7 个更好)。此外,拟议的蒸馏流水线通过 1.3 和 3.3 进一步改善了 SA-V val 和测试集上的 。然后,在图 3(b)中,我们改变了全局和 2D 潜在变量的数量,并发现使用两者可以获得最佳性能和加速。请注意,使用 2D 潜在变量以 6.3 倍的速度加速了基线,同时具有更好的性能。图3(c)显示了在不同图像编码器组合和记忆注意力块的数量中使用 2D Perceiver。我们选择使用两个记忆注意力块的 RepViT-M1 以获得最佳权衡。最后,在图 3(d)中,我们研究了在 2D Perceiver 网络中使用自注意力的方法。这里的动机是,由于每个 2D 潜在变量都关注一个没有与其他 2D 潜在变量重叠的局部区域,因此引入自注意力块将鼓励 2D 潜在变量之间的通信,从而产生更好的特征。我们的结果验证了这一假设。
4.7. 质性结果
在图 6 中,我们比较了 EdgeTAM 和 SAM 2 在 YouTubeVOS val 数据集上的可视化结果。我们选取了两个具有代表性的例子,一个包含来自同一类别的多个实例聚集在一起,另一个包含快速移动的物体和大量失真。对于第一个例子,EdgeTAM 的结果与 SAM 2 相似,并且在整个片段中保持了每个实例的身份。然而,在第二个例子中,我们观察到 EdgeTAM 陷入了一个典型的失败案例,即跟踪粒度可能始终跟随 SAM 2。在该例子中,EdgeTAM 没有将鸟的脚包含在预测的掩码中,因为在之前的帧中,脚不可见。

表格 4. 在使用不同提示的半监督 VOS 评估下,在 17 个视频数据集上的零样本准确率。对于所有提示类型,标注仅在第一帧提供。†:当真实掩码可用时,SAM 不用于 XMem 和 Cuite。
5. 结论
在本文中,我们发现 SAM 2 的延迟瓶颈在于内存注意力模块,并提出 EdgeTAM 以减少跨注意力带来的高开销,同时最大限度地减少性能下降。具体来说,我们提出 2D Spatial Perceiver,用于将密集存储的帧级别记忆编码为更小的 token 集合,同时保留其 2D 空间结构,这对密集预测任务至关重要。作为插件模块,2D Spatial Perceiver 可以应用于任何 SAM 2 变体。此外,我们还将 SAM 中用于图像分割的知识蒸馏流程扩展到视频领域,进一步提高了 EdgeTAM 的性能,而无需推理时间成本。我们的实验表明,EdgeTAM 很好地保留了 SAM 2 的能力,在 PVS、VOS 和 SA 任务中。更重要的是,它比 SAM 2 快 倍,并且在 iPhone 15 Pro Max 上可以达到 16 FPS。
A. 视频对象分割 (VOS)
在我们的主要提交中,我们遵循标准半监督视频对象分割协议,其中在推理过程中,第一帧上的 ground- truth masks 可用。在表 4 中,我们遵循 SAM 2 [48],而不是提供第一帧上的 masks,而是使用第一帧上的点击或框提示感兴趣的对象。由于 XMem ++ 和 CuteDo 不支持这些提示,我们使用 SAM[31]将提示转换为 masks。我们评估在 17 个零样本数据集上,包括 EndoVis 2018 [2],ESD[28],LVOSv2 [25],LV-VIS[65],UVO[67],VOST[56],PUMaVOS[3],Virtual KITTI 2 [6],VIPSeg[42], Wildfires[57],VISOR[16],FBMS[5],Ego-Exo4D[22],Cityscapes[15],Lindenthal Camera[23], HT1080WT Cells[21]和 Drosophila Heart[20]。
在本次评估套件中,除了 1 键设置之外,EdgeTAM 优于强大的基线,包括 和 Cute,提高了 2 到 5 个百分点。与 SAM 2 和 SAM 2.1 相比,EdgeTAM 仍然保持了可比的性能,尤其是在更准确的提示中,例如5-点击和地面真值掩码。
B. 实施细节
我们通常遵循原始 SAM 2 训练超参数用于图像分割预训练 [31] 和视频分割训练 [48]。在此,我们仅强调差异,完整的训练细节在表 5 中显示。首先,我们不使用 drop path 或层级衰减在图像编码器中。其次,我们的图像预训练阶段采用 128 批次大小和总共 175K 训练步数。在视频训练阶段,我们减少每张图像的最大掩码数量,从 64 降低到 32。更重要的是,我们没有在 SAM 2 Internal 数据集上进行训练,因此总训练步数从 300K 减少到 130K。最后,我们的训练包括在两个阶段都采用蒸馏损失。
C. 速度基准
在表 2 中,我们提供了在服务器 GPU(NVIDIA A100 和 V100)和移动 NPU(iPhone 15 Pro Max)上的吞吐量 FPS。V100 的基准测试是从每篇单独的论文中收集的,我们自己使用另外两个硬件进行基准测试。特别是为了优化吞吐量,在 A100上,我们使用 torch 编译所有模型。对于移动 NPU,我们使用 coremltools[1]将模型转换为 CoreML 格式,并使用 XCode 的性能报告工具在 iOS 18.1 上在 iPhone 15 Pro Max 上进行基准测试。请注意,EdgeTAM 与 SAM 2 的加速比在 A100 上不如在 iPhone 上明显。为了了解根本原因,我们在 A100 上监控了两个模型的流式多处理器(SM)利用率,发现即使使用 torch 编译,EdgeTAM 的 SM 使用率只有 且推理受 CPU 和 IO 限制。我们认为这是因为高端服务器 GPU (如 A100)拥有大量的并行可执行单元(EU),而 EdgeTAM 的尺寸很小,因此无法同时占用所有 EU。然而,EdgeTAM 的设计目标是边缘设备,如手机,我们在这里看到了与 SAM 2 相比 的加速。

表 5. 边缘TAM 图像分割预训练和视频分割训练的超参数和详细信息。

参考资料:
[1] EdgeTAM- On-Device Track Anything Model
#纯 ImageNet 做文生图
仅使用 ImageNet 数据集,超过 SD-XL 的 T2I 模型。
仅使用 ImageNet 数据集,超过 SD-XL 的 T2I 模型。
很多文生图模型在十亿级别的数据集上进行训练取得了显著的成果。一个信奉的原则是 "bigger is better",优先考虑数据量而不是质量。本文证明了小的,精心策划的数据集,可以匹配或者优于大量网上抓的数据训练的模型。
本文仅仅使用 ImageNet 数据集,通过精心的文本和图像增强,得到的效果是如图 1 所示:在 GenEval 上比 SD-XL 高 2 个点,在 DPGBench 上比 SD-XL 高 5 个点,同时仅仅使用了 1/10 的参数和 1/1000 的训练图像。
本文的结论表明:通过战略性的数据增强 (而非海量数据集) 可以为 T2I 提供可持续的路径。

图1:本文只用 ImageNet 训练的 text-to-image (T2I) 模型。左:本文 300M T2I 模型 (CAD-I 架构) 生成的图像,即使用 out-of-distribution prompts (粉红色大象,霓虹灯海龟) 也有很好理解文本。右:GenEval (上) 和 DPGBench (下) 的定量结果。气泡的大小表示参数量
专栏目录
https://zhuanlan.zhihu.com/p/687092760
1 纯 ImageNet 做文生图:我们能走多远?
论文名称:How far can we go with ImageNet for Text-to-Image generation?
论文地址:http://arxiv.org/pdf/2502.21318
Project Page:http://lucasdegeorge.github.io/projects/t2i_imagenet/
1.1 研究背景
Text-to-image (T2I) 生成的主流观点认为,更大的训练数据集会带来更好的性能。这种 "bigger is better" 的范式推动了该领域做到了十亿规模的图-文配对数据集,如 LAION-5B、DataComp12.8B 或 ALIGN-6.6B。主流观点认为数据应该多到捕获完整的文本-图像分布。
但是本文挑战了这个观点,即:认为数据量忽略了模型训练中数据效率和质量的问题。
当前的 data curation pipeline 存在 3 大重要缺陷:
- 当前的 data curation 范式仍然包括收集和策划大量网络抓取数据集,非常费算力。
- 当前的 data curation 过程未能消除社会偏见、不适当的内容、版权材料和隐私问题,最终直接体现在经过训练的模型中。
- 对于 specialized applications 的情况,做针对性的图文对非常耗时。
越来越多的 T2I 模型,比如 PixArt-α,Stable Diffusion (SD) 等等,使用了十亿规模的数据集进行训练。社区的反应不是解决核心数据质量问题,而是:收集更多数据。这种蛮力方法放大了计算成本、curation 的复杂性和数据集 bias。
本文提出了一个根本的转变:使用更小、精心策划的数据集训练 T2I 模型。
1.2 使 ImageNet 的文本像素多样化
本文使用 ImageNet,一个著名的数据集,其 bias 和 limitation 已经被彻底研究。ImageNet 本身只有简单的 label,且以 object 为中心,从未用于 T2I 扩散模型。
本文通过 2 个维度丰富 ImageNet 数据:
- Text-space 的增强: 使用 LLaVA,将ImageNet的类标签转换为语义丰富的场景描述。
- Pixel-space 的增强: 使用 CutMix,对图像进行了一些混合,引入了新的概念组合,创建了一些原始数据集中不存在的新概念组合。

图2:Data Curation 和训练的 Pipeline。使用 LLaVa VLM 为图像做长而详细的 caption。使用几种 CutMix 策略创建新的图像,结合几个 ImageNet 概念,并使用 LLaVa 做长而详细的 caption。在训练期间,采样一批正常图像和 CutMix 图像
图 2 说明了本文方法的 Pipeline。
1.3 Text-space 的增强
ImageNet 是一个 class-conditional 数据集,最初用于分类和目标检测任务。为了克服 ImageNet 有限的 class-conditional,本文实现了一个 2 阶段的 Pipeline:
AIO caption:"An image of"
缺点:1) 缺乏详细的描述。2) 缺乏 "person" 这个类别。
LLaVA caption: 采用 LLaVA 生成综合字幕,可以捕获到:1) 场景组成和空间关系;2) 背景元素和环境上下文; 3) 次要对象和参与者;4) 视觉属性 (颜色、大小、纹理);5) 元素之间的交互和交互。
这种增强弥补了 ImageNet 注释的差距,特别是对于类标签缺乏 person 的图像,以及多元素交互的图像。图 3 是 LLaVA 生成的更丰富的字幕示例。

图3:(左) 原始图像,(右) CutMix 像素增强图像的长合成字幕。所有字幕都是 LLaVa 生成,高度多样化,并增加了原始 ImageNet 数据集中不存在的组合性、颜色和概念的复杂细节
1.4 Pixel-space 的增强
对于图像增强,引入了一个结构化的 CutMix 框架,该框架系统地结合了概念,同时保留了对象中心性。本文定义了 4 种增强模式,每一种模式都旨在保持视觉连贯性,同时引入新的概念组合,如下:
(Half-Mix)
- 规模:2 幅图像都保持其原始分辨率。
- 位置:沿高度或宽度的确定性拆分。
- 覆盖范围:每个概念占最终图像的 50%。
- 保存:这 2 个概念都保持全分辨率。
(Quarter-Mix)
- 规模:CutMix 图像大小调整为 50% 边长。
- 位置:四个角之一的固定放置。
- 覆盖率:第二个概念占最终图像的 25%。
- 保存:基本图像中心区域保持不变。
(Ninth-Mix)
- 规模:CutMix 图像大小调整为 33.3% 的边长。
- 位置:沿图像边界的固定放置。
- 覆盖率:第二个概念占最终图像的 11.1%。
- 保存:基本图像中心,角保持不变。
(Sixteenth-Mix)
- 规模:CutMix 图像大小调整为 25% 边长。
- 位置:随机放置不是中央 10% 区域。
- 覆盖率:第二个概念占最终图像的 6.25%。
- 保存:基本图像中心区域保持不变。
每个增强策略生成 1,281,167 个样本,匹配 ImageNet 的训练集大小。图 3 显示了不同结构化增强的示例。
还定义了,从所有 4 种模式统一采样。每个模式的比例相等 (25%),以保持相同的总样本数。图像增强后,将 LLaVA 字幕应用于所有生成的图像,确保视觉和文本表示之间的语义对齐。这就可以得到详细的描述,可以在保持自然语言流畅性的同时准确反映增强的内容。
然后,使用增强之后的图片进行训练,算法如图 3 所示。
注意,这里作者的设置是:
当扩散过程的 timesteps ( 是一个超参数)时,以一定的概率 从 里采样,否则就从 中采样。

图3:使用增强之后的图片进行训练算法
1.5 实验设置
数据集:ImageNet,图片 rescale 到 256 × 256 分辨率。
VAE:使用 SD 的。
Text Encoder:T5。
Sampling:250 steps 的 DDIM。
评价指标:
- FID:50k in-distribution ImageNet 验证集,30k out-of-distribution MSCOCO captions 验证集。
- Precision and Recall, Density and Coverage:评估保真度和多样性,使用 Dinov2 backbone。
- CLIPScore (CS):评估生成图片与 text prompts 的对齐能力。
- GenEval 和 DPGBench。除了使用 GenEval 提供的默认短文本 prompts 外,作者还使用了 Llama-3.1 扩展这些 prompts,以近似训练期间使用的长提示的分布。
1.6 实验结果
作者在 GenEval 和 DPGBench 基准测试中测试了 DiT-I 和 CAD-I 模型的组成能力,并将性能与流行的最先进模型进行了比较,如图 4 和 5 所示。
图 4 报告了 GenEval 的结果,模型以 256×256 分辨率进行评估。⋄ 表示原始 GenEval prompts。⋆ 表示 extended GenEval prompts。与 SD3 相比,本文模型在分辨率为 256×256 时平均比 SD3 (0.56) 表现更好 (CAD-I 0.57,DiT-I 0.57),当使用扩展提示 ⋆ 进行评估时。本文模型也优于 SD1.5 (0.43),SD2.1 (0.50),SDXL (0.55) 和 PixArt-α (0.48),尽管这些模型以更高的分辨率进行评估。该基准测试中的分辨率至关重要。即使没有扩展提示 ⋄,本文的 CAD-I 模型在全分辨率下也能成功达到 SDXL 的性能,同时参数少 10 倍,只在 0.1% 数据上训练。

图4:GenEval 结果
图 5 报告了 DPGBench 上的结果,这个基准类似于 Geneval,但提示更复杂。作者观察到与 GenEval 类似的趋势:使用 DiT-I 实现了 76% 的整体准确率,比 SDXL 提高了 1.3%。CAD-I 的总体得分为 79.94%,比 SDXL 高出 +5%,PixArt-α 高出 +8%。令人印象深刻的是,本文模型达到了与 Janus 相当的准确度,这是一个具有生成能力的 1.3B 参数 VLM。值得注意的是,本文模型都特别擅长关系,CAD-I 为 93.5%,DiT-I 为 92.2%。

图5:DPGBench 结果
作者也分析了本文的增强对图像质量的影响。使用 DiTI 和 CAD-I 并在 ImageNet 上训练,带有短标题 "An image of ...",或从 LLaVA 获得的长字幕。图 6 报告了在 ImageNet 和 COCO 验证集上测试时的结果。本文的增强能够达到很低的 FID (DiT-I 为 8.52,CAD-I 为 6.62),并且具有更好的 precision, recall, density, 以及 coverage 分数。
对于 COCO,这一趋势都更加显着,这是一个 Zero-Shot 任务。本文的增强模型是唯一能够正确遵循提示的模型 (CLIP score 增加:DiT-I 从 13.16 到 24.85; CAD-I 从 12.89 到 26.60),同时保持相似的图像质量 (略高的 FID,但使用 Dinov2 backbone 的 FID 要低得多)。

图6:DiT-I L/2 和 CAD-I 模型的图像质量结果
不同模型之间的比较如图 7 所示。使用 "An image of ..." 的 prompt 格式,基线模型 (AIO) 在 prompt 含有 ImageNet 类之外的概念时难以生成连贯的图像。通过文本增强 (TA),该模型展示了改进的概念理解和组合能力,尽管图像质量仍然有限。结合文本和图像增强(TA + IA)可以提高图像质量和更好的即时理解。这种改进在 pirate ship 场景中尤为明显:虽然 TA 模型生成了一艘船尴尬地放在一碗汤中,但 TA + IA 模型创造了更自然的 pirate ship 在碗中航行的样子。同样,hedgehog and hourglass 示例中,TA + IA 组合显示出更精细的细节,更加美观,而 TA 模型很难渲染可识别的 hedgehog。

图7:模型之间的定性比较。从左到右:AIO 'An image of {class-name}'、Text-Augmentation (TA) 和 Text-Augmentation (TA + IA) 的图像增强。这些示例的 prompts:(a) a pirate ship sailing on a steaming soup, (b) a hedgehog and an hourglass, and (c) a crab sculpted from yellow cheese
#8个视觉大模型生成式预训练方法
视觉基础模型的生成式预训练的工作总结。
大语言模型的进展催生出了ChatGPT这样的应用,让大家对“第四次工业革命”和“AGI”的来临有了一些期待,LLM和视觉的结合也越来越多:比如把LLM作为一种通用的接口,把视觉特征序列作为文本序列的PrefixToken,一起作为LLM的输入,得到图片或者视频的caption;也有把LLM和图片生成模型、视频生成模型结合的工作,以更好控制生成的内容。当然2023年比较热门的一个领域便是多模态大模型,比如BLIP系列、LLaVA系列、LLaMA-Adapter系列和MiniGPT系列的工作。LLM的预训练范式也对视觉基础模型的预训练范式产生了一定的影响,比如MAE、BEIT、iBOT、MaskFEAT等工作和BERT的Masked Language Modeling范式就很类似,不过按照GPT系列的自回归方式预训练视觉大模型的工作感觉不是特别多。下面对最近视觉基础模型的生成式预训练的工作作一些简单的介绍。
LVM
《Sequential Modeling Enables Scalable Learning for Large Vision Models》是UC Berkely和Johns Hopkins University在2023提出的一个影响比较大的工作,视觉三大中文会议也在头版头条做了报道,知乎的讨论也比较热烈。
- Sequential Modeling Enables Scalable Learning for Large Vision Models(https://arxiv.org/abs/2312.00785)
- https://github.com/ytongbai/LVM
- https://yutongbai.com/lvm.html
按照自回归的生成式训练模型的工作之前也有,比如Image Transformer和Generative Pretraining from Pixels等,不过无论是训练的数据量还是模型的参数量都比较小。LVM把训练数据统一表述成visual sentences的形式。对训练数据、模型参数量都做了Scaling,并验证了Scaling的有效性和模型的In-context推理能力。
本文的一大贡献便是数据的收集和整理,和训练LLM的文本数据一样规模的视觉数据在之前缺乏的,因此从开源的各种数据源出发,得到了 1.64billion 图片的数据集 UVDv1(Unified Vision Dataset v1)。文中对数据的来源以及将不同数据统一为visual sentences描述形式的方法做了详细的介绍Fig 1,可以refer原文更多的细节。
Fig 1 Visual sentences 能够将不同的视觉数据格式化为统一的图像序列结构
Fig 2
模型的结构如图Fig 2所示,主要包含三部分:Tokenizer、Autoregressive Vision Model和DeTokenizer。
其中Tokenizer和DeTokenizer取自于VQ-GAN,codebook大小为8192,输入图片分辨率为,下采样倍数为16,因此一张输入图片对应的Token数目为,这一个模块通过LAION 5B数据的1.5B的子集来训练。
这样对于一个visual sentence,会得到一个Token的序列(和目前的很多多模态大模型不一样,这儿没有特殊的token用以指示视觉任务的类型),作为Autoregressive Vision Model的输入,通过causal attention机制预测下一个Token。文中的自回归视觉模型的结果和LLaMA的结构一样,输入的token 序列的长度为4096个token(16张图片),同时在序列的开始和结束分别会放置[BOS](begin of sentence)和[EOS](end of sentence),代表序列的开始和结束。整个模型在UVD v1(包含420 billion tokens)数据上训练了一个epoch,模型的大小包括四种:300 million、600 million、1 billion和3 billion。
Fig 3
从Fig 3可以看出,训练过程中,模型的loss一直在下降,而且模型参数量越大,loss下降越快
更多的实验结果分析可以refer原文。
EMU
《Generative Pretraining in Multimodality》是BAAI、THU和PKU的工作,提出了多模态大模型EMU,EMU的输入是image-text interleaved的序列,可以生成文本,也可以桥接一些扩散模型的Decoder生成图片。
Fig 4
EMU的结构如图Fig 4所示,包含四个部分,Visual Encoder(文中用的EVA-02-CLIP)、Causal Transformer、Multimodal Modeling(LLaMA)和Visual Decoder(Stable Diffusion)。
对于输入的 image-text-video interleaved的序列, EVA-CLIP会提取图片的特征, 同时通过causal Transformer得到 个visual embeddings ,即 CaisalTransformer 。对于包含 个frame的视频, 则会得到 个视觉embedding。在每一张图片或者每一帧的特征序列的开始和结束分别有特殊的 token, 即[IMG]和[/IMG]。
text通过文本的tokenizer得到文本特征序列,和视觉信息对应特征序列连接,并在序列的开始和结束处分别添加表述开始和结束的特殊token,即[s]和[/s]。最后得到的多模态序列作为LLaMA的输入,得到文本输出,而LLaMA输出的视觉特征序列作为扩散模型的条件输入,得到生成的图像。
Emu用Image-text pair的数据、Video-text pair的数据、Interleaved Image and Text的数据以及Interleaved Video and Text的数据进行预训练。对于预测的文本token来说,损失函数为预测下一个token的cross entropy loss;对于视觉token来说,则是的回归损失。
对Emu预训练之后,会对图片生成的Stable Diffusion的Decoder进行微调。微调的时候,只有U-Net的参数会更新,其他的参数固定不变。训练数据集为LAION-COCO和LAION-Aesthetics。每一个训练样本的文本特征序列的结尾处都会添加一个[IMG] token,最后通过自回归的方式得到个视觉特征,这些特征序列作为Decoder的输入得到生成的图片。
文中还对Emu进行多模态指令微调以对其human instructions。数据集包括来自于ShareGPT和Alpaca的文本指令、来自于LLaVA的图像-文本指令以及来自于VideoChat和Video-ChatGPT的video指令。微调的时候,Emu的参数都会固定不变,只有LoRA模块的参数更新。微调的指令跟随数据集格式如下:
[USER]:[ASSISTANT]:。
[User]和[ASSISTANT]分别是单词“word”和“assistant”对应的embedding,不同的任务下也有所不同。
Fig 5
Fig 5是Emu的In-context Learning推理的一个例子,输入图片-描述,以及query文本,会得到对应的输出图片。
4M
《4M: Massively Multimodal Masked Modeling》是瑞士洛桑联邦理工和Apple发表在NeurIPS 2023的一个工作,提出了一种对视觉模型做生成式预训练的范式4M(Massively Multimodal Masked Modeling),将多模态的输入信息编码为特征序列,作为Transformer encoder-decoder的输入,同时采用Masked Modeling的方式,在大量的数据集上对模型进行了训练预训练,可以实现多模态输入、多模态输出,得到的transformer encoder也可以作为一些视觉任务的backbone网络提取图片特征。
- 4M: Massively Multimodal Masked Modeling(https://arxiv.org/abs/2312.06647)
- 4M: Massively Multimodal Masked Modeling(https://4m.epfl.ch/)

Fig 6
模型的结构如图Fig 6所示,不同模态的输入按照不同的方式编码为特征序列,同时从特征序列中随机选择一部分作为context,另外一部分作为需要预测的target,模型基于context序列预测target序列。
文中对bounding box的Tokenization方式和Pix2Seq一样, 比如对于一个坐标为 的框, 会按照 1000 的分辨率对这些坐标做编码,即 , 这些编码之后的坐标和文本一样, 通过 WordPiece的text tokenizer得到对应的特征序列, 训练的时候通过cross entropy的方式计算重建的 loss。
分割的掩码通过ViT-B结构的encoder得到对应的特征序列, 也通过ViT-B结构的decoder得到对应的重建结果, 然后通过 损失计算重建损失。
RGB、normals或者depth图则是用VQ_VAE的的encoder得到特征序列,同时用扩散模型的decoder得到重建结果,损失不是扩散模型里面常用的噪声回归损失,而是重建clean image的损失。

Fig 7
预训练之后的模型可以通过自回归的方式得到输出的特征序列,这些特征序列可以通过对应的decoder解码得到输出的图片、文本等,如图Fig7所示。训练之后encoder可以作为目标检测、语义分割等视觉任务的骨架网络。
VL-GPT
《VL-GPT: A Generative Pre-trained Transformer for Vision and Language Understanding and Generation》是西交、腾讯和港大提出的一个工作。
- VL-GPT: A Generative Pre-trained Transformer for Vision and Language Understanding and Generation(https://arxiv.org/abs/2312.09251)
- https://github.com/AILab-CVC/VL-GPT
Fig 8
模型的结构如图Fig 8所示,包含两个部分,第一个部分是image tokenizer-detokenizer框架的训练,第二个部分是VL-GPT模型的预训练和指令微调。输入模型的文本、图片分别通过Image Tokenizer和Text Tokenizer得到图像和文本特征序列,连接之后得到imate-text interleaved的文本-图像特征序列,作为LLM的输入,通过自回归的方式得到输出的特征序列,输出的特征序列通过Image和Text Detokenizer得到生成的图片和文本。
Image tokenizer-detokenizer包含一个tokenizer 将图片编码为连续的视觉特征序列。detokenizer 则是将视觉特征转换为图片输出。
文中的 用了ViT结构, 得到输入图片 的特征序列 , 而detokenizer 则是用到了隐空间扩散模型, 包含一个transformer decoder用于基于 估计扩散模型的条件特征 可以作为扩散模型的 decoder的条件得到生成的图片 。训练的时候如图Fig 9所示, 用预训练的CLIP模型的图像encoder和文本encoder提取图像和文本特征作为监督信息,损失函数为
Fig 9
VL-GPT包含image tokenizer-detokenizer的tokenizer和detokenizer, 其组件分别为LLM (文中用到了LLaMA) 、图像encoder 、文本encoder 、图像detokenizer 和文本detokenizer 。输入image-text interleaved数据通过图像encoder和文本encoder得到多模态的特征序列 , 作为 的输入, 对下一个token进行预测。
预训练损失为 , 其中对于文本输出的token来说, 损失为 cross-entropy loss, 对于视觉token来说, 损失为 。VL-GPT也用到了LLaVA、SVIT、 InstructPixPix、Magicbrush和COCO Caption的数据进行指令微调。
更多的细节可以refer原文。
VILA
《VILA: On Pre-training for Visual Language Models》是NVIDIA和MIT提出的一个工作,文中对视觉语言模型预训练的有效机制进行了一些总结,并提出了一系列视觉语言的大模型VILA(Visual Language)。
Fig 10
模型的结构如图Fig 10左图所示,和LLaVA系列差不多,模型的训练包含三个阶段,如图Fig 10所示。
- LLM和ViT都是单独训练的,连接LLM和ViT的projector是随机初始化的,因此会首先对projector做训练。
- 这一个阶段对LLM和projector进行训练。
- 第二个阶段则是对预训练的模型进行视觉指令微调。
通过一系列的实验,文中得到了下面的三个结论:
- LLM冻结与更新:在预训练过程中,冻结大型语言模型(LLM)可以实现不错的零样本(zero-shot)性能,但缺乏上下文学习能力(in-context learning capability)。为了获得更好的上下文学习能力,需要对LLM进行更新。实验表明,更新LLM有助于在更深层次上对齐视觉和文本的潜在嵌入,这对于继承LLM的上下文学习能力至关重要。
- 交错预训练数据:交错的视觉语言数据(如MMC4数据集)对于预训练是有益的,而仅使用图像-文本对(如COYO数据集)则不是最佳选择。交错数据结构有助于模型在保持文本能力的同时,学习与图像相关的信息。
- 文本数据重混合:在指令微调(instruction fine-tuning)阶段,将文本指令数据重新混合到图像-文本数据中,不仅能够修复LLM在文本任务的性能退化,还能提高视觉语言任务的准确性。这种数据混合策略有助于模型在保持文本能力的同时,提升对视觉语言任务的处理能力。
EMU2
《Generative Multimodal Models are In-Context Learners》是Emu的团队提出的另外一个工作,文中提出的多模态大语言模型Emu2对Emu进行了一些结构和训练策略上的改进。
- Generative Multimodal Models are In-Context Learners(https://arxiv.org/abs/2312.13286)
- https://github.com/baaivision/Emu
- https://baaivision.github.io/emu2/
Fig 11
模型的结构如图Fig 11所示,包含三个部分:Visual Encoder、Multimodal LLM和Visual Decoder,文中分别用EVA-02-CLIP-E-plus、LLaMA-33B和SDXL对上述的三个模块进行参数初始化。和Emu相比,少了Casual Transformer,输入的图片通过mean pooling以及Visual Encoder提取图像特征之后,通过线性映射连接Visual Encoder和Multimodal LLM。
在预训练阶段,用到的训练数据包括image-text pair形式的数据(LAION-2B、CapsFusion-120M)、video-text pair形式的数据(WebVid-10M)、interleaved image-text形式的数据(Multimodal-C4 MMC4)、interleaved video-text形式的数据(YT-Storyboard-1B)、grounded image-text pair形式的数据(GRIT-20M、CapsFusoion-grounded-100M),同时为了保持模型的文本推理能力,还在只有文本数据的Pile上对模型进行了训练。图片都会通过visual encoder得到大小为的图像特征序列。
- 模型首先在image-text和video-text形式的数据上做了训练,损失函数只在text token上进行了计算。
- 接下来,固定住Visual Encoder的参数,对linear projection layer和Multimodal LLM的参数进行训练,包括文本的分类损失(这儿应该就是Cross Entropy)以及图像回归损失(针对图像特征的损失)。训练的时候,所有形式的数据都用来对模型进行了训练。
- 最后会对Visual Decoder进行训练,文中用SDXL-base对Visual Decoder的参数进行初始化,LLM输出的 大小为的图像特征序列会做为Decoder的条件,引导图片或者视频的生成。用到的训练数据包括LAION-COCO和LAION-Aesthetics,SDXL里面的Visual Encoder和VAE的参数都会固定不变,只有U-Net的参数会进行更新。
在指令微调阶段,用不同类型的数据,得到两个不同的指令微调模型,分别为Emu2-Chat和Emu2-Gen。Emu2-Chat可以基于多模态的输入得到对应的输出,Emu2-Gen则是接受文本、位置和图片的输入,生成符合输入条件的图片。
在训练Emu2-Chat的时候,用到了两种类型的数据,分别为academic-task-oriented 数据和multi-modal chat数据。academic-task-oriented数据包括image caption数据(比如COCO Caption和TextCaps)、visual question-answering数据(比如VQAv2、OKVQA、GQA、TextVQA)以及多模态分类数据(M3IT、RefCOCO、RecCOCO+和RefCOCOg),对应的system message为。multi-modal chat数据则是包括GPT辅助生成的数据(LLaVA和LLaVaR里面的数据)、来自于ShareGPT和Alpaca的语言指令数据和来自于VideoChat的视频指令数据,对应的system message为
![]()
在训练Emu2-Gen的时候,用到的数据包括CapsFusion-grounded-100M、Kosmos-2提到的GRIT、InstructPix2Pix里面数据、CapsFusion、LAION-Asthetics、SA-1B和LAION-High-Resolution,文中还从其他付费渠道收集了数据(比如Unsplash、Midjourney-V5和DALL-E-3生成的图片等)。和其他多模态大模型不一样,物体的坐标不是以文本的形式或者ROI特征向量的方式送入LLM,而是直接在黑白图片上对应的坐标位置处绘制相应的框,得到的图片通过Visual Encoder提取特征。整个序列如下:<s>A photo of <p>a man</p><coor>image embedding of object localization image</coor>[IMG]image embedding of man[/IMG]sitting next to <p>a dog</p><coor>image embedding of object localization image</coor>[IMG]image embedding of dog[/IMG][IMG]image embedding of the whole image[/IMG]</s>
Fig 12
生成的一些示例图片如图Fig 12所示。
DeLVM
《Data-efficient Large Vision Models through Sequential Autoregression》是华为诺亚实验室的一个工作,是在LVM基础上提出的一个工作。
- Data-efficient Large Vision Models through Sequential Autoregression(https://arxiv.org/abs/2402.04841)
- https://github.com/ggjy/DeLVM
Fig 13
模型结构和LVM一直,如图Fig 13 a 所示,这篇文章主要在两个方面做了改进探索,比如数据增强和蒸馏。数据增强主要是对存在长尾分布的数据中数量较少的这一类型的数据做重复的采样,也提高这部分数据的数量。
AIM
《Scalable Pre-training of Large Autoregressive Image Models》是苹果提出的一个工作,也是通过自回归的方式训练视觉基础模型,也发现了和LVM类似的和数据、模型参数量有关的Scaling效果,不过实现方式和LVM还是存在不小的差异。
- Scalable Pre-training of Large Autoregressive Image Models(https://arxiv.org/abs/2401.08541)
- https://github.com/apple/ml-aim
Fig 14
模型预训练时候的结构如图Fig 14所示, 输入图片划分为没有overlap且分辨率相同的patch , 并通过步长和kernel size大小相同的卷积层得到patch的特征, 得到的图像特征序列通过Causal Transformer按照raster order预测下一个特征序列, 得到特征向量通过一个MLP层得到对应的pixel。和LVM不一样, 没有采用VQ-GAN里面的image tokenizer、detokenizer和codebook。
AIM在DFN数据集上进行了预训练, 训练的损失函数为标准的预测下一个元素的自回归损失, 即

,在具体实现的时候则是
![]()
损失,即输入的图片patch为

, 预测的图片patch为

, 损失和MAE一样, 都是pixel级别的损失, 即

。文中也采用了和LVM类似的方式,用到了VQ-GAN类似的tokenizer,损失采用cross-entropy损失,但是效果不如pixel-wise的损失。
视觉基础模型按照自回归、causal attention的方式进行预训练, 即 , 其中

但是下游的任务一般是bidirectional attention, 为了弥补这种差异性, 文中把图像特征序列的前几个序列看作是prefix, 这部分序列在transformer里面按照bidirectional attention提取特征, 且不计算 loss, prefix的序列长度为 , 这部分序列的attentiom只大于 0 , 即 。如图Fig 15 所示。
Fig 15
如图Fig 16,AIM观察到了和LVM一样的Scaling现象,即模型参数量越多,训练的时候损失下降越快,效果也更好。在图Fig 17中也可以看到,训练的数据量越大,在验证集上的损失下降就越低。
Fig 16
Fig 17
整体来说,是非常solid的一个工作,更多的细节可以refer原文。
#免费将照片转换为吉卜力艺术图
您是吉卜力工作室梦幻艺术风格的忠实粉丝吗?如果我们说你可以用自己的照片免费制作吉卜力的作品呢?使用 Python 和 AI — 这并不像听起来那么难!
我将向您展示如何使用 Python 生成照片,使其看起来像来自吉卜力电影。
您需要的内容:
- 要转换的照片
- 计算机上安装的 Python
- 用于样式迁移的免费 AI 模型
第 1 步:安装所需的库
首先,打开您的 Python 环境并安装以下内容:
pip install torch torchvision pillow requests这些有助于 AI 和图像处理。
第 2 步:加载 Ghibli 风格的模型
我们将使用免费的 Ghibli AI 生成器模型。您可以在线找到预训练模型(搜索“Ghibli art style transfer model”)。
from PIL import Image
import torch
from torchvision import transforms
import requests
# Download a Ghibli-style model (example)
model_url = "https://huggingface.co/some-ghibli-model/resolve/main/model.pth"
response = requests.get(model_url)
with open("ghibli_model.pth", "wb") as f:
f.write(response.content)
# Load model
model = torch.load("ghibli_model.pth")
model.eval()第 3 步:应用 Ghibli Style Transfer
现在,让我们将您的照片变成吉卜力艺术绘画风格:
# Load and process your image
input_image = Image.open("your_photo.jpg")
preprocess = transforms.Compose([
transforms.Resize(512),
transforms.ToTensor(),
])
input_tensor = preprocess(input_image).unsqueeze(0)
# Apply style transfer
with torch.no_grad():
output = model(input_tensor)
# Save result
output_image = transforms.ToPILImage()(output.squeeze(0))
output_image.save("ghibli_output.jpg")现在检查您的文件夹 — 您应该会看到吉卜力风格的照片版本!
注意:最简单的方法是使用 Google Colab:
https://colab.research.google.com/github/justinjohn0306/Studio-Ghibli-Style-Transfer/blob/main/Ghibli_Style_Transfer.ipynb- 转到这个 Colab 笔记本(不是我的,但它有效)。
- 单击 “Runtime” > “Run all”。
- 出现提示时上传您的照片。
- 等待 ~5 分钟,您将获得吉卜力风格的版本!


获得更好结果的提示
- 使用清晰、高质量的照片以获得最佳效果。
- 尝试不同的 Ghibli AI 生成器免费模型,看看你喜欢哪种风格。
- 如果颜色看起来不对劲,请在编辑器中调整亮度/对比度。
常见问题
Q1:我可以在不编码的情况下执行此作吗?是的!一些网站提供 Ghibli 艺术风格的过滤器,但 Python 为您提供更多控制权。
Q2: 为什么我的输出看起来模糊不清?该模型可能并不完美。尝试不同的一个或调整图像大小。
Q3:这真的免费吗?是的,如果您使用免费模型和自己的照片。有些工具会收费,但 Python 允许您自己作。
#WinForm 任意控件绘制形状图形
(实现添加、删除、选中、移动、缩放功能)
Windows桌面应用程序开发的需求不断增长,WinForm 作为微软.NET 框架的一部分,因其易用性和高效性而受到许多开发者的青睐。对于初学者来说,通过拖拽控件快速搭建用户界面是一个非常友好的入门方式。
本文将详细探讨如何使用WinForm在C#中实现绘制基本图形(如矩形),并演示如何添加、删除、选中、移动以及缩放这些图形元素。所有示例均基于Windows 11操作系统和Visual Studio 2022编程环境,并使用了.NET Framework 4.6.0版本。
开发环境
操作系统:Windows 11
编程软件:Visual Studio 2022
.NET框架版本:.Net Framework 4.6.0
实现图形绘制功能
本文主要介绍如何在任意Control上绘制形状,具体包括以下功能:
1、绘制矩形
能够创建不同样式(不透明、透明、半透明)的矩形。
2、交互操作
按住鼠标左键并拖动来移动矩形。
点击矩形以选中它。
使用鼠标滚轮对选定矩形进行缩放。
3、通用性
只需传入目标控件对象作为参数,即可实现在该控件上的图形绘制功能。
演示案例

代码说明
创建形状的基础类:Shape
为了实现对图形的统一管理和操作,首先需要定义一个基础的Shape类,用于描述所有形状的通用属性和行为。
以下是该类的主要设计内容:
基本属性
1、ID
每个形状对象都拥有唯一的标识符(ID),用于快速查找、选中或操作特定形状。
2、颜色、线宽与透明度(Alpha)
颜色:定义形状的填充颜色或边框颜色。
线宽:设置形状边框的宽度,适用于矩形等有边界形状。
透明度(Alpha):通过调整颜色的Alpha通道值,支持不透明、半透明或完全透明的效果。
3、矩形手柄(调整大小)
定义多个矩形手柄(通常为小方块),分布在形状的边缘或角落,用于调整形状的大小。
4、选中状态
标记当前形状是否被选中。当选中时,显示手柄;未选中时,隐藏手柄。
基本方法(抽象方法)
为了确保每种形状都能实现必要的功能,Shape类定义了以下抽象方法,供子类继承并实现:
1、判断点是否在手柄上
方法签名:bool IsPointInHandle(Point point)
功能:根据鼠标点击的坐标,判断该点是否落在某个手柄上。如果是,则返回true,否则返回false。
2、判断显示手柄的方向类型
方法签名:HandleDirection GetHandleDirection(Point point)
功能:根据鼠标位置,判断当前手柄的方向类型(如左、右、上、下、左上角、右下角等)。这有助于后续调整形状大小时确定拉伸方向。
3、绘制矩形
方法签名:void DrawRectangle(Graphics g)
功能:使用Graphics对象绘制矩形的主体部分,包括填充颜色、边框样式和透明度。
4、绘制手柄
方法签名:void DrawHandles(Graphics g)
功能:绘制矩形的手柄,通常以小方块的形式分布在矩形的边缘或角落。手柄的颜色和大小可以根据需求自定义。
设计思路
通过将形状的基本属性和行为抽象到Shape类中,可以为后续扩展其他形状(如圆形、椭圆等)提供统一的接口。同时,这种设计方式符合面向对象编程的原则,便于代码的维护和扩展。
例如,当需要新增一种形状(如三角形)时,只需继承Shape类并实现上述抽象方法即可,而无需修改现有代码。这种模块化的设计不仅提高了代码的复用性,还增强了程序的可读性和灵活性。
应用场景
绘图工具:用户可以通过鼠标点击和拖动,在画布上添加、移动或缩放矩形等形状。
交互式界面:在窗体控件中动态绘制形状,并支持实时调整大小和位置。
自定义控件开发:结合WinForms的事件机制,实现复杂图形的交互功能。
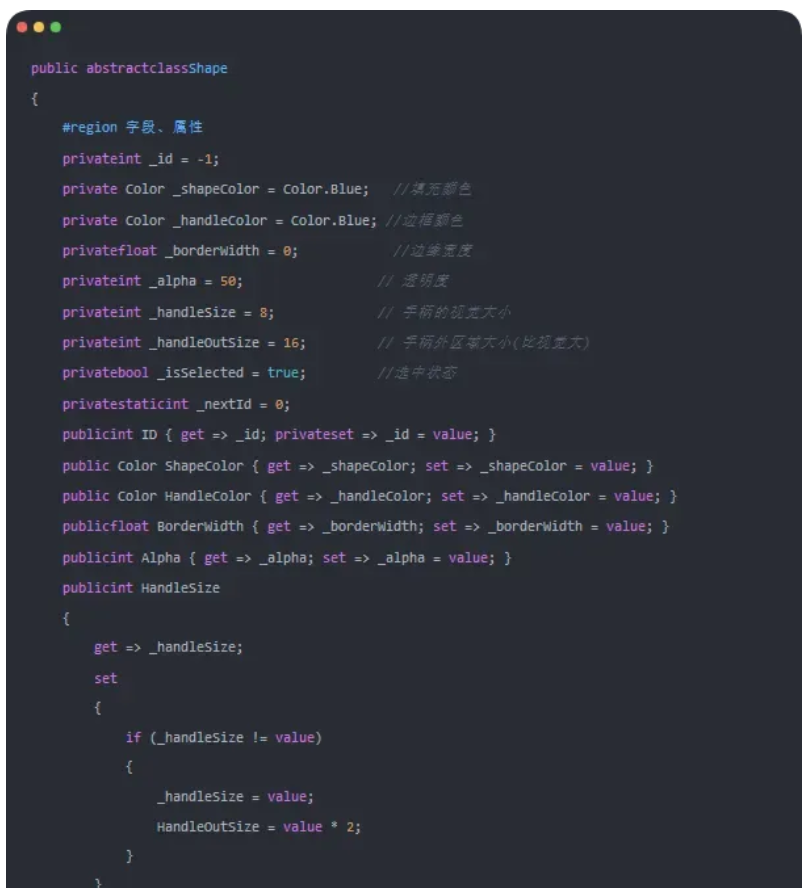
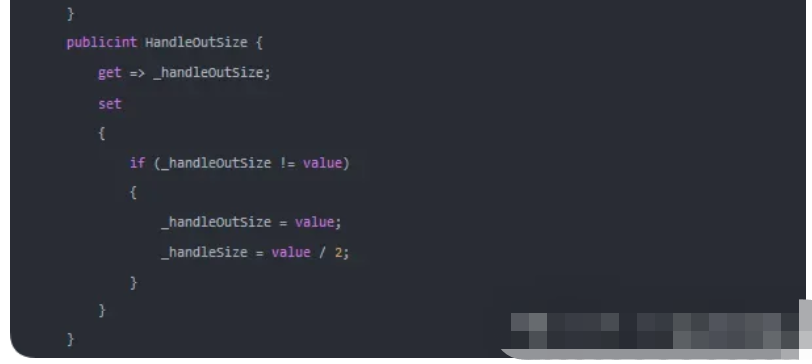
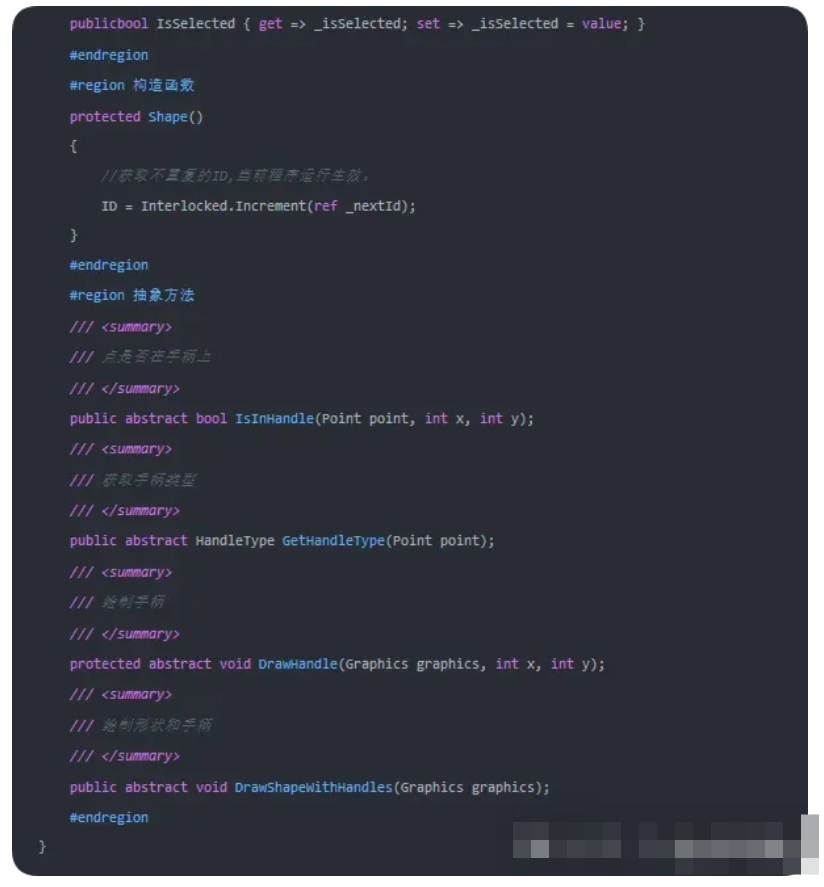
URectangle 类:继承自 Shape 类
URectangle 类继承自 Shape 类,用于创建矩形对象,并实现具体的绘制功能。
基本属性
X, Y:矩形左上角的坐标。
Width, Height:矩形的宽度和高度。
Rectangle:表示实际显示的矩形(整数坐标)。
RectangleF:用于缩放或转换的矩形(浮点数坐标)。
重写方法
重写 Shape 类中的方法,实现矩形的具体绘制功能:
绘制矩形主体。
支持缩放和转换操作。
通过继承 Shape 类,URectangle 实现了矩形的统一管理与具体功能。
publicclassURectangle: Shape
{
#region 字段|属性
private Rectangle rectangle;
public Rectangle Rectangle
{
get => rectangle;
set => rectangle = value;
}
private RectangleF rectangleF;
public RectangleF RectangleF
{
get => rectangleF;
set => rectangleF = value;
}
publicint X {
get { return rectangle.X; }
set
{
if (rectangle != null) rectangle.X = value;
}
}
publicint Y {
get { return rectangle.Y; }
set
{
if (rectangle != null) rectangle.Y = value;
}
}
public Point Point
{
get => new Point(X, Y);
set
{
X = value.X;
Y = value.Y;
}
}
publicint Width {
get => rectangle.Width;
set
{
if (rectangle!=null)
{
rectangle.Width = value;
}
}
}
publicint Height {
get => rectangle.Height;
set
{
if (rectangle != null)
{
rectangle.Height = value;
}
}
}
public Size Location
{
get => new Size(Width, Width);
set
{
Width = value.Width;
Width = value.Width;
}
}
#endregion
#region 构造函数
publicURectangle():base()
{
}
publicURectangle(Rectangle rectangle)
{
this.rectangle = rectangle;
}
#endregion
#region 绘制矩形相关
///<summary>
/// 绘制矩形和手柄(选中时绘制):
///</summary>
publicoverridevoidDrawShapeWithHandles(Graphics graphics)
{
using (var brush = new SolidBrush(Color.FromArgb(Alpha, ShapeColor)))
{
graphics.FillRectangle(brush, rectangle);
}
Pen pen = new Pen(ShapeColor, BorderWidth);
graphics.DrawRectangle(pen, rectangle);
if (IsSelected)
{
DrawHandle(graphics, rectangle.Left, rectangle.Top); // 左上角
DrawHandle(graphics, rectangle.Right, rectangle.Top); // 右上角
DrawHandle(graphics, rectangle.Left, rectangle.Bottom); // 左下角
DrawHandle(graphics, rectangle.Right, rectangle.Bottom); // 右下角
}
}
///<summary>
/// 绘制手柄:
///</summary>
protectedoverridevoidDrawHandle(Graphics graphics, int x, int y)
{
Rectangle handleRect = new Rectangle( x - HandleSize / 2,y - HandleSize / 2,HandleSize,HandleSize);
using (var brush = new SolidBrush(Color.FromArgb(Alpha, HandleColor)))
{
graphics.FillRectangle(brush, handleRect);
}
Pen pen = new Pen(HandleColor, BorderWidth);
graphics.DrawRectangle(pen, handleRect);
}
///<summary>
/// 获取要显示的手柄类型:根据指定点,判断当前矩形应该使用什么类型的手柄。
///</summary>
publicoverride HandleType GetHandleType(Point point)
{
if (IsInHandle(point, rectangle.Left, rectangle.Top))
return HandleType.TopLeft;
if (IsInHandle(point, rectangle.Right, rectangle.Top))
return HandleType.TopRight;
if (IsInHandle(point, rectangle.Left, rectangle.Bottom))
return HandleType.BottomLeft;
if (IsInHandle(point, rectangle.Right, rectangle.Bottom))
return HandleType.BottomRight;
return HandleType.None;
}
///<summary>
/// 指定点是否在手柄范围内
///</summary>
publicoverrideboolIsInHandle(Point point, int x, int y)
{
Rectangle handleRect = new Rectangle(x - HandleOutSize / 2,y - HandleOutSize / 2,HandleOutSize,HandleOutSize);
return handleRect.Contains(point);
}
#endregion
}ShapeModule 类:绘制形状到控件容器的实现 为了将创建的基本形状(如 URectangle)绘制到控件容器中,需要设计一个模块来处理与容器相关的事件绑定和操作逻辑。
以下是详细的设计思路和实现步骤:
功能概述
1、创建形状对象
使用 URectangle 类创建基本形状对象。
形状对象的属性包括位置、大小、颜色等。
2、绑定事件
将容器的相关事件(如鼠标按下、移动、释放、绘制等)绑定到对应的事件处理函数中。
通过这些事件,实现形状的绘制、选中、拖动、调整大小等功能。
核心事件及功能实现
Container_MouseDown
功能:判断鼠标点击位置是否在某个形状上或手柄上,并决定执行的操作。
如果点击空白区域:开始绘制新形状。
如果点击已有形状:选中该形状。
如果点击手柄:进入调整大小模式。
触发条件:鼠标左键按下时触发。
publicclassShapeModule
{
#region 字段 | 属性
privatefloat scaleX = 1.0f; //缩放X
privatefloat scaleY = 1.0f; //缩放Y
privatebool isScaled = false; //是否缩放
privateint selectedIndex = -1; //选择索引
private DrawMode currentMode = DrawMode.None; //当前模式
private HandleType handleType = HandleType.None; //手柄类型
private Point startPoint; //起始点
private Control container; //形状显示容器
private URectangle currentRect; //当前矩形
private URectangle displayRect; //选择的矩形
private ContextMenuStrip rightKeyMenuStrip; //右键菜单
private Dictionary<int, Shape> _shapeDictionary; //形状存储字典
publicfloat ScaleX
{
get => scaleX;
set
{
scaleX = value;
UpdateDisplayShape();
}
}
publicfloat ScaleY
{
get => scaleY;
set
{
scaleY = value;
UpdateDisplayShape();
}
}
public DrawMode CurrentMode
{
get => currentMode;
set => currentMode = value;
}
public Dictionary<int, Shape> ShapeDictionary { get => _shapeDictionary;privateset => _shapeDictionary = value; }
#endregion
#region 构造函数
publicShapeModule(Control container)
{
Initialize(container);
}
#endregion
#region 初始化
privatevoidInitialize(Control container)
{
this.container = container;
ShapeDictionary = new Dictionary<int, Shape>();
InitializeContainer();
InitializeRightKeyMenu();
}
#region 初始化容器
privatevoidInitializeContainer()
{
container.MouseDown += Container_MouseDown;
container.MouseUp += Container_MouseUp;
container.MouseMove += Container_MouseMove;
container.MouseUp += Container_MouseUp;
container.MouseWheel += Container_MouseWheel;
container.Paint += Container_Paint;
}
#endregion
#region 右键菜单功能
privatevoidInitializeRightKeyMenu()
{
// 创建菜单项
rightKeyMenuStrip = new ContextMenuStrip();
var copyItem = new ToolStripMenuItem("复制");
copyItem.Click += (s, e) => CopyAction();
var deleteItem = new ToolStripMenuItem("删除");
deleteItem.Click += (s, e) => DeleteAction();
// 创建右键菜单
rightKeyMenuStrip.Items.Add(copyItem);
rightKeyMenuStrip.Items.Add(deleteItem);
}
privatevoidCopyAction()
{
}
privatevoidDeleteAction()
{
ShapeDictionary.Remove(selectedIndex);
selectedIndex = -1;
container.Invalidate();
}
#endregion
#endregion
#region 形状显示相关:缩放、显示
///<summary>
/// 更新显示形状
///</summary>
privatevoidUpdateDisplayShape()
{
foreach (var shape in ShapeDictionary.Values)
{
if (shape is URectangle rectangle)
{
rectangle.Rectangle = new Rectangle(
(int)(rectangle.RectangleF.X * scaleX),
(int)(rectangle.RectangleF.Y * scaleY),
(int)(rectangle.RectangleF.Width * scaleX),
(int)(rectangle.RectangleF.Height * scaleY));
}
}
container.Invalidate();
}
///<summary>
/// 缩小
///</summary>
private RectangleF ScaleDown(Rectangle rect)
{
returnnew RectangleF(
rect.X / scaleX,
rect.Y / scaleY,
rect.Width / scaleX,
rect.Height / scaleY);
}
///<summary>
/// 放大
///</summary>
private Rectangle ScaleUp(RectangleF rect)
{
returnnew Rectangle(
(int)(rect.X * scaleX),
(int)(rect.Y * scaleY),
(int)(rect.Width * scaleX),
(int)(rect.Height * scaleY));
}
///<summary>
/// 放大
///</summary>
privatevoidZoomIn()
{
ScaleX += 0.1F;
ScaleY += 0.1F;
}
///<summary>
/// 缩小
///</summary>
privatevoidZoomOut()
{
ScaleX -= 0.1F;
ScaleY -= 0.1F;
}
#endregion
#region 事件
privatevoidContainer_MouseDown(object sender, MouseEventArgs e)
{
if (e.Button == MouseButtons.Left)
{
// 形状绘制
if (CurrentMode == DrawMode.Drawing)
{
currentRect = new URectangle();
startPoint = e.Location;
currentRect.Rectangle = new Rectangle(e.Location, Size.Empty);
}
// 形状移动
elseif (CurrentMode == DrawMode.Moving)
{
int dx = e.X - startPoint.X;
int dy = e.Y - startPoint.Y;
displayRect.X += dx;
displayRect.Y += dy;
displayRect.RectangleF = ScaleDown(displayRect.Rectangle);
startPoint = e.Location;
}
// 形状调整大小
elseif (CurrentMode == DrawMode.Resizing)
{
Rectangle rect = displayRect.Rectangle;
switch (handleType)
{
case HandleType.TopLeft:
rect.X = e.X;
rect.Y = e.Y;
rect.Width = displayRect.Rectangle.Right - e.X;
rect.Height = displayRect.Rectangle.Bottom - e.Y;
break;
case HandleType.TopRight:
rect.Y = e.Y;
rect.Width = e.X - displayRect.Rectangle.Left;
rect.Height = displayRect.Rectangle.Bottom - e.Y;
break;
case HandleType.BottomLeft:
rect.X = e.X;
rect.Width = displayRect.Rectangle.Right - e.X;
rect.Height = e.Y - displayRect.Rectangle.Top;
break;
case HandleType.BottomRight:
rect.Width = e.X - displayRect.Rectangle.Left;
rect.Height = e.Y - displayRect.Rectangle.Top;
break;
}
// 确保宽度和高度不为负
if (rect.Width > 0 && rect.Height > 0)
{
displayRect.RectangleF = ScaleDown(rect);
displayRect.Rectangle = rect;
}
}
// 形状判断选择
else
{
selectedIndex = -1;
foreach (var shape in ShapeDictionary.Values)
{
if (shape is URectangle uRectangle)
{
if (uRectangle.Rectangle.Contains(e.Location)
|| uRectangle.GetHandleType(e.Location) != HandleType.None)
{
selectedIndex = uRectangle.ID;
displayRect = uRectangle;
startPoint = e.Location;
handleType = uRectangle.GetHandleType(e.Location);
CurrentMode = handleType != HandleType.None ? DrawMode.Resizing : DrawMode.Moving;
break;
}
}
}
}
}
//右键菜单
if (e.Button == MouseButtons.Right)
{
if (selectedIndex != -1)
{
rightKeyMenuStrip.Show(container, e.Location);
}
}
container.Invalidate();
}
privatevoidContainer_MouseMove(object sender, MouseEventArgs e)
{
if (e.Button == MouseButtons.Left)
{
if (CurrentMode == DrawMode.Drawing)
{
int x = Math.Min(startPoint.X, e.X);
int y = Math.Min(startPoint.Y, e.Y);
int width = Math.Abs(startPoint.X - e.X);
int height = Math.Abs(startPoint.Y - e.Y);
currentRect.Rectangle = new Rectangle(x, y, width, height);
}
elseif (CurrentMode == DrawMode.Moving && selectedIndex >= 0)
{
int dx = e.X - startPoint.X;
int dy = e.Y - startPoint.Y;
displayRect.X += dx;
displayRect.Y += dy;
ShapeDictionary[selectedIndex] = displayRect;
displayRect.RectangleF = ScaleDown(displayRect.Rectangle);
startPoint = e.Location;
}
elseif (CurrentMode == DrawMode.Resizing && selectedIndex >= 0)
{
Rectangle rect = displayRect.Rectangle;
switch (handleType)
{
case HandleType.TopLeft:
rect.X = e.X;
rect.Y = e.Y;
rect.Width = displayRect.Rectangle.Right - e.X;
rect.Height = displayRect.Rectangle.Bottom - e.Y;
break;
case HandleType.TopRight:
rect.Y = e.Y;
rect.Width = e.X - displayRect.Rectangle.Left;
rect.Height = displayRect.Rectangle.Bottom - e.Y;
break;
case HandleType.BottomLeft:
rect.X = e.X;
rect.Width = displayRect.Rectangle.Right - e.X;
rect.Height = e.Y - displayRect.Rectangle.Top;
break;
case HandleType.BottomRight:
rect.Width = e.X - displayRect.Rectangle.Left;
rect.Height = e.Y - displayRect.Rectangle.Top;
break;
}
if (rect.Width > 0 && rect.Height > 0)
{
displayRect.Rectangle = rect;
displayRect.RectangleF = ScaleDown(rect);
ShapeDictionary[selectedIndex] = displayRect;
}
}
}
else
{
if (selectedIndex >= 0)
{
handleType = displayRect.GetHandleType(e.Location);
switch (handleType)
{
case HandleType.TopLeft:
case HandleType.BottomRight:
container.Cursor = Cursors.SizeNWSE;
break;
case HandleType.TopRight:
case HandleType.BottomLeft:
container.Cursor = Cursors.SizeNESW;
break;
default:
container.Cursor = displayRect.Rectangle.Contains(e.Location) ?
Cursors.SizeAll : Cursors.Default;
break;
}
}
else
{
container.Cursor = Cursors.Default;
}
}
container.Invalidate();
}
privatevoidContainer_MouseUp(object sender, MouseEventArgs e)
{
if (e.Button == MouseButtons.Left)
{
if (CurrentMode == DrawMode.Drawing && currentRect.Width > 0 && currentRect.Height > 0)
{
currentRect.RectangleF = ScaleDown(currentRect.Rectangle);
ShapeDictionary.Add(currentRect.ID, currentRect);
selectedIndex = currentRect.ID;
displayRect = currentRect;
startPoint = e.Location;
handleType = currentRect.GetHandleType(e.Location);
CurrentMode = handleType != HandleType.None ? DrawMode.Resizing : DrawMode.Moving;
}
CurrentMode = DrawMode.None;
container.Invalidate();
}
}
privatevoidContainer_Paint(object sender, PaintEventArgs e)
{
foreach (var shape in ShapeDictionary.Values)
{
if (shape.ID == selectedIndex)
{
shape.IsSelected = true;
shape.ShapeColor = Color.Red;
shape.HandleColor = Color.White;
}
else
{
shape.IsSelected = false;
shape.ShapeColor = Color.Blue;
shape.HandleColor = Color.White;
}
shape.DrawShapeWithHandles(e.Graphics);
}
if (currentRect == null) return;
if (CurrentMode == DrawMode.Drawing)
{
using (var brush = new SolidBrush(Color.FromArgb(50, 0, 0, 255)))
{
e.Graphics.FillRectangle(brush, currentRect.Rectangle);
}
e.Graphics.DrawRectangle(Pens.Blue, currentRect.Rectangle);
}
}
privatevoidContainer_MouseWheel(object sender, MouseEventArgs e)
{
if (e.Delta > 0) ZoomOut();
elseif (e.Delta < 0) ZoomIn();
}
#endregion
}枚举
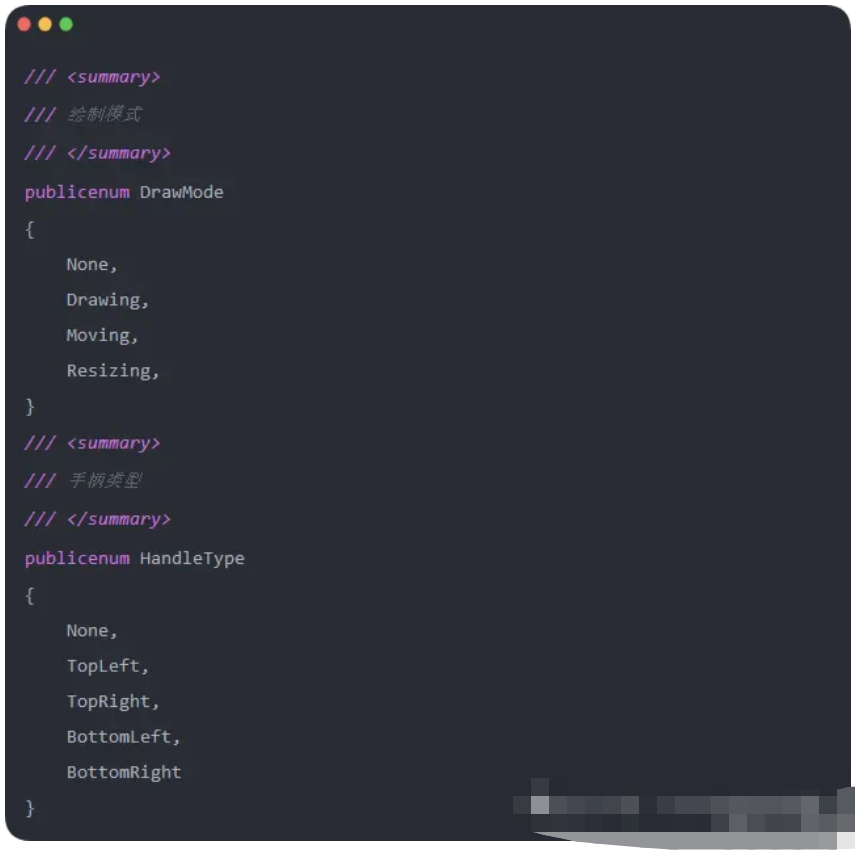
用户界面代码
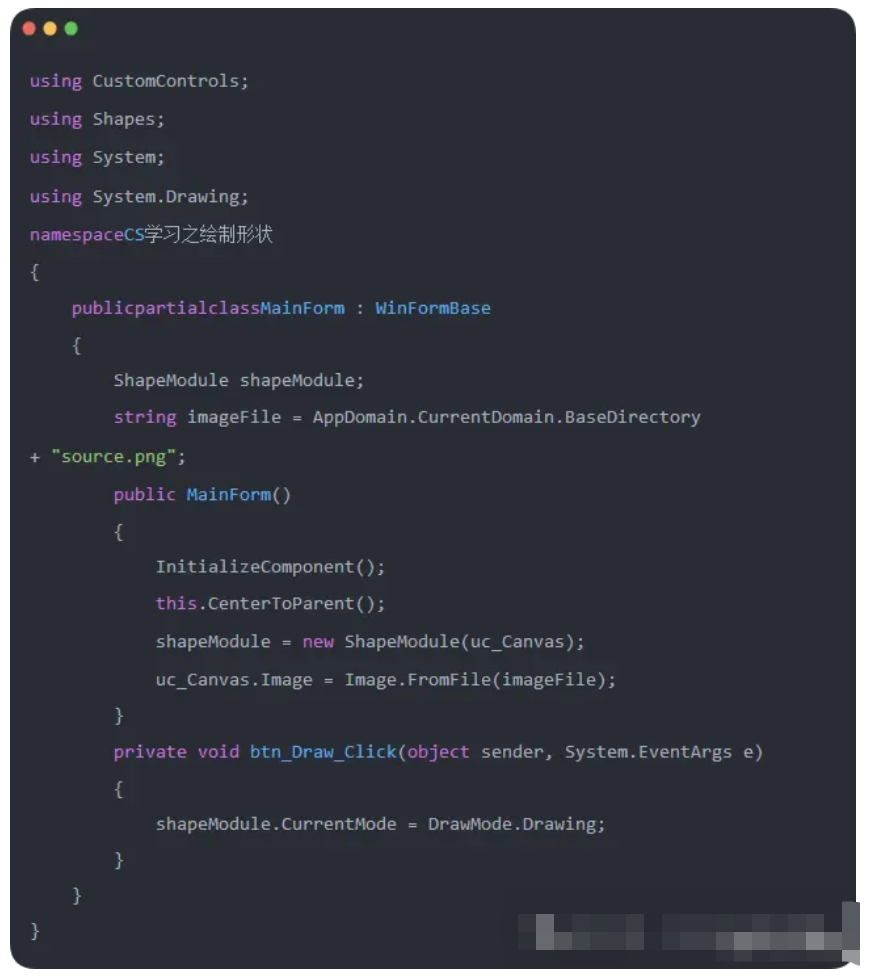
双缓存图像控件
用户界面

总结
该用户界面为前几期的内容创建,如想使用可翻阅前面的内容查看代码。
不使用该窗体也可以使用自定义的Form窗体,只需添加按钮,添加任意控件即可,注意设置Dock属性为Fill。
控件最好设置双缓冲,否则会出现界面闪烁。
设计缺陷:当用户自定义控件绘制图像时,如果也创建了下面实现的事件如鼠标按下事件(MouseDown),可能会起冲突。
DoubleBuffered = true; //启用双缓冲项目源码

















 1366
1366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









