







我自己的原文哦~ https://blog.51cto.com/whaosoft/13905076
#Executor-Workers架构
图解Vllm V1系列2
本文详细介绍了vllm v1的Executor-Workers架构,包括Executor的四种类型(mp、ray、uni、external_launcher)及其适用场景,以及通过图解展示了Executor与Workers之间的数据传输机制和整体架构,帮助读者理解vllm v1在分布式推理中的核心设计和运作方式。
前文:图解Vllm V1系列1:整体流程
在前文中,我们讨论了 vllm v1 在 offline batching / online serving 这两种场景下的整体运作流程,以offline batching为例:

整体上来看:
vllm v1将请求的pre-process和输出结果的post-process与实际的推理过程拆分在2个不同的进程中(process0, process1)。
Client负责请求的pre-process和输出结果的post-process,EngineCore负责实际的推理过程,不同进程间使用ZMQ来通信数据。
对于offline batching和online serving来说,它们会选取不同类型的Client进行运作,但是它们的EngineCore部分运作基本是一致的,如上图所示。
通过这样的进程拆分,在更好实现cpu和gpu运作的overlap的同时,也将各种模型复杂的前置和后置处理模块化,统一交给processor和output_processor进行管理。
本文我们来关注上图中的Executor部分,也就是管控模型分布式推理的核心部分,我们关注的是它的整体架构和初始化过程,而它实际执行推理的细节,我们留到后续文章细说。
一、Executor的类型
在vllm中,Executor一共有4种类型,由配置参数--distributed-executor-backend决定,相关的代码和文档参见:
代码:
- 决定executor的类型:https://github.com/vllm-project/vllm/blob/refs/tags/v0.8.2/vllm/config.py#L1465
- 根据executor的类型,import具体的executor:https://github.com/vllm-project/vllm/blob/refs/tags/v0.8.2/vllm/v1/executor/abstract.py#L25
文档:
对于--distributed-executor-backend,默认情况下为None,你当然也可以手动指定。在默认情况下,vllm会根据你的分布式配置(world_size)和你所使用的平台特征(cuda、neuron、是否安装/初始化/配置了ray等)来自动决定--distributed-executor-backend的取值。
我们来简单介绍下这4种类型的Executor。
(1)mp:MultiprocExecutor
- 适用场景:单机多卡。当单机的卡数满足分布式配置,且没有正在运行的ray pg时,默认使用mp
- 在mp的情况下,Executor成为一个主进程,其下的若干个workers构成了它的子进程们
(2)ray:RayDistributedExecutor
- 适用场景:多机多卡
- 在ray的情况下,Executor成为一个ray driver process,其下管控着若干worker process
(3)uni:UniProcExecutor
- 适用场景:单卡或 Neuron环境
(4)external_launcher:ExecutorWithExternalLauncher
- 适用场景:想要用自定义的外部工具(例如Slurm)来做分布式管理
注意:以上的“适用场景”描述的是一般情况,更具体的细节,请参见“决定executor类型”的相关代码。
在本文中,我们将以mp: MultiProcExecutor进行讲解,并假设这里的分布式配置仅用了tp,其余的细节留给用户自行阅读。
二、Executor -> Workers
2.1 整体架构-官网版
我们先来看下官方给出的Executor-Workers架构图。

上图右侧刻画了V1的架构:
- Scheduler和Executor都位于EngineCoreProc所在的进程上。如本文第一章offline batching的流程图所示,Scheduler决定单次调度步骤中要送去推理的请求,并将这些请求发送给Executor。
- 一个Executor下管理着若干workers,每个workers位于独立的进程上,可以理解成一个workers占据着一张卡
- Executor负责把请求broadcast到各个workers上
- 各个workers接收到请求,负责执行实际的推理过程,并将推理结果返回给Executor。
相比于V0,V1这种架构设计的优势在于:在V0中,worker0既要负责调度和数据分发、又要负责实际的推理计算。如此一来,各个workers间存在负载不均的问题,而worker0将成为性能的瓶颈。而V1通过拆分【调度】和【计算】过程解决了这个问题。
2.2 整体架构-细节版
现在我们已经通过vllm官方的示例图,初步了解了V1下Executor-Workers的架构,现在我们扩展这张架构图,来看更多的细节,为了画图简明,这里我们只展示了其中1个worker,没有画出全部workers:

上图展示的是使用MultiprocExecutor下的架构,如前文所说,该类型的Executor常被用于单机多卡的推理场景,我们按照从上到下,从左到右的顺序来解读上图。
1、MultiprocExecutor和Scheduler都位于EngineCoreProc所在的进程中。Scheduler负责决定单次调度步骤中,要送去推理的reqs,并将这些reqs传递给MultiprocExecutor。
2、在MultiprocExecutor上,我们将创建一个rpc_broadcast_mq队列:
- 该队列存储着Executor要broadcast给各个workers的【小数据(<=10MB)】,而【大数据(>10MB)】则不会进入此队列,而是通过zmq socket进行传输
- 每条数据可以被粗糙理解成是(method, data)的形式,data = 数据本身,method=你期望worker上调用什么样的方法来处理这条数据。
- 针对这个队列、以及大小数据的传输细节,我们将在本文第三部分详细介绍。
3、在MultiProcExecutor上,通过make_worker_process创建子进程:
- 每个进程占据一张卡,每个进程上运行着一个worker实例
- 在创建每个子进程时,我们会将rpc_broadcast_mq_handler,也就是输入队列的句柄也传递给子进程,这里你可以粗糙将“handler(句柄)”理解成是一个“地址”,有了这个地址,每个子进程才知道要去哪里找到并【连接】这个队列,以此读到队列中的数据。相关细节我们同样在后文给出。
4、每个Worker实例又由以下几部分组成:
- WorkerWrapper,每个Worker实例都有属于自己的WorkerWrapper。你可以将它形象理解成是一个worker的manager,它负责管控一个worker的生命周期(创建->销毁)、所占资源、扩展功能(例如在rlhf场景下的一些功能)等等。
- Worker,真正的Worker实例,它上面维护着两个重要队列:
- rpc_broadcast_mq:正如3中所说,单个worker通过rpc_broadcast_mq_handler这个句柄,连接上了Executor的rpc_broadcast_mq队列,这样它就能从这个队列中读取(method, data)数据。注意,这里说的是【连接】而不是创建,为了强调这一点,图中单worker上的该队列用虚线表示。
- worker_response_mq:单个worker【创建】的、用于存放这个worker上推理输出结果的队列。同样也会产出worker_response_mq_handler这个句柄。后续这个句柄将通过zmq socket传送给Executor,让Executor可以连接上这个队列,这样Executor就可以获得每个worker的输出结果。
- ModelRunner,一个worker实例下维护着一个ModelRunner实例,这个实例上维护着模型权重分片(model weights sharding)、这块卡上的kv_caches、attn_backend等一系列的具体模型信息,它将最终负责模型权重的加载(load_model),并执行实际的推理过程。
5、连接Executor和Worker的ZMQ sockets:
- Executor和Worker分属不同的进程,这里依然采用ZMQ sockets做进程间的通信。
- 这里其实创建了多个不同socket(为了表达简便,我统一画成ZMQ sockets),每个socket会用于不同内容的通信,例如:
- ready_socket:worker进程向Executor发送ready信号 + worker_broadcast_mq_handler
- local_socket:如前文所说,**除了使用上述的2个队列做Executor->Worker间的输入输出通信外,我们还会直接使用local_socket做输入输出通信。前者用于单机内快速通信较小的数据(<=10MB),后者用于通信大数据(>10MB)**。我们会在后文细说这一点。
- 等等
**6、worker_busy_loop()**:
在worker上启动busy loop,持续监听Executor发送的数据、做推理、并将推理结果持续返回给Executor。这样一来,这个worker就无限运转起来了,除非收到用户信号,显式终止掉这个worker,否则这个busy loop不会停止。
到此为止,我们简单总结一下在Executor->Workers的初始化环节都做了什么事:
- 首先,按照上图所示,创建了Executor->Workers架构,特别注意上述2个输入输出队列的初始化和连接。
- 对于每个Worker,我们通过init_device(),将它绑到指定的卡上,并对它做分布式环境初始化(即制定它的分布式通信group)
- 对于每个worker,我们通过load_model(),当ModelRunner实际去加载这个worker所要的模型分片
- 在每个worker上启动run_busy_loop(),让worker持续不断地运转起来。 更多的细节,请大家自行阅读源码。
接下来,我们着重来讨论这rpc_broadcast_mq和worker_response_mq这两个输入输出队列。
三、Executor与Worker间的数据传输机制
我们先快速回顾一下上文的内容:
(1)在我们的例子中,Executor的具体类型是MultiprocExecutor,它一般适用于单机多卡推理。
(2)Executor和Worker分属不同的进程,Executor需要把输入数据broadcast到Worker上,Worker需要把推理的输出结果返回给Executor。
(3)对于小数据(<=10MB),vllm使用rpc_broadcast_mq和worker_response_mq来做数据传输,这两个队列的本质是ShmRingBuffer(环形共享缓存),其中Shm即我们熟知的shared_memory,而ring是使用环形的方式往shm中读写数据(看不懂也没关系,我们马上来说细节)。
(4)对于大数据(>10MB),vllm使用zmq socket来做数据传输。
为什么要设计2种不同的进程间通信机制,来分别处理【小数据】和【大数据】呢?这里简单说几个我能想到的原因:
(1)首先,通过shm的方式读写数据时,不同的进程都从同一块共享内存(shm)上直接读取,这样数据不需要从一个进程的地址空间复制到另一个进程的的地址空间,也就是可以实现数据的“零拷贝访问”
(2)其次,通过shm的方式读写数据时,可以避免网络协议栈和数据重复写入的开销,可以实现更高效、更快的数据访问。
(3)那么,既然shm这么好,为什么只让【小数据】使用它,而让【大数据】走zmq socket呢?这是因为shm是一块固定的内存大小,一旦预分配好,就不能被改变了。在实际使用场景中,可能需要传输的数据量本身就不大,只是会偶发出现一些【大数据】传输的情况,因此我们没必要预留更大的shm空间,来应对这些只是偶发情况,这样会造成内存的浪费。所以我们额外使用zmq socket来处理这些偶发情况。
3.1 ShmRingBuffer(共享环形缓存)
我们先来看小数据传输的实现机制,相关代码参见:
假设我们现在只使用tp,即一个Executor下有若干tp workers,那么:
- Scheduler生成单次调度的结果,将这些结果传递给Executor,我们称单次调度的结果为一个chunk
- Executor拿到单次调度的结果,写入rpc_broadcast_mq(本质是ShmRingBuffer)中
- 这些tp workers都需要从rpc_broadcast_mq读取这个chunk(每个tp worker的输入是相同的)
- 各个tp workers执行推理,并将推理结果写入各自维护的worker_broadcast_mq(本质是ShmRingBuffer)中。
- Scheduler继续生成单次调度结果(chunk),重复以上步骤。
- 不难发现,对于一个chunk,我们总有1个writer,和1个或若干个readers,例如:
- rpc_broadcast_mq的chunk中,writer = Executor,readers = tp workers
- worker_broadcast_mq的chunk中,writer = 某个tp worker,reader = Executor
现在,让我们将ShmRingBuffer想象成是一个存储站:
- 这个存储站中有max_chunks个柜子,每个柜子用于存储一块数据(chunk),max_chunk默认值为10
- 每个柜子的最大数据存储量为max_chunk_bytes,该值当前默认为10MB
- 每个柜子上有一个面板(metadata),这个面板上有1 + n_reader个指示灯。其中1这个指示灯代表written_flag,即用于指示writer是否把chunk塞进了柜子(写入完毕),n_reader个指示灯代表reader_flags,分别表示这些readers是否已经将这个chunk读取完毕。
- 由此可知,对于一个柜子,只有当writer写入完毕后,readers才可以去读。只有当所有readers都读取完毕后,这个柜子里的chunk才可以被“废弃”,也就是这个柜子才可以重新回到“可写入”的状态,让writer写入新数据。
- Scheduler在做一轮又一轮的调度,产出一个又一个的chunk,那么这些chunk就按照顺序,依次装入这些柜子中,当这10个柜子的数据都被轮番用过以后,下一次再来新chunk前,就从0号柜开始复用起(当然要按照上条所说的,检查该柜子是否达到可复用状态),这种环形使用的方式,称之为“ring”。
有了以上这个形象的理解,现在我们再回过头来看vllm代码中的这部分注释,就不难读懂了,而关于代码的更多细节,请大家自行阅读源码:


3.2 zmq socket
正如前文所说,在Executor和Worker间做大数据(>10MB)的传输时,可以使用zmq socket,这块就是传统的zmq socket构建流程了,没有太多可说的。这里我们想结合worker.worker_busy_loop()(也就是一个worker持续读取输入、进行推理、写入输出)的过程,来具体看一下shm和zmq socket是如何配合运作的。
worker_busy_loop()入口:

从代码中我们发现一件有趣的事:这里好像只从shm上读取数据,并没有通过zmq socket呀!不要紧,我们现在深入rpc_broadcast_mq.dequeue()中一探究竟。
rpc_broadcast_mq.dequeue():

整体上说:
- 当一个chunk过来时,我们会先检查它的大小:
- 如果<=10MB,则装入shm对应的柜子中
- 如果 > 10MB,则先在shm对应的柜子中记上一笔(buf[0]==1),然后再通过zmq sokcet去send这份数据
- 以上过程不在所提供的代码截图中,需要大家自行找相关代码阅读
- 接着,我们会根据这个柜子的标志buf[0]是否为1,来检测对应的chunk是装在柜子里,还是通过zmq socket发送了。如果是前者,那么直接从shm读;如果是后者,那么就通过zmq socket做receive。
- 最后,如果当前chunk是大数据,虽然它不会装在对应的柜子里,但我们也会认为这个柜子已经被使用过。这样后一个chunk来的时候,它不会使用当前的柜子,而是使用下一个可用的柜子。
你可能会发现,在上述dequeue的代码中,存在2种zmq socket:local_socket和remote_socket,前者用于单机内的通信(writer和readers在一台node内),后者用于多机间的通信(writer和readers不在一台内)。由于我们当前都是以MultiprocExecutor这种单机场景为例的,所以我们提到的zmq socket都是指local_socket。
好,关于Executor->Worker架构的介绍就到这里了,大家可以配合本文,自行阅读源码,获取更多细节。在这个系列后面的文章中,我们还会看到更多Executor-> Worker配合运行的更多例子。
#T2I-R1
文生图也能这样玩?T2I-R1:把R1的推理范式应用到文生图任务!
文生图进入R1时刻:港中文MMLab发布T2I-R1。
论文:https://arxiv.org/pdf/2505.00703
代码:https://github.com/CaraJ7/T2I-R1
最近的大语言模型(LLMs)如OpenAI o1和DeepSeek-R1,已经在数学和编程等领域展示了相当强的推理能力。通过强化学习(RL),这些模型在提供答案之前使用全面的思维链(CoT)逐步分析问题,显著提高了输出准确性。最近也有工作将这种形式拓展到图片理解的多模态大模型中(LMMs)中。然而,这种CoT推理策略如何应用于自回归的图片生成领域仍然处于探索阶段,我们之前的工作Image Generation with CoT(https://github.com/ZiyuGuo99/Image-Generation-CoT)对这一领域有过首次初步的尝试。
与图片理解不同,图片生成任务需要跨模态的文本与图片的对齐以及细粒度的视觉细节的生成。为此,我们提出了适用于图片生成的两个不同层次的CoT推理:

Semantic-CoT
Semantic-CoT 是对于要生成的图像的文本推理,在图像生成之前进行。
负责设计图像的全局结构,例如每个对象的外观和位置。
优化Semantic-CoT可以在图片Token的生成之前显式地对于Prompt进行规划和推理,使生成更容易。
Token-CoT
- Token-CoT是图片Token的逐块的生成过程。这个过程可以被视为一种CoT形式,因为它同样是在离散空间中基于所有先前的Token输出后续的Token,与文本CoT类似。
- Token-CoT更专注于底层的细节,比如像素的生成和维持相邻Patch之间的视觉连贯性。
- 优化Token-CoT可以提高生成图片的质量以及Prompt与生成图片之间的对齐。

然而,尽管认识到这两个层次的CoT,一个关键问题仍然存在:我们怎么能协调与融合它们? 当前主流的自回归图片生成模型如VAR完全基于生成目标进行训练,缺乏Semantic-CoT推理所需的显式文本理解。虽然引入一个专门用于提示解释的独立模型(例如LLM)在技术上是可行的,但这种方法会显著增加计算成本、复杂性和部署的困难。最近,出现了一种将视觉理解和生成合并到单一模型中的趋势。在LMMs的基础上,这些统一LMMs(ULMs)不仅可以理解视觉输入,还可以从文本提示生成图像。然而,它们的两种能力仍然是解耦的,通常在两个独立阶段进行预训练,没有明确证据表明理解能力可以使生成受益。鉴于这些潜力和问题,我们从一个ULM(Janus-Pro)开始,增强它以将Semantic-CoT以及Token-CoT统一到一个框架中用于文本生成图像:

我们提出了BiCoT-GRPO,一种使用强化学习的方法来联合优化ULM的两个层次的CoT:
我们首先指示ULM基于Image Prompt来想象和规划图像来获得Semantic-CoT。然后,我们将Image Prompt和Semantic-CoT重新输入ULM来生成图片以获得Token-CoT。我们对于一个Image Prompt生成多组Semantic-CoT和Token-CoT,对于得到的图像计算组内的相对奖励,从而使用GRPO的方法来在一个训练迭代内,同时优化两个层次的CoT。
与图片的理解任务不同,理解任务有明确定义的奖励规则,图像生成中不存在这样的标准化的规则。为此,我们提出使用多个不同的视觉专家模型的集成来作为奖励模型。这种奖励设计有两个关键的目的:
- 它从多个维度评估生成的图像以确保可靠的质量评估
- 作为一种正则化方法来防止ULM过拟合到某个单一的奖励模型

根据我们提出的方法,我们获得了T2I-R1,这是第一个基于强化学习的推理增强的文生图模型。根据T2I-R1生成的图片,我们发现我们的方法使模型能够通过推理Image Prompt背后的真实意图来生成更符合人类期望的结果,并在处理不寻常场景时展现出增强的鲁棒性。


同时,定量的实验结果也表明了我们方法的有效性。T2I-R1在T2I-CompBench和WISE的Benchmark上分别比baseline模型提高了13%和19%的性能,在多个子任务上甚至超越了之前最先进的模型FLUX.1。


#One Step Diffusion Via ShortCut Models论文解读
AIGC新手,内容理解如有不对请多多指正。
原文:One Step Diffusion via Shortcut Models
github:GitHub - kvfrans/shortcut-models
摘要
为了缓解目前diffusion架构+flow matching生成速度慢且训练阶段复杂的问题提出了一个叫shortcut model的模型,整个训练过程采用单一网络、单一训练阶段。condition包括当前噪声强度,还取决于stepsize(为了在去噪过程中直接跳过),这个方法在作者的实验中比蒸馏的方法好,并且在推理的时候可以改变step budgets。
之前SD3采直流匹配训练,但是仍然需要28步,这篇论文在首页放了一张效果图,效果看起来很惊艳。
初步效果图
整个网络设置是端到端且只需要一次训练就可以完成一个one-step模型,不像之前的关于蒸馏的工作(参考Progressive Distillation for Fast Sampling of Diffusion Models、http://arxiv.org/abs/2211.12039、Relational Diffusion Distillation for Efficient Image Generation,这三个工作都基于教师-学生来蒸馏,通过多阶段的训练来逐渐折半DDIM的采样步数)。
前置知识
Flow-matching
流匹配的内容在网络上的很多博客都有讲解,这部分就简单带过一下。
流匹配实际上就是通过学习将噪声转化为数据的常微分方程(ODE)来解决生成模型问题,在直流匹配中,整个模型就把真实图像的概率分布和噪声的概率分布之间的路径当作一条直线进行传输,在给定 x0 和 x1 的情况下,速度 vt 是完全确定的。但是,如果只给定 xt,就会有多个可信的配对(x0、x1),因此速度会有不同的值,这就使得 vt 成为一个随机变量。Flow-matching模型就是用来估计预期值在xt条件下的vt是多少,然后vt是xt处所有可信速度的平均值。最后可以通过对随机采样的噪声 x0 和数据 x1 对的经验速度进行回归来优化流量模型。

例子就是直流匹配
这个速度vt就是直接用xt对t求导,就得到了x1-x0,然后整个模型优化就靠下面这个损失函数。

直流匹配的损失函数
实际上就是用回归的损失去尽量让预测的速度能够符合直流匹配定义的速度。
然后去噪过程就是从流量模型中采样,首先从正态分布中采样一个噪声点 x0。然后根据学习到流模型从x0到x1迭代更新该点,整个过程可通过在较小的离散时间间隔内进行欧拉采样来近似实现,因为是直线传输。
为什么提出ShortCut models?
作者通过一个实验去研究了完美训练的ODE在步数减少之后的缺陷,具体来说就是步长有限的情况下,还是很难做到能够将噪声分布确定性地映射到我们需要的数据分布。
作者做的实验,这个图示还是很清晰的,仅给定 xt,vt虽然是根据直流的路线去学习的,但是学习得到的vt是存在固有的不确定性的,vt是指向数据点平均值的,直到缩减到一步,一步的话所有的vt几乎是指向一个点,并不能对应原始数据分布,多样性完全崩塌了
流量匹配学习预测从 xt 到数据的平均方向,因此跟随预测的步长越大,将跳转到多个数据点的平均值。在 t=0 时,模型接收纯噪声输入,并且(x0,x1)在训练过程中随机配对,因此 t=0 时的预测速度指向数据集平均值。因此,即使在流量匹配目标的最优状态下,对于任何多模式数据分布,一步生成都会失败。这段是作者原话,感觉说得蛮清晰,就不加个人理解了。
ShortCut Models
insight:可以训练一个支持不同sampling budgets的一个模型,以时间步长t和步长d为作为条件。那么就顺势提出了下面这个公式。
![]()
shortcut models的核心公式
这个s就是输入Xt,t,d之后的出来的捷径,得到这个路径之后就可以直接让Xt从这个s出发跳步得到Xt+d,OK,那么整个model的训练目标就很明确了,就是通过shortcut model去学习这个s,条件是Xt,t,d。其实整个公式就是直流匹配的跳步模式,当d≈0的时候,就是flow-matching的训练模式,s就直接退化成了v。
那么要学的东西出来了,用什么去约束呢?第一种方法当然就是用小步长去接近flow-matching的forward过程,但是这样做的话训练成本也还是很高,尤其是对直接端到端训练来说,并且小步长实际上对flow-matching的改进不是很大。第二种就是本文用的方法,直接用shortcut model自己的性质,就是一个s步等于两个s/2步。也就是以下公式。

shortcut等价模型
初步看这个公式可能会疑惑为什么会除以2,请注意,上一个公式在s求出来之后还需要乘d,所以s其实不是最终路程,最终的路程是s*d,而整个式子左边的步长为2d,路程相同的情况下,两边同时除以2d才得出来右边等式的1/2系数。
d>0的时候就直接用这个公式,d=0就直接用流匹配去训练。整体流程如下
shortcut对flow-matching的优化
其实就是将flow-matching当作连续的一条线,shortcut直接输入了步长,然后网络获得步长之后直接去获得应道到路径上的哪个路径点,就是上面图左边曲线的黄色部分。整个训练过程把flow-matching综合起来构成了下面的损失函数:

总体损失函数
上述目标学习的是从噪声到数据的映射,在任何步长序列下查询时都是一致的,包括直接在单步中查询。目标中的流量匹配部分将捷径模型建立在小步长的基础上,以匹配经验速度样本。这就确保了捷径模型在多步长查询时具有基础生成能力,这与等效的流量匹配模型完全相同。第二部分的话,通过串联两个较小shortcut的序列,为较大步长构建适当的目标。这样,生成能力就从多步到少步再到一步。综合目标可通过单一模型和单一端到端训练运行进行联合训练。
训练细节
名词定义:经验目标就是对应损失函数第一项需要的目标,一致性目标就是对应损失函数第二项所需要的目标
当 d → 0 时,s等同于vt。因此可以使用flow-matching的损失来训练d=0时的捷径模型,即随机抽样 (x0, x1) 对并拟合vt的期望值。这个项可以看作是小步s的基础,以匹配数据去噪ODE,然后对t ∼ U (0, 1) 进行均匀采样。为了限制复合误差,并且限制引导路径的总长度。因此,我们选择了一种二元递归模型,即用两条捷径来构建一条两倍大的捷径。
然后确定一个步数 M 来表示逼近 ODE 的最小时间单位;在实验中使用了 128 步。根据 d∈ (1/128, 1/64 ... 1/2, 1),这将产生 log2(128) + 1 = 8 种可能的捷径长度。在每个训练步骤中,我们对 xt、t 和随机 d < 1 进行采样,然后使用shortcut连续进行两步。然后将这两步的并集作为目标,并且在2d处训练模型。
将 1-k 个经验目标与k个一致性目标的比例结合起来,构建一个训练批次。k=1/4是合理的。其实这部分也很好理解,因为这个端到端模型实际上就是需要先训练一个flow-matching较好的模型,然后第二项只是在flow-matching的基础上进行优化,如果flow-matching训练得不好,后一项自然训练不好,因为s_target是需要从flow-matching模型中采样的,后一项只能在d=0训练的基础模型上去拟合这个模型,本质上shortcut还是一个教师-学生的思路,但是不同于之前教师和学生都是模型,shortcut将教师-学生拆分为两个损失函数去训练同一个模型,从而实现了端到端。
CFG设定:评估 d = 0 时的捷径模型时使用 CFG,而在其他情况下则放弃 CFG。CFG 在捷径模型中的一个局限性是,必须在训练前指定 CFG 比例。
EMA:用EMA去从d=0的模型上生成d=1的一致性目标,本质上就是平滑一下误差。
其他就是一些网络设置,这里就不一一阐述了,有兴趣可以自己查看一下原论文。
实验结果
FID-50K分数评估
FID-50K分数评估
可以看到在端到端的训练框架中,shortcut models的FID-50k是SOTA,但是相对于PD的蒸馏方式来说,在一步蒸馏中效果还是有待提高。
对ShortCut提出需解决问题的验证
FID下降趋势
在文章开投我们就提到了这篇论文的insight,他是为了缓解flow-matching在步数极低的情况下的崩塌而提出了,这个实验也证明了这一点,在1步模型中,Shortcut的表现完全暴打直接用flow-matching训练的diffusion(但实际上这个对比没有什么特别大意义,flow-matching确实就不适合一步训练,这个问题SD3当时也提出来了)。
作者在后续甚至验证了shortcut在其他领域的鲁棒性,确实是一项非常完善的工作,有其他领域的读者可以去看下原文。
总结
shortcut models确实提供了一个直接在flow-matching上蒸馏的好办法,但是训练过程中的参数设定个人感觉还是靠多种尝试,例如K的选取或许会较大程度影响shortcut models的发挥。反观多阶段的训练方法,至少多阶段确保了一个训练得较为完善的教师模型能够作为参考,而shortcut models如果参数设置不对,flow-mathcing的基础模型可能会不够完善,进而倒是损失第二项会出现较大程度的累计误差。
其次,作者本人也提到了,虽然shortcut能够抑制flow-matching直接在1步训练上的崩溃,但是在步数太低的时候仍然和多步采样存在较大的性能差距(不过1步能做到这个程度已经很好了。。。)。
总的来说,这篇论文的工作很完善,也是一个比较新颖的减少采样步数的方案,但是本质上也是蒸馏的一种,并且端到端的训练相比于多阶段的训练确实更依靠经验,一不注意就会训练失败。
#Test-Time Scaling
突破大模型推理瓶颈!首篇「Test-Time Scaling」全景综述,深入剖析AI深思之道
本文由来自香港城市大学、麦吉尔大学(McGill)、蒙特利尔人工智能实验室(MILA)、人大高瓴人工智能学院、Salesforce AI Research、斯坦福大学、UCSB、香港中文大学等机构的多位研究者共同完成。第一作者为来自香港城市大学的博士生张启源和来自蒙特利尔人工智能实验室(MILA)的博士生吕福源。
当训练成本飙升、数据枯竭,如何继续激发大模型潜能?
💡 在追求通用人工智能(AGI)的道路上,大模型训练阶段的「暴力堆算力」已经逐渐触及天花板。随着大模型训练成本急剧攀升、优质数据逐渐枯竭,推理阶段扩展(Test-Time Scaling, TTS) 迅速成为后预训练时代的关键突破口。与传统的「堆数据、堆参数」不同,TTS 通过在推理阶段动态分配算力,使同一模型变得更高效、更智能 —— 这一技术路径在 OpenAI-o1 和 DeepSeek-R1 的实践中已初显威力。

图 1:预训练扩展和推理阶段扩展的示意。
在数学、编程等硬核任务上,TTS 表现亮眼;而在开放问答、多模态理解乃至复杂规划等场景中,它同样展现出巨大潜力。目前,研究者已探索了多种 TTS 策略,如 Chain-of-Thought (CoT)、Self-Consistency、Search 和 Verification,但该领域仍缺乏统一的研究视角与评估框架。
📘 最近,来自香港城市大学、麦吉尔大学(McGill)、蒙特利尔人工智能实验室(MILA)、人大高瓴人工智能学院、Salesforce AI Research、斯坦福大学、UCSB、香港中文大学等机构的多位研究者联合发布了首篇系统性的 Test-Time Scaling 领域综述。该文首次提出「What-How-Where-How Well」四维分类框架,系统拆解推理优化技术,为 AI「深思」绘制全景路线图。
论文标题:A Survey on Test-Time Scaling in Large Language Models:What, How, Where, and How Well
论文链接:https://arxiv.org/pdf/2503.24235
项目主页:https://testtimescaling.github.io/
GitHub 仓库:https://github.com/testtimescaling/testtimescaling.github.io/
🔍 论文亮点概览:
本篇 Survey 首次提出了一个覆盖全面、多层次、可扩展的四维正交分析框架:
- What to scale:扩什么?CoT 长度、样本数、路径深度还是内在状态?
- How to scale:怎么扩?Prompt、Search、RL,还是 Mixture-of-Models?
- Where to scale:在哪扩?数学、代码、开放问答、多模态……
- How well to scale:扩得怎样?准确率、效率、控制性、可扩展性……
在这个框架下,作者系统梳理了当前的主流 TTS 技术路线,包括:
- 并行策略:即同时生成多个答案,并选出最优解(如 Self-Consistency / Best-of-N)
- 逐步演化:即通过迭代修正逐步优化答案(如 STaR / Self-Refine)
- 搜索推理:结合并行与序列策略,探索树状推理路径(如 Tree-of-Thought / MCTS)
- 内在优化:模型自主控制推理步长(如 DeepSeek-R1 / OpenAI-o1)
基于这一框架,作者系统性地梳理了现有文献,实现了四大核心贡献:
- 文献解析:通过结构化分析方法,清晰界定各项研究的创新边界与价值定位;
- 路径提炼:总结出推理阶段扩展技术的三大发展方向:计算资源动态优化、推理过程增强和多模态任务适配;
- 实践指导:针对数学推理、开放问答等典型场景,提供具体可操作的技术选型建议;
- 开放社区:抛弃传统调研自说自话的特点,通过结合主页希望营造一个专门为 TTS 讨论的开放社区,集所有研究者的智慧,不断与时俱进更新更加实践的指导。
与同类综述相比,本文特别注重实用价值和开放讨论,不仅系统评估了不同 TTS 策略的性价比,还前瞻性地探讨了该技术的未来演进方向,包括轻量化部署、持续学习融合等潜在突破点。
作者表示,Test-time Scaling 不仅是大模型推理的「第二引擎」,更是迈向 AGI 的关键拼图。教会模型「三思而后行」,是我们迈向通用人工智能的重要旅程。
框架介绍
作者提出的框架从四个正交维度系统解构 TTS 技术:
1. What to Scale(扩展什么)- 界定推理过程中需要扩展的具体对象,包括:
- Parallel Scaling(并行扩展):并行生成多个输出,然后将其汇总为最终答案,从而提高测试时间性能;
- Sequential Scaling(序列扩展):根据中间步骤明确指导后面的计算;
- Hybrid Scaling(混合扩展):利用了并行和顺序扩展的互补优势;
- Internal Scaling(内生扩展):在模型内部参数范围内自主决定分配多少计算量进行推理,在推理时并不外部人类指导策略。
其中,作者为每一个扩展的形式,都进行了一些经典工作的介绍,从而丰富了对于扩展策略的外延描述,例如:在并行扩展中作者根据得到覆盖性的来源分为两个更小的类别,在单个模型上的反复采样和多个模型的采样。
2. How to Scale(怎么扩展)- 归纳实现扩展的核心技术路径:
- 训练阶段方法:监督微调(SFT)、强化学习(RL)等
- 推理阶段技术:刺激策略(Stimulation)、验证技术(Verification)、搜索方法(Search)、集成技术(Aggregation)
这个章节是重点章节,作者收录并整理了大量的经典的和最前沿的技术,例如在训练阶段中的强化学习技术,伴随 R1 而大火,因此在短短两个月内涌现出大量的工作,作者将它们尽数收入,同时分成基于奖励模型和不需奖励模型两类;对于刺激策略,作者分成了提示(Prompt),解码(Decode)、自重复(Self-Repetition)、模型混合(mixture-of-model)四类。
3. Where to Scale(在哪里扩展)- 明确技术适用的任务场景与数据集特性。
作者在这里提出尽管 TTS 的推出和验证是在某一类特定的推理任务上得到成功的,可是已经有足够多的工作开始显现出 TTS 是一种通用地能够提升在多样任务的策略,由此作者以推理(Reasoning)和通用 (General Purpose) 两类进行分类,一方面强调了 TTS 在越来越多样、越来越先进的推理任务中有很明显的效果,另一方面也不断跟踪 TTS 在更多通用任务上应用的效果。值得注意的是,作者整理出一个评测基准的表格,方便更多研究者直接从中去选择合适自己的基准。
4. How Well to Scale(效果怎么样)- 建立多维评估体系:
在当下,TTS 已经不仅是一个提高任务准确率的策略,当它成为一个新的值得被研究的核心策略时,对 TTS 的要求会更加多元化,这也是未来研究的主题。作者认为之后对 TTS 的优化重点将不仅仅局限在准确率的提升,是在于如何提高效率、增强鲁棒性和消除偏见等。

图 2:作者提出的 TTS 框架,包括 what, how, where 和 how well to scale。
作者不仅在每个维度下提供细粒度子类划分,还配套标注了代表性研究工作(如图 2 所示),使分类体系兼具理论完备性和实践指导价值。这一结构化的基础使得后续研究可以无缝地融入作者的分类体系,更清晰地展现其贡献。
为了更好的理解 what to scale 中的并行扩展,序列扩展,结合扩展和内生扩展,作者用一张清晰的示意图进行形象化的展示,同时,在图中使用 how to scale 的技术来组成不同的扩展策略,很好地示意了两个维度如何结合在一起。

图 3:从 what to scale 到 how to scale。
实践特色
作者强调本篇 Survey 以实用为原则,具体包括:使用所提出的框架分析文献,以及整理操作指南。
文献解析:为了帮助研究者系统性地剖析每项工作,作者设计了一个分析表格,通过将文献贡献对应到框架的四个维度(What/How/Where/How Well),以清晰地解构该工作。这种结构化分析方法不仅能清晰展现各研究的核心创新,更能有效揭示潜在的技术突破方向。

表 1:在现有文献中进行推理扩展时常用的组合方式。
操作指南:另一个潜在的亮点是持续收集 TTS 开发中的实用操作指南,而这些操作指南将以问答的形式展现。作者期待这些问答是具体的、现实的、一线的,因此,作者期待这篇 Survey 将维持开放性,邀请更多在一线研究的学者来参与这项操作指南的收录和编写。下面是作者现阶段的操作指南的内容和风格。

开放社区
有价值的洞见和实践指导是来自于第一线的科研和百花齐放的讨论的,作者期待将论文从传统的静态的一家之言转化为动态的百家之坛,并建立开放的社区来收集任何一线科研者提出的问题和总结的经验,而这些问题和经验在经过筛选后,会更新到最新的论文中,并在致谢中进行感谢。


挑战与未来
尽管 TSS 技术已崭露头角,本文总结了 TTS 当前面临的四大挑战:
- 扩展极限:在未来的 TTS 中,如何突破「暴力采样」的边际收益递减?我们急需在不同方向上探索策略
- 本质理解:tts 中多个模块是否真正驱动了推理改进?reward model 是否需要重新评估?我们依然需要在理论层面揭示技术有效性根源。
- 评估革新:传统指标无法捕捉推理过程质量,随着 test-time scaling 技术的发展,领域内急需开发细粒度评估体系,以便更全面地评估不同策略
- 跨域泛化:当前 TTS 方法在数学、代码任务中表现突出,但如何迁移至法律、金融等高风险场景?如何在推理过程中考虑现实世界的制约?
论文还指出,目前常见的技术如 SFT、RL、Reward Modeling 等虽被频繁使用,但背后的作用贡献尚不清晰,值得深入探索,例如:SFT 真的不如 RL 更泛化吗?R1 的时代下 SFT 的角色是什么?什么样的 Reward Modeling 更加高效?等等
此外未来 TTS 的发展重点包括:1. 统一评估指标(准确率 vs 计算开销);2. 拓展到金融、医学等真实场景;3. 构建具备自适应推理能力的通用智能体。
推理扩展策略正引领 AI 推理范式转变:让模型在「用」的时候持续变强。
#NYU教授公布2025机器学习课程大纲
所有人都在追LLM,高校为何死磕基础理论?
最近,Meta 公司首席 AI 科学家、图灵奖得主 LeCun 转发了他在纽约大学的同事 Kyunghyun Cho 的一篇帖子:内容是关于这位教授 2025 学年机器学习研究生课程的教学大纲和讲义。

讲义地址:https://arxiv.org/abs/2505.03861
教学大纲:https://docs.google.com/document/d/1OngR25IMEM5bJ458J8z4OCnTFG87KJ5ihgWojU1DD64
该课程聚焦于以随机梯度下降(SGD)为核心的基础机器学习算法,特意避开大型语言模型(LLM)内容,同时鼓励学生深入研读领域经典论文,回溯机器学习的理论发展脉络。
在这个人人都关注 LLM 的时代,这样的课程设计乍看似乎很特别。但对比其他高校的课程表会发现, 各大高校研究生机器学习课程仍普遍以基础理论和经典模型为核心。
比如斯坦福 CS229, 是经典的机器学习基础课程,2025 年冬季课程简介中,课程系统讲授包括线性回归、逻辑回归、SVM、神经网络、聚类、降维、EM 算法等基本模型与方法,强调数学推导与优化思想,广泛应用于跨领域研究。

MIT 的 6.790 课程是其研究生阶段的核心机器学习课程,前身为 6.867,现已更新为 6.7900。该课程强调从概率建模和统计推理的角度深入理解机器学习方法,适合希望在理论与实践之间建立坚实联系的学生。

清华电子系研究生课程也设置了《机器学习》《统计推断理论和方法》等核心理论课程。

而最新 LLM 内容多在专门选修课中出现,比如斯坦福大学 CS25: Transformers United,是一门专注于 LLM 和 Transformer 架构的研究型课程,详见报道《OpenAI、谷歌等一线大模型科学家公开课,斯坦福 CS 25 春季上新!》 。
可以看出,教育界普遍认为基础教学有助于学生长远发展。Cho 在撰写讲义时引用了 Sutton 的「苦涩教训」,强调通用可扩展方法(如以 SGD 为核心)比具体架构更重要。他刻意省略了复杂体系(如 LLM)而专注于历史上成熟的算法和数学直觉,认为「一个学期时间不足以深入所有主题」,只能先打下坚实基础。
此外,Cho 曾在博客中提到,2010–2015 年间深度学习尚未普及时,很多 ML 课程对神经网络仅作简单提及。
如今通过强调经典方法、阅读经典论文,可以让学生理解知识的源头与演进脉络,培养批判性思考能力。总体而言,基础导向的教学能让学生掌握算法背后的数学原理和优化方法,而不是「盲目套用」最新模型。
理论 VS 实践
但我们无法逃避的一个问题是:大学培养机制(尤其是研究生 / 博士教育)强调基础、原理和科研能力,而实际工作环境尤其在工业界常常需要快速响应、工程落地、产品迭代能力。
一味的强调「必须理解深层原理」,在某些语境下,确实可能显得有些「何不食肉糜」。
「你怎么连 attention 的 Q/K/V 向量都没推导过就来调模型?」现实可能是:「我只是想学个微调技巧,用 LLaMA 写个客服机器人。」
对此不少大学也在积极探索解决方案, 为弥补科研与工程能力脱节,不少学校推出了「桥接」课程或实践项目。
例如,斯坦福大学在开设 CS229 等理论课的基础上,还专门设立了 CS329S《机器学习系统设计》实践课。这门课着重讲授如何构建可实际部署、运行稳定且具备扩展性的机器学习系统,内容包括数据处理、特征提取、模型上线与监控等环节。

CMU 的机器学习博士生必须修读 10-718《机器学习实践》课程。在这门课中,学生需要完成学期项目,从头到尾搭建并部署一个完整的机器学习系统。课程描述明确指出,学生将通过项目学习处理真实场景下的数据问题,掌握从原始数据清洗到模型最终上线的全流程技能。

国内高校也开始重视实践教学。清华大学电子系与企业合作开设了多门实用性课程,如「大数据技术的应用与实践」、「高阶机器学习」和「智能制造」等,将行业实际案例和编程实践引入教学过程。

为何高校仍执着于「慢功」?
在当今技术飞速发展的背景下,许多高校依然强调「打好基础、追求深刻理解」,这并非单纯的「固步自封」。
真正的技术能力不仅在于「会用工具」或「能跑模型」,而在于理解方法背后的原理,在面对新问题、新技术时,具备独立分析、判断和创造的能力。 吴恩达曾在一篇文章中以个人经历说明持续学习基础知识的重要性,他强调「牢靠且及时更新的基础知识是成为一名高产机器学习工程师的关键」。
文章链接:https://www.deeplearning.ai/the-batch/issue-146/

这种理念的核心在于「抗变化性」。技术潮流更新迅速,从 CNN 到 Transformer,再到 LLM 和多模态系统,每一步都可能颠覆现有工程范式。
要适应这些变化,不能仅靠追逐热点,而需深入掌握优化、泛化、表示学习等底层理论。只有理解「为何这样设计」以及「背后的假设是什么」,才能在面对全新技术时避免迷茫。

此外,深厚的基础是科研与技术创新的起点。科研不仅是调参或复现论文,更在于提出问题、构建假设、设计新方法。这离不开扎实的数学工具、严谨的逻辑训练以及对经典工作的积累。基础课程培养的不仅是知识点,更是抽象思维与批判性思考能力。
深度学习教父、图灵奖得主 Geoffrey Hinton 在接受 MIT Technology Review 采访时指出,正是对基础算法的长期坚持和深入研究,才推动了深度学习的突破,「我们花了几十年时间打磨神经网络的基本原理,直到 2010 年代才迎来真正的应用爆发。基础知识的积累和理解,是 AI 领域每一次重大进步的根本。」
当然,这种教育路径并非忽视实践,而是强调:真正的实践力应建立在理解力之上。不仅要会用工具,更要了解其来龙去脉、适用边界与改进方向。
因此,「找工作」与「打基础」并非非此即彼的选择题,而是时间维度上的权衡。短期内,工具技能能带来直接的岗位匹配;但长期来看,基础能力才是跨越技术周期、持续成长的「护城河」。
课程讲义
现在我们回过头来看看这份 100 页 pdf 的课程讲义,它对机器学习进行了全面介绍,涵盖了基础概念和现代技术,有兴趣的读者可以阅读原文。

每一章的结构和内容概要如下:
第一章:能量函数 介绍能量函数作为机器学习中的统一主题的概念。解释了不同的机器学习范式(监督学习、无监督学习、分类、聚类等)如何可以被构架为最小化能量函数。讨论潜在变量和正则化在定义和学习能量函数中的作用。
第二章:机器学习中的基本分类思想 涵盖了基本的分类算法,包括感知器、边际损失、softmax 和交叉熵损失。解释分类器训练中的反向传播,重点在于线性和非线性能量函数。讨论了随机梯度下降(SGD)和自适应学习率优化方法。涉及泛化和模型选择,包括偏差 - 方差权衡和超参数调整。
第三章:神经网络的基本构建块 探索了神经网络架构中常用的构建块。讨论了归一化技术(批量归一化、层归一化)。介绍了卷积块、循环块和注意力机制。介绍了神经网络中置换等变性和不变性的概念。
第四章:概率机器学习和无监督学习 说明了如何从概率角度解释能量函数。涵盖了变分推断和高斯混合模型。讨论了连续潜在变量模型和变分自编码器(VAEs)。介绍了重要性采样及其方差。
第五章:无向生成模型 探索无向生成模型,重点介绍受限玻尔兹曼机(RBMs)和专家乘积(PoE)。讨论马尔可夫链蒙特卡洛(MCMC)方法用于从 RBMs 中采样。引入基于能量的生成对抗网络(EBGANs)。涵盖自回归模型。
第六章:进一步话题 提供了机器学习中几个高级主题的概述。讨论了一步强化学习和多步强化学习。探索了集成方法(袋装法,提升法)和贝叶斯机器学习。介绍元学习。探讨混合密度网络和因果关系。
经典论文

最后我们来看看 Cho 提到的经典论文,这里节选了一部分。
- 「Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning」——Ronald J. Williams
论文地址:https://link.springer.com/article/10.1007/BF00992696
该论文提出了 REINFORCE 算法,一种基于策略梯度的强化学习方法,用于训练连接主义模型(如神经网络)。该算法通过直接优化期望奖励,奠定了现代策略梯度方法的基础。
- 「Efficient Backprop」——Yann LeCun, Leon Bottou, Genevieve B. Orr, Klaus-Robert Müller(重点关注弟 4 节)
论文地址:https://link.springer.com/chapter/10.1007/978-3-642-35289-8_3
系统总结了反向传播(Backpropagation)的优化技巧,包括学习率调整、权重初始化、激活函数选择等。第 4 节特别讨论了高效训练神经网络的实用方法。
- 「Training Products of Experts by Minimizing Contrastive Divergence」——Geoffrey Hinton
论文地址:https://www.cs.toronto.edu/~hinton/absps/nccd.pdf
提出了对比散度(Contrastive Divergence, CD)算法,用于训练受限玻尔兹曼机(RBM)和专家乘积模型。这是深度学习复兴前的重要工作,为后续深度信念网络(DBN)奠定了基础。
- 「Auto-Encoding Variational Bayes」——D. Kingma, M. Welling
论文地址:https://arxiv.org/abs/1312.6114
提出了变分自编码器(Variational Autoencoder, VAE),通过变分贝叶斯方法实现高效的生成模型训练。VAE 结合了神经网络和概率建模,成为生成模型领域的里程碑。
- 「Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks」——Chelsea Finn, Pieter Abbeel, Sergey Levine
论文地址:https://arxiv.org/abs/1703.03400
提出了 MAML(Model-Agnostic Meta-Learning),一种通用的元学习算法,使模型能够通过少量样本快速适应新任务。MAML 在少样本学习(Few-Shot Learning)领域具有开创性意义。
更多详细内容请参见原讲义和教学大纲。
#UnifiedReward-Think
首个多模态统一CoT奖励模型来了,模型、数据集、训练脚本全开源
在多模态大模型快速发展的当下,如何精准评估其生成内容的质量,正成为多模态大模型与人类偏好对齐的核心挑战。然而,当前主流多模态奖励模型往往只能直接给出评分决策,或仅具备浅层推理能力,缺乏对复杂奖励任务的深入理解与解释能力,在高复杂度场景中常出现 “失真失准”。
那么,奖励模型是否也能具备像人类一样的深度思考能力?
近日,腾讯混元与上海 AI Lab、复旦大学、上海创智学院联合提出全新研究工作 UnifiedReward-Think,构建出首个具备长链式推理能力的统一多模态奖励模型,首次让奖励模型在各视觉任务上真正 “学会思考”,实现对复杂视觉生成与理解任务的准确评估、跨任务泛化与推理可解释性的大幅提升。
论文题目: Unified Multimodal Chain-of-Thought Reward Model through Reinforcement Fine-Tuning
项目主页:https://codegoat24.github.io/UnifiedReward/think
论文链接:https://arxiv.org/pdf/2505.03318
GitHub:https://github.com/CodeGoat24/UnifiedReward
模型:https://huggingface.co/collections/CodeGoat24/unifiedreward-models-67c3008148c3a380d15ac63a
数据集:https://huggingface.co/collections/CodeGoat24/unifiedreward-training-data-67c300d4fd5eff00fa7f1ede
一、背景与动机:奖励模型也需要 “思考”
当前的多模态奖励模型大多只能对结果进行 “表面判断”,缺乏深度推理与可解释的决策依据,难以支撑对复杂视觉任务的精准评估。
该工作研究团队提出关键问题:是否可以引入 “长链式思考”(Chain-of-Thought, CoT)机制,赋予奖励模型更强的推理能力?
挑战在于,当前缺乏高质量的多模态 CoT 奖励推理数据,传统 SFT 等训练范式难以直接教会模型掌握推理过程。
他们认为,多模态大模型本身具备深层、多维度的推理潜力,关键在于设计一套高效训练范式去激发并强化奖励模型的 “思考能力”。

二、解决方案:三阶段训练范式,逐步进化奖励模型推理能力
该研究提出一套新颖的 “三阶段” 训练框架,分为 “激发 → 巩固 → 强化”,层层推进模型的推理进化:
阶段一:冷启动激发(Cold Start)
使用仅 5K 图像生成任务的高质量 CoT 奖励推理数据,让模型学会基本的推理格式与结构。实验表明,这一阶段就能激发模型在多个视觉任务中的推理能力。
阶段二:拒绝采样巩固(Rejection Sampling)
利用冷启动后的模型在各视觉任务的泛化能力,对大规模多模态偏好数据进行推理,通过拒绝采样剔除逻辑错误样本,强化模型对正确思维链的推理模式。
阶段三:GRPO 强化(Group Relative Policy Optimization)
针对推理错误样本,引入 GRPO 强化学习机制,引导模型探索多样化推理路径,从错误中学习,逐步收敛到正确逻辑思考。
三、实验亮点:奖励模型不仅能 “显示长链推理”,还能 “隐式逻辑思考”
UnifiedReward-Think 在多个图像生成与理解任务中进行了系统评估,结果表明该模型具备多项突破性能力:
- 更强可解释性:能够生成清晰、结构化的奖励推理过程;
- 更高可靠性与泛化能力:各视觉任务均表现出显著性能提升;
- 出现隐式推理能力:即使不显式输出思维链,模型也能作出高质量判断,表明推理逻辑已 “内化” 为模型能力的一部分。
定量实验:长链推理带来全面性能飞跃

定量结果表明
- 在图像与视频生成奖励任务中,全面优于现有方法;
- 在图像理解类奖励任务上,长链思维链推理带来显著性能提升,验证了复杂视觉理解对深度推理能力的高度依赖;
- 即便在不显式输出思维链的情况下,模型仍能通过隐式逻辑推理保持领先表现,相比显式 CoT 推理仅有轻微下降,展现出强大的 “内化逻辑” 能力;
- 与基础版本 UnifiedReward 相比,加入多维度、多步骤推理带来了多任务的全面性能跃升,验证了 “奖励模型也能深度思考” 的价值。
消融实验:三阶段训练策略缺一不可
该工作进行了系统的消融实验,验证三阶段训练范式中每一步的独立贡献:
- 冷启动阶段:模型学会了 CoT 推理的结构,但对奖励预测的准确性仍较有限;
- 拒绝采样阶段:通过筛除推理错误样本,显著提升了模型对 “正确思维链” 的偏好,有效增强了模型的稳定性与泛化性;
- GRPO 阶段:提升幅度最大,模型聚焦于错误推理样本,通过多路径推理探索,逐步收敛至更精确的推理过程,体现出该阶段对 “推理纠错” 的关键作用。
- 无推理路径的 GRPO 版本效果显著下降。我们进一步验证:若去除 CoT 推理、让奖励模型仅对最终答案进行 GRPO 强化,虽然略优于 baseline,但提升比较有限。说明仅优化结果远不足以驱动深层推理能力的形成。
结论:显式建模思维链推理路径,是强化奖励模型泛化与鲁棒性的关键。GRPO 训练阶段之所以有效,根源在于 “强化正确推理过程”,而非仅仅是 “强化正确答案”。


定性效果展示
该工作在多种视觉任务中对模型进行了案例测试,展现出其按任务定制评估维度的能力。通过对图像、视频或答案进行细粒度、多维度打分,并基于各维度总分进行整体判断。此设计有效缓解了多模态模型中常见的 “推理过程与最终评分语义脱节” 问题,显著提升了评估的一致性与可信度。






四:总结
UnifiedReward-Think 展示了奖励模型的未来方向 —— 不仅仅是一个 “打分器”,而是一个具备认知理解、逻辑推理与可解释输出能力的智能评估系统。
目前,该项目已全面开源:包括模型、数据集、训练脚本与评测工具,欢迎社区研究者探索、复现与应用。
#Matrix-Game
生成视频好看还不够,还要能自由探索!昆仑万维开源Matrix-Game,单图打造游戏世界
世界模型的进度条,最近坐上了火箭。
去年 11 月,两家创业公司打造的 Oasis,首次在开源世界模型中实现了实时、可玩、可交互。生成的虚拟环境不仅包含画面,也体现出了对物理和游戏规则的理解。
Oasis 世界模型的演示动画。
今年 4 月,微软开源的交互式世界模型 MineWorld,再次提升了视觉效果,大幅提升了动作生成的一致性。

MineWorld 模型的生成效果。
上个星期,又有国外创业公司开源了 「多元宇宙」,能让不同玩家在一个世界模型里进行游戏。
眼看三维世界的 AI 研究越来越多,英伟达人工智能总监、杰出科学家 Jim Fan 提出了「物理图灵测试」,要给具身智能设立一个像图灵测试一样的标准:如果你分辨不出一个现实世界场景是不是由 AI 布置出来的,那完成任务的 AI 就可以认为通过了测试。
从前沿技术、应用再到测试基准,我们正在见证技术的全面兴起,众多科技公司蜂拥而入,仿佛大模型的爆发又要重演一遍。或许过不了多久,计算平台处理的单位就不再是 token,而是物理世界中的原子了。
今天又有更大的新闻曝出:5 月 13 日,昆仑万维宣布开源交互式世界基础模型 Matrix-Game,这不仅是世界模型技术向前迈进的一大步,更是空间智能领域交互式世界生成的重要里程碑。
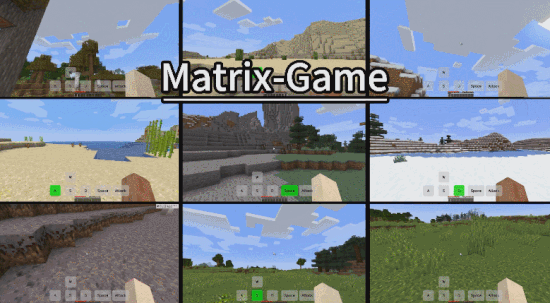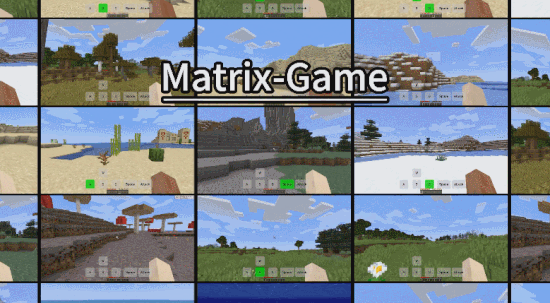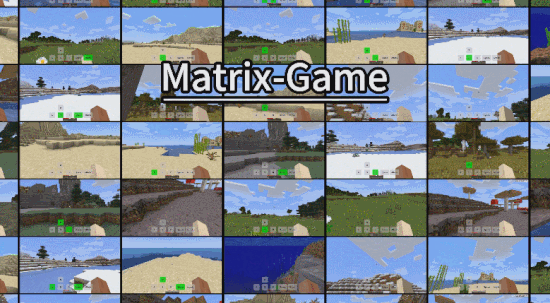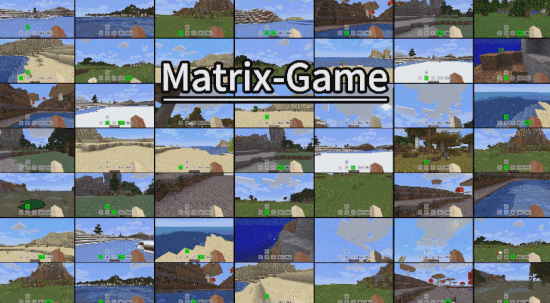
- Github:https://github.com/SkyworkAI/Matrix-Game
- HuggingFace:https://huggingface.co/Skywork/Matrix-Game
- 技术报告:https://github.com/SkyworkAI/Matrix-Game/blob/main/assets/report.pdf
- 项目主页:https://matrix-game-homepage.github.io
作为一款世界基础模型,Matrix-Game 能够生成完整可交互的游戏世界,能够对人类输入的操作指令进行正确响应,保留了游戏世界的空间结构与物理特性,画面也更加精致,超越了以往所有类似开源世界模型。
当然,它应用的应用范围不仅限于游戏,对于具身智能体训练与数据生成、影视与元宇宙内容生产也有重要意义。
昆仑万维表示,Matrix-Game 让世界不再只是被观看,而是被探索、被操控、被创造。这种主动式的探索或许正是空间智能发展的关键所在。
超越微软开源的交互式世界模型
Matrix-Game 强在哪儿?
Matrix-Game(17B+)是昆仑万维 Matrix 系列模型在交互式世界生成方向的首次落地,也是世界模型领域工业界首个开源的 10B + 大模型。
早在今年 2 月, 昆仑万维正式推出 Matrix-Zero 世界模型,迈出了其探索空间智能的关键一步。
昆仑万维表示,Matrix-Zero 其实包含两个子模型 —— 一个用于 3D 场景生成,另一个用于可交互的视频生成。
当时就有人问:这个可交互的视频生成模型可以用来做游戏吗?

几个月后,昆仑万维给出了答案。这次发布的 Matrix-Game 就是可交互视频生成模型在游戏方向的落地,它能够根据用户输入(键盘指令、鼠标移动等)生成连贯、可控的游戏互动视频。
和行业内的其他模型相比,它有以下几个特点:
1. 可以实现细粒度的用户交互控制。
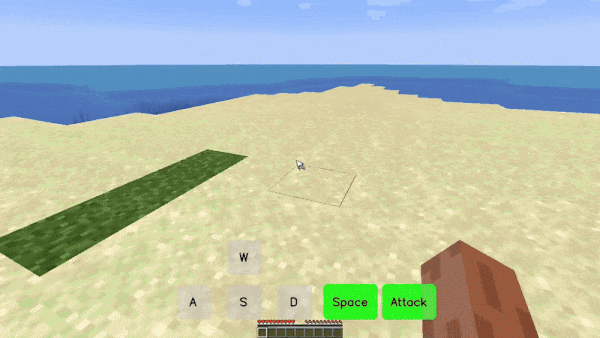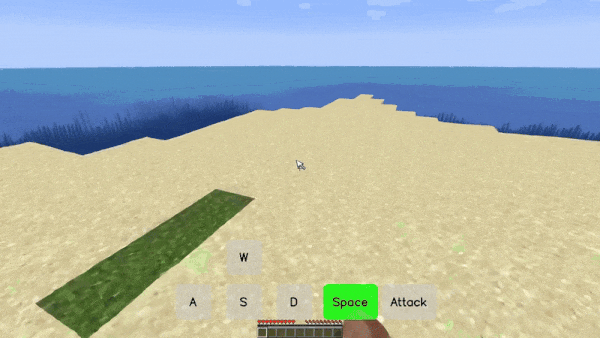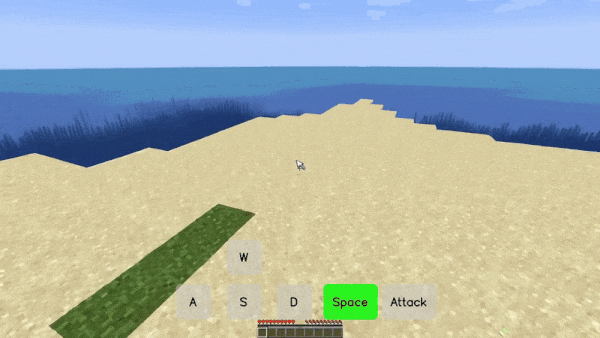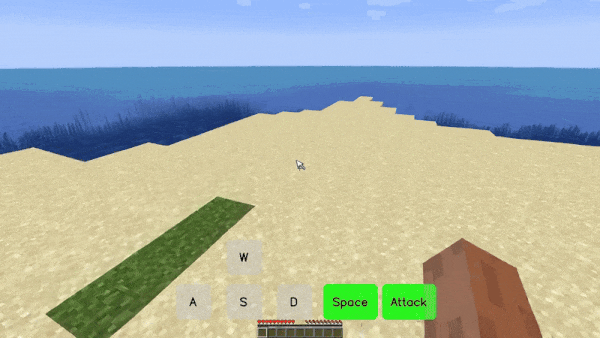
在游戏里,你可以通过按「W、S、A、D、Space、Attack」以及这些键的组合实现自由移动和攻击。在 Matrix-Game 创造的「我的世界(Minecraft)」游戏世界里,你可以得到相同的体验,无论控制信号是连续的(如视角转换)还是离散的(如前进、跳跃),而且每次移动都伴随着景物的变化。
比如在下面这个「前进 + 攻击」的场景中,游戏人物穿过一片树林来到池塘前,代表树木的方块在受到攻击后被破坏,这是模型生成的环境反馈信号。而且,虽然池塘和后面的山体大部分被树木遮挡,但模型依然生成了合理的结果,使得整个过程的景物变化非常丝滑。
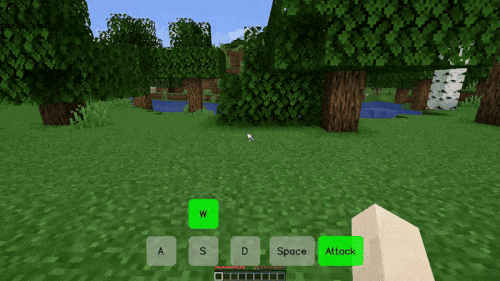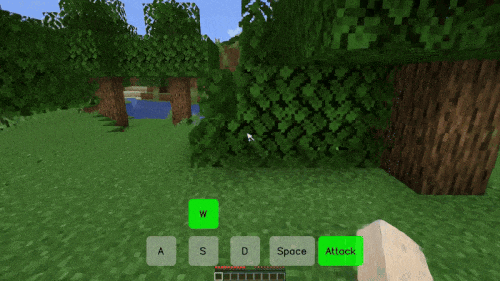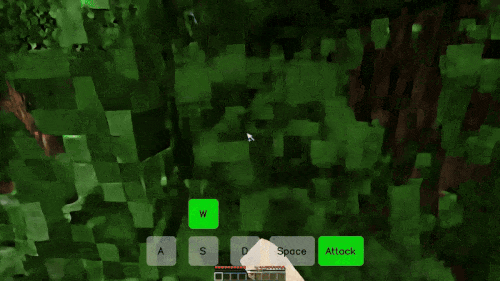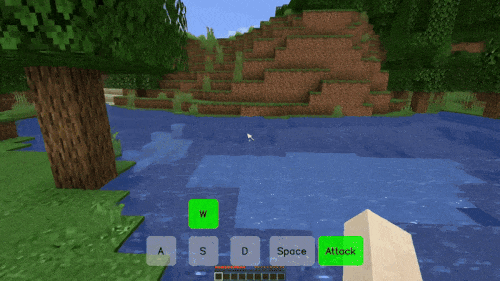
在一个「前进 - 向左 - 前进」的长镜头组合移动场景中,模型不仅严格遵守了用户的控制指令,还生成了丰富的景物变化,比如没入水中的逼真过程。
2. 生成效果具有高保真视觉与物理一致性。
在视频生成领域,能否保持视觉一致性、遵循物理规律是判断视频质量的试金石。但从业界的各种翻车视频来看,这些很难做好,更别说在交互视频这种需要推理交互效果的视频生成形式中。
但 Matrix Game 的表现令人眼前一亮,在交互中能生成物理上合理、视觉上一致的结果。
比如,在下面这个左右移动的场景中,草丛中的花有时会被树干遮挡,但随着脚步的进一步移动又会重现,这说明模型具有保持视觉一致性的能力。
再比如,在一个跳跃的操作中,我们能够看到河里的景物随着视角的变化而变化(跳起来之后,视角变高,能看到更全面的水底画面)。这都是模型根据所掌握的物理规律进行「脑补」的结果。
3. 拥有多场景泛化能力
在前面的例子中,我们已经看到,Matrix Game 能够生成非常丰富的 Minecraft 游戏场景,比如森林、沙滩、河流、平原等,这些环境涵盖不同地形、天气和生物群系。
其实,除此之外,它还能向非 Minecraft 游戏环境泛化,生成城市、古建等开放式场景的互动视频。
4. 具有系统化的评估体系
对于交互式视频生成这种相对较新的模型,应该从哪些维度评估生成质量?如果不想清楚这个问题,模型就很难有明确的优化方向。为了解决这一问题,昆仑万维提出了一套专为 Minecraft 世界建模设计的统一评测框架 —— GameWorld Score。
具体来说,GameWorld Score 从视觉质量、时间一致性、交互可控性、物理规则理解这四个维度来评价模型。视觉质量是指每一帧图像的清晰度、结构一致性与真实感,这也是人类感知视频质量的几个重要维度。时间一致性、交互可控性和物理规则理解上文已经提及。这几个维度合在一起,首次实现了对可交互视频感知质量 + 控制能力 + 物理合理性的全方位衡量,补齐了现有基准的短板。

在这个基准上,Matrix Game 与知名创业公司 Decart 的开源方案 Oasis 和微软的开源模型 MineWorld 进行了 PK,在四大维度上均取得领先成绩。


图源:Matrix-Game 技术报告
在双盲评测中,Matrix-Game 生成的视频评分也是大幅度领先:

图源:Matrix-Game 技术报告
在控制性上,Matrix-Game 在「运动」、「攻击」等动作上实现了超过 90% 的准确率,细粒度视角控制下依然可以保持高精度响应。

图源:Matrix-Game 技术报告
接下来是场景泛化能力,在 8 大典型 Minecraft 场景中,Matrix-Game 保持了全面领先,展现出卓越的环境适应性,这意味着它可以广泛应用于较复杂、动态的虚拟世界交互任务。

图源:Matrix-Game 技术报告
可见,不论是从数据、模型还是实测角度来看,Matrix-Game 都树立了当前交互式世界模型的新标杆。
Matrix-Game 是怎样练成的?
在昆仑万维发布的技术报告中我们可以发现,Matrix-Game 取得的优异成绩主要得益于研究团队在数据、模型架构等方面做出的技术创新。
精挑细选的 Matrix-Game-MC 数据集
目前,业界已有越来越多的研究尝试让世界模型生成游戏场景,但它们往往难以有效捕捉物理规则,泛化能力有限。
Matrix-Game 改变了这一现状。它是一个参数规模达 17B 的世界基座模型,专注于交互式图像到世界的生成,通过两阶段训练策略(无标签数据预训练 + 标注数据可控训练)训练而来,其中用到了昆仑万维自主构建的大规模数据集 ——Matrix-Game-MC。
Matrix-Game-MC 数据集涵盖从无标签预训练数据到精细标注的可控视频全流程。其中,无标签预训练数据来自 MineDojo 数据集中的视频资源,研究团队利用 MineDojo 工具系统性地采集了约 6000 小时的原始 Minecraft 游戏视频,并设计了三阶段过滤机制,依次对画质美学、动态合理性与视角稳定性等方面进行筛选,最终获得了超过 2700 小时的中质量数据和 870 小时的高质量数据,用于支持基模型的无监督预训练。

有标签部分则是采用探索代理(Exploration Agent)、程序化模拟(Unreal Procedural Simulation)两种策略混合生成的可控监督数据,包括高质量的《我的世界》游戏内容和在虚幻引擎(Unreal Engine)中手动构建的模拟交互场景,不仅包含精确的键盘与鼠标控制信号,也提供位置信息、动作标签及环境反馈信号,体量约 1000 小时。
另外得益于 Unreal 数据的融入,Matrix-Game 在更通用游戏场景的泛化上展现出了明显的优势。
图像到世界建模的模型架构
Matrix-Game 的目标是能够内化真实的物理交互、语义结构并支持交互式的视频生成。
从模型架构上看,Matrix-Game 的整体架构围绕图像到世界建模(Image-to-World Modeling)的方式设计。正如 2 月份 Matrix-Zero 所展示的,该系列模型受空间智能启发,纯粹从原始图像中学习,可参考单张图像生成能交互的视频内容。它通过构建一个一致的场景来学习理解世界,不依赖语言提示,仅基于视觉信号对空间几何、物体的运动及物理交互进行建模。

其中,视觉编码器或多模态主干网络处理的参考图像作为主条件输入,在高斯噪声及用户动作条件下,由 DiT 生成潜在表示,然后通过 3D VAE 解码器将其解码为连贯的视频序列。
MatrixGame 能够直接通过视觉内容感知、解读和建模世界,可以实现一致且结构化的理解。结合用户的动作输入,世界模型可以像 AI 图像生成工具一样直接生成「3D 游戏画面」。为了避免此前很多世界模型生成长时序内容不停变化的出戏情况,Matrix-Game 每次生成会以之前的 5 帧运动作为上下文逐段递进生成,保证了输出内容在时间上的连贯性。
在交互可控的问题上,人们输入的键盘动作(如跳跃和攻击)以离散的 token 表达,视角的移动则以连续的 token 表达。作者使用 GameFactory 的控制模块,同时融入了多模态 Diffusion Transformer 架构,还使用 CFG 技术提升了控制信号响应的鲁棒性。
简单总结一下,Matrix-Game 经过了数千小时高质量数据的训练,通过创新的模型架构既实现了对人类交互动作的准确反应,又能保持生成内容的一致连贯,进而实现了从图像到世界生成的突破。
技术发展到这种程度,世界模型在快速生成游戏、动态视频生成等应用上已经让人看到了希望。
昆仑万维的空间智能愿景
远不止游戏
走向多模态、3D 世界,是生成式 AI 的下一个发展大方向。
在去年的一个演讲中,斯坦福大学教授李飞飞曾指出,过去几十年,尤其是深度学习变革的十多年里,我们在视觉智能方面取得了巨大进步,但目前的视觉智能仍存在局限,主要集中在二维图像的识别和理解。而现实世界是三维的,要真正解决视觉问题,并将其与行动联系起来,就必须发展空间智能。
空间智能是朝着全面智能迈出的一个基本且关键的步骤。只有让机器具备空间智能,才能使其更好地理解三维世界,从而实现更复杂、更高级的智能。
昆仑万维的 Matrix-Game 是空间智能领域交互式世界生成的重要里程碑,将为多个领域的发展带来重要影响。
首先,从内容生产的角度来看,Matrix-Game 可以支持更低成本、更高自由度的丰富、可控的游戏地图与任务环境生成,助力游戏开发。
此外,它还可以与昆仑万维的其他 AI 产品联动,比如天工大模型能为 Matrix-Game 生成的游戏世界提供更智能的 NPC 交互逻辑;Mureka 能为这些动态生成的场景和视频提供匹配的背景音乐和音效;SkyReels 可以为生成的游戏提供更多画面和剧情。这些产品就像一块一块的拼图,一旦整合到一起,能助力的不止是游戏生产,还有影视、广告、XR 等内容的生产。
其次,从科研角度来看,Matrix-Game 所代表的空间智能是一个极具潜力的方向,因为它和具身智能等方向的发展息息相关,谷歌、微软等大玩家都在此方向发力。Matrix-Game 作为中国首批具备可交互视频生成能力的世界模型,对于推动国内空间智能领域发展有重要意义 。
「实现通用人工智能,让每个人更好地塑造和表达自我」,这是昆仑万维的使命。 这个使命在空间智能时代有了更深远的意义。当人类能在三维世界中自由创造和交互,当想象力不再受制于技术门槛,我们才真正开启了表达自我的新维度。
过去半年多时间,昆仑万维在奖励模型、多模态、推理、视频生成等方向开源了一系列 SOTA 级别模型,如今又在空间智能方向再下一城。可以说,从二维到三维,从语言大模型到多模态生成再到如今的交互式世界模型,昆仑万维的技术布局越来越清晰:构建一个完整的 AI 创作生态。在这个生态中,每个人都能找到自己的创新空间,每个创意都有机会快速变成产品。一个想象力真正成为生产力的时代正在加速到来。
#Flow-GRPO
首次!流匹配模型引入GRPO,GenEval几近满分,组合生图能力远超GPT-4o
本文由香港中文大学与快手可灵等团队联合完成。第一作者为香港中文大学 MMLab 博士生刘杰,他的研究方向为强化学习和生成模型,曾获 ACL Outstanding Paper Award。
流匹配模型因其坚实的理论基础和在生成高质量图像方面的优异性能,已成为图像生成(Stable Diffusion, Flux)和视频生成(可灵,WanX,Hunyuan)领域最先进模型的训练方法。然而,这些最先进的模型在处理包含多个物体、属性与关系的复杂场景,以及文本渲染任务时仍存在较大困难。与此同时,在线强化学习因其高效探索与反馈机制,在语言模型领域取得显著进展,但在图像生成中的应用仍处于初步阶段。
为此,港中文 MMLab、快手可灵、清华大学等团队联合提出 Flow-GRPO,首个将在线强化学习引入 Flow Matching 模型的工作。在 Flow-GRPO 加持下,SD3.5 Medium 在 GenEval 基准测试中的准确率从 63% 提升到 95%,组合式生图能力超越 GPT4o,这说明流匹配模型还有很大提升空间,Flow-GRPO 的成功实践,为未来利用 RL 进一步解锁和增强各类流匹配生成模型(包括但不限于图像、视频、3D 等)在可控性、组合性、推理能力方面的潜力,开辟了充满希望的新范式。
论文标题:Flow-GRPO: Training Flow Matching Models via Online RL
论文链接:https://www.arxiv.org/pdf/2505.05470
代码地址:https://github.com/yifan123/flow_grpo
模型地址:https://huggingface.co/jieliu/SD3.5M-FlowGRPO-GenEval
作者团队也会尽快提供 Gradio 在线 demo 和包含大量生成 case,强化学习训练过程中图片变化的网页,帮助读者更好地体会 RL 对于流匹配模型的极大提升。
一.核心思路与框架概览
Flow-GRPO 的核心在于两项关键策略,旨在克服在线 RL 与流匹配模型内在特性之间的矛盾,并提升训练效率:
- ODE-SDE 等价转换: 流匹配模型本质上依赖确定性的常微分方程(ODE)进行生成。为了强化学习探索所需的随机性,作者采用了一种 ODE 到随机微分方程(SDE)的转换机制。该机制在理论上保证了转换后的 SDE 在所有时间步上均能匹配原始 ODE 模型的边缘分布,从而在不改变模型基础特性的前提下,为 RL 提供了有效的探索空间。
- 去噪步数「减负」提效: 在 RL 训练采样时,大胆减少生成步数(例如从 40 步减到 10 步),极大加速数据获取;而在最终推理生成时,仍然使用完整步数,保证高质量输出。在极大提升 online RL 训练效率的同时,保证性能不下降。

图 1 Flow-GRPO 框架
二. ODE to SDE
GRPO 的核心是依赖随机采样过程,以生成多样化的轨迹批次用于优势估计和策略探索。但对于流匹配模型,其确定性的采样过程不满足 GRPO 要求。为了解决这个局限性,作者将确定性的 Flow-ODE 转换为一个等效的 SDE,它匹配原始模型的边际概率密度函数,在论文附录 A 中作者提供了详细的证明过程。原始的 flow matching 模型 inference 的时候按照如下公式:

转变成 SDE 后,最终作者得到的采样形式如下:

之后就可以通过控制噪声水平的参数很好地控制 RL 策略的探索性。
三.Denoising Reduction
为了生成高质量的图像,流模型通常需要大量的去噪步骤,这使得在线强化学习的训练数据收集成本较高。作者发现,对于在线强化学习训练,较大的时间步长在样本生成时是多余的,只需要在推理时保持原有的去噪步骤仍能获得高质量的样本。作者在训练时将时间步长设置为 10,而推理时的时间步长保持为原始的默认设置 40。通过这样的「训练时低配,测试时满配」的设置,达到了在不牺牲最终性能的情况下实现快速训练。
四.核心实验效果
Flow-GRPO 在多个 T2I(文本到图像)生成任务中表现卓越:
- 复杂组合生成能力大幅提升: 在 GenEval 基准上,将 SD3.5-M 的准确率从 63% 提升至 95%,在物体计数、空间关系理解、属性绑定上近乎完美,在该评测榜单上效果超越 GPT-4o!

图 2 Flow-GRPO 训练过程中的性能持续上升

图 3 GenEval 各项指标详细结果

图 4 在 GenEval 基准上的定性比较
- 文字渲染精准无误: 视觉文本渲染准确率从 59% 大幅提升至 92%,可以较为准确地在图片中渲染文字。

- 更懂人类偏好: 在人类偏好对齐任务上也取得了显著进步。

- 奖励黑客行为显著减少: Flow-GRPO 在性能提升的同时,图像质量和多样性基本未受影响,有效缓解 reward hacking 问题。

五.总结与展望
作为首个将在线强化学习引入流匹配模型的算法,Flow-GRPO 通过将流模型的确定性采样机制改为随机微分方程(SDE)采样,并引入 Denoising Reduction 技术,实现了在流匹配模型上的高效在线强化学习。实验结果显示,即便是当前最先进的 flow matching 模型,在引入强化学习后依然有显著的性能提升空间。Flow-GRPO 在组合式生成、文字渲染和人类偏好等任务上,相比基线模型均取得了大幅改进。
Flow-GRPO 的意义不仅体现在指标上的领先,更在于其揭示了一条利用在线强化学习持续提升流匹配生成模型性能的可行路径。其成功实践为未来进一步释放流匹配模型在可控性、组合性与推理能力方面的潜力,尤其在图像、视频、3D 等多模态生成任务中,提供了一个充满前景的新范式。
#Minecraft Universe(MCU)
MCU:全球首个生成式开放世界基准,革新通用AI评测范式
该工作由通用人工智能研究院 × 北京大学联手打造。第一作者郑欣悦为通用人工智能研究院研究员,共同一作为北京大学人工智能研究院博士生林昊苇,通讯作者为北京大学助理教授梁一韬和通用人工智能研究院研究员郑子隆。
开发能在开放世界中完成多样任务的通用智能体,是AI领域的核心挑战。开放世界强调环境的动态性及任务的非预设性,智能体必须具备真正的泛化能力才能稳健应对。然而,现有评测体系多受限于任务多样化不足、任务数量有限以及环境单一等因素,难以准确衡量智能体是否真正「理解」任务,或仅是「记住」了特定解法。
为此,我们构建了 Minecraft Universe(MCU) ——一个面向通用智能体评测的生成式开放世界平台。MCU 支持自动生成无限多样的任务配置,覆盖丰富生态系统、复杂任务目标、天气变化等多种环境变量,旨在全面评估智能体的真实能力与泛化水平。该平台基于高效且功能全面的开发工具 MineStudio 构建,支持灵活定制环境设定,大规模数据集处理,并内置 VPTs、STEVE-1 等主流 Minecraft 智能体模型,显著简化评测流程,助力智能体的快速迭代与发展。
- 论文地址:https://arxiv.org/pdf/2310.08367
- 代码开源:https://github.com/CraftJarvis/MCU
- 项目主页:https://craftjarvis.github.io/MCU
- MineStudio:https://github.com/CraftJarvis/MineStudio
🚨开放世界AI,亟需理想的评测基准!
传统测试基准包含有标准答案的任务(如代码、推理、问答),但开放世界任务 Minecraft 有着完全不同的挑战:
- 目标开放多样:任务没有唯一解,策略可以千变万化;
- 环境状态庞杂:状态空间近乎无限,还原真实世界复杂度;
- 长周期任务挑战:关键任务持续数小时,智能体需长期规划。
在这样的环境中,我们需要的不只是一个评分系统,而是一个维度丰富、结构多元的综合评测框架。
🌌MCU:为开放世界 AI 打造的「全方位试炼场」
当前已有不少 Minecraft 的测试基准,但它们普遍面临「三大瓶颈」:
- 任务单一:局限于如挖钻石、制造材料等少数几个场景的循环往复。
- 脱离现实:部分建模任务甚至超出了普通人类玩家的能力范畴。
- 依赖人工评测:效率低下,导致评测难以规模化推广。

与之前 minecraft 测试基准对比示意图。
针对以上痛点,MCU 实现了以下三大核心突破:
一:3,452 个原子任务 × 无限组合生成,构筑海量任务空间
MCU 构建了一个覆盖真实玩家行为的超大任务库:
- 11 大类 × 41 子类任务类型:如挖矿、合成、战斗、建造等;
- 每个任务都是「原子级粒度」:可独立测试控制、规划、推理、创造等能力;
- 支持 LLM 动态扩展任务,比如:用钻石剑击败僵尸、雨天徒手采集木材、
在沙漠中建一座水上屋。
🔁任意组合这些原子任务,即可生成无限的新任务,每一个都对 AI 是全新挑战!

模拟多样化真实世界挑战。
二. 任务全自动生成 × 多模态智能评测,革新评估效率
GPT-4o 赋能,一句话生成复杂世界:
- 自动生成完整的任务场景(包括天气、生物群系、初始道具等)。
- 智能验证任务配置的可行性,有效避免如「用木镐挖掘钻石」这类逻辑错误型任务。
VLM(视觉语言模型)驱动,彻底改变了传统人工打分的低效模式:
- 基于 VLM 实现对任务进度、控制策略、材料利用率、执行效率、错误检测及创造性六大维度的智能评分。
- 模型自动生成详尽的评估文本,评分准确率高达 91.5%;
- 评测效率相较人工提升 8.1 倍,成本仅为人工评估的 1/5!

任务生成 x 多模态评测流程图。
三:高难度 × 高自由度的「试金石」任务设计,深度检验泛化能力
MCU 支持每个任务的多种难度版本,如:
- 「白天在草原击杀羊」VS「夜晚在雨林躲避怪物并击杀羊」;
- 「森林里造瀑布」VS「熔岩坑边缘建造瀑布」。
这不仅考验 AI 是否能完成任务,更深度检验其在复杂多变环境下的泛化与适应能力。
📉打破「模型表现良好」的幻象:现有 SOTA 模型能否驾驭 MCU ?
我们将当前领域顶尖的 Minecraft 智能体引入 MCU 进行实战检验:GROOT:视频模仿学习代表;STEVE-I:指令执行型控制器;VPT(BC/RL):基于 YouTube 行为克隆训练而成的先驱。结果发现,这些智能体在简单任务上表现尚可,但在面对组合任务和陌生配置场景时,完成率急剧下降,且错误识别与创新尝试是其短板。




SOTA 模型在 MCU 上的测试结果。
研究团队引入了更细粒度的任务进度评分指标(Task Progress),区别于传统 0/1 式的「任务完成率」,它能动态刻画智能体在执行过程中的阶段性表现,哪怕任务失败,也能反映其是否在朝正确方向推进。
实验发现,当前主流模型如 GROOT、STEVE-I、VPT-RL,在原子任务中尚有可圈可点的表现,但一旦面对更具组合性和变化性的任务,其成功率便会骤降。甚至对环境的微小改动也会导致决策混乱。比如「在房间内睡觉」这个看似简单的任务,仅仅是将床从草地搬到屋内,就让 GROOT 频繁误把箱子当床点击,甚至转身离开现场——这揭示了现有模型在空间理解与泛化上的明显短板。
更令人警醒的是,智能体在建造、战斗类任务中的「创造性得分」与「错误识别能力」几乎全面落后。这说明它们尚未真正具备人类那种「发现问题、调整策略」的自主意识,而这正是通用智能迈向下一个阶段的关键。
MCU 的评测结果首次系统性地揭示了当前开放世界智能体在「泛化、适应与创造」这三大核心能力上存在的鸿沟,同时也为未来的研究指明了方向:如何让 AI 不仅能高效完成任务,更能深刻理解任务的本质,并创造性地解决复杂问题。
#2025,Agent智能体应用大年
Sam Altman最新深度专访
今天凌晨3点,全球著名投资机构红杉资本(Sequoia Capital)发布了,Sam Altman参加其举办的“2025 AI Ascent”大会。
OpenAI联合创始人兼首席执行官SamA ltaman作为特邀嘉宾,接受了32分钟的专访和现场提问。Altaman回顾了OpenAI的创业历程、产品规划/发展、对AI行业的看法等。
在谈到火爆全球的AI Agent时,Altaman认为,2025年将是智能体大规模应用的一年,尤其是是在编程领域,智能体会成为主导力量。并在未来几年内,智能体作为“数字化劳动力”帮助各行业节省大量时间、提升工作效率以创造巨大商业价值。
其实在这之前,Altaman就曾在其个人博客上写了一篇深度长文,介绍智能体将如何增强世界经济、改变现有数字化工作模式。事实上,微软、OpenAI作为全球最大的智能体开发平台之一,在2025年已经有大量实际应用案例,包括众多世界500强客户。
下面「AIGC开放社区」将根据问答的形式,为大家整理了专访内容,期间Altaman也接受了现场观众的提问。英语好的小伙伴,也可以直接看原视频。
主持人:欢迎下一位嘉宾,SamAltman。你已经是这里的常客了,感谢你再次来到我们的活动现场。这里还是OpenAI的第一个办公室对吧?
Altman:是的,这里就是我们的第一个办公室。2016年的时候,我们刚刚起步,当时这里只有14个人左右,我们围坐在一起,看着白板,讨论着我们要做什么。那时候,我们更像是一个有强烈信念和方向的研究实验室,但并没有一个明确的行动计划。甚至公司或产品的概念都还难以想象,像LLMs(大语言模型)这样的想法还非常遥远。
主持人:说到2016年,当时你们有没有想过今天会取得这样的成就?
Altman:没有。当时我们只是在尝试一些新东西,比如玩视频游戏。现在我们在这方面已经做得很好了。不过,我们的第一个消费者产品并不是ChatGPT,而是Dolly。我们的第一个产品其实是API。我们尝试了几个不同的方向,最终决定要构建一个系统来看看它是否有效。我们不仅仅是写研究论文,我们还尝试玩视频游戏、操作机器人手等。
,时长31:58
完整视频
后来,我们开始尝试无监督学习,并构建语言模型,这导致了GPT-1、GPT-2的出现,到了GPT-3时,我们觉得这个东西有点酷,但还不知道该怎么用它。我们也意识到,我们需要更多的资金来继续扩展。从GPT-3到GPT-4,我们进入了数十亿美元模型的世界,这对于纯粹的科学实验来说很难做到,除非你像粒子加速器那样的项目。
于是,我们开始思考如何将这个东西变成一个可以支撑所需投资的业务。我们觉得这个方向可能会变得有用。我们曾将GPT-2作为模型权重发布,但并没有引起太多关注。
我观察到的一个现象是,如果你做一个API,通常会有一些好处。这在许多YC公司中都是如此。而且,如果你能让东西变得更容易使用,通常会有很大的好处。所以,我们决定写一些软件,很好地运行这些模型。我们没有去构建一个产品,因为我们不知道该构建什么,而是希望通过API让别人找到可以构建的东西。
2020年6月左右,我们发布了GPT-3API,世界并没有太在意,但硅谷却觉得这有点酷,觉得它指向了某种东西。尽管大多数世界没有关注,但一些初创公司的创始人觉得这很酷,甚至有人说这是AGI(通用人工智能)。我记得唯一真正用GPT-3API构建实际业务的公司是一些提供文案撰写服务的公司。那是GPT-3唯一超过经济门槛的用途。
但我们注意到,尽管人们无法用GPT-3API构建很多伟大的业务,但他们喜欢与它交谈。当时它在聊天方面很糟糕,我们还没有想出如何通过RHF(可能指某种技术或方法)让它更容易聊天,但人们仍然喜欢这么做。从某种意义上说,这是API产品唯一的杀手级用途,除了文案撰写,这也最终促使我们构建了ChatGPT。
到了ChatGPT3.5发布时,可能已经有八种类别而不是一个类别可以用API构建业务。但我们坚信人们只是想与模型交谈。我们曾做过Dolly,Dolly表现还可以,但我们知道我们想构建这个模型,这个产品,让你能够与模型交谈,并且随着我们能够进行的微调,我们更坚定了这个想法。这个产品在2022年11月30日左右发布,大约六年的时间里,今天已经有超过5亿人每周都在使用它。
主持人:是啊,你已经参加了我们三次活动,期间经历了许多起伏,但似乎在过去六个月里,你们一直在快速推出产品。你是如何让一家大公司随着时间的推移加快产品发布的速度的?
Altman:我认为许多公司犯的一个错误是,它们变大了,但并没有做更多的事情。它们只是变大了,因为它们本应如此,但它们发布的产品数量却没有增加。这就是当事情变得像糖浆一样黏稠时。我喜欢让每个人都忙碌起来,让团队保持小规模,并且要做的事情要与你拥有的人数成正比,否则你就会有40个人参加每个会议,在产品的小部分上争吵不休。
有一个古老的商业观察结果是,一个好的高管是一个忙碌的高管,因为你不想让人们无所事事。但我认为,在我们公司以及许多其他公司中,研究人员、工程师、产品人员几乎创造了所有的价值,你希望这些人忙碌且具有影响力。
所以,如果你要扩张,你最好做更多的事情,否则你就会有很多人坐在房间里争吵、开会或讨论各种事情。所以,我们尽量让相对较少的人承担大量的责任。而要让这种方式奏效,就需要做很多事情。而且,我们真的认为现在有机会去构建一个重要的互联网平台。但要做到这一点,如果我们真的要成为人们在许多不同服务中、在他们的生活中以及在所有这些不同类别和较小类别中使用的个性化AI,那么我们需要弄清楚如何启用这些东西,这就有太多的东西需要去构建了。
主持人:在过去六个月里,有没有你特别自豪推出的东西?
Altman:现在的模型已经很好了。当然,它们仍然有需要改进的地方,我们正在快速地进行改进,但我认为ChatGPT已经是一个非常好的产品,因为模型本身非常好。当然,还有其他因素也很重要,但我对一个模型能够如此出色地完成如此多的事情感到惊讶。你们正在构建小型和大型模型,做很多事情,正如你所说。那么,观众们该如何避免成为你们发展的障碍呢?
Altman:我想,把我们看作是人们的核心AI订阅和使用那种东西的方式就好。其中一部分将是ChatGPT内部的内容,我们还会有一些其他真正关键的部分。但大部分情况下,我们希望构建越来越智能的模型。我们会有一些类似未来设备、未来事物的界面,这些有点像操作系统。然后,我们知道我们还没有完全弄清楚API或SDK,或者你想叫它什么,以真正成为我们的平台。但我们会有办法的。
这可能需要我们尝试几次,但我们最终会做到的。我希望这能够在全球范围内创造巨大的财富,并让人们在上面构建东西。但我们会去构建核心AI订阅和模型,然后是核心服务,还有很多其他的东西需要构建。所以,不要成为核心AI订阅,但你可以做其他所有事情。我们会尝试的。如果你能提供比我们更好的核心AI订阅服务,那就太好了。
主持人:有传言说你们正在筹集400亿美元的资金,估值达到3400亿美元。那么,从现在开始,你们的雄心壮志有多大呢?
Altman:我们会继续努力打造出色的模型,推出优质的产品,除此之外并无其他宏大的计划。我们坚信,只要专注于眼前的任务,就能取得成功。我们深知,要实现目标,需要大量的AI基础设施,需要构建大规模的AI工厂,不断提升模型性能,打造卓越的消费级产品以及完善相关配套服务。我们以灵活应变著称,会根据世界的变化及时调整策略。至于明年要构建的产品,我们现在可能都还没开始思考。我们有信心能够打造出人们真正喜爱的产品,对我们的研究路线图也充满信心,目前从未像现在这样乐观。研究路线图上当然是要打造更智能的模型,但我们只会专注于眼前的一步或两步。你相信向前推进,而不是倒推规划。
Altman:谁有问题?有人要提问吗?
观众:您认为大公司在转型为更AI原生的组织方面,无论是使用工具还是生产产品,都做错了什么?很明显,小公司在创新方面远远超过了大公司。
Altman:我觉得这在每次重大的技术变革中都会发生。这对我来说并不奇怪。他们做错的事情和他们一直以来做错的事情一样,那就是人们和组织都非常固步自封。如果每季度或每两季度事情都在快速变化,而你有一个每年只开一次会以决定允许使用哪些应用程序以及将数据放入系统意味着什么的信息安全委员会,那真的是太痛苦了。但这就是创造性破坏,这就是初创公司获胜的原因,这就是行业发展的方式。
我对大公司愿意这样做的速度感到失望,但并不惊讶。我的预测是,还会有一两年的挣扎,假装这一切不会改变一切,然后是最后时刻的投降和匆忙行动,但那时已经太迟了。一般来说,初创公司只是以旧的方式超越了人们。这也会发生在个人身上,比如和一个20岁的年轻人聊聊,看看他们是如何使用ChatGPT的,然后和一个35岁的人聊聊,看看他们是如何使用它的或其他服务的,差异令人难以置信。这让我想起了智能手机刚出来的时候,每个孩子都能非常熟练地使用它,而年纪较大的人则花了三年时间才学会基本的操作。当然,人们最终会融合在一起,但目前在AI工具上的代沟是疯狂的,而公司只是这种现象的另一个症状。
主持人:有没有人还有问题?只是跟进一下,年轻人使用ChatGPT的哪些酷炫用例可能会让我们感到惊讶?
Altman:他们真的把它当作一个操作系统来使用。他们会以复杂的方式设置它,将其连接到许多文件,并且他们在脑海中记住了相当复杂的提示,或者你知道的,他们会复制粘贴这些内容。当然,这些都很酷,也很令人印象深刻。还有另一种情况,那就是他们不会在不做决策之前不询问ChatGPT他们应该做什么。
它拥有他们生活中每个人的完整上下文以及他们所谈论的内容,你知道的,记忆功能在这方面发生了真正的变化。但总的来说,可以简化为,老年人将ChatGPT用作谷歌的替代品,也许30多岁和40多岁的人将其用作生活顾问,而大学生则将其当作操作系统。
主持人:你们在OpenAI内部是如何使用它的呢?
Altman:它为我们编写了很多代码。具体有多少,我也不清楚。而且,当人们提到代码数量时,我觉得这总是很愚蠢,因为你说微软代码中有30%是……以代码行数来衡量是如此荒谬的方式。也许我能说的有意义的事情是,它正在编写真正重要的代码,而不是那些无关紧要的部分。
主持人:下一个问题。我觉得阿尔弗雷德关于你们想去哪里的问题的答案很有趣,主要集中在消费者和核心订阅上,而且你们的大部分收入也来自消费者订阅。那么,为什么在10年后还要保留API呢?
Altman:我真的希望所有这些最终都能合并成一件事,比如你可以用OpenAI登录其他服务,其他服务应该有一个令人难以置信的SDK来接管ChatGPT的UI。但就目前而言,你将拥有一个了解你的个性化AI,它拥有你的信息,知道你想要分享什么,也知道你生活中的所有上下文,你将希望能够在很多地方使用它。当然,我同意目前版本的API离那个愿景还很远,但我认为我们可以做到。
主持人:有人想接着问一个问题。你刚才说的有点像我的问题。我们这些构建应用层公司的人,我们想使用这些不同的API组件,甚至是尚未发布的深度研究API,并用它们来构建东西。那么,这会是你们的优先事项吗?我们应该如何思考这个问题?
Altman:我认为最终会有一种介于两者之间的新协议,类似于HTTP,用于未来互联网的发展。在这个协议下,事物将被联邦化并分解为更小的组件,智能体将不断地公开和使用不同的工具,而身份验证、支付、数据传输等功能都将在这个层面上内建,每个人都相互信任,所有事物都能相互交流。我并不完全清楚这将是什么样子,但它正在逐渐从迷雾中显现出来。随着我们对它有了更好的理解,这可能需要我们经过几次迭代才能实现。但这就是我想看到的发展方向。
观众:嗨,Sam。我对在游乐场中尝试语音模型感到非常兴奋,我有两个问题。首先,语音对于OpenAI在基础设施方面的优先级有多重要?你能分享一下你对它将如何出现在产品和ChatGPT核心产品中的看法吗?
Altman:我认为语音极其重要。老实说,我们还没有开发出足够好的语音产品。没关系。就像我们在开发出优秀的文本模型之前也花了一段时间一样。我们会解决这个问题的。当我们做到这一点时,我认为很多人会更倾向于使用语音交互。当我第一次看到我们目前的语音模式时,最让我感兴趣的是它在触摸界面之上开辟了一个新的交互层面,你可以一边说话一边在手机上点击操作。
我仍然认为语音与图形用户界面结合会有一些令人惊叹的创新,但我们还没有找到。在那之前,我们会先让语音变得真正出色。而且,我认为这不仅会使现有设备更加酷炫,而且我认为语音将能够催生出全新的设备类别,只要我们能让它达到真正人类水平的语音交互。
观众:类似的问题。关于编程,我很好奇,编程只是另一个垂直应用,还是它在OpenAI的未来中更具核心地位?编程在未来OpenAI的定位是怎样的?
Altman:编程在未来OpenAI的定位中更为核心。目前,如果你向ChatGPT提问,你得到的是文本回复,或许还有图像。但你希望得到的是一个完整的程序。也就是说,你希望这些模型能够通过编程来在现实世界中执行各种操作,比如调用一系列API等。
因此,我认为编程将处于一个核心类别中。我们当然也会通过API和平台将其公开。不过,ChatGPT在编写代码方面应该表现出色。所以,我们会从助手时代过渡到智能体时代,最终实现应用的全面升级。这个过程会感觉非常连贯。
观众:我有一个关于路线图的问题。你对更智能的模型充满信心,我有一个心理模型,其中包含一些要素,比如更多的数据、更大的数据中心、Transformer架构、测试时计算等。有没有一些被低估的要素,或者一些可能不在大多数人心理模型中的东西,但会成为其中的一部分?
Altman:这些要素每一个都很困难,当然,最大的杠杆仍然是重大的算法突破。我认为可能还有一些10倍甚至100倍的改进空间,虽然这样的机会不多,但即使有一个或两个也是意义重大的。不过,算法、数据、计算能力,这些是主要的要素。
观众:嗨,我有一个问题。你领导着世界上最优秀的机器学习团队之一。你是如何在让像Issa这样的聪明人追逐深度研究或一些看起来令人兴奋的东西,和自上而下地推动项目,比如我们打算构建这个,我们打算让它实现,尽管我们不知道它是否可行之间取得平衡的?有些项目需要如此多的协调,以至于必须有一些自上而下的协调,但我认为大多数人在这方面做得太过头了。我们花了很多时间去研究一个运作良好的研究实验室是什么样子的。事实上,几乎能给我们提供建议的人都已经去世了。
人们经常问我们,为什么OpenAI能够持续创新,而其他AI实验室却只是模仿,或者为什么生物实验室X没有取得好成绩,而生物实验室Y却取得了好成绩。我们一直在说,我们观察到的原则是什么,我们是如何从历史中学习它们的。然后每个人都说,好的,但我要去做别的事情。我们说,没关系,你来找我们是为了寻求建议,你想做什么就去做吧。但我发现,我们尝试运行研究实验室的这些原则,我们并没有发明它们,我们是毫不羞愧地从其他优秀的历史研究实验室抄袭过来的,这些原则对我们来说效果很好。
然后,那些自认为有聪明的理由去做其他事情的人,结果并不成功。我认为这些大型模型的一个真正有趣的事情是,作为一个热爱知识的人,它们有可能让我们回答这些令人惊叹的长期人文问题,比如循环变化、艺术等有趣的事情,甚至还可以检测社会中是否存在系统性偏见等微妙的事情,这些是我们以前只能假设的。我想知道OpenAI是否有关于与学术研究人员合作的想法,或者是否有路线图,以帮助解锁这些我们第一次能够学习的新事物,无论是人文科学还是社会科学。
Altman:我们确实有学术研究项目,我们与研究人员合作,有时会做一些定制工作,但大多数时候,人们只是说,我想访问这个模型,或者也许我想访问基础模型。我认为我们在这方面做得很好。我们激励结构的很大一部分是推动模型变得尽可能智能、廉价和广泛可用,这很好地服务于学术界和整个世界。
所以,我们大约90%的努力都集中在让通用模型在各个领域变得更好。我很好奇你是如何看待定制化的。你提到的联邦化,比如用OpenAI登录,带来你的记忆和上下文。我只是好奇你如何看待定制化,以及这些不同的应用特定的后训练是否只是试图让核心模型变得更好的一种权宜之计。
Altman:从某种意义上说,我认为理想的状态是一个非常小的推理模型,拥有万亿个标记的上下文,你可以将你整个生活都融入其中。这个模型永远不会重新训练,权重永远不会定制。但它能够在你的整个上下文中进行推理,并且高效地做到这一点。
你生命中的每一次对话、你读过的每一本书、你收到的每一封邮件、你查看过的每一件事都在其中,再加上你从其他来源连接的所有数据。你的生活不断追加到上下文中,你的公司也会对公司的数据做同样的事情。我们今天做不到这一点。但我认为任何其他东西都是这种理想状态的妥协,我希望我们最终能够实现这种定制化。
观众:你认为未来12个月里,大部分价值创造会来自哪里?是更先进的记忆能力,还是允许智能体做更多事情并与现实世界互动的安全性或协议?
Altman:从某种意义上说,价值将继续来自三个方面:构建更多的基础设施、更智能的模型,以及构建将这些东西整合到社会中的框架。如果你推动这些方面,我认为其他事情会自行解决。在更详细的层面上,我认为2025年将是智能体完成大规模应用的年份。特别是编程领域,我预计这将是一个主导类别。
,时长01:48
明年,我认为会有更多像人工智能发现新事物的情况,也许人工智能会取得一些重大的科学发现,或者协助人类做到这一点。你知道的,我有点相信,人类历史上大部分真正的可持续经济增长来自于在你已经遍布全球之后,大部分来自于更好的科学知识,然后将其应用于世界。
然后在2027年,我认为这一切将从智力领域转移到物理世界,机器人将从一个新奇事物转变为一个真正的经济价值创造者。但这只是我目前的一个即兴猜测。
主持人:我可以补充一个问题吗。现在有了更多的视角,你对这里的创始人们有什么关于韧性、耐力和力量的建议吗?
Altman:随着时间的推移,事情会变得更容易。作为创始人的旅程中,你会面临很多逆境,挑战会变得更大,风险也会更高,但随着时间的推移,应对这些挑战的情感负担会变得更容易。所以,在某种意义上,尽管抽象地说,挑战变得更大、更困难,但你的应对能力、积累的韧性会随着时间的推移而增强。
而且,我认为对于创始人来说,最大的挑战不是挑战发生的时候。在公司历史上,很多事情都会出错。在事情发生的那一刻,你可以得到很多支持,你可以依靠肾上腺素来应对。
你知道的,即使是真正的大事,比如公司耗尽资金倒闭,也会有很多人来支持你。你可以度过难关,然后继续前进。我认为真正难以应对的是危机之后的余波。人们更多地关注如何在危机发生的那一刻、第二天或第三天应对,而真正有价值的是学会如何在危机发生后的第60天,当你试图重建的时候,如何应对。我认为这是一个可以练习并变得更好的领域,谢谢大家。
#网友痛批不如GPT2025万篇投稿破纪录,作者被逼全员审稿
ICCV 2025评审结果公布了!
这届ICCV论文投稿数量创历史新高。据大会官方公布,今年共收到11152份有效投稿,远超往届规模。
ICCV 2023顶会共收到了8088篇投稿
截至评审截止日期,11152篇有效投稿论文均已获得至少3份评审意见。
作者可以在5月16日晚上11:59(夏威夷时间)前提交rebuttal,ICCV 2025将于6月25日公布最终录用决定。
根据Paper Copilot发布的统计数据,论文评分曲线现已公开。
评分含义如下:
1:拒绝
2:弱拒绝
3:边缘拒绝
4:边缘接受
5:弱接受
6:接受
到目前为止,大约36%的人得分在3.67以上,只有4%的得分高于4.0。得分在3.67到4.0之间,大约有50%-70%的录用机会。
作为计算机视觉三大顶会之一,ICCV每两年举办一次,今年将于10月19日至23日,在夏威夷檀香山举办。
目前,已有许多童鞋晒出自己的评审结果了。
评审结果,遭全网吐槽
由于评审意见的公开时间多少有些「奇葩」,目前的讨论还没有很多。
网友表示,看到的大多是负面评论、攻击和批评。
网友吐槽:这是人能写出来的review吗?
「我都不会说是GPT写的,因为GPT比这个人有脑子多了,这个只能称为类人。」
大意如下:
该论文提出了一种通过视觉-语言模型结合推理阶段搜索来提高模型「理解力」的方法,该方法本质上是一种检索增强生成 (RAG) 方法。该方法包括预测生成内容之前的「后续内容的值」,并声称能够减少模型幻觉现象。我试图在论文中找到这些被引用的术语的定义。如果论文旨在提高模型的「理解力」,那么理应存在一个精确且客观的衡量标准,对于「幻觉」现象也应如此。然而,我并没有找到这些术语的明确定义,这导致「提高理解力」这一目标的定义实际上取决于用于衡量它的方法,即第4.2节中使用的基准测试。因此,我只能认为该论文在特定的一组基准测试所定义的任务上表现良好,而这种良好表现也是通过同样的基准测试来衡量的。在有限的评审时间内,我无法确定该方法在概念上是否可靠。我希望看到这些术语的明确定义、用于衡量它们的指标,以及优化这些指标的原理,特别是该论文提出的方法是如何实现这些优化的。考虑到影响该领域实证性能的诸多因素,我很难仅凭实验结果来判断其学术价值。
Pinar表示,「真诚感谢「辛勤」工作的ICCV审稿人,你们怕不是直接把ChatGPT的结果复制粘贴上来了!这行云流水般的胡言乱语,配上量子级的模棱两可,同时接受和拒绝,简直是薛定谔的审稿意见。」
Akshit认为,「所谓的领域专家显然误解了概念,这让我感到滑稽。我被要求阐释一些要么不存在,要么补充材料中已有的内容。」
还有网友表示沮丧,没有一个审稿人阅读补充材料。
还有人吐槽,比CVPR有更多不称职的评审。
不过,也有网友的积极评价——对ICCV评审质量提升感到惊讶,新政策确实发挥作用了。
还有一些网友晒出凡尔赛成绩单。
ICCV投稿量从2019年约4300篇逐步增长,到2021年突破6000篇,2023年更跃升至8000+篇。
论文录用率则在25%-26%区间波动,极少数论文被选为大会报告,大多数以Poster形式交流成果。
ICCV对审稿人的要求
ICCV通常会邀请近年在顶级会议(CVPR/ICCV/ECCV)或相关期刊上有发表成果的学者作为审稿人。
大会共邀请了6位大会主席 (PC)、500位领域主席 (AC),以及约8000名审稿人参与评审。
全员参与审稿,离大谱?
每位投稿论文的作者都被要求担任审稿人。
前段时间,谷歌DeepMind研究员刘若茜吐槽了ICCV 2025全员参与审稿的制度。
她表示,我理解审稿人紧缺的现状,但强制规定「作者必须参与审稿」,且任何一人超期未完成,就会导致其所有论文被直接拒稿,这种规定实在荒谬了。
「完全不考虑作者也是人,谁还没个急事难处」?
马克斯·普朗克研究所主任Michael Black非常认同,他表示会修改要求,让任何在CVPR/ICCV/ECCV发表过3篇以上论文作者必须参与评审。
这不有作者因为错过了评审截止日期,为自己论文被拒担惊受怕。
ICCV官方公布了最终结果,97.18%评审按时提交,只有95名审稿人错过了截止日期。
禁用LLM评审
此外,ICCV 2025明确禁止在评审过程中使用大模型(如ChatGPT),以确保评审意见的原创性和真实性。
审稿人必须提供真实评论,一方面对论文作者负责,另外在线聊天机器人会收集对话历史记录,以改进其模型。
因此,在评审过程中使用它们将违反ICCV保密政策。
加州大学圣地亚哥分校的Alex表示,完成今年的ICCV审稿后,整个人都不好了。
评论区表示同样感觉很糟糕,整体论文质量在下滑。
评审规则延续了以往的高标准,严格执行评审截止日期,确保每篇论文至少获得三份评审意见。
任何未能在截止日期前提交评审的审稿人,其作为作者的论文也将被直接拒稿。
根据官方统计,97.18%的评审意见均按时提交,仅有95位审稿人错过截止时间,导致112篇论文可能受影响。
ICCV建议审稿人发掘论文中的闪光点,鼓励具有创新性或大胆假设的工作。
如果一篇论文提出了新的思想,即使在某标准数据集上未超过SOTA性能,也不应仅因为这一点而被拒稿。
来自约克大学CS助理教授Kosta Derpanis转发一位网友的建议,勉励所有拿到不如意结果的研究者们:
对某些人来说,ICCV的评审结果并非如你所愿。 这就是学术发表的常态——既要享受偶尔的成功喜悦,也要应对常见的失意挫折。这就是游戏的规则。
不妨趁此机会重新调整,仔细审视评审意见中的有效反馈,有价值的建议往往就藏在其中。有时你需要更深入地挖掘,但这些意见确实能帮助提升你的研究成果乃至整体研究思路。
对于那些还有机会的同行,祝你们好运!我见过太多在rebuttal阶段实现翻盘的论文。
同行评审:荣耀与荒诞
针对ICCV评审结果,来自Pattern Recognition Lab的科学家Andreas Maier发表了一篇长文,阐述了当前同行评审的现状。
评审:简洁批判,但过于简短
一位审稿人收到的论文,主题是降低医学图像生成计算复杂性的技术——将高维卷积分解为低维操作。
这是个有趣的点子,虽然不算全新,但在技术上似乎有潜力。
审稿人仔细研读后,将目光锁定在论文的评估部分,给出评价:
论文仅在一个鲜为人知的单一模态上测试,缺乏对公共数据集的验证(审稿人贴心地列出了可用的数据集建议);性能提升的报告缺乏鲁棒性检查;更别提视觉比较的呈现混乱,连CT成像的标准Hounsfield单位都没用上。
简而言之:好想法,烂评估。于是,审稿人给出了一个「边缘拒绝」(Borderline Reject)的评价。
他的评审简洁但精准:总结了核心理念,肯定了优点,指出了数据集选择、泛化不足和图像呈现的具体问题。
这样的评审,专业、中肯、切中要害。
然而,他万万没想到,这份简洁的评审竟成了后续「剧情」的导火索。
领域主席「模板攻击」
几周后,审稿人收到了AC的反馈。
原本期待的是技术性的讨论,然而,现实却像一部黑色喜剧:
AC指责审稿人的评论「缺乏足够细节」,甚至引用了评审中根本不存在的语句!
这份反馈,更像是从《ICCV被动攻击反馈模板手册™》中直接复制粘贴,机械得让人怀疑AC是否真的读过评审。
审稿人震惊之余,礼貌但犀利地回复:指出自己的评论基于领域标准,而引用的「原文」子虚乌有,并反问道AC能否具体说明问题出在哪里。
这一幕,堪称学术界「皇帝的新衣」——模板化的反馈不仅无助于改进,反而暴露了评审流程中的官僚病。
程序主席快速反应
审稿人没有让这场闹剧无休止地发酵,他将问题升级到程序主席,简明扼要地陈述了事实。
好在,程序主席的反应堪称神速。
不到两小时,线下讨论展开;当晚,AC亲自回复审稿人,问题迅速化解。
一场可能拖延数周的学术纷争,在一天内画上句号。
同行评审的「抓马」
这场风波虽小,却折射出大规模同行评审的深层问题。
在ICCV这样的顶会上,审稿人,尤其是资深学者,常常需要同时处理数十篇论文,时间捉襟见肘。
AC则要协调数百篇论文、评审和rebuttal,堪称「学术项目经理」。
在这种高压环境下,人与人之间的对话,逐渐被模板、复选框、自动回复所取代。
结果呢?
评审的质量标准开始滑向「容易量化」的指标:字数、格式、是否填满表格。
一份两页的泛泛之谈,可能顺利过关,而一份紧凑、切中要害的论文,却被打上「细节不足」的标签。
AC忙碌到,只能复制粘贴反馈,甚至懒得读评审原文。这种官僚式回复,让同行评审失去了它应有的灵魂。
ICCV 2025的这场风波提醒我们:
评审的质量不在于篇幅,而在于洞察;评审的意义不在于形式,而在于对话。
参考资料:
https://x.com/papercopilot/status/1920964042123858217
https://iccv.thecvf.com/Conferences/2025/ReviewerGuidelines
https://papercopilot.com/statistics/iccv-statistics/

















 903
903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









