







资讯 | Deepseek-V2多头潜在注意力(Multi-head Latent Attention)原理及PyTorch实现
GS Lab 图科学实验室Graph Science Lab 2025年01月23日 22:48 广东

探索 DeepSeekV2 中的 GPU 利用率瓶颈和多头潜在注意力实现。
在本文中,我们将探讨两个关键主题。首先,我们将讨论和了解 Transformer 模型(也称为大型语言模型 (LLM))在训练和推理过程中遇到的瓶颈问题。
然后,我们将深入研究 LLM 架构中有关 KV 缓存的特定瓶颈问题,以及 DeepSeek 的创新方法多头潜在注意力如何解决这个问题。

http://arxiv.org/pdf/2405.04434v5
DeepSeek-V2 是一种强大的开源混合专家 ( MoE ) 语言模型,其特点是通过创新的 Transformer 架构进行经济的训练和高效的推理。它包含236B 个总参数,其中每个 token 激活21B ,并支持128K 个token的上下文长度。
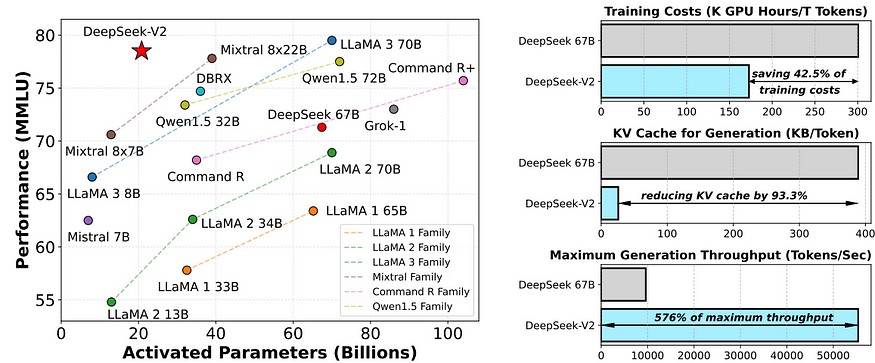
DeepSeek-V2 性能表现位居开源模型前列,成为最强开源 MoE 语言模型。在 MMLU 上,DeepSeek-V2 仅用少量激活参数就取得了顶级性能。与 DeepSeek 67B 相比,DeepSeek-V2 性能大幅提升,节省了 42.5% 的训练成本,减少了93.3% 的KV 缓存,最大生成吞吐量提升至 5.76 倍。
GPU 处理中的瓶颈问题
近年来,图形处理单元 (GPU) 的研究和投资激增。事实上,当我写这篇文章时,我偶然看到了NVIDIA已成为第二大最有价值的上市公司的消息,其估值高达3 万亿美元。
但为什么会这样呢?答案在于 AI 模型需要运行大量的数学运算,而 GPU 有助于加快运行速度。它们在执行计算方面已经变得非常高效,因此,它们的需求量很大,这并不奇怪。
GPU 的速度已经变得太快了。它们能够以惊人的速度执行计算,以每秒浮点运算次数 (FLOP) 来衡量。
但存在一个问题——计算速度远远超过了内存带宽(GB/s),即 GPU 中不同内存区域之间传输数据的速度。这种不匹配造成了瓶颈,拖慢了整个过程。
为了帮助说明瓶颈问题,让我们看一下图 1 和图 2。
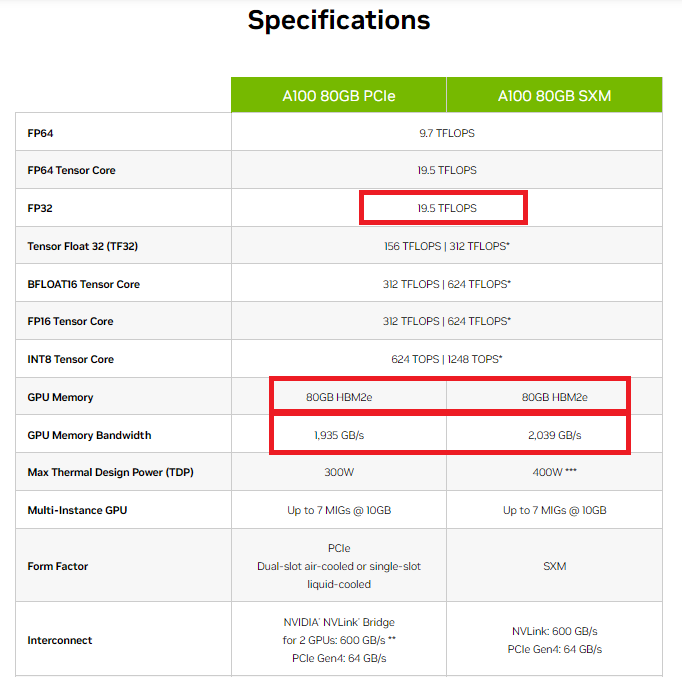
图片 1
图1显示了 NVIDIA A100 GPU 的规格。如您所见,这款强大的 GPU 可以在 FP32 模式下执行令人印象深刻的 19.5 TFLOP(万亿次浮点运算)。但是,其 GPU 内存带宽限制在 2 TB/s 左右。虽然这两者是两码事,但还是有联系的。
这突出了一个关键点,瓶颈并不总是在于我们可以执行多少操作,而是在于我们在 GPU 的不同部分之间传输数据的速度有多快。如果数据传输的数量随着内存的增加而增加,延迟也会增加。*我们计算中涉及的张量的大小和数量在其中起着重要作用。
例如,对同一个张量多次计算同一个操作可能比对大小相同的不同张量计算同一个操作更快。这是因为 GPU 需要移动张量,这会降低速度。因此,我们的目标不应该只是优化我们执行的操作数量(KV 缓存、MQA、GQA),还应该尽量减少我们需要进行的内存访问和传输。
图 2 将有助于澄清这些概念,并让您更好地理解这些操作的工作原理。图 2 说明了 GPU 中 Attention 操作的发生方式。
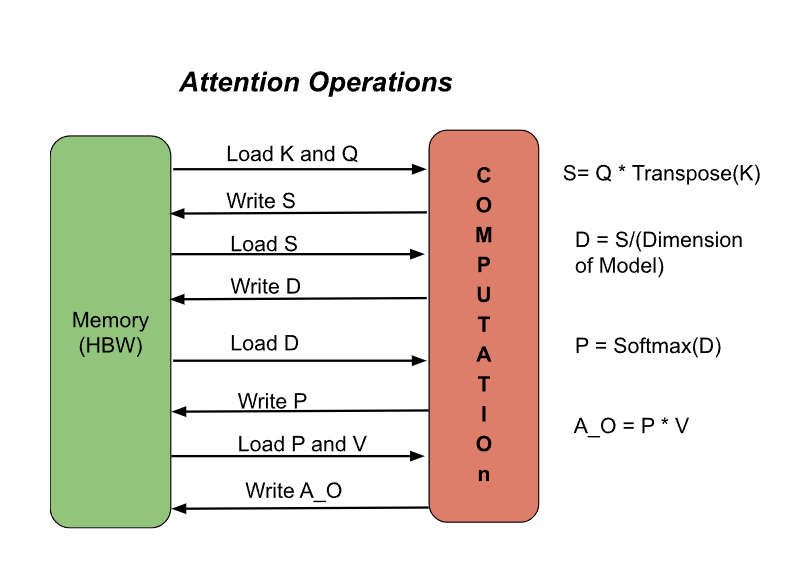
图 2:GPU 中的注意力操作
现在我们已经探讨了瓶颈问题,很明显它可以显著增加延迟。为了解决这个问题并减少推理过程中的延迟,研究人员提出了各种方法,包括闪存注意、多查询注意、分组查询注意、KV 缓存方法、滚动缓冲区 KV 缓存等。即使是最近流行的方法 MAMBA 也间接解决了这个问题。
仔细查看图 1,您会发现 GPU 内存为 80 GB HBM2e(高带宽第二代增强型)。然而,在训练和推理大型语言模型(近年来,尤其是随着LLM 和多模态模型的兴起,这些模型的参数呈指数级增长 )时,这种 HBM 内存很快就会成为限制因素,造成流程瓶颈并增加延迟。

那么,DeepSeek 解决了什么瓶颈问题?
众所周知,KV 缓存推理是一种有助于减少注意力机制(vanilla transformer — 注意力就是你所需要的全部论文架构)中计算负载的解决方案。它通过在 Key 和 value 中缓存 token 来生成下一个 token。然而,在处理长序列的实际场景中,KV 缓存会变得非常大且占用大量内存。这限制了最大批处理大小和序列长度,从而造成了瓶颈。
为了解决这一瓶颈并减少延迟,DeepSeek 的研究人员提出了一种名为多头潜在注意力的新方法。这种新方法旨在缓解瓶颈问题并加快推理过程。
DeepSeek-V2 采用了两种创新架构
用于前馈网络 (FFN) 的DeepSeekMoE架构。
多头潜在注意力(MLA)用于注意力机制。
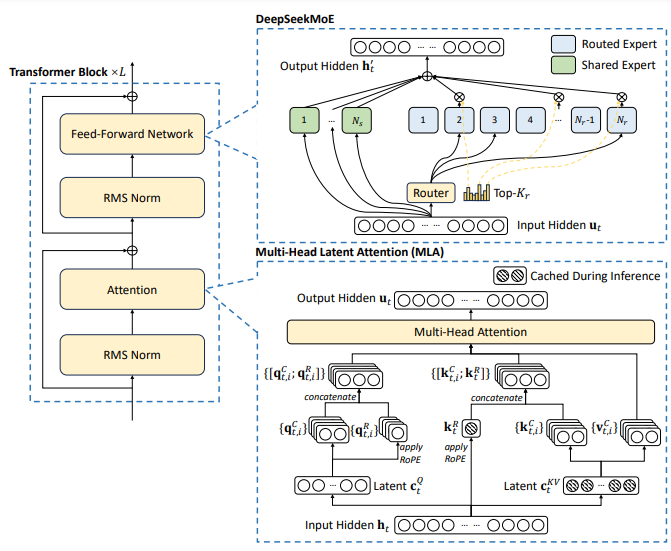
DeepSeekV2 Transformer Block由DeepSeekMoE+MLA组成
DeepSeekMoE
在标准 MoE 架构中,每个 token 被分配一个(或两个)专家,并且每个 MoE 层都有多个专家,所有专家在结构上都与标准 FFN 相同。这种设置体现了两个问题:一个 token 的指定专家将打算在其参数中汇集截然不同的知识,这些知识很难同时利用;其次,分配给不同专家的 token 可能需要共同的知识,从而导致多个专家聚集在一起获取各自参数中的共享知识。
为了解决这两个问题,DeepSeekMoE 引入了两种策略来提高专家的专业化程度:
-
细粒度专家细分:为了更有针对性地获取每个专家的知识,通过分割 FFN 中间隐藏维度,将所有专家细分为更细的粒度。因此
-
共享专家隔离:隔离某些专家作为始终处于激活状态的共享专家,旨在捕获不同情境下的共同知识,并通过将共同知识压缩到这些共享专家中,减少其他路由专家之间的冗余。
让我们在 DeepSeekMoE 中为第 t个 token制定专家任务。如果u_t是此 token 的 FFN 输入,则输出h`_ t 将为:
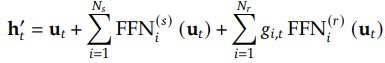
其中 𝑁𝑠 和 𝑁&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2489
2489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









