







LoRA(Low-Rank Adaptation) 是一种通过低秩矩阵分解实现参数高效微调的技术。其核心思想是:冻结预训练模型参数,仅通过训练两个低秩矩阵来模拟参数变化量。以下是通俗解释与代码实现:
一、原理图解(3步理解)
1、旁支结构: 在原始模型层(如线性层)旁添加两个小矩阵
A
A
A(降维)和
B
B
B(升维),其中秩
r
≪
d
r≪d
r≪d(原矩阵维度)。
更新后的权重矩阵可以表示为:
W ′ = W + Δ W = W + A ⋅ B W' = W + \Delta W = W + A⋅ B W′=W+ΔW=W+A⋅B
其中, Δ W = A ⋅ B \Delta W = A ⋅ B ΔW=A⋅B是低秩更新矩阵.
2、训练过程: 只更新
A
A
A 和
B
B
B ,原始参数
W
W
W 保持冻结。
3、推理合并: 训练后将
Δ
W
\Delta W
ΔW 与
W
W
W 合并,不增加推理耗时。
在微调过程中,只训练低秩矩阵 A和B,而冻结原始模型的权重,从而大幅减少计算开销。
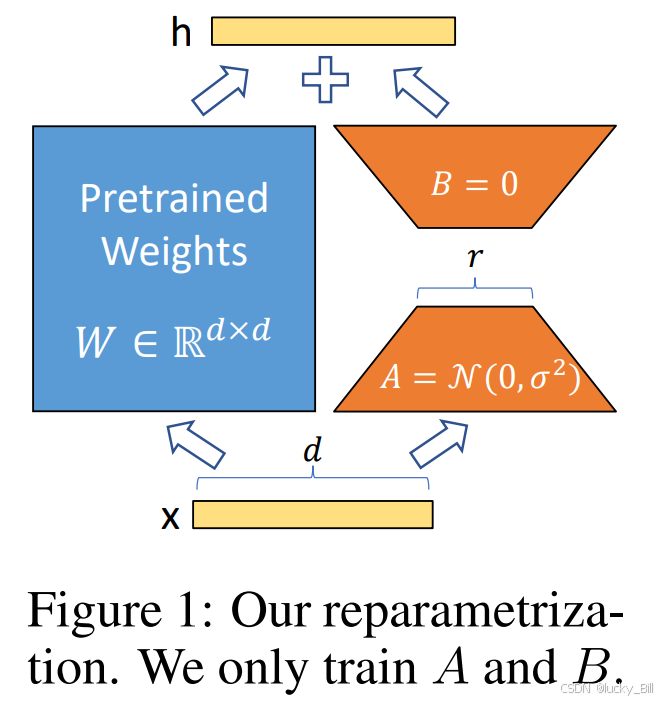

LoRA大大节省微调大模型的参数量;效果和全量微调差不多;微调完的LoRA模型权重可以Merge回原来的权重,不会改变模型结构,推理时不增加额外计算量;你可以通过改变r参数,最高情况等同于全量微调。
特点:
高效性:由于只训练低秩矩阵,参数量大幅减少(通常为原始模型参数的0.1%-1%),计算和存储开销显著降低。
模块化:LoRA的适配模块(低秩矩阵)可以独立于原始模型保存和加载,便于在不同任务之间切换。
兼容性:可以与多种模型架构(如Transformer)和任务(如文本分类、生成、翻译)结合使用。
避免灾难性遗忘:由于原始模型权重被冻结,LoRA在适配新任务时不会破坏预训练模型的通用知识。
可扩展性:可以与其他高效微调方法(如Adapter、Prefix Tuning)结合使用,进一步提升性能。
应用场景:
- 资源受限的环境:在计算资源有限的情况下高效微调大模型。
- 多任务学习:通过为不同任务训练独立的低秩矩阵,快速适配多个任务。
- 持续学习:在保留预训练知识的同时,逐步适配新任务。
二、Pytorch代码实现(以线性层为例)
import torch
import torch.nn as nn
class LoRALinear(nn.Module):
def __init__(self, in_dim, out_dim, rank=8, alpha=16):
super().__init__()
self.rank = rank
self.scaling = alpha / rank # 缩放系数
# 原始权重(冻结)
self.weight = nn.Parameter(torch.randn(out_dim, in_dim), requires_grad=False)
# LoRA矩阵(可训练)
self.lora_A = nn.Parameter(torch.randn(rank, in_dim)) # 降维矩阵
self.lora_B = nn.Parameter(torch.zeros(out_dim, rank)) # 升维矩阵(初始化为0)
def forward(self, x):
# 原始输出 + LoRA调整项
original = x @ self.weight.T
lora_adjust = (x @ self.lora_A.T) @ self.lora_B.T # 低秩分解
return original + self.scaling * lora_adjust
关键点:
- lora_B 初始化为0,确保训练开始时旁路无影响
- scaling 系数平衡新旧参数权重(通常设为 α / r α/r α/r)
三、实战示例(Hugging Face场景)
from transformers import AutoModel
from peft import LoraConfig, get_peft_model
# 加载预训练模型
model = AutoModel.from_pretrained("bert-base-uncased")
# 配置LoRA参数(仅微调注意力层的q_proj和v_proj)
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["query", "value"], # 指定微调模块
lora_dropout=0.1,
bias="none"
)
# 应用LoRA
model = get_peft_model(model, lora_config)
print(f"可训练参数量: {model.print_trainable_parameters()}")
# 输出示例:0.8M/110M (仅0.7%参数被训练)
四、超参数选择建议
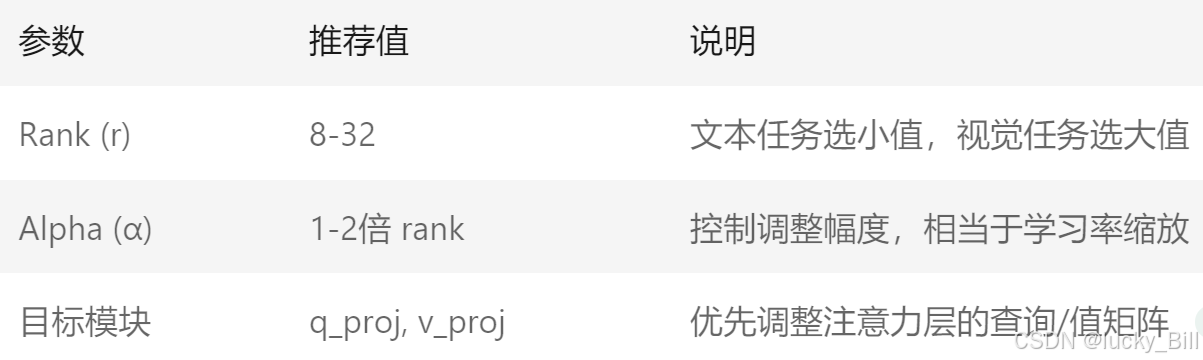
通过这种方式,LoRA能以1-10%的参数量实现接近全参数微调的效果,实际应用中,可结合Hugging Face的 peft 库快速实现适配。
LoRA的核心优势在于参数高效性而非训练高效性:虽然其可训练参数(低秩矩阵A和B)显著减少(例如从175B降至百万级),但在单卡训练时速度提升有限。这是因为整个预训练模型(PLM)仍需参与前向和反向传播计算,梯度计算过程涉及全部模型参数,而不仅仅是旁路的低秩矩阵。
具体来说:

LoRA的梯度计算包括两个步骤:
1、需要计算整个PLM的梯度;
2、使用这些梯度来计算注入矩阵的梯度。

















 2758
2758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









