









目录
1 前言
1.1 IHBA
蜜獾算法(Honey Badger Algorithm,HBA)由Fatma A. Hashima[1]等人于2021年提出,主要模拟了蜜獾的挖掘和寻找蜂蜜的动态搜索行为,该算法具有结构简单、控制参数少、寻优能力强、收敛速度快等特点。在挖掘阶段中,它利用自己的嗅觉来确定猎物的大致位置;当到达那里时,它会绕着猎物移动,以选择合适的位置来挖掘和捕捉獵物;在采蜜阶段中,蜜獾利用引导獾的位置直接定位蜂巢。HBA在寻优能力以及收敛速度方面具有一定的优势,但是该算法在搜索能力、收敛精度、易陷入局部最优值等方面还有一定的改进空间,文献[2]采用了3点改进策略提出了IHBA:
(1)基于Chebyshev混沌映射的种群初始化:HBA采用随机方法初始化种群位置,对初始条件高度依赖,使得搜索过程无法稳定地获得目标精度和收敛速度。混沌映射具有随机性、遍历性、规律性等特点,在处理初始种群问题时能有效保持种群的多样性,避免算法过早收敛。
式中,ub和lb为搜索空间的上界和下界,j为[1, N]。
(2)基于莱维飞行的蜜獾更新机制:引入莱维飞行对采蜜阶段的蜜獾位置进行更新,当其以极大的概率在食物源附近进行小范围游走时更有助于算法完成局部开发过程,而极小概率产生的大步长有利于算法跳出局部最优,进一步增强新生解的质量,避免遍历不充分、全局勘探不足、在迭代中后期易陷入局部最优等问题。
式中,为食物源位置,
为经莱维飞行变异后的蜜獾新个体,
为步长控制量,
为点对点乘法,Levy(
)表示随机搜索路径。
(3)引入最优个体自适应变异策略:采用以迭代次数t为系统参量的变异因子对算法当前找到的最优解进行自适应变异,基于贪婪选择算法推选出质量更高的食物源并参与下轮迭代。自适应t分布是融合高斯分布与柯西分布优点随机参数组,当其作为变异因子对可行解进行扰动时,可使算法具有一定的局部随机搜索能力以避免陷入局部最优。
式中,和
分别为第他次和第t+1次迭代中的食物源位置,
为变异后的食物源位置。
1.2 Isomap-Adaboost-SVM
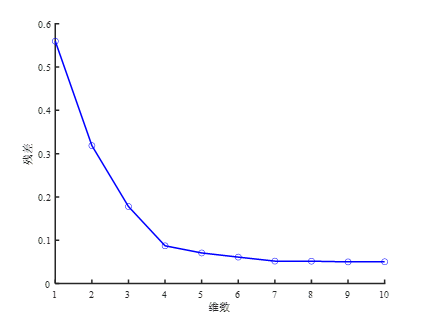
Isomap,中文名叫“等距特征映射”,是一种非线性的降维算法,应用于降维、可视化等领域。该算法核心在于发现并利用流形空间的特点,引入测地线距离和提出对应的距离计算方法。从Isomap的名字上看,它是一种等距映射算法,也就是说降维后的点,两两之间距离不变,这个距离是测地距离。
AdaBoost,中文名叫“自适应增强”,由Yoav Freund和Robert Schapire在1995年提出,其基本思想为:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数。
支持向量机(Support Vector Machine,SVM)由数学家Vapnik等人[3]早在1963年提出,它是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。SVM使用铰链损失函数计算经验风险并在求解系统中加入了正则化项以优化结构风险,是一个具有稀疏性和稳健性的分类器 。SVM可以通过核方法进行非线性分类,是常见的核学习方法之一 。SVM的方法就是间隔最大化,也就是说求解能够正确划分训练数据集并且几何间隔最大的分离超平面,分为两种类型:硬间隔最大化,也就是说训练数据集线性可分并且间隔相对较大;与之对应的是软间隔最大化,表示训练数据集近似可分。
1.3 Isomap-Adaboost-IHBA-SVM
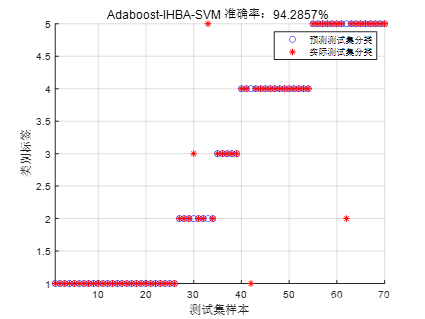
SVM的关键在于核函数,可以将低维空间中难于划分的向量映射到高维空间。但这个办法带来的困难就是计算复杂度的增加,而核函数正好巧妙地解决了这个问题。常调节参数c和g,二者的具体含义如下:c是惩罚系数,理解为调节优化方向中两个指标(间隔大小,分类准确度)偏好的权重,即对误差的宽容度,c越高,说明越不能容忍出现误差,容易过拟合,c越小,容易欠拟合,c过大或过小,泛化能力变差;g是选择RBF函数作为kernel后,该函数自带的一个参数。隐含地决定了数据映射到新的特征空间后的分布,g越大,支持向量越少,g值越小,支持向量越多。支持向量的个数影响训练与预测的速度。由上述分析可知,c、g这两个参数对SVM效果的影响至关重要,本文采用IHBA优化参数c、g,利用最佳参数对 Isomap-Adaboost-SVM网络进行训练。
2 仿真结果
2.1 IHBA
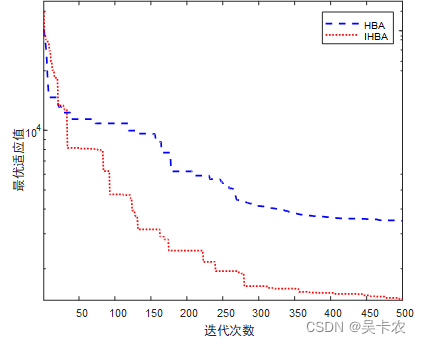
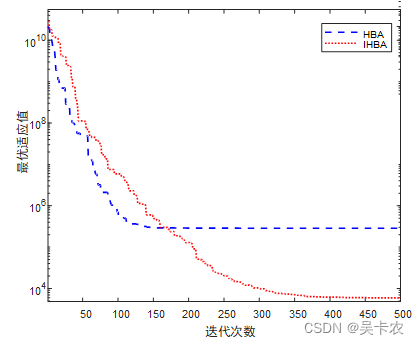
2.2 Isomap-Adaboost-SVM

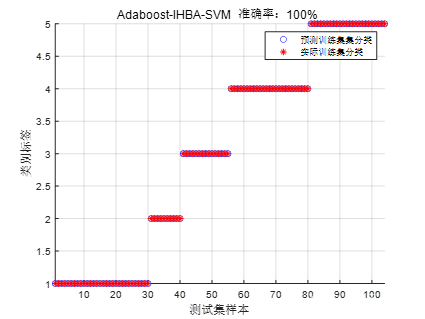
2.3 Isomap-Adaboost-IHBA-SVM
3 参考文献
[1] Fatma A. Hashim, Essam H. Houssein, Kashif Hussain, et al.Honey badger algorithm: new metaheuristic algorithm for solving optimization problems[J]. Mathematics and Computers in Simulation, 2022, (192): 84-110.
[2] 董红伟,李爱莲,解韶峰,崔桂梅.多策略改进的蜜獾优化算法[J/OL].小型微型计算机系统:1-12[2023-05-04].http://kns.cnki.net/kcms/detail/21.1106.TP.20221123.1326.032.html
4 Matlab代码
部分代码如下图所示:
[predict_test,predict_train]=svm_ada(train_wine,test_wine,train_wine_labels,test_wine_labels)
%% 待优化参数信息
dim=2; % 待优化参数个数,c和g
ub=[500 100]; % 参数取值上界
lb=[0.0001 0.0001]; % 参数取值下界
fobj=@(x)fun(x,train_wine_labels,train_wine,test_wine_labels,test_wine);
N=20; % 种群大小
Max_iter=30; % 迭代数
%% 迭代计算
[~,best_p,fbest_store,X]=IHBA(N,Max_iter,lb,ub,dim,fobj);
具体代码详情:
https://mbd.pub/o/bread/mbd-ZJiYlJlq![]() https://mbd.pub/o/bread/mbd-ZJiYlJlq
https://mbd.pub/o/bread/mbd-ZJiYlJlq
















 940
940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











