








论文名称:SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks
作者:Lingxiao Yang, Ru-Yuan Zhang, Lida Li, Xiaohua Xie
Code:https://github.com/ZjjConan/SimAM
介绍
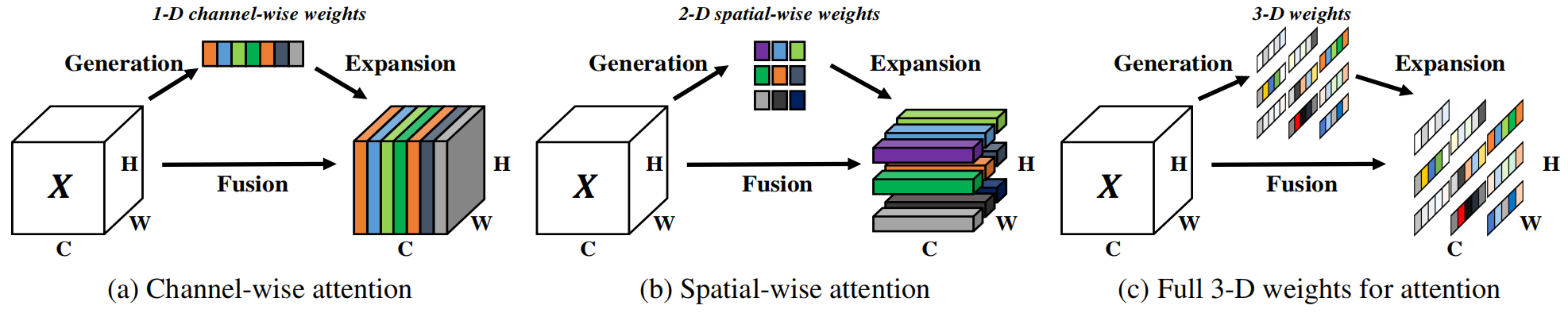
本文提出了一种简单有效的3D注意力模块,基于著名的神经科学理论,提出了一种能量函数,并且推导出其快速解析解,能够为每一个神经元分配权重。主要贡献如下:
- 受人脑注意机制的启发,我们提出了一个具有3D权重的注意模块,并设计了一个能量函数来计算权重;
- 推导了能量函数的封闭形式的解,加速了权重计算,并保持整个模块的轻量;
- 将该模块嵌入到现有ConvNet中在不同任务上进行了灵活性与有效性的验证。
相关工作
就目前而言,网络表达能力的提升主要体现在两个方面:网络结构和注意力模块
网络结构:从AlexNet到VGG再到ResNet越来越深的网络堆叠结构,或是GoogLeNet等更宽的结构赋予了网络更强的表达能力,也有相当多的工作使用AutoML来避免人工设计。
然而,作者的目标是设计一个轻量级的即插即用的模块以应用于各种任务,而无需对网络结构做出较大的改变
注意力模块:
以SENet为代表的通道注意力模块或是一些空间注意力模块,虽然取得了不错的效果,但是其计算权重的算法多是人工设计,需要大量的计算量,当然也有一些模块受到神经科学的启发。
局限性:对于通道注意力/空间注意力来说,他们往往只是对不同通道/位置区别对待,而对所有的位置/通道同等对待;并且其往往需要额外的子网络来生成权重。
方法
作者认为注意机制的实现应该遵循神经计算中的一些统一原则。因此,基于一些成熟的神经科学理论提出了一种新的方法。
在视觉神经学中,那些信息量(most informative)最大的神经元通常与周围神经元拥有不同的放电模式。
同时,一个活跃的神经元也可能一直周围的神经元活动,这种现象被称为”空间抑制“。
换言之,在视觉中,表现出明显空间一直效应的神经元应该被赋予更高的重要性,而找到这些神经元的最简单方式就是测量一个目标神经元与其他神经元之间的线性可分性。
能量函数
基于以上科学发现,提出了以下的能量函数(公式来源参考):
e
t
(
w
t
,
b
t
,
y
,
x
i
)
=
(
y
t
−
t
^
)
2
+
1
M
−
1
∑
i
=
1
M
−
1
(
y
0
−
x
^
i
)
2
.
(1)
e_t(w_t,b_t,\mathbf{y},x_i) = (y_t-\hat{t})^2+\frac{1}{M-1}\sum_{i=1}^{M-1}(y_0-\hat{x}_i)^2.\tag{1}
et(wt,bt,y,xi)=(yt−t^)2+M−11i=1∑M−1(y0−x^i)2.(1)
t
t
t和
x
i
x_i
xi是输入
X
∈
R
C
×
H
×
W
X\in \mathbb{R}^{C\times H\times W}
X∈RC×H×W中单通道上的目标神经元和其他神经元
t ^ = w t t + b t \hat{t}=w_tt+b_t t^=wtt+bt和 x ^ i = w t x i + b t \hat{x}_i=w_tx_i+b_t x^i=wtxi+bt是 t t t和 x i x_i xi的线性变换, w t w_t wt和 b t b_t bt分别代表线性变换的权重和偏置
i i i是空间维度上的索引, M = H × W M=H\times W M=H×W代表该个通道上神经元的个数
( 1 ) (1) (1)式中的所有量都是标量,当 y t = t ^ y_t=\hat{t} yt=t^和所有 x i = y o x_i=y_o xi=yo时取得最小值,其中, y t y_t yt和 y o y_o yo是两个不同的值
求解 ( 1 ) (1) (1)式的最小值等价于求解目标神经元和其他所有神经元之间的线性可分性
简便起见,使用二值标签,即
y
t
=
1
y
o
=
−
1
y_t=1\quad y_o=-1
yt=1yo=−1,并且添加了正则项,则最终的能量函数如下:
e
t
(
w
t
,
b
t
,
y
,
x
i
)
=
1
M
−
1
∑
i
=
1
M
−
1
(
−
1
−
(
w
t
x
i
+
b
t
)
)
2
+
(
1
−
(
w
t
t
+
b
t
)
)
2
+
λ
w
t
2
.
(2)
e_t(w_t,b_t,\mathbf{y},x_i) = \frac{1}{M-1}\sum_{i=1}^{M-1}(-1-(w_tx_i+b_t))^2+(1-(w_tt+b_t))^2+\lambda w_t^2.\tag2
et(wt,bt,y,xi)=M−11i=1∑M−1(−1−(wtxi+bt))2+(1−(wtt+bt))2+λwt2.(2)
公式的来源应该是SVM,将当前神经元设置为正类,其余神经元设置为负类,来衡量他们之间的差异性。
解析解
理论上, 每个通道拥有 M M M个能量函数,逐一求解是很大的计算负担
幸运的是,可以获得
(
2
)
(2)
(2)的闭式解(即解析解),如下:
w
t
=
−
2
(
t
−
μ
t
)
(
t
−
μ
t
)
2
+
2
σ
t
2
+
2
λ
,
(3)
w_t=-\frac{2(t-\mu_t)}{(t-\mu_t)^2+2\sigma_t^2+2\lambda},\tag3
wt=−(t−μt)2+2σt2+2λ2(t−μt),(3)
b
t
=
−
1
2
(
t
−
μ
t
)
w
t
.
(4)
b_t=-\frac{1}{2}(t-\mu_t)w_t.\tag4
bt=−21(t−μt)wt.(4)
其中 μ t = 1 M − 1 ∑ i = 1 M − 1 x i \mu_t=\frac{1}{M-1}\sum_{i=1}^{M-1}x_i μt=M−11∑i=1M−1xi, σ t 2 = 1 M − 1 ∑ i = 1 M − 1 ( x i − μ t ) 2 \sigma_t^2=\frac{1}{M-1}\sum_{i=1}^{M-1}(x_i-\mu_t)^2 σt2=M−11∑i=1M−1(xi−μt)2,实际上就是该通道中除去目标神经元的均值和方差
由于解析解是在单个通道上获得的,因此可以合理假设每个通道中所有像素遵循相同的分布,最小能量即为:
e
t
∗
=
4
(
μ
2
+
λ
)
(
t
−
μ
)
2
+
2
σ
2
+
2
λ
.
(5)
e_t^*=\frac{4(\mu^2+\lambda)}{(t-\mu)^2+2\sigma^2+2\lambda}.\tag5
et∗=(t−μ)2+2σ2+2λ4(μ2+λ).(5)
能量越低,神经元t与周围神经元的区别越大,重要性越高。因此,神经元的重要性可以通过
1
/
e
t
∗
1/e_t^*
1/et∗得到。
根据以往的神经学研究,哺乳动物大脑中的注意力调节通常表现为神经元反应的增益效应,因此使用放缩运算而非加法来实现加权:
X
~
=
s
i
g
m
o
i
d
(
1
E
)
⊗
X
,
(6)
\widetilde{X}=sigmoid(\frac{1}{E})\otimes X,\tag6
X
=sigmoid(E1)⊗X,(6)
同时
s
i
g
m
o
i
d
sigmoid
sigmoid函数还可以限制
E
E
E中的过大值,并且不会影响每个神经元的相对重要性
Pytorch代码为:
def forward(X,lambda):
n = X.shape[2] * X.shape[3] - 1
d = (X - X.mean(dim=[2,3])).pow(2)
v = d.sum(dim=[2,3])/n
E_inv = d / (4 * (v + lambda)) +0.5
return X * torch.sigmoid(E_inv)
实验
在各类任务上都取得了相当好的效果。















 331
331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









