










 这篇博客介绍了SimAM,一种无参数的注意力机制,用于提升CNN中神经元的线性可分性。通过引入二进制标签和能量函数,该模块通过降低神经元间的重叠度来强调重要神经元。作者提供了论文链接、代码和博客详细解释了其工作原理和实现。
这篇博客介绍了SimAM,一种无参数的注意力机制,用于提升CNN中神经元的线性可分性。通过引入二进制标签和能量函数,该模块通过降低神经元间的重叠度来强调重要神经元。作者提供了论文链接、代码和博客详细解释了其工作原理和实现。
SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks
论文链接(已收录于ICML 2021):
http://proceedings.mlr.press/v139/yang21o/yang21o.pdf
代码:https://github.com/ZjjConan/SimAM
参考博客:https://blog.csdn.net/hb_learing/article/details/11907785
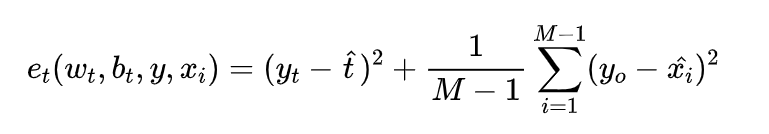
其中:
1、 ;
2、 和
分别指输入特征X的目标神经元和其他神经元,
3、 指空间维度上的索引
4、 指 在某个通道上所有神经元的个数
5、 和
分别指某个神经元变换时的“权重” 和 “偏差”
6、引入二进制标签代替 和
,其中:
7、求解最小化 ,相当于找到了目标神经元与其他神经元的线性可分性 (怎么理解勒,看下面的个人想法):
表示 “我就是我” ,
表示 “你就是你” , 我俩相加的值越小,说明我俩越不重叠,分的越开,区别越大, 那么 “我” 就越重要!
最小化上述公式等价于训练同一通道内神经元 t 与其他神经元之间的线性可分性。为简单起见,我们采用二值标签,并添加正则项,最终的能量函数定义如下:
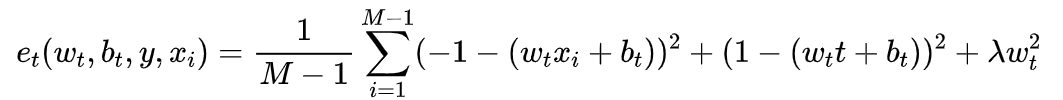
理论上,每个通道有 个能量函数。幸运的是,上述公式具有如下解析解:
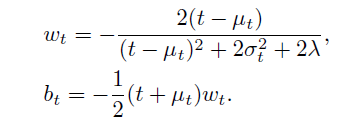
其中:
1、
![]()
2、
![]()
3、解析解:就像一元二次方程一样,当有解时,一定可以用一个公式把解求出来,
例如:
分别把 和
带入原公式,就可以求出最小能量:
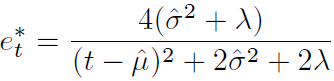
其中:
1、从统计的角度来说,并且为了减少计算量, 和
可以分别由均值和方差代替,因此有了下面两个代替式子
2、均值 , 方差
上述公式意味着:能量越低,神经元 t 与周围神经元的区别越大,重要性越高。因此,神经元的重要性可以通过 得到。到目前为止,我们推导了能量函数并挖掘了神经元的重要性。按照注意力机制的定义,我们需要对特征进行增强处理:
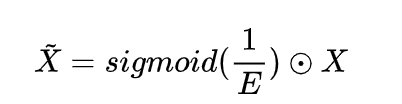
下图给出了SimAM的pytorch风格实现code:



















 4337
4337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











