








分层Local Vision Transformer,通用主干网络,各类下游任务实现SOTA。
论文名称:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
作者:Ze Liu ,Yutong Lin,Yue Cao,Han Hu,Yixuan Wei,Zheng Zhang,Stephen Lin,Baining Guo
Code:https://github.com/microsoft/Swin-Transformer
介绍
自AlexNet以来,CNN作为骨干(backbone)在计算机视觉中得到了广泛应用;另一方面,自然语言处理中的网络结构的演变则走了一条不同的道路,现在的主流结构是Transformer。
Transformer是为序列建模和转换任务而设计的,它以关注数据中的长期依赖关系而著称。其在NLP领域的巨大成功吸引了人们研究它对CV的适应性,最近的实验显示其在图像分类和联合视觉语言建模方面有所成效。
本文的主要贡献有:
- 提出了一种分层Transformer,其可以作为计算机视觉的通用主干网络,并且在各类下游任务上取得SOTA;
- 通过Shift Windows实现了对输入图像尺寸的线性时间复杂度。

Method
整体结构
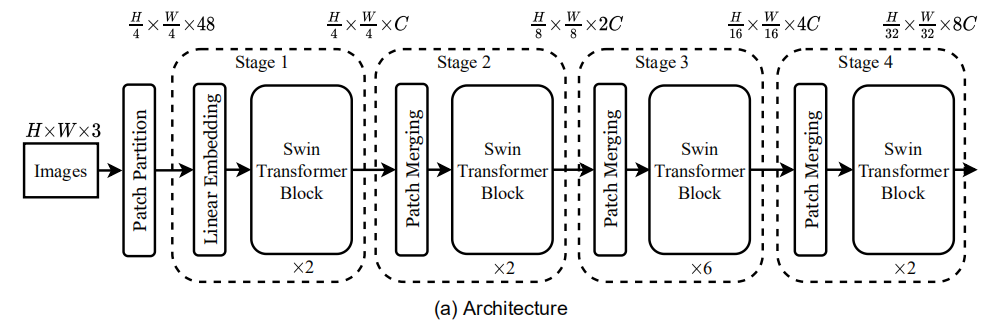
上图是Swin Transformer中最小版本的可视化结构图,其主要流程如下:
- 通过Patch Partition将输入的RGB图像分割成不重叠的Patch,堆叠进B维度;
- 使用Linear Embedding将通道映射至C;
- 紧接着使用两个连续的Swin Transformer Block,将上述组合称为Stage 1;
- 为了获得分层表示,通过Patch Merging对Stage 1的输出继续进行分块,并且同样会使用Linear Layer进行通道降维,再使用几个连续的Swin Transformer Block;如此,便能构成更多的Stage.
Shifted Window based Self-Attention

连续的Swin Transformer如上图所示,其主要流程如下:
-
对于第一个Swin Transfromer Block,会先对输入 Z l − 1 Z^{l-1} Zl−1使用LayerNorm,然后使用W-MSA(Window based Self-Attention),并且使用残差连接得到 z ^ l \hat z^l z^l,可以写成如下形式:
Z ^ l = W − M S A ( L N ( Z l − 1 ) ) + Z l − 1 \hat Z^l = W-MSA(LN(Z^{l-1}))+Z^{l-1} Z^l=W−MSA(LN(Zl−1))+Zl−1 -
接下来使用LN、MLP(两层、GELU激活函数)和残差连接的得到最终输出 Z l Z^l Zl,可以写成如下形式:
Z l = M L P ( L N ( Z ^ l ) ) + Z ^ l Z^l=MLP(LN(\hat Z^l))+\hat Z^l Zl=MLP(LN(Z^l))+Z^l -
对于接下来的Swin Transformer Block,会将其W-MSA替换成SW-MSA(Shifted Window based Self-Attention),可写成如下形式:
Z ^ l + 1 = S W − M S A ( L N ( Z l ) ) + Z l Z l + 1 = M L P ( L N ( Z ^ l + 1 ) ) + Z ^ l + 1 \hat Z^{l+1} = SW-MSA(LN(Z^{l}))+Z^{l}\\ Z^{l+1}=MLP(LN(\hat Z^{l+1}))+\hat Z^{l+1} Z^l+1=SW−MSA(LN(Zl))+ZlZl+1=MLP(LN(Z^l+1))+Z^l+1
至此便完成了连续的Swin Transformer Block的构建,由于需要将这两种组合起来达到信息交换的目的,因此层数的设置应为偶数。
Self-attention in non-overlapped windows
为了实现线性的时间复杂度,提出在Window(窗口)中进行建模,窗口以非重叠的方式均匀地划分图像,这种方式在局部窗口中进行Patch的关系建模,计算注意力时,会将Patch展品与标准多头自注意力的时间复杂度对比如下:
Ω
(
M
S
A
)
=
4
h
w
C
2
+
2
(
h
w
)
2
C
Ω
(
W
−
M
S
A
)
=
4
h
w
C
2
+
2
M
2
h
w
C
\Omega(MSA)=4hwC^2+2(hw)^2C\\ \Omega(W-MSA)=4hwC^2+2M^2hwC
Ω(MSA)=4hwC2+2(hw)2CΩ(W−MSA)=4hwC2+2M2hwC
其中输入包含
M
×
M
M\times M
M×M个Patch。
由于M是固定的,所有W-MSA对输入图像尺寸的复杂度呈线性。
Shifted window partitioning in successive blocks
虽然W-MSA解决了MSA时间复杂度随输入二次增长的问题,但是不同窗口间没有信息交流,这显然会限制模型的建模能力。
为了保持高效的同时进行有效建模,提出了Shifted Window:

通过控制不同框的大小,实现上一层不同Window之间的信息交流,但是这样较难实现,并且Window的数量会从 [ h M ] × [ w M ] [\frac hM]\times[\frac wM] [Mh]×[Mw]增加到 ( [ h M ] + 1 ) × ( [ w M ] + 1 ) ([\frac hM]+1)\times([\frac wM]+1) ([Mh]+1)×([Mw]+1),并且某些Window的大小会小于 M × M M\times M M×M,因此提出了一种更简单的方法来实现这个功能:

将原有的窗口以M/2的大小进行偏移,将多出的部分移动到相对的位置,这样就实现了不同Window之前的信息交流,不过需要注意的一点是,实际计算的过程中会使用Mask,将上图右侧移动过来的位置给盖住,原因是这部分的注意力没有意义。
Relative position bias
添加了相对位置偏置
B
∈
R
M
2
×
M
2
B\in \mathbb R^{M^2\times M^2}
B∈RM2×M2,其描述每个Window相对于其它Window的相对位置,注意力公式可以写成:
A
t
t
e
n
(
Q
,
K
,
V
)
=
S
o
f
t
M
a
x
(
Q
K
T
/
d
+
B
)
V
Atten(Q,K,V)=SoftMax(QK^T/\sqrt d +B)V
Atten(Q,K,V)=SoftMax(QKT/d+B)V
该相对位置偏置相较于绝对位置嵌入拥有更好的性能。
由于每个轴上的相对位置的取值范围都是 [ − M + 1 , M − 1 ] [-M+1,M-1] [−M+1,M−1],于是生成一个小的偏置矩阵 B ^ ∈ R ( 2 M − 1 ) × ( 2 M − 1 ) \hat B\in \mathbb{R}^{(2M-1)\times(2M-1)} B^∈R(2M−1)×(2M−1),相对位置偏置 B B B从 B ^ \hat B B^中采样而来。
Patch merging
Patch merging起到一个“下采样”的作用,具体实现方式是CNN中空间到深度的变换,将空间信息堆叠进通道中,这就相当于变相扩大了Window的大小

代码分析
Window operation
window_partition:
将输入图像分割成 w i n d o w _ s i z e × w i n d o w _ s i z e window\_size\times window\_size window_size×window_size大小的patch,并堆叠进Batch维度。
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size,
W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous(
).view(-1, window_size, window_size, C)
return windows
window_reverse:
恢复,用于残差连接之前。
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size,
window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
WindowAttention
该部分代码为W-MSA和SW-MSA,具体切换依赖于输入数据和mask,该模块只计算负责Window内的自注意力。
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - \
coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(
1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - \
1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index",
relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)#使用一个线性层生成QKV,使用切片分开
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)#对输出进行映射
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C //
self.num_heads).permute(2, 0, 3, 1, 4)
# make torchscript happy (cannot use tensor as tuple)
q, k, v = qkv[0], qkv[1], qkv[2]
q = q * self.scale #意义不明
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(
2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None: #当使用SW-MSA时,会使用mask
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N,
N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def extra_repr(self) -> str:
return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'
def flops(self, N):
# calculate flops for 1 window with token length of N
flops = 0
# qkv = self.qkv(x)
flops += N * self.dim * 3 * self.dim
# attn = (q @ k.transpose(-2, -1))
flops += self.num_heads * N * (self.dim // self.num_heads) * N
# x = (attn @ v)
flops += self.num_heads * N * N * (self.dim // self.num_heads)
# x = self.proj(x)
flops += N * self.dim * self.dim
return flops
SwinTransformer
SwinTransformerBlock:
class SwinTransformerBlock(nn.Module):
r""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resulotion.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
if min(self.input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.shift_size = 0
self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(
drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
if self.shift_size > 0: # shift_size表示使用SW-MSA
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
# nW, window_size, window_size, 1
mask_windows = window_partition(img_mask, self.window_size)
mask_windows = mask_windows.view(-1,
self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(
attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(
x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
# partition windows
# nW*B, window_size, window_size, C
x_windows = window_partition(shifted_x, self.window_size)
# nW*B, window_size*window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C)
# W-MSA/SW-MSA
# nW*B, window_size*window_size, C
attn_windows = self.attn(x_windows, mask=self.attn_mask)
# merge windows
attn_windows = attn_windows.view(-1,
self.window_size, self.window_size, C)
shifted_x = window_reverse(
attn_windows, self.window_size, H, W) # B H' W' C ,还原
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(
self.shift_size, self.shift_size), dims=(1, 2)) # 使用torch.roll实现shift
else:
x = shifted_x
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
stage:
下面的代码用来实现一个stage,每个stage中的MSA部分包含偶数个Swin Transformer Block
class BasicLayer(nn.Module):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
# build blocks
# 偶数层使用Shift,奇数层不用
self.blocks = nn.ModuleList([
SwinTransformerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
shift_size=0 if (
i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(
drop_path, list) else drop_path,
norm_layer=norm_layer)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(
input_resolution, dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
Swin Transformer:
主干以及head,将多个stage组合起来,但是对分割似乎不太友好,因为Swin Transformer只有下采样,上采样过程需要使用CNN的方法自行实现。
class SwinTransformer(nn.Module):
r""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
use_checkpoint=False, **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=4, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# absolute position embedding
if self.ape:
self.absolute_pos_embed = nn.Parameter(
torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.absolute_pos_embed, std=.02)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate,
sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(
depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (
i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint)
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(
self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'absolute_pos_embed'}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'relative_position_bias_table'}
def forward_features(self, x):
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
downsample
这里的下采样采用的是空间到深度的转换:
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x
其他
PatchEmbed:
对输入图像使用PatchEmbed生成token表示:
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] //
patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim,
kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return x
通用型的主干网络需要什么?
本文旨在使用Transformer构建一个通用的主干网络,那么一个通用的主干网络需要什么呢?
- 轻量
- 强大的特征提取能力
- 多尺度
local vision transformer
众所周知,Transformer是一种自注意力,而自注意力的关键就是计算全局中所有token之间的关系,这似乎与local有很大的矛盾。
最近越来越多的工作对local vision transformer进行研究,其实际上是一种local attention,比如之前的VOLO outlooker attention,其优点主要在于计算复杂度低,相较于Transformer的全局粗略建模能够更精细地在局部进行建模(VOLO的观点),但是其局部的关注与Transformer是相悖的,因此提出了各种Cross Window的信息交流方式:
比如本文的Shift Windows,美团Twins的local attention和global attention结合,华为MSG-Transformer使用的信使token,交大GG-Transformer使用的AdaptivelyDilatedSplitting使用Dilate的思想来从全局采集Window(类似于shuffle加上从深度到空间的转换),腾讯的Shuffle Transformer(与GG-Transformer类似)等,以及之前的Recurrent Criss-Cross Attention,其利用横纵轴上信息计算全局注意力,或是类似于RCCA模块的CSWin Transformer。
这些都是local attention,但是通过不同的方法增强了其全局建模的能力,具体原因可能是因为local attention的稀疏连接性,这也是VOLO的思想所在,并且除了上述网络,也在很多网络中得以体现,比如ECANet针对SENet的改进,其使用一维卷积获得注意力权重,但是取得了更好的效果。
关于这点将在Demystifying Local Vision Transformer: Sparse Connectivity, Weight Sharing, and Dynamic Weight进行讨论——Local vision transformer work的原因究竟是什么?















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









