






文章目录
一、小波变换应用
传统的傅里叶分析中,信号是完全在频域展开,不包含任何时域信息。而小波变换具有多分辨率的特点,在时域和频域上都有表征局部信息的能力,时间窗和频率窗都可以根据信号的具体形态动态调整,在低频部分采用较低的时间分辨率,提高频率的分辨率,在高频情况下,采用较低的频率分辨率来获得精确的时间定位。
小波变换被广泛地应用在诸多领域,在信号分析方面主要用于滤波、去噪、压缩和传递等方面。
二、小波变换的基本数学原理
2.1小波函数

2.2连续小波变换

2.3离散小波变换

2.4正交小波变换

2.5小波函数介绍
三、小波变换在MATLAB中的实现
3.1小波变换
使用Matlab进行1维小波分析主要使用的函数有:
wavedec小波分解
waverec 小波重建
appcoef 近似系数
detcoef 细节系数

下面直接用具体的例子来进行说明:
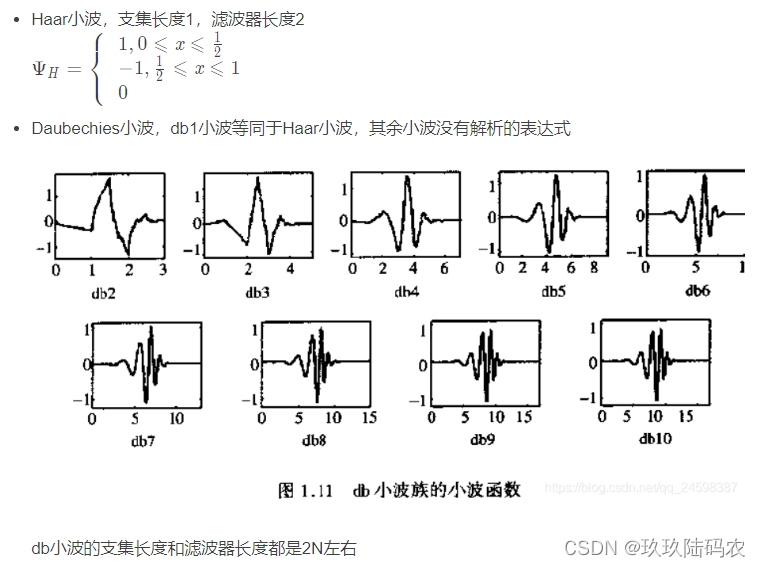
clc;clear
load sumsin
figure
plot(sumsin)
title('Signal')
figure
[c,l]=wavedec(sumsin,3,'db2');
approx=appcoef(c,l,'db2');
[cd1,cd2,cd3]=detcoef(c,l,[1,2,3]);
subplot(2,2,1)
plot(approx)
title('Approximation Coefficients')
subplot(2,2,2)
plot(cd3)
title('Level 3 Detail Coefficients')
subplot(2,2,3)
plot(cd2)
title('Level 2 Detail Coefficients')
subplot(2,2,4)
plot(cd1)
title('Level 1 Detail Coefficients')
x=waverec(c,l,'db2');
figure
plot(x)

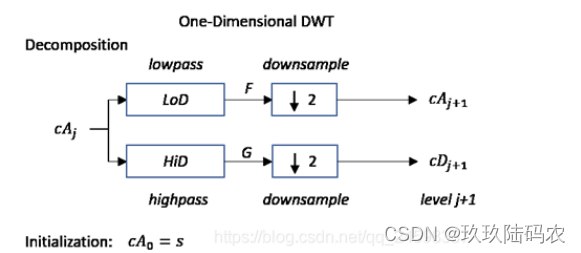
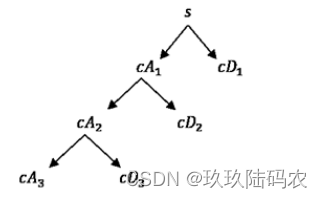
从小波变换的算法中其实可以看到,MATLAB中小波变换的算法实际上是先不断的将信号通过高通和低通滤波器后,进行2倍下采样的过程,因此信号会越来越短。
接下来对具体信号进行实验:
clear;clc;
%电机数据均为15Hz,内部负载为80load,采样率为5120Hz,取1个周期的数据
%由于频率过高,进行降采样,频率为1280Hz,采样点为1280
load('normal.mat');
normal=data(1:4:5120*4,5);
load('broken.mat');
broken=data(1:4:5120*4,5);
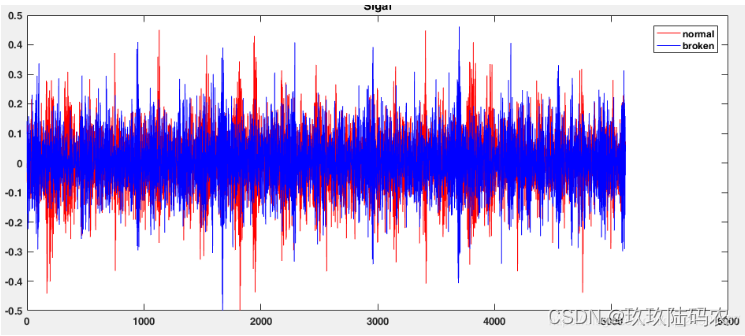
figure;
plot(normal,'r')
hold on
plot(broken,'b')
hold off
title('Sigal')
legend('normal','broken')
figure;
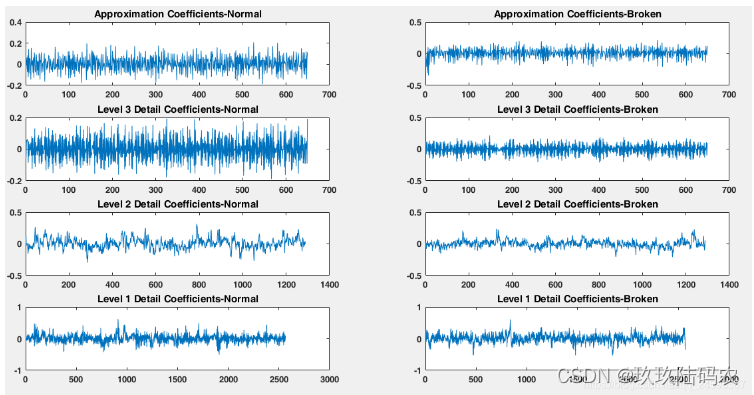
[c1,l1]=wavedec(normal,3,'db6');
approx=appcoef(c1,l1,'db6');
[cd1,cd2,cd3]=detcoef(c1,l1,[1,2,3]);
subplot(4,2,1)
plot(approx)
title('Approximation Coefficients-Normal')
subplot(4,2,3)
plot(cd3)
title('Level 3 Detail Coefficients-Normal')
subplot(4,2,5)
plot(cd2)
title('Level 2 Detail Coefficients-Normal')
subplot(4,2,7)
plot(cd1)
title('Level 1 Detail Coefficients-Normal')
[c2,l2]=wavedec(broken,3,'db6');
approx=appcoef(c2,l2,'db6');
[cd1,cd2,cd3]=detcoef(c2,l2,[1,2,3]);
subplot(4,2,2)
plot(approx)
title('Approximation Coefficients-Broken')
subplot(4,2,4)
plot(cd3)
title('Level 3 Detail Coefficients-Broken')
subplot(4,2,6)
plot(cd2)
title('Level 2 Detail Coefficients-Broken')
subplot(4,2,8)
plot(cd1)
title('Level 1 Detail Coefficients-Broken')
3.2小波包变换
小波包变换的主要函数有:
wpdec:1维小波 包分解
wprec:1维小波包重建
wpcoef:小波包系数
wprcoef:小波包系数重建
bestttree:最好小波树分析
wpdec的基本用法是:
T=wpdec(s,N,‘wavename’)
同样使用具体函数进行说明:
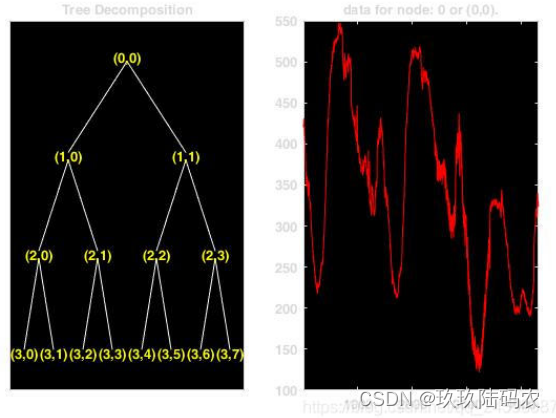
clc;clear;
load leleccum;s=leleccum;
wpt=wpdec(s,3,'db6');
figure;
plot(wpt)
figure;
c22=wpcoef(wpt,[2 2]);%等价于cww=wpcoef(wpt,5);
plot(c22)
而重建小波系数信息的命令wprcoef和wpcoef有所布偶听,wpcoef只是根据子节点的信息重建小波包系数,重建的长度只有1/2^j,而wprcoef则是根据本节点的子节点和同层的其他节点的信息重建小波包系数。可以得到原信号的完全信息,重建一个和原始信号长度一致的小波包系数。
由于小波包分解使一个树型结构,进行小波包变换的基本思想是让信息能量集中,在细节系数中寻找有序性,因此单纯把所有系数进行分解没有实际的帮助,只会增加计算量,因此需要有一定的衡量原则,一般采用熵最小原则,熵越小,信息的规律性越强,一般的判别方法是看系数分解后的系数的熵的和是否大于原系数的熵。在小波包分解的过程中还可以设置不同的熵计算方法。
四、PCA算法
4.1 PCA降维MATLAB使用案例


首先使用MATLAB自带的PCA函数
[pc,score,latent,tsquare] = pca(feature) %feature是799*216的矩阵
用latent来计算降维后取多少维度能够达到自己需要的精度
cumsum(latent)./sum(latent)
一般取到高于95%就可以了,这里我们取前40维,精度达到了0.9924
pca函数已经给出了所有的转换后矩阵表示,也就是输出的score项,取出前40维就是降维后特征
feature_after_PCA=score(:,1:40)
精度分析
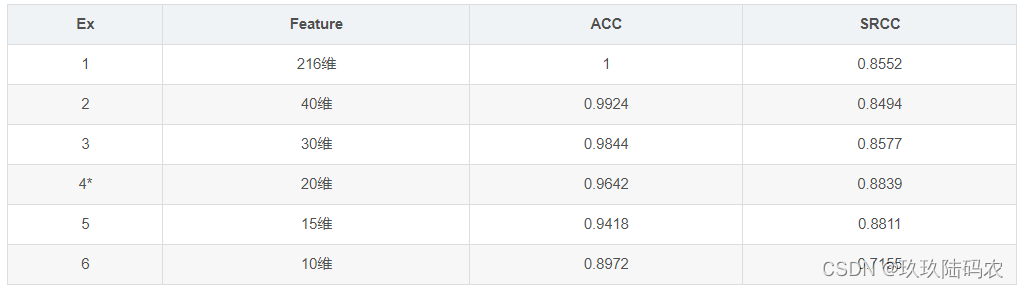
可见也不是取得维数越多效果越好,降维不仅能起到加快计算速度的作用,说不定还能去除一些冗余干扰提高拟合效果呢
4.2PCA实现步骤及其与opencv中PCA实现方式的对比
PCA(Principal Components Analysis,中文名叫主成分分析,是数据降维很常用的算法。按照书上的说法是:寻找最小均方意义下,最能代表原始数据的投影方法。PCA的一个经典应用就是人脸识别,感兴趣的可以在网上搜eigenface。
PCA的主要思想是寻找到数据的主轴方向,由主轴构成一个新的坐标系,这里的维数可以比原维数低,然后数据由原坐标系向新的坐标系投影,这个投影的过程就可以是降维的过程。
原理网上一搜内容很多,这里推荐一篇讲原理讲得不错的文章: http://www.csdn123.com/html/blogs/20130320/180.htm 大家可以参考。下面着重讨论PCA的实现,由于我主要是在做图像处理时用的PCA,所以以对图像进行降维来说明。
1 对训练集图像进行处理
读取测试集中的所以图像,然后将其保存在一个矩阵中。如果图像个数为m,图像长宽为i、j,则我们创建矩阵A(m, n = ij)用来保存图像数据。数组的每一行表示一个图像的所有像素信息,每一列表示一个维度,也即不同图像在同一位置的像素信息,降维也即用更少的列来代表图像。
经过对训练集的图像进行处理后,所有的图像都在表示在了一个矩阵中,我们假设这个矩阵是data。则data的维数为mn,其中n=i*j,及n为一张图像的所以像素点。
2 求平均值mean
在data矩阵中每一个维度上的平均值,具体方法为对data矩阵的每一列求平均值mean。如果是人脸识别的话,这一步得到的就是mean face(平均脸)。
3 每列减去均值
将data矩阵的的每列减去该列的均值,这样每列的数据均值为0。我有用C来表示相减的值,及C=data-mean
4 计算协方差矩阵
协方差矩阵表示不同随机变量之间的相互关系,图像中也即求任意两个像素之间的关系。如果两个随机变量的协方差为正或为负,表明两个变量之间具有相关性,如果为零表示两个变量不相关。通过计算协方差矩阵,我们就可以获得不同像素之间的关系。针对人脸识别,计算的协方差矩阵大小为n*n,其中n表示图像的像素点个数。
计算协方差的矩阵具体操作的A = C’ * C/n,这里C‘为C矩阵的转置。注意这里有个除n。在后面代码中会提到。
5 计算协方差矩阵A的特征值和特征向量
由于协方差矩阵是实对称阵,所以可以求得其所有的特征值和特征向量,其共有n个特征值和特征向量。
6 选择主成分(投影矩阵)
所谓主成分即是具有最大特征值的特征向量,所以我们需要将特征向量按照特征值由大到小排序,然后根据精度要求选择不同数量的特征向量,例如我们选择了前pca_dim个特征向量,通常pca_dim远小于n(在我们的人脸识别实验中,为了达到95%的精度,pca_dim只有72,而n为120140=17040)。
这里我们所选择的主成分实际上就是投影矩阵,我们用project_mat表示。project_mat的维度为npca_dim.
7 将训练集进行降维
此步骤将原始的训练集进行降维变换,方法就是对原始矩阵用project_mat进行投影。
原始的图像数据data是mn的矩阵,投影后就成了npca_dim的矩阵(每一列都是一个特征向量)。
特别注意这里投影时并不是想网上很多博客中所说的dataproject_mat。正确的方法应该是Cproject_mat,及(data-mean)*project_mat。
8 将测试集进行降维
同步骤6相似,读取所有的测试集图像,然后对其也进行降维操作。如果测试集有M幅图像,则降维后的矩阵为Mpca_dim。
注意对测试集进行降维时也不是直接用测试集的dataproject_mat,正确的做法应该是测试集的(data-mean)*project_mat。
下面是我写代码对PCA的实现,其中有与Opencv中自带的计算PCA方法的对比。
注意为了方便对矩阵的操作,我在代码中使用的开源的Eigen库,Eigen是个很方便的数学出来工具,尤其是对矩阵的处理。
Eigen库的主页http://eigen.tuxfamily.org/index.php?title=Main_Page
使用Eigen也很简单,下载好开源包后,直接在工程的属性页面“附加包含目录”把Eigen的目录添加进去。配置好后在在代码中添加#include”Eigen/Eigen”和using namespace Eigen两行就可以使用了。
#include<iostream>
#include<fstream>
#include"Eigen/Eigen"
#include<opencv2\opencv.hpp>
using namespace Eigen;
using namespace std;
using namespace cv;
void BubbleSort(float *pData, int Count);//冒泡排序
const int num = 5; // 样本数量
const int dim = 10; // 样本的维度(一张图片的维度)
const int pca_dim = 4;// pca dimension of each sample
int main()
{
// 原始数据:每一行代表一个样本(这里为了测试时随机生成的)
MatrixXf data =MatrixXf::Random(num, dim);
// 求每一维度上的平均值,即每一列的平均值,最后求出来是一个行向量
MatrixXf mean =data.colwise().mean();
cout<<"------------------Orignal data-------------------------\n"<<data<<endl;
//cout<<"----------------Mean------------------\n"<<mean<<endl;
MatrixXf C(num, dim); // data-mean
MatrixXf C_T(dim, num);// C的转置
for(int i=0; i<num; i++)
{
C.row(i) =data.row(i)-mean; //C= data-mean
}
C_T =C.transpose();
/*
协方差矩阵A的维度为dim*dim,这里除不除dim最后结果都一样,
在书中的定义中是要除的,估计是有数学含义的。
*/
MatrixXf A =C_T*C;
EigenSolver<MatrixXf> sol_A;
sol_A.compute(A);
//求协方差矩阵的特征值和特征向量
MatrixXf eigenvals_A =sol_A.eigenvalues().real();
MatrixXf eigenvecs_A =sol_A.eigenvectors().real();
//排序
float a[dim]={0.0};
for(int i=0; i<dim; i++)
{
a[i] =eigenvals_A(i, 0);
}
BubbleSort(a, dim);
MatrixXf sorted_eigenvals_A(dim, 1);
MatrixXf sorted_eigenvecs_A(dim, dim);
//对特征值从大到小排序
for(int i=0; i<dim; i++)
{
sorted_eigenvals_A(i, 0) =a[i];
}
//对应的改变特征向量的排序
for(int i=0; i<dim; i++)
{
for(int j=0; j<dim; j++)
{
if(eigenvals_A(i, 0) == a[j])
{
sorted_eigenvecs_A.col(j) =eigenvecs_A.col(i);
}
}
}
//求PCA的投影矩阵及降维结果
MatrixXf project_mat(dim, pca_dim); //投影矩阵
MatrixXf res(num, pca_dim); //最终输出,维度为num*pca_dim
for(int i=0; i<pca_dim; i++) //抽取主成分
{
project_mat.col(i) =sorted_eigenvecs_A.col(i);
}
/*
res就是原始数据降维后的矩阵
特别注意,这里是C*project_mat,即(data-mean)*project_mat
在网上看到很多人这里都是直接用的data*project_mat,那样是不对的
*/
res =C* project_mat;
//-----------------------------OpenCV中的PCA--------------------------------//
CvMat *pca_input =cvCreateMat( num, dim, CV_32FC1); // 输入
CvMat *pca_avg =cvCreateMat( 1, dim, CV_32FC1); // 平均值
CvMat *pca_eigenvalue =cvCreateMat( 1, std::min(num, dim), CV_32FC1); // 特征值
CvMat *pca_eigenvector =cvCreateMat( std::min(num, dim), dim, CV_32FC1);// 特征向量
CvMat *pca_eigenvector_T =cvCreateMat(dim, std::min(num, dim), CV_32FC1); // 特征向量
CvMat *pca_output =cvCreateMat(num, pca_dim, CV_32FC1); // 输出
// 数据导入
for(int i=0; i<num; i++)
{
for(int j=0; j<dim; j++)
{
cvSetReal2D(pca_input, i, j, data(i, j));
}
}
cvCalcPCA(pca_input, pca_avg, pca_eigenvalue, pca_eigenvector, CV_PCA_DATA_AS_ROW);
cout<<"\n---------------Eeigen Tool降维结果-----------------"<<endl;
cout<<res<<endl;
cout<<"---------------OpenCV Tool降维结果---------------"<<endl;
cvProjectPCA(pca_input, pca_avg, pca_eigenvector, pca_output);
// 数据输出
for(int i=0; i<num; i++)
{
for(int j=0; j<pca_dim; j++)
{
float temp =0.0;
temp =cvGetReal2D(pca_output, i, j);
cout<<temp<<" ";
}
cout<<endl;
}
system("pause");
return 0;
}
//冒泡排序算法
void BubbleSort(float *pData, int Count)
{
float iTemp;
for(int i=1; i<Count; i++)
{
//一共进行(count-1)轮,每次得到一个最大值
for(int j=Count-1; j>=i; j--) //每次从最后往前交换,得到最大值
{
if(pData[j]>pData[j-1])
{
iTemp = pData[j-1];
pData[j-1] = pData[j];
pData[j] = iTemp;
}
}
}
}
最后通过对比,发现用Eigen自己实现的PCA与Opencv实现的PCA结果的数值是一样的,但是有些向量的符号相反。

PS:可能有的读者发现了有些博客中讲PCA降维时,在第一步生成原始的data矩阵维度为dim*m(dim为一个图像的维度,m为训练集图片的张数)。
如果是这种情况的话,则上面的A 应该等于 C*C' (C'是C矩阵的转置),最后求降维后的矩阵时公式也应该变为project_mat的转置乘以(data-mean)。
总之,不管data矩阵的维度是dim*m还是m*dim,我们都要确保第四步求得的协方差A的维度是dim*dim。因为协方差矩阵表示的就是data中各维度的关系。
五、机器学习之分类器——Matlab中各种分类器的使用总结(随机森林、支持向量机、K近邻分类器、朴素贝叶斯等)
Matlab中常用的分类器有随机森林分类器、支持向量机(SVM)、K近邻分类器、朴素贝叶斯、集成学习方法和鉴别分析分类器等。各分类器的相关Matlab函数使用方法如下:
首先对以下介绍中所用到的一些变量做统一的说明:
train_data——训练样本,矩阵的每一行数据构成一个样本,每列表示一种特征
train_label——训练样本标签,为列向量
test_data——测试样本,矩阵的每一行数据构成一个样本,每列表示一种特征
test_label——测试样本标签,为列向量
①随机森林分类器(Random Forest)
TB=TreeBagger(nTree,train_data,train_label);
predict_label=predict(TB,test_data);
②支持向量机(Support Vector Machine,SVM)
SVMmodel=svmtrain(train_data,train_label);
redict_label=svmclassify(SVMmodel,test_data);
③K近邻分类器(KNN)
KNNmodel=ClassificationKNN.fit(train_data,train_label,'NumNeighbors',1);
predict_label=predict(KNNmodel,test_data);
④朴素贝叶斯(Naive Bayes)
Bayesmodel=NaiveBayes.fit(train_data,train_label);
predict_label=predict(Bayesmodel,test_data);
⑤集成学习方法(Ensembles for Boosting)
Bmodel=fitensemble(train_data,train_label,'AdaBoostM1',100,'tree','type','classification');
predict_label=predict(Bmodel,test_data);
⑥鉴别分析分类器(Discriminant Analysis Classifier)
DACmodel=ClassificationDiscriminant.fit(train_data,train_label);
predict_label=predict(DACmodel,test_data);
具体使用如下:(练习数据下载地址如下http://en.wikipedia.org/wiki/Iris_flower_data_set,简单介绍一下该数据集:有一批花可以分为3个品种,不同品种的花的花萼长度、花萼宽度、花瓣长度、花瓣宽度会有差异,根据这些特征实现品种分类)
%% 随机森林分类器(Random Forest)
nTree=10;
B=TreeBagger(nTree,train_data,train_label,'Method', 'classification');
predictl=predict(B,test_data);
predict_label=str2num(cell2mat(predictl));
Forest_accuracy=length(find(predict_label == test_label))/length(test_label)*100;
%% 支持向量机
% SVMStruct = svmtrain(train_data, train_label);
% predictl=svmclassify(SVMStruct,test_data);
% predict_label=str2num(cell2mat(predictl));
% SVM_accuracy=length(find(predict_label == test_label))/length(test_label)*100;
%% K近邻分类器(KNN)
% mdl = ClassificationKNN.fit(train_data,train_label,'NumNeighbors',1);
% predict_label=predict(mdl, test_data);
% KNN_accuracy=length(find(predict_label == test_label))/length(test_label)*100
%% 朴素贝叶斯 (Naive Bayes)
% nb = NaiveBayes.fit(train_data, train_label);
% predict_label=predict(nb, test_data);
% Bayes_accuracy=length(find(predict_label == test_label))/length(test_label)*100;
%% 集成学习方法(Ensembles for Boosting, Bagging, or Random Subspace)
% ens = fitensemble(train_data,train_label,'AdaBoostM1' ,100,'tree','type','classification');
% predictl=predict(ens,test_data);
% predict_label=str2num(cell2mat(predictl));
% EB_accuracy=length(find(predict_label == test_label))/length(test_label)*100;
%% 鉴别分析分类器(discriminant analysis classifier)
% obj = ClassificationDiscriminant.fit(train_data, train_label);
% predictl=predict(obj,test_data);
% predict_label=str2num(cell2mat(predictl));
% DAC_accuracy=length(find(predict_label == test_label))/length(test_label)*100;
%% 练习
% meas=[0 0;2 0;2 2;0 2;4 4;6 4;6 6;4 6];
% [N n]=size(meas);
% species={'1';'1';'1';'1';'-1';'-1';'-1';'-1'};
% ObjBayes=NaiveBayes.fit(meas,species);
% x=[3 3;5 5];
% result=ObjBayes.predict(x);
六、关于PCA等数据预处理的几个疑惑
首先要对训练样本的特征进行归一化, 特别强调的是, 归一化操作只能在训练样本中进行, 不能才CV集合或者测试集合中进行, 也就是说归一化操作计算的各个参数只能由训练样本得到, 然后测试样本根据这里得到的参数进行归一化, 而不能直接和训练样本放在一起进行归一化。
另外, 在训练PCA降维矩阵的过程中,也不能使用CV样本或者测试样本, 这样做是不对的。 有很多人在使用PCA训练降维矩阵的时候, 直接使用所有的样本进行训练, 这样实际上相当于作弊的, 这样的话降维矩阵是在包含训练样本和测试样本以及CV样本的情况下训练得到的, 在进行测试的时候, 测试样本会存在很大的优越性, 因为它已经知道了要降维到的空间情况。
6.1PCA问题1
I:进行特征预处理的数据,能否将测试集和训练集联合进行?
II:PCA中,对训练数据进行了PCA降维,对测试数据集的降维应该如何?我看网上说是把训练集得到的变换矩阵保存下来,用(测试集-训练集的均值),然后乘以这个转换矩阵?
III:对样本的行进行归一化的作用是什么?是否会影响SVM的分类精度?
IV:做PCA对Logit回归和SVM的精度有什么影响?我看有人说,svm是基于几何度量,做PCA会使样本间距离变化,导致SVM性能变差?
6.2PCA回答1
1、进行特征预处理的数据,能否将测试集和训练集联合进行?
答:事实上,针对训练集做什么样的预处理,就应该对测试集进行什么样的预处理。因此,即使是分开进行,也应该统一做法:如选择相同的旋转矩阵、选择相同的MinMax值等。
2、PCA中,对训练数据进行了PCA降维,对测试数据集的降维应该如何?我看网上说是把训练集得到的变换矩阵保存下来,用(测试集-训练集的均值),然后乘以这个转换矩阵?
答:我个人觉得使用测试集减去测试集的均值,然后乘以训练集得到的矩阵更为合理。当然,如果训练数据和测试数据来自于相同的分布,它们几乎会有差不多的均值和旋转矩阵。
3、对样本的行进行归一化的作用是什么?是否会影响SVM的分类精度?
答:归一化可以减少优化过程可能存在的无法收敛到极值点的风险,且归一化后的数据特征间均衡,更容易使用更为简单的模型做拟合。它是会影响SVM的精度的,往往会提高精度。
4、做PCA对Logit回归和SVM的精度有什么影响?我看有人说,svm是基于几何度量,做PCA会使样本间距离变化,导致SVM性能变差?
答:从理论上说,可以提高模型的泛化能力;同时,个人觉得使用PCA后再进行SVM不会是的性能变差,论据可以参考“SVM实践”章节的代码。
6.3PCA问题2
请问为什么对所有数据做一次PCA降维以后,再用这些数据划分训练集和测试集,得到的模型精度很好,但是导师说这样做不对,是偷看了先验信息,这是为什么呢,请大神解答!
6.4PCA回答2
你训练的时候不应该知道测试数据的性质的吧?一起训练就等于你训练的时候利用了测试数据的信息。
数据首先分成训练集、测试集;对训练集进行PCA,将拟合之后获得的特征向量矩阵用在测试集上去;
6.5PCA问题3
用pca来对训练集与测试集分别降维并进行分类的问题?
最近在用pca方法来对数据进行降维。训练集数据为300×1000,共有300个训练样本,每个样本有1000维。用matlab自带的函数[COEFF,SCORE,latent]=princimp(traindata)来获得转换矩阵COEFF,根据latent来选择降维后的维数n,用转换矩阵COEFF(:,1:n)与300×1000的训练数据相乘得到降维后的数据。之后,用训练样本的转换矩阵与测试数据600×1000相乘,得到降维后的测试数据。之后,使用SVM进行分类,效果只有0.5%左右,比没有降维前的要差很多。这个过程是哪里有问题吗?
6.6PCA回答3
第一,为什么要指定维度为200呢?这个是自己瞎想的吧,不建议采用。可以另贡献值大于95或者其他参数,得到对应的维数,然后得到COEFF(:,1:n)。写一个循环,就能求出来需要的维度了。
第二,测试集的每个样本要先去训练集的均值,然后再乘以coeff。
七、关于归一化的疑惑
7.1问题1
先对数据划分训练集和测试集后归一化和对数据归一化后划分测试集和训练集,两者的区别?
7.2回答1-1
理论上还是应该先划分数据集,然后对训练数据做预处理,并且保存预处理的参数,在用同样的参数处理测试集。
因为划分训练集和测试集就是假设只知道训练集的信息,而认为测试集数据是来自未来的,不可得知。如果之前统一做预处理之后再划分的话就利用了测试集的信息。
7.3回答1-2
两种顺序本质上差别不会太大,之前也查过一些相关资料,都讲的比较简单,我就说说自己的一些理解。虽然抽样原则上并不改变原数据分布,但是有两点需要注意:1.如果数据中存在个别极端值,这些极端值划分不同可能会造成该变量归一化时放缩比例差距较大2.原则上来说,训练模型时使用的训练集是不能使用测试集中的信息,假设某列变量的最大值超出训练集中该变量的最大值,将会导致归一化后的变量值大于1。如果模型对要求输入的变量值要求±1之间,那就得注意顺序了总的来说我还是prefer先归一化,影响会稍微小些。
7.4回答1-3
先回答问题。因为不了解你的学习模型具体是哪种,所以不太好回答。不过一般来说,先划数据集后标准化和先标准化再划分,对最终数据的影响不大。实践中,一般都先归一化,后划分训练集和测试集。原因嘛,因为数据整理和学习模型是两伙人在搞……狗头保命。咳咳,认真的说。虽然两者一般没有区别,但要考虑到个别极端数值的影响。如果不做标准化,先划数据集,万一有个别极端数据出现在测试集,而没有出现在训练集,那用的时候就要出问题。传统的数据整理和学习模型分成两个步骤,凡事先做数据整理,看起来笨是笨了点,很多时候其实不做或者后做也行,但人们还是坚持这样做,自然有它的道理。
八、机器学习中训练集和测试集归一化-matlab
8.1Matlab归一化函数(mapminmax)
功能:将矩阵的每一行处理成[-1,1]区间。处理需要归一化的m*n矩阵X,归一化后的矩阵记为Y。
主要有5种调用形式
【1】方式1
[Y,PS] = mapminmax(X,YMIN,YMAX)
其中,YMIN是我们期望归一化后矩阵Y每行的最小值,YMAX是我们期望归一化后矩阵Y每行的最大值。
例1:待处理矩阵X=[4 5 6;7 8 9]我们期望归一化后每行的最小值为0,最大值为1.程序如下
X=[4 5 6;7 8 9];
mapminmax(X,0,1)
运行结果:
ans =
0 0.5000 1.0000
0 0.5000 1.0000
【2】方式2
[Y,PS] = mapminmax(X,FP)
FP是一个结构体成员,主要是FP.ymin(相当于YMIN), FP.ymax(相当于YMAX)。1和2处理效果一样,只不过参数的带入形式不同。
例2:
X=[4 5 6;7 8 9];
FP.ymin = 0;
FP.ymax = 1;
mapminmax(X,FP)
运行结果:
ans =
0 0.5000 1.0000
0 0.5000 1.0000
【3】方式3
Y = mapminmax('apply',X,PS)
PS是训练样本的映射,测试样本的预处理方式应与训练样本相同。只需将映射PS apply到测试样本。
例3.训练样本是X,测试样本是M,归一化后的训练样本是Y
X=[4 5 6;7 8 9];
M = [2 3;4 5];
[Y,PS] = mapminmax(X,0,1);
mapminmax('apply',M,PS)
运行结果:
ans =
-1.0000 -0.5000
-1.5000 -1.0000
【4】方式4
X = mapminmax('reverse',Y,PS)
将归一化后的Y反转为归一化之前
例4.将n(M的归一化)反转为M
X=[4 5 6;7 8 9];
M = [2 3;4 5];
[Y,PS] = mapminmax(X,0,1);
n = mapminmax('apply',M,PS);
mapminmax('reverse',n,PS)
运行结果:
ans =
2 3
4 5
【5】方式5
dx_dy = mapminmax('dx_dy',X,Y,PS)
根据给定的矩阵X、标准化矩阵Y及映射PS,获取逆向导数(reverse derivative)。如果给定的X和Y是m行n列的矩阵,那么其结果dx_dy是一个1×n结构体数组,其每个元素又是一个m×n的对角矩阵。这种用法不常用,这里不再举例。
mapminmax的数学公式为y = (ymax-ymin)*(x-xmin)/(xmax-xmin) + ymin。如果某行的数据全部相同,此时xmax=xmin,除数为0,则此时数据不变。
8.2归一化简介
本文不是介绍如何使用matlab对数据集进行归一化,而是通过matlab来介绍一下数据归一化的概念。
以下内容是自己的血泪史,因为归一化的错误,自己的实验过程至少走了两个星期的弯路。由此可见机器学习中一些基础知识和概念还是应该扎实掌握。
背景介绍:
- 归一化后加快了梯度下降求最优解的速度,归一化有可能提高精度。
- 训练集和测试集归一化方法相同。
数据集不小,81132337,81行表示包含81维属性,132337列表示包含132337条训练数据。 数据中包含NaN数据。
使用matlab中的mapminmax函数,归一化到默认的范围[-1 +1]。
为了方便演示,我们以一个简单的矩阵来说明归一化。

这是34的矩阵,表示有4条训练数据,每条数据有3个属性。数据归一化应该针对属性,而不是针对每条数据,针对每条数据是完全没有意义的,因为只是等比例缩放,对之后的分类没有任何作用。这是我遇到的 第一个坑。
【注意:mapminmax是对每列进行归一化】
针对属性进行归一化的代码
inst = [1 2 3 4; 2 3 4 5; 3 4 5 6];
inst_norm = mapminmax(inst);
得到的归一化矩阵如下
inst = [1 2 3 4; 2 3 4 5; 3 4 5 6];
inst_norm = mapminmax(inst')';
得到的归一化矩阵如下

我们应该采用 第一种归一化方法,即对属性进行归一化。
训练集和测试集归一化的方法应该相同,但是在具体实验过程中,脑子发生了短路,对训练集的归一化是针对属性的,但是测试集却针对了数据,这是我遇到的 第二个坑。这种做法让测试结果接近随机,跟训练集没什么关系。
网上有一些说法,觉得训练集和测试集应该放到一起进行归一化,我觉得这种做法有所不妥,这样会让测试集受到训练集的影响,导致训练集和测试集不相互独立。
正确的做法是记录下训练集的归一化方法,用该方法对测试集单独进行归一化,matlab中的 mapminmax函数提供了相应的机制。
对于一条新的数据,应该先按照训练集的归一化方法进行归一化,再进行分类,比如对于如下一条新数据,

通过如下代码
inst = [1 2 3 4; 2 3 4 5; 3 4 5 6];
[inst_norm, settings] = mapminmax(inst);
test = [1 3 5]';
test_norm = mapminmax('apply', test, settings);
其中settings记录了训练集的归一化方法,得到以下归一化结果,可以参考矩阵(2)

mapminmax会跳过NaN数据,最好的方法是归一化之后,将NaN赋值成0。
inst_norm(find(isnan(inst_norm))) = 0;
8.3PCA原理分析和Matlab实现方法
【说明】本博客并不打算长篇大论推论PCA理论,而是用最精简的语言说明鄙人对PCA的理解,并在最后给出用Matlab计算PCA过程的三种方法。
8.3.1PCA原理简要说明
PCA算法主要用于降维,就是将样本数据从高维空间投影到低维空间中,并尽可能的在低维空间中表示原始数据。PCA的几何意义可简单解释为:
0维-PCA:将所有样本信息都投影到一个点,因此无法反应样本之间的差异;要想用一个点来尽可能的表示所有样本数据,则这个点必定是样本的均值。
1维-PCA:相当于将所有样本信息向样本均值的直线投影;
2维-PCA:将样本的平面分布看作椭圆形分布,求出椭圆形的长短轴方向,然后将样本信息投影到这两条长短轴方向上,就是二维PCA。(投影方向就是平面上椭圆的长短轴方向);
3维-PCA:样本的平面分布看作椭圆形分布,投影方法分别是椭圆球的赤道半径a和b,以及是极半径c(沿着z轴);
PCA简而言之就是根据输入数据的分布给输入数据重新找到更能描述这组数据的正交的坐标轴,比如下面一幅图,对于那个椭圆状的分布,最方便表示这个分布的坐标轴肯定是椭圆的长轴短轴而不是原来的x ,y轴。

那么如何求出这个长轴和短轴呢?于是线性代数就来了:我们需要先求出这堆样本数据的协方差矩阵,然后再求出这个协方差矩阵的特征值和特征向量,对应最大特征值的那个特征向量的方向就是长轴(也就是主元)的方向,次大特征值的就是第二主元的方向,以此类推。
8.3.2直接调用Matlab工具箱princomp( )函数实现
实现PCA的方法, 可【1】直接调用Matlab工具箱princomp( )函数实现,也可【2】 自己实现PCA的过程,当然也可以【3】使用快速PCA算法的方法。
(1)方法一:[COEFF SCORE latent]=princomp(X)
参数说明:
1)COEFF 是主成分分量,即样本协方差矩阵的特征向量;
2)SCORE主成分,是样本X在低维空间的表示形式,即样本X在主成份分量COEFF上的投影 ,若需要降k维,则只需要取前k列主成分分量即可
3)latent:一个包含样本协方差矩阵特征值的向量;
实例:假设有8个样本,每个样本有4个特征(属性),使用PCA方法实现降维(k维,k小于特征个数4),并提取前2个主成份的特征,即将原始数据从4维空间降维到2维空间。
%% 样本矩阵X,有8个样本,每个样本有4个特征,使用PCA降维提取k个主要特征(k<4)
k=2; %将样本降到k维参数设置
X=[1 2 1 1; %样本矩阵
3 3 1 2;
3 5 4 3;
5 4 5 4;
5 6 1 5;
6 5 2 6;
8 7 1 2;
9 8 3 7]
%% 使用Matlab工具箱princomp函数实现PCA
% 高版本库可能需要将princomp换成PCA
[COEFF SCORE latent]=princomp(X)
pcaData1=SCORE(:,1:k) %取前k个主成分
运行结果:
X =
1 2 1 1
3 3 1 2
3 5 4 3
5 4 5 4
5 6 1 5
6 5 2 6
8 7 1 2
9 8 3 7
COEFF =
0.7084 -0.2826 -0.2766 -0.5846
0.5157 -0.2114 -0.1776 0.8111
0.0894 0.7882 -0.6086 0.0153
0.4735 0.5041 0.7222 -0.0116
SCORE =
-5.7947 -0.6071 0.4140 -0.0823
-3.3886 -0.8795 0.4054 -0.4519
-1.6155 1.5665 -1.0535 1.2047
-0.1513 2.5051 -1.3157 -0.7718
0.9958 -0.5665 1.4859 0.7775
1.7515 0.6546 1.5004 -0.6144
2.2162 -3.1381 -1.6879 -0.1305
5.9867 0.4650 0.2514 0.0689
latent =
13.2151
2.9550
1.5069
0.4660
pcaData1 =
-5.7947 -0.6071
-3.3886 -0.8795
-1.6155 1.5665
-0.1513 2.5051
0.9958 -0.5665
1.7515 0.6546
2.2162 -3.1381
5.9867 0.4650
后期训练集与测试集
8.3.3自己实现PCA的过程
PCA的算法过程,用一句话来说,就是“ 将所有样本X减去样本均值m,再乘以样本的协方差矩阵C的特征向量V,即为PCA主成分分析 ”,其计算过程如下:
[1].将原始数据按行组成m行n列样本矩阵X(每行一个样本,每列为一维特征)
[2].求出样本X的协方差矩阵C和样本均值m;(Matlab可使用cov()函数求样本的协方差矩阵C,均值用mean函数)
[3].求出协方差矩阵的特征值D及对应的特征向量V;( Matlab可使用eigs()函数求矩阵的特征值D和特征向量V )
[4].将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P;(eigs()返回特征值构成的向量本身就是从大到小排序的)
[5].Y=(X-m)×P即为降维到k维后的数据;
PS:关于协方差矩阵,很多人有点郁闷,有些教程用协方差矩阵,而有些资料是用散步矩阵计算,其实协方差矩阵和散步矩阵就是一个倍数关系: 协方差矩阵C×(n-1)=散步矩阵S 。我们可以使用Matlab工具箱的cov函数求协方差矩阵C。
%% 自己实现PCA的方法
[Row Col]=size(X);
covX=cov(X); %求样本的协方差矩阵(散步矩阵除以(n-1)即为协方差矩阵)
[V D]=eigs(covX); %求协方差矩阵的特征值D和特征向量V
meanX=mean(X); %样本均值m
%所有样本X减去样本均值m,再乘以协方差矩阵(散步矩阵)的特征向量V,即为样本的主成份SCORE
tempX= repmat(meanX,Row,1);
SCORE2=(X-tempX)*V %主成份:SCORE
pcaData2=SCORE2(:,1:k)
运行结果:
SCORE2 =
-5.7947 0.6071 -0.4140 0.0823
-3.3886 0.8795 -0.4054 0.4519
-1.6155 -1.5665 1.0535 -1.2047
-0.1513 -2.5051 1.3157 0.7718
0.9958 0.5665 -1.4859 -0.7775
1.7515 -0.6546 -1.5004 0.6144
2.2162 3.1381 1.6879 0.1305
5.9867 -0.4650 -0.2514 -0.0689
pcaData2 =
-5.7947 0.6071
-3.3886 0.8795
-1.6155 -1.5665
-0.1513 -2.5051
0.9958 0.5665
1.7515 -0.6546
2.2162 3.1381
5.9867 -0.4650
对比方法一和方法可知,主成份分量SCORE和SCORE2的绝对值是一样的(符号只是相反方向投影而已,不影响分析结果),其中pcaData是从SCORE提取前2列的数据,这pcaData就是PCA从4维降到2 维空间的数据表示形式,pcaData可以理解为:通过PCA降维,每个样本可以用2个特征来表示原来4个特征了。
8.3.4使用快速PCA算法的方法
PCA 的计算中最主要的工作量是计算样本协方差矩阵的本征值和本征向量。假设样本矩阵 X 的大小为 n ×d ( n 个 d 维样本特征向量 ) ,则样本散布矩阵 ( 协方差矩阵 ) S 将是一个 d×d 的方阵,故当维数 d 较大时计算复杂度会非常高。例如当维数 d= 10000 , S 是一个 10 000 ×10 000 的矩阵,此时如果采用上面的 princomp 函数计算主成份, Matlab 通常会出现内存耗尽的问题( out of memory ), 即使有足够多的内存,要得到 S 的全部本征值可能也要花费数小时的时间。
快速PCA的方法相关理论,可以参考 张铮的《精通Matlab数字图像处理与识别 》第12章( P307 ),PDF可在附件下载:http://download.csdn.net/detail/guyuealian/9799160
fastPCA函数用来对样本矩阵A进行快速主成分分析和降维(降至k维),其输出pcaA为维后的k维样本特征向量组成的矩阵,每行一个样本,列数k为降维后的样本特征维数,相当于princomp函数中的输出SCORE, 而输出V为主成分分量,相当于princomp函数中的输出COEFF。
%% 使用快速PCA算法实现的方法
[pcaData3 COEFF3] = fastPCA(X, k )
其中fastPCA函数的代码实现如下:
function [pcaA V] = fastPCA( A, k )
% 快速PCA
% 输入:A --- 样本矩阵,每行为一个样本
% k --- 降维至 k 维
% 输出:pcaA --- 降维后的 k 维样本特征向量组成的矩阵,每行一个样本,列数 k 为降维后的样本特征维数
% V --- 主成分向量
[r c] = size(A);
% 样本均值
meanVec = mean(A);
% 计算协方差矩阵的转置 covMatT
Z = (A-repmat(meanVec, r, 1));
covMatT = Z * Z';
% 计算 covMatT 的前 k 个本征值和本征向量
[V D] = eigs(covMatT, k);
% 得到协方差矩阵 (covMatT)' 的本征向量
V = Z' * V;
% 本征向量归一化为单位本征向量
for i=1:k
V(:,i)=V(:,i)/norm(V(:,i));
end
% 线性变换(投影)降维至 k 维
pcaA = Z * V;
% 保存变换矩阵 V 和变换原点 meanVec
运行结果为:
pcaData3 =
-5.7947 -0.6071
-3.3886 -0.8795
-1.6155 1.5665
-0.1513 2.5051
0.9958 -0.5665
1.7515 0.6546
2.2162 -3.1381
5.9867 0.4650
COEFF3 =
0.7084 -0.2826
0.5157 -0.2114
0.0894 0.7882
0.4735 0.5041
九、【机器学习】 Matlab 实现多种分类器(感知机、KNN、Logistic、最大熵、决策树、朴素贝叶斯)的二分类
9.1写在之前
这是本人的统计学习方法作业之一,老师要求一定要用Matlab编程,本人在此之前未曾大量使用Matlab,因此某些算法可能因为不知道函数或者包而走了弯路。代码高亮查了一下,没找到Matlab的所以用了C的。部分算法参考了某些算法的python算法,如有建议或者错误欢迎指出,谢谢!
数据集
提供的flower.txt文件为鸢尾花数据集,共分为3类花(前50个样本为一类,中间50个样本为一类,后50个样本为一类,每一朵花包含4个维度的测量值(feature)。现只处理二分类问题,因而只使用前100个数据。其中,每组前40个用作训练,后10个用作测试。因此,该数据集训练样本80个,测试样本20个。
主程序
首先,在matlab工程新建script文件classification.m,参考代码如下:
classification.m
clear;
%% step1: 划分数据集
flower = load('flower.txt');
train_X = [flower(1:40, :);flower(51:90, :)];
train_Y = [ones(40, 1); zeros(40, 1)];
test_X = [flower(41:50, :);flower(91:end, :)];
test_Y = [ones(10, 1); zeros(10, 1)];
%% step2:学习和预测,预测test_y
output_perceptron = perceptron(train_X, train_Y, test_X);%因为随机取起点,所以每次运行分类结果不一定一样
output_knn = knn(train_X, train_Y, test_X); %简单测试,k取9效果比较好
output_logistic = logistic(train_X, train_Y, test_X);
output_entropy = entropy(train_X, train_Y, test_X);
output_tree = tree(train_X, train_Y, test_X);
output_nb = nb(train_X, train_Y, test_X); %数据集为连续型数据,需用高斯贝叶斯分类器
%% step3:分析结果,准确率召回率等
output_set = [output_perceptron;output_knn;output_logistic;output_entropy;output_tree;output_nb];
compare(test_Y,output_set);
function compare(test_Y,output)
result = [];
for i = 1:length(output(:,1))
[ACC,PRE,REC] = evaluation(test_Y,output(i,:));
result = [result;[ACC,PRE,REC]];
end
bar(result);
grid on;
legend('ACC','PRE','REC');
set(gca,'XTickLabel',{'perceptron','knn','logistic','entropy','tree','nb'});
xlabel('分类器种类');
ylabel('指标值');
end
function [ACC,PRE,REC] = evaluation(test_Y,output) %评估分类性能,ACC分类准确率、PRE精确率、REC召回率
TP = 0;
FN = 0;
FP = 0;
TN = 0;
for i = 1:length(test_Y)
if test_Y(i)==1
if output(i)==1
TP = TP + 1;%将正类预测为正类数
else
FN = FN + 1;%将正类预测为负类数
end
else
if output(i)==1
FP = FP + 1;%将负类预测为正类数
else
TN = TN + 1;%将负类预测为负类数
end
end
end
ACC = (TP+TN)/(TP+FN+FP+TN);
PRE = TP/(TP+FP);
REC = TP/(TP+FN);
end
子程序
第二步:分别新建6个函数,perceptron,knn,logistic,entropy,tree,nb,实现相应7个分类器,将代码分别复制到以下对应文本框内。每个分类器的输入只有训练集和测试集的X,其返回结果为测试集的y(一个向量)。
perceptron.m
function [ test_Y ] = perceptron( X, Y, test_X )
%% 初始化w,b,alpha,
w = [0,0,0,0];
b = 0;
alpha = 1; % learning rate
sample = X;
for i = 1:length(Y)
if Y(i)==1
sign(i) = 1;
else
sign(i) = -1;
end
end
sign = sign';
maxstep = 1000;
%% 更新 w,b
for i=1:maxstep
[idx_misclass, counter] = class(sample, sign, w, b);%等式右边为输入,左边为输出,理解为函数调用
%obj_struct = class(struct_array,'class_name',parent_array)
%idx_misclass:误分类序号索引,counter:
if (counter~=0)%~=代表不等于
R = unidrnd(counter);%产生离散均匀随机整数(一个),即随机选取起点训练
%fprintf('%d\n',R);
w = w + alpha * sample(idx_misclass(R),:) * sign(idx_misclass(R));
b = b + alpha * sign(idx_misclass(R));
else
break
end
end
%%
for i=1:length(test_X)
if(w*test_X(i,:)'+b >=0)
test_Y(i) = 1;
else
test_Y(i) = 0;
end
end
end
function [idx_misclass, counter] = class(sample, label, w, b)
counter = 0;
idx_misclass = [];
for i=1:length(label)
if (label(i)*(w*sample(i,:)'+b)<=0) %如果有误分类点,进行迭代
idx_misclass = [idx_misclass i];
%fprintf('%d\n',idx_misclass);
counter = counter + 1;
end
end
end
knn.m
function [ test_Y ] = knn( X, Y, test_X )
k = 7;
for i = 1:length(test_X)
for j = 1:length(X)
dist(i,j) = norm(test_X(i)-X(j));
end
[B,idx] = mink(dist(i,:),k);
result(i,:) = Y(idx);
end
for i = 1:length(test_X)
if(sum(result(i,:))>=k/2)
test_Y(i) = 1;
else
test_Y(i) = 0;
end
end
end
logistic.m
function [J, grad] = costFunction(theta, X, Y, lambda)
m = length(Y);
grad = zeros(size(theta));
J = 1 / m * sum( -Y .* log(sigmoid(X * theta)) - (1 - Y) .* log(1 - sigmoid(X * theta)) ) + lambda / (2 * m) * sum( theta(2 : size(theta), :) .^ 2 );
for j = 1 : size(theta)
if j == 1
grad(j) = 1 / m * sum( (sigmoid(X * theta) - Y)' * X(:, j) );
else
grad(j) = 1 / m * sum( (sigmoid(X * theta) - Y)' * X(:, j) ) + lambda / m * theta(j);
end
end
end
function g = sigmoid(z)
g = zeros(size(z));
g = 1 ./ (1 + exp(-z));
end
entropy.m
function [ test_Y ] = entropy( X, Y, test_X )
%% 变量定义
maxstep=10;
w = [];
labels = []; %类别的种类
fea_list = []; %特征集合
px = containers.Map(); %经验边缘分布概率
pxy = containers.Map(); %经验联合分布概率,由于特征函数为取值为0,1的二值函数,所以等同于特征的经验期望值
exp_fea = containers.Map(); %每个特征在数据集上的期望
N = 0; % 样本总量
M =0; % 某个训练样本包含特征的总数,这里假设每个样本的M值相同,即M为常数。其倒数类似于学习率
n_fea = 0; % 特征函数的总数
fit(X,Y);
test_Y = [];
for q = 1:length(test_X) %测试集预测
p_Y = predict(test_X(q));
test_Y = [test_Y,p_Y];
end
%% 变量初始化
function init_param(X,Y)
N = length(X);
labels = unique(Y);
%初始化px pxy
for i = 1:length(X)
px(num2str(X(i,:))) = 0;
pxy(num2str([X(i,:),Y(i)])) = 0;
end
%初始化exp_fea
for i = 1:length(X)
for j = 1:length(X(i,:))
fea = [j,X(i,j),Y(i)];
exp_fea(num2str(fea)) = 0;
end
end
fea_func(X,Y);
n_fea = length(fea_list);
w = zeros(n_fea,1);
f_exp_fea(X,Y);
end
%% 构造特征函数
function fea_func(X,Y)
for i = 1:length(X)
px(num2str(X(i,:))) = px(num2str(X(i,:))) + 1.0/double(N);
pxy(num2str([X(i,:),Y(i)])) = pxy(num2str([X(i,:),Y(i)]))+ 1.0/double(N);
for j = 1:length(X(1,:))
key = [j,X(i,j),Y(i)];
fea_list = [fea_list;key];
end
end
fea_list = unique(fea_list,'rows');
M = length(X(i,:));
end
function f_exp_fea(X,Y)
for i = 1:length(X)
for j = 1:length(X(i,:))
fea = [j,X(i,j),Y(i)];
exp_fea(num2str(fea)) = exp_fea(num2str(fea)) + pxy(num2str([X(i,:),Y(i)]));
end
end
end
%% 当前w下的条件分布概率,输入向量X和y的条件概率
function py_X =f_py_X(X)
py_X = containers.Map();
for i = 1:length(labels)
py_X(num2str(labels(i))) = 0.0;
end
for i = 1:length(labels)
s = 0;
for j = 1:length(X)
tmp_fea = [j,X(j),labels(i)];
if(ismember(tmp_fea,fea_list,'rows'))
s = s + w(ismember(tmp_fea,fea_list,'rows'));
end
end
py_X(num2str(labels(i))) = exp(s);
end
normalizer = 0;
k_names = py_X.keys();
for i = 1:py_X.Count
normalizer = normalizer + py_X(char(k_names(i)));
end
for i = 1:py_X.Count
py_X(char(k_names(i))) = double(py_X(char(k_names(i))))/double(normalizer);
end
end
%% 基于当前模型,获取每个特征估计期望
function est_fea = f_est_fea(X,Y)
est_fea = containers.Map();
for i = 1:length(X)
for j = 1:length(X(i,:))
est_fea(num2str([j,X(i,j),Y(i)])) = 0;
end
end
for i = 1:length(X)
py_x = f_py_X(X);
py_x = py_x(num2str(Y(i)));
for j = 1:length(X(i,:))
est_fea(num2str([j,X(i,j),Y(i)])) = est_fea(num2str([j,X(i,j),Y(i)])) + px(num2str(X(i,:)))*py_x;
end
end
end
%% GIS算法更新delta
function delta = GIS()
est_fea = f_est_fea(X,Y);
delta = zeros(n_fea,1);
for i = 1:n_fea
try
delta(i) = 1 / double(M*log(exp_fea(num2str(fea_list(i,:)))))/double(est_fea(num2str(fea_list(i,:))));
catch
continue;
end
end
delta = double(delta) / double(sum(delta));
end
%% 训练,迭代更新wi
function fit(X,Y)
init_param(X,Y);
i = 0;
while( i < maxstep)
i = i + 1;
delta = GIS();
w = w + delta;
end
end
%% 输入x(数组),返回条件概率最大的标签
function best_label = predict(X)
py_x = f_py_X(X);
keys = py_x.keys();
values = py_x.values();
max = 0;
best_label = -1;
for i = 1:py_x.Count
if(py_x(char(keys(i))) > max)
max = py_x(char(keys(i)));
best_label = str2num(char(keys(i)));
end
end
end
end
tree.m
function [ test_Y ] = tree( X, Y, test_X )
global tree;
tree = [];
disp("The Tree is :");
build_tree(X,Y);
% disp(tree);
S = regexp(tree, '\s+', 'split');
test_Y = [];
var = 0;
condi = 0;
for i = 1:length(test_X)
tx = test_X(i,:);
for j=1:length(S)
if contains(S(j),'node')
var = tx(str2num(char(S(j+1))));
condi = str2num(char(S(j+2)));
if var < condi
if contains(S(j+3),'leaf')
ty = char(S((j+3)));
ty = ty(6);
test_Y = [test_Y,str2num(ty)];
break
else
j = j + 3;
end
else
if contains(S(j+4),'leaf')
ty = char(S((j+4)));
ty = ty(6);
test_Y = [test_Y,str2num(ty)];
break
else
j = j + 4;
end
end
end
end
end
end
function build_tree(x, y, L, level, parent_y, sig, p_value)
% 自编的用于构建决策树的简单程序,适用于属性为二元属性,二分类情况。(也可对程序进行修改以适用连续属性)。
% 输入:
% x:数值矩阵,样本属性记录(每一行为一个样本)
% y:数值向量,样本对应的labels
% 其它参数调用时可以忽略,在递归时起作用。
% 输出:打印决策树。
global tree;
if nargin == 2
level = 0;
parent_y = -1;
L = 1:size(x, 2);
sig = -1;
p_value = [];
% bin_f = zeros(size(x, 2), 1);
% for k=1:size(x, 2)
% if length(unique(x(:,k))) == 2
% bin_f(k) = 1;
% end
% end
end
class = [0, 1];
[r, label] = is_leaf(x, y, parent_y); % 判断是否是叶子节点
if r
if sig ==-1
disp([repmat(' ', 1, level), 'leaf (', num2str(label), ')'])
tree = [tree,[' leaf(', num2str(label), ')']];
elseif sig ==0
disp([repmat(' ', 1, level), '<', num2str(p_value),' leaf (', num2str(label), ')']);
tree = [tree,[' leaf(', num2str(label), ')']];
else
disp([repmat(' ', 1, level), '>', num2str(p_value),' leaf (', num2str(label), ')']);
tree = [tree,[' leaf(', num2str(label), ')']];
end
else
[ind, value, i_] = find_best_test(x, y, L); % 找出最佳的测试值
%
% if ind ==1
% keyboard;
% end
[x1, y1, x2, y2] = split_(x, y, i_, value); % 实施划分
if sig ==-1
disp([repmat(' ', 1, level), 'node (', num2str(ind), ', ', num2str(value), ')']);
tree = [tree,[' node ', num2str(ind), ' ',num2str(value)]];
elseif sig ==0
disp([repmat(' ', 1, level), '<', num2str(p_value),' node (', num2str(ind), ', ', num2str(value), ')']);
tree = [tree,[' node ',num2str(ind), ' ', num2str(value)]];
else
disp([repmat(' ', 1, level), '>', num2str(p_value),' node (', num2str(ind), ', ', num2str(value), ')']);
tree = [tree,[' node ',num2str(ind), ' ', num2str(value)]];
end
% if bin_f(i_) == 1
x1(:,i_) = [];
x2(:,i_) = [];
L(:,i_) = [];
% bin_f(i_) = [];
% end
build_tree(x1, y1, L, level+1, y, 0, value); % 递归调用
build_tree(x2, y2, L, level+1, y, 1, value);
end
function [ind, value, i_] = find_best_test(xx, yy, LL) % 子函数:找出最佳测试值(可以对连续属性适用)
imp_min = inf;
i_ = 1;
ind = LL(i_);
for i=1:size(xx,2);
if length(unique(xx(:,i))) ==1
continue;
end
% [xx_sorted, ii] = sortrows(xx, i);
% yy_sorted = yy(ii, :);
vv = unique(xx(:,i));
imp_min_i = inf;
best_point = mean([vv(1), vv(2)]);
value = best_point;
for j = 1:length(vv)-1
point = mean([vv(j), vv(j+1)]);
[xx1, yy1, xx2, yy2] = split_(xx, yy, i, point);
imp = calc_imp(yy1, yy2);
if imp<imp_min_i
best_point = point;
imp_min_i = imp;
end
end
if imp_min_i < imp_min
value = best_point;
imp_min = imp_min_i;
i_ = i;
ind = LL(i_);
end
end
end
function imp = calc_imp(y1, y2) % 子函数:计算熵
p11 = sum(y1==class(1))/length(y1);
p12 = sum(y1==class(2))/length(y1);
p21 = sum(y2==class(1))/length(y2);
p22 = sum(y2==class(2))/length(y2);
if p11==0
t11 = 0;
else
t11 = p11*log2(p11);
end
if p12==0
t12 = 0;
else
t12 = p12*log2(p12);
end
if p21==0
t21 = 0;
else
t21 = p21*log2(p21);
end
if p22==0
t22 = 0;
else
t22 = p22*log2(p22);
end
imp = -t11-t12-t21-t22;
end
function [x1, y1, x2, y2] = split_(x, y, i, point) % 子函数:实施划分
index = (x(:,i)<point);
x1 = x(index,:);
y1 = y(index,:);
x2 = x(~index,:);
y2 = y(~index,:);
end
function [r, label] = is_leaf(xx, yy, parent_yy) % 子函数:判断是否是叶子节点
if isempty(xx)
r = true;
label = mode(parent_yy);
elseif length(unique(yy)) == 1
r = true;
label = unique(yy);
else
t = xx - repmat(xx(1,:),size(xx, 1), 1);
if all(all(t ==0))
r = true;
label = mode(yy);
else
r = false;
label = [];
end
end
end
end
nb.m
function [ test_Y ] = nb( X, Y, test_X )
%% 计算每个分类的样本的概率
labelProbability = tabulate(Y);
%P_yi,计算P(yi)
P_y1=labelProbability(1,3)/100;
P_y2=labelProbability(2,3)/100;
%% 计算每个属性(列)的均值与方差
X1 = [];
X2 = [];
for i = 1:length(X)
if(Y(i)==1)
X1 = [X1;X(i,:)];
else
X2 = [X2;X(i,:)];
end
end
%% 计算每个类的均值和方差
x1_mean = mean(X1,1);
x1_std = std(X1,0,1);
x2_mean = mean(X2,1);
x2_std = std(X2,0,1);
test_Y = [];
for i = 1:length(test_X)
p1 = 1; %归属第一个类的概率
p2 = 1; %归属第二个类的概率
for j = 1:length(test_X(1,:))
p1 = p1 * gaussian(test_X(i,j),x1_mean(j),x1_std(j)); %p(xj|y)
p2 = p2 * gaussian(test_X(i,j),x2_mean(j),x2_std(j));
end
p1 = p1 * P_y1;
p2 = p2 * P_y2;
if(p1>p2)
test_Y = [test_Y,1];
else
test_Y = [test_Y,0];
end
end
%% 定义高斯(正太)分布函数
function p = gaussian(x,mean,std)
p = 1/sqrt(2*pi*std*std)*exp(-(x-mean)*(x-mean)/(2*std));
end
end
结果分析
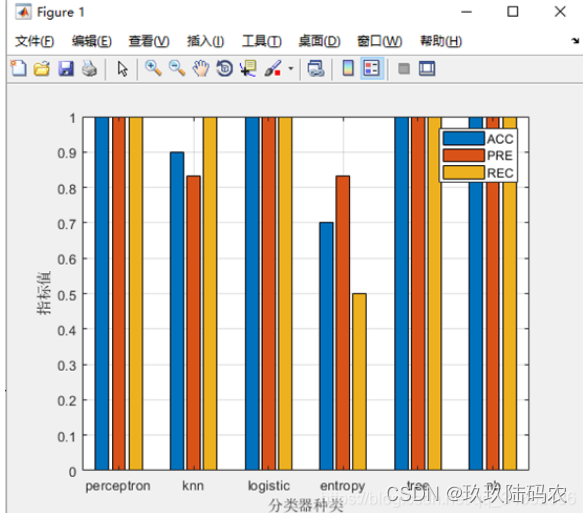
运行classification.m脚本,将所得到的6个分类器的结果与真实test_Y进行比较,对各分类器的结果进行简单分析比较。
运行结果为每个类的预测标签,通过测试集真实标签对比,构造处混淆矩阵,可以计算得到分类准确率ACC、分类精确率PRE、分类召回率REC,以其作为评价指标可绘制柱形图对比,结果如下图所示,具体代码见classification.m 的step3。
从分类结果上来看,感知机、罗吉斯特回归、决策树、朴素贝叶斯的表现最好,全部指标都达到了满值,一方面是这些分类器分类效果比较好,另一方面也由于训练样本不足而导致。分类效果一般的是KNN,这是由K的取值而导致的不稳定分类,分类效果最差的是最大熵,原因可能因为训练集数据是连续的,而实现最大熵的时候将每一条数据当成离散的特征函数,导致分类效果不佳。值得一提的是,朴素贝叶斯最开始实现的时候也会存在这个问题,但朴素贝叶斯处理连续数据时可做正态分布假设,实现时使用高斯朴素贝叶斯,其结果表现良好。















 1964
1964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









