






摘要
DETR简化了目标检测的流程,避免了许多需要手动设计的模块,比如没有proposal(Faster R-CNN),没有Anchor(YOLO),没有center(CenterNet),也没有繁琐的NMS,根据目标和全局图像信息的关系,直接预测输出检测框和分类。在COCO数据集上,DETR的准确性和检测速度性能与Faster R-CNN相当。而且,DETR可以很容易地推广到全景分割。
一、模型的整体结构
模型采用了一种基于Transformer的encoder-decoder结构,Transformer是一种流行的序列预测结构。Transformer的self-attention机制明确地对序列中元素之间的所有成对交互进行建模,使这些架构特别适合于集预测的特定约束,例如删除重复预测。

- Backbone
利用传统的CNN网络Resnet,将输入的图像变成特征图
输入图片尺寸:
![[公式]](https://img-blog.csdnimg.cn/20210309160450321.png)
输出特征尺寸:
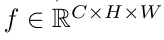
- Transformer encoder-decoder
f
f
f–>
z
0
z_0
z0 : 1*1卷积压缩维度

再压缩到一维:
d
∗
H
W
d*HW
d∗HW,输入到encoder,
- FFN
FFN包括一个具有ReLU激活函数和d维隐藏层的3层感知器和一个线性投影层,独立解码为包含类别得分和预测框坐标的最终检测结果。

二、损失函数
匈牙利算法二分匹配策略:
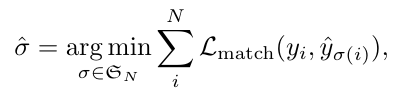
其中定义
L
m
a
t
c
h
L_{match}
Lmatch:
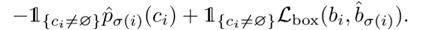
定义
L
b
o
x
L_{box}
Lbox:
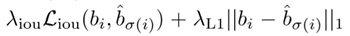
三、实验
与目标检测经典框架Faster RCNN进行对比:
效果与经典方法Faster RCNN差不多,对于大目标的检测效果有所提升,但在小目标的检测中表现较差。















 1842
1842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









