






大模型成为发展通用人工智能的重要途径
专用模型:
针对特定任务,一个模型解决一个问题
通用大模型:
个模型应对多种任务、多种模态
书生·浦语大模型开源历程
6月7日 InternLM 千亿参数语言大模型发布
7月6日 千亿参数大模型全面升级 支持 8K 语境、26 种语言 全面开源,免费商用: InternLM-78 模型、全链条开源工具体系
8月14日 书生·万卷 1.0 多横态预训练语料库开源发布
8月21日 升级版对话模型 InternLM-Chat-7B v1.1 发布 开源智能体框架 Lagent 支持从语言模型到智能体升级转换
8月28日 InternLM 千亿参数模型 参数量升级至 123B
9月20日 增强版InternLM-20B 开源 开源工具链全线升级
2024年1月17日 InternLM 2 开源
书生·浦语 2.0(InternLM2)的体系
面向不同的使用需求,每个规格包含三个模型版本
7B 为轻量级的研究和应用提供了一个轻便但性能不俗的模型
20B 模型的综合性能更为强劲,可有效支持更加复杂的实用场景
InternLM2-Base 高质量和具有很强可塑性的模型基座是模型进行深度领域适配的高质量起
InternLM2 在 Base基础上,在多个能力方向进行了强化,在评测中成绩优异,同时保持了很好的通用语言能力,是我们推荐的在大部分应用中考虑选用的优秀基座
InternLM2-Chat 在 Base 基础上,经过 SFT 和 RLHF,面向对话交互进行了优化,具有很好的指令避循、共情聊天和调用工具等的能力
书生·浦语 2.0(InternLM2)的主要亮点
超长上下文
综合性能全面提升
优秀的对话和创作体验
工具调用能力整体升级
突出的数理能力和实用的数据分析功能
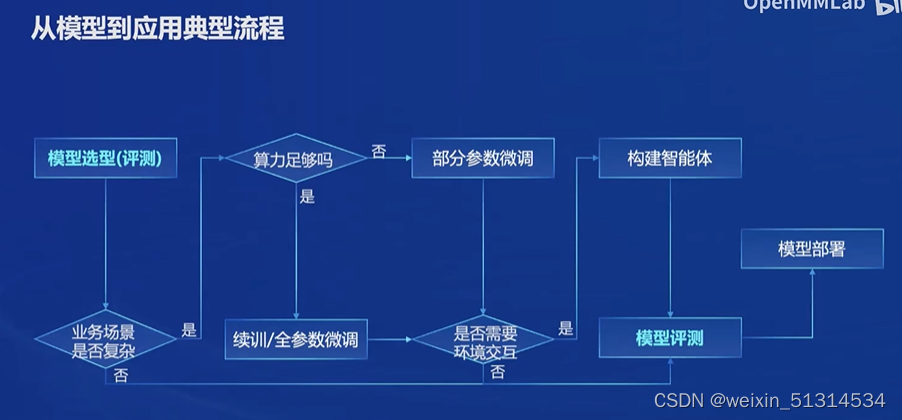
从模型到应用典型流程
书生浦语全链条开源开放体系
开放高质量语料数据:书生万卷1.0与书生万卷CC,数据集获取:https://opendatalab org.cn/
预训练:高可扩展,支持从 8 卡到千卡训练千卡加速效率达 92%;极致性能优化,Hybrid Zero 独特技术+极致优化,加速 50%;兼容主流,无缝接入 HuggingFace等技术生态,支持各类轻量化技术;开箱即用,支持多种规格语言模型修改配置即可训练
微调:大语言模型的下游应用中,增量续训和有监督微调是经常会用到两种方。增量续训,使用场景:让基座模型学习到一些新知识,如某个垂类领域知识;训练数据:文章、书籍、代码等。有监督微调,使用场景:让模型学会理解各种指令进行对话,或者注入少量领域知识;训练数据:高质量的对话、问答数据
评测:OpenCompass 2.0司南大模型评测体系
部署:LMDeploy 提供大模型在GPU上部署的全流程解决方案,包括模型轻量化、推理和服务。
智能体:轻量级智能体框架Lagent,支持多种类型的智能体能力,灵活支持多种大预言模型,简单易拓展,支持丰富的工具















 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









