







前言
在数据科学和机器学习领域,对复杂数据集进行高精度的分类预测是一个常见且关键的任务。本文通过MATLAB代码示例详细介绍了如何使用反向传播神经网络(BP神经网络)进行多输入单输出的回归预测,涵盖了整个流程从数据处理到模型训练和性能评估的各个步骤。

环境准备
环境准备阶段的目的是确保我们的MATLAB环境是清洁的,没有干扰因素:
warning off % 关闭警告信息可以避免一些不必要的输出,使得结果更加清晰。
close all % 关闭所有图形窗口可以确保后续生成的图像是我们刚刚创建的,而不是之前遗留的。
clear % 清除所有变量可以去除先前脚本运行可能遗留在内存中的变量。
clc % 清空命令行窗口可以为新的运行结果提供一个干净的视觉环境。
导入数据
此部分使用xlsread函数从Excel文件中读取数据集:
dataset = xlsread('dataset.xlsx'); % 读取'xlsx'文件中的数据并存储到变量'dataset'中。
划分训练集和测试集
为了验证我们模型的泛化能力,我们需要将数据集划分为训练集和测试集:
randomIndices = randperm(357); % 生成一个1到357的随机排列数组,数值357应该是数据集的样本总数。
使用该随机排列,我们选择前240个样本作为训练集,剩下的作为测试集:
inputs_train = dataset(randomIndices(1: 240), 1: 12)';
targets_train = dataset(randomIndices(1: 240), 13)';
numTrainSamples = size(inputs_train, 2);
上述代码将前12列作为输入特征,第13列作为目标输出,并通过转置操作'确保数据以正确的格式被神经网络接收。
inputs_test = dataset(randomIndices(241: end), 1: 12)';
targets_test = dataset(randomIndices(241: end), 13)';
numTestSamples = size(inputs_test, 2);
测试集的处理方式与训练集类似,但是只包含剩余的样本。
数据归一化
为了提高模型的训练效率和性能,对数据进行归一化处理:
[normalized_inputs_train, input_norm_settings] = mapminmax(inputs_train, 0, 1);
normalized_inputs_test = mapminmax('apply', inputs_test, input_norm_settings);
mapminmax函数将数据缩放到0和1之间,并且保存了归一化的参数,这样我们可以用相同的参数来归一化测试数据。
encoded_targets_train = ind2vec(targets_train);
encoded_targets_test = ind2vec(targets_test);
ind2vec函数通常用于将标签编码成神经网络的目标向量。这里似乎是将一个回归问题看作了分类问题,如果这是个回归任务,这步操作可能不适用。
建立模型
创建一个前馈神经网络:
net = newff(normalized_inputs_train, encoded_targets_train, 6);
其中newff是创建新的前馈神经网络的函数,6表示隐藏层的神经元数量。
设置训练参数
设置网络的一些训练参数,如迭代次数、目标误差和学习率:
net.trainParam.epochs = 1000; % 设置最大迭代次数为1000。
net.trainParam.goal = 1e-6; % 设置目标误差为很小的数,通常来说越小模型越精确,但训练时间可能更长。
net.trainParam.lr = 0.01; % 设置学习率,控制权重更新的幅度。
训练网络
使用train函数训练定义好的神经网络:
net = train(net, normalized_inputs_train, encoded_targets_train);
这一步会更新网络的权重和偏差,以最小化误差函数。
仿真测试
在训练集和测试集上进行仿真,得到预测值:
sim_targets_train = sim(net, normalized_inputs_train);
sim_targets_test = sim(net, normalized_inputs_test);
sim函数用于模拟神经网络的输出。
数据反归一化和排序
将输出结果反归一化,并排序:
decoded_sim_targets_train = vec2ind(sim_targets_train);
decoded_sim_targets_test = vec2ind(sim_targets_test);
如果确实是分类问题,则vec2ind函数将神经网络的输出向量转换回它们原来的标签形式。
排序是为了方便后续的性能评估和可视化对比。
性能评价
计算预测准确率:
accuracy_train = sum((decoded_sim_targets_train == sorted_targets_train)) / numTrainSamples * 100;
accuracy_test = sum((decoded_sim_targets_test == sorted_targets_test)) / numTestSamples * 100;
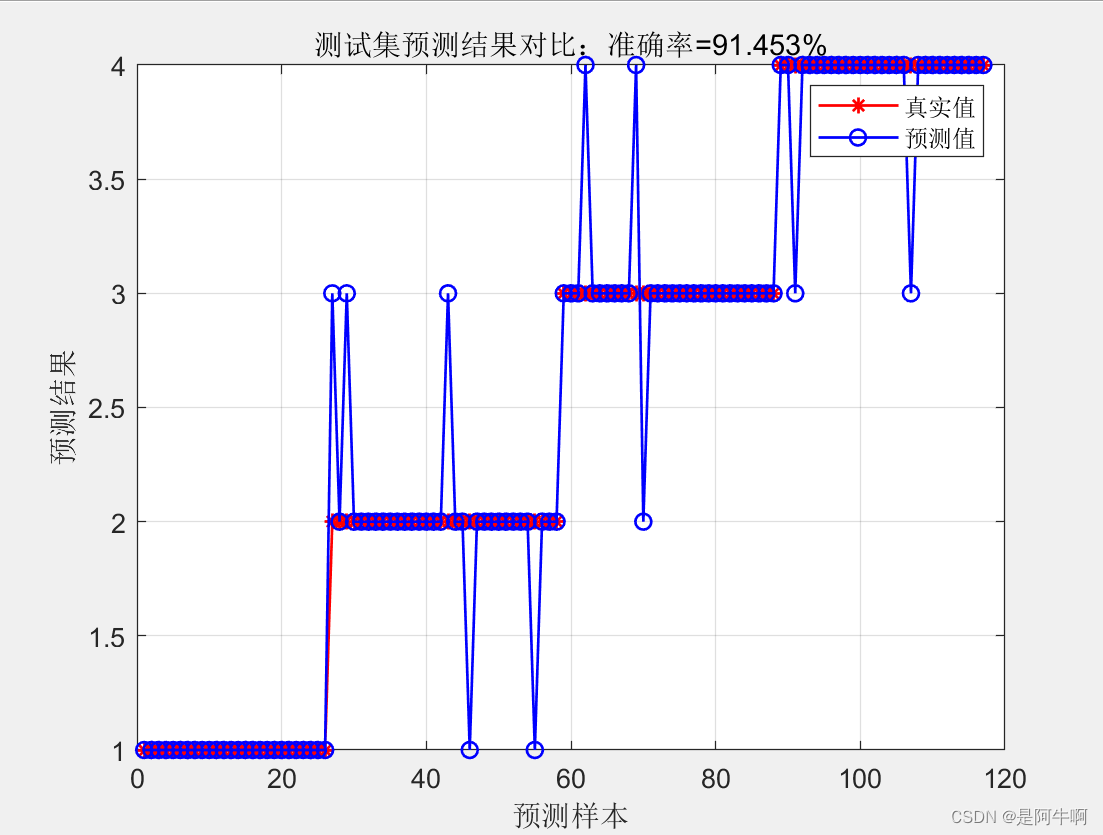
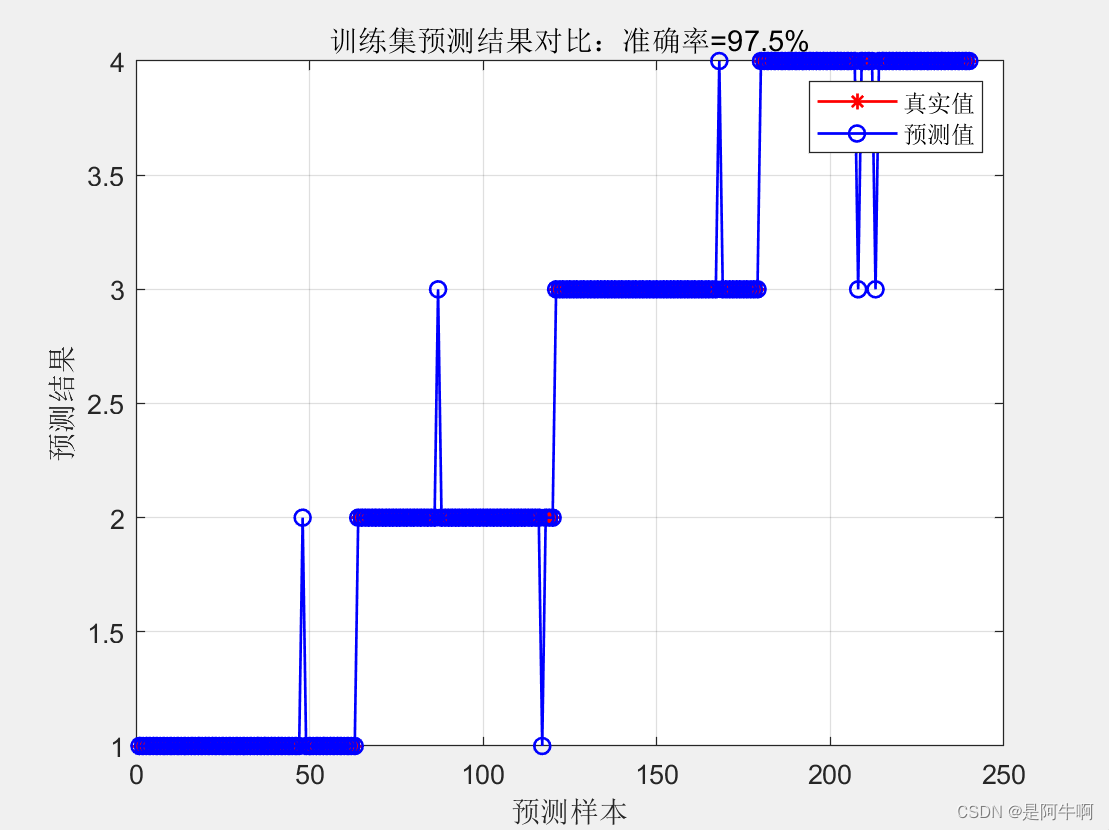
准确率反映了模型预测正确的样本占总样本数的比例。
结果可视化
使用plot函数绘制预测值和真实值的对比图,以及使用title, xlabel, ylabel函数设置图像的标题和坐标轴标签。使用legend添加图例,以grid添加网格线增强可读性。
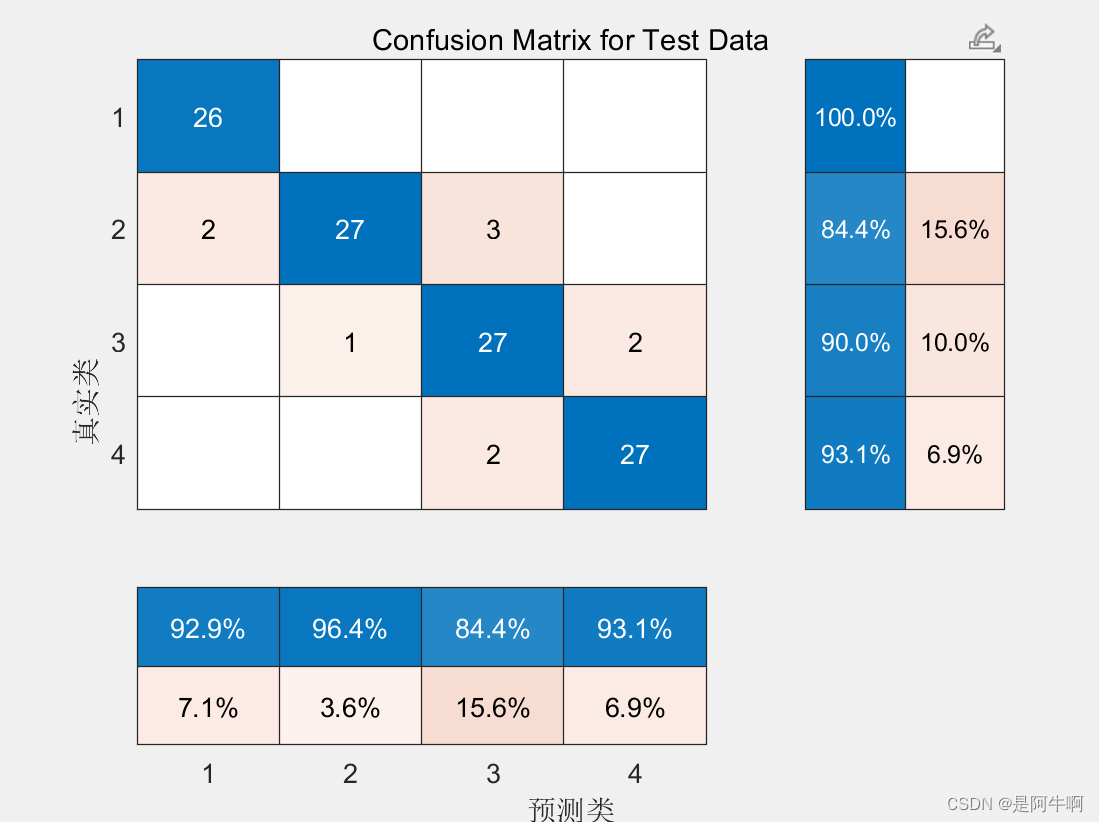
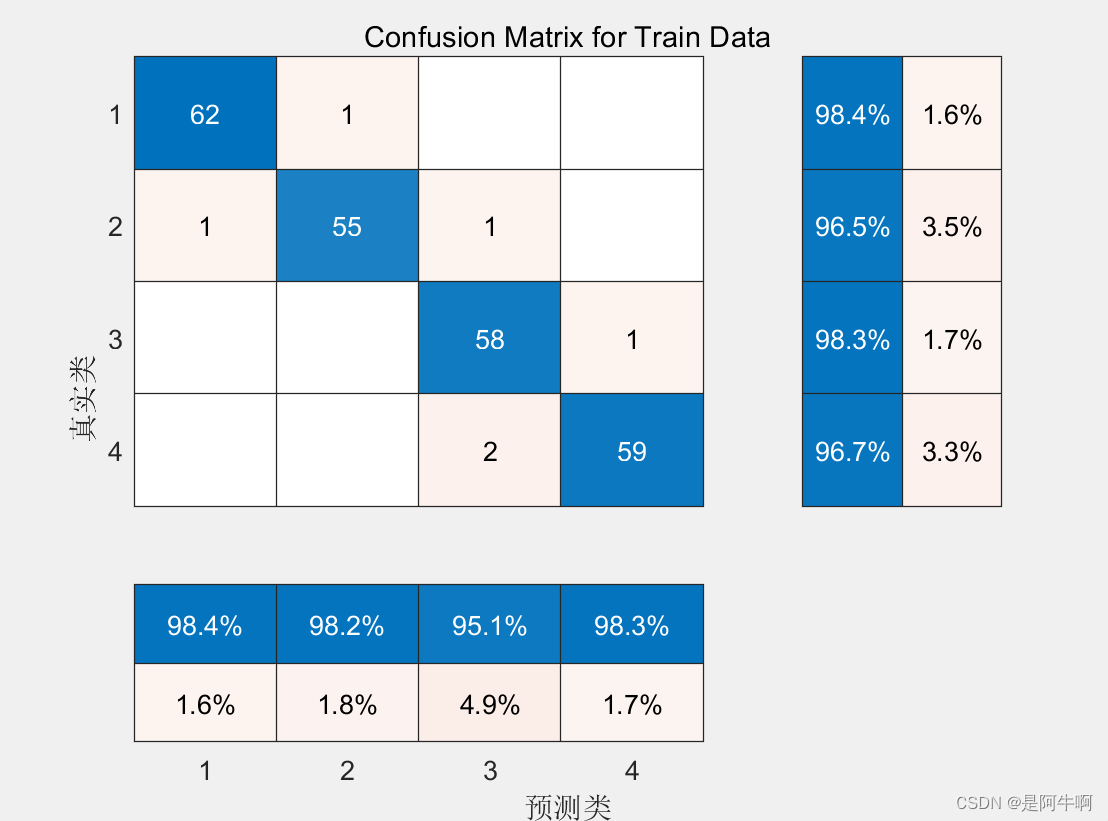
混淆矩阵
这部分代码生成了混淆矩阵的可视化,通常在分类问题中更为常见。混淆矩阵显示了模型在不同类别上的表现,包括真阳性、假阳性、真阴性和假阴性的数目。
confusionMatrix.Title = 'Confusion Matrix for Train Data';
confusionMatrix.ColumnSummary = 'column-normalized';
confusionMatrix.RowSummary = 'row-normalized';
以上就是整个MATLAB脚本的详细解释。需要注意的是,程序将回归问题处理为了分类问题。具体如何处理,取决于原始数据集以及实际问题的需求。在使用之前,可能需要根据具体场景对代码做一些调整。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









