







第二门课 第一周(改善深层神经网络:超参数调试、正则化以及优化)
一、训练,验证,测试集(Train / Dev / Test sets)
1、数据集的划分:在机器学习发展的小数据量时代,常见做法是将所有数据三七分,就是人们常说的 70% 验证集,30%测试集,如果没有明确设置验证集,也可以按照 60%训练,20%验证和 20%测 试集来划分。这是前几年机器学习领域普遍认可的最好的实践方法。
数据集规模相对较小,适用传统的划分比例,数据集规模较大的,验证集和测试集要小于数据总 量的 20%或 10%。
2、验证集的目的就是验证不同的算法,检验哪种算法更有效。
3、测试集的目的是对最终所选定的神经网络系统做出无偏估计,如果不需要无偏估计,也可以不设置测试集。
对于一个判断是否为猫的例子,训练集可能是从网络上抓下来的图片(图片分辨率很高,很专业,后期制 作精良),而验证集和测试集是用户上传的图片(随意拍摄的,像素低,比较模糊),因此最好确保验证集和测试集的数据来自同一分布。
二、偏差,方差(Bias /Variance)
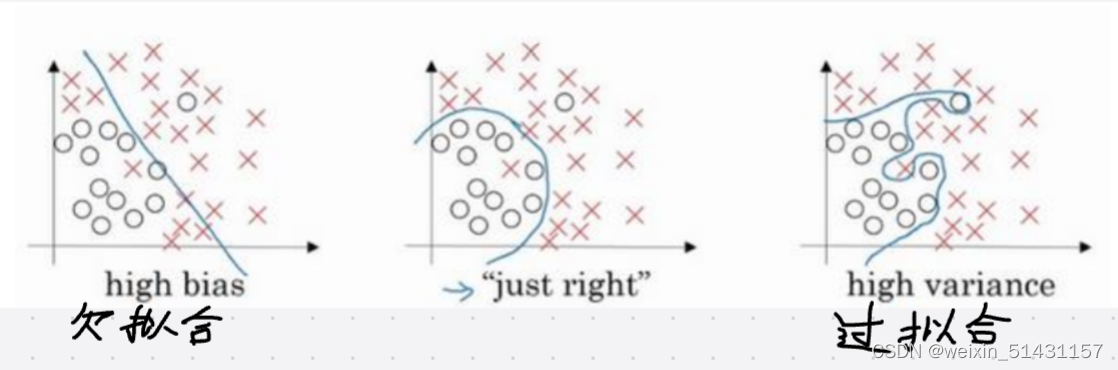
1、欠拟合现象:是指在训练集上表现得不好,存在高偏差。
2、过拟合现象:是指在验证集上的表现比在训练集上相差较大,存在高方差。
通过查看训练集误差和验证集误差,我们便可以诊断算法是否具有高方差。
3、高方差解决方法:如果方差高,最好的解决办法就是采用更多数据;此外还可通过正则化来解决,是一种非常 实用的减少方差的方法,正则化时会出现偏差方差权衡问题,偏差可能略有增加,如果网络 足够大,增幅通常不会太高。
(只要正则适度,通常构建一个更大的网络,便可以在不影响方差的同时减少偏差;采用更多数据,通常可以在不过多影响偏差的同时减少方差。)
三、正则化
1、不使用正则化
第0次迭代,成本值为:0.6557412523481002
第10000次迭代,成本值为:0.16329987525724213
第20000次迭代,成本值为:0.13851642423245572
训练集:
Accuracy: 0.9478672985781991
测试集:
Accuracy: 0.915
由分割曲线可见有一点过拟合
2、L1正则化是指权值向量w 中各个元素的绝对值之和(数值分析向量的一范数),但L1正则化会让权重向量在最优化的过程中变得稀疏(即非常接近0),故很少使用。
3、L2正则化是指权值向量w 中各个元素的平方和然后再求平方根(数值分析向量的二范数),L2正则化中的权重向量大多是分散的小数字。
正则化参数𝜆(在python中为避免冲突用lambd表示)
第0次迭代,成本值为:0.6974484493131264
第10000次迭代,成本值为:0.2684918873282239
第20000次迭代,成本值为:0.2680916337127301
使用正则化,训练集:
Accuracy: 0.9383886255924171
使用正则化,测试集:
Accuracy: 0.93
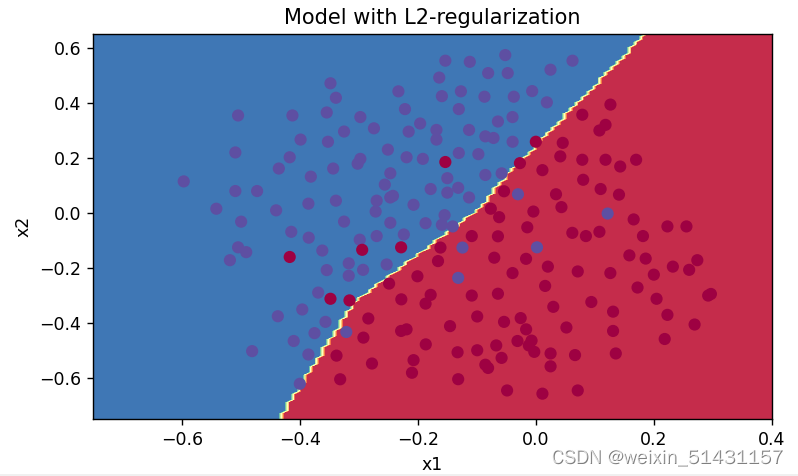
由分割曲线可知,边界变得光滑,有效地减小过拟合。
L2正则化也称为权重衰减原因?

4、dropout(随机失活) 正则化
dropout 会遍历网络的每一层,并设置消除神经网络中节点的概率(将keep_prob设置为小于1的值)。
第10000次迭代,成本值为:0.0610169865749056
第20000次迭代,成本值为:0.060582435798513114
使用随机删除节点,训练集:
Accuracy: 0.9289099526066351
使用随机删除节点,测试集:
Accuracy: 0.95

可见测试集准确率有所提高,随机失活可以有效地减少过拟合。
四、归一化输入
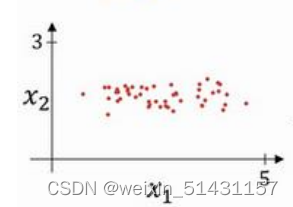

左图输入特征x1与x2若不进行归一化,则代价函数会变得和右图一般扁长,在寻找最低点时弯弯绕绕(需迭代次数较多)

1、零均值化(使特征均值为0)

2、归一化方差

类似于标准正态分布(均值为零,方差为1),使输入特征在一个相似范围内。
归一化后的损失函数:
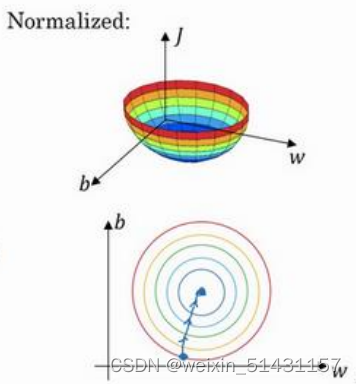
优点:1、迭代至最低点次数更少
2、可以减少梯度爆炸和梯度消失
五、初始化参数
参数W和b的初始化,有三种初始化的方式(初始化为零、随机初始化、抑梯度异常初始化)
1、初始化为零(将W和b都初始化为零)
parameters["W" + str(l)] = np.zeros((layers_dims[l],layers_dims[l-1]))
parameters["b" + str(l)] = np.zeros((layers_dims[l],1))性能非常差,模型没有进行学习,代价函数没有发生变化。
通常来说,零初始化都会导致神经网络无法打破对称性,最终导致的结果就是无论网络有多少层,最终只能得到和Logistic函数相同的效果。
2、随机初始化(W随机初始化,b初始化为0)
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * 10
parameters['b' + str(l)] = np.zeros((layers_dims[l], 1))当学习率为0.01时,迭代次数为10000时,损失值最小降至0.39左右(下面左图);
2.1进一步提高迭代次数至100000时,损失值最低降至0.35,且在60000次左右就趋于收敛(下面右图)。
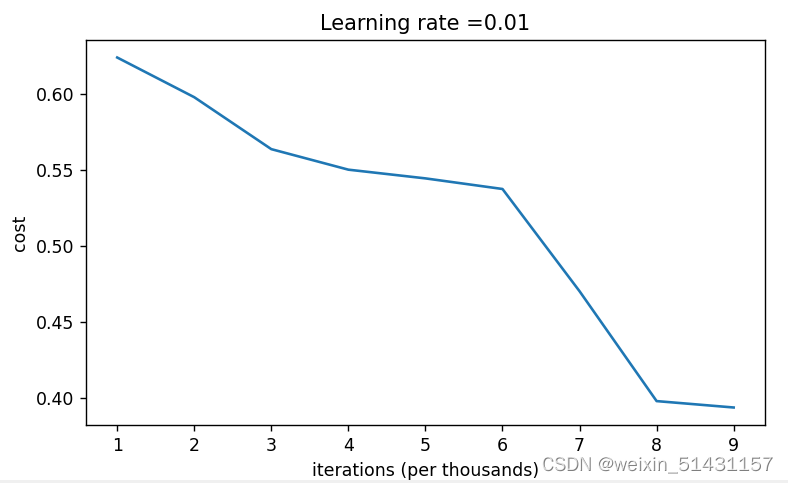
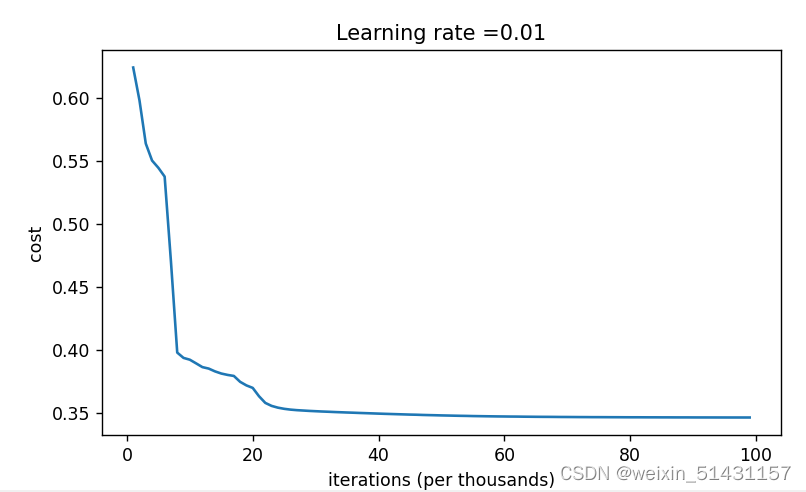
思考是否可以通过增大学习率来降低损失值呢?
2.2对此,将学习率提升至0.5,发现损失值更高,通过增加迭代次数发现收敛速度更快。
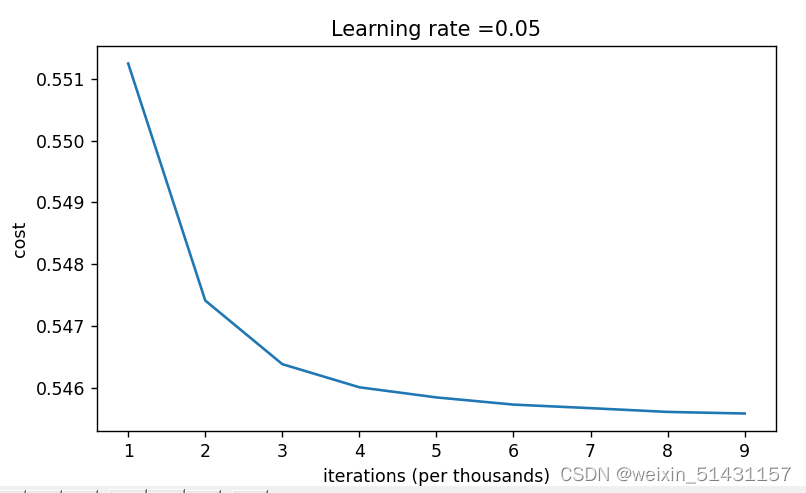
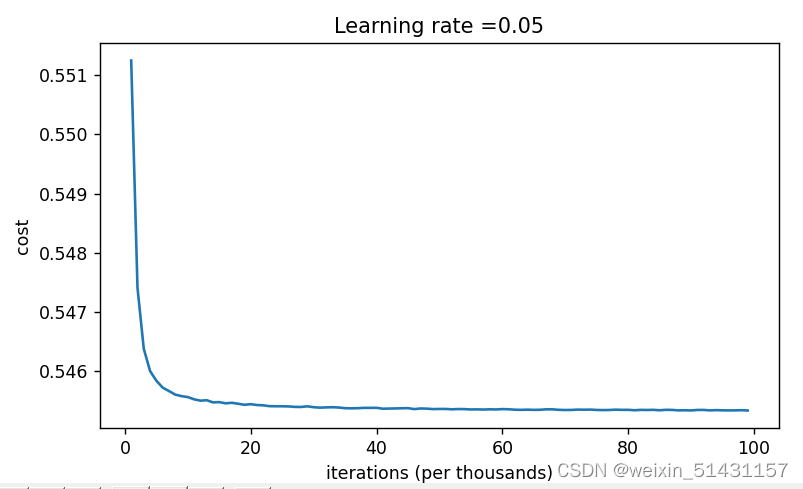
分析:提高学习率只是提高了梯度下降的速度,使损失函数更快地收敛至最低点(故学习率为0.05更快收敛),这样做不但最终不能降低损失值,反而提升了损失值,效果更差。
2.3 为此验证降低学习率是否会对损失值产生影响?

实验发现一开始出现了损失值大于一的现象,最后收敛至0.64。
2.4对此回顾最开始随机初始化W参数时,参数初始化的值是否太大?
对此减小初始化的值
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * 10 #原先初始化的值
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) #现缩小十倍
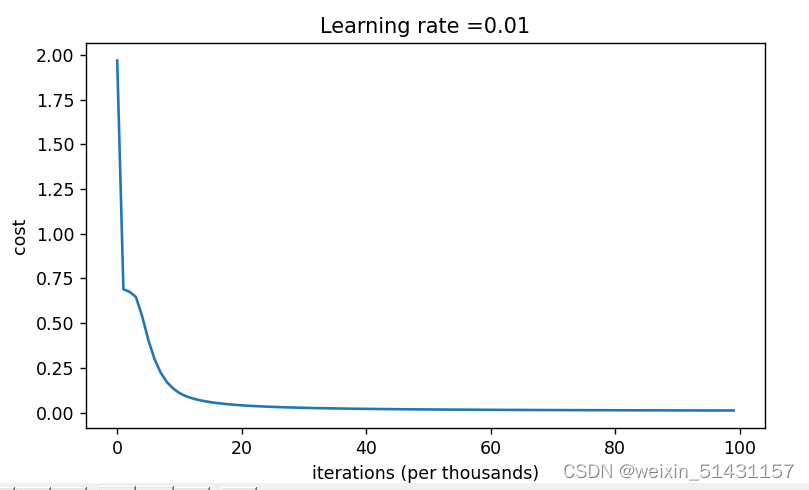
实验发现损失值快速下降,最终损失值几乎等于0,效果非常好
总结:随机初始化参数(W随机初始化,b初始化为0)的方式若是发现损失值太大,考虑增大迭代次数,看最终收敛值,若还是太大,那么可以考虑是否参数W初始化的太大,适当的进行调整。
3、抑梯度异常初始化
使用更小的参数值来初始化
根据以往经验,参数W随机初始化需乘以一个变量(这样做将参数限定在了一个很小的范围)
tanh激活函数:
Relu激活函数:
式中:为上一层神经元数量(上一层维度)
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * np.sqrt(2 / layers_dims[l - 1])
parameters['b' + str(l)] = np.zeros((layers_dims[l], 1))实验:
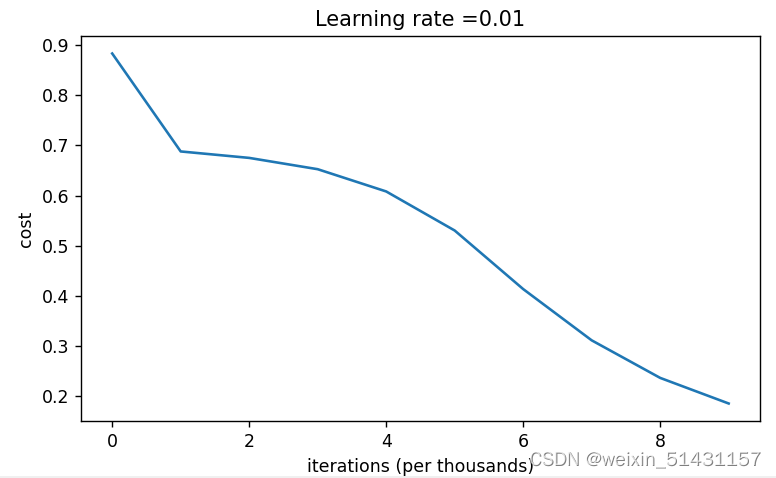

结果发现损失值最终收敛接近于0,效果非常好。
思考:若将激活函数改变为tanh时会发生什么?
总结:抑梯度异常初始化相比起随机初始化方法更优秀,因为不用担心初始化参数W太大或太小,最终损失函数的结果表现的很好















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









