






概要
模型部署时会涉及到非极大值抑制、尺度的变换、不仅带来部署上的不便,更是会影响到检测的速度,因此本文带来一种基于yolov8模型端到端部署的解决方案,即通过将NMS操作与模型的输出进行合并,并导出为onnx。使得最终模型的输出就是最终的目标,勿需进行繁杂的后处理,同时由于onnx的加速,使得推理速度进一步得到提高。并将实现的技术源码进行开源。
1.模型导入

将yolov8模型加载进来,可直接利用原生的yolov8模型加载函数
2. 设置输出图片的大小
设置输入图片的大小为模型导出onnx格式做准备
3.模型的兼容性设置
替换模型卷积里的激活函数,使得模型转换onnx兼容性提高
4.添加端到端NMS操作
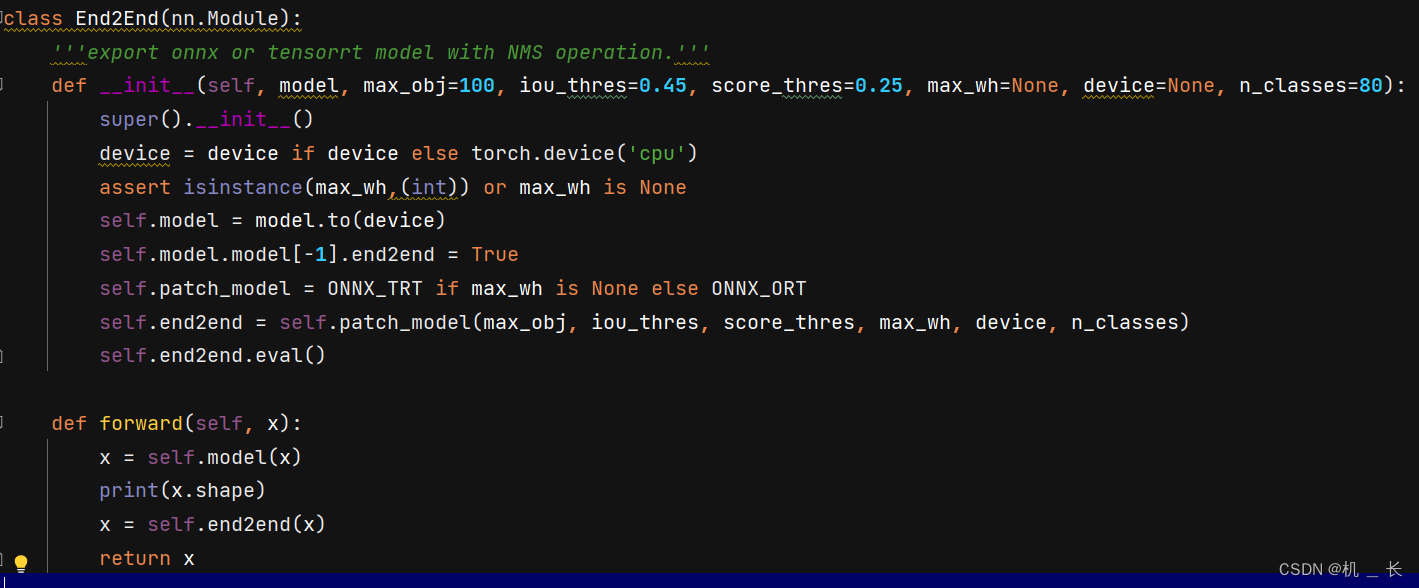
定义一个新的 End2End 模型如下图,将模型和NMS操作拼接到一起,在输出一个新的能实现端到端检测的新模型,其中
5. 将端到端模型导出为onnx
将修改后的端到端模型以及开头设置的图片,输入模型转换函数。
6. 模型导出指令
python export.py --weights last.pt --grid --end2end --simplify --topk-all 100 --iou-thres 0.50 --conf-thres 0.30 --img-size 640 640 --max-wh 640 --device 0
点个关注私信我发源码哦















 99
99











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









