







 超级会员免费看
超级会员免费看
1.知识蒸馏的原理
在目标检测中,知识蒸馏的原理主要是利用教师模型(通常是大型的深度神经网络)的丰富知识来指导学生模型(轻量级的神经网络)的学习过程。通过蒸馏,学生模型能够在保持较高性能的同时,减小模型的复杂度和计算成本。
知识蒸馏实现的方式有多种,但核心目标是将教师模型学习到的知识迁移到学生中去(通常是通过各种损失函数进行实现)。
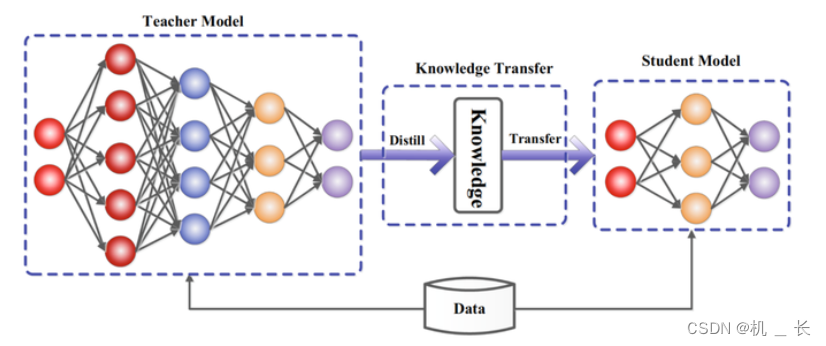
本项目支持yolov8检测、分割、关键点任务的知识蒸馏,并对蒸馏代码进行详解,比较容易上手。蒸馏方式多种,支持 logit和 feature-based蒸馏以及在线蒸馏。:
2.logit 蒸馏原理
Logit蒸馏原理主要基于深度学习中的知识迁移技术,特别是在模型压缩和加速领域。其核心思想是利用大型、复杂的教师模型(Teacher Model)的logits(逻辑层的原始输出得分)来指导小型、轻量的学生模型(Student Model)的学习。
Logits是教师模型在做出最终决策之前的原始得分,这些得分在数值上表示了模型对每个类别的预测置信度。相较于最

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 6319
6319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









