







特征工程
1、为什么要对数值类型的特征做归一化?
为了消除数据特征之间的量纲影响。
常用方法:
(1)线性函数归一化: X n o r m = ( X − X m i n ) / ( X m a x − X m i n ) X_{norm}=(X-X_{min})/(X_{max}-X_{min}) Xnorm=(X−Xmin)/(Xmax−Xmin)
特点:将结果映射到[0,1]范围,实现对原始数据的等比缩放
(2)零均值归一化: z = ( x − μ ) / σ z=(x-\mu)/\sigma z=(x−μ)/σ
特点:将原始数据映射到均值为0、标准差为1的分布上
- 学习速率相同时,未归一化的数据不同维度更新速度不同,需要较多迭代才能得到最优解
- 而归一化处理后,不同维度更新速度一致,容易更快的通过梯度下降找到最低点
- 实际应用中,通过梯度下降法求解的模型通常需要归一化,包括线性回归、逻辑回归、支持向量机、神经网络等模型。对于决策树模型并不适用,信息增益比与特征是否经过归一化无关
2、怎样处理类别型特征?
(1)序号编码:常用于有序类别
(2)独热编码:常用于无需类别
- A型血(1,0,0,0);B型血(0,1,0,0);。。。
- 类别较多时存在问题:①使用稀疏向量(如独热)可以有效节省空间;②配合特征选择来降低维度。高维特征可能导致:K近邻,难以衡量两点间的距离;逻辑回归,参数数量会随着维度增高而增加,容易导致过拟合;通常只有部分维度对分类、预测有帮助
(3)二进制编码
- 先给每个类别赋予ID,然后转化成二进制编码
- 维数少于独热编码,节省了存储空间
3、什么是组合特征?如何处理高维组合特征?
- 为了提高复杂关系的拟合能力,在特征工程中常会把一阶离散特征两两组合,构成高阶组合特征。
- 如果类别数量过多,组合特征会导致参数规模过大。可以尝试将两个特征分别降维
4、怎样有效找到组合特征?
基于决策树的特征组合寻找方法:
每一条从根节点到叶节点的路径都可以看成是一种特征组合的方式
5、有哪些文本表示模型?它们的优缺点?
词袋模型
将每篇文章堪称一袋子词,忽略每个词出现的顺序
常用TF-IDF: I D F ( t ) = l o g ( ( 文 章 总 数 ) / ( 包 含 单 词 t 的 文 章 总 数 + 1 ) ) IDF(t)=log((文章总数)/(包含单词t的文章总数+1)) IDF(t)=log((文章总数)/(包含单词t的文章总数+1))
对文章进行单词级别划分有时并不合理,可将连续出现的n个词组成的词组作为一个单独特征放到向量表示中去,构成N-gram模型
同一个词可能有多种词性变化,却有相似含义,可对单词进行词干抽取(word stemming),将不同词性的单词统一为同一词干的形式
主题模型
从文本库中发现有代表性的主题,得到每个主题上词的分布特性,计算出每篇文章的主题分布
词嵌入与深度学习模型
将每个词都映射成低维空间上的一个稠密向量
6、word2vec如何工作?它和LDA有什么区别与联系?
CBOW:根据上下文预测当前词的生成概率
skip-gram:根据当前词预测上下文各词的生成概率
输入层:独热编码
隐藏层:K个隐含单元由N维输入向量和N*K维权重矩阵计算得到。在CBOW中,还需求和各个输入词计算出的隐含单元
输出层:K维隐藏层向量和K*N维权重矩阵计算得到。softmax激活函数,计算出每个单词的生成概率
训练权重:反向传播算法,每次迭代将权重沿梯度更优的方向进行一小步更新
softmax存在归一化项,使得迭代过程慢,由此产生hierarchical softmax和negative sampling
模型的改进:
- 把常见词组作为一个单词
- 少采样常见词,出现概率高就有越高的概率被扔掉
- 负采样,每个训练样本只更新模型中一小部分权重(真实的正例+少数负例)(更常出现的词,更容易被选为负例
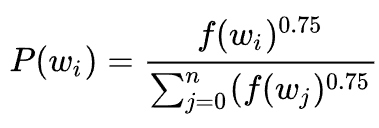
- 层次softmax:利用哈夫曼树结构,为每个词进行01编码。定义从根节点开始,每次经过中间节点,做二分类任务,不对词进行向量学习,而是对中间节点进行向量学习,每个叶子节点可通过路径中经过的中间节点去表示
LDA是利用文档中单词的共现关系来对单词按主题聚类,也可以理解为对“文档-单词”矩阵进行分解,得到“文档-主题”和“主题-单词”两个概率分布。
word2Vec是对“上下文-单词”矩阵进行学习,上下文由周围几个单词组成。
7、图像训练数据不足会带来什么问题?如何缓解?
主要问题:过拟合
缓解:
(1)基于模型。简化模型(如将非线性模型简化成线性模型)、添加约束项以缩小假设空间(如L1、L2正则)、集成学习、Dropout超参数等
(2)基于数据。数据扩充
直接在图像空间进行变换:
- 一定程度内的随机旋转、平移、缩放、裁剪、填充、左右翻转等
- 对图像中的像素添加噪声扰动,如椒盐噪声、高斯白噪声等
- 颜色变换。在图像的RGB颜色空间上进行主成分分析,得到3个主成分的特征向量和特征值,在每个像素的RGB值上添加增量
- 改变图像亮度、清晰度、对比度、锐度等
对图像进行特征提取,在图像特征空间内进行变换,利用通用数据扩充或上采样技术:
- SMOTE算法
使用生成模型合成新样本:
- 生成对抗网络
(3)借助已有的其它模型或数据进行迁移学习















 3312
3312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









