







强化学习的直觉
强化学习的思想借鉴了心理学、神经科学领域,即希望智能体(agent)像人一样,通过不断与外界进行交互,作用于环境,并得到环境的反馈,根据奖励和惩罚来调整自己的策略,不断修炼,希望最终学到的策略得到的奖励能够最大化。
一般来说,一个科研思路都是从直觉开始的,但是怎么把直觉抽象出来,进行精确的数学表达,从而可以量化自己的直觉是很重要的。
经过之前科学家们的不断探索,总结出了一条适用于实现强化学习这个想法的数学框架,即马尔科夫决策过程(MDP)
马尔科夫决策过程(MDP)形式化强化学习的直觉
如何形式化强化学习这种思路的直觉呢?强化学习的目的是让智能体不断与环境进行交互,根据环境的反馈来调整自己的策略,马尔科夫决策过程是这样形式化上面这个过程的:
- 状态 S S S, 定义智能体当前所处的环境的状态
- 动作 A A A,定义智能体可能作用于环境的动作
- 奖励 R R R,定义智能体从环境中得到的反馈,如果是惩罚,奖励可以设置为负数
- 环境模型:状态转移概率 p ( s ′ ∣ s , a ) p(s'|s,a) p(s′∣s,a),智能体在状态 s s s下对环境执行动作 a a a,环境模型接收到动作 a a a后变为状态 s ′ s' s′的概率。奖励概率 p ( r ∣ s , a ) p(r|s,a) p(r∣s,a),智能体在状态 s s s下对环境执行动作 a a a,环境模型接收到动作 a a a后返回奖励为 r r r的概率。
- 马尔科夫性:智能体做出的决策只与当前状态有关,而与历史状态无关。 p ( s t + 1 ∣ a t + 1 , s t , . . . , a 0 ) = p ( s t + 1 ∣ a t + 1 , s t ) p(s_{t+1}|a_{t+1},s_t,...,a_0) = p(s_{t+1}|a_{t+1},s_t) p(st+1∣at+1,st,...,a0)=p(st+1∣at+1,st),马尔科夫性质可以加大简化问题求解的复杂度,极大地提高了学习的效率和效果。
贝尔曼公式可以衡量策略的好坏(策略评估)
强化学习的目的是求解最优策略,那么衡量最优策略的指标是什么呢?
就是奖励。智能体想要学习到最优的策略以得到最大的奖励。
假设现在智能体已经有了一个策略,从状态
s
1
s_1
s1出发,一直经过状态
s
2
s_2
s2,
s
3
s_3
s3,
.
.
.
...
...,
s
n
s_n
sn,每次到达一个状态会获得一个奖励,即获得
r
1
r_1
r1,
r
2
r_2
r2,
.
.
.
...
...,
r
n
r_n
rn,我们想要最大化奖励,即
r
1
+
r
2
+
.
.
.
+
r
n
r_1+r_2+...+r_n
r1+r2+...+rn要最大,一般我们会引入一个折扣因子
γ
\gamma
γ(0-1之间),最大化奖励的公式变成:
r
1
+
γ
r
2
+
γ
2
r
3
.
.
.
+
γ
n
−
1
r
n
r_1+\gamma r_2+\gamma^2 r_3...+\gamma^{n-1} r_n
r1+γr2+γ2r3...+γn−1rn,引入
γ
\gamma
γ有两个好处,第一个是这个级数会变得收敛,第二个是它可以平衡即时奖励和未来奖励的比重。
那给定一个策略,从任意状态出发一直执行策略到结束,都会得到这样一个求和的奖励链,那么这个奖励链的值越大,就说明当前状态越有价值,这样一个奖励链叫做return(回报),状态价值的定义就是从该状态出发一直到结束的回报的期望。
定义一个状态的回报为
G
t
G_t
Gt,则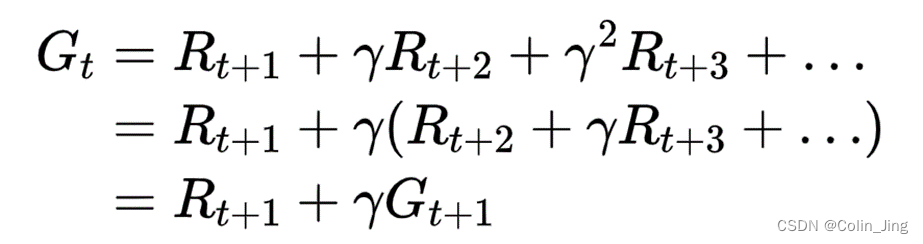
定义状态价值
v
π
(
s
)
v_\pi(s)
vπ(s):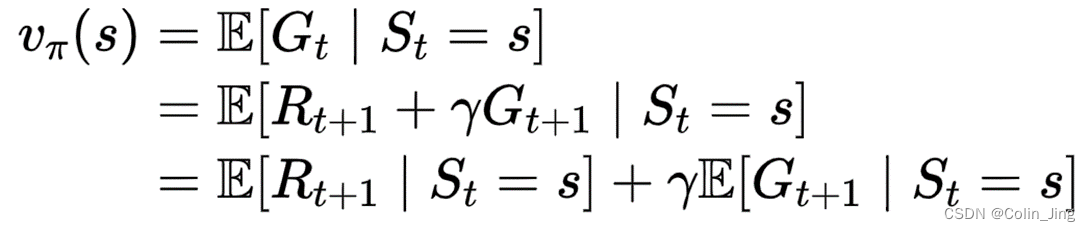
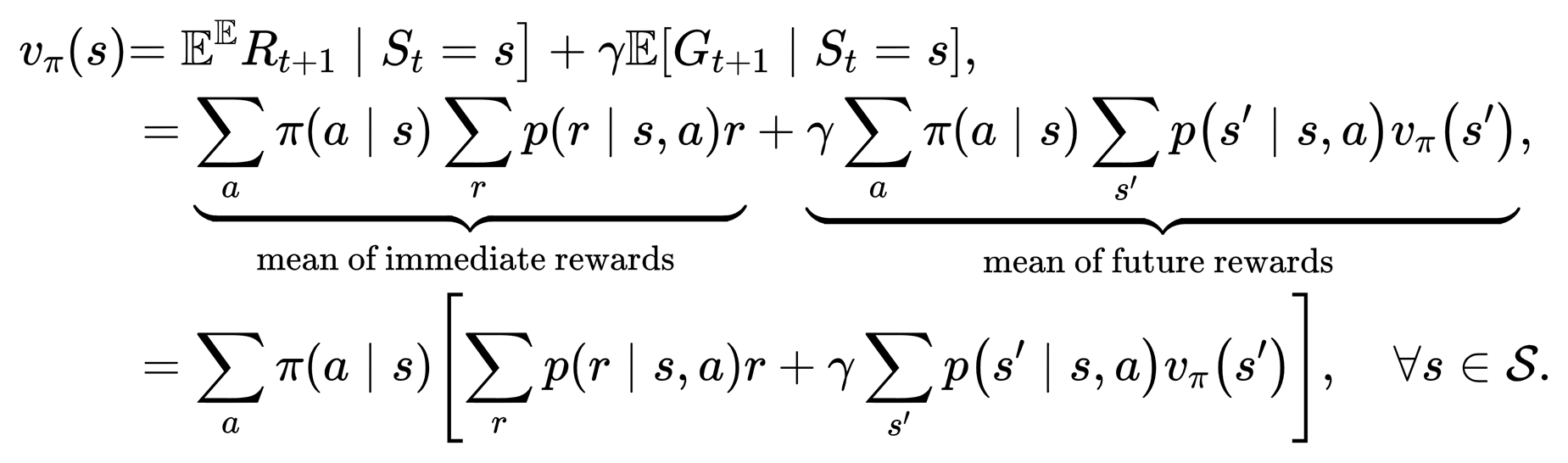
写成矩阵-向量的形式:
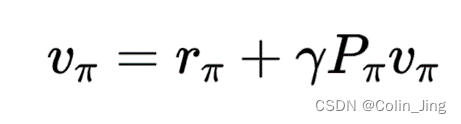
通过迭代求解即可求得所有的
v
π
v_\pi
vπ















 1720
1720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











