







情感图像内容分析:二十年回顾与新视角
摘要:
图像可以传达丰富的语义,并在观众中引发各种情绪。近年来,随着情绪智力的快速发展和视觉数据的爆炸式增长,人们对情感图像内容分析(AICA)进行了广泛的研究。在本次调查中,我们将全面回顾AICA在最近二十年的发展,特别是在三个主要挑战方面的最新方法——情感差距、感知主观性和标签噪音和缺失。我们首先介绍了在AICA中广泛使用的关键情绪表示模型,并描述了可用的数据集,用于通过定量比较标签噪声和数据集偏差来进行评估。然后,我们总结和比较了
(1)情感特征提取的代表性方法,包括手工和深层特征,
(2)主导情感识别、个性化情感预测、情感分布学习和从噪声数据或少量标签学习的学习方法,以及
(3)基于AICA的应用。
最后,我们讨论了一些挑战和未来的研究方向,如图像内容和上下文理解、群体情感聚类和观众-图像交互。
在《心灵的社会》(The Society of Mind)[1]一书中,明斯基(1970年图灵奖得主)声称,“问题不在于智能机器是否能有任何情感,而在于机器是否能在没有情感的情况下智能。”
重要性: 虽然情感在机器和人工智能中起着至关重要的作用,但人们对情感计算的关注远低于客观语义理解,比如计算机视觉中的对象分类。 人工智能的迅速发展在语义理解方面取得了显著的成功,并对情感互动提出了更高的要求。 例如,能够识别和表达情感的同伴机器人可以为人类,尤其是老年人和独生子女提供更和谐的陪伴。
原因1: 为了拥有类似人类的情感,机器首先应该了解人类是如何通过多种渠道表达情感的,比如语音、手势、面部表情和生理信号[2]。 虽然其他信号很容易被抑制或掩盖,但由交感神经系统控制的生理信号独立于人类的意志,因此提供了更可靠的信息。 然而,由于需要特殊类型的可穿戴传感器,因此捕捉精确的生理信号非常困难且不切实际。
原因2: 另一方面,随着近年来相机在移动设备上的便捷接入和社交网络(如Twitter、Flickr、微博)的广泛普及,人们习惯了用图片、视频和文本[3]在网上分享自己的经历和表达自己的观点。
选择: 识别大量多媒体数据中的情感内容为理解用户的行为和情感提供了另一种途径。
正如我们所知,“一幅画抵得上千言万语”,这表明图像可以传达丰富的语义。与现有的分析图像感知方面的研究不同,比如对象检测和语义分割,情感图像内容分析(AICA)侧重于在更高的层次上理解语义——认知层次,即理解观众中的图像可能诱发的情感,这更具挑战性。利用AICA自动推断人类的情绪状态,有助于评估他们的心理健康状况,发现情感异常,防止对自己乃至整个社会的极端行为。例如,在图1中,发布图像(b)的用户比发布图像(a)的用户更有可能产生负面情绪。

AICA对推断人类情绪状态的相关性和重要性示例。图像来自FI数据集[4]。
1.1主要目标和挑战
主要目标:
对于一个输入图像,AICA的主要目的是
(1)识别出能够诱导特定观众或大多数观众的情绪(根据心理学,情绪可以在不同的模型中表现出来,例如:分类或维度。详见第2节),
(2)分析图像中包含的哪些刺激唤起了这种情绪(例如特定的物体或颜色组合),
(3)将识别出的情绪应用到现实世界的不同应用中,以提高情商的能力。
挑战:
(1) 情感鸿沟。
与计算机视觉中的语义鸿沟类似,情感鸿沟是AICA面临的主要挑战之一,可以将其定义为“特征与用户感知信号所带来的预期情感状态缺乏重合”[5],如图2所示。
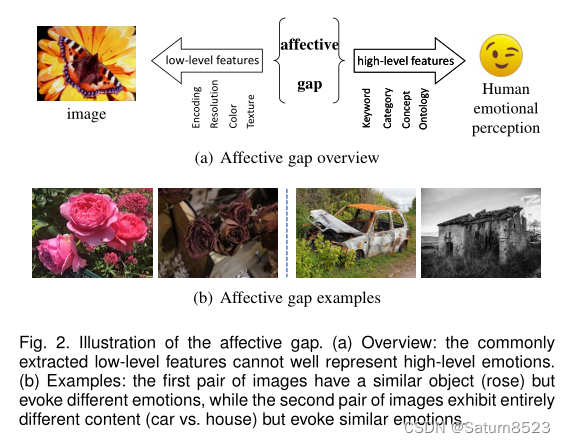
情感鸿沟的例证。(a) 概述:通常提取的低级特征不能很好地代表高级情感。(b) 示例:第一对图像具有相似的对象(rose),但引发不同的情绪,而第二对图像显示完全不同的内容(汽车与房屋),但引发相似的情绪。
为了弥合情感鸿沟,研究人员主要专注于提取能够更好地区分不同情感差异的区别性特征,包括Gabor[6]、Gist[7]、艺术元素[8]、艺术原则[9]、以及,以及形容词-名词对(ANP)[10]到像卷积神经网络(CNN)[11,4]和区域[12]这样的深层次的形容词-名词对。
基于不同的观看者可以对图像的感知情感达成一致的假设,这些AICA方法主要将图像分配为主导(平均)情感类别(DEC)。这个任务可以作为一个传统的单标签学习问题来执行。
除了提取视觉特征,合并可用的上下文信息也有助于AICA任务[13],如图3所示。 同一个图像在不同的语境下可能会引发不同的情绪。 例如,在图3(a)中,如果我们只看到孩子,我们可能会根据他的表情感到惊讶;但在孩子为庆祝生日而吹蜡烛的情况下,这更有可能让我们感到高兴。在图3(b)中,如果我们看到排球运动员哭泣,我们可能会感到悲伤;但如果对这张图片有评论的话, “十年后,我们终于赢了!”,我们,尤其是该队的业余排球运动员,可能会感到兴奋。

上下文信息在AICA中也起着重要作用。 (a) 没有和有详细场景背景的图像会唤起不同的情感(惊喜与快乐)。 (b) 文本语境也会影响同一图像的情感感知(悲伤与兴奋)。
(2) 知觉的主观性。
不同的观众可能对同一张图片有完全不同的情绪反应,这是由许多个人和语境因素造成的,如文化背景、个性和社会语境[14、15、16]。 例如,对于图4(a)中的“黑暗中的光”图像,对捕捉自然现象感兴趣的观众可能会兴奋地看到这种景象,而害怕雷电的观众可能会感到恐惧。 这一事实导致了所谓的主观感知问题。因此,对于这个高度主观的变量,仅仅预测DEC是不够的,因为它不能很好地反映不同观众之间的差异。
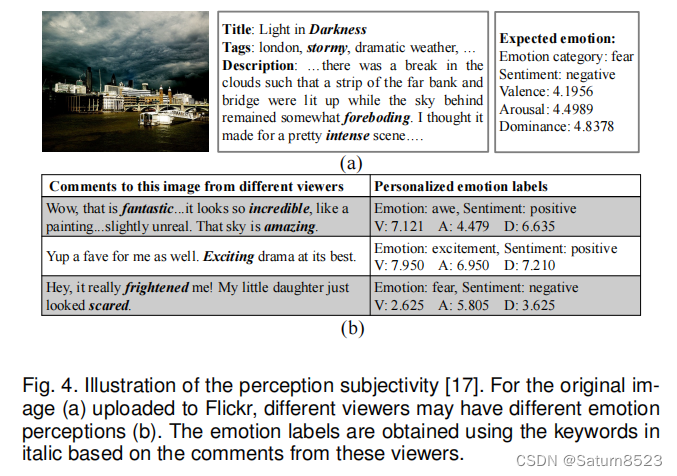
对知觉主观性的阐释[17]。 对于上传到Flickr的原始图像(a),不同的观众可能有不同的情绪感知(b)。 情感标签是根据这些观众的评论,使用斜体字的关键词获得的。
为了解决主观性问题,我们可以进行两种AICA任务[15]:对于每个观众,我们可以预测个性化的情绪感知;对于每个图像,我们可以指定多个情感标签。对于后者,我们可以采用多标签学习方法,将一幅图像与多个情感标签关联起来。然而,由于不同情绪标签的重要性或程度实际上是不平等的,因此情绪分布学习更有意义,其目的是了解每种情绪对图像的描述程度[16]。
(3)标签噪音和缺失。
最近基于深度学习的AICA方法,尤其是CNN,已经取得了令人鼓舞的结果。然而,训练这些模型需要大量的标签数据,这是非常昂贵和耗时的获取,不仅因为在ground-truth generation中的情感标签是高度不一致的,而且因为在一些情况下,如艺术作品,只有专家才能提供可靠的标签。在现实世界的应用程序中,可能只有很少甚至没有标记的情感数据。如何处理这种情况是非常值得研究的。无监督/弱监督学习和少数/零shot学习是两个有趣的方向。
一个可能的解决方案是利用无限量的网络图像和相关标签作为标签[19]。然而,这样的标签可能不完整且有噪音。图像可能与不相关或远程相关的标记相关联。 如何从有噪音的标签图像中学习是主要的挑战。 基于图像和文本之间的语义关联对视觉表示施加一些约束是一种直接的解决方案。 首先以无监督或半监督的方式学习文本模型和嵌入,然后对关键词标签进行去噪,有助于“清除”标签噪声。
此外,如果我们在一个领域(如抽象绘画)中有足够的标记数据,我们如何有效地将训练有素的模型转移到另一个未标记或标记稀疏的领域?由于存在域偏移或数据集偏差[20,21],直接迁移往往会导致性能较差,如图5所示。 具体而言,Panda等人[22]将AICA中的数据集偏差分为两类。 一个是正集偏差。由于源域中每个情感类别(如娱乐)的视觉概念缺乏多样性,基于此类数据学习的模型很容易记住其所有特质,并失去推广到目标域的能力。 另一个是负集偏差。源域中的其他数据集(例如来自除娱乐之外的其他类别的数据)不能很好地代表视觉世界的其他部分。
例如,目标域中的一些负样本与源域中的正样本相混淆。因此,学习过的分类器可能过于自信。 领域适应和领域泛化可能有助于解决这个问题。

域转移的图示。 (a) ArtPhoto[8]和FI[4]数据集中的图像有不同的风格:艺术风格和社交风格。 (b) 如果通过微调ResNet-101模型,在ArtPhoto和FI数据集上,训练数据集与测试数据集不同,则情绪分类性能(%)显著下降[18]。
1.2本次调查的组织
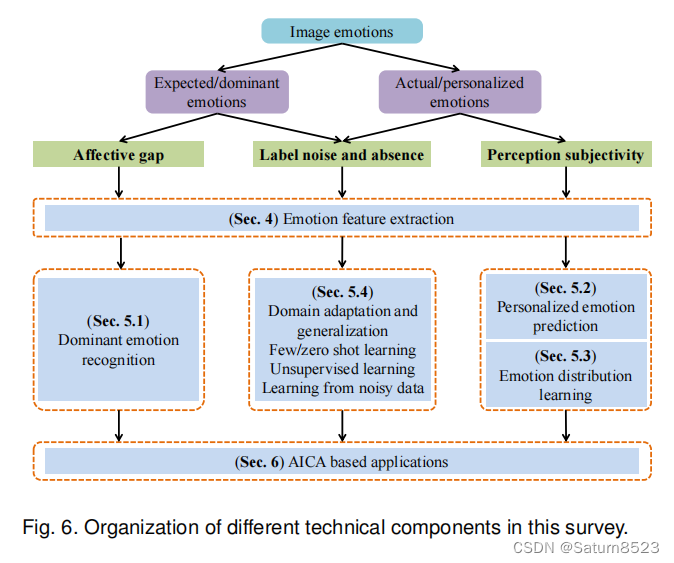
在本次调查中,我们集中回顾了目前在AICA的最新研究方法,并概述了未来的研究趋势。 首先,我们介绍1.3节的简史,并与1.4节的其他相关主题进行比较。 其次,我们在第二节中描述了广泛使用的情感表达模型。 第三,在第3节中,我们总结了用于进行AICA评估的可用数据集,并定量比较标签噪声和数据集偏差。 第四,基于1.1节的主要目标和挑战,我们总结并比较了在情感特征提取、学习方法(主要情感识别、个性化情感预测、情感分布学习、噪声数据或少数标签学习)方面的代表性方法,和章节4、5、6中基于AICA的应用,如图6所示。 最后,我们在第7节讨论了可能的研究方向。
1.3简史
-
情感计算。
在情感计算被称为这一术语之前,早期的第一项工作包括1978年申请的一项用于确定说话人语音情感的分析仪专利[23],1990年发表的关于合成语音中情感产生的科学论文[24],或1992年发表的神经网络面部表情识别[25]。自从明斯基提出智能机器的情绪识别问题[1]以来,情绪相关的研究备受关注,比如情绪智力的定义[26]。1997年,皮卡德首次提出了情感计算的概念[27]:“情感计算是指与情感或其他情感现象相关、源自或有意影响情感或其他情感现象的计算”。
一些有影响的事件包括:2005第一届IEEE和AAAI的情感计算和智能交互国际会议(ACII),2007是情感计算促进协会(AAAC)成立的基础(最初命名为HuMAIN协会),2009年在Interspeech举办了第一次公开的“情感挑战”,2010年推出了IEEE情感计算交易(TAFFC),2011年举办了第一次国际视听情感挑战与研讨会(AVEC),2014年在ACM多媒体中提出了多媒体领域的情感和社会信号,2018年第一届亚洲ACII等。 -
情感图像内容分析。
AICA的发展始于心理学和行为研究,如国际情感图片系统(IAPS)[28,29],以研究视觉刺激和情绪之间的关系。
最早的情感识别方法之一是基于低级整体Wiccest和Gabor特征[6]。
从那时起,设计了几个具有代表性的手工特征,例如低级艺术元素[8]、中级艺术原则[9]和高级形容词-名词对(ANP)[10]。
2014年,通过CNN进行迁移学习,通过大规模数据预训练参数[30]。
为了应对主观性挑战,我们考虑了个性化情绪预测[31,15]和情绪分布学习[14,32,33,34]。
最近,针对标签缺失挑战研究了领域适应[35,36,37]和零shot学习[38]。
图7总结了通用情感计算和AICA中具有代表性的里程碑。
1.4与其他相关主题的比较
-
与其他模式的情感计算进行比较。
情感内容分析也在其他模式中得到了广泛研究,如文本[39,40]、语音声学[41,42]和语言学[43]、音乐[44,45]、声音[46]、面部表情[47,48,49,50]、视频[51,52]、生理信号[53,54,55]和多模式数据[56,57,58,59]。 虽然所采用的情绪模型和学习方法相似,但图像的情感计算与其他形式有明显的区别,尤其是提取的情绪特征。 虽然对其他模式的调查进行得很好,但对非洲联盟的调查却不全面。 由于图像是表达情感的重要渠道,我们相信对AICA的深入分析可以促进情感计算的发展。 我们的IJCAI 2018会议论文[60]之前介绍了这个调查的一个初步版本。 与会议论文相比,该期刊版本在以下五个方面进行了广泛的改进。 首先,详细的挑战和简短的历史被纳入。 其次,我们总结和比较了在情感模型、可用数据集、情感特征和学习方法方面比较有代表性的作品。 第三,我们进行了大量的实验来公平地比较不同的AICA方法的有效性。 第四,我们添加了一些基于AICA的应用程序。 最后,讨论了未来的研究方向。 -
与计算机视觉的比较。
AICA的任务通常由三个步骤组成:人类注释、视觉特征提取和学习视觉特征与感知情绪之间的映射[61]。 虽然这三个步骤似乎与计算机视觉(CV,第三个步骤是视觉特征和图像标签(如对象)之间的映射学习)非常相似,但AICA和CV之间存在显著差异。 以对象分类和情感分类为例。 (1) 即使在对象分类中弥合了语义鸿沟,仍然存在情感鸿沟。 例如,一张画着一只可爱的狗的图片和一张画着一只吠叫的狗的图片可以唤起不同的情绪。 (2) 对象是一个客观的概念(可爱的狗和吠叫的狗都是狗),而情感是一个相对主观的概念(两张图片中的快乐和恐惧)。 (3) 相应地,对象分类属于图像的感知方面,而AICA侧重于认知层面。 对象分类主要由CV社区研究,而AICA是一项跨学科的任务,需要心理学、认知科学、多媒体和机器学习等。
2.心理学的情绪模型
在心理学中,有几种不同的情感计算相关概念,如emotion、affect、mood和sentiment。 讨论这些概念的差异或相关性超出了本次调查的范围。有兴趣的读者可以参考[67]了解更多细节。 评价理论以解释情感体验的发展而闻名[68]。 它解释了个体对同一刺激的情绪反应的可变性。 根据Ortony、Clore和 Collins(OCC)模型[69],情绪的产生源于对事件、因素和对象的刺激进行认知评估或评估。 个体对刺激的实际感知和解释方式决定了情绪的产生方式。
心理学家主要采用两种情绪表征模型来测量情绪:范畴情绪状态(CES)和维度情绪空间(DES),如表1所示。
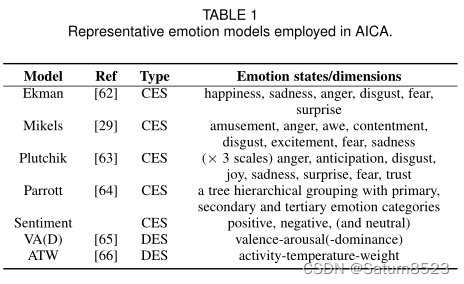
CES模型将情绪分为几个基本类别。
最简单的CES模型是二元positive和negative(极性)[70,55]。 在这种情况下,“emotion”通常被称为“sentiment”,有时也包括neutral中性情绪。 由于sentiment过于粗糙,因此设计了一些相对精细的emotion情绪模型, 例如Ekman的六种情绪(愤怒anger、厌恶disgust、恐惧fear、幸福happiness、悲伤sadness、惊讶surprise)[62]和 Mikels的八种情绪(娱乐amusement、愤怒anger、敬畏awe、满足contentment、厌恶disgust、兴奋excitement、恐惧fear和悲伤sadness)[29]。
随着心理学理论的发展,分类情绪变得越来越多样化和精细化,比如考虑社会情绪[71]。 除了八种基本情绪类别(愤怒anger、预期anticipation、厌恶disgust、恐惧fear、喜悦joy、悲伤sadness、惊讶surprise、信任truse)之外,Plutchik[63]还将每种情绪分为三种强度,从而提供了一个更丰富的集合。 例如,快乐和恐惧的三种强度分别是狂喜ecstasy→快乐joy→宁静serenity与恐怖terror→害怕fearness→恐惧apprehension。
另一种代表性的CES模型是Parrott的树层次分组[64],它用一级、二级和三级类别来表示情绪。 例如,一个三级情感层次结构被设计成1级的两个基本类别(积极和消极),2级的六个类别(愤怒、恐惧、喜悦、爱、悲伤和惊讶),以及3级的25个细粒度的情感类别。 虽然CES模型易于用户理解,但有限的情感类别无法很好地反映情感的复杂性和微妙性。 此外,心理学家还没有就应该包括多少离散的情绪类别达成共识。
不同的是,DES模型使用连续的2D、3D或更高维笛卡尔空间来表示情绪,如valence-arousal-dominance效价-唤醒度-优势度(VAD)[65]和可能增加的强度、新颖性或其他,以及activity-temperature-weight活动-温度-权重[66]。
VAD是使用最广泛的DES模型[72],其中效价代表从积极到消极的愉悦感,唤醒度代表从兴奋到平静的情绪强度,优势度代表从受控到控制的控制程度。pleasure-arousal-dominance(PAD)愉悦度是指情感的正负属性,唤醒度是指个体的情感激活程度,优势度表示对情景和他人的控制程度。 在实践中,优势度很难测量,而且经常被忽略,这导致了常用的二维VA空间[5]。 理论上,每一种情感都可以表示为笛卡尔空间中的一个坐标点。然而,用户很难区分绝对连续值,这限制了DES模型的应用。
CES和DES之间的比较如表2所示。与CES相比,DES能够表示更细粒度和更全面的情感,这分别反映了它们在粒度和可描述性上的差异。此外,它们不是相互独立的,而是相互关联的。[73,74]研究了CES和DES之间的关系以及从一个到另一个的转换。例如,正配价与快乐状态有关,而负配价与悲伤或愤怒状态有关;放松状态与低觉醒有关,而愤怒与高觉醒有关。
例如,为了进一步区分愤怒和恐惧(两者都是负价,但高唤醒),一个人需要支配(愤怒高,但恐惧低)。
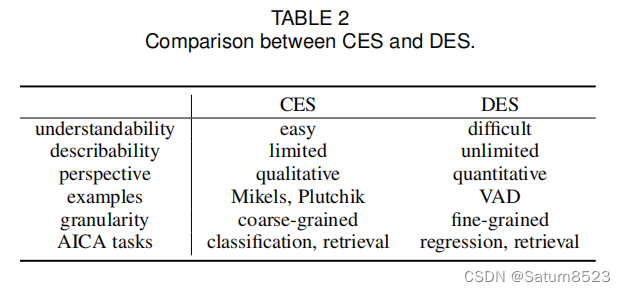
CES和DES主要用于分类和回归任务,分别具有离散和连续的情绪标签。
因此,所采用的学习模式是不同的。对于情感图像检索任务,两种模型都可以用于不同的情感距离测量(例如,对于CES,Mikels的情感轮[15],对于DES,使用欧氏距离)。如果我们将DES离散成几个常数值,我们也可以将其用于分类[66]。我们可以考虑通过排名为基础的标签减轻DEC(主导情感类别)理解困难。
另一个值得一提的相关概念是,对多媒体的反应可以是预期的、诱导的或感知的情绪。 预期情绪是多媒体创作者想要让人们感受到的情绪, 感知情绪是人们感受到的被表达的情绪, 而诱导/感受到的情绪是观众感受到的实际情绪。 本次调查的目的不是讨论各种情绪模型的差异或相关性,而是相信心理学和认知科学的成果有助于AICA任务。
3 数据集
在早期,情感数据集只包含心理学或艺术团体构建的小规模图像。 随着数字摄影和在线社交网络的发展,越来越多的大型数据集通过对发布在互联网上的图像进行抓取来创建。 我们在表3中总结了AICA的所有数据集。
3.1不同数据集的简要介绍
-
International Affective Picture System国际情感图片系统(IAPS)[28]是一个视觉情感刺激的图像数据集,用于心理学中情感和注意力的实验研究[28]。 该数据集包含1182幅具有不同内容或场景的纪实风格自然色图像,如肖像、婴儿、动物、风景等。约100名大学生参加了9分制的VAD评分。每个图像分数的平均值和标准差(STD)可以很容易地推导出来。 IAPS的子集A(IAPSa)[29]是从IAPS中收集的,通过描述离散的情感类别来描述图像。 具体来说,我们选择了203张负面图片和187张正面图片,然后由20名本科生参与者进行标记。据我们所知,这是第一个使用离散情感类别标记的情感图像数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 870
870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











