







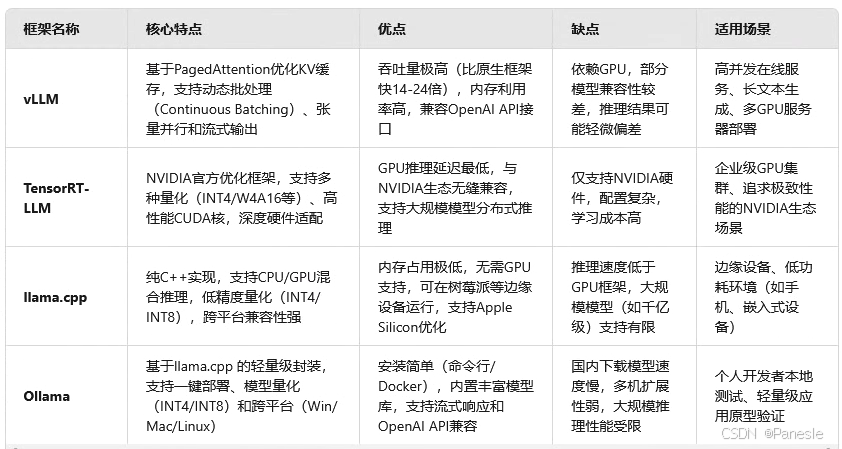
主流大模型加速推理框架的对比
补充说明:
性能与硬件权衡
vLLM 和 TensorRT-LLM 依赖GPU,适合高吞吐、低延迟的企业级场景;llama.cpp 和 Ollama 侧重CPU/轻量GPU支持,适合资源受限环境。
Ollama 在易用性上优于 llama.cpp ,但性能弱于后者;TensorRT-LLM 的硬件绑定特性使其在NVIDIA生态中无可替代。
量化与模型兼容性
TensorRT-LLM 和 llama.cpp 支持低至INT4的量化,显著降低显存占用;
vLLM 对多数开源模型兼容性较好,而 Ollama 依赖社区模型库,需手动扩展。
部署复杂度
Ollama 和 llama.cpp 适合快速部署,而 vLLM 和 TensorRT-LLM 需专业调优。

















 4045
4045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









