主流文本翻译模型的分类及对比分析:
一、传统翻译模型
基于规则的方法
原理:依赖人工编写的语法规则和词典进行词对词转换。
特点:准确性高但灵活性差,无法处理复杂句式和文化差异。
典型应用:早期机器翻译工具(如词典式翻译软件)。
统计机器翻译(SMT)
原理:通过分析双语语料库的统计规律生成翻译结果。
特点:相比规则方法更灵活,但依赖大量标注数据,对未登录词和上下文处理能力弱。
二、神经网络翻译模型
循环神经网络(RNN)
原理:通过序列建模逐词生成翻译结果。
特点:能捕捉上下文信息,但长距离依赖处理能力差,训练速度慢。
典型模型:早期谷歌神经机器翻译(GNMT)。
Transformer架构模型
原理:基于自注意力机制实现全局上下文建模。
特点:
优点:并行计算效率高,擅长处理长文本和复杂句式。
缺点:模型参数量大,训练资源消耗高。
典型模型:
GPT系列(如GPT-3.5、GPT-4):擅长生成流畅自然的翻译,支持多语言,但需注意专业术语准确性。
BERT:更注重双向语义理解,适合作为翻译模型的编码器。
三、大语言模型(LLM)驱动的翻译
通用大模型(如GPT-4、腾讯元宝)
优势:
支持多语言混合输入和跨模态翻译(如文本+图像)。
能结合上下文生成更自然的翻译,擅长处理文化差异和俚语。
在专业领域(如法律、医学)表现优于传统模型。
局限性:对实时性要求高的场景(如同声传译)仍有延迟问题。
垂直优化模型
典型代表:
Codex:专攻代码翻译,支持编程语言间的精准转换。
Whisper:专注于语音到文本的翻译,支持多语言语音识别。
特点:在特定领域表现突出,但通用性较弱。
四、场景专用模型
SVTR(场景文本识别模型)
特点:针对图像中的文本(如菜单、路牌)进行端到端识别与翻译,无需拆分视觉和序列模型,效率更高。
局限性:对低分辨率或复杂背景图像的处理能力有限。
多模态翻译模型
功能:结合图像、语音、文本综合翻译(如拍照翻译菜单)。
现状:大部分模型仍处于发展阶段,识别精度和翻译流畅度待提升。
五、主流模型横向对比
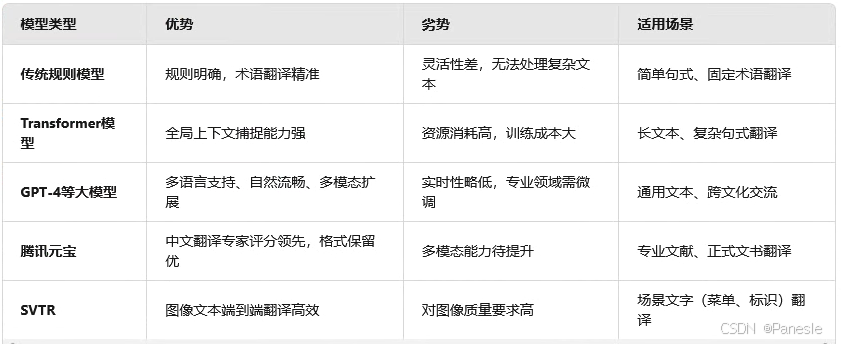
总结建议
日常通用翻译:优先选择GPT-4、腾讯元宝等大模型,平衡质量与效率。
专业领域需求:使用垂直优化模型(如Codex)或对大模型进行领域微调。
实时场景:可尝试讯飞星火、Kimi等同声传译优化模型。
图像文本翻译:SVTR或结合多模态工具(如GPT-4V)提升准确率。

























 2965
2965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









