







Nari Labs的Dia-1.6B模型详解
一、模型概述
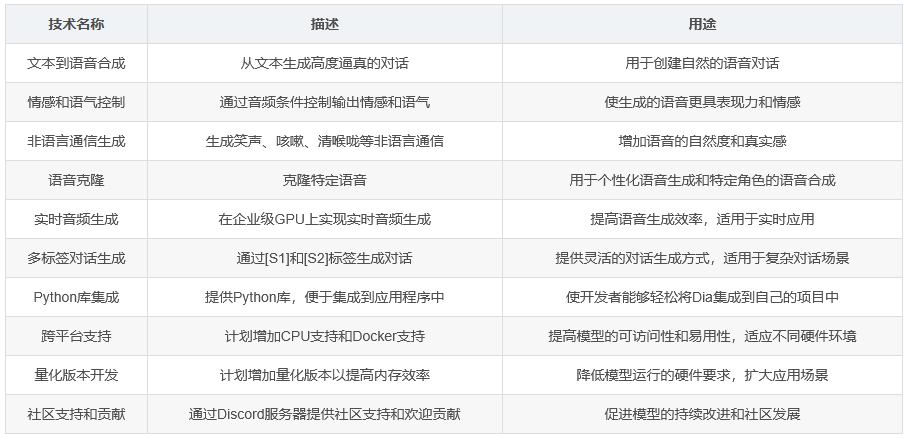
Dia是由Nari Labs开发的一个拥有1.6B参数的文本到语音模型。该模型能够直接从剧本生成高度逼真的对话,并且可以通过音频条件控制情感和语气。此外,Dia还可以生成非语言交流,如笑声、咳嗽、清喉咙等。目前,该模型仅支持英语生成。
二、访问与使用
Nari Labs为加速研究,提供了预训练模型检查点和推理代码的访问权限,模型权重托管在Hugging Face上。此外,还提供了一个演示页面,用于比较Dia模型与ElevenLabs Studio和Sesame CSM-1B的性能差异。
为了方便用户,Dia还有一个无需GPU的ZeroGPU空间可供使用。用户也可以加入Discord服务器,获取社区支持和新功能的访问权限。对于希望体验更大版本Dia的用户,可以加入等待列表以获得早期访问权限。
三、快速开始指南
提供了两种安装和运行Dia的方法:
- 使用uv命令:
git clone https://github.com/nari-labs/dia.git
cd dia && uv run app.py
- 创建虚拟环境并安装uv:
git clone https://github.com/nari-labs/dia.git
cd dia
python -m venv .venv
source .venv/bin/activate
pip install uv
uv run app.py
四、功能特性
(一)对话生成
Dia可以通过[S1]和[S2]标签生成对话。例如:
text = "[S1] Dia is an open weights text to dialogue model. [S2] You get full control over the output."
output = model.generate(text)
(二)非语言通信生成
模型能够生成诸如笑声、咳嗽等非语言通信。例如:
text = "[S1] Dia is an open weights text to dialogue model. (laughs) [S2] You get full control over the output."
output = model.generate(text)
(三)语音克隆
Dia支持语音克隆功能。用户可以在Hugging Face空间上传想要克隆的音频,并在脚本前放置其转录文本。确保转录文本遵循所需格式后,模型将仅输出脚本内容。
(四)Python库使用示例
import soundfile as sf
from dia.model import Dia
model = Dia.from_pretrained("nari-labs/Dia-1.6B")
text = "[S1] Dia is an open weights text to dialogue model. [S2] You get full control over the output."
output = model.generate(text)
sf.write("simple.mp3", output, 44100)
五、硬件要求与推理速度
Dia已在GPU上进行了测试(支持pytorch 2.0+和CUDA 12.6),目前尚未支持CPU。初次运行时,由于需要下载Descript Audio Codec,耗时较长。
在企业级GPU上,Dia能够实现实时音频生成。而在较旧的GPU上,推理速度会较慢。例如,在A4000 GPU上,Dia大约每秒生成40个token(86个token相当于1秒音频)。对于支持的GPU,torch.compile可以提高速度。
完整版本的Dia需要大约10GB的VRAM才能运行。未来计划增加量化版本以提高内存效率。
六、许可与免责声明
该项目遵循Apache License 2.0许可。严格禁止以下用途:
-
身份误用:未经许可,不得生成酷似真实个体的音频。
-
欺骗性内容:不得使用该模型生成误导性内容(例如假新闻)。
-
非法或恶意用途:不得将该模型用于非法活动或意图造成伤害的行为。
使用该模型即表示您同意遵守相关法律标准和道德责任。Nari Labs不对任何滥用行为负责,并坚决反对对该技术的不道德使用。
七、未来工作与贡献
项目团队计划进行以下改进:
-
优化推理速度。
-
增加量化以提高内存效率。
-
添加Docker支持。
Nari Labs是一个小型团队,由1名全职和1名兼职研究工程师组成。团队热烈欢迎任何贡献,并邀请大家加入Discord服务器进行讨论。
Dia-1.6B核心技术汇总

















 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









