







 本文探讨深度学习在街景图像地理位置识别中的应用,介绍基于CNN的模型和实际代码,展示深度学习自动学习特征、利用上下文信息的优势。通过实验,证明深度学习在不同环境和城市中的有效性和高准确性。未来研究将关注模型优化、多模态信息融合和实时性提升。
本文探讨深度学习在街景图像地理位置识别中的应用,介绍基于CNN的模型和实际代码,展示深度学习自动学习特征、利用上下文信息的优势。通过实验,证明深度学习在不同环境和城市中的有效性和高准确性。未来研究将关注模型优化、多模态信息融合和实时性提升。
🚀 本文选自专栏:人工智能领域200例教程专栏
从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。
✨✨✨ 每一个案例都附带有在本地跑过的代码,详细讲解供大家学习,希望可以帮到大家。欢迎订阅支持,正在不断更新中,本专栏最终不低于200篇文章案例~
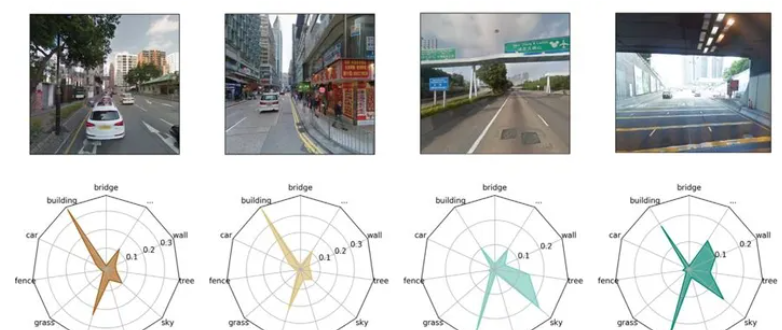
一.基于深度学习的街景图像地理位置识别
随着深度学习技术的飞速发展,人工智能在各个领域展现出强大的潜力。其中,基于深度学习的街景图像地理位置识别成为近年来备受关注的研究方向之一。本文将深入探讨深度学习在街景图像地理位置识别中的应用,介绍相关算法和技术,并附上实际代码示例。
街景图像地理位置识别是指通过分析街景图像,确定图像中拍摄的具体地理位置的过程。这对于导航、地图更新和城市规划等应用具有重要意义。传统方法中,往往需要手工设计特征和规则,但随着深度学习的兴起,可以通过神经网络从大量数据中学习表示,取得更好的效果。

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











