






超前进位加法器(Carry LookAhead Adder)
-
设计思想
由于行波进位加法器具有明显的延迟,从图中可以看出延迟主要是由进位传播链引起的,因此如何可以快速得到每一位的进位信号是加速计算的关键,这里提出了一种新的设计思想,即让每一位进位的产生近依赖于同一输入信号,这样便可以同时计算得到每一位的进位信号。 -
公示推导
这里引入两个信号位:进位产生位(gi)和进位传递位(pi),使得所有各位的进位都不依赖于低位的进位,每一位的进位可以同时产生,因而得到结果的延迟与运算位数无关,逻辑表达式如下:

四位加法器的计算公式: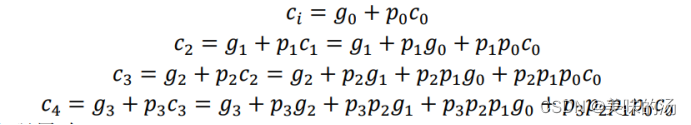
- 架构图
理论上对于64位加法器的设计同样可以按照上面的推导全部展开,然而此时ci的表达式太长,意味着对逻辑门扇入和扇出的要求太大,电路的实现会变得十分复杂。因此设计64位的超前进位加法器可以采用多级分层实现的方案。将64位输入分解为16组4位的超前进位加法器,第一级得到得到的16组为超前进位的第二级,该级组间仍然使用超前进位的逻辑进行实现,可以进一步再分为4组,形成第三级。因此这里设计的64位超前进位加法器由3级超前进位逻辑实现。
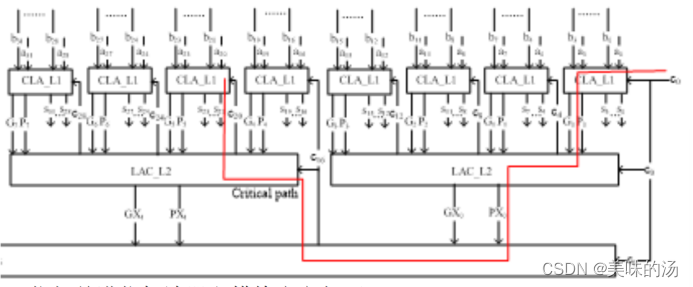
上图为32位加法器示意图,64位架构与其相同。
-
关键路径分析
图中红色路径为此加法器的关键路径,可以看出此加法器的延迟为3级超前进位的产生延迟,与操作数位数的延迟关系为T=Log(N)*t(CLA) -
verilog代码
module adder_nocarry(
input A,B,C_in,
output S,
output g,p
);
assign S = A ^ B ^ C_in;
assign g = A & B;
assign p = A ^ B;
endmodule
module adder_LKAHD_4bit( //超前三位计算进位信号
input [3:0]A,B,
input C_in,
output [3:0]Y,
output G,P
);
wire [3:0]c,g,p;
adder_nocarry add0 (A[0],B[0],C_in,Y[0],g[0],p[0]);
adder_nocarry add1 (A[1],B[1],c[0],Y[1],g[1],p[1]);
adder_nocarry add2 (A[2],B[2],c[1],Y[2],g[2],p[2]);
adder_nocarry add3 (A[3],B[3],c[2],Y[3],g[3],p[3]);
CLA_4bit cla (g,p,C_in,c);
assign G = g[3] | (p[3]&g[2]) | (p[3]&p[2]&g[1]) | (p[3]&p[2]&p[1]&g[0]) ;
assign P = p[0]&p[1]&p[2]&p[3];
endmodule
module CLA_4bit(
input [3:0]g,p,
input C_in,
output [3:0]C
);
assign C[0] = g[0] | (p[0]&C_in);
assign C[1] = g[1] | (p[1]&g[0]) | (p[0]&p[1]&C_in) ;
assign C[2] = g[2] | (p[2]&g[1]) | (p[2]&p[1]&g[0]) | (p[2]&p[1]&p[0]&C_in);
assign C[3] = g[3] | (p[3]&g[2]) | (p[3]&p[2]&g[1]) | (p[3]&p[2]&p[1]&g[0]) | (p[3]&p[2]&p[1]&p[0]&C_in) ;
endmodule
module adder_LKAHD_16bit(
input [15:0] A,B,
input C_in,
output [15:0]S,
output GX,PX
);
wire [3:0] C,G,P;
adder_LKAHD_4bit Add3 (A[15:12],B[15:12],C[2],S[15:12], G[3], P[3]);
adder_LKAHD_4bit Add2 (A[11:8], B[11:8], C[1],S[11:8], G[2], P[2]);
adder_LKAHD_4bit Add1 (A[7:4], B[7:4], C[0],S[7:4], G[1], P[1]);
adder_LKAHD_4bit Add0 (A[3:0], B[3:0], C_in,S[3:0], G[0], P[0]);
CLA_4bit cla1 (G,P,C_in,C);
assign GX = G[3] | (P[3]&G[2]) | (P[3]&P[2]&G[1]) | (P[3]&P[2]&P[1]&G[0]) ;
assign PX = P[0]&P[1]&P[2]&P[3];
endmodule
module adder_LKAHD_64bit(
input [63:0] A,B,
input C_in,
output [63:0]S,
output C_out
);
wire [3:0] C,GX,PX;
adder_LKAHD_16bit Add7 (A[63:48], B[63:48], C[2], S[63:48], GX[3], PX[3]);
adder_LKAHD_16bit Add6 (A[47:32], B[47:32], C[1], S[47:32], GX[2], PX[2]);
adder_LKAHD_16bit Add5 (A[31:16], B[31:16], C[0], S[31:16], GX[1], PX[1]);
adder_LKAHD_16bit Add4 (A[15:0], B[15:0], C_in, S[15:0], GX[0], PX[0]);
CLA_4bit cla2 (GX,PX,C_in,C);
assign C_out = C[3];
endmodule
测试文件
module adder_LKAHD_tb();
reg [63:0]a,b;
reg cin;
wire cout;
wire [63:0]s;
adder_LKAHD_64bit T3 (.A(a),.B(b),.C_in(cin),.S(s),.C_out(cout));
integer i = 0;
initial
begin
cin = 1;
for(i=0;i<16;i=i+1)
begin
a = $random;
b = $random;
#10;
end
cin = 0;
for(i=0;i<16;i=i+1)
begin
a = $random;
b = $random;
#10;
end
end
endmodule















 197
197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









