








名称解释:
SFM(Structure from Motion)是三维重建中的一个关键步骤或技术(是三维重建pipeline的一部分,又称稀疏重建,)。SFM利用从多个图像中提取的特征点以及这些图像之间的对应关系,通过计算相机的位姿和运动轨迹,从而恢复出场景的三维结构。SFM是从运动中恢复结构的过程,它利用序列图像中的运动信息来推断出场景的三维结构。
每个关键点给出的表面先验是指基于关键点所提取的信息,对物体或场景表面的预期或假设性的描述。这些关键点通常是通过图像处理技术从二维图像中提取的,并且包含了关于物体形状、结构或纹理等重要信息。
表面先验在三维重建中起到了关键的作用。由于从二维图像恢复三维结构是一个复杂且存在多解的问题,因此引入表面先验可以帮助约束和指导重建过程,提高重建的准确性和稳定性。通过利用关键点给出的表面先验,可以减少重建中的歧义性,并更好地还原出物体的真实形状和结构。
具体来说,表面先验可以包括多种信息,例如表面的平滑性、连续性、曲率变化等。这些先验知识可以帮助算法在重建过程中填充缺失的数据、平滑噪声、修复损坏的部分,从而得到更完整、更真实的三维模型。
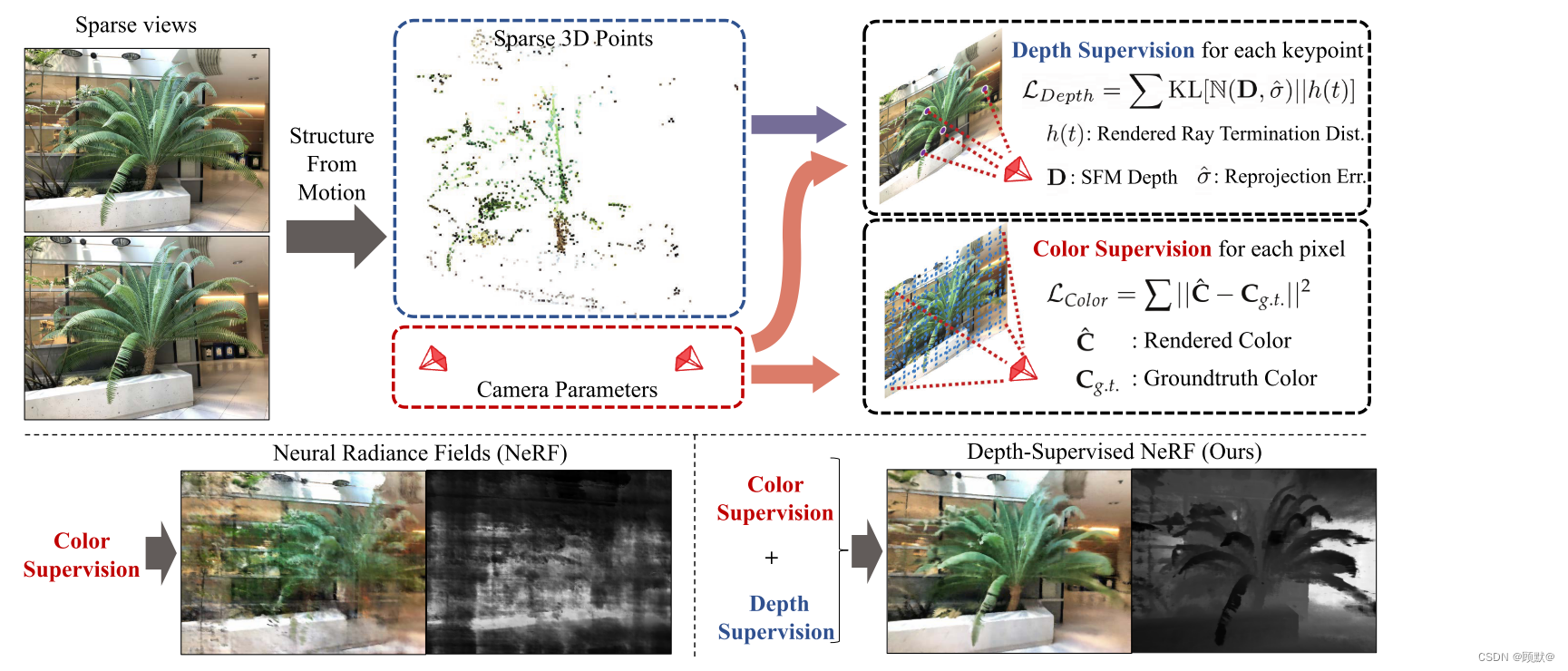
图1。当输入图像不足时,训练 NRFs 可能很困难。我们利用从运行SFM估计的3D 点云恢复的深度进行额外的监督,并施加一个损失,以确保渲染光线的终止分布对应每个关键点给出的表面先验。由于我们的监督是对 NERF 的补充,它可以与任何这样的方法相结合,以减少过度适应和加速训练。
Abstract
神经辐射场(NeRF)的一个常见故障模式是在输入视图数量不足时拟合不正确的几何形状。一个潜在的原因是,标准的体绘制并没有强制场景的几何体由空白空间和不透明表面组成的约束。我们通过DS-NeRF(深度监督神经辐射场)形式化上述假设,这是一种利用现成的深度监督来学习辐射场的损失。我们利用了当前NeRF管道需要具有已知相机姿态的图像的事实,这些相机姿势通常通过运行运动恢复结构(SFM)来估计。至关重要的是,SFM还产生稀疏的3D点,可以在训练期间用作“自由”深度监督:我们添加了一个损失,以鼓励射线的终止深度分布与给定的3D关键点相匹配,并包含深度不确定性。DS-NeRF可以提供更少的训练视图来渲染更好的图像然而训练速度还快2~3倍.此外,我们表明,我们的损失是兼容的其他最近提出的NeRF方法,表明深度是一个便宜的,容易消化的监督信号。最后,我们发现DS-NeRF可以支持其他类型的深度监控,例如扫描深度传感器和RGB-D重建输出。
1. Introduction
具有隐式表示的神经渲染已成为一种广泛使用的技术,用于解决许多视觉和图形任务,范围从视图合成到重新照明,到姿势和形状估计,到3D感知图像合成和编辑,到建模动态场景。神经辐射场(NeRF)的开创性工作通过使用隐式函数对体积密度和颜色观测进行编码,展示了令人印象深刻的视图合成结果。
尽管如此,NeRF仍有一些局限性。给定少量输入视图,重建场景外观和几何形状可能是不适定的。图2显示NeRF可以学习非常不准确的场景几何形状,但仍然可以准确地渲染火车视图。然而,这样的模型产生的新的测试视图渲染差,基本上过拟合列车集。此外,即使有大量的输入视图,NeRF的训练仍然很耗时;在单个GPU上以中等分辨率对单个场景进行建模通常需要10小时到几天。由于昂贵的光线投射操作和冗长的优化过程,训练是缓慢的。
x在这项工作中,我们探索深度作为一个额外的,廉价的监督来源,以指导几何学NeRF。典型的NeRF管道需要图像和相机姿态,后者是从运动恢复结构(SFM)求解器(如COLMAP)中估计的。除了返回相机,COLMAP还输出稀疏的3D点云以及它们的重投影误差。我们施加一个损失,以鼓励射线的终止分布,以匹配3D关键点,将重投影误差作为一个不确定性的措施。这是比仅重建RGB强得多的信号。在没有深度监督的情况下,NeRF隐含地解决了多个视图之间的3D对应问题。然而,这个精确问题的稀疏版本已经由SFM解决,其解决方案由稀疏3D关键点给出。因此,深度监督通过将其搜索(软)锚定在具有稀疏显式对应的隐式对应上来改进NeRF。
我们的实验表明,这个简单的想法转化为训练NeRF及其变体的巨大改进,无论是训练速度还是所需的训练数据量。我们观察到,深度监督NeRF可以将模型训练速度提高2- 3倍,同时产生相同质量的结果。对于稀疏视图设置,实验表明,与NeRF真实的和Redwood-3dscan 上的原始NeRF和最近的稀疏视图NeRF模型相比,我们的方法合成了更好的结果。我们还表明,我们的深度监督损失与从其他来源(如深度相机)获得的深度配合良好。我们的代码和更多结果可在https://www.cs.cmu.edu/indsnerf/.
2.相关工作
3. Depth-Supervised Ray Termination(深度监督射线终止)
现在,我们提出我们的proposed depth-supervised loss for training NeRFs(训练神经元的建议深度监督的损失)。我们首先回顾体绘制,然后分析射线的终止分布。我们以深度监督分布损失作为结论。
3.1. Volumetric rendering revisited(回顾体积渲染)
3.2. Deriving depth-supervision
回想一下,大多数 NRF 管道需要带有相关摄像机矩阵的图像(P1,P2,. .) ,通常使用如 COLMAP [22]这样的 SFM 软件包进行估计。重要的是,SFM 使用光束法平差,它也返回3 d 关键点{ X: x1,x2,. . ∈ R3}和可见性标志,其中关键点可以从相机 j: Xj包含于x 看到。给定图像 Ij 和它的相机 Pj,我们估计可见关键点 xi包含于 Xj 的深度 通过简单地投影 xi 与 Pj,取重新投影的 z 值作为关键点的深度 Dij。
Depth uncertainty.
毫无疑问,Dij 本身就是由于虚假通信而产生的噪音估计,摄像机参数噪声,或者 COLMAP 优化不佳。特定关键点 xi 的可靠性可以使用检测到关键点的视图之间的平均重投影误差 σi 来测量。具体而言,我们将射线遇到的第一个表面的位置建模为一个随机变量 Dij,其正态分布在 COLMAP 估计的深度 Dij 周围,方差 σi: Dij ~ N (Dij,σi帽)。结合关于理想终止分布行为的直觉,我们的目标是最小化Xi图像坐标的渲染射线分布 hij (t)和噪声深度分布之间的 KL 散度:

Ray distribution loss.
上面的等价性(见我们的附录作为证据)允许终止分布 h (t)通过概率 COLMAP 深度监视进行训练:
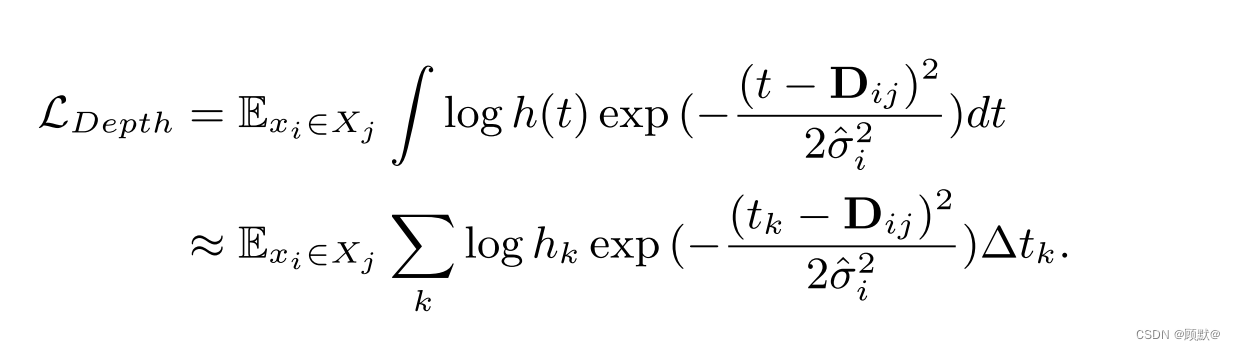
我们对 NeRF 的总体训练损失是 L = LColor +λDLDepth,其中 λD 是一个超参数平衡色彩和深度监督。















 1291
1291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









