







nnU-Net早期被众人所熟知是有一年参加了医学图像分割领域的十项全能比赛(MSD)并获得了冠军,接着该团队在最近又推出了nnUNet v2,使得功能更强大,代码的集成化更好。
需要的配置要求和相关环境的配置
使用最新版本的 Python3.9 或更高版本保证正常工作,而且使用pytorch的版本要高于1.12.0.最好使用GPU版本。
然后首先使用conda创建一个虚拟环境,接着根据源代码提供的requires.txt进行对相关库的配置。接着这将在计算机上创建 nnU-Net 代码的副本,以便可以根据需要修改,进入所在文件的终端输入:(注意有个".")
pip install -e .

创建相对应的环境变量
因为改模型的所提供的代码环境集合的太好了,所以通过相应的cmd的系统命令可以更好地运行。
因此首先得创建三个空文件夹nnUNet_raw、nnUNet_preprocessed和nnUNet_results,接着打开cmd将对应的路径写入环境变量:
set nnUNet_raw=对应的路径名称
相关数据集:
对于数据集使用的是十项全能比赛中的数据集(MSD),其中网址为: link,可以下载相关的数据集进行训练。其中数据集由三个组件组成:原始图像、相应的分割图和指定 一些元数据。
其中数据集的对应格式为:
nnUNet_raw/Dataset001_NAME1
├── dataset.json
├── imagesTr
│ ├── ...
├── imagesTs
│ ├── ...
└── labelsTr
├── ...
nnUNet_raw/Dataset002_NAME2
├── dataset.json
├── imagesTr
│ ├── ...
├── imagesTs
│ ├── ...
└── labelsTr
├── ...
注意此时应把nnUNet_raw文件夹置空,将下载的数据集改为Data00X_NAME1放在该文件外边。
数据集的转换
nnU-Net v2给出了相应的脚本进行数据集的转换,使用的是:
nnUNetv2_convert_MSD_dataset
如果报错就说明有可能前面的环境变量没设置好。
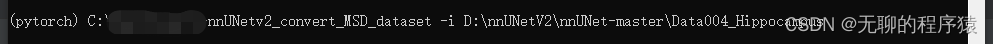
这时候nnUNet_raw文件夹会出现对应的数据集,因此转化成功。也可以通过查看相应的dataset.json文件进行判断是否转化成功。其中dataset.json转化成功后的为:
{
"channel_names": { # formerly modalities
"0": "T2",
"1": "ADC"
},
"labels": { # THIS IS DIFFERENT NOW!
"background": 0,
"PZ": 1,
"TZ": 2
},
"numTraining": 32,
"file_ending": ".nii.gz"
"overwrite_image_reader_writer": "SimpleITKIO" # optional! If not provided nnU-Net will automatically determine the ReaderWriter
}
与刚下载的数据集是有区别的。

接着再将数据集转入到nnUNet_preprocessed文件中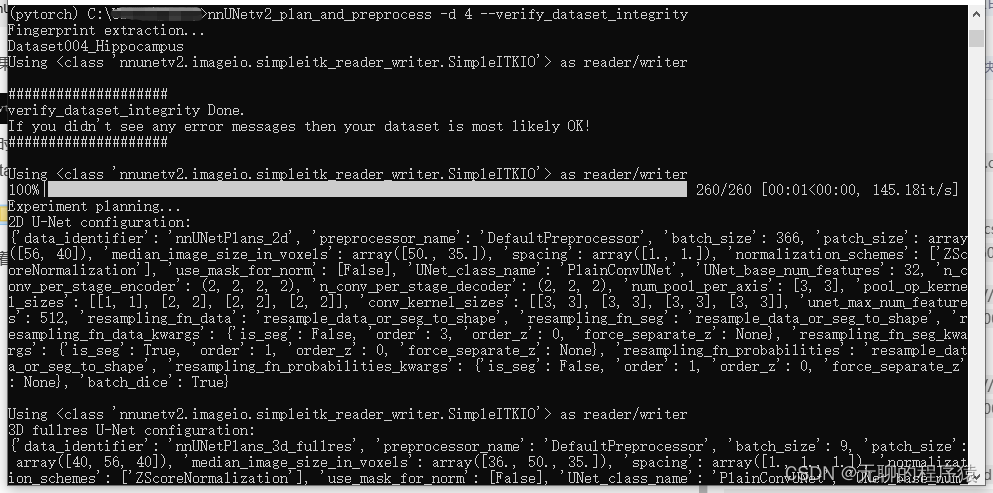
此时也会自动将对应的数据集转成相应的格式转进入nnUNet_preprocessed文件中。
开始训练
将数据集的相关事情处理好后就可以开始对图片进行训练了,同时也可以使用自己的数据集进行训练,其中相关的数据集的转化可以参考nnU-Net v2在GitHub上所提出的注意事项进行转化。
开始在cmd上输入:
nnUNetv2_train DATASET_NAME_OR_ID UNET_CONFIGURATION FOLD [additional options, see -h]
- DATASET_NAME_OR_ID:为训练数据集的ID号码;
- UNET_CONFIGURATION:为数据集相应的格式,在nnUNet_preprocessed可以查看;
- FOLD:为k折交叉验证。
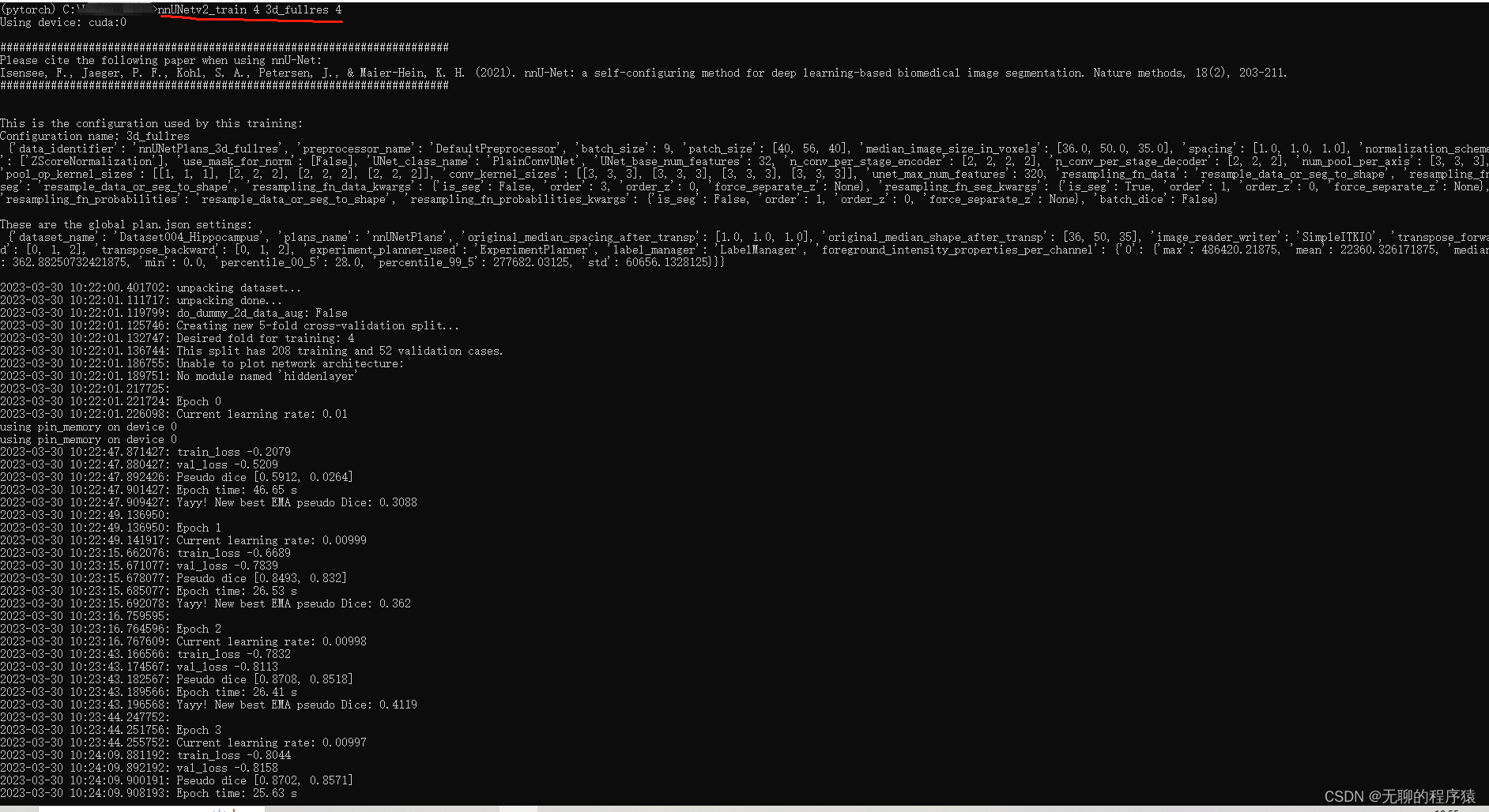
接着就是开始等待训练结果啦~
默认是1k轮训练,学习率从1开始往下走。训练结束后nnUNet_results会写入训练结果: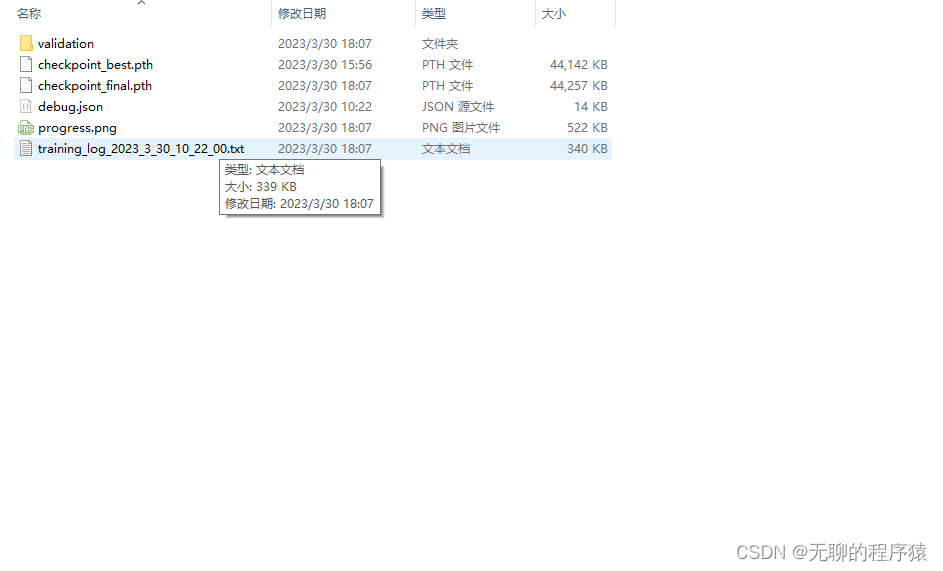















 1082
1082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









