







文本文件可存储的数据量多得难以置信:交通数据、社会经济数据、文学作品等等。
每当需要分析或修改存储在文件中的信息时,读取文件都很有用,对数据分析应用程序来说尤其如此。
文件读取
❶ python的文件读取,又可以细分为:
● 绝对路径的文件读取
● 相对路径的读取
❷ 文件的数据读取,细分为:
● 整个文件内容读取
● 指定文件内容的字符数读取
● 指定文件行数读取
>
下面将依次进行演示
绝对路径读取(windows)
绝对路径读取:指的是要读取的文件,与当前文件不在同一个文件夹下,需写上完整的文件文件路径和文件名称
>
读取文件关键字open()
open()两个参数:
文件名完整路径
mode="r"(r表示读(read的简写),r可以省略不写,也可以直接r"文件路径和文件名")
#文件读取:
#绝对路径读取文件
file = open("D:\py_pro\lufei\reptile\day09\Rdemo.py")
print(file)
file.colse() #养成好习惯,最后关闭文件
#输出报错:
OSError: [Errno 22] Invalid argument: 'D:\\py_pro\\lufei\reptile\\day09\\Rdemo.py'因为在python中,
\是转义字符,如果想在字符串中表示\,需要使用\\来表示。在你的代码中,\r被解释为回车符,导致路径错误。解决方案:
● 需要将路径中的
\替换为/● 或者使用双反斜杠
\\来表示单个反斜杠>
修改后的代码如下:
#文件读取:
#绝对路径读取文件,以下两种方式二选一即可:
# file = open("D:/py_pro/lufei/reptile/day09/Rdemo.py")
file = open("D:\\py_pro\\lufei\\reptile\\day09\\Rdemo.py")
print(file)
file.colse() #养成好习惯,最后关闭文件
#输出:
<_io.TextIOWrapper name='D:\\py_pro\\lufei\\reptile\\day09\\Rdemo.py' mode='r' encoding='cp936'>另外,想要快速知道一个文件的绝对路径,可以在pycharm中,找到对应的文件:
右键点击Copy Path/Reference... -> 点击"Absolute Path Ctrl+Shift+ C"即可
相对路径读取
相对路径的读取:指的是要读取的文件与当前文件在同一个文件夹下,可以直接写文件名
示例如下:
#相对路径读取文件:当文件中有中文时,windows系统默认加上encoding="utf-8"
file = open("douban250.html",encoding="utf-8")
print(file)
file.colse() #养成好习惯,最后关闭文件
#输出:
<_io.TextIOWrapper name='douban250.html' mode='r' encoding='utf-8'>可以看出无论是绝对路径、还是相对路径读取文件,得到的都是一个对象
open只是一个句柄,想要获取文件里的具体数据,就需要再进行文件数据的读取
文件数据读取
读取文件后,得到是一个文件对象,想要获取文件中的具体数据,就需要用到具体的读取数据方法:
● 整个文件内容读取
● 指定文件内容的字符数读取
● 指定文件行数读取
>
代码示例如下:
#相对路径读取文件:当文件中有中文时,windows系统默认加上encoding="utf-8"
file = open("douban250.html", encoding="utf-8")
#获取当前文件的所有数据:
print("所有:",file.read())
#输出:
所有: <!DOCTYPE html>
<html lang="zh-CN" class="ua-windows ua-webkit">
<head>……由于文件内容较多,此处省略
#获取文件的前10个字符:
print("前10个字符:",file.read(10))
#输出:
前10个字符: <!DOCTYPE
#读取文件的第一行:
print(file.readline())
file.colse() #养成好习惯,最后关闭文件
#输出:
<!DOCTYPE html>文件读取的正确姿势
通常,读取文件就是将磁盘的数据转到内存上来进行一系列操作,实际应用中读取的数据本身内存特别大,这时候如果全部读取,电脑内存就会崩掉。
>
所以,我们通常是读取文件对象,然后进行循环语句进行需要的信息提取或操作,操作完之后立即进行垃圾回收,以减少电脑内存消耗
#文件读取:
#相对路径读取文件:当文件中有中文时,windows系统默认加上encoding="utf-8"
file = open("douban250.html", encoding="utf-8")
#循环高效操作:
for line in file:
print(line)
file.colse() #养成好习惯,最后关闭文件
#输出:
<!DOCTYPE html>
<html lang="zh-CN" class="ua-windows ua-webkit">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<meta name="renderer" content="webkit">……此处省略文件写入
保存数据的最简单的方式之一是将其写入到文件中。
通过将输出写入文件,即便关闭包含程序输出的终端窗口,这些输出也依然存在:你可以在程序结束运行后查看这些输出, 可与别人分享输出文件,还可编写程序来将这些输出读取到内存中并进行处理。
覆盖写
所谓覆盖写入:
如果没有该文件即创建一个新文件
如果有文件就清空全部文件内容,重新写
示例如下:
file = 'programming.txt'
with open(file, 'w') as file_object:
file_object.write("I love programming.")代码运行后,生成一个'programming.txt'文件
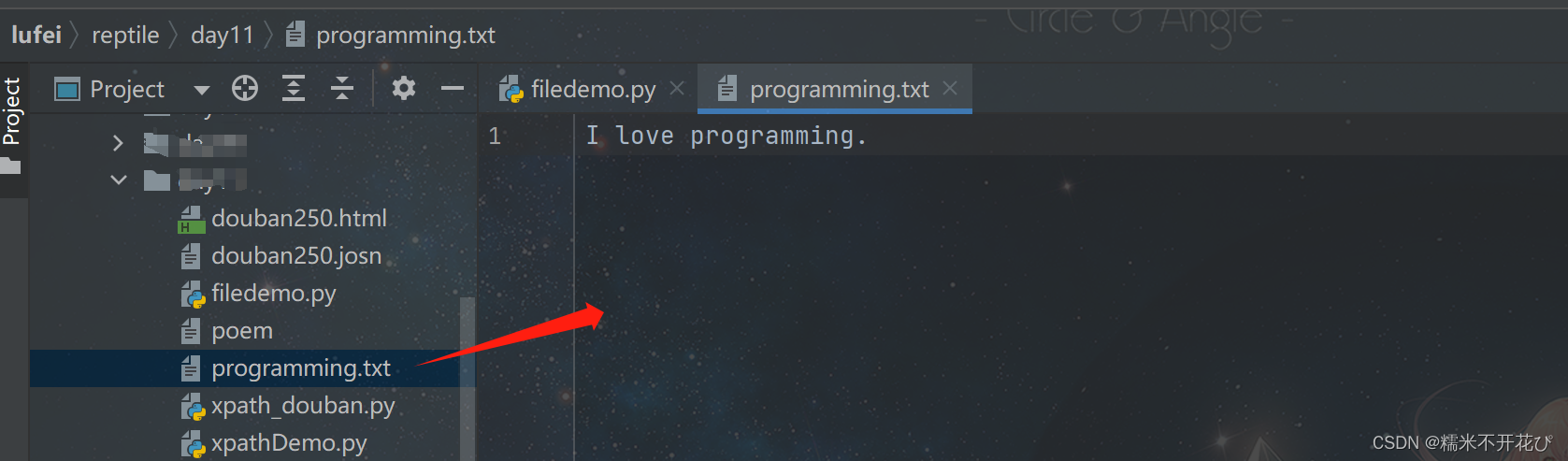
重新修改了写如内容:
file = 'programming.txt'
with open(file, 'w') as file_object:
file_object.write("hello world!~")重新执行代码后,并没有重新生成'programming.txt'文件,但是可以看出,文件内容已经更新了:

追加写
所谓追加写入:
如果没有该文件即创建一个新文件
如果文件已存在,就在文件的最后追加新内容
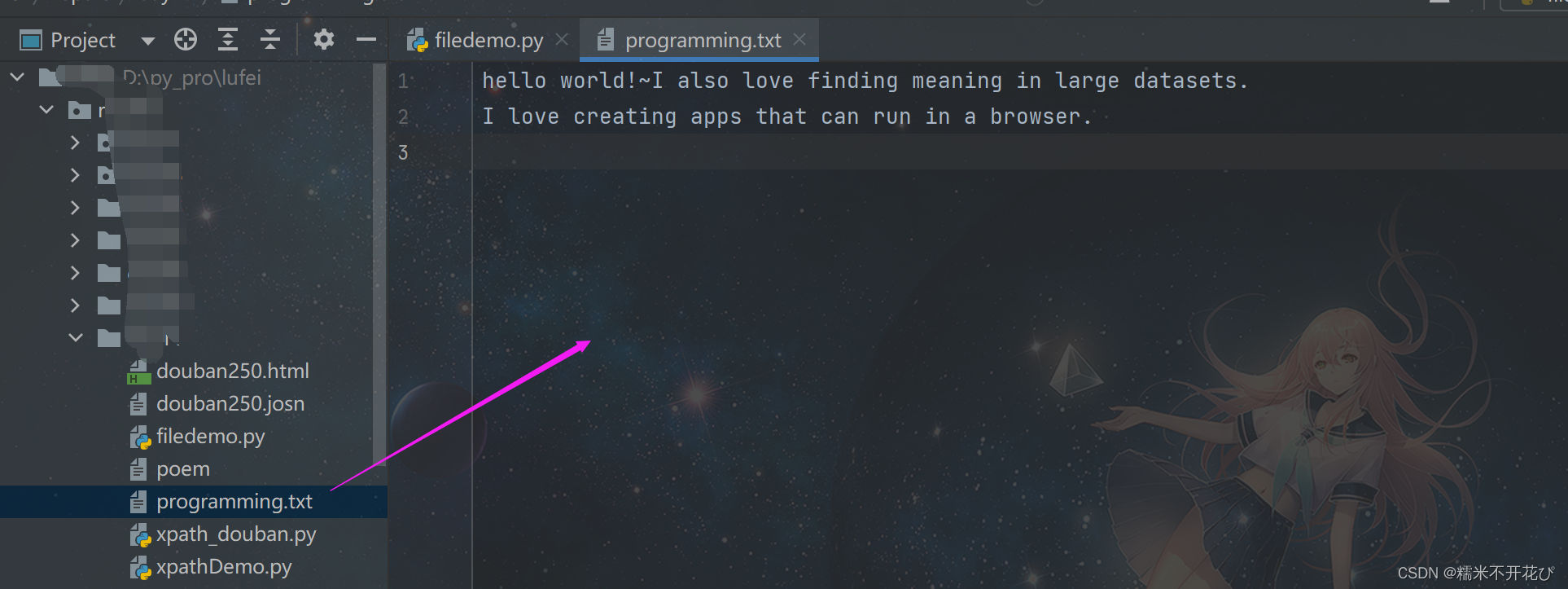
file = 'programming.txt'
with open(file, 'a') as file_object:
file_object.write("I also love finding meaning in large datasets.\n")
file_object.write("I love creating apps that can run in a browser.\n")代码执行后,查看'programming.txt'文件:
python的编码与解码
编码:常用于存储、网络传输,都使用字节进行编码
解码:常用于读文件、读字符串,都使用字节进行解码
>
常见的编码与解码规则有:GBK、UFT8(编码与解码的规则必须一致)
python默认使用的是UTF8
中文文件,如果不使用UFT8就会报错、或者打开文件是乱码,这就是编码与解码问题
>
编码方法:encode("utf-8")
#编码方法:
s = "i am 明"
s1 = s.encode("utf-8") #也可以省略-,直接写utf8
s2 = s.encode("GBK")
#解码方法:字节数据对象.decode("规则")
# print(s1.decode("GBK")) #会报错,因为上面用的规则是"utf-8"
print(s1.decode("utf-8"))
print(s2.decode("GBK"))栗子
比如我在pycharm中有一个文本文件,里面内容是中文
当我在另一个py文件中进行读取时并打印时,会产生如下报错:
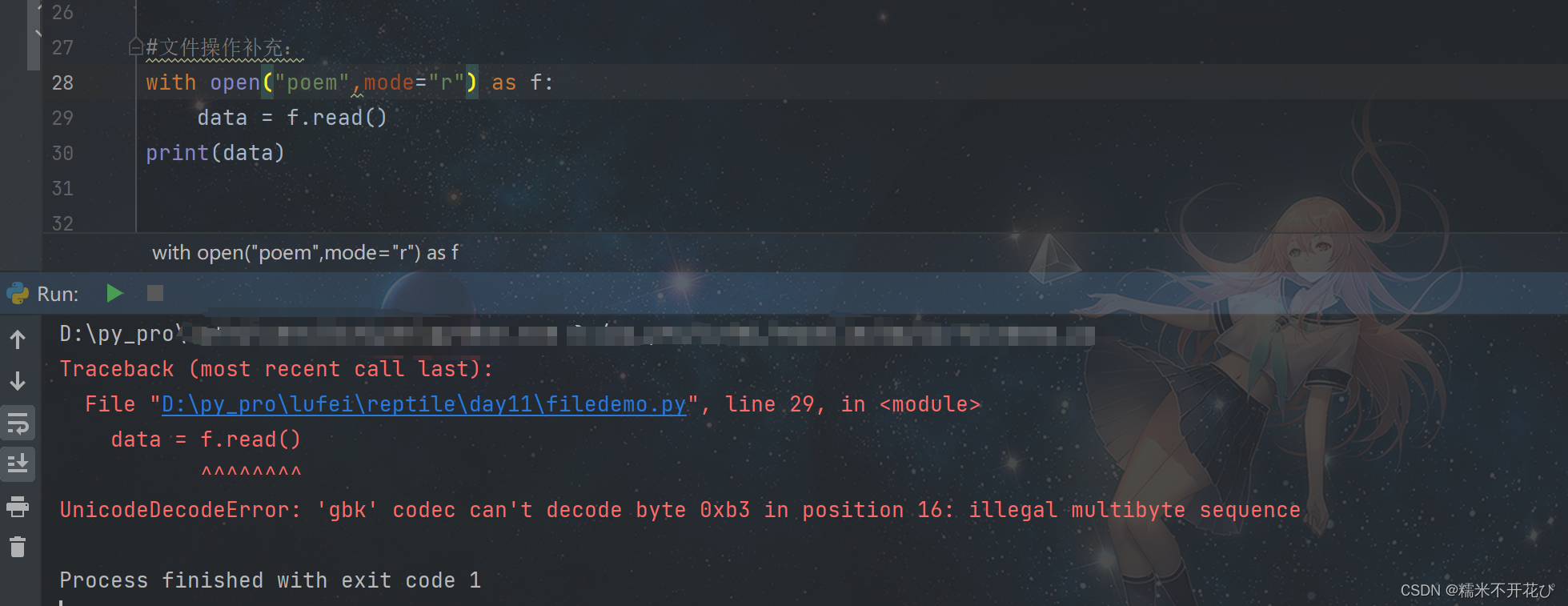
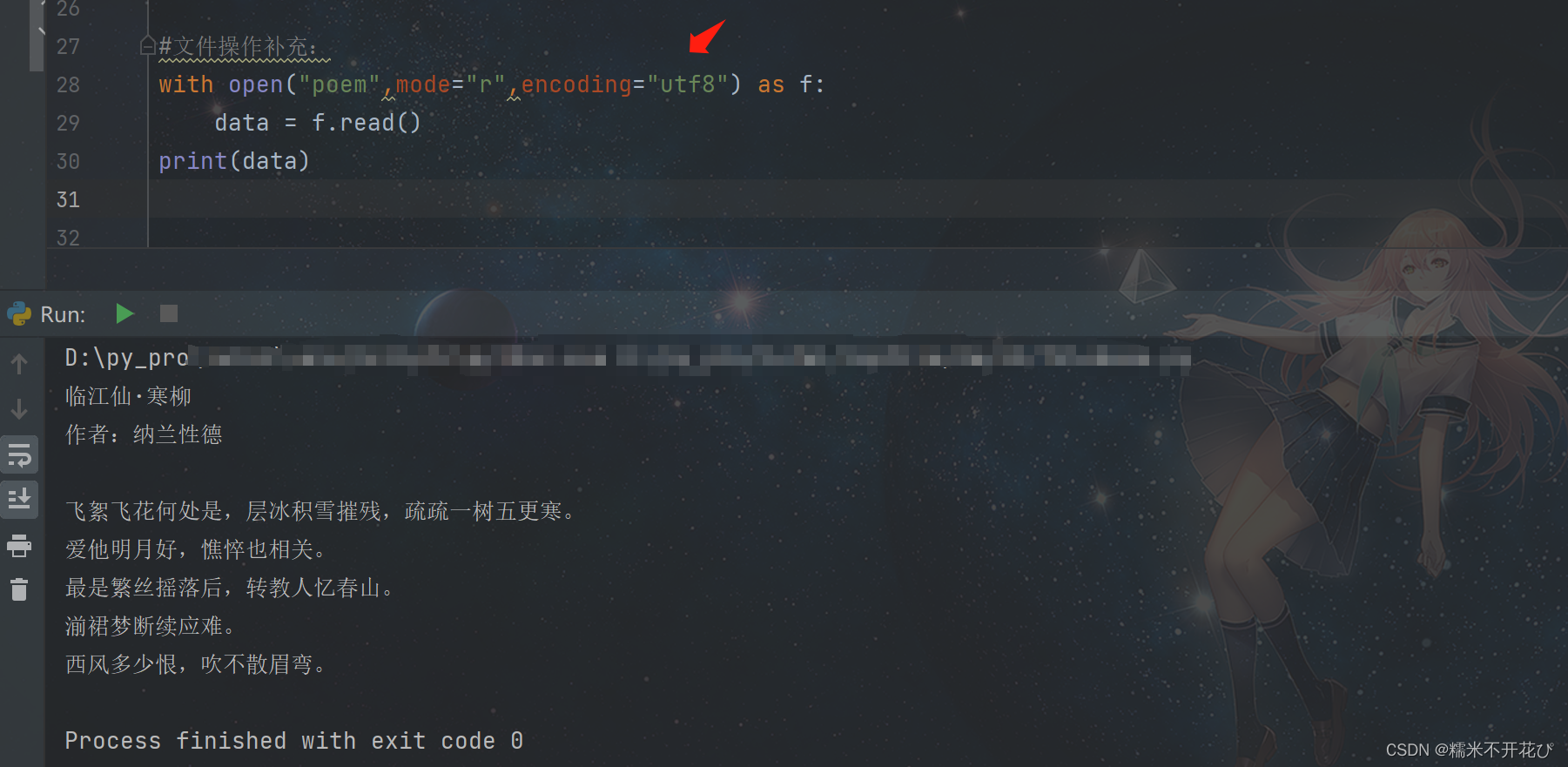
是因为:我的文本文件内容全是中文,在with open时没有定义编码规则,导致无法解码
解决方案:with open括号里加上编码规则即可正常读取内容:
os模块
os模块是Python标准库中的一个模块,提供了与操作系统交互的功能。它允许你访问操作系统的功能,如文件和目录操作、进程管理、环境变量等。
os常用函数
文件和目录操作
os.getcwd():获取当前工作目录的路径。os.chdir(path):改变当前工作目录为指定路径。os.listdir(path):返回指定目录下的所有文件和目录的名称列表。os.mkdir(path):创建一个新的目录os.mkdir(文件名):在当前启动文件的目录下创建一个新的文件夹os.rmdir(path):删除指定目录。os.remove(path):删除指定文件。
路径操作
os.path.join(path1, path2, ...):将多个路径组合成一个路径。os.path.abspath(path):返回指定路径的绝对路径。os.path.dirname(path):返回指定路径的目录名。os.path.basename(path):返回指定路径的文件名。os.path.exists(path):判断指定路径是否存在。os.path.isfile(path):判断指定路径是否为文件。os.path.isdir(path):判断指定路径是否为目录。
环境变量
os.environ:一个包含当前环境变量的字典。os.getenv(var_name):获取指定环境变量的值。os.putenv(var_name, value):设置指定环境变量的值。
进程管理
os.system(command):执行系统命令。os.popen(command):执行系统命令并返回一个文件对象。os.kill(pid, signal):向指定进程发送信号。os.getpid():获取当前进程的ID。os.getppid():获取当前进程的父进程ID。














 8787
8787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









