







官方学习文档:Building an LLM Application - LlamaIndex
一、LlamaIndex简介
LlamaIndex 是一个用于 LLM 应用程序的数据框架,用于注入,结构化,并访问私有或特定领域数据。
在本质上,LLM(如GPT)为人类和推断出的数据提供了基于自然语言的交互接口。广泛可用的大模型通常在大量公开可用的数据上进行的预训练,包括来自维基百科、邮件列表、书籍和源代码等。
构建在LLM模型之上的应用程序通常需要使用私有或特定领域数据来增强这些模型。不幸的是,这些数据可能分布在不同的应用程序和数据存储中。它们可能存在于API之后、SQL数据库中,或者存在于PDF文件以及幻灯片中。
LlamaIndex应运而生。
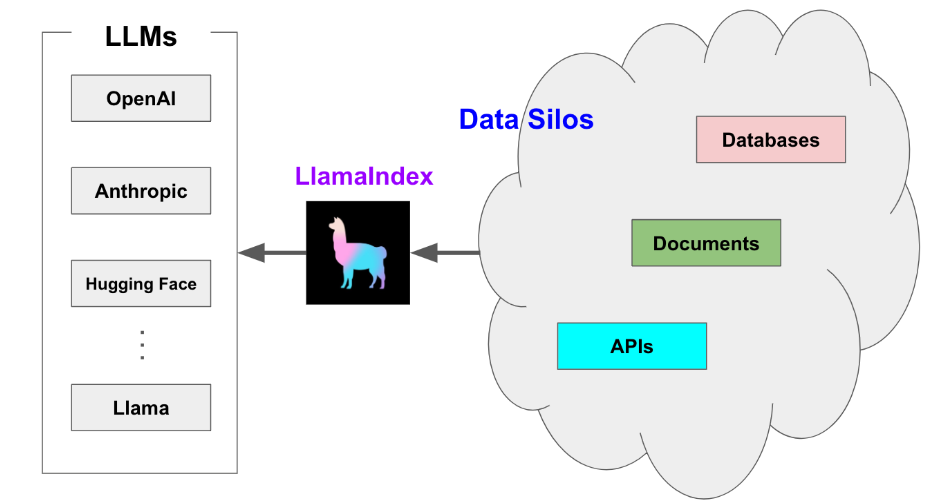
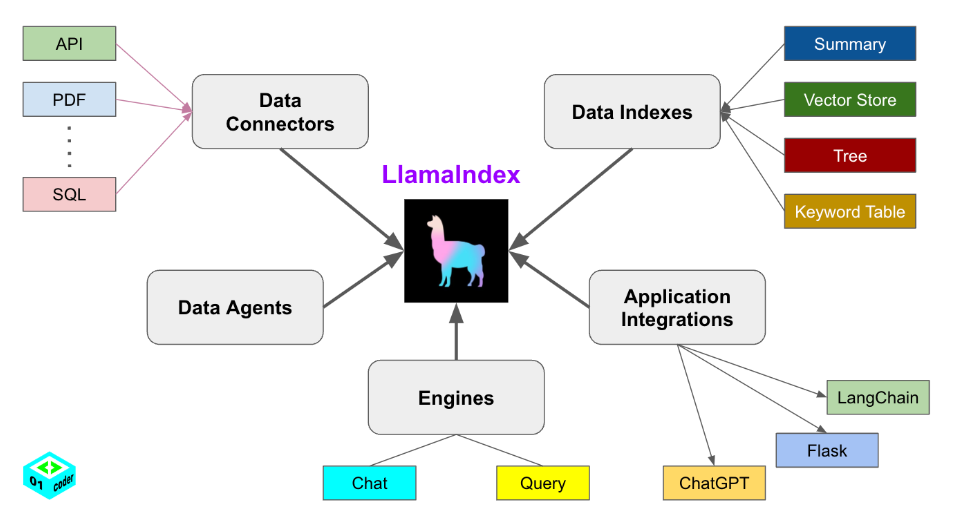
LlamaIndex 提供了5大核心工具:
- Data connectors 数据连接器
- Data indexes 数据索引
- Engines 引擎
- Data agents 数据智能体
- Application integrations 应用集成


二、LlamaIndex环境配置
llamaindex不同版本间的兼容性较差。
建议新创建一个环境,python:3.10,torch:2.1.2+cu118
requirements_llamaIndex.txt
# python ==3.10
accelerate==1.0.1
aiohappyeyeballs==2.4.3
aiohttp==3.10.10
aiosignal==1.3.1
altair==5.4.1
annotated-types==0.7.0
anyio==4.6.2.post1
async-timeout==4.0.3
attrs==24.2.0
beautifulsoup4==4.12.3
blinker==1.8.2
cachetools==5.5.0
certifi==2022.12.7
charset-normalizer==2.1.1
click==8.1.7
chroma-hnswlib==0.7.6
chromadb==0.6.3
dataclasses-json==0.6.7
Deprecated==1.2.14
dirtyjson==1.0.8
distro==1.9.0
einops==0.8.0
exceptiongroup==1.2.2
filelock==3.16.1
frozenlist==1.4.1
fsspec==2024.9.0
gitdb==4.0.11
GitPython==3.1.43
greenlet==3.1.1
h11==0.14.0
httpcore==1.0.6
httpx==0.27.2
huggingface-hub==0.23.1
idna==3.4
InstructorEmbedding==1.0.1
Jinja2==3.1.4
jiter==0.6.1
joblib==1.4.2
jsonschema==4.23.0
jsonschema-specifications==2024.10.1
llama-cloud==0.1.2
llama-index==0.11.17
llama-index-agent-openai==0.3.4
llama-index-cli==0.3.1
llama-index-core==0.11.17
llama-index-embeddings-huggingface==0.3.1
llama-index-embeddings-instructor==0.2.1
llama-index-embeddings-openai==0.2.5
llama-index-indices-managed-llama-cloud==0.4.0
llama-index-legacy==0.9.48.post3
llama-index-llms-huggingface==0.3.5
llama-index-llms-openai==0.2.13
llama-index-multi-modal-llms-openai==0.2.2
llama-index-program-openai==0.2.0
llama-index-question-gen-openai==0.2.0
llama-index-readers-file==0.2.2
llama-index-readers-llama-parse==0.3.0
llama-index-vector-stores-chroma==0.4.1
llama-parse==0.5.7
llamaindex-py-client==0.1.19
markdown-it-py==3.0.0
MarkupSafe==3.0.1
marshmallow==3.22.0
mdurl==0.1.2
minijinja==2.2.0
modelscope==1.19.0
mpmath==1.3.0
multidict==6.1.0
mypy-extensions==1.0.0
narwhals==1.9.3
nest-asyncio==1.6.0
networkx==3.4.1
nltk==3.9.1
numpy==1.26.3
openai==1.51.2
packaging==24.1
pandas==2.2.3
pillow==10.2.0
propcache==0.2.0
protobuf==5.28.2
psutil==6.0.0
pyarrow==17.0.0
pydantic==2.9.2
pydantic_core==2.23.4
pydeck==0.9.1
Pygments==2.18.0
pypdf==4.3.1
python-dateutil==2.9.0.post0
pytz==2024.2
PyYAML==6.0.2
referencing==0.35.1
regex==2024.9.11
requests==2.32.3
rich==13.9.2
rpds-py==0.20.0
safetensors==0.4.5
scikit-learn==1.5.2
scipy==1.14.1
sentence-transformers==2.7.0
sentencepiece==0.2.0
six==1.16.0
smmap==5.0.1
sniffio==1.3.1
soupsieve==2.6
SQLAlchemy==2.0.35
streamlit==1.36.0
striprtf==0.0.26
sympy==1.13.3
tenacity==8.5.0
text-generation==0.7.0
threadpoolctl==3.5.0
tiktoken==0.8.0
tokenizers==0.19.1
toml==0.10.2
#torch==2.1.2+cu118
#torchaudio==2.1.2+cu118
#torchvision==0.16.2+cu118
tornado==6.4.1
tqdm==4.66.5
transformers==4.41.1
triton==2.1.0
typing-inspect==0.9.0
typing_extensions==4.12.2
tzdata==2024.2
urllib3==1.26.13
watchdog==4.0.2
wrapt==1.16.0
yarl==1.15.2三、LlamaIndex调用大模型
默认支持的线上大模型只有ChatGPT,调用其他线上模型则需要额外处理。
1、线上调用ChatGPT
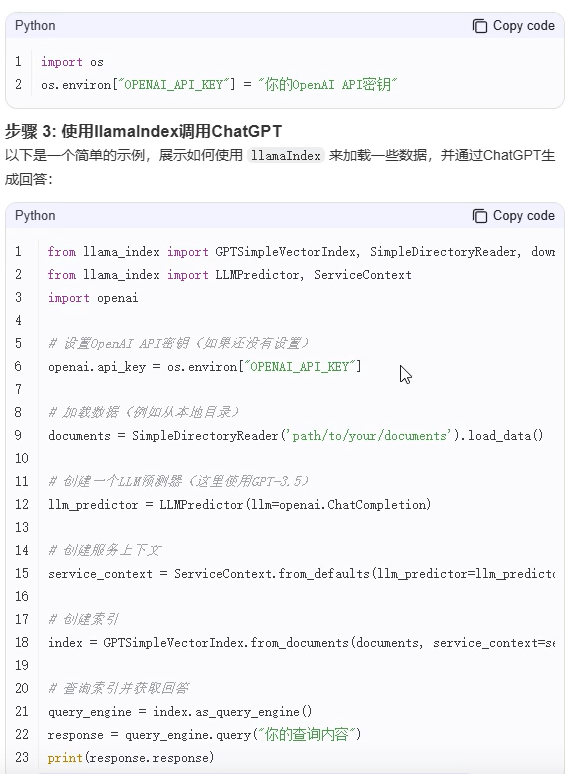
2、线上调用Qwen
需要重写模型方法
from llama_index.core.llms import CustomLLM,LLMMetadata
from dashscope import Generation
from typing import Any
class QwenLLM(CustomLLM):
@property # 用于将类中的方法定义为属性
def metadata(self) -> LLMMetadata:
return LLMMetadata(
model_name='qwen-max', # 模型名称
context_window=8192, # 上下文窗口大小(根据通义千问实际值调整)
num_output=1024, # 默认输出长度
is_chat_model=True # 是否是聊天模型
)
def complete(self, prompt: str, **kwargs: Any) -> str:
"""同步生成文本(必须实现)"""
response = Generation.call(
model='qwen-max',
prompt=prompt,
api_key= "sk-******", # 替换为你的API Key
**kwargs
)
return response.output['text'] # 获取大模型输出结果
def stream_complete(self, prompt: str, **kwargs: Any):
"""流式生成文本(可选,但需占位)"""
return NotImplementedError("通义千问流式输出暂未实现")qwen_max = QwenLLM()
res = qwen_max.complete("你好,通义千问!")
print(res)3、本地调用Qwen
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.llms import ChatMessage
llm = HuggingFaceLLM(
model_name="F:\models\Qwen\Qwen2.5-0.5B-Instruct",
tokenizer_name= "F:\models\Qwen\Qwen2.5-0.5B-Instruct",
model_kwargs={
"trust_remote_code":True # 允许加载自定义代码
},
tokenizer_kwargs={"trust_remote_code":True},
)
# res = llm.chat(messages=[ChatMessage(role="user",content="什么是量子力学?")])
res = llm.chat(messages=[ChatMessage("什么是量子力学?")])
print(res)四、LlamaIndex实现RAG引擎
Step01 加载模型
Step02 设置模型
Step03 读取数据
Step04 创建索引
Step05 创建查询引擎
Step06 通过引擎进行查询
1、query_engine
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLM
#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径
model_name="F:\models\sentence-transformers\paraphrase-multilingual-MiniLM-L12-v2"
)
llm = HuggingFaceLLM(
model_name="F:\models\Qwen\Qwen2.5-0.5B-Instruct",
tokenizer_name="F:\models\Qwen\Qwen2.5-0.5B-Instruct",
model_kwargs={"trust_remote_code":True},
tokenizer_kwargs={"trust_remote_code":True}
)from llama_index.core import Settings,SimpleDirectoryReader,VectorStoreIndex
#将创建的嵌入模型赋值给全局设置的embed_model属性,
#这样在后续的索引构建过程中就会使用这个模型。
Settings.embed_model = embed_model
#设置全局的llm属性,这样在索引查询时会使用这个模型。
Settings.llm = llm
#从指定目录读取所有文档,并加载数据到内存中
documents = SimpleDirectoryReader(input_dir="test_data").load_data()
print("docunments:",documents)
#创建一个VectorStoreIndex,并使用之前加载的文档来构建索引。
# 此索引将文档转换为向量,并存储这些向量以便于快速检索。
index = VectorStoreIndex.from_documents(documents)
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
res = query_engine.query("面膜的主要成分?")
print(res)2、chat_engine
from llama_index.core import Settings,SimpleDirectoryReader,VectorStoreIndex
Settings.embed_model = embed_model
Settings.llm = llm
documents = SimpleDirectoryReader(input_dir="test_data").load_data()
index = VectorStoreIndex.from_documents(documents)
# 创建chat engine
chat_engine = index.as_chat_engine(
chat_mode="context", # 可根据需求更改
verbose=True
)
# 交互式对话循环
while True:
test_input = input("用户:")
if test_input == "exit":
break
res = chat_engine.chat(test_input)
print(f"AI助手:{res}")五、LlamaIndex构建完整的RAG
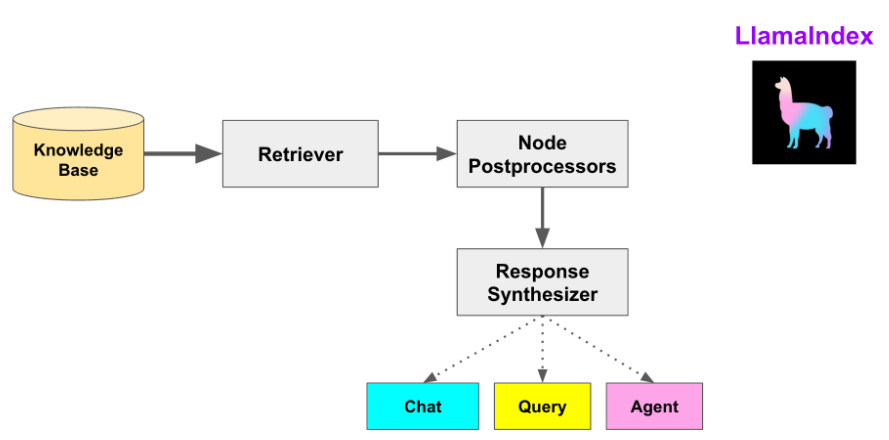
构建完整的RAG检索增强生成管道
RAG是一种将检索系统与生成式AI结合的技术架构,主要包含以下组件:
- 文档加载和处理
- 向量存储
- 检索器(Retriever)
- 响应合成器(Response Synthesizer)
- 后处理器(Postprocessor)
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLM
# 一、模型初始化
# 使用本地路径的HuggingFace模型
embed_model = HuggingFaceEmbedding(
model_name=r"F:\models\sentence-transformers\paraphrase-multilingual-MiniLM-L12-v2"
)
llm = HuggingFaceLLM(
model_name=r"F:\models\Qwen\Qwen2.5-0.5B-Instruct",
tokenizer_name=r"F:\models\Qwen\Qwen2.5-0.5B-Instruct",
model_kwargs={"trust_remote_code":True},
tokenizer_kwargs={"trust_remote_code":True}
)
import chromadb
from llama_index.core import Settings,SimpleDirectoryReader,VectorStoreIndex
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import StorageContext
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.response_synthesizers import get_response_synthesizer
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.postprocessor import SimilarityPostprocessor
from llama_index.core.node_parser import SentenceSplitter
#from llama_index.core.indices.vector_store.retrievers import QueryCache
#from llama_index.core.cache import SimpleCache
# 二、系统配置
Settings.embed_model = embed_model # 全局嵌入模型
Settings.llm = llm # 全局语言模型
# 三、数据加载
documents = SimpleDirectoryReader(input_dir="test_data").load_data() # 自动解析txt/pdf/docx等常见格式
# 四、向量存储
db = chromadb.PersistentClient(path="chroma_db") # 数据保存到chroma_db目录
chroma_collection = db.get_or_create_collection("test01")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 五、索引构建
"""
1.文档分块
2.生成嵌入向量
3.存储到ChromaDB
"""
# 自定义文本分割器(可选)
text_splitter = SentenceSplitter(
separator="###", # 主分割符
chunk_size=768, # 中文信息密度高,可适当增大
chunk_overlap=128,
paragraph_separator="###" # 段落分隔符标识
)
# index = VectorStoreIndex.from_documents(
# documents=documents,
# storage_context=storage_context,
# transformations=[text_splitter] # 关键注入点(可选)
# )
# 若加载现有向量数据库
index = VectorStoreIndex.from_vector_store(
vector_store=vector_store,
storage_context=storage_context
)
# 六、检索系统
"""
1.检索策略:返回相似度top_k的结果
2.扩展性:支持自定义检索算法
"""
#cache = QueryCache()
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=10, # 召回范围
similarity_cutoff=0.5, # 相似度阈值
vector_store_query_mode="hybrid", # 混合检索模式(向量+BM25语义,实际触发的是ChromaDB的混合搜索能力)
alpha=0.5, # 权重平衡参数(0=纯关键词,1=纯向量)
)
# 推荐方案
# [ 检索流程 ] 稀疏检索(如BM25) → 召回50条 → 密集检索(向量搜索) → 召回5条 → 合并去重 → 重排序 → 返回Top15
# retriever = VectorIndexRetriever(
# similarity_top_k=15, # 最终返回结果数
# vector_store_query_mode="sparse", # 启用稀疏检索模式
# sparse_top_k=50, # 稀疏检索召回数量
# dense_top_k=5, # 密集检索召回数量
# reranker=BgeRerank() # 重排序模型
# )
# 七、响应生成
"""
1.检索:找到相关文档片段
2.生成:综合上下文生成自然语言回答
如果不传参数,通常会使用默认配置:简洁的回答风格、基于检索到的前几名结果、使用系统默认的LLM
"""
response_synthesizer = get_response_synthesizer()
query_engine = RetrieverQueryEngine( # 组装查询引擎
retriever=retriever,
response_synthesizer=response_synthesizer,
#对检索结果进行过滤和排序
#可以设置相似度阈值
#支持自定义后处理逻辑
node_postprocessors=[
SimilarityPostprocessor(similarity_cutoff=0.5) # 过滤低质量结果
]
)
# 八、执行查询
res = query_engine.query("品牌理念是什么")
print(res)
print("检索到的文档数:", len(res.source_nodes))
print("相似度分数:", [node.score for node in res.source_nodes])
print([node for node in res.source_nodes])检索结果质量不高
- 调整similarity_top_k参数
- 优化文档分块策略
- 使用混合检索策略
响应速度慢
- 使用向量数据库索引
- 启用缓存
- 优化检索策略
构建一个完整的RAG管道需要考虑多个方面:
- 合适的向量存储选择
- 优化的检索策略
- 高效的响应合成
- 完善的后处理机制
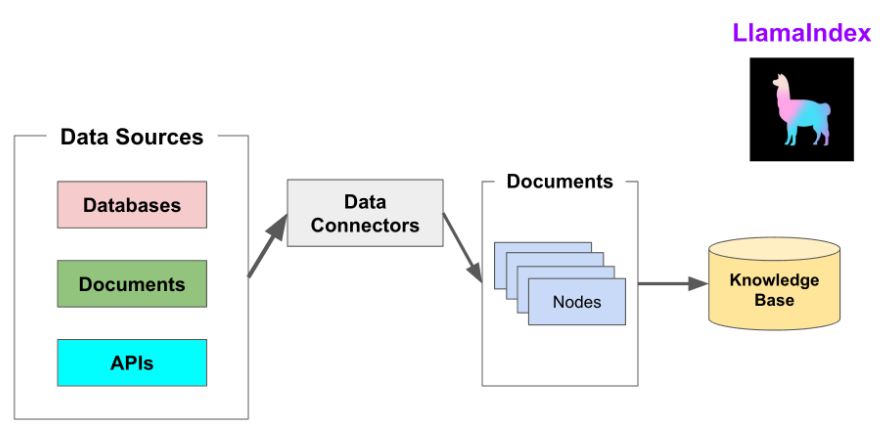
LlamaIndex 的数据连接器通过 LlamaHub 提供。LlamaHub 是一个开源仓库,包含可轻松集成到任何 LlamaIndex 应用。Llama Hub
从LlamaHub加载数据连接器
以下示例代码从 LlamaHub 加载 Markdown 文档数据连接器。关于该数据连接器的细节,请参考https://llamahub.ai/l/file-markdown
from pathlib import Path
from llama_index import download_loader
MarkdownReader = download_loader("MarkdownReader")
loader = MarkdownReader()
documents = loader.load_data(file=Path('./README.md'))六、拓展
当未检索出相关文档,需要llm自主回答时:
from llama_index.core.query_engine import BaseQueryEngine
from llama_index.core import get_response_synthesizer
from typing import Optional, Any
class SmartQueryEngine(BaseQueryEngine):
def __init__(
self,
retriever,
response_synthesizer=None,
empty_response_prompt="请根据你的知识回答以下问题:\n{query_str}",
similarity_threshold=0.4
):
super().__init__()
self.retriever = retriever
self.response_synthesizer = response_synthesizer or get_response_synthesizer()
self.empty_response_prompt = empty_response_prompt
self.similarity_threshold = similarity_threshold
def _query(self, query_str: str):
# 执行检索
nodes = self.retriever.retrieve(query_str)
# 判断逻辑
if len(nodes) == 0 or max(n.score for n in nodes) < self.similarity_threshold:
# 自主回答模式
prompt = self.empty_response_prompt.format(query_str=query_str)
response = self.response_synthesizer.llm.complete(prompt)
return Response(response=response.text, source_nodes=[])
else:
# 正常RAG模式
return self.response_synthesizer.synthesize(query_str, nodes)
async def _aquery(self, query_str: str):
# 异步实现(逻辑同_query)
...
# 初始化自定义引擎
smart_engine = SmartQueryEngine(
retriever=retriever,
similarity_threshold=0.5, # 自主回答阈值
empty_response_prompt=(
"你是一个专业助理,请直接回答用户问题,不要提及检索结果。\n"
"问题:{query_str}"
)
)
















 271
271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









