






- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
一、导包和基本配置
1.1 导入安装好的python库
首先导入了常用的python库,然后导入了一些pytorch库:
import ast
import contextlib
import json # 用于json和Pytho数据之间的相互转换
import math # 数学函数模块
import platform # 获取操作系统信息
import warnings #警告程序员关于语言或库功能的变化的方法
import zipfile
from collections import OrderedDict, namedtuple
from copy import copy
from pathlib import Path # Path将str转换为Path对象,使字符串路径易于操作的模块
from urllib.parse import urlparse
import cv2 # 调用OpenCV的cv库
import numpy as np
import pandas as pd
import requests # Python的HTYP客服端库
import torch
import torch.nn as nn # 专门为神经网络设计的模块化接口
from PIL import Image # 图像基础操作模块
from torch.cuda import amp # 混合精度训练模块
1.2 加载自定义模块
from utils.datasets import exif_transpose, letterbox # 加载数据集的函数
from utils.general import (LOGGER, check_requirements, check_suffix, colorstr, increment_path, make_divisible,
non_max_suppression, scale_coords, xywh2xyxy, xyxy2xywh) # 定义了一些常用的工具函数
from utils.plots import Annotator, colors, plot_one_box # 定义了Annotator类,可以在图像上绘制矩形框和标注信息
from utils.torch_utils import time_sync # 定义了一些与PyTorch有关的工具函数
二、基础组件
2.1 autopad
autopad模块用于Conv函数核Classify函数中,根据输入的卷积核大小k,自动计算卷积核padding数(0填充)。
v5中只有两种卷积:1、下采样卷积:conv3x3 s=2 p=k//2=1
2、feature size 不变的卷积:conv1x1 s=1 p=k//2=1
def autopad(k, p=None): # kernel, padding
# Pad to 'same' shape outputs
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
2.2 Conv
Conv是标准卷积层函数,是整个网络中最核心的模块,由卷积层+BN层+激活函数组成。
**主要作用:**实现了将输入特征经过卷积层、激活函数、归一化层,得到输出层。同时可以指定是否使用归一化层。
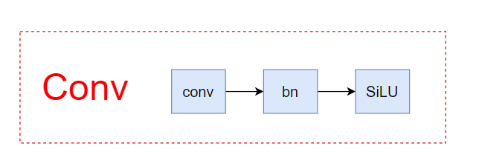
class Conv(nn.Module):
# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups,activation)
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
super().__init__()
# 卷积层
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
# 归一化层
self.bn = nn.BatchNorm2d(c2)
# 激活函数
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
# 正向计算,网络执行的顺序是根据forward函数来决定的
def forward(self, x):
# conv卷积 -> bn -> act激活
return self.act(self.bn(self.conv(x)))
# 正向融合计算
def forward_fuse(self, x):
# conv卷积 -> act激活
return self.act(self.conv(x))
注意:这个类中还有一个特殊函数fuseforward,这是一个前向加速推理模块,在前向传播过程中,通过融合conv+bn层,达到加速推理作用,一般用于测试或验证阶段。
2.3 DWConv
DWCov是GCONV的极端情况,深度分离(DepthWise)卷积层。
class DWConv(Conv):
# Depth-wise convolution
def __init__(self, c1, c2, k=1, s=1,act=True): # ch_in, ch_out, kernel, stride,activation
super().__init__(c1, c2, k, s, g=math.gcd(c1, c2),act=act)
2.4 Bottleneck
Bottleneck是一个标准的瓶颈层,由 1x1conv + 3x3conv + shortcut残差块 组成。在BottleneckCSP和yolo.py的parse_model中调用。
模型结构:
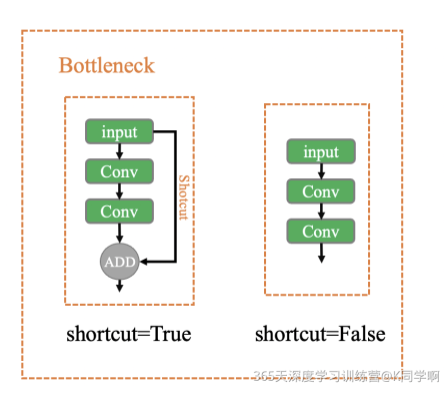
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
# 1*1卷积层
self.cv1 = Conv(c1, c_, 1, 1)
# 3*3卷积层
self.cv2 = Conv(c_, c2, 3, 1, g=g)
# shortcut=True 并且 c1==c2 才能做shortcut, 将输入和输出相加之后再输出
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
参数:
- c1:第一个卷积的输入channel
- c2:第二个卷积的输出channel
- shortcut:bool 是否有shortcut连接,默认为True
- g:表示从输入通道到输出通道的阻塞连接数。卷积分组的个数: =1就是普通卷积 >1就是深度可分离卷积
- e:expansion ratio e*c2 就是第一个卷积的输出channel=第二个卷积的输入channel
2.5 BottleneckCSP
BottleneckCSP也是瓶颈层,由几个Bottleenck模块的堆叠 + CSP结构 组成。
模块结构:
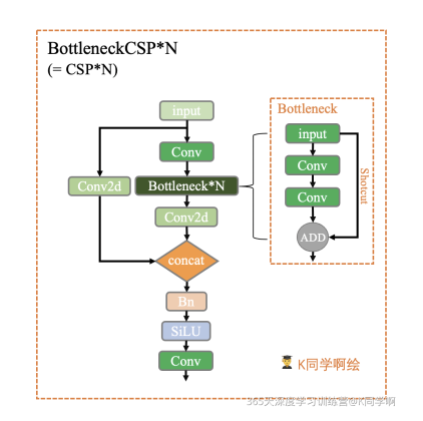
class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
# 4个1*1卷积层的堆叠
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
self.cv4 = Conv(2 * c_, c2, 1, 1)
# bn层
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
# 激活函数
self.act = nn.SiLU()
# m:叠加n次Bottleneck的操作
# 操作符*可以把一个list拆开成一个个独立的元素
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), 1))))
参数:
- c1:整个BottleneckCSP的输入channel
- c2:整个BottleneckCSP的输出channel
- n:有n个Bottleneck
- shortcut:bool Bottleneck中是否有shortcut连接,默认为True
- g:表示从输入通道到输出通道的阻塞连接数。Bottleneck中的3x3卷积类型: =1就是普通卷积 >1就是深度可分离卷积
- e:expansion ratio c2xe=中间其他所有层的卷积核个数/中间所有层的输入输出channel数
- torch.cat((y1,y2), dim=1):这里是指定第11个维度上进行合并,即再channel维度上合并
- c_:bottleneckCSP结构的中间层的通道数,由膨胀率e决定
2.6 C3
C3是一种简化版的BottleneckCSP,模块和BottleneckCSP模块类似,但是少一个Conv模块,只有3个卷积,可以减少参数,所以取名C3。
模块结构:
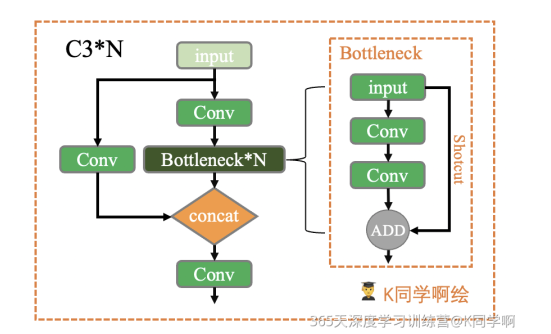
在C3TR模块和yolo.py的parse_model模块调用。
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
# 3个1*1卷积层的堆叠,比BottleneckCSP少一个
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
# 将第一个卷积层和第二个卷积层的结果拼接在一起
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
参数:
- c1:整个BottleneckCSP的输入channel
- c2:整个BottleneckCSP的输出channel
- n:有n个Bottleneck
- shortcut:bool Bottleneck中是否有shortcut连接,默认为True
- g:表示从输入通道到输出通道的阻塞连接数。Bottleneck中的3x3卷积类型: =1就是普通卷积 >1就是深度可分离卷积
- e:expansion ratio c2xe=中间其他所有层的卷积核个数/中间所有层的输入输出channel数
- torch.cat((y1,y2), dim=1):这里是指定第11个维度上进行合并,即再channel维度上合并
- c_:bottleneckCSP结构的中间层的通道数,由膨胀率e决定
2.7 SPP
SPP(Spatial Pyramid Pooling)空间金字塔池化模块,用在骨干网络收尾阶段,用于融合多尺度特征。这个模块的主要作用是为了将更过不同分辨率的特征进行融合,得到更多的信息。
高层网络层的感受野的语义信息表征能力强,低层网络层的感受野空间细节信息表征能力强。
SPP是目标检测算法中对高层特征进行多尺度池化以增加感受野的重要措施之一。
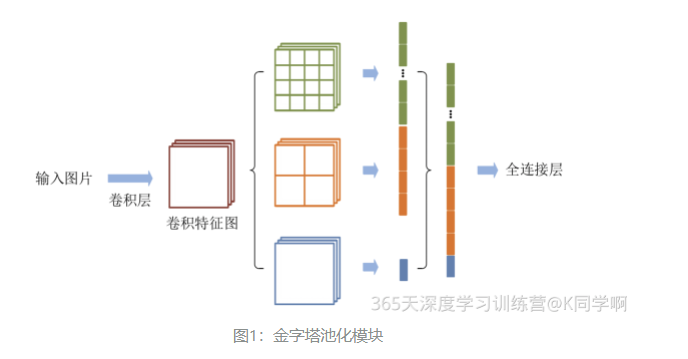
**经典的空间金字塔池化模块:**1、将输入的卷积特征分成不同尺寸 ----> 2、每个尺寸提取固定维度的特征 ----> 3、将这些特征拼接成一个固定的维度。
**如图所示:**输入的卷积特征图的大小为(w,h),
**第一层空间金字塔:**采用 4*4 的刻度对特征图进行划分,其将输入的特征图分成 16 个块,每块大小为 (w/4, h/4) ;
**第二层空间金字塔:**采用 2*2 的刻度对特征图进行划分,其将输入的特征图分成 4 个块,每块大小为 (w/2, h/2) ;
**第三层空间金字塔:**将整张特征图作为一块,今昔特征提取操作,最终的特征向量为 21=16+4+1 维。
模块结构:
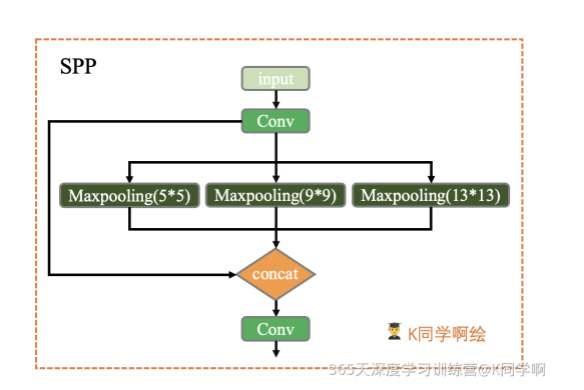
class SPP(nn.Module):
# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
def __init__(self, c1, c2, k=(5, 9, 13)):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
2.8 Contract
Contract是收缩模块。调整张量的大小,将宽高收缩到通道中。
Contract 函数改变输入特征的shape,将feature map的 w 和 h 维度(缩小)的数据收缩到channel维度上(放大)。
如:当gain = 2时,x(1,64,80,80)的图像 ----> x(1,256,40,40)的图像。其操作类Focus,但更灵活,并且少一个卷积。
class Contract(nn.Module):
# Contract width-height into channels, i.e. x(1,64,80,80) to x(1,256,40,40)
def __init__(self, gain=2):
super().__init__()
self.gain = gain
def forward(self, x):
b, c, h, w = x.size() # assert (h / s == 0) and (W / s == 0), 'Indivisible gain'
s = self.gain
x = x.view(b, c, h // s, s, w // s, s) # x(1,64,40,2,40,2)
# permute:改变tensor的维度顺序
x = x.permute(0, 3, 5, 1, 2, 4).contiguous() # x(1,2,2,64,40,40)
# .view:改变tensor的维度
return x.view(b, c * s * s, h // s, w // s) # x(1,256,40,40)
2.9 Expand
Expand是Contract的你操作,扩张模块,将特征图像素变大。用在yolo.py的parse_model模块,用得不多。
改变输入特征的shape,是将channel维度(变小)的数据扩展到W和H维度(变大)。
如:当gain = 2时,x(1,64,80,80)的图像 ----> x(1,16,160,160)的图像。
class Expand(nn.Module):
# Expand channels into width-height, i.e. x(1,64,80,80) to x(1,16,160,160)
def __init__(self, gain=2):
super().__init__()
self.gain = gain
def forward(self, x):
b, c, h, w = x.size() # assert C / s ** 2 == 0, 'Indivisible gain'
s = self.gain
x = x.view(b, s, s, c // s ** 2, h, w) # x(1,2,2,16,80,80)
x = x.permute(0, 3, 4, 1, 5, 2).contiguous() # x(1,16,80,2,80,2)
return x.view(b, c // s ** 2, h * s, w * s) # x(1,16,160,160)
2.10 Concat
Concat是拼接函数,将两个tensor拼接起来。在yolo.py的parse_model模块调用。
这个是自定义模块,dimension是维度值,说明沿着哪一个维度进行拼接。当dimension=1时,将多张相同尺寸的图像在通道维度上拼接(通道数可能不同)。
这个函数是讲自身(a list of tensors)按照某个维度进行concat,常用来合并前后两个feature map, 也就是yolov5结构图中的Concat。
class Concat(nn.Module):
# Concatenate a list of tensors along dimension
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
return torch.cat(x, self.d)
三、本周任务
本周任务:将YOLOv5s网络模型中的C3模块按照下图方式修改,并跑通YOLOv5。
**任务提示:**仅需修改./models/common.yaml文件。
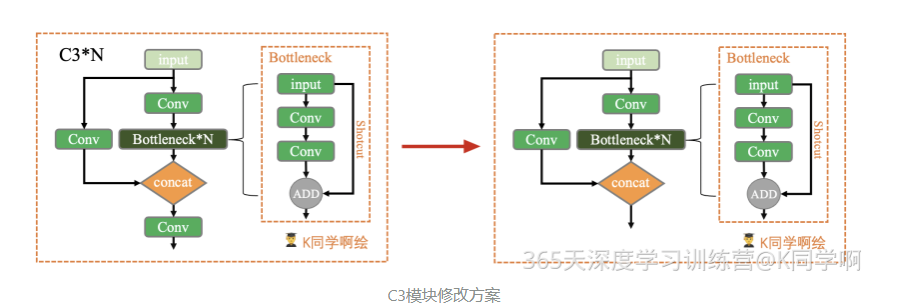
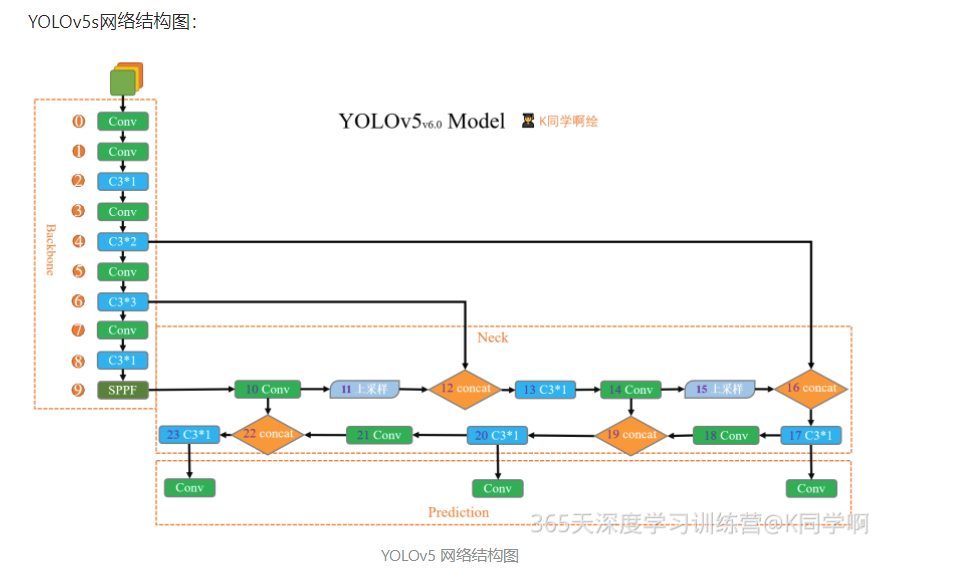
因此,修改后的代码为:
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2/2) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1)
执行命令:

运行结果:
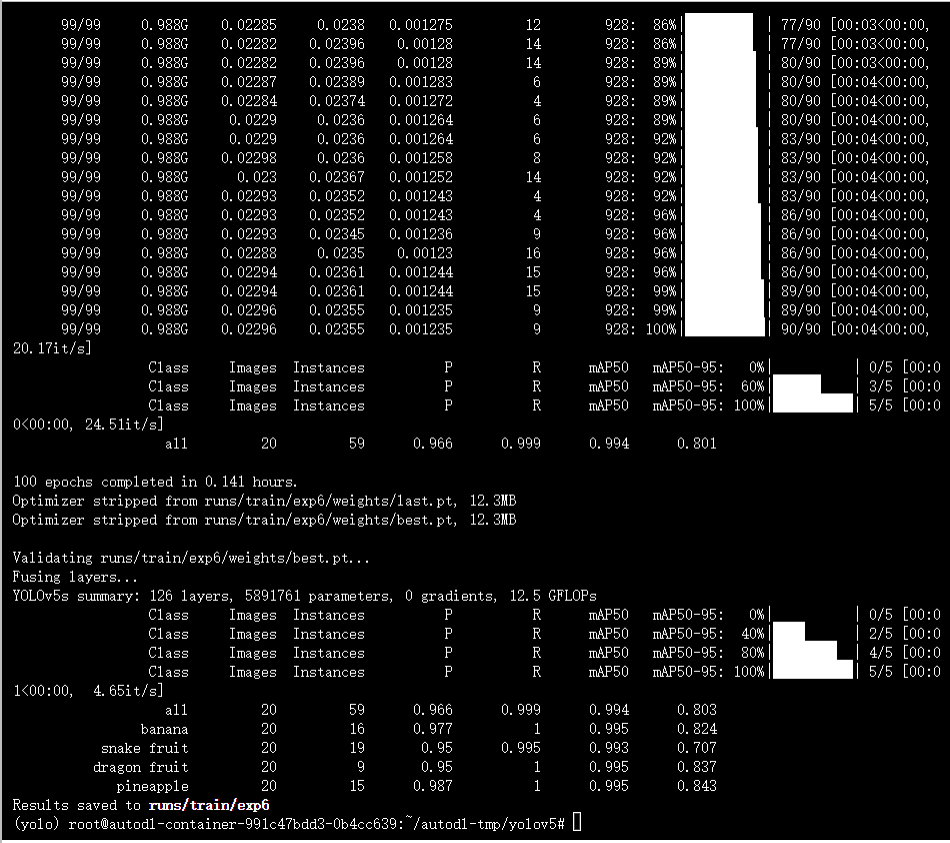
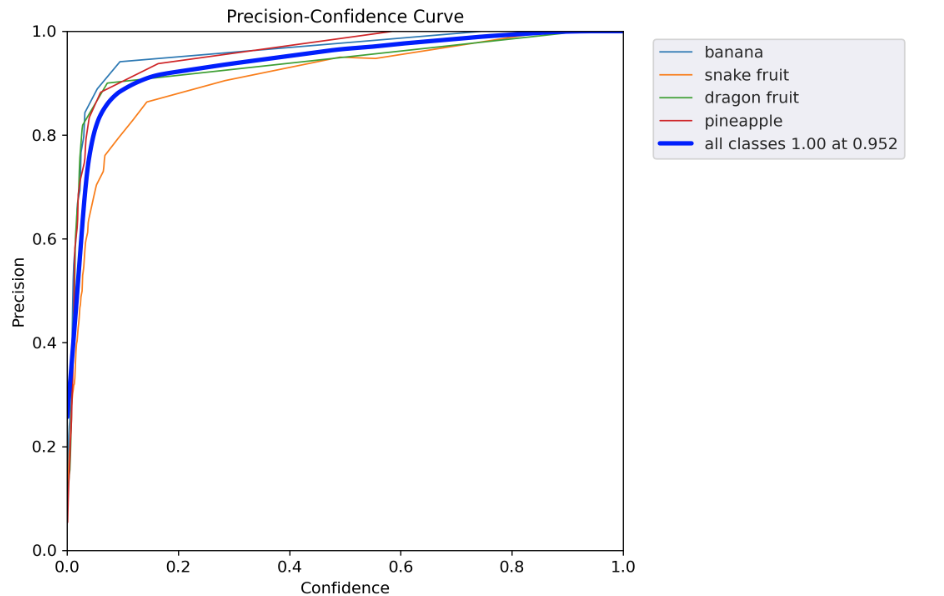
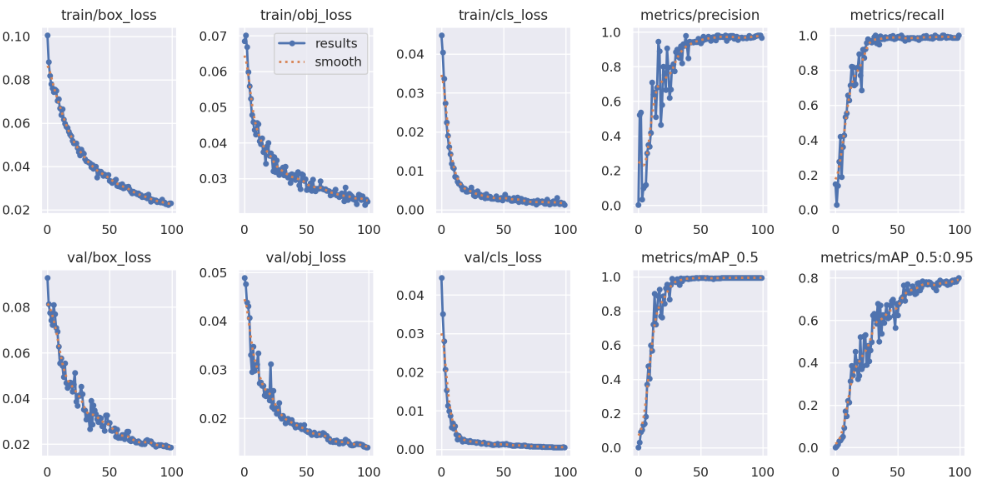

四、总结
由于最近都是考试周,忙于备考,因此这次关于yolov5中的common.py文件的解读,暂时只学习到了文件代码中的基础组件部分。
在common.py文件中代码最开始导入了需要的包,包括python的一些基本库和pytorch库。然后就是加载自定义模块,包括加载数据集的函数,一些与pytorch有关的工具函数。
然后就是学习了commom文件中基础组件,包括autopad用于根据输入的卷积核自动计算模块所需的pad值。Conv标准卷积层函数,将输入特诊经过卷积层、激活函数、归一化层,最终得到输出层。其中在该类中有一个特殊函数fuseforward,这是在测试或验证阶段用于加速推理的前向加速推理模块。DWCov是GCONV的极端情况,很少用。Bottleneck标准瓶颈层,用于提取特征,在BottleneckCSP中进行了调用。BottleneckCSP由Bottleneck模块和CSP结构组成的瓶颈层。C3模块是一个简化版的BottleneckCSP,与之相比,只是缺少一个Conv。但其效果如同作者所说simpler, faster and lighter。SPP空间金字塔池化,用在骨干网络收尾阶段,进行特征提取操作,融合得到更多的信息。Contract和Expand分别是收缩模块和扩张模块,调节特征图的像素大小。Concat是拼接函数,根据dimension的值来确定沿着哪个维度进行拼接。














 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









