






 文章介绍了病例对照研究的基本概念,包括其用于探究病因的特点、设计流程与核心特征。强调了在研究中防止和控制选择偏倚、信息偏倚和混杂偏倚的重要性,提到了匹配、分层分析和多因素分析等方法来校正这些偏倚。此外,还讨论了巢式病例对照研究的优势以及如何选择合适的对照群体。
文章介绍了病例对照研究的基本概念,包括其用于探究病因的特点、设计流程与核心特征。强调了在研究中防止和控制选择偏倚、信息偏倚和混杂偏倚的重要性,提到了匹配、分层分析和多因素分析等方法来校正这些偏倚。此外,还讨论了巢式病例对照研究的优势以及如何选择合适的对照群体。
目录
1.基本概念与特征
病例对照研究是以现在确诊的患有某特定疾病的病人作为病例,以不患有该病但具有可比性的个体作为对照,通过询问,实验室检查或复查病史,搜集既往各种可能的危险关素的暴露史,测量开比较病例组与对照纵中冬内素的暴露比例,经统计学检验,若两红差别有意义,则可认为人素与疾病之间存在着统计学上的关联。

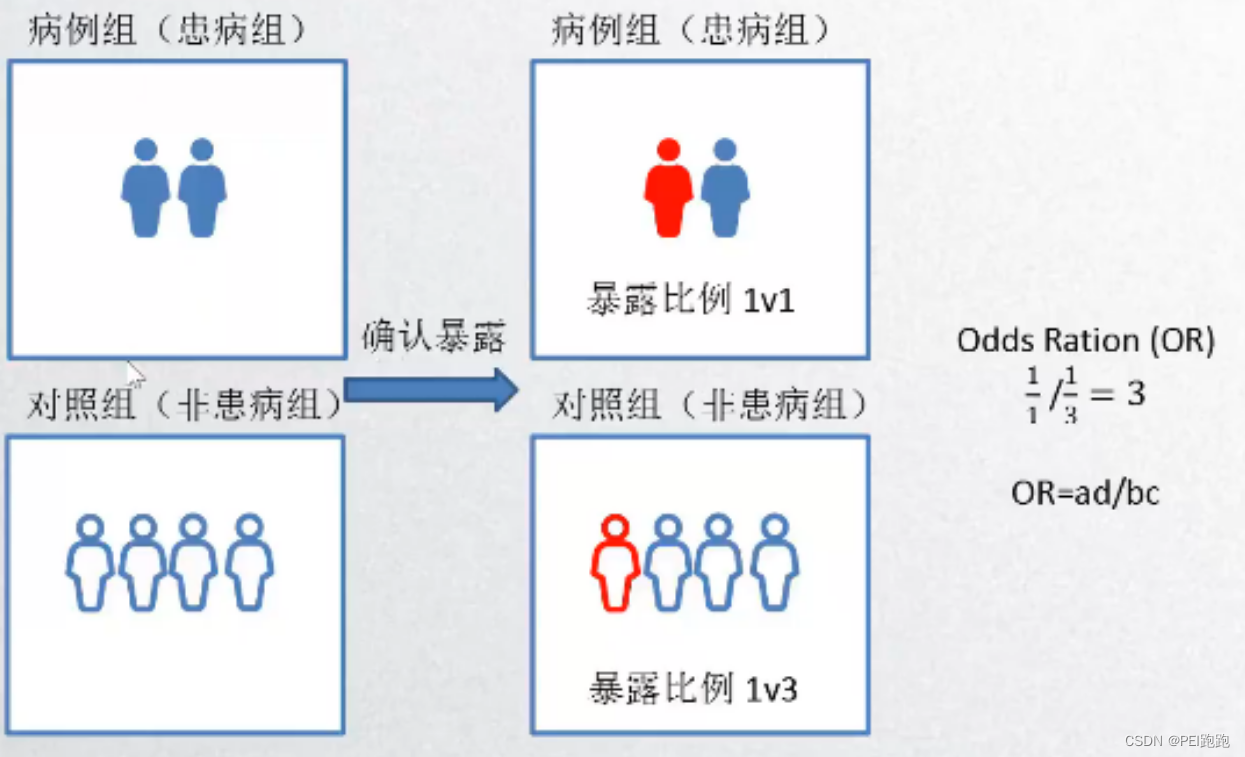
2. 病例对照研究设计的核心特征:
(1)探究病因:由果及内,计算OR值,无法计算发病率与RR,无法验证病因
(2)设立对照:病例组和对照组中多种暴露情况直接对比
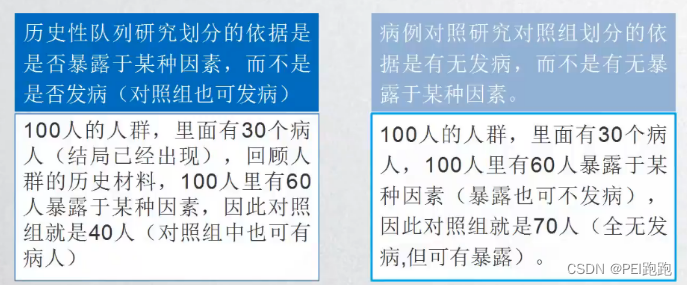
3.病例对照VS历史队列
病例对照研究: 以患某病人群作为病例组,以不患有该病但具有可比性人群作为对照组,回顾性地寻找暴露于预测变量的差异,研究预测变量与疾病之间的关联。
回顾性队列研究: 队列研究将某一特定人群按是否暴露及暴露程度分为不同亚组,追踪各组结局发生率,从而观察变量与结局之间有无因果关联及关联程度。回顾性队列研究队列的募集、基线测量及随访均发生在过去。
例如:
研究吸烟和肺癌的关系:

4.病例对照研究——设计流程与要点
(1)提出假设,明确研究问题
危险因素研究
预后因子研究
治疗疗效研究
(2)确定结局变量与研究要素
主要结局指标、次要结局指标
人口学因素
暴露因素
(3)确定研究人群(重点难点)
病例组来源(代表性)
对照组来源 (一致性)
(4)确定控制(匹配) 因素 是否要做匹配 匹配哪些因素
(5)确定数据收集方式 抽样方法
收集方法
(6)数据分析 描述统计 显著性检验 关联分析
5.病例对照研究设计——质控关注点
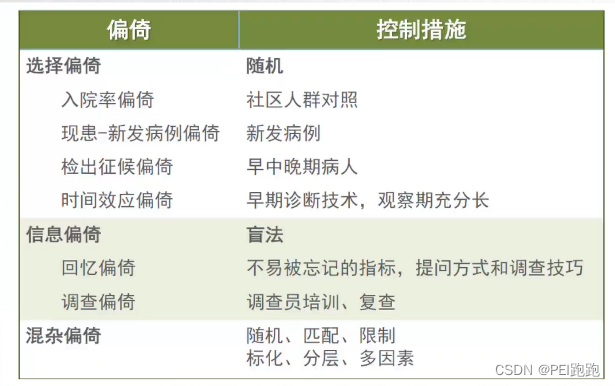
(1)病例对照组的选择靠谱么?(选择偏倚) 病例组一一诊断标准是否统一? (金标准,最好是新发病例? ) 对照组一一对照的选择是否独立于暴露因素?
(2)你拿到的信息是事实么?(信息偏倚) 回忆偏移一一他对我说实话了么?
调查偏移一一我是不是诱惑他说了我想听的话?
测量偏倚一一我是否更仔细对待这个患者的检查?
(3)你的患者分类正确么 ?(分类偏倚) 将一个病例错误地认为是健康人而分到对照组中去,或者将假阳性分到阳性者中,把假 阴性分到阴性者中去。暴露因素或者是疾病都会因错误分类而发生偏倚。
(4)不可避免的偏筒(混杂偏倚) 混杂偏倚即所研究因素的影响与其他外部因素的影响混在一起,不能分开的状况
案例:非留体类抗炎药是否能预防大肠癌

6.巢式病例对照
目的:病例组与对照组,在可能与暴露因素有关联的其他因素的分布上,是否基本保持一致?
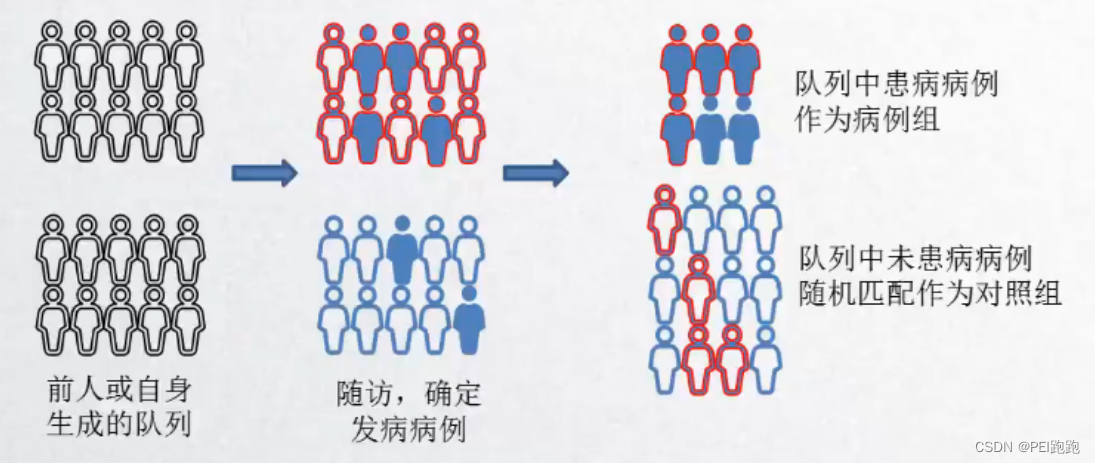
优点:
1、暴露资料在疾病诊断前就已经收集,选择性偏倚和信息偏倚小 2、病例和对照来源于同一队列,可比性较好
3、可以计算发病率,统计和检验效率高于传统的病例对照研究 4、 样本量小于队列研究,节省人力和物力
5、证据级别更强(本质上是个队列研究)
7.如何选择更好的对照
医院对照、伙伴对照……
8.匹配
目的:病例组与对照组,在可能与暴露因素有关联的其他因素的分布上,是否基本保持一致?
匹配(matching)
目的 剔除某些已知的可能的干扰因素
做法 对照与病例在某些因素与特征上保持一致
切忌 疾病因果链上的因素不应该匹配,如吸烟血脂 与心血管疾病
1、病例组和对照组不匹配
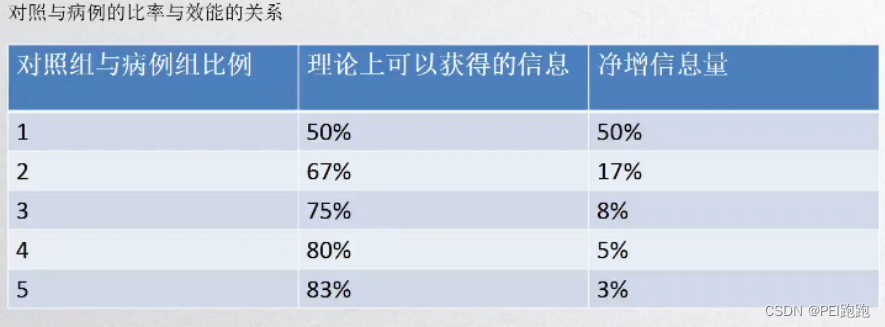
从研究设计规定的病例和对照人群中,分别抽取一定量的样本 对照组大于病例组
病例组和对照组要能代表人群的全部病例
2、频数匹配(成组匹配)
匹配因素在对照组和病例组所占的比例一致
3、个体匹配(配对)
以病例和个人为单位进行匹配
年龄、性别、分期等等 (1:1——1:4)
适合较为罕见的暴露因素
增加效能和控制混杂
避免过度匹配
过度匹配:
把不该匹配的因素进行了匹配,不仅增加了工作难度,而且该因素可能是所研究疾病的一个危险因素。由于参与匹配的因子不参与分析,导致信息丢失。通常性别和年龄是常用的匹配信息:
9.如何更好选择对照
病例组与对照组,在可能与暴露因素有关联的其他因素的分布上,是否基本保持一致?
混杂因素的特征
是研究结局的危险因素
与要研究的暴露因素有关联
但又不是暴露因素与结局之间的中间因素
病例组与对照组中该因素的分布不一致,即会导致混杂偏倚
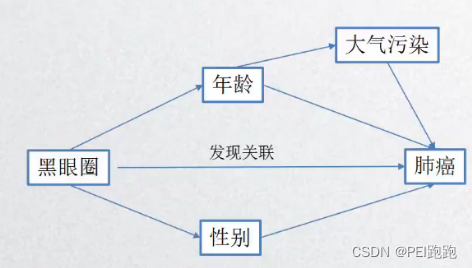
10.不可避免的偏倚(混杂偏倚)
混杂偏倚即所研究因素的影响与其他外部因素的影响混在一起,不能分开的状况
限制:入排标准加以限制。增加研究对象的同质性,提高内部有效性。(都吸烟)
匹配:病例对照研究匹配后还要进行分层分析。各组吸烟比例都是50%)
分层分析:将资料按照混杂因素分层。一次分析一种暴露-疾病关联: 连续变量转为离散变量丢失定程度的信息。
倾向性分析:手术/保守治疗患者在疾病程度、年龄、经济方面有较大不同,此此时采用倾向性分析。
多因素分析:将多个可能的混杂因素变量引入分析模型,可以是多元线性模型、logistics回归、比例风险模型、因子分析等。
偏倚控制方法:

















 3968
3968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









