






ORB特征
包含以下两部分:
- FAST角点提取:与原版不同的是计算了主方向
- BRIEF描述子:使用了先前计算的方向信息
FAST关键点
检测思想:如果一个像素与邻域像素差别较大,则可能为角点
检测过程如下:
BRIEF描述子
基本原理
BRIEF提供了一种计算二值串的捷径,而并不需要去计算一个类似于SIFT的特征描述子。它需要先平滑图像,然后在特征点周围选择一个Patch,在这个Patch内通过一种选定的方法来挑选出来nd个点对。然后对于每一个点对 ( p , q ) (p,q) (p,q),我们来比较这两个点的亮度值,如果 I ( p ) > I ( q ) I(p)>I(q) I(p)>I(q)则这个点对生成了二值串中一个的值为1,如果 I ( p ) < I ( q ) I(p)<I(q) I(p)<I(q),则对应在二值串中的值为-1,否则为0。所有nd个点对,都进行比较之间,我们就生成了一个nd长的二进制串。
对于nd的选择,我们可以设置为128,256或512,这三种参数在OpenCV中都有提供,但是OpenCV中默认的参数是256,这种情况下,非匹配点的汉明距离呈现均值为128比特征的高斯分布。一旦维数选定了,我们就可以用汉明距离来匹配这些描述子了。
点对选择(各种Pattern)
设我们在特征点的邻域块大小为S×S内选择nd个点对(p,q),Calonder的实验中测试了5种采样方法:
1)在图像块内平均采样;
2)p和q都符合 ( 0 , 1 25 S 2 ) \left ( 0,\frac{1}{25}S^2 \right ) (0,251S2)的高斯分布;
3)p符合 ( 0 , 1 25 S 2 ) \left ( 0,\frac{1}{25}S^2 \right ) (0,251S2)的高斯分布,而q符合 ( 0 , 1 100 S 2 ) \left ( 0,\frac{1}{100}S^2 \right ) (0,1001S2)的高斯分布;
4)在空间量化极坐标下的离散位置随机采样
5)把p固定为 ( 0 , 0 ) (0,0) (0,0),q在周围平均采样
下面是上面5种采样方法的结果示意图。

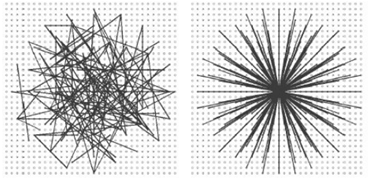
匹配(基于cv的Matcher)
汉明距离(Hamming distance)
用汉明距离(Hamming distance)作为两个二进制串之间的距离(差异),指不同位数的个数。这个在计算机硬件层面可以直接用异或实现,很友好。
在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。例如:
1011101 与 1001001 之间的汉明距离是 2。
2143896 与 2233796 之间的汉明距离是 3。
“toned” 与 “roses” 之间的汉明距离是 3。
要决定有多少个位不同,只需将 xor 运算加诸于两个字码就可以,并在结果中计算有多个为1的位。两个字码中不同位值的数目称为汉明距离(Hamming distance) 。
OpenCV中的Matcher
特征点匹配位于feature2D的模块中所以在使用的时候应该在头文件中加入:
#include<opencv2/features2d/features2d.hpp>
模块中有三个类
继承关系如下:
cv::DescriptorMatcher
DescriptorMatcher的类型:
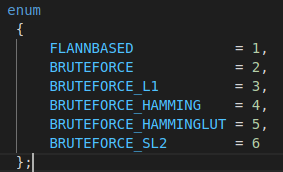
可以直接使用 DescriptorMatcher,参数如上图👆,示例如下👇
//BFMatcher 暴力匹配
vector<DMatch> BFmatches;
Ptr<DescriptorMatcher> BFMatcher = DescriptorMatcher::create("BruteForce-Hamming");
//Ptr<BFMatcher> Bmatcher = BFMatcher::create();
BFMatcher->match(descriptors1, descriptors2, BFmatches);
cv::BFMatcher
Brute-Force匹配器很简单,它取第一个集合里的一个特征的描述子与第二个集合里所有其他特征和它通过一些距离计算进行匹配,返回匹配最近的值。
对于BF匹配器,OPENCV中首先得用 BFMatcher 类创建 BF 匹配器对象,它可取两个参数:第一个参数是 normType,它指定要使用的距离量度。默认是NORM_L2。对于SIFT,SURF很好。(还有NORM_L1)。对于二进制字符串的描述子,比如ORB,BRIEF,BRISK等,应该用NORM_HAMMING。使用Hamming距离度量,如果ORB使用VTA_K == 3或者4,应该用NORM_HAMMING2。第二个参数是布尔变量,crossCheck 默认值是false。如果设置为True,匹配条件就会更加严格,只有到A中的第i个特征点与B中的第j个特征点距离最近,并且B中的第j个特征点到A中的第i个特征点也是最近时才会返回最佳匹配(i,j), 即这两个特征点要互相匹配才行。
BFMatcher对象有两个方法 BFMatcher.match() 和 BFMatcher.knnMatch()。第一个方法会返回最佳匹配。第二个方法为每个关键点返回k个最佳匹配,其中k是由用户设定的。
cv::FlannBasedMatcher
Flann-based matcher 使用快速近似最近邻搜索算法寻找(用快速的第三方库近似最近邻搜索算法),示例如下👇
//FlannBasedMatcher:
vector<DMatch> FlannMatches;
Ptr<FlannBasedMatcher> FlannMatcher = FlannBasedMatcher::create();
FlannMatcher->match(descriptors1, descriptors2, FlannMatches);
两种方法的比较
两者的区别在于BFMatcher总是尝试所有可能的匹配,从而使得它总能够找到最佳匹配,这也是Brute Force(暴力法)的原始含义。而FlannBasedMatcher中FLANN的含义是Fast Library for Approximate Nearest Neighbors,从字面意思可知它是一种近似法,算法更快但是找到的是最近邻近似匹配,所以当我们需要找到一个相对好的匹配但是不需要最佳匹配的时候往往使用FlannBasedMatcher。当然也可以通过调整FlannBasedMatcher的参数来提高匹配的精度或者提高算法速度,但是相应地算法速度或者算法精度会受到影响。
此外,使用特征提取过程得到的特征描述符(descriptor)数据类型有的是float类型的,比如SurfDescriptorExtractor,SiftDescriptorExtractor。有的是uchar类型的,比如说有ORB,BriefDescriptorExtractor。对应uchar类型的匹配方式只有BruteForce(大概?)。所以ORB和BRIEF特征描述子只能使用BruteForce匹配法。
匹配优化
在比对描述值相似度的方法中,最简单直观的方法就是使用暴力匹配方法(Brute-Froce Matcher),即计算某一个特征点描述子与其他所有特征点描述子之间的距离,然后将得到的距离进行排序,取距离最近的一个作为匹配点。这种方法简单粗暴,其结果也是显而易见的,但也可能有大量的错误匹配,这就需要使用一些机制来过滤掉错误的匹配。
1. 汉明距离小于最小距离的两倍
经典的方法有汉明距离小于最小距离的两倍,选择已经匹配的点对的汉明距离不大于最小距离的两倍作为判断依据,如果不大于该值则认为是一个正确的匹配;大于该值则认为是一个错误的匹配。
// 匹配对筛选
double min_dist = 1000, max_dist = 0;
// 找出所有匹配之间的最大值和最小值
for (int i = 0; i < descriptors1.rows; i++)
{
double dist = matches[i].distance;
if (dist < min_dist) min_dist = dist;
if (dist > max_dist) max_dist = dist;
}
// 当描述子之间的匹配大于2倍的最小距离时,即认为该匹配是一个错误的匹配。
// 但有时描述子之间的最小距离非常小,可以设置一个经验值作为下限
vector<DMatch> good_matches;
for (int i = 0; i < descriptors1.rows; i++)
{
if (matches[i].distance <= max(2 * min_dist, 30.0))
good_matches.push_back(matches[i]);
}
2. 交叉匹配(BFMatcher的第二个参数可以实现)
针对暴力匹配,可以使用交叉匹配的方法来过滤错误的匹配。交叉过滤的思想是再进行一次匹配,反过来使用被匹配到的点进行匹配,如果匹配到的仍然是第一次匹配的点的话,就认为这是一个正确的匹配。举例来说就是,假如第一次特征点A使用暴力匹配的方法,匹配到的特征点是特征点B;反过来,使用特征点B进行匹配,如果匹配到的仍然是特征点A,则就认为这是一个正确的匹配,否则就是一个错误的匹配。OpenCV中BFMatcher已经封装了该方法,创建BFMatcher的实例时,第二个参数传入true即可,BFMatcher bfMatcher(NORM_HAMMING,true)。
3. KNN匹配
在匹配过程中,为了排除因为图像遮挡和背景混乱而产生的无匹配关系的关键点,SIFT的作者Lowe提出了比较最近邻距离与次近邻距离的SIFT匹配方式:取一幅图像中的一个SIFT关键点,并找出其与另一幅图像中欧式距离最近的前两个关键点,在这两个关键点中,如果最近的距离除以次近的距离得到的比率ratio少于某个阈值T,则接受这一对匹配点。因为对于错误匹配,由于特征空间的高维性,相似的距离可能有大量其他的错误匹配,从而它的ratio值比较高。显然降低这个比例阈值T,SIFT匹配点数目会减少,但更加稳定,反之亦然。
const float minRatio = 1.f / 1.5f;
const int k = 2;
vector<vector<DMatch>> knnMatches;
matcher->knnMatch(leftPattern->descriptors, rightPattern->descriptors, knnMatches, k);
for (size_t i = 0; i < knnMatches.size(); i++) {
const DMatch& bestMatch = knnMatches[i][0];
const DMatch& betterMatch = knnMatches[i][1];
float distanceRatio = bestMatch.distance / betterMatch.distance;
if (distanceRatio < minRatio)
matches.push_back(bestMatch);
}















 2648
2648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









