





训练效果差
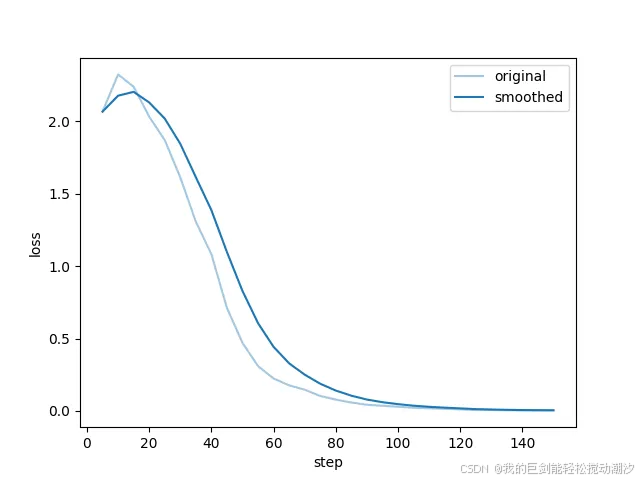
个人感觉,深蓝和浅蓝的线最后没合并在一起,效果会很差。
建议:加大轮数。但听说加太大也不好,要找个中间值。
格式冲突引发了训练出错和聊天时格式报错
1.训练出错
情况:训练出错
可能原因:
1.检查点有训练集,然后和现在训练的样本格式不一样。
2.再点一次开始可能就好了。

2.聊天报错
情况:2个训练集放一起,然后chat,问问题返回格式出错
可能原因:
1.检查点训练集格式不统一

个人感觉,深蓝和浅蓝的线最后没合并在一起,效果会很差。
建议:加大轮数。但听说加太大也不好,要找个中间值。
1.训练出错
情况:训练出错
可能原因:
1.检查点有训练集,然后和现在训练的样本格式不一样。
2.再点一次开始可能就好了。
2.聊天报错
情况:2个训练集放一起,然后chat,问问题返回格式出错
可能原因:
1.检查点训练集格式不统一
 2367
2367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























