







1.先验概率
以抛硬币为例,假如有人告诉我们所抛硬币正面朝上的概率p1=0.7,反面朝上的概率p2=0.3。在这种情况下,我们会倾向预测结果是正面,因为0.7>0.3,此时错误率就是1-0.7=0.3,也就是反面朝上的概率。
对于这种在观测前我们就知道的概率p1和p2就是先验概率(指的是在观测前我们就已知的结果概率分布 p(y))。此时我们不需要考虑其他因素,例如硬币的大小、质量等等。
2.后验概率
但在实际情况中,往往有很多因素会对我们的预测结果造成不同程度的影响,而并不是像前面一样不考虑其他因素的影响,所以就有了当……因素时,硬币……的概率是多少,当硬币正面朝上时用数学表达式就是p(y=1|x),当硬币反面朝上时用数学表达式就是p(y=0|x)。这里的x指的是影响预测结果的因素。
3.引入贝叶斯公式求解后验概率
后验概率这种表达叫做条件概率(conditional probability),一般写作 p(A|B) ,即仅当B事件发生时A发生的的概率,假设p(A)和p(B)都大于0,则有:

于是我们的后验概率就有:
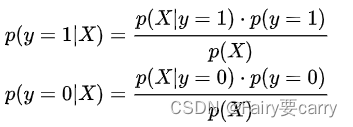
举个例子
假设做了100次硬币实验,有大中小三种硬币(x)。其中30次结果是反面(y=0),在反面时小硬币出现6次。在70次正面向上的情况中(y=1) 小硬币出现了7次。我们此时假设x指的是小硬币,观察公式:
1、分母p(x)代表观测x为小硬币出现的概率,那么p(x)=(6+7)/100=0.13
2、分子上的p(x|y=0)代表当结果是反面时,小硬币的概率。有实验结果可知:p(x|y=0)=6/30=0.2。而分子上的p(y=0)=30/100=0.34
于是我们就可以因此计算当观测到小硬币时反面的后验概率:
p(y=0|x)=(0.2*0.3)/0.13=0.46
同理也可计算观测到小硬币时正面的后验概率:
p(y=1|x)=(0.1*0.7)/0.13=0.54
**贝叶斯决策的预测值是选取后验概率最大的结果。**在二分类问题中,也就是对比p(y=0|x) 和p(y=1|x)的结果。因为0.54>0.46,因此我们认为观测到小硬币时的结果是正面的概率更大。
贝叶斯决策论的不足之处
贝叶斯决策中假设比较强,实际操作起来并不容易:
很喜欢原作者的这一段话:
抛开统计学习不谈,贝叶斯思想是对生活也很有指导意义,毕竟我们总是不断利用先验(过往的经验)和观测到现象(x)做出决策(试图得到后验概率)。那为什么懂了那么多道理(规则),却依然过不好这一生呢(误差太大)?根本原因在于别人的先验和我们的可能差别太大了,最终导致了过高的方差以至于过拟合(笑)。
4.朴素贝叶斯分类算法
1.核心算法


2.朴素贝叶斯的特点:
1. 简化计算和降低模型复杂度 :假设特征之间相互独立,意味着每个特征对于类别的影响是独立的,不受其他特征的影响。这样,联合概率分布可以分解为各个特征的单独概率的乘积。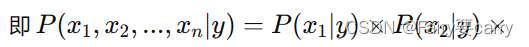
这种独立性假设大大简化了计算,因为对于每个特征的概率估计可以单独进行,不需要考虑特征之间的组合情况。这样就大大降低了模型的复杂度和计算成本。
2. 解决高维特征空间下的稀疏性问题
在现实生活中,数据往往具有高维特征空间的特点(特征数多纬度高),即特征的取值非常多,导致样本在整个特征空间中的分布非常稀疏。如果不做特征独立的假设,需要统计每种特征组合下的样本数量,这对于数据量有限的情况下可能会导致很多组合的样本数量为零,从而无法准确估计概率。
通过假设特征之间相互独立,我们可以将整个特征空间拆解为单个特征的概率估计,每个特征的取值数量相对较少,这样可以避免统计上的稀疏性问题,使得概率估计更加可靠和准确。
3.缺点:
朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
3.例子

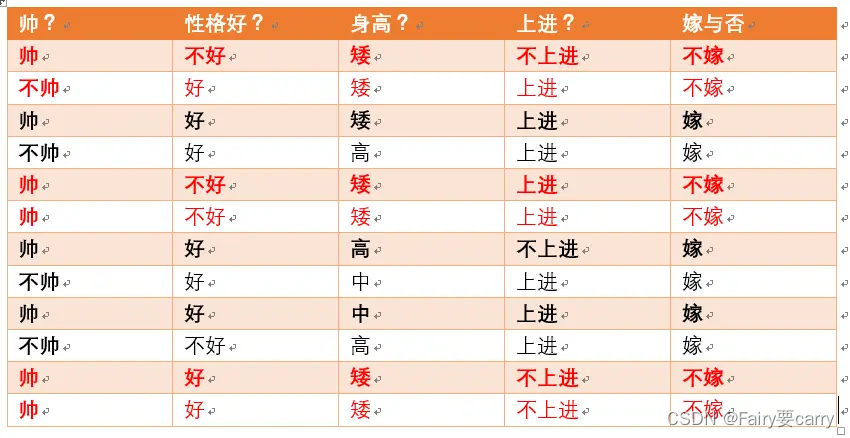
https://zhuanlan.zhihu.com/p/26262151


















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











