







 本文详细介绍了如何在Windows环境中创建并激活名为yolov9的虚拟环境,安装CUDA、PyTorch等深度学习库,并配置YOLOv9的需求包、数据指引文件和train_dual.py参数,以优化GPU使用效率。
本文详细介绍了如何在Windows环境中创建并激活名为yolov9的虚拟环境,安装CUDA、PyTorch等深度学习库,并配置YOLOv9的需求包、数据指引文件和train_dual.py参数,以优化GPU使用效率。
一、创建新的虚拟环境
1、打开Anaconda Powershell Prompt(AnacondaInstall)

2、导入YOLOv9程序的目录
指令格式为 cd ......(YOLOv9程序的绝对路径)


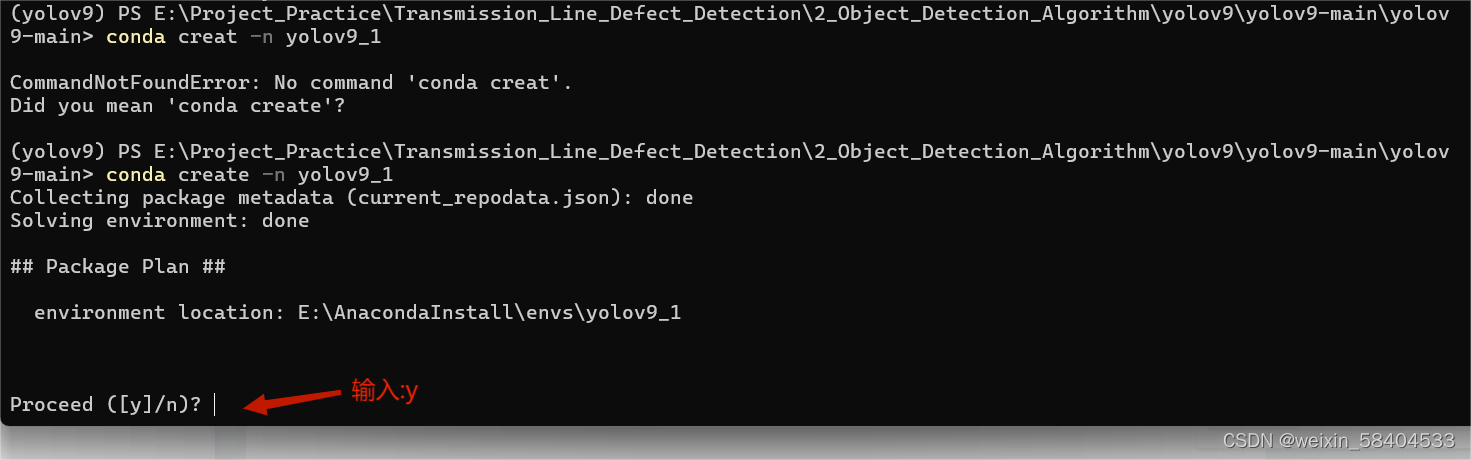
3、创建名为yolov9的虚拟环境
终端命令输入以下指令,创建一个名为yolov9(命名可以按自己习惯)的虚拟环境,其python版本为3.8(视自己情况设置)
conda create -n yolov9 python=3.8y/n时输入y,继续创建虚拟环境
4、激活yolov9虚拟环境
终端命令输入以下指令
conda activate yolov9效果如下:

二、安装CUDA、Pytorch、Torchversion三者匹配的深度学习环境
1、查看设备支持的CUDA最高版本
终端命令输入以下指令
nvidia-smi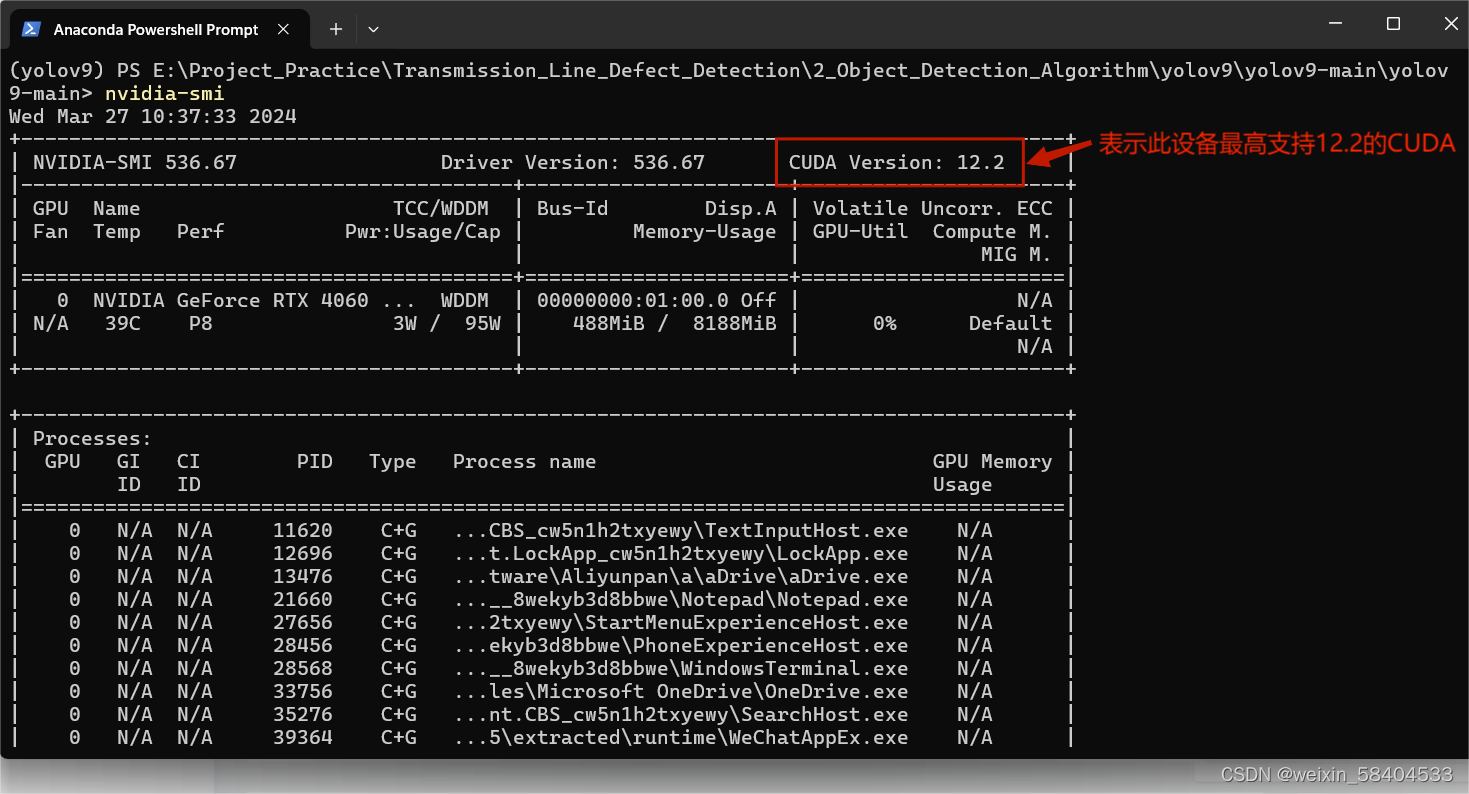
2、PyTorch官网下载版本为12.1的CUDA
官网链接如下
Previous PyTorch Versions | PyTorch Installing previous versions of PyTorch![]() https://pytorch.org/get-started/previous-versions/终端命令输入以下图片指示的代码:
https://pytorch.org/get-started/previous-versions/终端命令输入以下图片指示的代码:
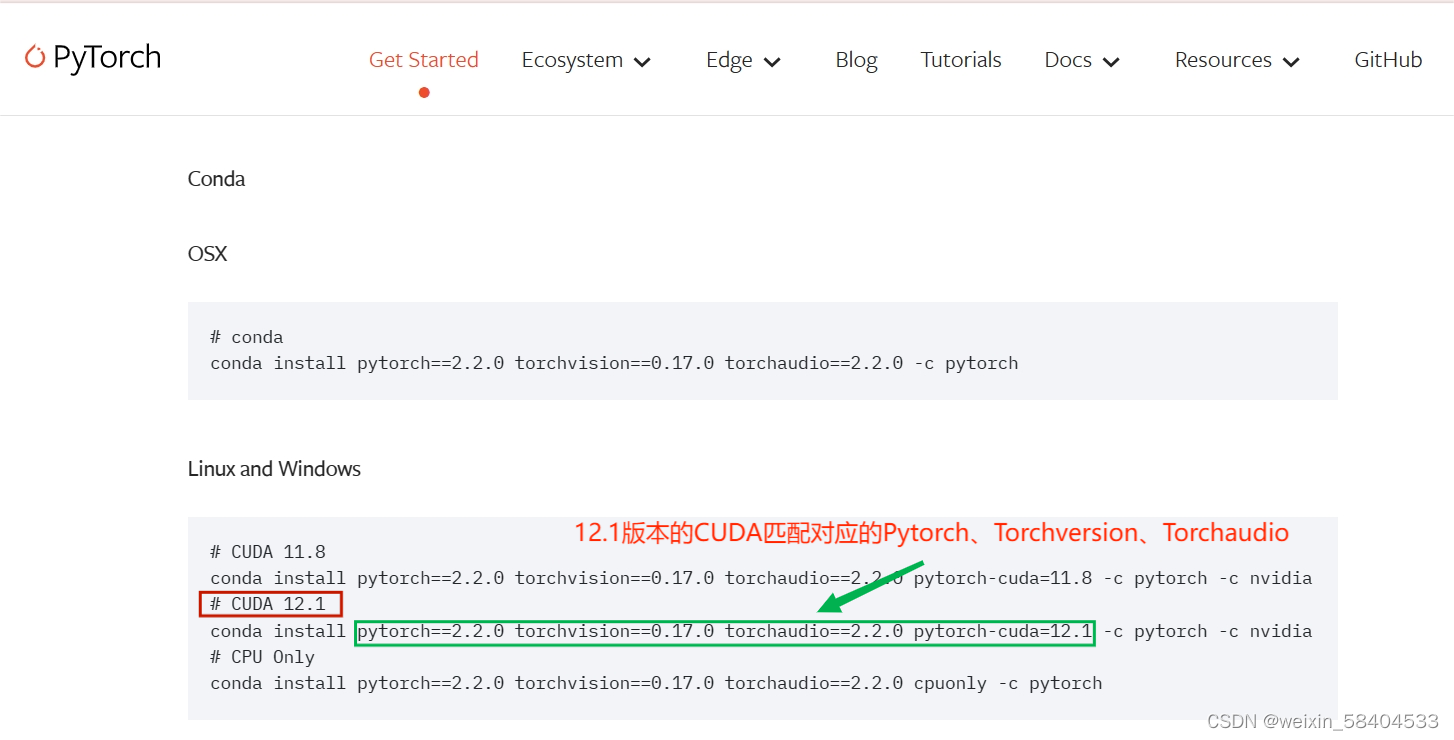
# CUDA 12.1
conda install pytorch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 pytorch-cuda=12.1 -c pytorch -c nvidia特别提醒:
出现GPU占用率不高的一般原因:
(1)安装的CUDA版本超过了支持的设备最高版本
(2)CUDA、Pytorch、Torchversion、Torchaudio版本不对应
(3)works、batch-size参数设置过小
三、安装YOLOv9自带的需求包requirements.txt
1、终端命令输入指令
#不加清华源
pip install -r requirements.txt
注意一定要在根目录下有requirements.txt文件。
2、若下载requirements.txt(或者其他第三方库)速度过慢可以尝试加清华源后下载
清华源代码如下:
conda config --remove-key channels
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple四、修改数据指引文件coco.yaml
注明训练集、验证集和测试集的绝对路径,注意用正斜杠“/”,并且将自己数据集的标签类别标明
以下是示例:
train: E:/Project_Practice/Insulator_Defect_detection/Du_Data/pin_defect/images/train
val: E:/Project_Practice/Insulator_Defect_detection/Du_Data/pin_defect/images/test
test: E:/Project_Practice/Insulator_Defect_detection/Du_Data/pin_defect/images/test
# Classes
names:
0: pin_defect
五、修改train_dual.py的参数
1、修改路径(此处注意用的是正斜杠“/”,而电脑目录一般用的是反斜杠“\”,建议都用绝对路径)
(1)data为数据路径,coco.yaml中需写明训练集、测试集的路径等信息
(2)cfg为网络结构路径,yolov9-c.yaml是yolov9原模型的网络结构
(3)project为模型训练结果保存路径,为防止混乱,建议一个模型改一个保存路径
(4)weights为权重路径
(5)hpy为超参数路径
parser.add_argument('--data', type=str, default= 'E:/Project_Practice/Transmission_Line_Defect_Detection/2_Object_Detection_Algorithm/yolov9/yolov9-main/yolov9-main/data/coco.yaml', help='dataset.yaml path')
parser.add_argument('--cfg', type=str, default= 'E:/Project_Practice/Transmission_Line_Defect_Detection/2_Object_Detection_Algorithm/yolov9/yolov9-main/yolov9-main/models/detect/yolov9-c.yaml', help='model.yaml path')
parser.add_argument('--project', default=ROOT / 'runs/yolov9_pin', help='save to project/name')
parser.add_argument('--weights', type=str, default=ROOT / 'yolov9-c-converted.pt', help='initial weights path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-high.yaml',help='hyperparameters path')2、修改训练参数
(1)epochs为训练轮次
(2)batch-size为一次训练所抓取的数据样本数量,应为2的n次方
(3)wokers为装载数据时CPU的线程数,应为2的n次方
parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
parser.add_argument('--batch-size', type=int, default=4, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--workers', type=int, default=4, help='max dataloader workers (per RANK in DDP mode)')六、运行train_dual.py训练自己的数据集
步骤及效果如下:
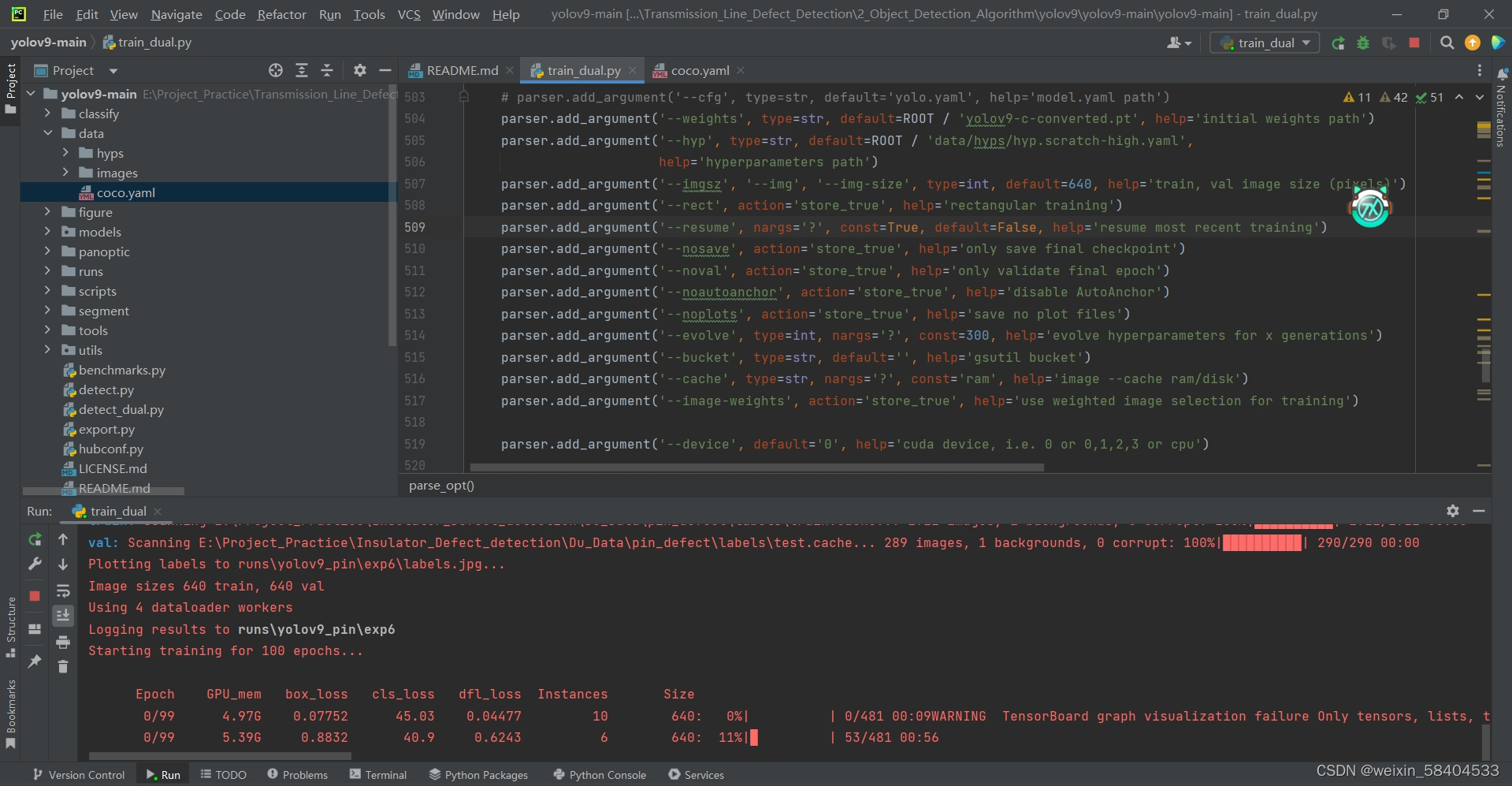
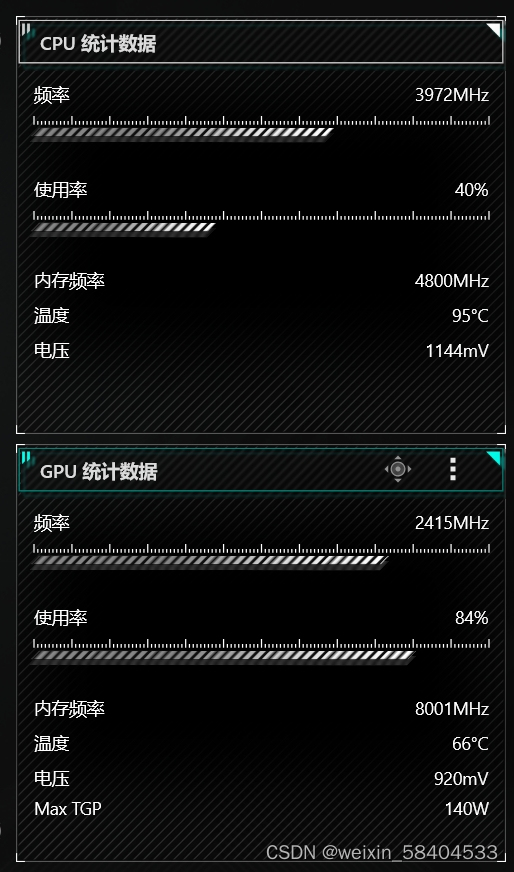
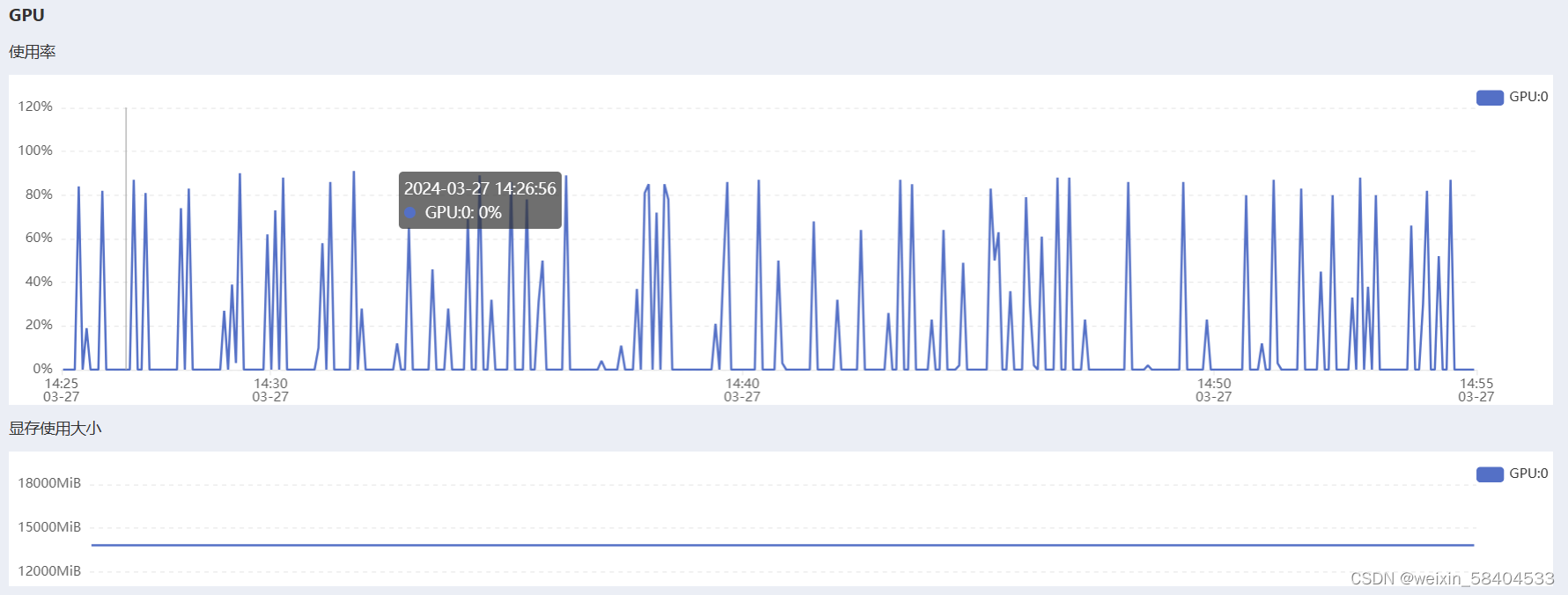
可见,经过以上环境配置,GPU占有率在80~90%的合适区间,以下是在AutoDL上租服务器跑时的GPU占有率情况。(之前自己走过弯路,训练时间非常长,以此文总结心得和收获)















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









