






大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。
本周精选了10篇LLM领域的优秀论文,来自Meta AI、浙江大学、清华大学、苏黎世联邦理工学院等机构。
1
SeamlessM4T-Massively Multilingual & Multimodal Machine Translation
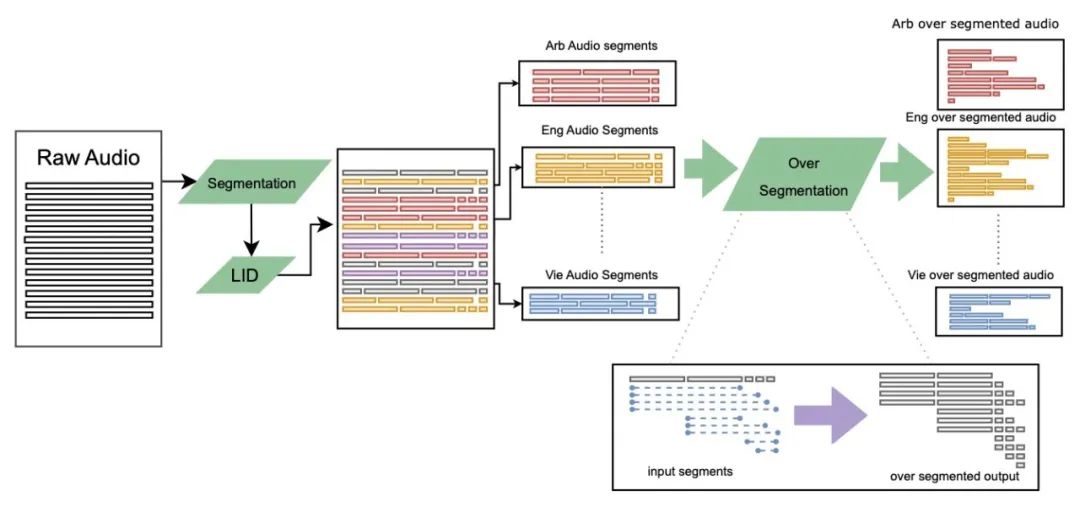
这篇论文介绍了一种名为 SeamlessM4T 的大规模多语言和多模态机器翻译模型,它可以帮助个人在多达 100 种语言之间进行语音翻译。尽管近期基于文本的模型突破了 200 种语言的翻译覆盖范围,但统一的语音到语音翻译模型尚未取得类似的进展。为了解决这个问题,作者提出了一个支持语音到语音翻译、语音到文本翻译、文本到语音翻译、文本到文本翻译和自动语音识别的单一模型。他们使用 100 万小时的开放语音音频数据来学习自我监督的语音表示,并创建了一个多模态的自动对齐语音翻译语料库。通过过滤和人类标注以及伪标签数据,他们开发了第一个能翻译成和从英语到语音和文本的多语言系统。在 FLEURS 评估中,SeamlessM4T 在直接语音到文本翻译中取得了比之前最佳水平提高 20% 的 BLEU 评分。与强大的级联模型相比,SeamlessM4T 在语音到文本翻译中提高了 1.3 个 BLEU 点,在语音到语音翻译中提高了 2.6 个 ASR-BLEU 点。经过鲁棒性测试,该系统在语音到文本任务中对背景噪音和说话人变化表现得更好。作者还评估了 SeamlessM4T 在性别偏见和添加毒性方面的翻译安全性。最后,他们在 GitHub 上开源了所有贡献,以供更多人学习和使用。
链接:https://www.aminer.cn/pub/64e5849c3fda6d7f063af4d6
2
ChatHaruhi: Reviving Anime Character in Reality via Large Language Model
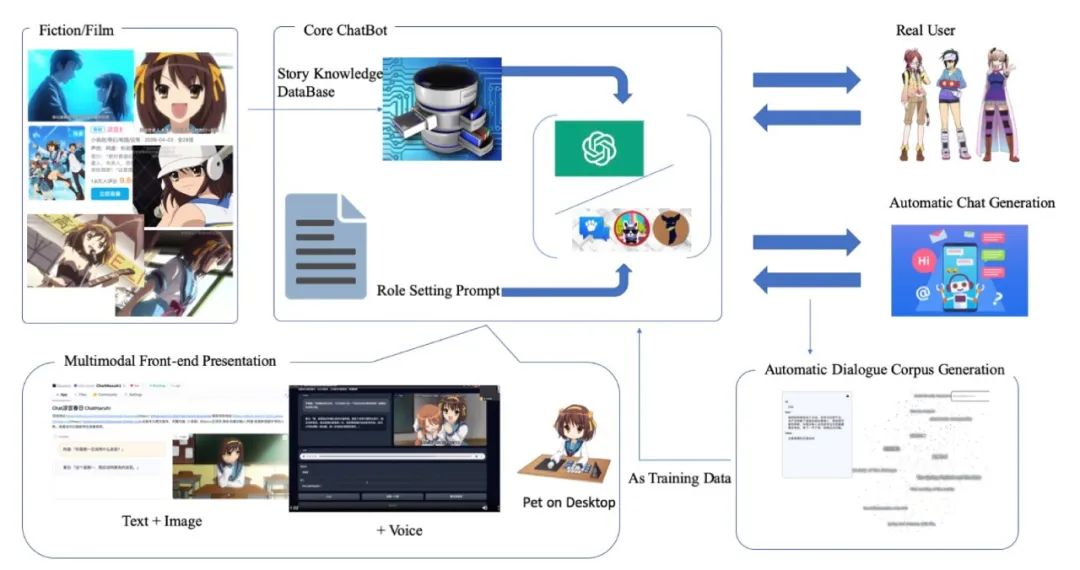
这篇论文介绍了一种通过大型语言模型复活动画角色的方法。尽管基于大型语言模型的角色扮演聊天机器人已经引起了关注,但还需要更好的技术来实现对特定虚构角色的模仿。论文提出了一种通过改进提示和从剧本中提取的角色记忆来控制语言模型的算法。作者构建了一个名为 ChatHaruhi 的数据集,涵盖了 32 个中英文电视剧和动画角色,共有超过 54,000 个模拟对话。自动和人类评估均显示,该方法在角色扮演能力上比基线方法有了显著提升。
链接:https://www.aminer.cn/pub/64e2e15a3fda6d7f06466a72
3
Instruction Tuning for Large Language Models: A Survey
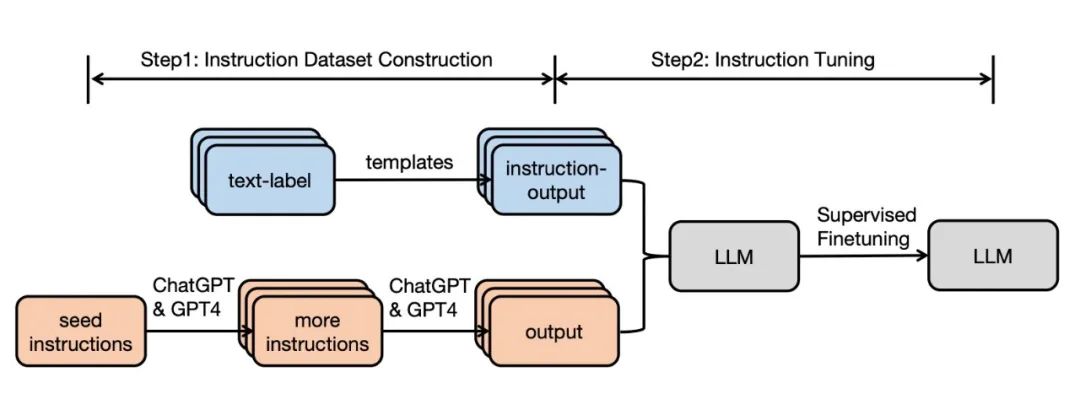
这篇论文综述了指令调整(Instruction Tuning,简称 IT)这一迅速发展的领域的研究工作。指令调整是一种关键技术,可以提高大型语言模型(Large Language Models,简称 LLMs)的能力和可控性。指令调整是指在监督下,将 LLM 进一步训练在包含\textsc{(instruction, output)}对的数据集上,从而弥合 LLM 的下一个单词预测目标与用户让 LLM 遵循人类指令的目标之间的差距。在本文中,我们对文献进行了系统性的回顾,包括 IT 的一般方法论,IT 数据的构建,IT 模型的训练,以及在不同模式、领域和应用中的应用,同时还分析了影响 IT 结果的方面(例如,指令输出的生成,指令数据集的大小等)。我们也回顾了 IT 的潜在陷阱以及对它的批评,同时指出了现有策略的当前不足,并提出了一些有益的研究方向。
链接:https://www.aminer.cn/pub/64e432c73fda6d7f0600b894
4
Code Llama: Open Foundation Models for Code
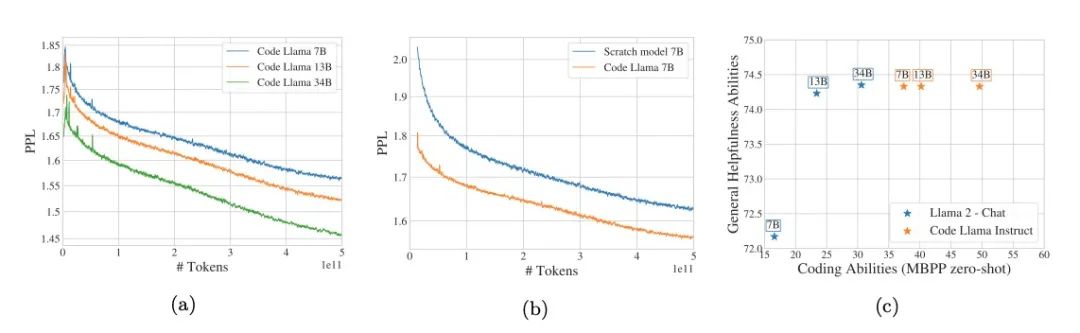
我们发布了名为 Code Llama 的一组大型语言模型,该模型基于 Llama 2,为代码提供了最先进的性能、填充能力、对大型输入上下文的支持以及零样本指令跟随能力。我们提供了多种变体以覆盖广泛的应用范围:基础模型(Code Llama)、Python 专长(Code Llama - Python)以及指令跟随模型(Code Llama - Instruct),各自的参数分别为 70 亿、130 亿和 340 亿。所有模型都在 16k 令牌的序列上训练,并在具有多达 100k 令牌的输入上显示出改进。7B 和 13B Code Llama 以及 Code Llama - Instruct 变体支持基于周围内容的填充。Code Llama 在多个代码基准测试中达到了最先进的性能,分别在 HumanEval 和 MBPP 上达到了 53% 和 55% 的得分。值得注意的是,Code Llama - Python 7B 在 HumanEval 和 MBPP 上的表现优于 Llama 2 70B,而我们的所有模型在 MultiPL-E 上的表现都优于其他任何公开可用的模型。我们将 Code Llama 发布在允许研究和商业使用的宽松许可证下。
链接:https://www.aminer.cn/pub/64e82e45d1d14e646633f5aa
5
ProAgent: Building Proactive Cooperative AI with Large Language Models
这篇论文介绍了一种名为 ProAgent 的新框架,它利用大型语言模型来帮助智能体在与人类或其他智能体的合作中更具前瞻性和主动性。传统的合作智能体方法主要依赖于学习方法,策略泛化严重依赖于与特定队友的过去交互,这限制了智能体在面对新队友时的策略重新调整能力。ProAgent 则可以预见队友的未来决策,并为自己制定增强的计划,表现出卓越的合作推理能力,能够动态适应以提高与队友的合作效果。此外,ProAgent 框架具有高度的模块化和可解释性,可以无缝集成到各种协调场景中。实验结果显示,ProAgent 在 Overcook-AI 框架中的表现优于五种基于自我游戏和基于人口训练的方法,在与人类代理模型的合作中,其性能平均提高了超过 10%,超过了目前的最先进方法 COLE。这一进步在涉及与具有不同特性的 AI 代理和人类对手的互动的多样化场景中是一致的。这些发现激发了未来人类与机器人合作的研究。可以在 https://pku-proagent.github.io 网站上进行实际操作演示。
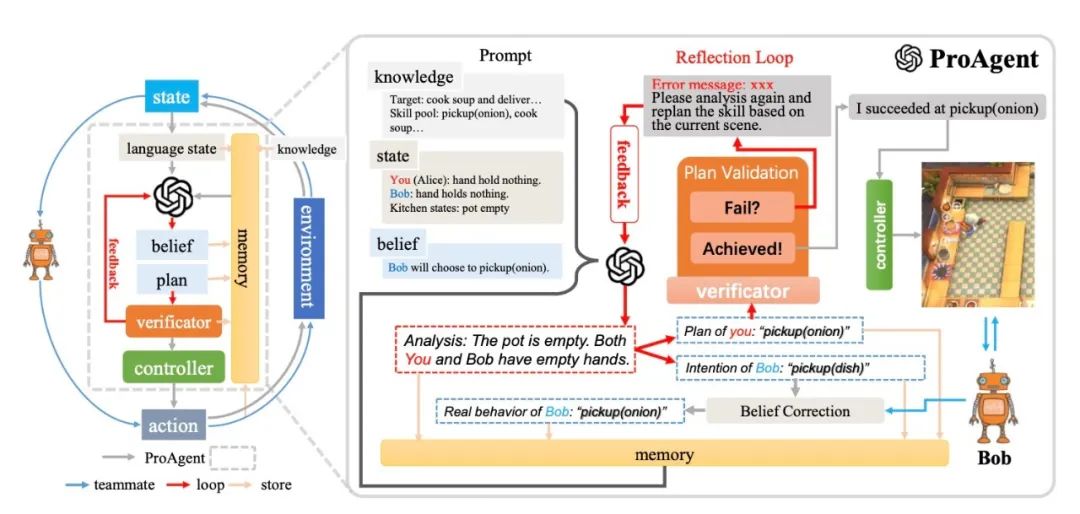
链接:https://www.aminer.cn/pub/64e5849c3fda6d7f063af3cd/
6
A Survey on Large Language Model based Autonomous Agents
这篇论文是关于基于大型语言模型的自主智能体的研究概述。之前的研究往往集中在有限知识下在孤立环境中训练智能体,这与人类的学习过程相去甚远,因此使得智能体难以实现类人的决策。近年来,通过获取大量的网络知识,大型语言模型 (LLMs) 在实现人类水平智能方面表现出了巨大的潜力。这引发了基于 LLM 的自主智能体研究的激增。为了充分利用 LLM 的潜力,研究人员为不同应用设计了各种智能体架构。在这篇论文中,我们从整体上对这些研究进行了系统回顾,具体来说,我们的重点在于构建基于 LLM 的智能体,为此我们提出了一个统一的框架,涵盖了大部分以前的工作。此外,我们还提供了 LLM 为基础的人工智能智能体在社会科学、自然科学和工程领域各种应用的概述。最后,我们讨论了用于评估 LLM 为基础的人工智能智能体的常用策略。根据以前的研究,我们还提出了这个领域的几个挑战和未来方向。
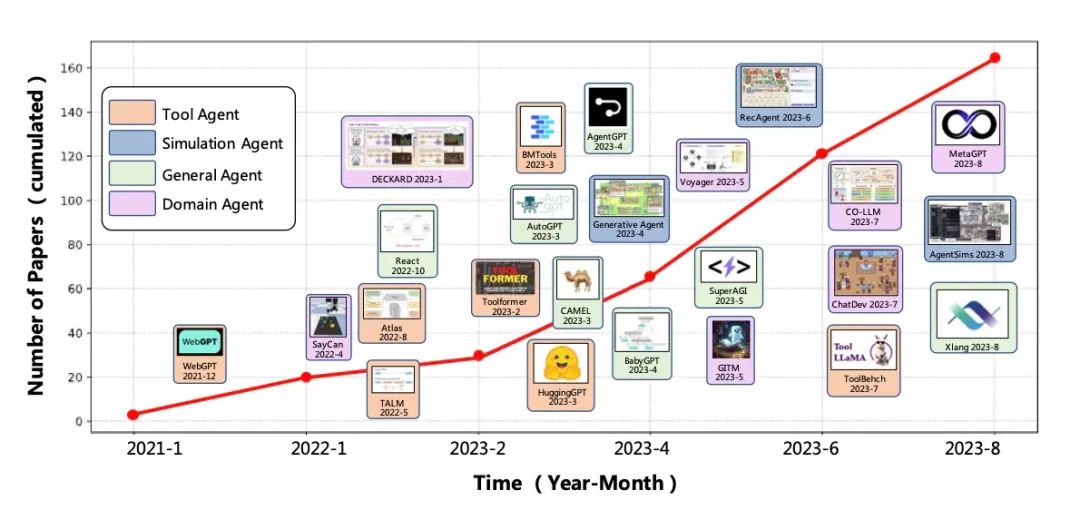
链接:https://www.aminer.cn/pub/64e5849c3fda6d7f063af42e
7
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors in Agents
这篇论文主要研究了如何通过大型语言模型(LLM)增强的自主智能体(agents)实现多智能体协作,并探索在这种协作中出现的新兴行为。作者提出了一个名为 AgentVerse 的多智能体框架,该框架可以模仿人类群体动态,协作地调整其组成,以实现整体效果大于部分的目标。实验结果表明,该框架可以有效地部署多智能体团队,其性能优于单个智能体。此外,作者还深入探讨了在协作任务执行过程中,团队内个体智能体之间社交行为的产生。针对这些行为,作者讨论了一些可能的策略,以利用积极的行为并减轻负面行为,从而提高多智能体团队的协作潜力。相关代码将在 https://github.com/OpenBMB/AgentVerse 上发布。
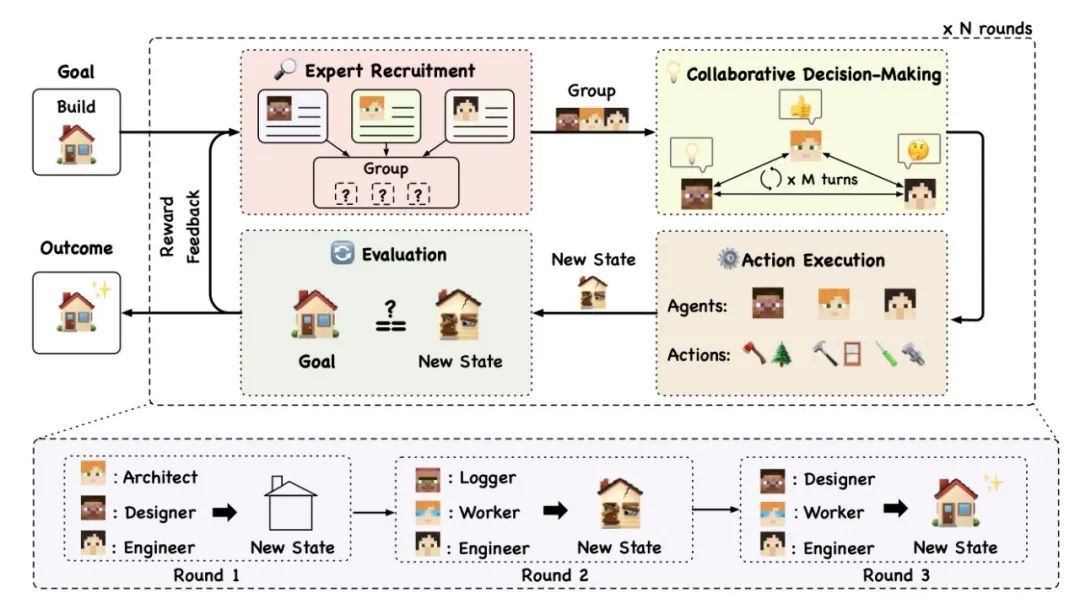
链接:https://www.aminer.cn/pub/64e432c73fda6d7f0600b8cd
8
Giraffe: Adventures in Expanding Context Lengths in LLMs
这篇论文主要研究了大型语言模型(LLM)在上下文长度扩展方面的问题。现有的 LLM 通常使用注意力机制,并依赖固定的上下文长度,这限制了它们在评估时可以处理的输入序列的长度。为了解决这个问题,作者对不同的上下文长度扩展方法进行了广泛的调查,并在基座 LLaMA 或 LLaMA 2 模型上进行了测试。他们还引入了一些自己的设计,特别是一种新的截断策略,用于修改位置编码的基础。作者使用三个新的评估任务(FreeFormQA、AlteredNumericQA 和 LongChat-Lines)以及困惑度进行了测试,并发现线性缩放是扩展上下文长度的最佳方法。他们还发现,通过在评估时使用更长的缩放,可以进一步提高性能。此外,他们还在截断的基础上发现了有前景的扩展能力。为了支持该领域的进一步研究,作者发布了三个新的具有 130 亿参数的长上下文模型,分别称为 Giraffe:4k、16k 和 32k 的上下文模型,这些模型都是从基座 LLaMA-13B 和 LLaMA2-13B 训练的。他们还发布了可以复制结果的代码。
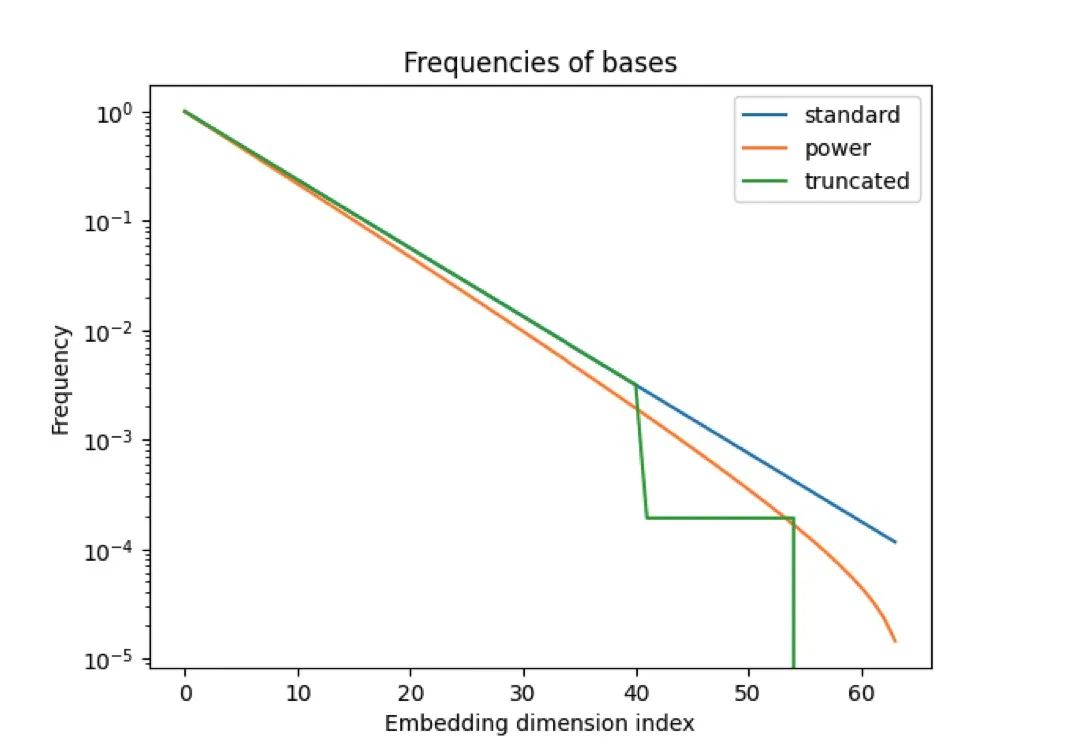
链接:https://www.aminer.cn/pub/64e432c73fda6d7f0600b8ef
9
Graph of Thoughts: Solving Elaborate Problems with Large Language Models
我们介绍了一种名为"思维图谱"(Graph of Thoughts,简称 GoT)的框架,它超越了如链式思考和思维树(Tree of Thoughts,简称 ToT)等范式,在大型语言模型(LLMs)中的提示能力方面取得了进步。GoT 的主要优势在于,它可以将 LLM 生成的信息建模为任意图,其中信息单位(“LLM 思考”)是顶点,边表示这些顶点之间的依赖关系。这种方法使得可以将任意的 LLM 思考组合成协同结果,提炼整个思维网络的本质,或使用反馈环增强思考。我们在不同任务上展示了 GoT 比现有技术更优越,例如,将排序质量提高 62%,同时将成本降低 31%。我们确保 GoT 可以扩展到新的思考转换,因此可以用来推动新的提示方案。这项工作使 LLM 推理更接近人类的思考,或者类似回溯这样的人脑机制,这两者都形成复杂的网络。
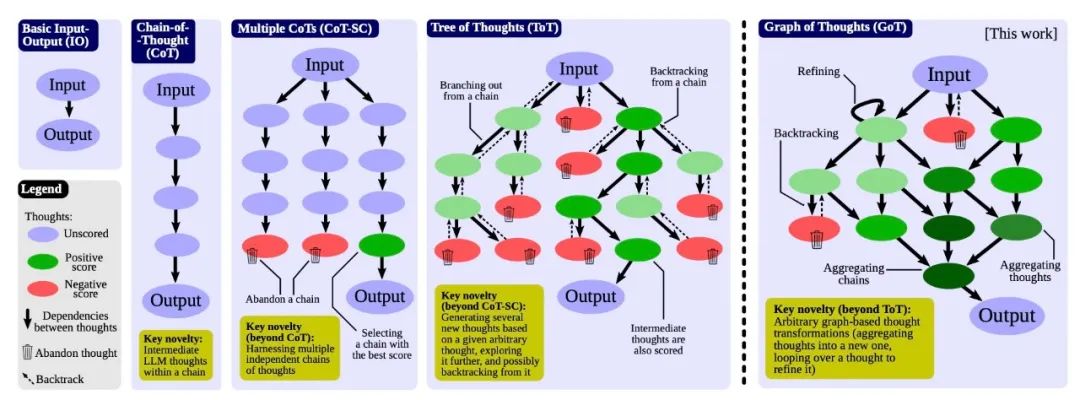
链接:https://www.aminer.cn/pub/64e2e15a3fda6d7f06466ace
10
Federated Learning in Big Model Era: Domain-Specific Multimodal Large Models
这篇论文主要讨论了大模型时代下联邦学习的发展,提出了一种特定于领域的多模态大型模型的联邦学习框架。这种框架允许多个企业利用私有领域数据共同训练垂直领域的大型模型,从而实现智能服务。作者深入讨论了联邦学习在大模型时代在智能基础和目标方面的战略转变,以及面临的新挑战,包括异构数据、模型聚合、性能与成本权衡、数据隐私和激励机制等。论文还通过一个案例研究,描述了领先企业如何通过多模态数据和专家知识,为城市安全运营管理提供分布式部署和有效的协调,以及基于大型模型能力的数据质量改进和技术创新。初步实验结果表明,企业可以通过多模态模型联邦学习来增强和积累智能能力,共同创建一个智能城市模型,提供高质量的智能服务,覆盖能源基础设施安全、居民社区安全和城市运营管理。建立的联邦学习合作生态系统有望进一步整合产业、学术和研究资源,实现多个垂直领域的大型模型,并推动人工智能和多模态联邦学习的大规模工业应用和前沿研究。
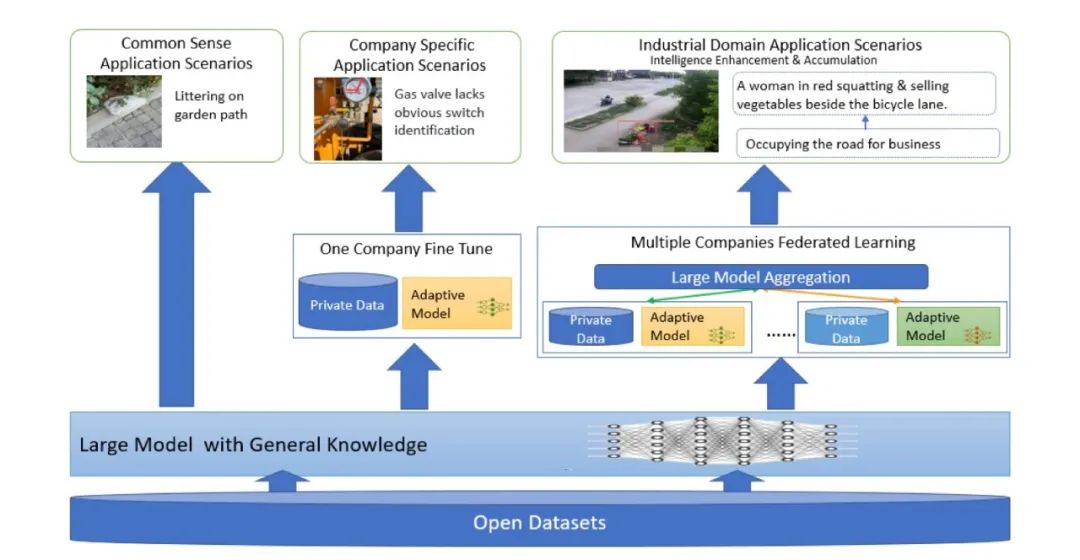
链接:https://www.aminer.cn/pub/64e5846c3fda6d7f063ac938/
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓


















 1082
1082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









