






#! https://zhuanlan.zhihu.com/p/660373004
最近在学习语义分割,刚刚入门,做一些小笔记。
图像分割
传统图像分割
基于阈值的分割
设置阈值将像素分为两类,大于阈值置1,小于阈值置0,得到二值图。在目标类像素值差异非常大的情况下适用。
基于区域的分割
通过寻找相邻像素之间的相似性并且将它们分组在一个公共类别下来工作。从一些像素设置为种子像素开始,算法通过检测直接边界并将它们分类为相似或不相似来工作。然后将直接邻居视为种子并重复这些步骤直到整个图像被分割。比如流行分水岭算法。
边缘检测分割
过滤器在卷积时提供图像的边缘。
基于聚类的分割
现代分割算法通常是使用聚类算法来工作。相似的点划分为一组,每一组称为一簇。比如k-means无监督算法将共同属性像素聚集在一起作为特定片段来工作:
- 随机的选择一个初始化的k值;
- 随机将数据点分配给k个簇中的任何一个;
- 计算各个簇的中心店;
- 计算每一个数据点离各个簇中心点的距离;
- 按照它们之间的距离将这些数据点分配给离它们最近的簇;
- 重新计算这些中心点;
- 重复4-6,直到各个聚类中心点不再变化或者达到设定迭代次数。
这个方法适用于数据量比较小的情况,并且仅适用于凸数据集。
现代图像分割
两个阶段:一个是基于传统机器学习的分割,一个是基于深度学习的图像分割。自从FCN被提出以来,CNN正式应用在图像分割领域,同时U-net随之诞生。
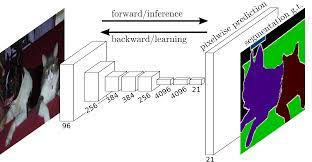
基于深度学习的分割模型通常会输出一个原图分辨率同等大小的掩码图,这些掩码图通常是n通道的,n是模型的输出类别数。对应到n通道中的每一个掩码图本质上都是一章二分类图,存在对象的位置会被填充为1,其余区域则由0组成,类的索引从0到n-1。
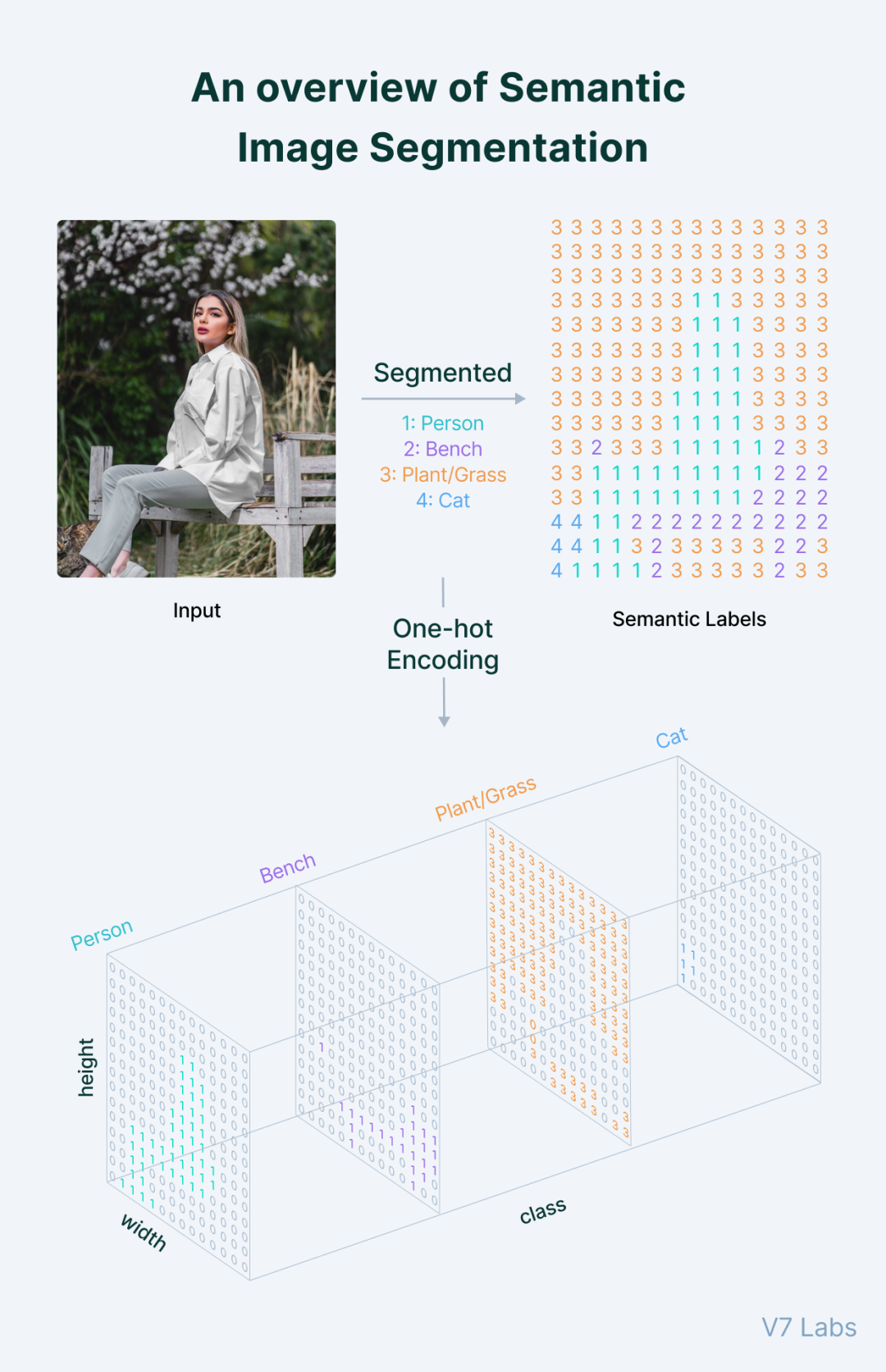
编解码架构
主要由 编码器(encoder)、长跳跃连接(long skip connection)和解码器(decoder) 组成。
编码器
用于提取网络特征,通过下采样得到特征图。有效感受野决定了网络利用上下文信息的能力。
编码器通过池化和步长卷积来降低分辨率,扩大感受野。
早期网络主要着力于提高两点:效率和上下文信息捕捉。主流方法有:扩大感受野和注意力机制。
扩大感受野
- 使用大卷积核的GCN等方法;
- 使用空洞卷积的DeepLab等方法;
- 使用池化操作的PSPNet等方法;
局限性:
- 参数量过大会导致过拟合;
- 理论感受野远小于实际感受野;
- 空洞卷积容易引起局部领域的信息丢失;
- 池化操作导致小尺寸目标丢失;
感受野太小难以捕获大尺寸对象;感受野太大引入过多噪声和无效信息。必须设置合理的多尺度表征来获得有效合理的感受野。DMNet提出了动态多尺度的过滤器来自适应不同的目标尺寸。解决了尺度参数设计的问题。CPFNet通过借鉴SK-Net的思想引入了尺度感知模块来自适应的融合来自不同尺度的特征。
注意力机制
- 结合通道和空间双注意力的DANet等;
- 借鉴自注意力机制的NonLocal等;
要从维度和效率方面去考虑优化。
长跳跃链接
与ResNet中的残差连接用于解决梯度消失问题的目的不同,U-Net或者FCN中的长跳跃连接是为了弥补下采样的信息损失问题。
另外,长跳跃连接实现不同层级特征之间的信息融合,提取更有效的特征。
-
融合更多的特征
比如*UNet++*尝试长短跳跃连接来实现信息共享
-
融合更好的特征
一方面可以从数据源进行去噪处理;另一方面可以从模型角度处理噪音,比如Attention-UNet引入门控注意力强化前景区域抑制背景区域;MultiResUNet堆叠多个1×1卷积进行特征提纯。
浅层特征注重边缘纹理等空间细节,缺乏高级语义;深层特征具备高级语义,缺乏空间细节。不同层级的特征融合存在语义鸿沟。ExFuse提出了许多方法在浅层特征引入更多的语义信息,深层特征嵌入空间信息。
解码器
解码器的作用是将编码器所提取到的高级特征上采样至固定分辨率以实现端到端的训练从而完成像素级的密集预测分类。
解码器的关键在于高效还原压缩的高级语义特征。包括上采样和特征输出。
将一个特征图上采样有两种方式:线性插值和反卷积。
线性插值根据公式模拟未知点的信息,与数据无关。而反卷积可学习,可以获得更优的分割性能,但会引入过多的参数量和计算。DUsampleing基于通道重排的思路设计了新型上采样方式(上卷积),结合两者优势。
特征输出用于更新模型参数。通常大多数网络只输出最后一层特征图,但是中间层的特征也很重要。比如GoogLeNet提及的辅助损失;PSPNet和DSN,DSN中提出了深监督,为所有层级的输出特征都建立监督机制,一是可以综合多个输出层的信息来学习更加鲁棒的特征,二是可以缓解梯度消失现象,加速网络收敛。
问题:
-
需要监督多少层特征?
根据数据特性选择。
-
需要监督哪些层特征?
靠近输出层的中间特征更重要。
-
如何分配合适权重?
同上。
演进思路
2020年ViT诞生,Transformer正式在CV方向进行应用,下面介绍Transformer和CNN的区别。
归纳偏置
CNN由于归纳偏置无需大量数据和trick就可以有不错效果;Transformer虽然没有归纳偏置,但是却有了更高的上限。
远距离依赖
CNN由于感受野有限无法捕获有效的长距离依赖,大尺寸目标分割效果比较差。Transformer天生适合处理全局目标。
空间分辨率
Transformer自始至终保持输入和输出的空间分辨率不变,对于语义分割这种非常注重空间细节信息的密集型预测分类任务来说非常重要,可以缓解CNN多次下采样**导致的小目标信息损失问题。
不过Transformer对于底层特征的提取能力较差,容易导致小目标的错误预测,所以后期涌现出很多CNN+Transformer的网络结构。
- 当感觉定量结果上已经难以再去提升时,可以尝试从定性角度出发,譬如从改善图像分割边缘这个点入手,虽然从数值指标上几乎不会有什么差距,但可视化结果展示出来的分割边界就是个极大的优势,不失为一个亮点去宣传。
- 当感觉主流的数据集已经趋于饱和时,尝试转换个思路去突破,例如大家都做白天,你便可以做夜视场景;大家都做基于陆地的场景解析,你可以做基于水下的场景分割;大家都在做基于晴天的场景,你便可以尝试做风雷雨雪等极端场景下的分割等等;甚至自己还可以开辟一个新的方向出来开源新数据集。
- 正所谓它山之石可以攻玉,平常一定要多阅读积累,广泛涉猎相关领域的知识,不求精通点到为止。
下面进行一些网络介绍:
医学图像分割
U-Net

UNet的encoder下采样4次,一共下采样16倍,对称地,其decoder也相应上采样4次,将encoder得到的高级语义特征图恢复到原图片的分辨率。
相比于FCN和Deeplab等,UNet共进行了4次上采样,并在同一个stage使用了skip connection,而不是直接在高级语义特征上进行监督和loss反传,这样就保证了最后恢复出来的特征图融合了更多的low-level的feature,也使得不同scale的feature得到了的融合,从而可以进行多尺度预测和DeepSupervision。4次上采样也使得分割图恢复边缘等信息更加精细。
- 编码器:用于将输入图像编码为多个不同级别的特征表示,通常由一堆卷积和池化组成。
- 解码器:用于将编码器学到的判别性特征(lower-resolution)语义逐步投影至与原始空间分辨率一致的像素空间(higher-resolution)进行密集预测分类,通常由上采样模块和卷积组成。
- 长跳跃链接:在网络中进行上采样的同时,将来自编码器网络的更高分辨率的特征图与上采样的特征图拼接(contact)起来,以便更好地学习后续卷积的表征【FCN中采用Add操作】。上采样是一种稀疏操作,引入早期阶段的良好先验可以更好地帮助网络定位到目标。
import torch
import torch.nn as nn
# 定义U-Net模型
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
# 定义编码器部分
self.encoder = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
# ... 其他卷积层和池化层
)
# 定义解码器部分
self.decoder = nn.Sequential(
# ... 其他卷积层和上采样层
nn.ConvTranspose2d(in_channels, out_channels, kernel_size=2, stride=2)
)
def forward(self, x):
# 编码器部分
encoded_features = self.encoder(x)
# 解码器部分
decoded_features = self.decoder(encoded_features)
# 进行短连接,将编码器部分的特征图和解码器部分的特征图拼接在一起
concatenated_features = torch.cat((encoded_features, decoded_features), dim=1)
# 继续解码操作,得到最终的分割结果
output = self.final_conv(concatenated_features)
return output
DSN
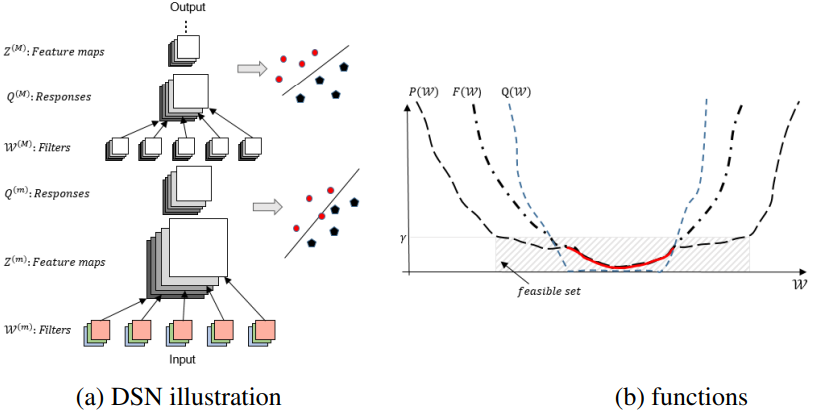
DSN在网络的中间层引入额外的监督信号,在训练过程中提供更多的梯度信号,缓解梯度消失的问题。
代码示例如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
class DSNet(nn.Module):
def __init__(self, num_classes=21):
super(DSNet, self).__init__()
# 定义卷积层
self.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1)
self.conv3 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1)
self.conv4 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1)
self.conv5 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
# 定义全连接层
self.fc1 = nn.Linear(512, num_classes) # 最终分类层
self.fc2 = nn.Linear(512, num_classes) # 中间监督信号的分类层
def forward(self, x):
# 前向传播函数
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
intermediate_output = F.relu(self.conv4(x))
x = F.relu(self.conv5(intermediate_output))
# 最终分类层
final_output = self.fc1(x)
# 中间监督信号的分类层
intermediate_output = self.fc2(intermediate_output)
return final_output, intermediate_output
Attention U-Net
提出了一种基于门控注意力attention gate的模型,抑制背景区域,强调前景区域,自动学习如何区分目标的外形和尺寸。
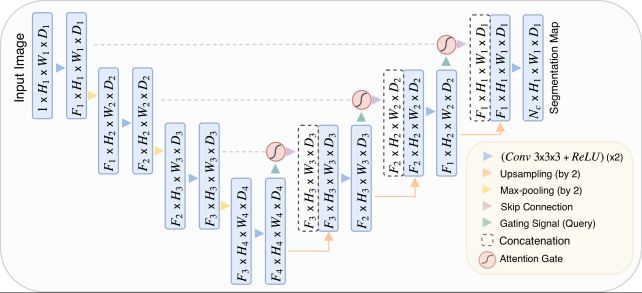
具体而言,Attention U-Net在解码器的每一层引入了注意力机制。这些注意力机制允许网络在进行解码的同时,根据输入图像的内容,动态地调整各个位置的特征的重要性。
在Attention U-Net中,注意力机制的基本思想是利用输入特征图的不同位置之间的关系来调整特征图。具体来说,Attention U-Net中的注意力机制由以下步骤组成:
-
特征提取(Feature Extraction): 首先,输入图像通过卷积层和激活函数等操作,被转换成特征图。这些特征图包含了图像的抽象表示。
-
计算注意力分数(Attention Scores): 然后,通过特定的卷积操作,从这些特征图中计算出注意力分数。注意力分数表示了每个位置对于其他位置的重要性。这个操作通常使用卷积神经网络中的卷积层来完成,以学习特征之间的复杂关系。
-
计算加权特征(Weighted Features): 利用计算得到的注意力分数,将原始特征图中的特征进行加权,得到加权特征。这个步骤将不同位置的特征以不同的权重相加,形成了加权的特征表示。
-
特征融合(Feature Fusion): 最后,将加权特征与原始特征图进行融合,形成最终的特征表示。这个融合过程可以通过简单的加法操作来实现。
代码示例:
import torch
import torch.nn as nn
class AttentionBlock(nn.Module):
def __init__(self, F_g, F_l, F_int):
super(AttentionBlock, self).__init__()
self.W_g = nn.Sequential(
nn.Conv2d(F_g, F_int, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(F_int)
)
self.W_x = nn.Sequential(
nn.Conv2d(F_l, F_int, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(F_int)
)
self.psi = nn.Sequential(
nn.Conv2d(F_int, 1, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
def forward(self, g, x):
g1 = self.W_g(g)
x1 = self.W_x(x)
psi = self.psi(g1 + x1)
return x * psi
class AttentionUNet(nn.Module):
def __init__(self, in_channels, out_channels):
super(AttentionUNet, self).__init__()
# 编码器部分
self.encoder = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True)
)
# 注意力机制
self.attention = AttentionBlock(64, 64, 32)
# 解码器部分
self.decoder = nn.Sequential(
nn.Conv2d(64, out_channels, kernel_size=3, stride=1, padding=1),
nn.Sigmoid()
)
def forward(self, x):
enc = self.encoder(x)
att = self.attention(enc, enc)
dec = self.decoder(att)
return dec
# 使用示例
# 输入通道数为3,输出通道数为1(二进制分割任务)
model = AttentionUNet(in_channels=3, out_channels=1)
# 输入数据(batch_size, channels, height, width)
input_data = torch.randn(1, 3, 256, 256)
# 获取模型输出
output = model(input_data)
print(output.shape) # 输出的形状
U-Net++

精度提升,以及测试集中的可剪枝性可以大幅缩减参数,有篇讲解特别好,鞭辟入里,讲了这个Net提出的过程:研习U-Net
CE-Net
- 特征编码器模块:使用预训练的ResNet块作为固定特征提取器;
- 上下文提取器模块:密集空洞卷积块(DAC)和残差多核池块(RMP)组成,捕获更多高级信息并保留空间信息;
- 特征解码器模块:连续的1×1卷积,3×3转置卷积和1×1卷积,利用转置卷积学习自适应映射恢复具有更多详细信息的特征。
nnU-Net
-
自动化的架构选择: nnU-Net通过自动化的方法,根据提供的训练数据集,选择适合特定任务的最佳网络架构。这种自动化的架构选择过程有助于避免手动调整网络结构的繁琐过程。
-
数据增强和预处理: nnU-Net包括了一套强大的数据增强和预处理技术,以提高网络的鲁棒性和泛化能力。这些技术可以帮助网络更好地适应不同场景和变化。
-
3D图像分割支持: nnU-Net不仅适用于2D图像分割,还支持3D图像分割任务,这使得它可以应用于医学图像等领域的体积数据分割任务。
-
强大的性能和泛化能力: nnU-Net的设计目标是在保持良好性能的同时,提供对不同任务和数据集的广泛适应性。它在医学图像分割等领域取得了很好的效果。
主要参考资料:
-
以及文中提到的模型的相关论文。
强力推荐哈工大AI视觉实验室的公众号CVHub















 1760
1760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









