






 本文介绍了BiSeNet,一种针对实时语义分割提出的新方法,通过双分支网络结构(空间路径和上下文路径)保留空间信息和扩大感受野,同时结合注意机制和特征融合模块以提高精度和速度。文章详细讨论了当时的研究进展和挑战,以及BiSeNet的独特解决方案。
本文介绍了BiSeNet,一种针对实时语义分割提出的新方法,通过双分支网络结构(空间路径和上下文路径)保留空间信息和扩大感受野,同时结合注意机制和特征融合模块以提高精度和速度。文章详细讨论了当时的研究进展和挑战,以及BiSeNet的独特解决方案。
实时语义分割学习笔记03 BiSeNet: 双分支网络
一、提出的问题:
语义分割需要丰富的空间信息和较大的感受野。然而,现代方法通常会为了实现实时推理速度而牺牲空间分辨率,从而导致性能低下。
1、解决:双路径
第一路径:一个步长较小的空间路径,以保留空间信息并生成高分辨率特征。
第二路径:采用了快速降采样策略的上下文路径,以获得足够的感受野。
2、其他贡献:
引入了一个新的特征融合模块,以有效地组合特征。
二、当时的研究进展:
1、加速模型的方法
a. 通过对原始输入图像裁剪或缩放来限制输入大小 (IcNet),虽然该方法简单有效,但空间细节的丢失破坏了预测,特别是在边界附近,导致度量和可视化的准确性下降。
b.通过修剪网络的通道(ENet , SegNet),尤其是在基础模型的早期阶段。然而,这削弱了空间容量。
c .ENet [25] 建议放弃模型的最后阶段,以追求一个极其严密的框架。然而,这种方法的缺点也是显而易见的:由于 ENet 放弃了最后阶段的下采样操作,模型的感受野不足以覆盖大型物体,导致分辨能力较差。
2、针对以上的方法中存在的一些问题,当时的一些解决方法
以上的方法为了实现快速推理,在准确性和速度上中做出了权衡。并丢失了部分的空间容量和空间细节。
a. Spatial Details (空间细节) : 指图像中的局部、微小特征和结构,例如纹理、边缘、角点等。使得我们能够识别和理解图像中的各种模式和形状。
b. Spatial Capacity(空间容量):指图像中所包含的整体空间信息的容量或容纳能力。它可以受到分辨率、维度和图像大小等因素的影响。空间容量的大小直接影响图像的数据量和处理复杂性。牺牲空间容量通常意味着减少图像中的像素数、维度或分辨率,以降低存储和计算成本。
3、U 型结构,用于缓解空间容量和细节的损失
U 形状的网络结构是指一种具有上升和下降路径的网络形式,可以有效地捕获对象的边界和细小结构。
a. 编码器(Encoder): 位于 U 形的左侧,负责将输入图像进行层级化的特征提取和降维。这一过程通常通过卷积层和池化层的组合来实现,逐渐捕获图像的抽象特征。(用于不断的获取高级语义特征,突出特征细节)
b. 解码器(Decoder): 位于 U 形的右侧,负责将编码器提取到的特征图进行上采样和解码,恢复到原始图像的分辨率。这一过程通常通过上采样和反卷积等操作来实现。
作者认为:U 形技术更适合被视为一种缓解,而不是一个必要的解决方案。
4、 BiSeNet采用的解决办法:主要解决(空间信息丢失和感受野收缩)
a. Spatial Path (SP)分支: 目的是应对空间信息的丧失。通过堆叠三个卷积层,得到分辨率为原始的1/8的特征
图,以保留丰富的空间细节。
b. Context Path (CP)分支: 目的是解决感受野收缩的问题。在 Xception 的尾部添加全局平均池化层,其感受野达到了骨干网络的最大值。
三、相关工作
1、空间信息保留
语义分割任务中,卷积神经网络(CNN)通过连续的下采样操作对高层次的语义信息进行编码, 这样一来不不可避免的丢失空间中的上下文信息。然而,在语义分割任务中,图像的空间信息对于预测详细的输出至关重要。
a. DUC、PSPNet和DeepLab 等使用扩张卷积(dilated convolution)来保持特征图的空间尺寸,并通过空洞卷积捕获更大的感受野。
b. Global Convolution Network [26]: 利用“大核”(large kernel)扩大感受野,以增强对空间信息的感知。比如据采用5X5的卷积核。
2、U 形网络
作者提到,使用U形结构的方法,包括原始的FCN网络、使用反卷积层的U形结构、U-net引入的有用的跳跃连接网络结构、Global Convolution Network将U形结构与大核卷积结合使用等。
3、上下文信息
上下文信息在语义分割任务中至关重要,因为它有助于生成高质量的分割结果。PSPNet 使用"PSP"模块,其中包含几个不同尺度的平均池化层。DeepLab v3 计了一个具有全局平均池化的ASPP模块,以捕捉图像的全局上下文。此外,还有一些方法采用了自适应感受野的卷积层,以获取自适应的上下文信息。DFN 在U形结构的顶部添加了全局池化,以编码全局上下文。
a. ASPP(Atrous Spatial Pyramid Pooling),空洞空间卷积池化金字塔。目的与普通的池化层一致,尽可能地去提取特征。
b. 自适应感受野的卷积层是一种通过自动调整卷积核的大小,以适应输入图像中不同位置的特征尺度的网络层。

4、注意机制(Attention mechanism)
是一种利用高层次信息来引导前馈网络的方法。在深度学习中,注意力机制通常用于加强模型对输入中关键部分的关注。注意机制可以根据输入的不同部分分配不同的权重,使网络更专注于对任务有重要影响的区域。目前主要的注意力机制包括以下的内容:
a. 尺度相关的注意力: 根据输入图像的尺度应用注意机制。这意味着模型可以根据对象或场景的尺度自适应地调整注意力。
b. 通道注意力: 在某些情况下,注意机制可以应用于不同通道的特征图上,以便更好地学习特定通道的重要性。
c.全局上下文注意力: 通过学习全局上下文信息,并将其作为注意力来修正特征。这种方法有助于模型更好地理解整体场景。
5、当时的实时语义分割方法:
a. SegNet: 利用了一个小型的网络结构和skip-connected方法来实现快速分割。Skip-connected方法是通过在网络中引入跳跃连接,将底层的详细信息传递到上层,从而提高分割的准确性。
b. E-Net : 从头设计了一个轻量级网络,实现了极高的速度。轻量级网络通常具有较少的参数和计算复杂度。
c. ICNet : ICNet使用图像级联(image cascade)来加速语义分割方法。级联方法通常涉及在不同分辨率下处理图像,从而在减少计算负担的同时保持分割的准确性。
c. : 其他方法采用级联网络结构以减少在“简单区域”中的计算。通过在处理简单区域时降低计算复杂度,可以更有效地实现实时分割。
四、Bilateral Segmentation Network
在BiSeNet中采用了双分支分别解决,模型如下:
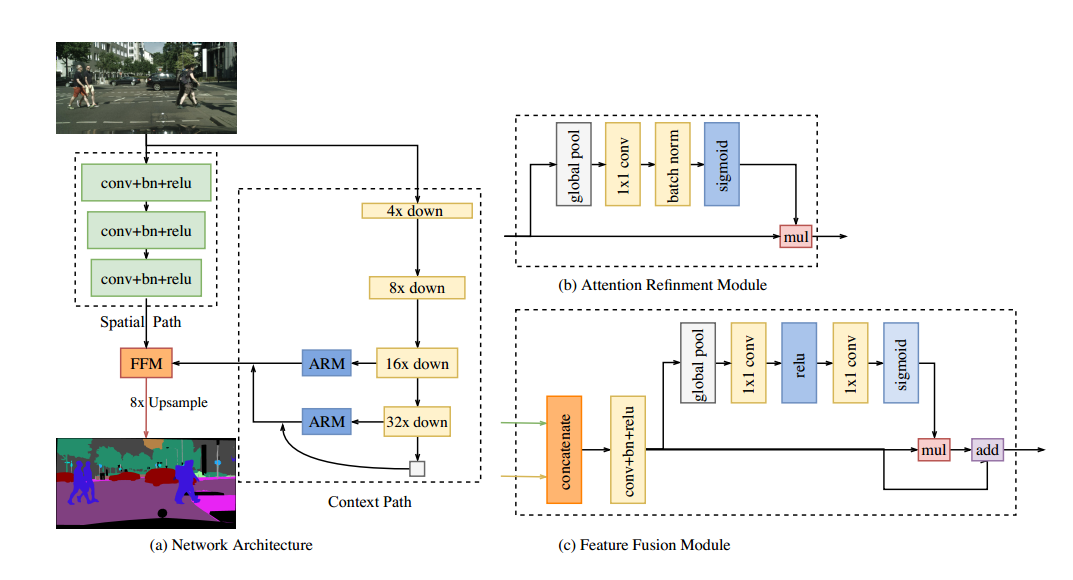
其中:
( a ) 网络结构。区块长度表示空间大小,厚度表示通道数量。
( b ) 注意力细化模块(ARM)的组件。
( c ) 特征融合模块(FFM)的组成部分。读取线表示我们仅在测试时才进行这一处理。
1、空间路径(Spatial Path)
每一层包括步长 = 2 的卷积,然后是批量归一化 和 ReLU 。因此,该路径提取的输出特征图是原始图像的 1/8。由于特征图的空间尺寸较大,因此它能编码丰富的空间信息。
2、上下文路径(Context Path)
上下文路径的目的是提供足够大的感知野。一些方法通过使用金字塔池化模块 、空洞空间金字塔池化 或大核卷积 来扩大感知野。然而,这些操作计算复杂且占用内存,导致速度较慢。
作者提出了一个特定的Attention Refinement Module(ARM),用于细化每个阶段的特征。ARM利用全局平均池化捕获全局上下文,并计算一个注意力向量来引导特征学习。这种设计可以在不进行任何上采样操作的情况下轻松集成全局上下文信息,因此计算成本极低。
3、注意机制(Attention mechanism)
如图b所示:
a. 全局池化 全局池化用于获取大的感知野,以提供丰富的上下文信息
b.
4、 Feature Fusion Module(特征融合模块)
由于空间路径和上下文路径的特征维度不同(维度分别为 1 8 \frac{1}{8} 81)和 1 16 \frac{1}{16} 161或 1 32 \frac{1}{32} 321 。特征融合模块首先连接两个路径的输出特征,然后使用批归一化来平衡特征的尺度。接下来,对连接后的特征进行池化得到特征向量,并计算一个权重向量。这个权重向量用于重新加权特征,实现特征选择和组合。

















 1252
1252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









