






YOLO网络详解
YOLO(You Only Look Once)
yolo是一种流行的目标检测系统,其核心思想是将目标检测任务转化为一个回归问题,通过单个神经网络同时进行目标的定位和分类,实现实时高效的目标检测。具体来说,YOLO算法的工作原理包括以下几个步骤:
-
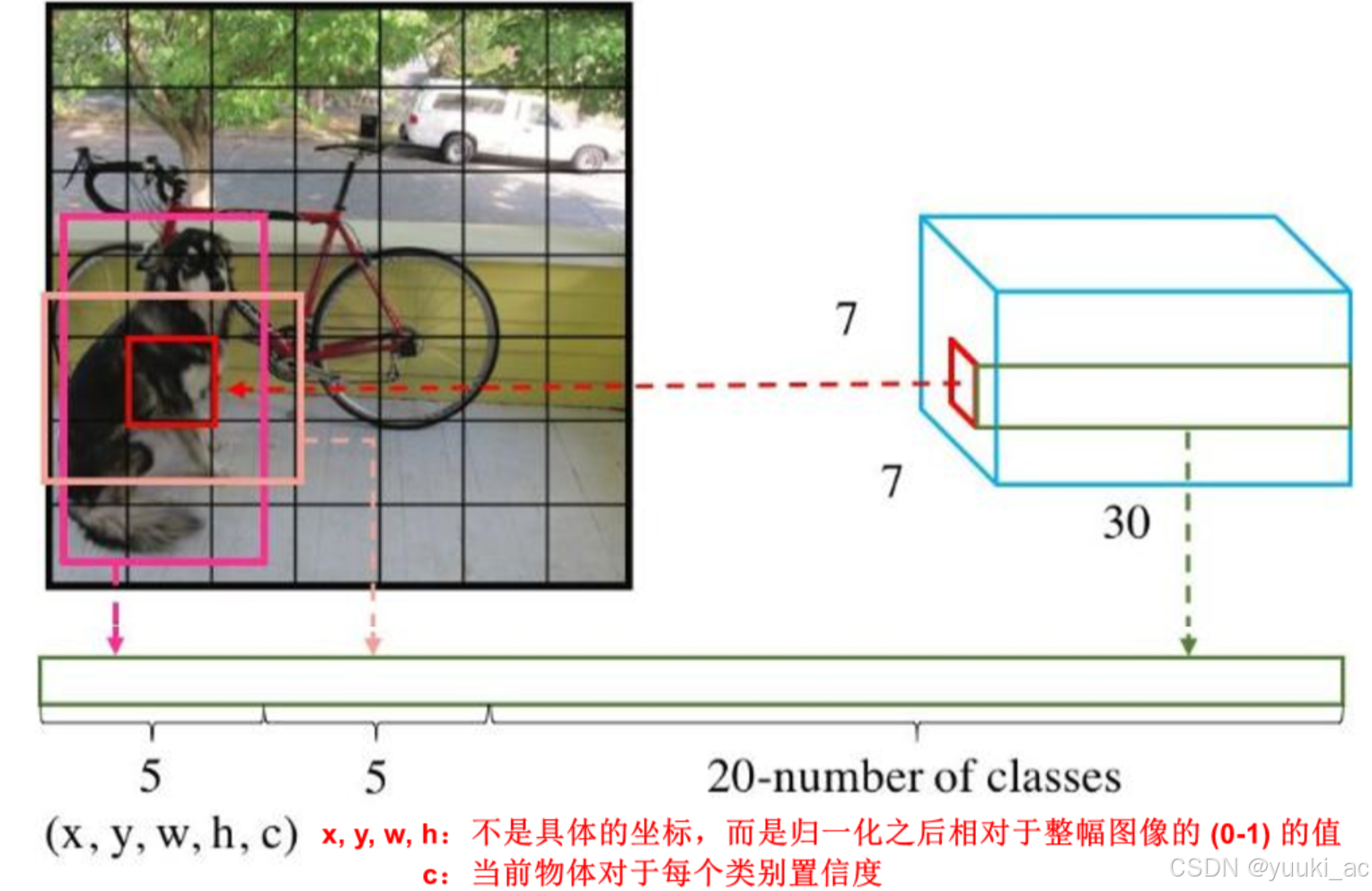
网格划分:YOLO将输入图像划分为固定大小的网格(例如S×S)。每个网格负责预测该网格中的物体(目标的中心是否落在这个网格)。
-
边界框预测:每个网格预测多个(2个)边界框(bounding boxes),每个边界框包含物体的中心坐标、宽度和高度。(是直接预测出来的,没有Anchor box)
-
物体分类:对于每个边界框,使用分类器来预测物体的类别,通常使用卷积神经网络(CNN)来提取特征,并使用全连接层进行分类。
-
置信度评估:每个边界框还预测一个置信度分数,表示该边界框中存在物体的概率以及边界框的准确度。
-
非极大值抑制(NMS):对于每个类别,使用NMS选择具有最高置信度的边界框,并剔除与其重叠度较高的边界框。

每个边界框由五个值表示:[x, y, w, h, confidence],其中[x, y]是框中心坐标,[w, h]是框的宽高,[confidence]表示框内有物体的概率。
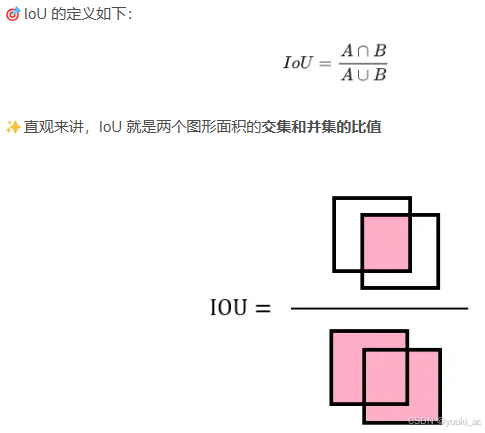
重叠度的计算方法:交并比IoU=两个框的交集面积/两个框的并集面积。
基础模型:
-
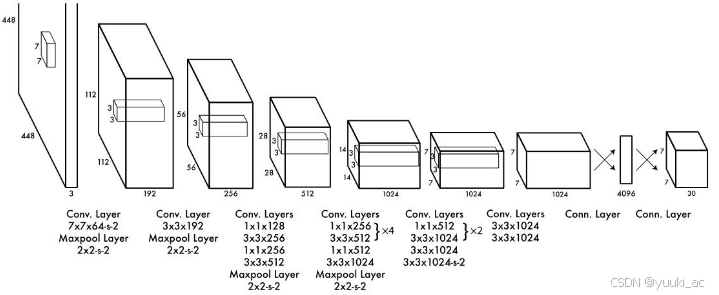
YOLO v1-2016:直接回归出位置。使用ImageNet数据集对前20层卷积网络进行预训练,然后使用完整的网络,在PASCAL VOC数据集上进行对象识别和定位的训练。最后一层采用线性激活函数,其它层都是Leaky ReLU。训练中采用了drop out和数据增强(data augmentation)来防止过拟合;模型预测。将图片resize成448x448的大小,送入到yolo网络中,输出一个 7x7x30 的张量(tensor)来表示图片中所有网格包含的对象(概率)以及该对象可能的2个位置(bounding box)和可信程度(置信度)。在采用NMS(Non-maximal suppression,非极大值抑制)算法选出最有可能是目标的结果。
-
优点
-
速度非常快,处理速度可以达到45fps,其快速版本(网络较小)甚至可以达到155fps。
-
训练和预测可以端到端的进行,非常简便。
-
-
缺点
-
准确率会打折扣
-
对于小目标和靠的很近的目标检测效果并不好
-
-
关于yolov1的设计:输入图像的尺寸为448×448,经过24个卷积层(前三层通道64->192可能是拼接/经过下一层卷积得到),2个全连接的层(FC),最后在reshape操作,输出的特征图大小为7×7×30。
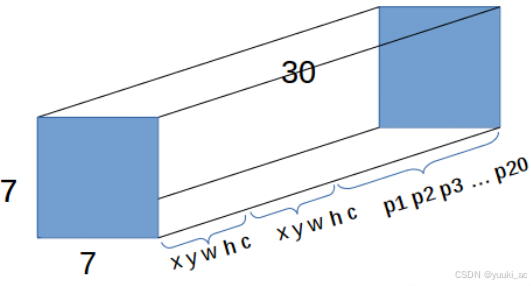
最后一层 7*7*30:
![]()
解释:5->基本向量[x, y, w, h, confidence];2(大目标+小目标);20classes->多个类别的检测(one-hot编码)
问题解读
1.分类对于每一个grid cell都是一个,但是bounding box有多个,是根据哪个box进行分类的呢?
在训练的时候会在线计算每个predictor预测的bounding box和ground truth的IOU,计算出来的IOU大的那个predictor,就会负责预测这个物体,另外一个则不预测。(置信度定义为 Pr(Object) ∗ IOUtruth pred,如果该单元格中不存在对象(对象中心点在不在grid cell里面),则Pr(Object)=0置信度分数应为零。否则,置信度得分等于预测框与地面实况之间的IOU)。无论bounding box有多少个,每个grid cell只有一组(条件)类别概率,也就是分类是针对grid cell的,而对应到bounding box时只需要计算条件概*框的置信度:
![]()
2.每个网格预测的两个bounding box是怎么得到的?
在训练的时候,每个样本的ground truth的box是知道的,对应于相当于下采样后的的feature map,也能找到在feature map中对应的格子的位置。如果一个grid cell是该物体的中心位置,则这个grid cell负责预测这个物体。每个grid cell都预测了若干个box,其中会有一个box具有与ground truth的某个box有最大的iou,则由这个box负责调整box的位置(另外的预测的box就忽略了)。YOLO每个格子(grid cell)的2个bounding box事先并不知道会在什么位置,只有经过前向计算,网络会输出2个bounding box,这两个bounding box与样本中对象实际的bounding box计算IOU。这时才能确定,IOU值大的那个bounding box,作为负责预测该对象的bounding box。YOLOV1的bounding box初始时是随机生成的(输出端才能得到,初始时没有这个值),经过多轮loss计算反向传播,更新参数值,然后获得好的预测结果。(yolov2之后就是用预先生成的Anchor Box)
重点:训练开始阶段,网络预测的bounding box可能都是乱来的,但总是选择IOU相对好一些的那个(损失函数也是针对这个来),随着训练的进行,每个bounding box会逐渐擅长对某些情况的预测(可能是对象大小、宽高比、不同类型的对象等)。所以,这是一种进化或者非监督学习的思想(不能当作传统的监督学习)。
3.box的计算
box的位置坐标为(x,y,w,h),其中x和y表示box中心点与该格子边界(左上角)的相对值,也就是说x和y的大小被限制在[0,1]之间(即box的中心点必须限制在grid cell里),假如候选框的中心刚好与网格的中心重合,那么x=0.5,y=0.5。 w和h表示预测box的宽度和高度相对于整幅图片的宽度和高度的比例,这样(x,y,w,h)就都被限制在[0,1]之间(有个归一化的思想),与训练数据集上标定的物体的真实坐标(Gx,Gy,Gw,Gh)进行对比训练,每个网格负责预测中心点落在该格子的物体的概率。
4.yolo检测流程
将一张图片分成49个小格,每个小格能生成2个不一样的框,最终在2个框中选择一个框住一个完整物体可能性最大的框,并预测出框住的物体的最大可能类别(但是预测的时候还是保留98个框与对应类别),最终在得出的98个框中选择(利用NMS过滤掉低置信度的框,并且把重复的框去掉)概率最高的几个框画出在图片上,作为最终显示出来的识别效果。(先选框再预测类别)
假设一个grid cell的98个张量的1号位置的元素是表示物体是“狗”的概率,那么针对“狗”这个类别,需要做三件事:
-
设置一个概率值p,将98个张量的1号位置小于p的全部置0(假如p = 0.2,则将是狗的概率<0.2的这些概率全部置0),相当于认为这些框识别出来的分类不可能是“狗”了
-
将这98个张量按照1号元素的大小(是“狗”的概率)依次排序
-
进行非极大值抑制(Non-Maximum Suppression)
5.什么是非极大值抑制(NMS)?
主要目的是去掉重复预测同一个物体的框,只保留最优的那个框。上面我们已经得到按照”狗“的概率大小排好序的98个张量,接下来操作如下:
-
将排在第一名的最大的那个概率对应的bounding box拿出来,依次和后面的概率对应的框做对比,比什么?比IOU(交并比,可以理解为体现两个框重合部分大小的一个量)
-
设置一个值i,如果两个框的IOU>i,则说明这两个框重合度很高,我们认为这两个框预测的是同一个物体,那么这两个框最终只能留一个,我们选择分类概率大的框留下,将概率小的框对应的概率值置0(淘汰)
-
将第一名跟后面比较完一遍,再将概率第二高的框按相同的规则依次和后面比,以此类推…
有上面3个步骤我们将1号位置:“狗”的分类情况过滤完成,后面要做的就是将剩余19个分类按照和以上3个步骤相同的方式完成。最终,经过层层筛选,不断置0,淘汰,有一些框凭借优秀的精准度存活了下来,将最终留下的概率非0的框及所对应的类别画在图上,即得出最终的目标检测结果。
注意: NMS只发生在后处理预测阶段(不是现实推理),训练阶段是不能用NMS的,因为在训练阶段不管这个框是否用于预测物体,其都和损失函数相关,不能随便重置成0。
6.怎么理解训练时输出的数据代表各种分类概率、置信度、位置信息等与反向传播梯度下降的关系?
对于输出的7*7*30,是回归出来的数据,是经过拟合得到的意义(如检测概率,置信度等等,通过梯度下降反向传播使拟合效果更好),因此,在检测时,不会有与真实IOU的计算,全部由一轮前向传播得到直接的数据,然后经过NMS输出。(训练时不NMS,检测时不计算与真实值的IOU)
groungTruth格式:
-
<filename>: 表示这个文件是对应于哪一个jpg图片的。 -
<size>:表示对应的jpg图片大小。 -
<object>:就是这个图片中的目标在图片中的信息。包括:目标名字,是否难识别,以及目标在整个图片中的坐标位置。(有几个 object 就是有几个目标)
损失函数组成:
-
confidence损失:负责检测的box的label是在线计算的IOU(注意是
标签(GT)的置信度是iou,评估值网络是多少就是多少),不负责和无目标的都为0,为了平衡,加入$λnoobj$ -
位置损失:容易理解,负责检测的才有位置损失,其他的都不需回传损失,也就不需要计算,此外小目标对于预测wh的误差更敏感,用开根的方法缓解。举例来说,大小为10和大小为100的目标,预测大小分别为20和110,损失一样但是显然小目标检测的更差一些,开根后,(√20−√10)^2=1.7(20−10)^2=1.7,而(√110−√100)^2=0.24(110−100)^2=0.24,相当于强化了小目标的wh的损失。
-
类别损失:容易理解,含有目标的网格才有类别损失,其他都不需要回传损失,也就不需要计算。
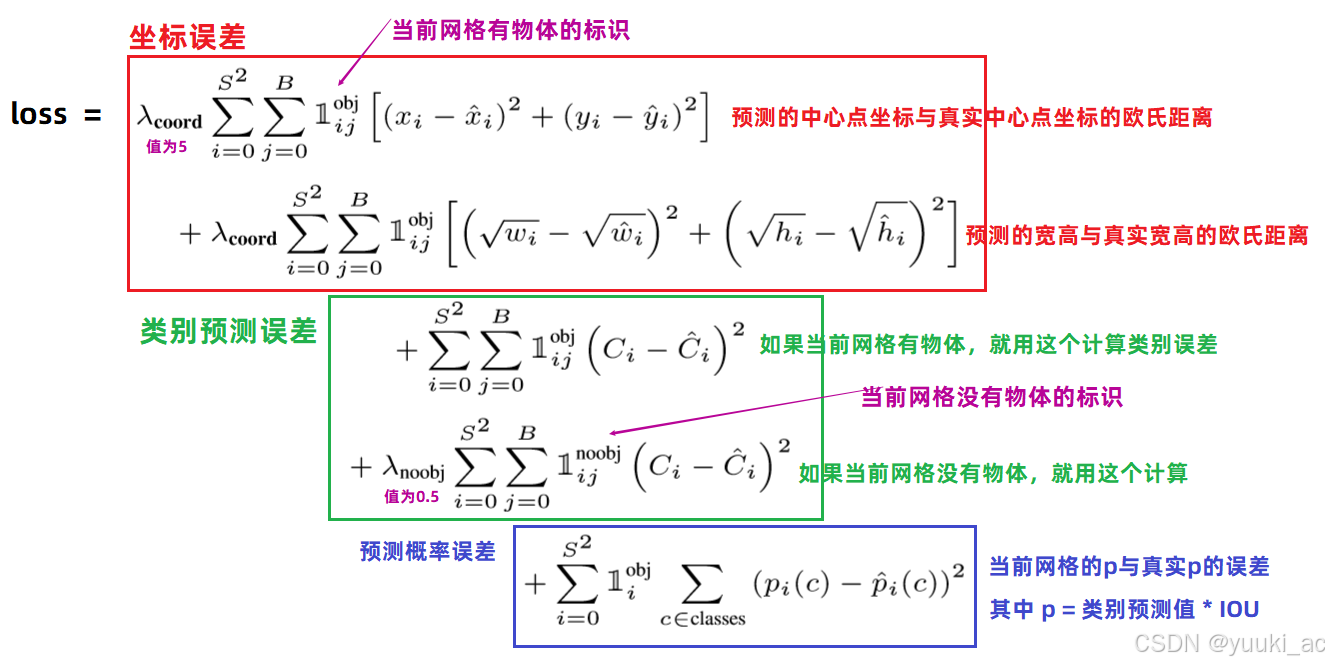
7.每个grid cell 都有两个 bounding box 谁来 拟合 ground truth 做损失函数呢?
看谁和 ground truth的 IoU 更大。比如这里 就是由 外面这个大框 负责拟合 ground truth,让其尽量的逼近 调整成 ground truth 的样子,那么另外一个框就被打入冷宫了 ,它什么都不用做(计算其他的损失就只用算IOU大的那个,小的只算noobj),尽量让他置信度降为0。
7.yolo的不足
-
一个cell预测的两个边界框共用一个类别预测, 在训练时会选取与标签IoU更大的一个边框负责回归该真实物体框,在测试时会选取置信度更高的一个边框,另一个会被舍弃,且会选取计算后对应概率最高的类别物体,因此7×7=49个gird cell最多只能预测49个物体(种类)。
-
因为每一个 grid cell只能有一个分类,也就是他只能预测一个物体(个数),这也是导致YOLO对小目标物体性能比较差的原因。如果所给图片极其密集,导致 grid cell里可能有多个物体,但是YOLO模型只能预测出来一个,那这样就会忽略在本grid cell内的其他物体。
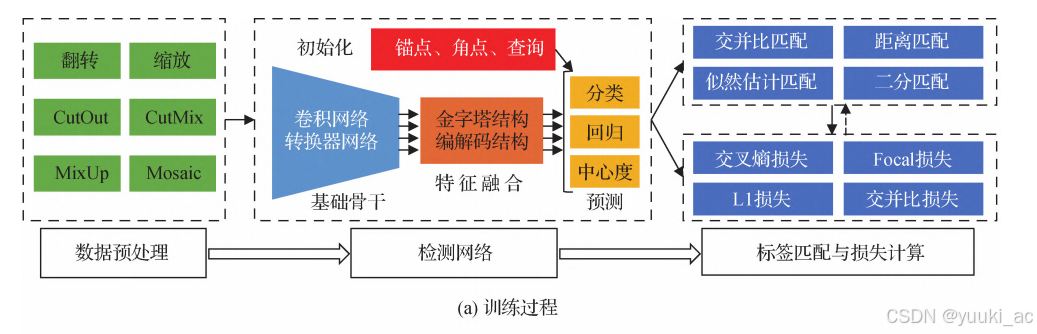
目标检测的训练(主要针对yolo)
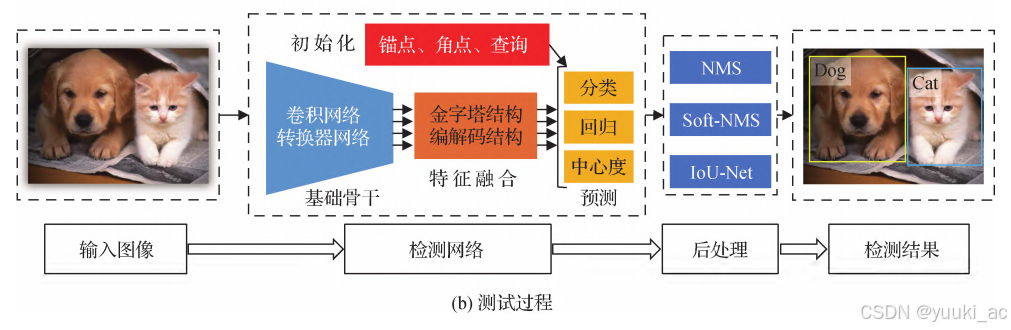
目标检测的测试
YOLO v2-2017:全流程多尺度方法
YOLOv2相对v1版本,在继续保持处理速度的基础上,从预测更准确(Better),速度更快(Faster),识别对象更多(Stronger,但只是理论上)这三个方面进行了改进。

-
batch normalization:批标准化有助于更快的收敛,解决反向传播过程中的梯度消失和梯度爆炸问题,降低对一些超参数的敏感性,并正则化,以获得更好的收敛速度和收敛效果。在yoloV2中卷积后全部加入Batch Normalization,网络会提升2%的mAP。
-
使用高分辨率图像微调分类模型:YOLOV2在采用 224x224 图像进行分类模型预训练后,再采用 448x448 的高分辨率样本对分类模型进行微调(v1没有的)(10个epoch),使网络特征逐渐适应 448x448 的分辨率。然后再使用 448x448 的检测样本进行训练,缓解了分辨率突然切换造成的影响。网络的mAP提升了约4%。
-
采用Anchor Boxes并使用聚类提取anchor尺寸:每个grid采用5个先验框,总共有13x13x5=845个先验框。对训练集中标注的边框进行聚类分析,统计出更符合样本中对象尺寸的先验框,这样就可以减少网络微调先验框到实际位置的难度。YoloV2选择了聚类的五种尺寸最为anchor box。/;
-
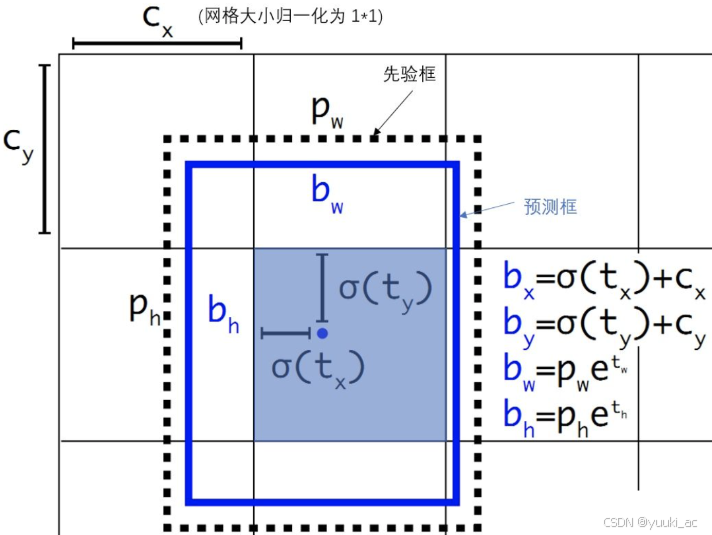
边框位置的预测:Yolov2中将边框的结果约束在特定的网格中。σ是sigmoid函数。 tx,ty,tw,th,to是要学习的参数。由于σ函数将 tx,ty约束在(0,1)范围内,预测边框的蓝色中心点被约束在蓝色背景的网格内。约束边框位置使得模型更容易学习,且预测更为稳定。
-
细粒度特征融合:图像中对象会有大有小,为了更好的检测出一些比较小的对象,最后输出的特征图需要保留一些更细节的信息。YOLO2引入一种称为passthrough层的方法在特征图中保留一些细节信息。具体来说,就是在最后一个pooling之前,特征图的大小是26x26x512,将其1拆4,直接传递(passthrough)到pooling后(并且又经过一组卷积)的特征图,两者叠加到一起作为输出的特征图。
-
多尺度训练:YOLO2没有全连接层,可以输入任何尺寸的图像。因为整个网络下采样倍数是32,采用了{320,352,…,608}等10种输入图像的尺寸,这些尺寸的输入图像对应输出的特征图宽和高是{10,11,…19}。训练时每10个batch就随机更换一种尺寸,使网络能够适应各种大小的对象检测。
-
速度更快(网络结构更新):yoloV2提出了Darknet-19(有19个卷积层和5个MaxPooling层)网络结构作为特征提取网络。yoloV2的网络中只有卷积+pooling,从416x416x3 变换到 13x13x5x25。增加了batch normalization,增加了一个passthrough层,去掉了全连接层,以及采用了5个先验框:
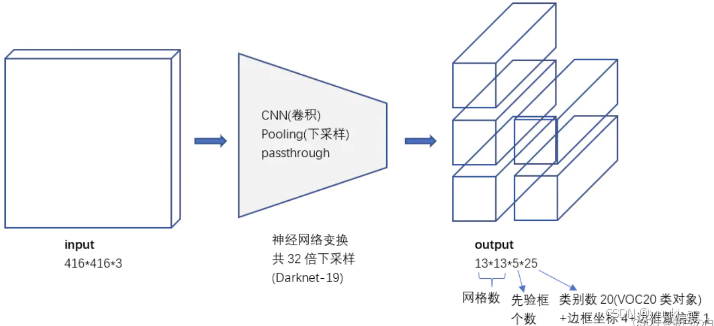
YOLO v3-2018
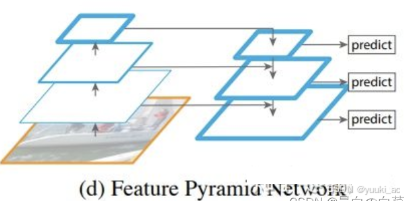
yoloV3以V1,V2为基础进行的改进,主要有:利用多尺度特征进行目标检测(针对小目标改进很大);先验框更丰富(三个不同尺度);调整了网络结构;对象分类使用logistic代替了softmax,更适用于多标签分类任务。
-
多尺度检测(特征金字塔FPN):通常一幅图像包含各种不同的物体,有大有小。比较理想的是一次就可以将所有大小的物体同时检测出来。在不同级别的feature map对应不同的scale,可以在不同级别的特征图中进行目标检测。首先建立图像金字塔,对不同深度的feature map分别进行目标检测,当前层的feature map会对未来层的feature map进行上采样,当前的feature map就可以获得“未来”层的信息,使低阶特征与高阶特征有机融合。
-
网络模型结构:YOLO3采用了Darknet-53的网络结构(含有53个卷积层),它借鉴了残差网络ResNet的做法,在层之间设置了shortcut,来解决深层网络梯度的问题。Yolov3的网络结构是比较经典的one-stage结构,分为输入端、Backbone、Neck和Prediction四个部分。v3没有池化层和全连接层,网络的下采样是通过设置卷积的stride=2来达到的,每当通过这个卷积层之后图像的尺寸就会减小到一半。
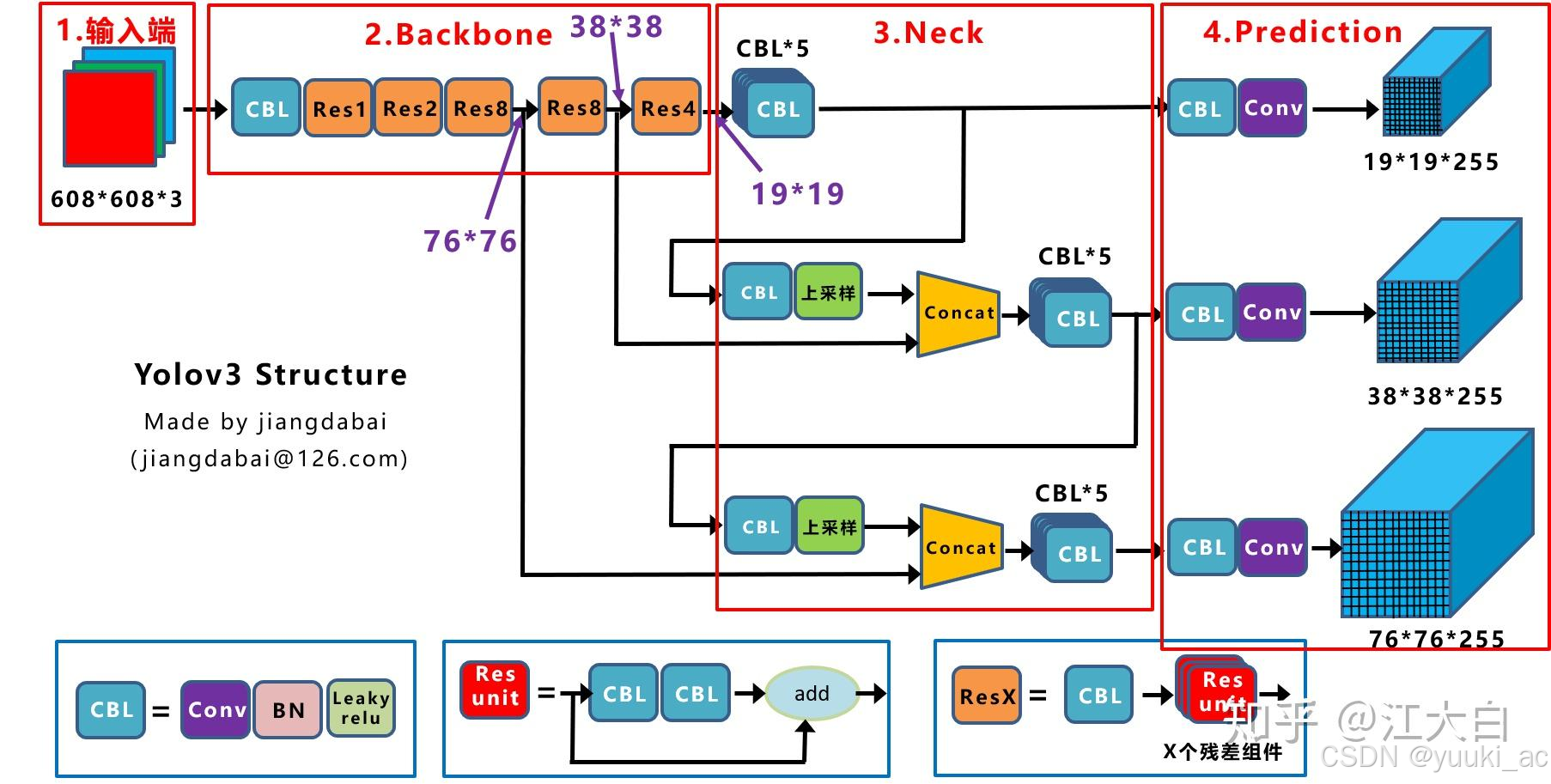
-
1、CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成。
2、Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
3、ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是416->208->104->52->26->13大小。
4、Concat:张量拼接,会扩充两个张量的维度,例如26×26×256和26×26×512两个张量拼接,结果是26×26×768。
5、Add:张量相加,张量直接相加,不会扩充维度,例如104×104×128和104×104×128相加,结果还是104×104×128。
-
-
先验框:yoloV3采用K-means聚类得到先验框的尺寸,为每种尺度设定3种先验框,总共聚类出9种尺寸的先验框。

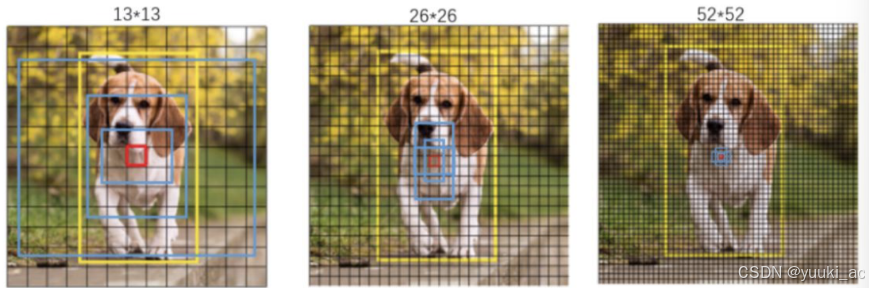
-
Logistic回归:预测对象类别时不使用softmax(某些class有重叠(多标签的目标分类),softmax不方便,比如woman和person),而是被替换为一个1x1的卷积层+logistic激活函数的结构。
logistic分类器将每个类别的输出视为独立的二分类问题,对每个类别使用sigmoid函数进行激活。sigmoid函数将输出限制在0到1之间,表示每个类别的存在概率。
在YOLOv3 中,利用逻辑回归来预测每个边界框的客观性分数( object score ),也就是YOLOv1 论文中说的confidence :
● 正样本: 如果当前预测的包围框比之前其他的任何包围框更好的与ground truth对象重合,那它的置信度就是 1。
● 忽略样本: 如果当前预测的包围框不是最好的,但它和 ground truth对象重合了一定的阈值(这里是0.5)以上,神经网络会忽略这个预测。
● 负样本: 若bounding box 没有与任一ground truth对象对应,那它的置信度就是 0
Q1:为什么YOLOv3要将正样本confidence score设置为1?
置信度意味着该预测框是或者不是一个真实物体,是一个二分类,所以标签是1、0更加合理。并且在学习小物体时,有很大程度会影响IOU。如果像YOLOv1使用bounding box与ground truth对象的IOU作为confidence,那么confidence score始终很小,无法有效学习,导致检测的Recall不高。
Q2:为什么存在忽略样本?
由于YOLOV3采用了多尺度的特征图进行检测,而不同尺度的特征图之间会有重合检测的部分。例如检测一个物体时,在训练时它被分配到的检测框是第一个特征图的第三个bounding box,IOU为0.98,此时恰好第二个特征图的第一个bounding box与该ground truth对象的IOU为0.95,也检测到了该ground truth对象,如果此时给其confidence score强行打0,网络学习的效果会不理想。
-
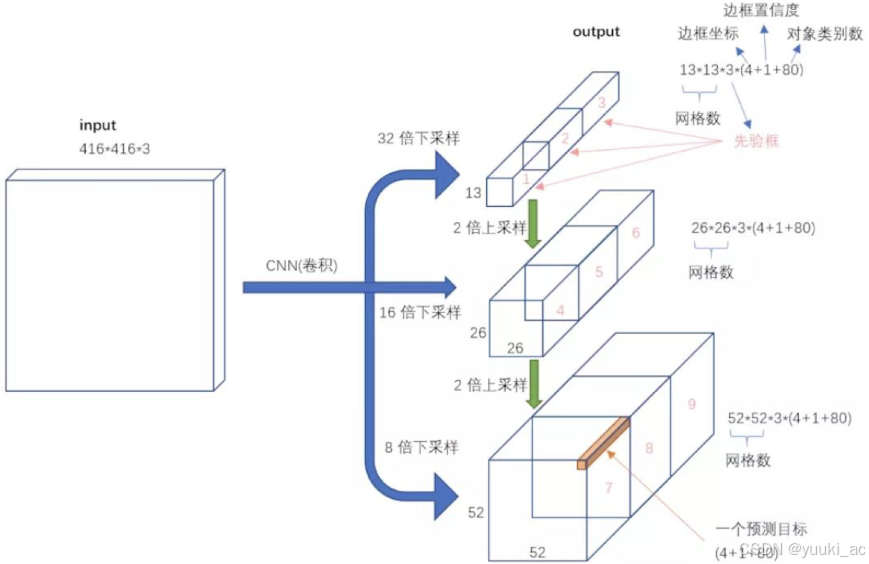
yolov3输入与输出:输入416×416×3的图像,通过darknet网络得到三种不同尺度的预测结果;YOLOv3共有13×13×3 + 26×26×3 + 52×52×3个预测 。每个预测对应85维,分别是4(坐标值)、1(置信度分数)、80(coco类别概率)。
YOLO v4-2020
YOLO V4是YOLO系列一个重大的更新,其在COCO数据集上的平均精度(AP)和帧率精度(FPS)分别提高了10% 和12%。
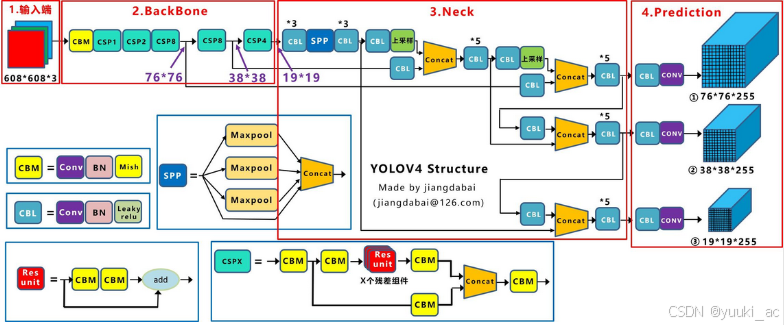

- CBM:Yolov4网络结构中的最小组件,由Conv+Bn+Mish激活函数三者组成。
- CSPX:由三个卷积层和X个Res unint模块Concate组成。
- SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
-
输入端采用mosaic数据增强:它将四张图像拼接成一张图像进行训练。通过这种方式,模型能够在训练时看到更加多样化的组合场景,从而提升了模型对不同物体大小和复杂背景的适应性。
-
Backbone上采用了CSPDarknet53、Mish激活函数、Dropblock等方式:CSPNet(Cross Stage Partial Network,跨阶段部分网络)通过在不同阶段引入部分连接,减少了计算量并提高了模型的学习效率。
-
Neck中采用了SPP、FPN+PAN的结构:PANet特征融合:YOLOv4引入了PANet(Path Aggregation Network)模块,用于在不同尺度的特征图之间进行信息传递和融合,以获取更好的多尺度特征表示。SPP:具体是在CSPDarknet-53网络的后面,通过在不同大小的池化层上进行特征提取,从而捕捉到不同尺度上的上下文信息。
-
输出端则采用CIOU_Loss、DIOU_nms操作:CIOU是一种改进的目标检测损失函数,用于衡量预测框和真实框之间的距离。CIOU是DIoU的进一步扩展,除了考虑框的位置和形状之间的距离外,还引入了一个附加的参数用于衡量框的长宽比例的一致性。
-
SAM(Spatial Attention Module):通过引入SAM模块,YOLOv4能够自适应地调整特征图的通道注意力权重。以增强对目标的感知能力。
🔬YOLOv5算法简介-2020
YOLOv5是一种单阶段目标检测算法(前面是Darknet框架,现在是PyTorch),该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
-
输入端:在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
-
基准网络:融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP1/2结构;
-
Neck网络:目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,Yolov5中添加了FPN+PAN结构;
-
Head输出层:输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
-
自对抗训练(Self-Adversarial Training, SAT):YOLOv4 采用了一种新颖的自对抗训练方法。在训练过程中,模型先通过反向传播的方式使得网络产生一个对抗噪声,然后再利用这个噪声进行训练。这种方法增强了模型的鲁棒性和防御对抗攻击的能力,进一步提高了检测的精度。
-
自学习边界框锚:YOLOv5 引入了自学习边界框锚(AutoAnchor)机制,在训练过程中,锚框可以根据数据集自动调整。相比于固定的锚框设计,自学习锚框能够更好地适应不同的数据集和场景,提高了边界框预测的精度和学习效率。这一机制有效地减少了手动调整锚框参数的复杂性,提升了训练效果。
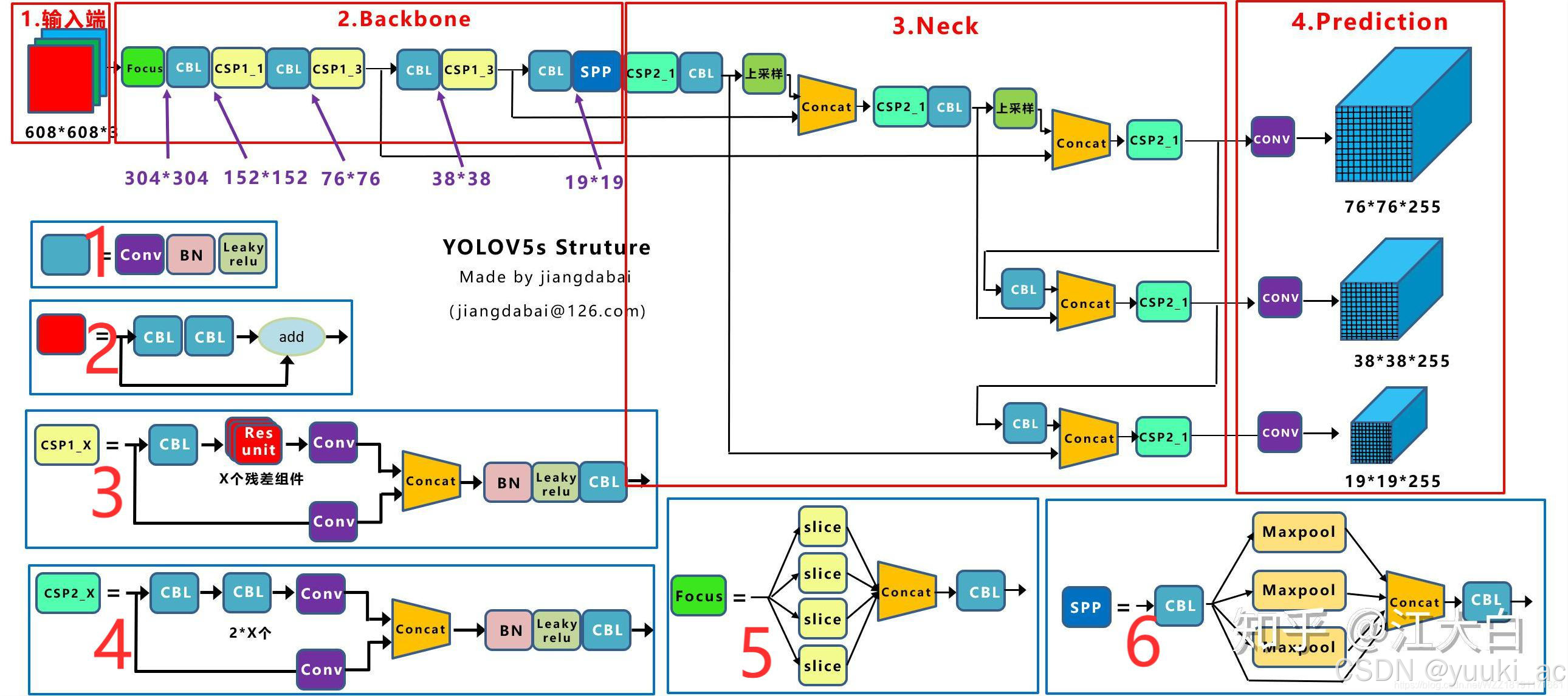
对于一个目标检测算法而言,通常可以将其划分为4个通用的模块,具体包括:输入端、基准网络、Neck网络与Head输出端,对应于上图中的4个红色模块。
基本组件
-
Focus:基本上就是YOLO v2的passthrough。
-
CBL:由Conv+Bn+Leaky_relu激活函数三者组成。
-
CSP1_X:借鉴CSPNet网络结构,由三个卷积层和X个Res unint模块Concate组成。
-
CSP2_X:不再用Res unint模块,而是改为CBL。
-
SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
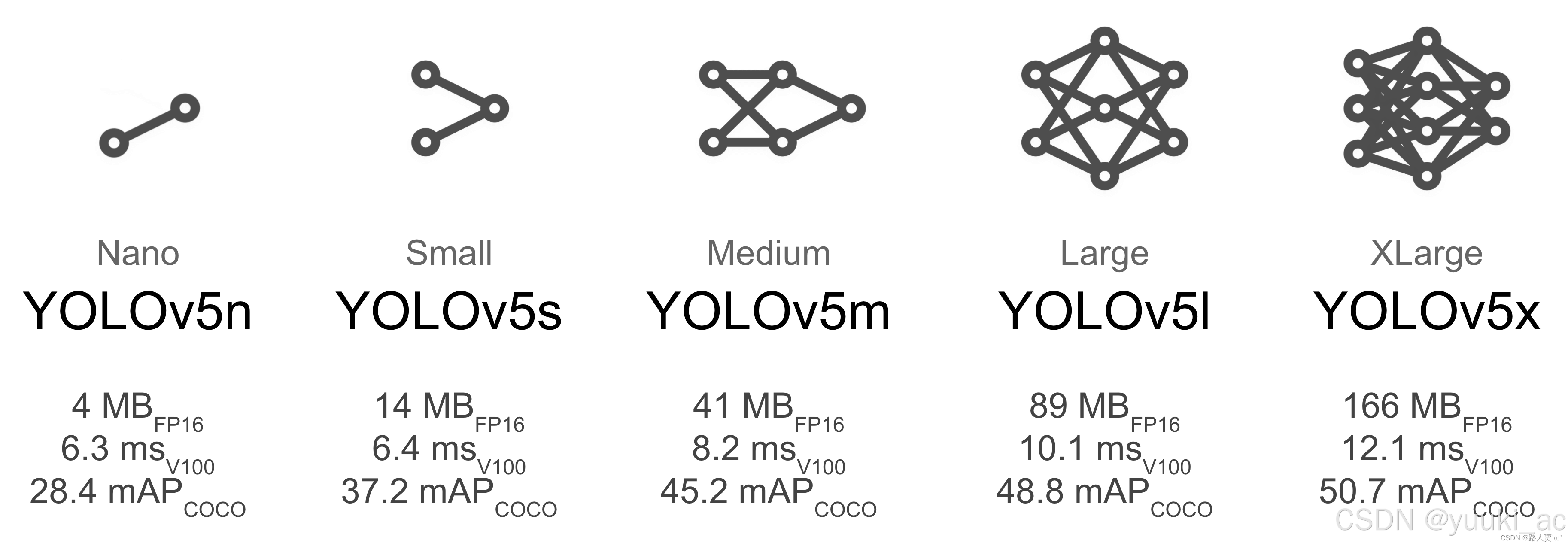
YOLOv5算法具有4个版本,具体包括:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x.
Yolov5s网络是Yolov5系列中深度最小,特征图的宽度最小的网络。后面的3种都是在此基础上不断加深,不断加宽。
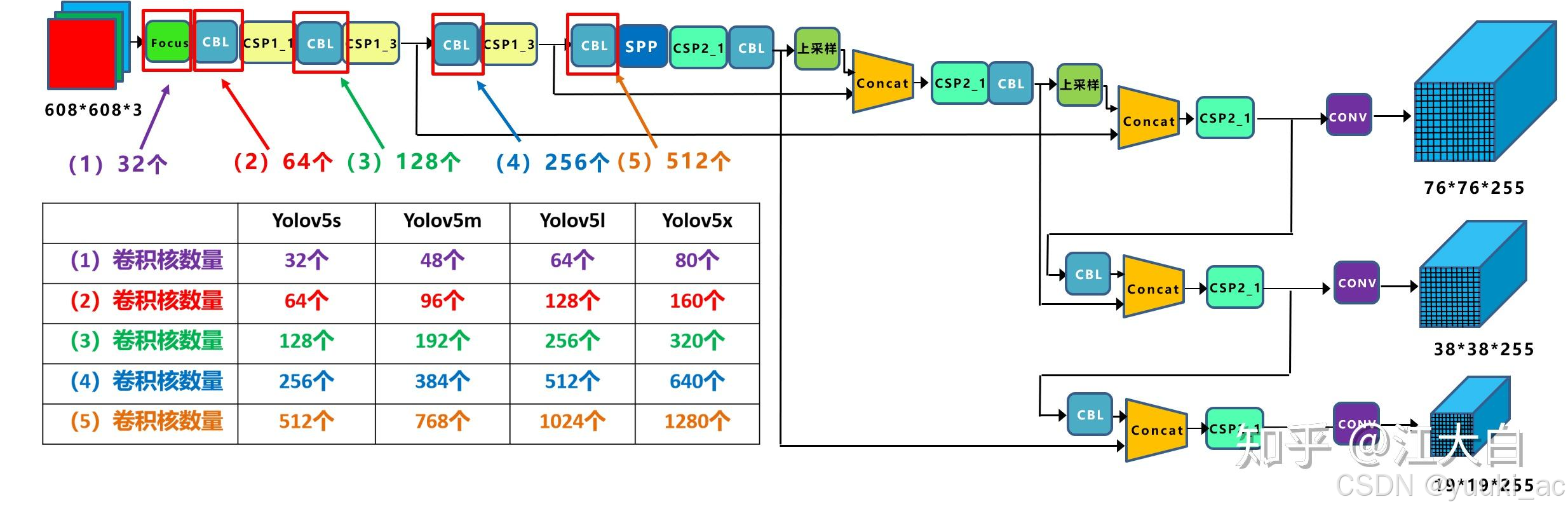
输入端-输入端表示输入的图片。该网络的输入图像大小为608*608,该阶段通常包含一个图像预处理阶段,即将输入图像缩放到网络的输入大小,并进行归一化等操作。在网络训练阶段,YOLOv5使用Mosaic数据增强操作提升模型的训练速度和网络的精度;并提出了一种自适应锚框计算与自适应图片缩放方法。
-
数据增强:四张图缩放后拼接为一张新的图
-
自适应锚框计算:通过K-means聚类算法计算一组合适的矛框尺寸,避免手动调整
-
自适应图片缩放: 根据原始图像尺寸和网络输入尺寸计算缩放比例,对图像进行缩放,并在必要时填充边缘以保持网络输入尺寸的一致性。(在模型推理时使用,训练时仍然使用固定的输入尺寸。)
Backbone基准网络-基准网络通常是一些性能优异的分类器种的网络,该模块用来提取一些通用的特征表示。YOLOv5中不仅使用了CSPDarknet53结构,而且使用了Focus结构作为基准网络。
-
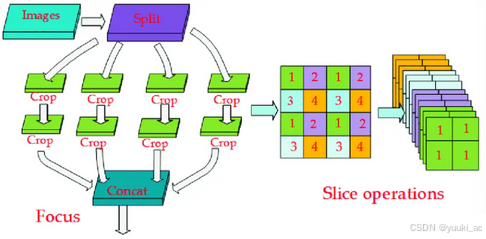
Focus结构:通过特定的切片、拼接和1*1卷积,使保留信息的同时计算量减少、通道数增加(提供更丰富的特征)
-
CSP结构
-
CSP1_X:在Backbone中使用,通过共享权重减少计算量。
-
CSP2_X:在Neck中使用,结合CSP结构和Focus结构的优点,进一步减少计算量并保持特征表达能力。
-
CSPNet(Cross Stage Partial Network)是一种用于计算机视觉任务,尤其是在目标检测领域中的网络结构优化技术。CSPNet的核心思想是在网络的多个阶段中共享权重,以此来减少计算量和参数数量,同时保持或提升模型的性能。
Neck网络-Neck网络通常位于基准网络和头网络的中间位置,利用它可以进一步提升特征的多样性及鲁棒性。虽然YOLOv5同样用到了SPP模块、FPN+PAN模块,但是实现的细节有些不同。
-
FPN (特征金字塔网络):通过自顶向下的路径传递高层的语义信息。
-
PAN (路径聚合网络):通过自底向上的路径传递低层的细节信息。
Head输出端-Head用来完成目标检测结果的输出。针对不同的检测算法,输出端的分支个数不尽相同,通常包含一个分类分支和一个回归分支。YOLOv5利用GIOU_Loss来代替Smooth L1 Loss函数,从而进一步提升算法的检测精度。
-
CIOU_Loss(Complete Intersection over Union Loss)是一种用于目标检测任务中bounding box预测的损失函数。CIOU_Loss不仅考虑了重叠区域(IoU),还考虑了中心点距离和宽高比,从而更全面地衡量预测框和真实框之间的相似度。CIOU_Loss的计算包括以下几个部分:
-
IoU(Intersection over Union):计算预测框和真实框的交集与并集的比值。
-
距离惩罚(Distance Penalty):计算预测框中心点与真实框中心点的欧氏距离。
-
宽高比惩罚(Aspect Ratio Penalty):计算预测框与真实框的宽高比的差的惩罚项。
-

-
DIOU_nms(Distance Intersection over Union Non-Maximum Suppression)是一种改进的非极大值抑制(NMS)算法,它在传统的IoU(Intersection over Union)NMS的基础上增加了对预测框与真实框中心点距离的考量。DIOU_nms的目的是更精确地筛选出最佳的检测框,尤其是在处理重叠目标和相近目标时。
-
DIOU (距离交并比):一种改进的IoU,考虑了预测框和真实框之间的中心点距离。
-
nms (非极大值抑制):用于筛选重叠的预测框,保留最佳的检测结果。
-
YOLOv5训练策略:YOLOv5的训练策略包括多尺度训练、warmup预热、cosine学习率下降、EMA权重更新和混合精度训练。
YOLOv5改进方向:YOLOv5作为一个开放的算法框架,社区已经提出了多种改进方案,包括添加注意力机制、替换主干网络、改进损失函数和NMS算法等。
💡模型&应用选择
yolo-v3/5/8使用较多,yolov5是针对yolov4在工程应用上做了一些列工程优化,使得用起来有更多的选择和更加的简单在实际测试中,Yolov4的准确性有不错的优势,而Yolov5的多种网络结构使用起来更加灵活。
YOLOv3/v4/v5网络架构与轻量化部署深度解析
一、YOLOv3架构与轻量化
-
核心网络结构
- 主干网络(Backbone):采用Darknet-53(53层卷积),包含5个残差块,通过步长卷积替代池化层实现下采样,生成多尺度特征图(13×13、26×26、52×52)。
- 特征融合:FPN+PAN结构,通过上采样和拼接融合不同层级的语义信息,提升小目标检测能力。
- 检测头:每个尺度预测3个锚框,使用Logistic回归替代Softmax,支持多标签分类。
-
轻量化改进
- Tiny-YOLOv3:主干替换为Tiny Darknet(8层卷积),移除残差模块,仅保留2个检测头(13×13、26×26),参数量8.7M,速度123 FPS(V100)。
- 优化方向:引入深度可分离卷积或Ghost模块,减少计算量40%,适用于低算力设备(如树莓派)。
二、YOLOv4架构与轻量化
-
核心网络结构
- 主干网络:升级为CSPDarknet53,通过CSP(跨阶段部分连接)结构拆分特征通道,减少计算冗余,提升梯度复用效率。
- 特征增强模块:
- SPP(空间金字塔池化):融合4种不同尺度的最大池化特征,扩大感受野。
- PANet:双向特征金字塔,结合FPN(自顶向下)和PAN(自底向上)路径,增强多尺度目标定位能力。
- 激活函数:采用Mish,负区间保留梯度,提升非线性表达能力。
-
轻量化改进
- YOLOv4-Tiny:精简CSPDarknet为2个检测头,移除SPP模块,参数量5.9M,速度65 FPS(V100)。
- YOffleNet:用ShuffleNet替代主干网络,参数量降至原模型的39%,适用于移动端(46 FPS,Jetson Nano)。
三、YOLOv5架构与轻量化
-
核心网络结构
- 主干网络:基于CSPDarknet,引入Focus结构(切片操作替代卷积下采样),输入分辨率416×416时计算量减少75%。
- 模块创新:
- C3模块:简化CSP结构为3个卷积层,减少参数量(原CSP模块的60%)。
- SPPF:串行池化替代并行,加速特征金字塔生成(计算速度提升30%)。
- 自适应训练:动态调整锚框尺寸,支持输入图像尺寸灵活缩放(无需固定为32倍数)。
-
轻量化改进
- YOLOv5s:通过深度因子(0.33)和宽度因子(0.5)调整模型规模,参数量7.5M,速度140 FPS(V100)。
- YOLOv5-Ghost:用GhostNet替换CSPDarknet,参数量3.8M,速度200 FPS(Jetson Xavier)。
四、YOLOv3、YOLOv4、YOLOv5网络结构对比
| 网络组件 | YOLOv3 | YOLOv4 | YOLOv5 |
|---|---|---|---|
| 主干网络 | Darknet-53(53层卷积,5个残差块,无池化层,步长卷积下采样) | CSPDarknet53(CSP结构减少计算冗余,引入Mish激活函数) | CSPDarknet(动态调整深度/宽度因子,SPPF模块优化计算效率) |
| 颈部网络 | FPN(特征金字塔网络) | SPP(空间金字塔池化)+ PANet(双向特征融合) | FPN + PAN(双向跨尺度融合,SPPF加速池化操作) |
| 检测头 | 3个尺度(13x13, 26x26, 52x52),每个尺度3个锚框 | 3个尺度,锚框数量与YOLOv3相同,CIoU Loss优化边界框回归 | 3个尺度(可扩展至5),自适应锚框计算,GIOU Loss |
| 激活函数 | Leaky ReLU | Mish(增强非线性,减少梯度消失) | SiLU(平衡计算效率与精度) |
| 训练优化 | Mosaic数据增强(YOLOv4后引入),二元交叉熵损失 | Mosaic数据增强,CIoU Loss,SAT自对抗训练 | 自适应锚框,自动化数据增强(Albumentations),动态学习率调整 |
| 轻量化方向 | Tiny-YOLOv3(8层卷积,2个检测头,无残差模块) | YOLOv4-Tiny(CSP精简版,2个检测头,GhostNet/ShuffleNet优化) | YOLOv5s(深度/宽度因子控制规模,参数仅7.5M) |
五、轻量化网络结构对比
| 轻量化网络 | 主干网络 | 颈部/检测头优化 | 参数量与速度 |
|---|---|---|---|
| Tiny-YOLOv3 | Tiny Darknet(8层卷积,无残差) | 2个检测头(13x13, 26x26),FPN简化 | 参数量:8.7M,速度:123 FPS(V100) |
| YOLOv4-Tiny | CSPDarknet精简版(CSP + Mish) | 2个检测头,PANet简化,SPP模块移除 | 参数量:5.9M,速度:65 FPS(V100) |
| YOLOv5s | CSPDarknet(深度因子0.33,宽度因子0.5) | FPN+PAN精简,SPPF快速池化 | 参数量:7.5M,速度:140 FPS(V100) |
| YOLOv5-Ghost | GhostNet替换CSPDarknet | 保留FPN+PAN,深度可分离卷积优化 | 参数量:3.8M,速度:200 FPS(Jetson Xavier) |
六、核心差异与创新点
| 对比维度 | YOLOv3 | YOLOv4 | YOLOv5 |
|---|---|---|---|
| 结构创新 | 引入残差模块,多尺度预测(FPN) | CSP结构减少计算冗余,SPP+PANet强化特征融合 | Focus切片操作(后改为6x6卷积),SPPF加速池化 |
| 训练策略 | 基础数据增强,固定锚框 | Mosaic增强,SAT自对抗训练,CIoU Loss | 自适应锚框,自动化增强(Albumentations库) |
| 轻量化技术 | 简单减少卷积层(Tiny-YOLOv3) | CSP精简 + GhostNet/ShuffleNet模块 | 动态深度/宽度因子,GhostNet集成 |
| 适用领域 | 实时性要求高的场景(无人机、移动端) | 复杂场景小目标检测(安防、自动驾驶) | 工业检测(PCB缺陷识别)、边缘计算(Jetson部署) |
YOLOv3系列
| 版本 | 参数量 (M) | FLOPs (B) | 速度 (FPS) | 准确度 (mAP@0.5:0.95) | 适用硬件场景 |
|---|---|---|---|---|---|
| YOLOv3 | 61.5 | 155.6 | 30-45 | 33.0% | 通用GPU(如V100) |
| Tiny-YOLOv3 | 8.7 | 5.6 | 123 (V100) | 23.7% | 树莓派、Jetson Nano |
| Lite-YOLOv3 | 3.1 | 2.8 | 150 (2080Ti) | 30.6% | 低功耗嵌入式设备 |
核心特点:
- YOLOv3:Darknet-53主干网络,3尺度预测,适合通用场景但参数量较大;
- Tiny-YOLOv3:简化至8层卷积,移除残差模块,速度优先但精度显著下降;
- Lite-YOLOv3:引入深度可分离卷积和Bottleneck模块,平衡精度与资源消耗。
YOLOv4系列
| 版本 | 参数量 (M) | FLOPs (B) | 速度 (FPS) | 准确度 (mAP@0.5:0.95) | 适用硬件场景 |
|---|---|---|---|---|---|
| YOLOv4 | 64.0 | 180.3 | 40-50 | 43.5% | 高端GPU(如V100) |
| YOLOv4-Tiny | 5.9 | 3.8 | 65 (V100) | 40.2% AP50 | Jetson Nano、移动端 |
| Scaled-YOLOv4 | 25.8 | 70.2 | 15 (V100) | 55.4% | 高性能服务器 |
核心特点:
- YOLOv4:CSPDarknet53主干,SPP+PANet特征融合,Mosaic数据增强提升小目标检测;
- YOLOv4-Tiny:精简CSP结构,移除SPP模块,速度与精度均衡;
- Scaled-YOLOv4:通过通道分割和结构优化,AP提升至COCO最高水平(55.8%),适合大规模部署。
YOLOv5系列
| 版本 | 参数量 (M) | FLOPs (B) | 速度 (FPS) | 准确度 (mAP@0.5:0.95) | 适用硬件场景 |
|---|---|---|---|---|---|
| YOLOv5s | 7.5 | 16.5 | 140 (V100) | 37.4% | 通用GPU、边缘服务器 |
| YOLOv5n | 1.9 | 4.5 | 443 (2080Ti) | 28.4% | 手机、低端嵌入式设备 |
| YOLOv5-Ghost | 3.8 | 7.2 | 200 (Xavier) | 34.1% | Jetson系列、FPGA |
| YOLOv5x | 86.7 | 209.1 | 12 (V100) | 50.1% | 高精度工业检测 |
核心特点:
- YOLOv5s:动态深度/宽度因子调整,SPPF加速池化,兼顾速度与精度;
- YOLOv5n:最小模型,Focus切片操作替代卷积,适合极低功耗场景;
- YOLOv5-Ghost:GhostNet替换主干网络,参数量减少58%,边缘端实时推理首选。
七、适用领域总结
- YOLOv3:适合通用实时检测(如视频监控),轻量版Tiny-YOLOv3适用于嵌入式设备。
- YOLOv4:在精度与速度间平衡,适合复杂场景(自动驾驶、卫星图像分析)。
- YOLOv5:模块化设计+工业级优化,适合快速部署(生产线质检、无人机避障)。
- 轻量化版本:Tiny系列适用于移动端(APP实时检测),YOLOv5s/Ghost适合边缘AI芯片(如NVIDIA Jetson)。

















 2161
2161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









