







概念
聚类算法是一种典型的无监督学习算法。聚类算法根据样本之间的相似性,将样本划分到不同的类别中,对于不同的相似度计算方法,会得到不同的聚类结果。
聚类的作用
聚类在工作中的主要用途如下:

聚类分类
划分聚类(Partitioning Clustering)
- 原理:将数据集划分为预定数量的簇,每个簇由其成员的平均值(如K-means)或代表点(如K-medoids)定义。
- 代表算法:K-means
- 优点:简单、快速,对大规模数据集有效。
- 缺点:需要预先指定簇的数量,对初始质心选择敏感,对噪声和异常点敏感。
层次聚类(Hierarchical Clustering)
- 原理:通过创建一个簇的层次结构来组织数据,可以生成树状图(树状聚类图)。
- 优点:不需要预先指定簇的数量,能够发现任意形状和大小的簇。
- 缺点:计算复杂度较高,对噪声和异常值敏感。
基于密度的聚类(Density-Based Clustering)
- 原理:根据数据空间中的密度分布来形成簇。
- 代表算法:DBSCAN、OPTICS
- 优点:不需要预先指定簇的数量,能够发现任意形状的簇。
- 缺点:对数据的局部密度变化敏感,对参数敏感。
基于网格的聚类(Grid-Based Clustering)
- 原理:将数据空间划分成有限数量的单元或“网格”,并在这些网格单元上应用聚类算法。
- 代表算法:STING、CLIQUE
- 优点:特别适合于大规模数据集和高维数据,减少计算量和存储需求。
- 缺点:可能受到网格分辨率的影响。
基于模型的聚类(Model-Based Clustering)
- 原理:假设数据是由多个概率分布生成的,每个分布对应一个簇。
- 代表算法:高斯混合模型GMM
- 优点:能够处理具有复杂分布的数据。
- 缺点:计算复杂度较高,需要选择合适的概率模型。
模糊聚类(Fuzzy Clustering)
- 原理:允许数据点以不同的隶属度属于多个簇。
- 代表算法:模糊C均值聚类(Fuzzy C-Means Clustering)
- 优点:能够处理现实世界中事物的模糊性和不确定性。
- 缺点:计算复杂度较高。
谱聚类(Spectral Clustering)
- 原理:基于图论和线性代数的聚类方法,利用数据的谱信息来发现簇结构。
- 优点:能够发现复杂形状的簇,不需要预先指定簇的数量。
- 缺点:对数据的特征矩阵敏感。
基于图的聚类(Graph-Based Clustering)
- 原理:将数据点视为图中的节点,通过分析节点之间的连接关系来发现簇结构。
- 优点:特别适用于具有复杂关系和层次结构的数据集。
- 缺点:计算复杂度较高,对图的构建敏感。
聚类模型评估
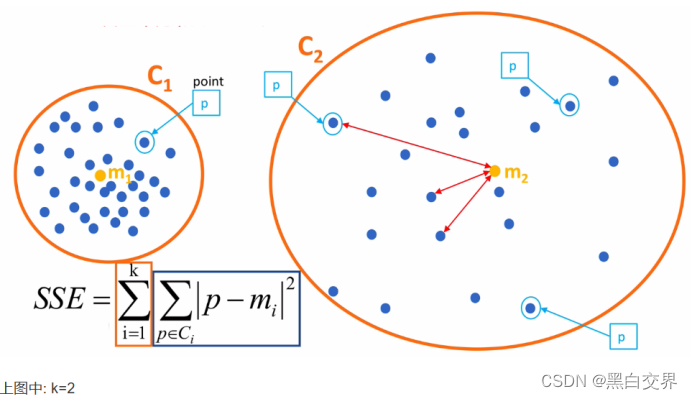
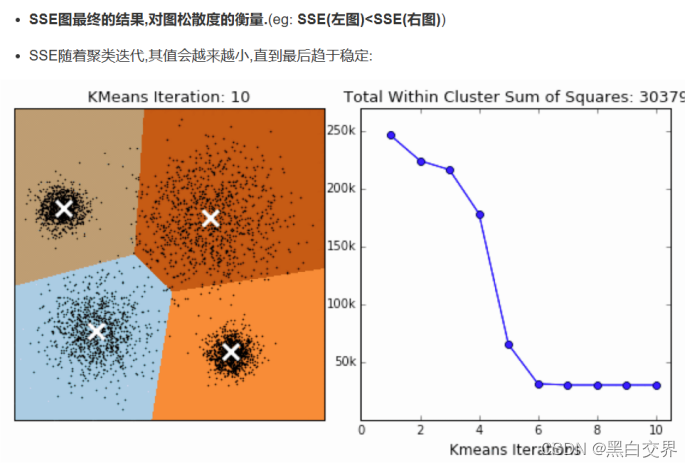
误差平方和SSE
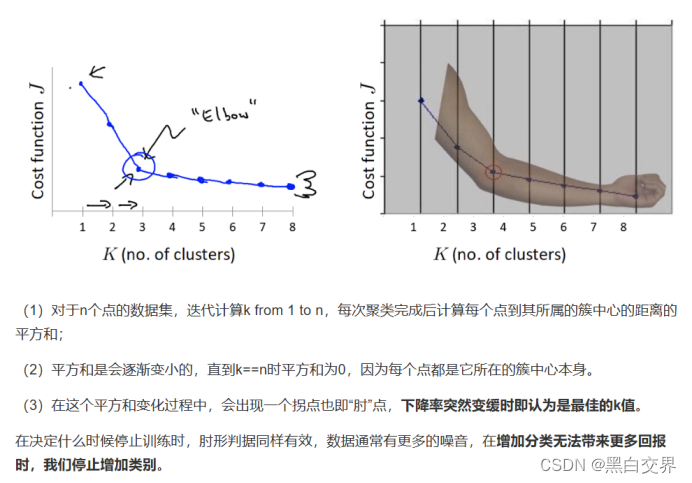
“肘”方法
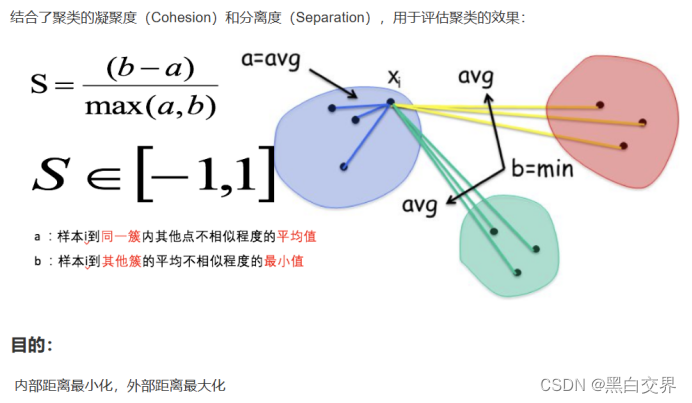
轮廓系数法
CH系数(Calinski-Harabasz Index)

总结
















 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









