







#记录对感知机模型的粗浅理解#
概念
感知机是一种简单的线性分类模型,用于处理二元分类问题。它由一个带有阈值的单层神经元组成。感知机模型接收输入特征向量,通过对特征与权重的线性组合加上偏置项,并应用激活函数(通常为阶跃函数或符号函数)来输出类别标签。其基本概念包括:
- 输入:输入由特征向量(Xi)组成,每个特征与对应的权重相乘后求和,再加上偏置项(b)。
- 权重:每个特征都有一个对应的权重,权重表示了每个特征对分类决策的重要性。
- 偏置项:偏置项决定了模型在没有任何输入时的输出值。
- 激活函数:通常使用阶跃函数或符号函数作为激活函数,用来将线性组合的结果转换为最终的类别标签。
- 学习算法:感知机模型通过基于误分类点的损失函数进行学习,采用梯度下降等优化算法来更新权重和偏置项,以减小损失函数,使模型能够更好地分类数据。
- 决策边界:感知机模型将特征空间划分为两个区域,这些区域通过一个超平面(决策边界)分隔,使得每个类别的样本都在相应的区域内。
简单理解如下图所示:
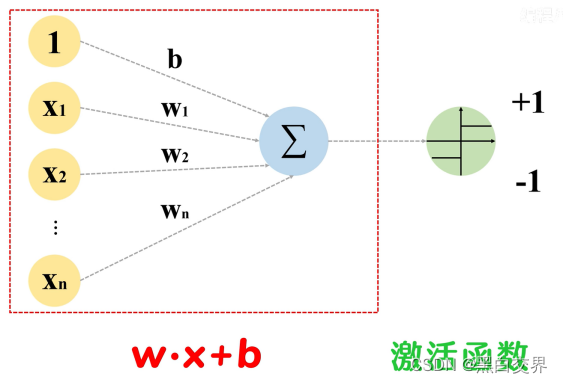
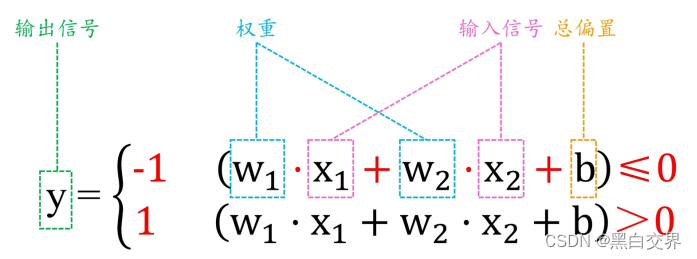
感知机模型是用于解决分类问题的模型。简单的感知机模型包括Perceptron(感知器),进一步看,使用多个感知机模型可以形成深度学习的感知网络,用于复杂的分类问题。
损失函数
这里说说其损失函数的理解,感知机用误分类样本到决策函数的距离来衡量模型的偏差。如图所示,其中中间行为误差衡量
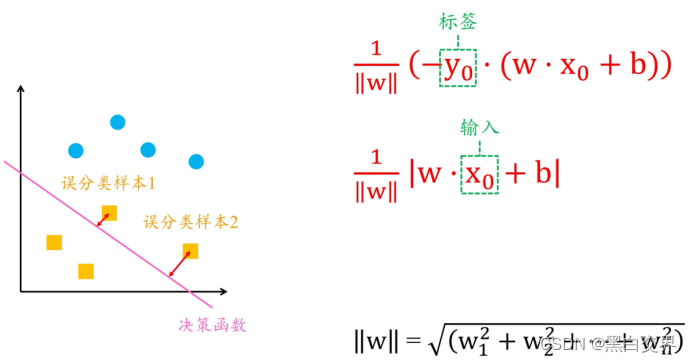
由于算法结果对决策函数的位置不敏感,所以可以将1/||W||部分去掉,则损失函数为:
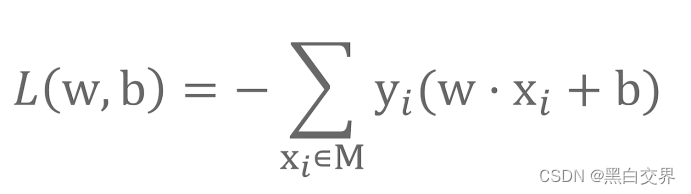
Perceptron简单示例
# 导入必要的库
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Perceptron
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集(作为分类的示例数据集)
iris = load_iris()
X = iris.data[:, :2] # 仅使用前两个特征便于演示
y = (iris.target != 0) * 1 # 转换为二元分类问题(1表示virginica,0表示其他)
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 标准化特征数据(对于Perceptron和许多其他模型很重要)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 初始化Perceptron分类器
perceptron = Perceptron(max_iter=100, eta0=0.1, random_state=42)
# 训练Perceptron模型
perceptron.fit(X_train, y_train)
# 使用训练好的Perceptron模型进行预测
y_pred = perceptron.predict(X_test)
# 计算模型的准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'准确率:{accuracy:.2f}')
# 可选:打印模型的系数和截距
print(f'系数:{perceptron.coef_}')
print(f'截距:{perceptron.intercept_}')文章内容学习自B站编程八点档的视频
若有错误,请批评指正!















 2585
2585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









